作者:IvanCodes
日期:2025年7月25日
專欄:Spark教程
Apache Spark 作為統一的大數據分析引擎,以其高性能和靈活性著稱。要充分利用Spark的強大能力,首先需要根據不同的應用場景和資源環境,正確地部署其運行環境。本教程將詳細指導您如何下載 Spark,并逐步解析和部署其四種核心運行模式。
一、下載 Apache Spark
在進行任何部署之前,我們首先需要獲取 Spark 的安裝包。
- 訪問 Spark 官方網站
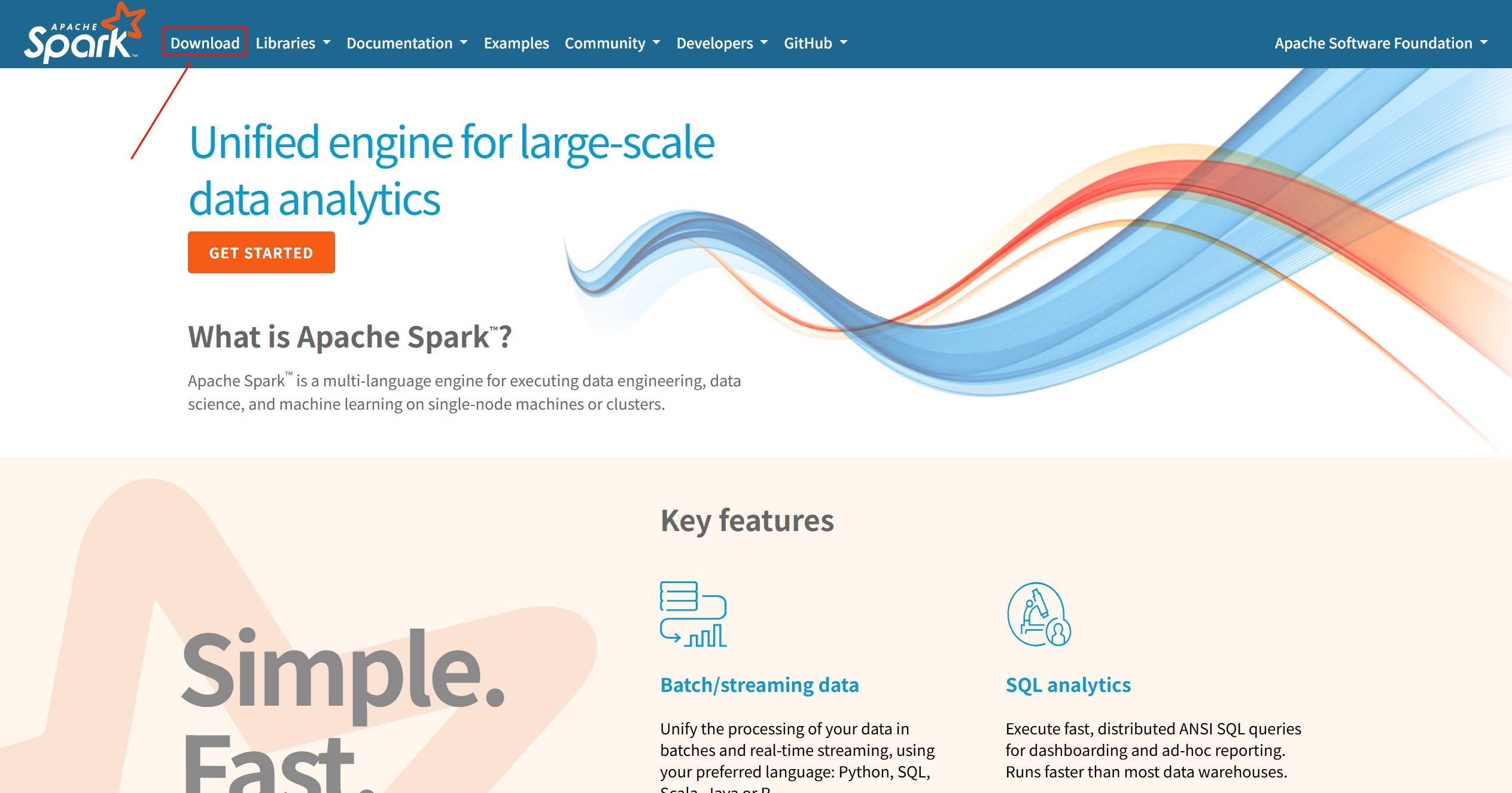
- 打開您的瀏覽器,訪問 Apache Spark 官方網站:
https://spark.apache.org/ - 在網站的導航欄中,您會看到一個醒目的 “Download” 鏈接。
- 打開您的瀏覽器,訪問 Apache Spark 官方網站:
- 在下載頁面選擇版本和包類型
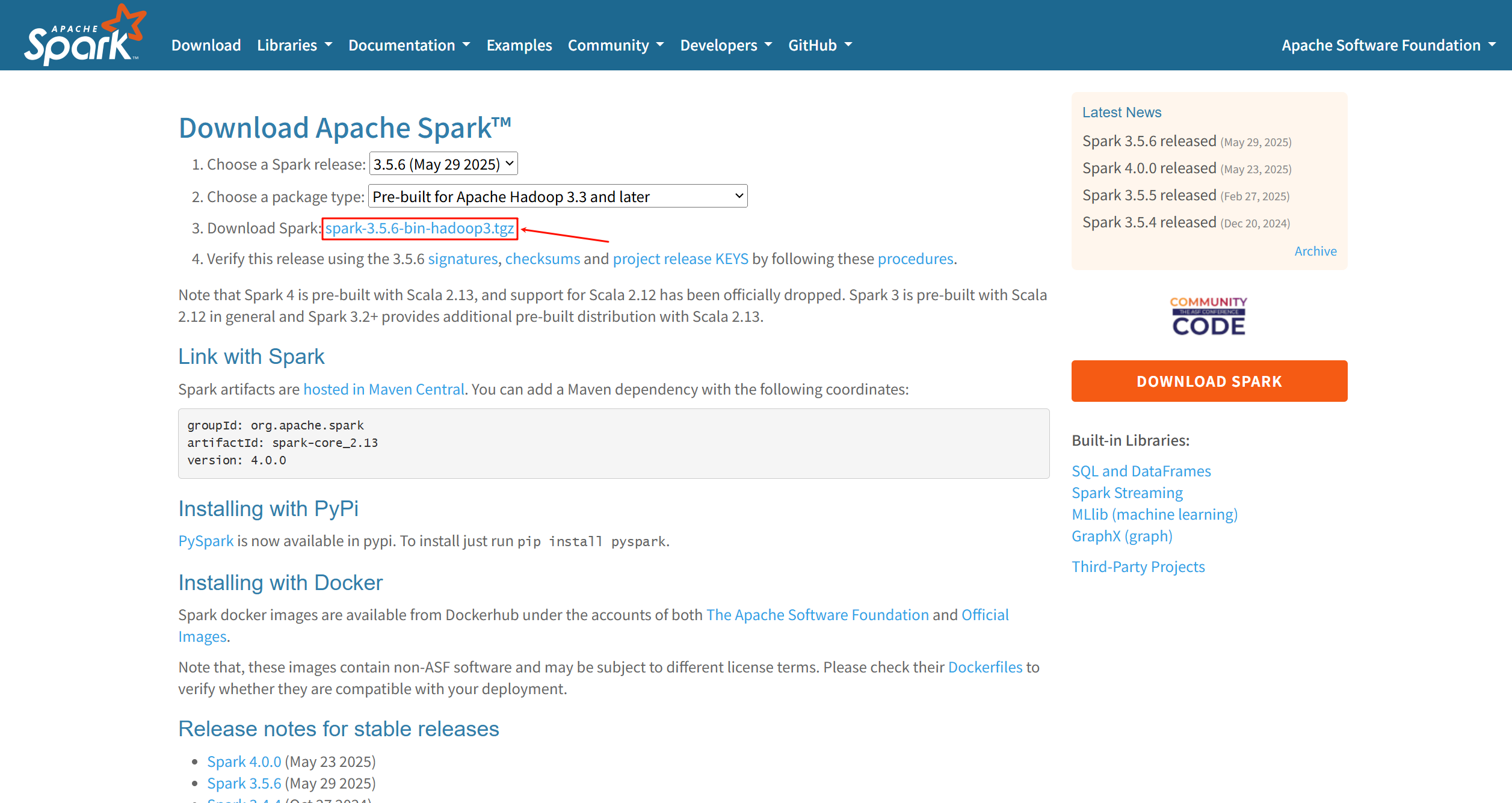
- 點擊 “Download” 鏈接后,您將進入下載配置頁面。
- 步驟 1 (Choose a Spark release): 選擇您需要的 Spark 版本。根據您的截圖,我們選擇 3.5.6 (請以官網實際為準)。
- 步驟 2 (Choose a package type): 選擇包類型。對于大多數情況,特別是與Hadoop集成的環境,選擇預編譯好的版本是最方便的。例如,選擇
Pre-built for Apache Hadoop 3.3 and later。 - 步驟 3 (Download Spark): 點擊生成的下載鏈接。
- 從鏡像站點下載二進制包
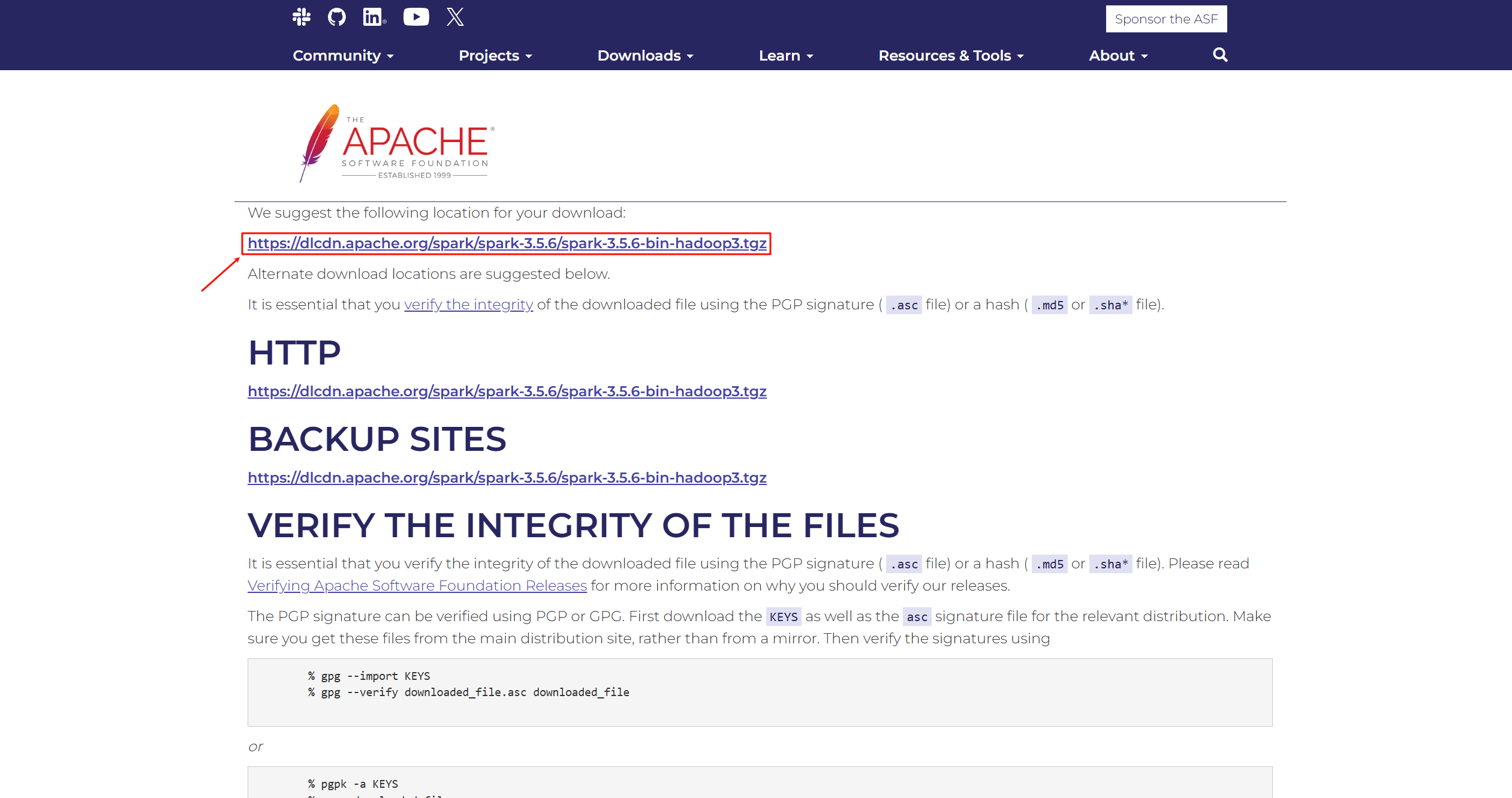
- 點擊上一步的鏈接后,您會被引導至一個包含多個下載鏡像的頁面。
- 選擇頁面頂部建議的主下載鏈接進行下載。
- 將下載好的二進制包 (例如
spark-3.5.6-bin-hadoop3.tgz) 上傳到您的操作服務器 (例如hadoop01) 的/export/software目錄下。
- 解壓安裝包 (在 hadoop01 操作)
- 目標安裝路徑為
/export/server,并重命名為spark。
- 目標安裝路徑為
mkdir -p /export/server
cd /export/softwares
tar -zxvf spark-3.5.6-bin-hadoop3.tgz -C /export/server/
cd /export/server
mv spark-3.5.6-bin-hadoop3 spark
二、Spark 四種核心運行模式詳解與部署
2.1 Local 模式 (本地模式)
特點與用途:
所謂的 Local 模式,就是不需要任何集群節點資源,僅在單臺機器上就能執行 Spark 代碼的環境。它非常適合用于教學、快速原型開發、調試和單元測試。在此模式下,所有Spark組件 (Driver, Executor) 都在同一個JVM進程中以多線程的方式運行。
部署與運行步驟:
- 啟動 Local 環境 (Spark Shell)
- 進入解壓并重命名后的 Spark 目錄,執行
spark-shell啟動一個交互式的Scala環境。
- 進入解壓并重命名后的 Spark 目錄,執行
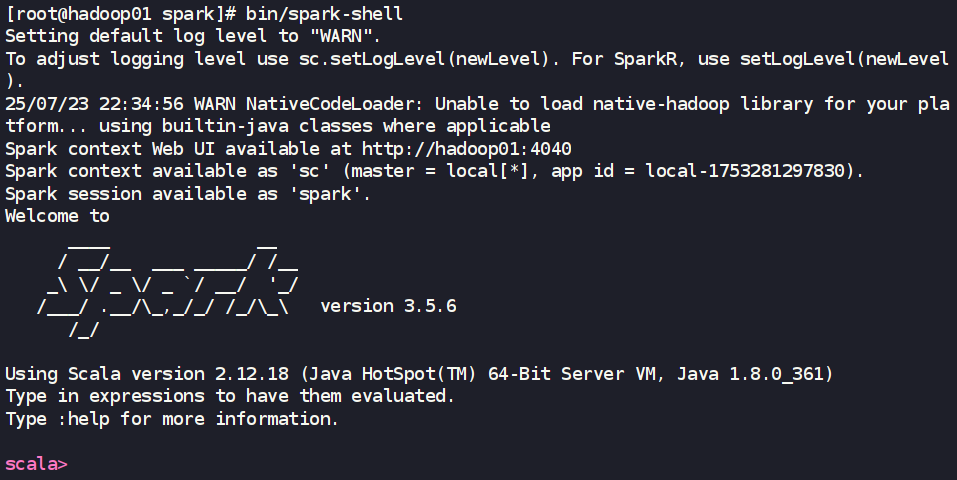
cd /export/server/spark
bin/spark-shell
- 啟動成功后,您會看到 Spark 的歡迎信息,并進入 Scala 提示符
scala>。
- 訪問 Web UI 監控頁面
- 當
spark-shell或任何Spark應用在 Local 模式下運行時,它會啟動一個內嵌的 Web UI 用于監控任務執行情況。 - 默認端口是
4040。在瀏覽器中訪問:http://hadoop01:4040(請將hadoop01替換為您的實際主機名或IP)。
- 當

- 在命令行工具中執行代碼
- 在
spark-shell中,可以直接執行 Spark 代碼。例如,我們可以對一個文本文件進行詞頻統計。首先,在data目錄下創建一個word.txt文件。
- 在
cd /export/server/spark
mkdir Data
echo "hello spark hello world" > Data/wordcount.txt
- 然后在已啟動的
spark-shell中執行:
sc.textFile("data/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect

-
退出 Local 模式
- 在
spark-shell中,按Ctrl+C組合鍵,或輸入Scala命令:quit。
- 在
-
通過
spark-submit提交應用- 除了交互式運行,也可以提交打包好的應用程序。
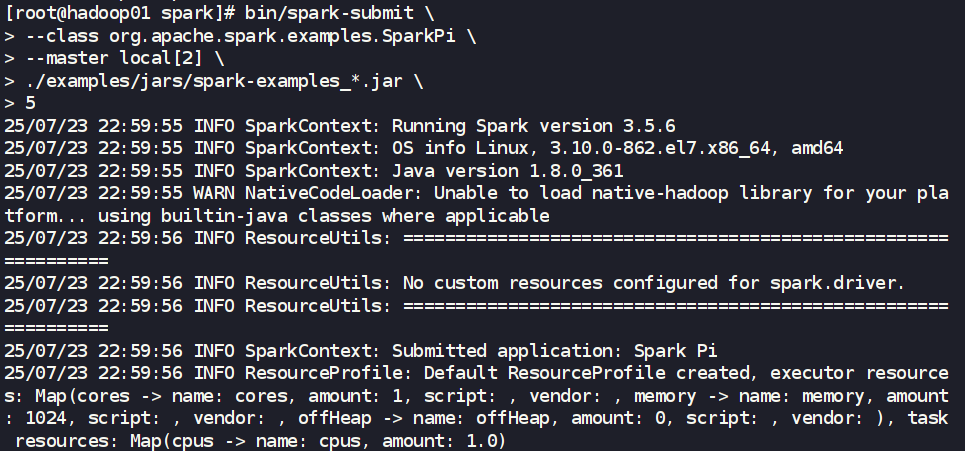
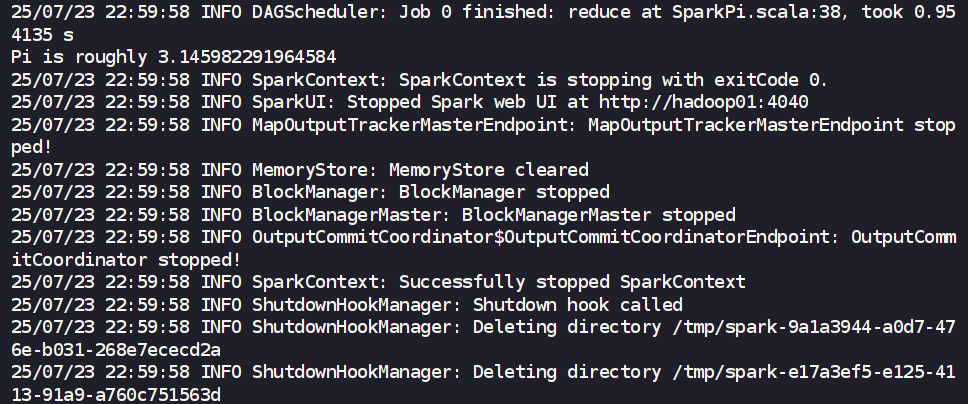
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_*.jar \
5
- 參數解析:
--class: 指定要執行的主類。--master local[2]: 明確指定使用Local模式,并分配2個CPU核心。local[*]表示使用所有可用核心。./examples/jars/spark-examples_*.jar: 應用程序所在的JAR包。5: 傳遞給應用程序主函數的參數。
2.2 Standalone 模式 (獨立部署模式)
特點與用途:
Standalone 模式是 Spark 自帶的、完整的集群資源管理框架,采用經典的 Master-Slave 架構。它獨立于其他資源管理器 (如YARN),部署簡單,非常適合搭建專門用于運行 Spark 應用的中小型集群。
部署步驟:
- 集群規劃:
hadoop01: Master, Workerhadoop02: Workerhadoop03: Worker
(為了充分利用資源,Master節點通常也兼作一個Worker節點)
- 修改配置文件 (在 Master 節點
hadoop01上操作)- 配置 Worker 節點列表 (
workers或slaves):
- 配置 Worker 節點列表 (
cd /export/server/spark/conf
cp workers.template workers
vim workers
編輯 workers 文件,清除原有內容,并添加所有Worker節點的主機名,每行一個:
hadoop01
hadoop02
hadoop03
- 配置環境變量 (
spark-env.sh):
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
在文件末尾添加以下內容:
export JAVA_HOME=/export/server/jdk1.8.0_361
export SPARK_MASTER_HOST=hadoop01
JAVA_HOME: 指定JDK的安裝路徑。SPARK_MASTER_HOST: 明確告知集群Master節點的主機名或IP地址。
- 分發 Spark 目錄
- 將
hadoop01上配置好的/export/server/spark目錄完整同步到所有Worker節點。
- 將
cd /export/server
scp -r spark/ root@hadoop02:/export/server/
scp -r spark/ root@hadoop03:/export/server/
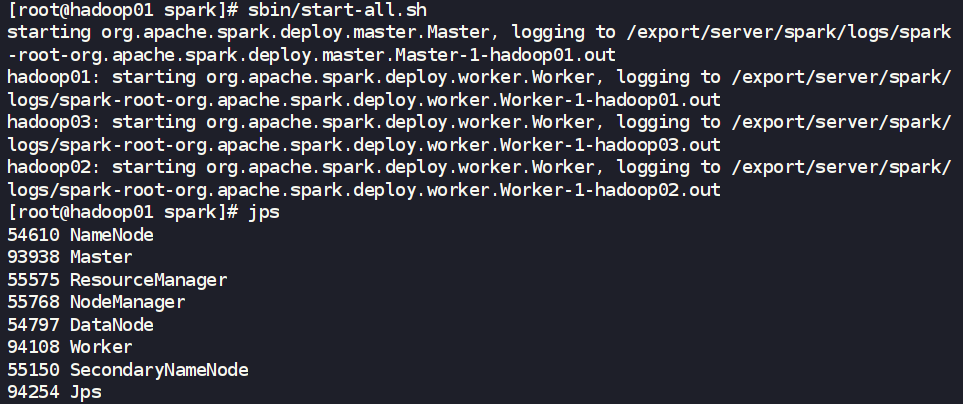
- 啟動 Standalone 集群
- 在 Master 節點 (
hadoop01) 上執行一鍵啟動腳本。
- 在 Master 節點 (
cd /export/server/spark
sbin/start-all.sh
- 此腳本會啟動
hadoop01上的 Master 進程,并根據workers文件的內容,通過SSH遠程啟動所有Worker節點上的 Worker 進程。
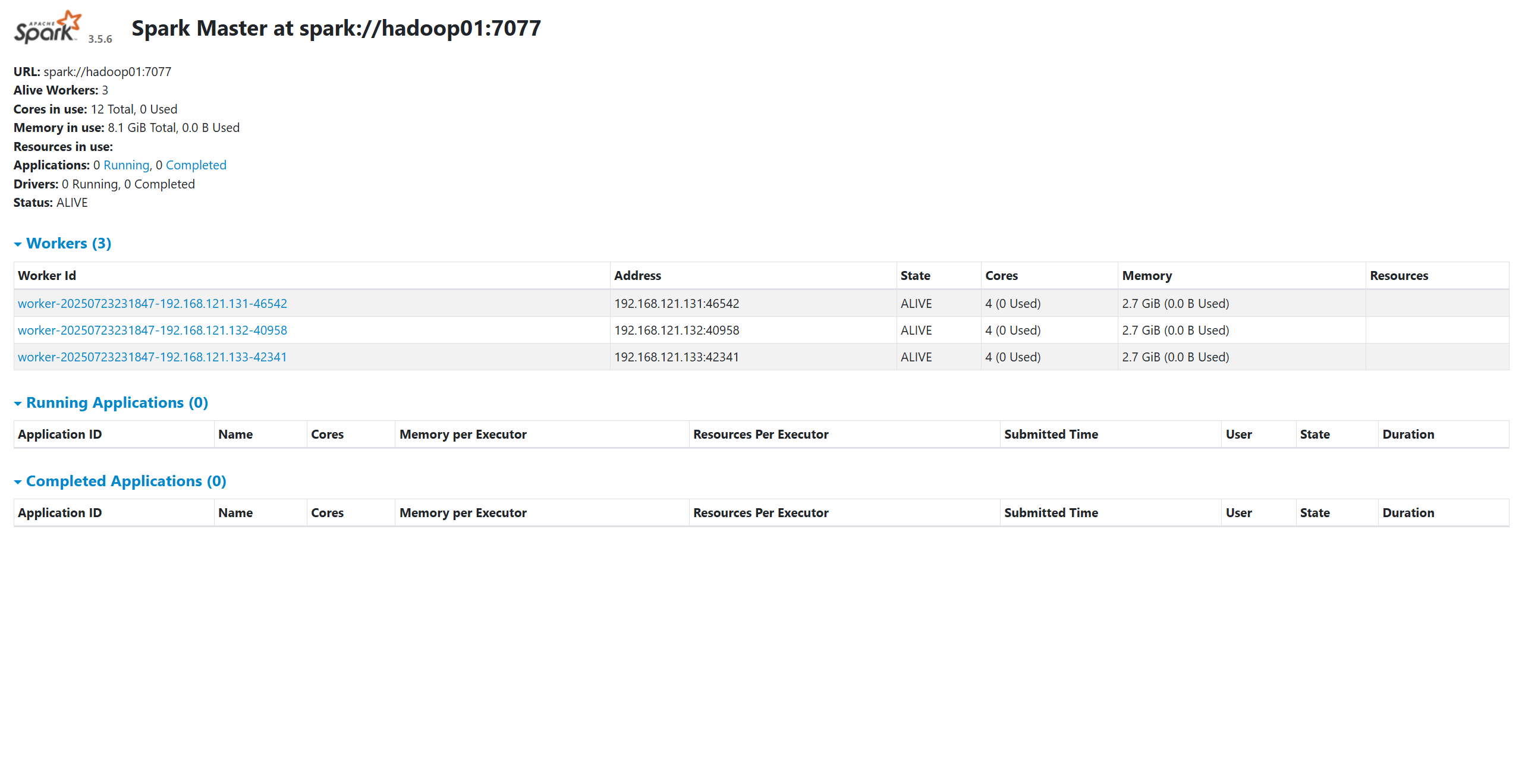
- 驗證集群狀態
- 在所有節點上執行
jps命令。hadoop01應有Master和Worker進程,hadoop02和hadoop03應有Worker進程。 - 訪問 Master Web UI: 在瀏覽器中打開
http://hadoop01:8080(默認端口)。
- 在所有節點上執行
- 提交應用到 Standalone 集群
cd /export/server/spark
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop01:7077 \
./examples/jars/spark-examples_*.jar \
10
--master spark://hadoop01:7077: 指定連接到 Standalone Master 的地址。7077是Master接收客戶端連接的默認端口。

Standalone 模式高級配置:
- 配置歷史服務 (History Server)
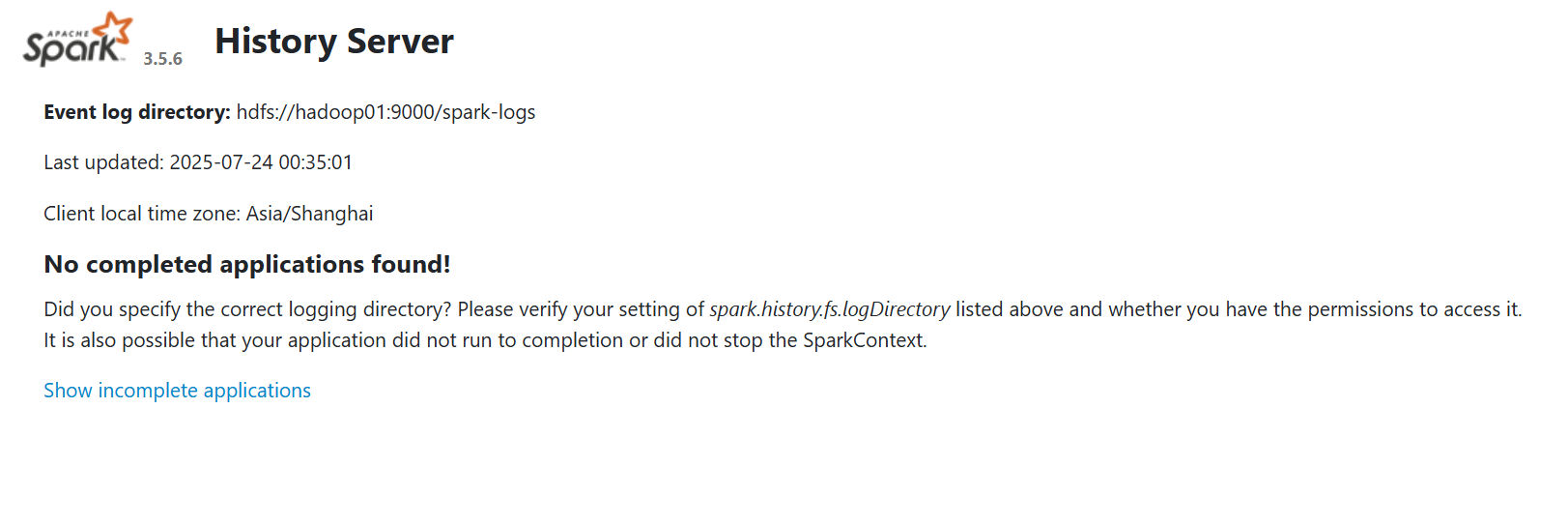
- 問題: Spark 應用運行結束后,其在
4040端口的UI會隨之關閉,無法查看歷史任務的執行詳情。 - 解決方案: 配置歷史服務器,將應用運行日志持久化到HDFS,并通過一個常駐服務來展示這些歷史記錄。
- 步驟:
- 啟動 HDFS。
- 創建 HDFS 日志目錄:
hadoop fs -mkdir /spark-logs - 修改
spark-defaults.conf(在conf目錄下創建):
- 問題: Spark 應用運行結束后,其在
cp spark-defaults.conf.template spark-defaults.conf
hdfs dfs -mkdir /spark-logs
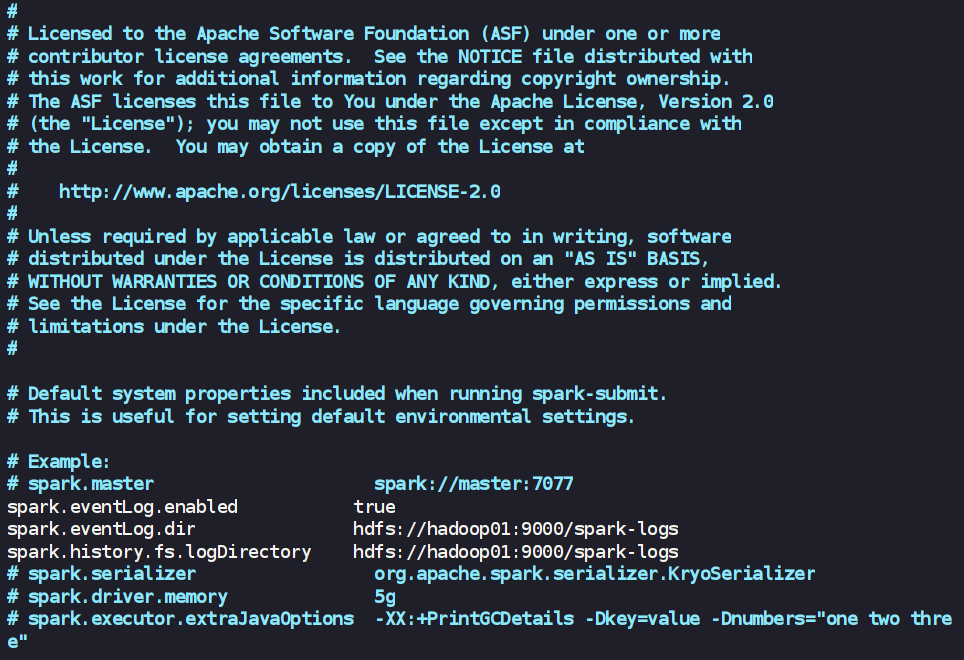
vim spark-defaults.conf
添加:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop01:9000/spark-logs
spark.history.fs.logDirectory hdfs://hadoop01:9000/spark-logs
- 修改
spark-env.sh:
添加:
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://hadoop01:9000/spark-logs -Dspark.history.retainedApplications=50"
- 分發配置文件到所有節點。
cd /export/server/spark/
scp -r conf/ root@hadoop02:/export/server/spark/conf/
scp -r conf/ root@hadoop03:/export/server/spark/conf/
- 啟動歷史服務 (在
hadoop01上):
sbin/start-history-server.sh

- 訪問歷史服務 Web UI:
http://hadoop01:18080
高可用部署步驟:
- 集群規劃:
hadoop01: Spark Master (主), ZooKeeper Server, Worker
hadoop02: Spark Master (備), ZooKeeper Server, Worker
hadoop03: ZooKeeper Server, Worker
1. 確保 ZooKeeper 集群正常運行
在進行 Spark HA 配置前,您必須擁有一個正在穩定運行的 ZooKeeper 集群。請確保在 hadoop01, hadoop02, hadoop03 上的 ZooKeeper 服務已經啟動(如果還沒有配置,可以查看往期文章《二、ZooKeeper 集群部署搭建》)
- 可以通過在每個節點執行
zkServer.sh status來驗證 ZooKeeper 集群的狀態。
2. 停止現有的 Standalone 集群
- 如果在進行此配置前,您已經啟動了普通的 Standalone 集群,請務必先停止它。
cd /export/server/spark
sbin/stop-all.sh
3. 修改 spark-env.sh 配置文件 (在所有Spark節點)
- 這是配置 HA 的核心步驟。我們需要修改所有 Spark 節點 (
hadoop01,hadoop02,hadoop03) 上的/export/server/spark/conf/spark-env.sh文件。 - 首先,注釋掉或刪除 之前為普通 Standalone 模式配置的
SPARK_MASTER_HOST和SPARK_MASTER_PORT(如果存在)。
# SPARK_MASTER_HOST=hadoop01
# SPARK_MASTER_PORT=7077
- 然后,添加以下 用于啟用 ZooKeeper 恢復模式的配置:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop01:2181,hadoop02:2181,hadoop03:2181 -Dspark.deploy.zookeeper.dir=/spark"
4. 分發配置文件
- 將在
hadoop01上修改好的spark-env.sh同步到hadoop02和hadoop03,確保所有節點的配置完全一致。
cd /export/server/spark/conf
scp spark-env.sh root@hadoop02:/export/server/spark/conf/
scp spark-env.sh root@hadoop03:/export/server/spark/conf/
5. 啟動 HA 集群
- 與普通 Standalone 不同,HA 模式下我們不能簡單地使用
start-all.sh來啟動所有 Master。我們需要手動在規劃為 Master 的每個節點上分別啟動 Master 進程。 - 在
hadoop01上啟動第一個 Master:
zkServer.sh start
cd /export/server/spark
sbin/start-master.sh
- 在
hadoop02上啟動第二個 Master:
# 首先登錄到 hadoop02
ssh hadoop02
zkServer.sh start
cd /export/server/spark
sbin/start-master.sh
- 啟動后,這兩個 Master 會通過 ZooKeeper 進行Leader選舉,其中一個會成為 Active,另一個則成為 Standby。
- 最后,在任意一個 Master 節點 (例如
hadoop01) 上啟動所有 Worker 節點:
# 確保 workers 文件中包含了所有 Worker 節點 (hadoop01, hadoop02, hadoop03)
cd /export/server/spark
sbin/start-workers.sh # 或者 sbin/start-all.sh 也可以,它會智能地只啟動workers
6. 驗證 HA 集群狀態
- 查看進程:在
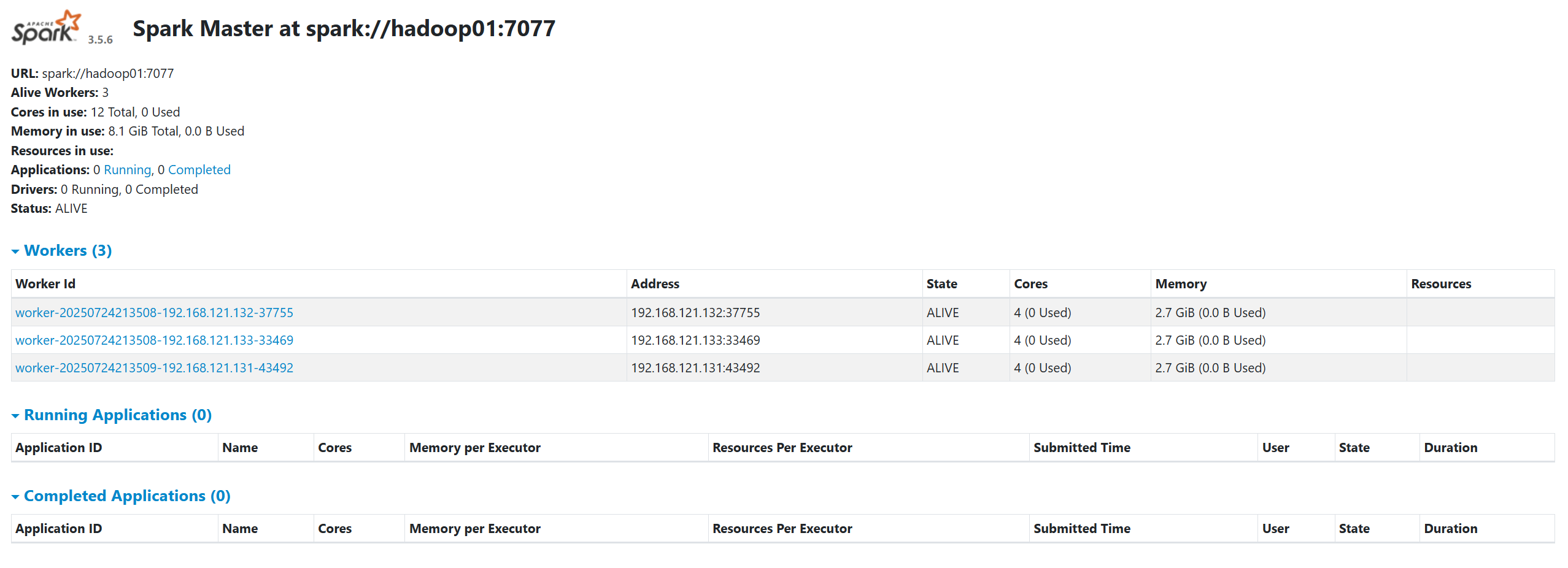
hadoop01和hadoop02上執行jps,都應該看到Master進程。在所有三個節點上都應該看到Worker進程。 - 訪問 Web UI:
- 分別訪問兩個 Master 的 Web UI:
http://hadoop01:8081和http://hadoop02:8081。 - 你會發現其中一個頁面的狀態 (Status) 顯示為
ALIVE,這是 Active Master。 - 另一個頁面的狀態顯示為
STANDBY,這是 Standby Master。 - 兩個頁面上都應該能看到所有活躍的 Worker 節點。
- 分別訪問兩個 Master 的 Web UI:
7. 提交應用到 HA 集群
- 提交應用時,
--master參數需要指定所有 Master 節點的地址,用逗號分隔。
cd /export/server/spark
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop01:7077,hadoop02:7077 \
./examples/jars/spark-examples_*.jar \
5
- 客戶端會首先嘗試連接列表中的第一個 Master (
hadoop01:7077)。如果它不是 Active Master,客戶端會被重定向到當前真正的 Active Master。如果第一個 Master 掛了,客戶端會自動嘗試連接列表中的下一個 Master (hadoop02:7077)。
2.3 YARN 模式 (推薦)
特點與用途:
YARN 模式是將 Spark 作為一個應用程序運行在現有的 Hadoop YARN 集群之上。YARN 負責統一的資源分配和調度。這是生產環境中最主流、最健壯的部署模式,因為它實現了與Hadoop生態中其他計算框架 (如MapReduce) 的資源共享、統一權限管理和高可用性。
部署與配置步驟:
第一步:配置 YARN 核心文件
這是最關鍵的一步。我們需要一次性完成對 YARN 的資源定義和基礎服務配置。
在 hadoop01 上,編輯 yarn-site.xml 文件:
vim /export/server/hadoop/etc/hadoop/yarn-site.xml
在 <configuration> 和 </configuration> 標簽之間,確保包含以下所有屬性:
<!-- 定義每個NodeManager節點可用于分配給容器的總物理內存 (單位MB) -->
<!-- 這個值應該根據你機器的實際物理內存來設置,通常是物理內存的70%-80% -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value> <!-- 示例值: 8GB -->
</property><!-- 定義每個NodeManager節點可用于分配給容器的總虛擬CPU核心數 -->
<!-- 通常設置為機器的CPU核心數或超線程數 -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>8</value> <!-- 示例值: 8核 -->
</property><!-- 啟用YARN的輔助服務 (aux-service) 功能,為Spark Shuffle Service做準備 -->
<!-- 保留 mapreduce_shuffle 以兼容MapReduce作業 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property><!-- (推薦) 關閉YARN對物理內存和虛擬內存的嚴格檢查 -->
<!-- Spark有自己的內存管理機制,YARN的嚴格檢查可能誤殺正常運行的Spark Executor -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
第二步:為 YARN “植入” Spark 依賴
這是我們解決 ClassNotFoundException 的最終方案,遠比修改環境變量更可靠。
- 在
hadoop01上,找到 Spark for YARN 的核心 Jar 包:
ls /export/server/spark/jars/spark-yarn_*.jar
- 將這個 Jar 包物理復制到所有節點的 YARN 核心庫目錄中:
# (請將下面的文件名替換為您上一步找到的真實文件名, 如 spark-yarn_2.12-3.5.6.jar)
# 復制到 hadoop01
cp /export/server/spark/jars/spark-yarn_*.jar /export/server/hadoop/share/hadoop/yarn/lib/# 復制到 hadoop02
scp /export/server/spark/jars/spark-yarn_*.jar root@hadoop02:/export/server/hadoop/share/hadoop/yarn/lib/# 復制到 hadoop03
scp /export/server/spark/jars/spark-yarn_*.jar root@hadoop03:/export/server/hadoop/share/hadoop/yarn/lib/
為什么這么做?
將 spark-yarn Jar 包直接放入 YARN 的 classpath 中,可以確保 YARN NodeManager 在啟動 Spark 的 Shuffle Service 或其他 Spark 組件時,總能找到所需的類,從根本上解決類加載問題。
第三步:配置 Spark 客戶端
現在輪到 Spark 了,我們只需要告訴它 Hadoop 的配置文件在哪里。
在 hadoop01 上,編輯 spark-env.sh 文件:
vim /export/server/spark/conf/spark-env.sh
在文件末尾添加 (如果不存在的話):
export HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
第四步:分發配置并重啟 YARN
- 精確分發
yarn-site.xml:
scp /export/server/hadoop/etc/hadoop/yarn-site.xml root@hadoop02:/export/server/hadoop/etc/hadoop/
scp /export/server/hadoop/etc/hadoop/yarn-site.xml root@hadoop03:/export/server/hadoop/etc/hadoop/
- 重啟 YARN 服務:
cd /export/server/hadoop/sbin/
./stop-yarn.sh
./start-yarn.sh
第五步:驗證與排錯指南 (核心)
- 驗證所有進程:
jps
ssh hadoop02 "jps"
ssh hadoop03 "jps"
確保 ResourceManager 在主節點上運行,并且所有節點上都有 NodeManager 進程。
- 排錯指南:如果 NodeManager 沒有啟動
- 立即登錄 到啟動失敗的那個節點 (例如
ssh hadoop02)。 - 立刻查看 該節點的 NodeManager 日志文件,查找 ERROR 信息。這是定位問題的唯一途徑。
- 立即登錄 到啟動失敗的那個節點 (例如
# (請根據ls的真實文件名調整)
tail -n 200 /export/server/hadoop/logs/yarn-root-nodemanager-hadoop02.log
- 常見錯誤包括:
yarn-site.xml配置語法錯誤、spark_shuffle服務類找不到 (說明第二步Jar包沒放對位置或沒分發)、端口沖突等。
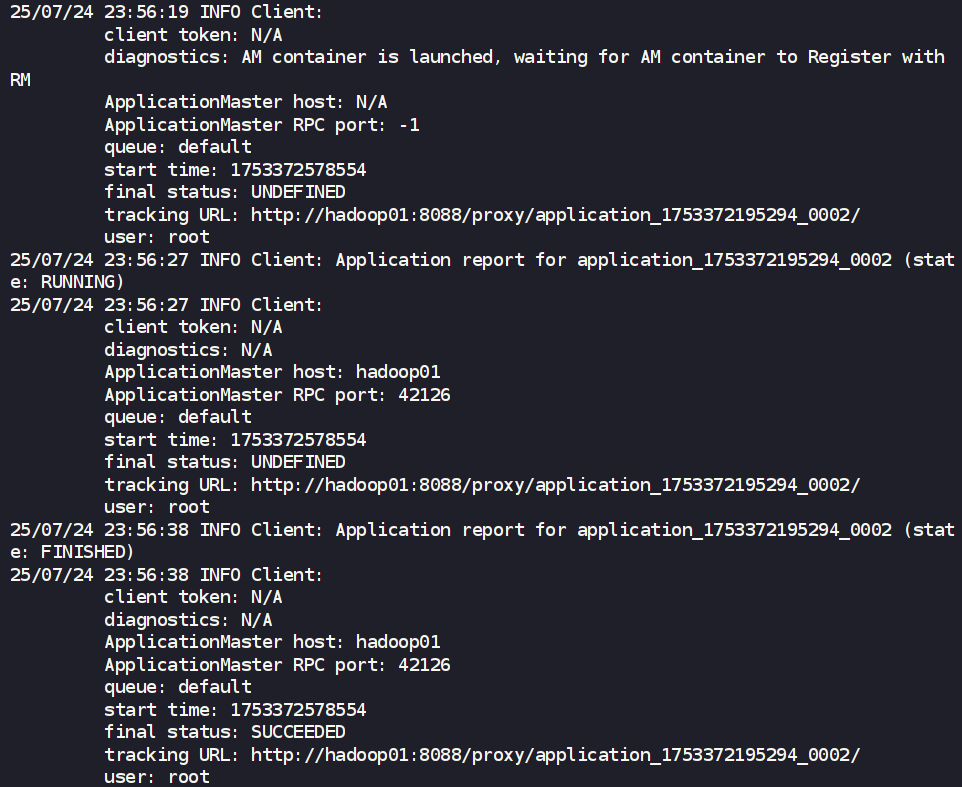
第六步:提交應用到 YARN
(這部分與之前版本相同,僅作展示)
- YARN-Client 模式 (
--deploy-mode client)
cd /export/server/spark
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_*.jar \
5
- YARN-Cluster 模式 (
--deploy-mode cluster)
cd /export/server/spark
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_*.jar \
5
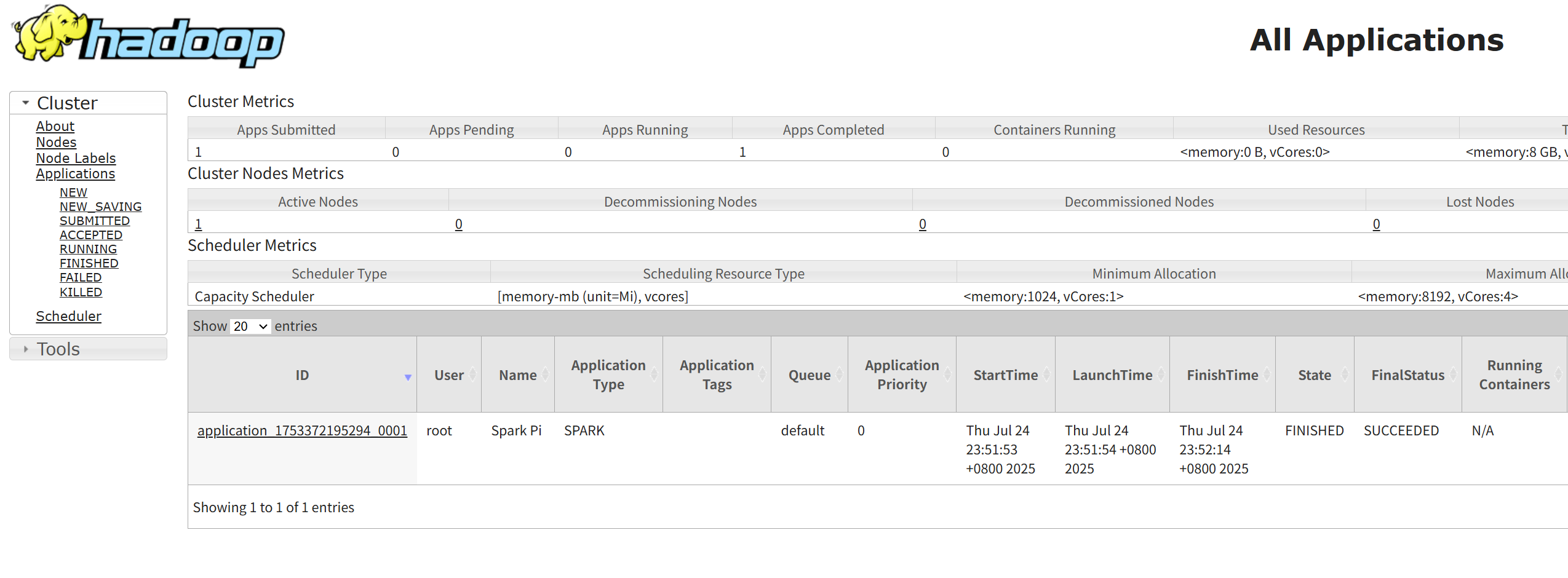
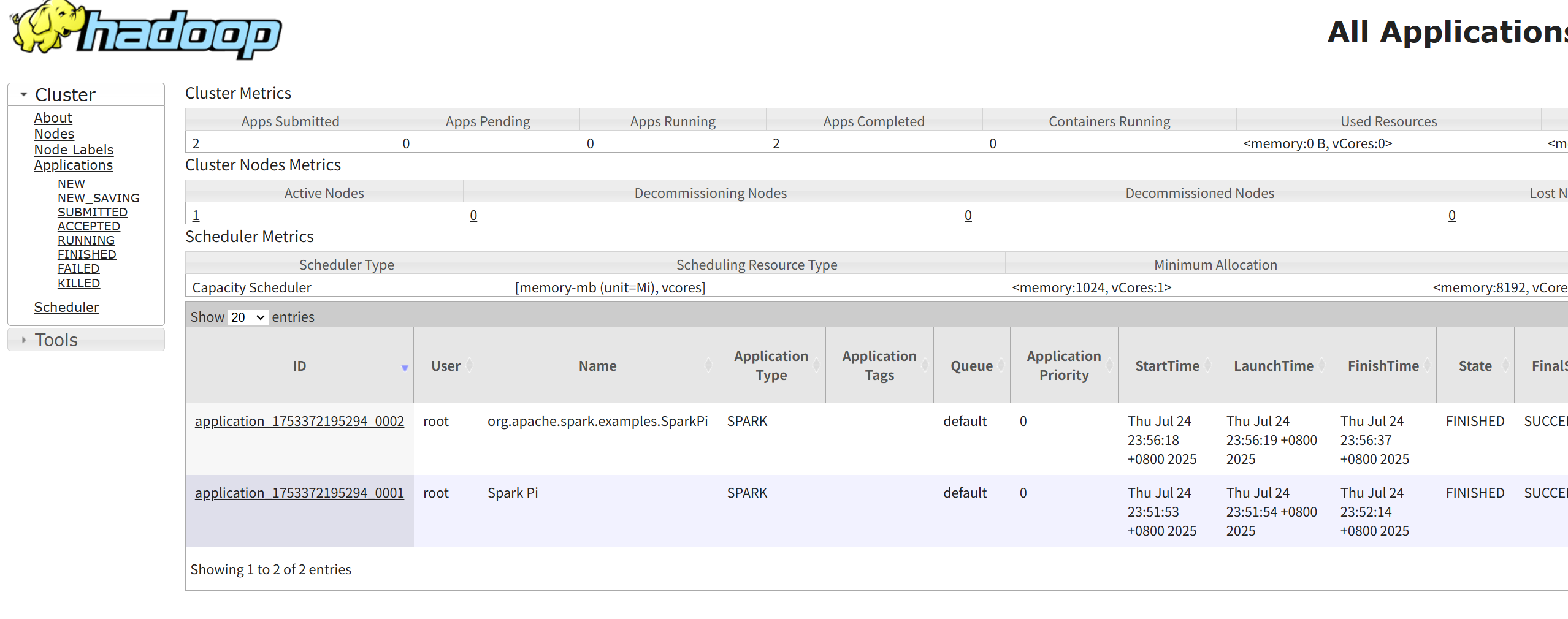
監控與驗證:
提交應用后,訪問 YARN ResourceManager 的 Web UI: http://hadoop01:8088。
2.4 Windows 模式 (本地開發)
特點與用途:
這本質上就是在Windows操作系統上運行Spark的Local模式。它的初衷是方便開發者在不啟動虛擬機的情況下,進行本地開發和功能測試。然而,這條看似便捷的道路,實際上充滿了挑戰,極易遇到各種匪夷所思的環境兼容性問題。
純 PowerShell 配置
網上的許多教程會指導您通過圖形界面 (GUI) 點擊“我的電腦”->“屬性”->“高級系統設置”來手動添加環境變量。這種方法不僅繁瑣,而且極易出錯 (比如,在Path變量中漏掉分號,或者路徑復制錯誤)。
本教程將完全摒棄這種原始方式,采用純 PowerShell 代碼來完成所有環境配置。
部署步驟:
第一步:準備一個純凈的Java 環境
Java 是 Spark 的生命之基,它的配置正確與否,決定了我們能否打贏這場戰爭。
- 安裝 Java (JDK):
- Spark 3.5.x 與 Java 8, 11, 17 兼容。為避免任何兼容性問題,推薦使用命令行安裝一個純凈的、久經考驗的 Eclipse Temurin 8 (LTS) 版本。
- 以管理員身份打開 PowerShell,執行:
winget install -e --id EclipseAdoptium.Temurin.8.JDK
- 配置環境變量 (純 PowerShell 方式):
- 安裝后,必須 關閉并重新打開一個新的管理員 PowerShell 窗口,以加載系統路徑。
- 在新窗口中,執行以下命令,完成
JAVA_HOME和Path的配置(請根據您機器上實際的安裝路徑和版本號進行修改):
# 設置 JAVA_HOME (請 double check 這個路徑是否存在)
# 'Machine' 表示這是一個系統級別的環境變量,對所有用戶生效
[System.Environment]::SetEnvironmentVariable('JAVA_HOME', 'C:\Program Files\Eclipse Adoptium\jdk-8.0.422.8-hotspot', 'Machine')# 將 JAVA_HOME\bin 添加到系統 Path
$javaBinPath = [System.Environment]::GetEnvironmentVariable('JAVA_HOME', 'Machine') + '\bin'
$oldPath = [System.Environment]::GetEnvironmentVariable('Path', 'Machine')
[System.Environment]::SetEnvironmentVariable('Path', "$oldPath;$javaBinPath", 'Machine')
- 最終驗證: 再次關閉并重新打開一個普通的 PowerShell 窗口,執行
java -version。如果成功顯示版本,說明地基已打好。
第二步:部署 Spark 與 Hadoop“輔助工具”
本方法的詳細步驟,請參考《二、Spark 開發環境搭建 IDEA + Maven 及 WordCount 案例實戰》里面的第三部分
-
解壓 Spark:
- 將 Spark 二進制包 (例如
spark-3.5.6-bin-hadoop3.tgz) 解壓到一個絕對不能包含中文、空格或特殊字符的純英文路徑,例如E:\spark。
- 將 Spark 二進制包 (例如
-
配置
winutils.exe(決戰的開始):- Spark 依賴 Hadoop 的代碼,而 Hadoop 在 Windows 上需要
winutils.exe和hadoop.dll這兩個“翻譯官”來模擬 Linux 的文件權限和操作。 - 在 這個 GitHub 倉庫 (例如
cdarlint/winutils) 中,找到與您的 Spark 預編譯時所用的 Hadoop 版本相匹配的winutils.exe和hadoop.dll。例如,spark-3.5.6-bin-hadoop3意味著您需要 Hadoop 3.x 的版本。 - 創建一個目錄,例如
E:\hadoop\bin。 - 將下載的
winutils.exe和hadoop.dll放入E:\hadoop\bin目錄下。
- Spark 依賴 Hadoop 的代碼,而 Hadoop 在 Windows 上需要
-
配置
HADOOP_HOME環境變量 (純 PowerShell 方式):- 打開一個新的管理員 PowerShell 窗口。
第三步:迎接最終的考驗 —— 啟動 Spark
-
重啟 PowerShell:
- 為了加載剛剛設置的
HADOOP_HOME,請再次打開一個全新的 PowerShell 窗口。
- 為了加載剛剛設置的
-
進入
bin目錄:
cd E:\spark\bin
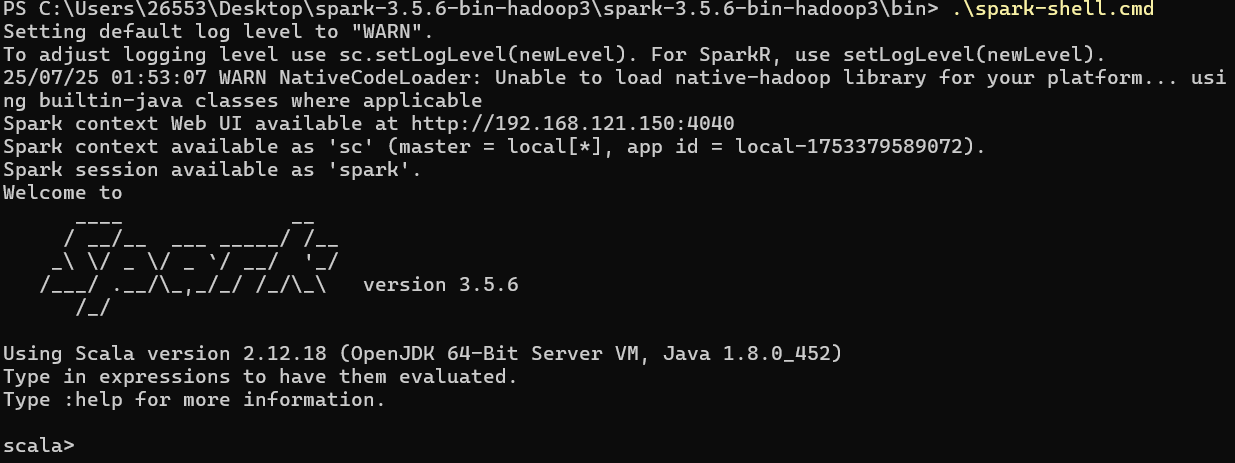
- 執行啟動命令:
.\spark-shell.cmd
- 必須使用
.\,這是 PowerShell 的安全規則,表示執行當前目錄下的腳本。
此時,您將直面命運的審判。如果一切順利 (Java配置無誤,winutils.exe版本匹配且路徑正確),Spark Shell 將成功啟動,不會出現 NullPointerException, FileNotFoundException 或找不到 winutils 的紅色錯誤信息。
如果失敗了怎么辦?
- 仔細閱讀錯誤信息,99% 的問題都與
JAVA_HOME路徑錯誤、HADOOP_HOME未設置或winutils.exe版本不匹配有關。 - 回到前面的步驟,逐一檢查每個路徑和環境變量是否完全正確。
- 最終,考慮“鄭重警告”中的建議。
總結
- Local: 學習、開發、測試的最佳選擇,簡單快捷。
- Standalone: 快速搭建專用的Spark集群,獨立性強。
- YARN: 與Hadoop生態深度集成,是企業級生產環境的標準部署模式。
- Windows: 方便Windows用戶進行本地開發,核心是正確配置
winutils。



)

IOU)










)


