買的電子書沒有目錄書簽看著不舒服,手動加書簽加到想吐。想有沒有辦法快速加書簽。這要分為PDF目錄部分可以被復制和不可被復制兩種情況。不可復制時,要用到工具把目錄提取出來,變成文字。
工具:Foxit Phantom福昕閱讀器(下載鏈接:Foxit Phantom福昕閱讀器官網)、excel、在線文字轉換網址。
文字可復制
觀察書簽的格式,想辦法變成我們需要的樣子
先添加兩個書簽,然后導出,保存在一個你能找到的地方。
打開這個書簽,觀察它。可以發現,它的NAME和PAGE表示的是PDF的位置和書簽的名字,我們要做的就是,把這部分內容替換成我們自己的內容思考完發現,只要我們得到這兩列數據,就可以

想辦法得到“目錄”和“頁碼”兩列數據
替換的宗旨就是,把目錄和頁碼分成兩列
-
直接復制目錄到一個文本文件中
-
全局替換頁碼前的“……”為“#”(其他符號也行,但是是點號、頓號和/經常出現在目錄文字描述中,不要用)
-
文字復制到excel中
-
替換技巧:先替換“…”,然后替換“#.”為“#”,要不然會把1.2.1中的“.”替換掉。最后把“##”替換為“#”。
-
看一遍文本,確認是目錄后是#和頁碼,才算干凈

-
把處理好的文本文件粘貼到excel中,然后以“#”分列,標題和頁碼就分成了兩列。
-
這里的頁碼是書的頁碼,還要都加上一個數字11(前面有幾頁,可以根據你導出的page值和實際值對應)變成PDF的頁碼
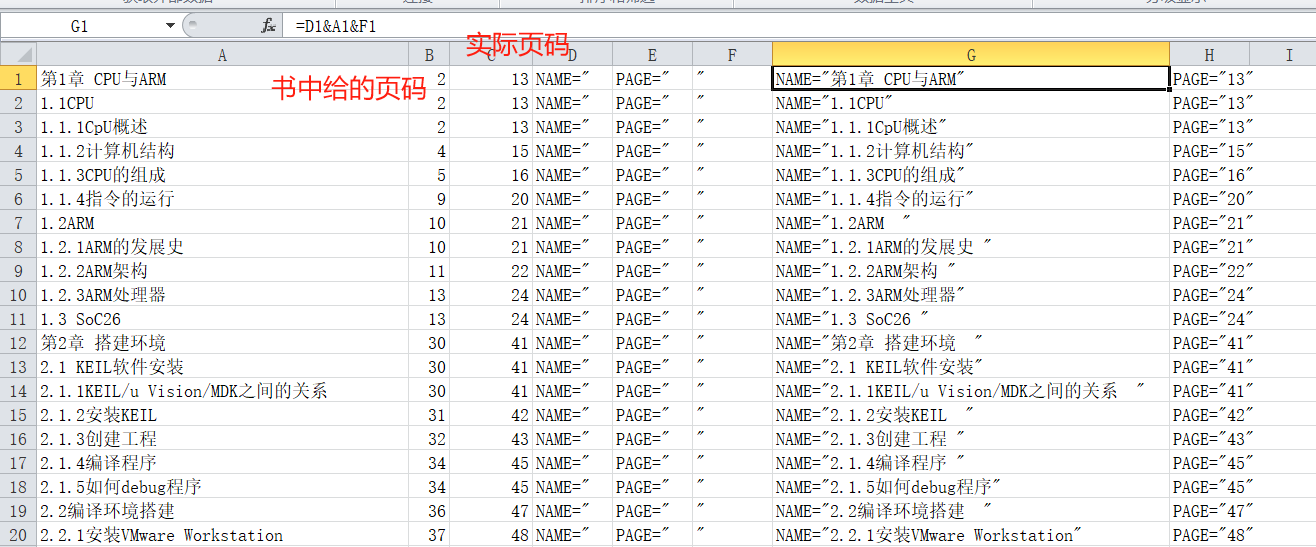
-
然后利用excel的函數功能&把單元格中的內容拼裝成書簽需要的格式。公式為“=A1&A3&A5”
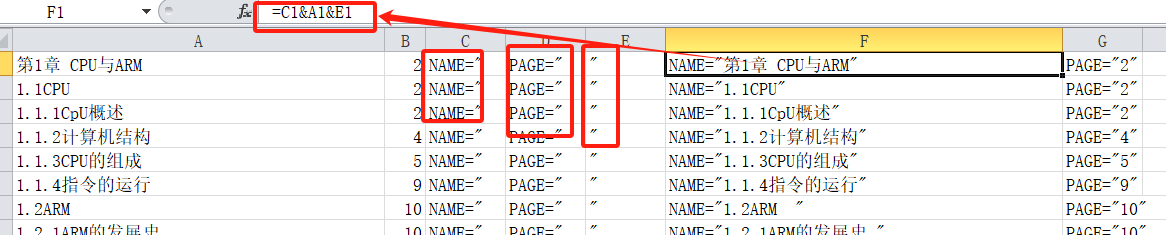
把目錄按照一定的格式放進書簽的xml中
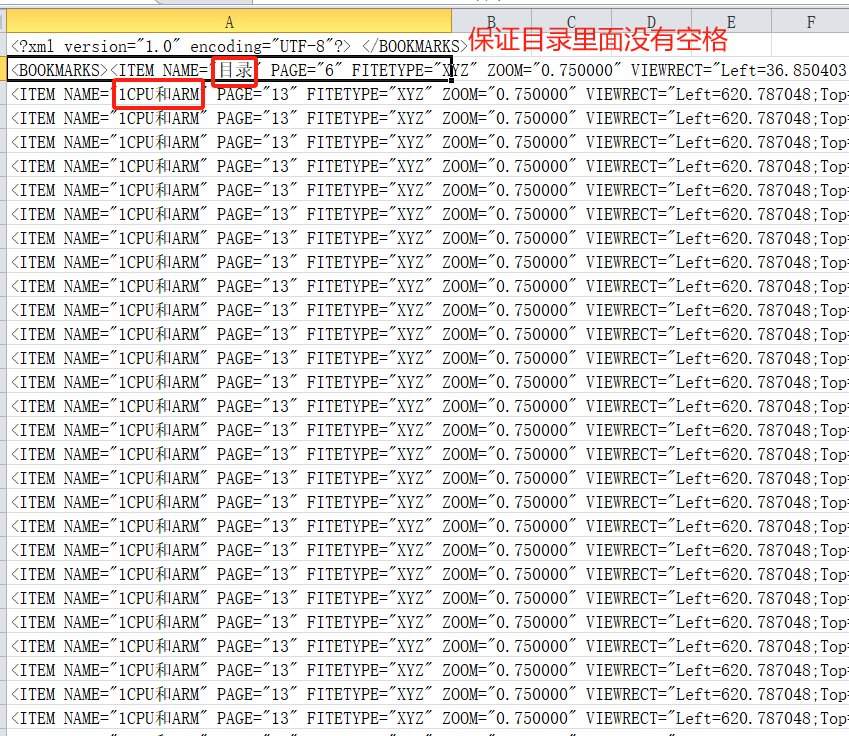
- 最后一行的“”先粘貼出來放個位置
- 用下拉的方式,復制出很多的行的格式(目錄有幾個行就拉幾個行)
- 再把“”粘貼到最后一行去
- 數據–分列–“按照空格分列”,然后就把NAME和PAGE分離出來了。
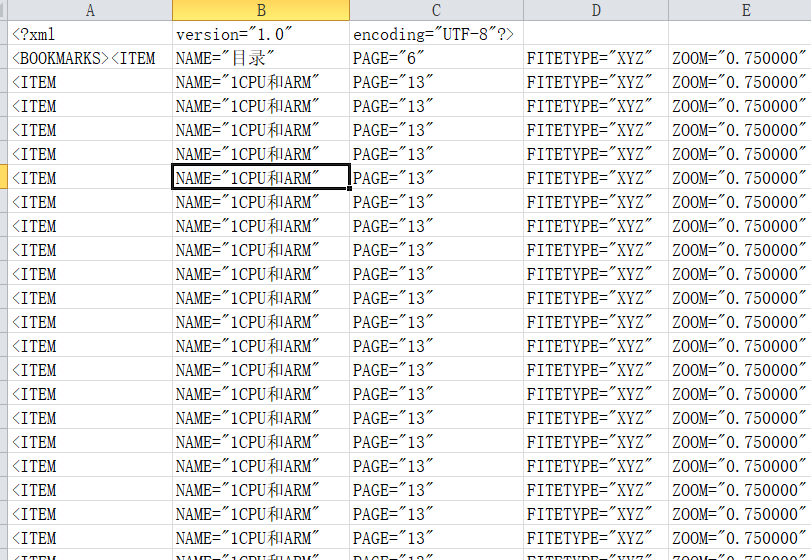
接下來把我們需要的NAME和PAGE填進去
- 步驟5中準備好的NAME和PAGE,覆蓋書簽圖中的B和C列,注意以“123”只粘貼值的方式粘貼

- 然后把excel中的內容粘貼回書簽的xml中
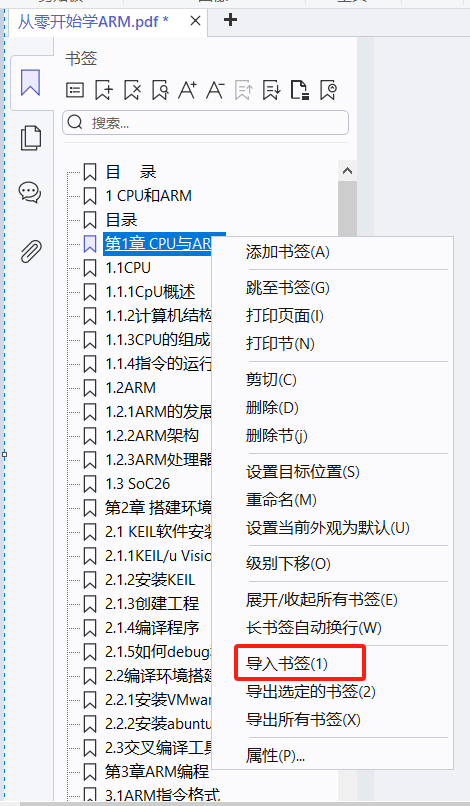
- 打開書的書簽,“導入書簽”
- 分級的話,自己動手分級也挺方便
文字不可復制
用圖片轉文字功能,將文字提取出來,得到想要的格式。有一下幾種途徑:
- deepseek圖片轉文字(缺點:沒頁碼,要自己加)
- https://ocr.wdku.net/,有點兒慢,但是可以在線使用
- 豆包等AI工具(缺點:要登錄)


)

(下))







安全狗)

)
隊列實踐請看下一篇)



