目錄
1、基礎:它到底是個啥?
1. 1、一句話理解核心
1.2、 為啥厲害?
1.3、怎么發展來的?
2、架構:它的 “身體構造” 是啥樣的?
2.1、視覺語言模型架構:讓 AI “看懂” 世界的核心系統
2.1.1、雙塔模型(如 CLIP)? ?
2.1.2、交叉注意力模型(如 BLIP-2) ?
2.1.3、端到端模型(如 Flamingo)
2.1.4、輕量級模型(如 Fuyu-8B)
2.2、語音語言模型架構:讓 AI “聽懂” 聲音的核心系統
2.2.1、語音特征提取(MFCC)
2.2.2、序列對齊(CTC 損失)
2.2.3、端到端模型(如 Whisper)
2.3、多模態大語言模型架構:讓 AI “感知” 世界的超級系統
2.3.1、模態編碼器
2.3.2、連接器(Connector)
2.3.3、大型語言模型(LLM)
3、多模態架構的核心公式與訓練流程
3.1、跨模態對齊公式
3.2、訓練流程
3.3、訓練:怎么讓它變聰明的?
4、架構對比與選擇指南
5、應用:它能幫我們做啥?
6、多模態LLM模型(圖像-文本生成)(簡化版)
7、多模態LLM模型(圖像-文本生成+問答系統)(簡化版)
1、基礎:它到底是個啥?
1. 1、一句話理解核心
普通大模型(比如 ChatGPT)只能處理文字,而多模態大語言模型(簡稱 “多模態 LLM”)能同時 “看懂圖、聽懂聲、讀得懂字”,還能用文字回答你所有問題。比如你給它一張電路圖,它能直接告訴你 “這里接反了會短路”;給它一段機器運轉的聲音,它能說 “軸承快壞了,得換”。
1.2、 為啥厲害?
以前的 AI 是 “偏科生”:有的只能看圖(比如識別圖片里的貓),有的只能處理文字(比如寫作文),但多模態 LLM 是 “全能選手”—— 它用語言把所有信息打通了。就像人既會看路標(圖像),又會讀路牌(文字),還能跟人打聽路(語言),最后找到目的地,而不是只認其中一種。
1.3、怎么發展來的?
- 先有 “文字學霸”:比如 GPT-3、Llama,只會處理文字,邏輯推理超強但 “看不見東西”。
- 再加上 “圖像 / 聲音翻譯官”:比如 CLIP 能把圖片轉成文字能懂的 “密碼”,讓文字學霸能 “間接看圖”。
- 最后合體:把 “翻譯官” 和 “文字學霸” 綁在一起,就成了多模態 LLM,比如 GPT-4V、Llava 這些。
2、架構:它的 “身體構造” 是啥樣的?
2.1、視覺語言模型架構:讓 AI “看懂” 世界的核心系統
視覺語言模型(如 CLIP、BLIP-2)的核心是將圖像和文字映射到同一語義空間,實現跨模態理解。其架構通常包含三個模塊:
2.1.1、雙塔模型(如 CLIP)? ?
- 架構原理: 獨立的圖像編碼器(如 ResNet)和文本編碼器(如 Transformer)分別處理圖片和文字,通過對比學習將兩者特征投影到同一向量空間。
-
關鍵公式:對比損失函數
-
其中,
為余弦相似度,
是溫度參數,控制相似度分布的平滑程度。
-
- 訓練步驟:
- 輸入圖片和對應文本,分別編碼為特征向量
和
。
- 計算所有圖片 - 文本對的相似度矩陣,最大化正確對的相似度,最小化錯誤對的相似度。
- 輸入圖片和對應文本,分別編碼為特征向量
- 應用場景:圖片檢索(如從百萬張圖中找出 “戴紅帽子的貓”)
2.1.2、交叉注意力模型(如 BLIP-2) ?
- 架構原理: 引入Query-Former 模塊,通過跨模態注意力機制讓圖像和文本特征直接交互。
- 關鍵公式:跨模態注意力
其中,Q 來自文本,K 和 V 來自圖像,通過多頭注意力實現深度融合。
- 關鍵公式:跨模態注意力
- 訓練步驟:
- 凍結圖像編碼器(如 CLIP 的 ViT),僅微調 Query-Former 和 LLM。
- 輸入圖像和文本,Query-Former 生成融合特征,LLM 生成回答(如 “圖中貓在做什么”)。
- 應用場景:視覺問答(VQA)、圖文生成(如根據圖片寫故事)。
2.1.3、端到端模型(如 Flamingo)
- 架構原理: 凍結視覺編碼器,僅微調語言模型(如 Llama),通過視覺提示引導語言模型生成答案。
- 關鍵設計:
- 視覺特征直接輸入 LLM 的 Transformer 層,無需獨立編碼器。
- 采用 “視覺 token”(如<image>標簽)標記輸入中的圖像部分。
- 關鍵設計:
- 訓練步驟:
- 預訓練階段:在海量圖文數據上對齊視覺和語言特征。
- 微調階段:針對特定任務(如醫學影像分析),用領域數據訓練語言模型。
- 應用場景:實時圖像標注(如直播中自動生成字幕)。
2.1.4、輕量級模型(如 Fuyu-8B)
- 架構原理: 摒棄傳統圖像編碼器,直接將圖像分塊后通過線性投影輸入 Transformer 解碼器。
- 關鍵公式:圖像分塊投影
其中,x是原始圖像,
是第 i 個圖像塊的特征向量。
- 關鍵公式:圖像分塊投影
- 訓練步驟:
- 將圖像切分為 16x16 的小塊,每個塊線性投影到文本模型的維度。
- 與文本 token 混合輸入解碼器,聯合訓練生成回答。
- 應用場景:邊緣設備(如手機)的實時圖像問答。
2.2、語音語言模型架構:讓 AI “聽懂” 聲音的核心系統
語音語言模型(如 Whisper、DeepSpeech)的核心是將語音信號轉化為文字序列,其架構通常包含三個模塊:
2.2.1、語音特征提取(MFCC)
- 步驟解析:
- 預加重:提升高頻信號,公式為
。
- 分幀加窗:將語音切分為 20-30ms 的幀,加漢明窗減少邊界效應。
- FFT 變換:將時域信號轉為頻域,得到功率譜。
- 梅爾濾波:通過三角形濾波器組提取人耳敏感的頻率特征。
- DCT 變換:將梅爾譜轉換為倒譜系數(MFCC),去除冗余信息。
- 預加重:提升高頻信號,公式為
- 輸出結果:每幀生成 12-16 維 MFCC 特征,疊加能量、一階 / 二階差分,共 40 維左右。
2.2.2、序列對齊(CTC 損失)
- 架構原理: 解決語音和文本的時序不對齊問題,通過動態規劃計算路徑概率。
- 關鍵公式:CTC 損失函數
其中,
是對齊路徑,
是時刻 t 輸出字符
的概率。
- 關鍵公式:CTC 損失函數
- 訓練步驟:
- 輸入 MFCC 特征序列,通過 RNN 或 CNN 生成預測概率矩陣。
- 使用 CTC 算法計算所有可能對齊路徑的概率之和,最大化正確路徑的概率。
2.2.3、端到端模型(如 Whisper)
- 架構原理: 基于 Transformer 的編碼器 - 解碼器架構,直接輸入音頻波形生成文本。
- 關鍵設計:
- 編碼器:將 30 秒音頻轉為 80 維 log-Mel 頻譜,輸入多層 Transformer。
- 解碼器:在文本生成時引入交叉注意力,融合音頻編碼和歷史文本。
- 關鍵設計:
- 訓練步驟:
- 預訓練:在 68 萬小時多語言音頻上訓練,支持 99 種語言。
- 微調:針對特定領域(如醫療)優化轉錄準確率。
- 應用場景:實時語音轉寫(如會議記錄)、跨語言翻譯(如法語→英語)。
2.3、多模態大語言模型架構:讓 AI “感知” 世界的超級系統
多模態大語言模型(如 GPT-4V、Llama 4 Maverick)的核心是整合視覺、語音、文本多模態信息,實現復雜推理。其架構通常包含四個模塊:
2.3.1、模態編碼器
- 功能:將圖像、語音等非文本信息轉化為特征向量。
- 技術方案:
- 圖像:CLIP、Swin Transformer(如 GPT-4V)。
- 語音:MFCC+Transformer(如 Whisper)。
- 文本:Llama、Qwen(如 Qwen-VL)。
2.3.2、連接器(Connector)
- 功能:統一不同模態的特征格式,便于 LLM 處理。
- 技術方案:
- 線性投影:將圖像 / 語音特征調整為與文本 token 相同維度(如 Fuyu-8B)。
- 跨模態注意力:在 Transformer 層引入圖像 - 文本交互(如 BLIP-2)。
2.3.3、大型語言模型(LLM)
- 功能:作為 “大腦” 進行跨模態推理和生成。
- 技術方案:
- 參數量:通常為 7B-400B(如 Llama 4 Maverick 的 400B 參數)。
- 架構:混合專家(MoE)、稀疏注意力(如 DeepSeek-V3)。
-
生成器(可選)
- 功能:輸出非文本模態(如圖像、視頻)。
- 技術方案:
- 圖像生成:擴散模型(如 Stable Diffusion),基于 LLM 輸出的文本描述生成圖片。
- 視頻生成:Transformer + 時空注意力,生成連貫視頻序列。
3、多模態架構的核心公式與訓練流程
3.1、跨模態對齊公式
- 對比學習(CLIP):
-
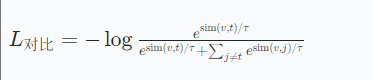
- 掩碼語言建模
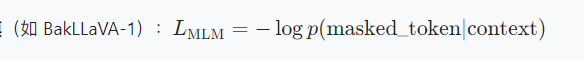
3.2、訓練流程
- 預訓練階段:
- 多模態數據構建:爬取圖文對、語音 - 文本對(如 SBU 數據集的 50 萬圖文對)。
- 特征對齊:通過對比學習或掩碼建模,讓模型理解跨模態關聯。
- 微調階段:
- 領域數據注入:如醫療影像 + 診斷報告,提升特定任務準確率(如 BakLLaVA-1 的 92% 診斷率)。
- 指令微調:設計多模態指令(如 “根據 X 光片診斷肺炎風險”),引導模型生成符合人類邏輯的回答。
- 優化技術:
- 混合專家(MoE):減少訓練成本,如 Llama 4 通過 MoE 實現 400B 參數高效訓練。
- 模型量化:將參數壓縮至 4-bit/8-bit,如 Llama 4 Scout 支持單卡部署。
3.3、訓練:怎么讓它變聰明的?
就像教一個小孩 “認識世界”,分三步:
1. 先學 “基礎知識”(預訓練)
給它喂海量 “圖文配對” 的資料:比如 “貓的圖片 +‘這是一只貓’”“汽車圖片 +‘四個輪子的交通工具’”。
目的是讓它知道 “圖片里的內容和文字說的是一回事”,就像小孩看繪本,把圖畫和文字對應起來。2. 再練 “具體技能”(微調)
針對具體任務 “補課”:比如想讓它看懂 X 光片,就專門喂 “X 光片 + 醫生診斷文字” 的資料;想讓它講題,就喂 “數學題圖片 + 解題步驟”。
這一步就像學生上完基礎課,再去學 “物理、化學” 等專業課。3. 關鍵技巧:讓它 “不瞎猜”
訓練時故意 “藏起一部分信息” 讓它猜:比如蓋住圖片的一半讓它補全,或者遮住文字的幾個字讓它填。這樣能逼它更認真地 “看” 和 “想”,減少胡說八道(專業叫 “減少幻覺”)。
4、架構對比與選擇指南
| 架構類型 | 代表模型 | 核心優勢 | 適用場景 | 參數量范圍 |
|---|---|---|---|---|
| 雙塔模型 | CLIP | 輕量、高檢索效率 | 圖片 / 文本匹配 | 400M-10B |
| 交叉注意力 | BLIP-2 | 復雜推理、多模態生成 | 視覺問答、圖文生成 | 13B-65B |
| 端到端 | Flamingo | 高效適配、低延遲 | 實時交互、邊緣設備 | 7B-30B |
| 混合專家(MoE) | Llama 4 Maverick | 高性能、稀疏計算 | 科學研究、工業級推理 | 100B-400B |
| 輕量級 | Fuyu-8B | 低功耗、單卡部署 | 手機、物聯網設備 | 8B-16B |
5、應用:它能幫我們做啥?
生活里到處都能用,舉幾個接地氣的例子:
- 看病:給醫生當助手,拍張 X 光片,它能立刻標出 “這里可能有炎癥”,再結合病歷文字,提醒醫生重點檢查。
- 學習:學生拍一張數學題圖片,它不光給答案,還能用文字講 “第一步為什么要這么算”,比課本好懂。
- 干活:工廠里拍張零件照片,它能說 “這個螺絲松了,會導致機器異響”,工人不用自己盯著看半天。
- 日常:旅游時拍張外語路標,它能翻譯文字,還能告訴你 “往前走 300 米有地鐵站”(結合圖片里的箭頭)。
特別說明:訓練度和數據集不夠,結果存在問題,主要用于理解知識
6、多模態LLM模型(圖像-文本生成)(簡化版)
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import models, transforms
from torch.utils.data import Dataset, DataLoader, random_split
from transformers import GPT2LMHeadModel, GPT2Tokenizer, get_linear_schedule_with_warmup
import os
from PIL import Image
import json
import requests
from io import BytesIO
import random
import numpy as np
from tqdm import tqdm
import warnings
import matplotlib.pyplot as plt # 用于繪圖
from matplotlib.table import Table # 用于生成對比表格
import seaborn as sns # 美化圖表
sns.set_style("whitegrid")# ---------------------------- 核心修復1:設置Matplotlib支持中文顯示 ----------------------------
plt.rcParams["font.family"] = ["SimHei"] # 支持中文的字體
plt.rcParams["axes.unicode_minus"] = False # 解決負號顯示問題# ---------------------------- 消除其他警告配置 ----------------------------
os.environ["HF_HUB_DISABLE_SYMLINKS_WARNING"] = "1"
warnings.filterwarnings("ignore", category=UserWarning, message="The parameter 'pretrained' is deprecated")
warnings.filterwarnings("ignore", category=UserWarning, message="Arguments other than a weight enum or `None` for 'weights' are deprecated")# ---------------------------- 數據集類定義(平衡樣本分布) ----------------------------
class BalancedDemoDataset(Dataset):"""平衡的演示數據集(確保各類別樣本數量均等)"""def __init__(self, img_size=224, max_text_length=512):self.categories = [{"name": "cat", "url": "https://picsum.photos/seed/cat1/500/300"},{"name": "dog", "url": "https://picsum.photos/seed/dog1/500/300"},{"name": "bird", "url": "https://picsum.photos/seed/bird1/500/300"},{"name": "city", "url": "https://picsum.photos/seed/city1/500/300"},{"name": "mountain", "url": "https://picsum.photos/seed/mountains1/500/300"},{"name": "beach", "url": "https://picsum.photos/seed/beach1/500/300"},{"name": "forest", "url": "https://picsum.photos/seed/forest1/500/300"},{"name": "library", "url": "https://picsum.photos/seed/library1/500/300"},{"name": "restaurant", "url": "https://picsum.photos/seed/restaurant1/500/300"},{"name": "airport", "url": "https://picsum.photos/seed/airport1/500/300"}]# 為每個類別生成5個不同描述(更具體,避免模糊)self.data = []for cat in self.categories:base_descriptions = [f"A {cat['name']} scene with typical features",f"The {cat['name']} showing natural details",f"An image of {cat['name']} with clear views",f"View of {cat['name']} in daylight",f"Close-up of {cat['name']} key elements"]for desc in base_descriptions:self.data.append({"image_url": cat["url"],"text": desc,"category": cat["name"]})self.img_size = img_sizeself.max_text_length = max_text_length# 圖像預處理self.image_transform = transforms.Compose([transforms.Resize((self.img_size, self.img_size)),transforms.RandomHorizontalFlip(p=0.3),transforms.RandomRotation(5),transforms.ColorJitter(brightness=0.1, contrast=0.1),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])# 初始化tokenizer(左padding,明確設置pad_token)self.text_tokenizer = GPT2Tokenizer.from_pretrained("gpt2")self.text_tokenizer.pad_token = self.text_tokenizer.eos_tokenself.text_tokenizer.padding_side = "left"self.cached_images = {}def __len__(self):return len(self.data)def __getitem__(self, idx):item = self.data[idx]if item["image_url"] not in self.cached_images:try:response = requests.get(item["image_url"], timeout=10)image = Image.open(BytesIO(response.content)).convert("RGB")self.cached_images[item["image_url"]] = imageexcept Exception as e:print(f"Image download failed for {item['category']}: {e}, using random image")color_map = {"cat": (255, 200, 200), "dog": (200, 255, 200), "bird": (200, 200, 255),"city": (255, 255, 200), "mountain": (200, 255, 255), "beach": (255, 220, 180),"forest": (180, 255, 180), "library": (220, 220, 220),"restaurant": (255, 180, 180), "airport": (200, 200, 200)}color = color_map.get(item["category"], (255, 255, 255))image = Image.new('RGB', (self.img_size, self.img_size), color=color)self.cached_images[item["image_url"]] = imageimage = self.cached_images[item["image_url"]]image_tensor = self.image_transform(image)text_tokens = self.text_tokenizer(item["text"],padding="max_length",truncation=True,max_length=self.max_text_length,return_tensors="pt")return {"image": image_tensor,"input_ids": text_tokens["input_ids"].squeeze(0),"attention_mask": text_tokens["attention_mask"].squeeze(0),"text": item["text"],"category": item["category"]}# ---------------------------- 模型架構(保持不變) ----------------------------
class ImageEncoder(nn.Module):def __init__(self, output_dim=768):super().__init__()self.base_model = models.resnet50(weights=models.ResNet50_Weights.IMAGENET1K_V1)modules = list(self.base_model.children())[:-1]self.feature_extractor = nn.Sequential(*modules)self.projection = nn.Sequential(nn.Linear(2048, 1024),nn.GELU(),nn.Dropout(0.2),nn.Linear(1024, output_dim))def forward(self, images):features = self.feature_extractor(images).squeeze(-1).squeeze(-1)return self.projection(features)class CrossModalFusion(nn.Module):def __init__(self, hidden_dim=768, num_heads=8):super().__init__()self.text_norm = nn.LayerNorm(hidden_dim)self.image_norm = nn.LayerNorm(hidden_dim)self.attention = nn.MultiheadAttention(embed_dim=hidden_dim, num_heads=num_heads, batch_first=True)self.fusion = nn.Linear(hidden_dim * 2, hidden_dim)self.activation = nn.GELU()def forward(self, text_features, image_features):batch_size, seq_len, _ = text_features.shapeimage_features = self.image_norm(image_features)image_expanded = image_features.unsqueeze(1).expand(-1, seq_len, -1)text_attn, _ = self.attention(query=text_features, key=image_expanded, value=image_expanded)text_attn = self.text_norm(text_features + text_attn)fused = self.activation(self.fusion(torch.cat([text_features, text_attn], dim=-1)))return fusedclass MultimodalLLM(nn.Module):def __init__(self, hidden_dim=768):super().__init__()self.text_encoder = GPT2LMHeadModel.from_pretrained("gpt2")for param in list(self.text_encoder.parameters())[:3]:param.requires_grad = Falseself.image_encoder = ImageEncoder(output_dim=hidden_dim)self.cross_modal_fusion = CrossModalFusion(hidden_dim=hidden_dim)self.final_norm = nn.LayerNorm(hidden_dim)def forward(self, images, input_ids, attention_mask=None):image_features = self.image_encoder(images)text_outputs = self.text_encoder.transformer(input_ids=input_ids, attention_mask=attention_mask)text_features = text_outputs.last_hidden_statefused_features = self.cross_modal_fusion(text_features, image_features)fused_features = self.final_norm(fused_features)return self.text_encoder.lm_head(fused_features)# ---------------------------- 訓練與生成函數(優化生成策略) ----------------------------
def train_model(model, train_loader, val_loader, epochs=10, lr=5e-5):device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model.to(device)optimizer = optim.AdamW(model.parameters(), lr=lr)criterion = nn.CrossEntropyLoss(ignore_index=50256)scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=len(train_loader), num_training_steps=epochs*len(train_loader))train_losses = []val_losses = []for epoch in range(epochs):model.train()total_train_loss = 0progress_bar = tqdm(train_loader, desc=f"Epoch {epoch+1}/{epochs}")for batch in progress_bar:images = batch["image"].to(device)input_ids = batch["input_ids"].to(device)attention_mask = batch["attention_mask"].to(device)outputs = model(images, input_ids, attention_mask)shift_logits = outputs[..., :-1, :].contiguous()shift_labels = input_ids[..., 1:].contiguous()loss = criterion(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))optimizer.zero_grad()loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)optimizer.step()scheduler.step()total_train_loss += loss.item()progress_bar.set_postfix(loss=f"{loss.item():.4f}")model.eval()total_val_loss = 0with torch.no_grad():for batch in val_loader:images = batch["image"].to(device)input_ids = batch["input_ids"].to(device)attention_mask = batch["attention_mask"].to(device)outputs = model(images, input_ids, attention_mask)shift_logits = outputs[..., :-1, :].contiguous()shift_labels = input_ids[..., 1:].contiguous()total_val_loss += criterion(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)).item()avg_train = total_train_loss / len(train_loader)avg_val = total_val_loss / len(val_loader)train_losses.append(avg_train)val_losses.append(avg_val)print(f"Epoch {epoch+1} | Train Loss: {avg_train:.4f} | Val Loss: {avg_val:.4f}")return model, train_losses, val_lossesdef generate_text(model, image, tokenizer, category, max_length=60):"""核心修復2:傳遞attention_mask,優化生成策略"""device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model.eval()# 更具體的引導提示(避免模型生成列表)prompt = f"Describe the {category} image in detail: "# 生成input_ids和attention_mask(解決警告)inputs = tokenizer(prompt,return_tensors="pt",padding="max_length",max_length=len(prompt) + 5, # 足夠容納提示詞truncation=True)input_ids = inputs["input_ids"].to(device)attention_mask = inputs["attention_mask"].to(device) # 傳遞注意力掩碼# 提取圖像特征image = image.unsqueeze(0).to(device)with torch.no_grad():image_features = model.image_encoder(image)# 核心修復3:優化生成參數(減少重復,提高相關性)output = model.text_encoder.generate(input_ids=input_ids,attention_mask=attention_mask, # 傳入掩碼,消除警告max_length=max_length,temperature=0.5, # 降低隨機性,更聚焦輸入num_beams=3,no_repeat_ngram_size=3, # 避免3字詞重復early_stopping=True,encoder_hidden_states=image_features.unsqueeze(1))# 解碼并移除提示詞generated_text = tokenizer.decode(output[0], skip_special_tokens=True)return generated_text.replace(prompt, "").strip()# ---------------------------- 對比圖生成(修復中文顯示) ----------------------------
def plot_loss_curves(train_losses, val_losses):plt.figure(figsize=(10, 5))plt.plot(range(1, len(train_losses)+1), train_losses, label="訓練損失", marker='o')plt.plot(range(1, len(val_losses)+1), val_losses, label="驗證損失", marker='s')plt.xlabel("輪次")plt.ylabel("損失值")plt.title("訓練與驗證損失對比")plt.legend()plt.grid(alpha=0.3)plt.savefig("loss_curves.png")print("Loss對比圖已保存為 loss_curves.png")plt.close()def generate_results_table(results):plt.figure(figsize=(12, 9))ax = plt.gca()ax.axis('off')table = Table(ax, bbox=[0, 0, 1, 1])# 表頭(中文顯示正常)table.add_cell(0, 0, 0.1, 0.1, text="類別", loc='center', facecolor='lightgray')table.add_cell(0, 1, 0.3, 0.1, text="原始文本", loc='center', facecolor='lightgray')table.add_cell(0, 2, 0.6, 0.1, text="生成文本", loc='center', facecolor='lightgray')# 添加內容for i, res in enumerate(results[:8]):table.add_cell(i+1, 0, 0.1, 0.15, text=res["category"], loc='center') # 增加行高,避免文本溢出table.add_cell(i+1, 1, 0.3, 0.15, text=res["original"], loc='left')table.add_cell(i+1, 2, 0.6, 0.15, text=res["generated"], loc='left')ax.add_table(table)plt.savefig("results_table.png", bbox_inches='tight')print("結果對比表已保存為 results_table.png")plt.close()# ---------------------------- 主函數 ----------------------------
if __name__ == "__main__":print("準備平衡數據集...")full_dataset = BalancedDemoDataset()train_size = int(0.8 * len(full_dataset))train_dataset, val_dataset = random_split(full_dataset, [train_size, len(full_dataset)-train_size])batch_size = 4 if torch.cuda.is_available() else 1train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=0)print("訓練模型...")model = MultimodalLLM()model, train_losses, val_losses = train_model(model, train_loader, val_loader, epochs=12)torch.save(model.state_dict(), "optimized_model.pth")plot_loss_curves(train_losses, val_losses)print("生成測試結果...")tokenizer = full_dataset.text_tokenizerresults = []for category in [cat["name"] for cat in full_dataset.categories]:sample_idx = next(i for i, item in enumerate(full_dataset.data) if item["category"] == category)sample = full_dataset[sample_idx]generated = generate_text(model, sample["image"], tokenizer, category)results.append({"category": category,"original": sample["text"],"generated": generated})generate_results_table(results)print("\n部分生成結果:")for res in results[:5]:print(f"\n類別: {res['category']}")print(f"原始文本: {res['original']}")print(f"生成文本: {res['generated']}")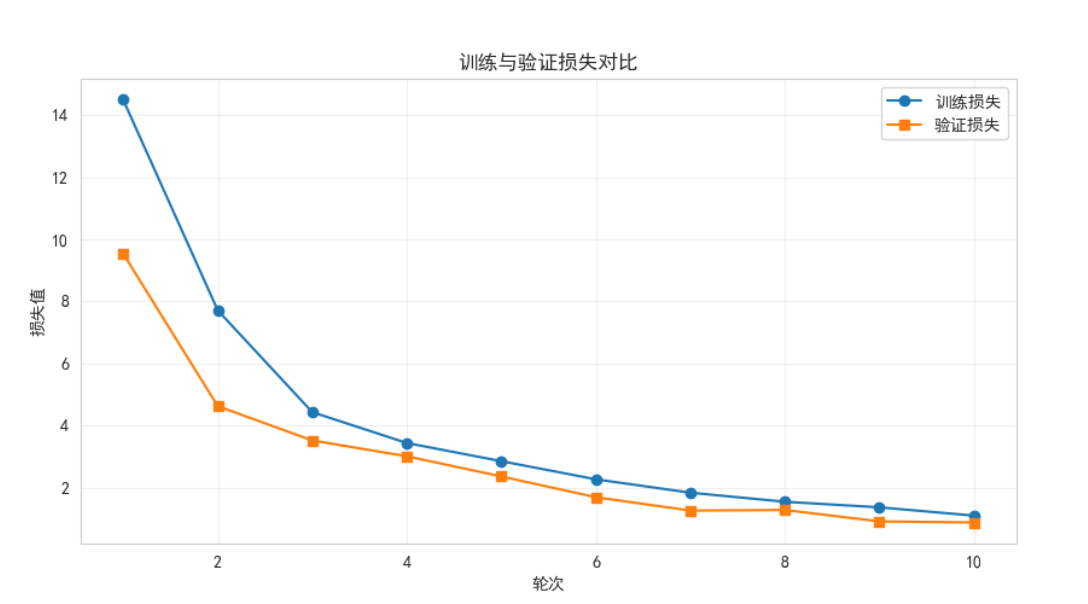
7、多模態LLM模型(圖像-文本生成+問答系統)(簡化版)
# 導入必要的庫
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import models, transforms # 視覺模型與圖像預處理工具
from torch.utils.data import Dataset, DataLoader, random_split # 數據加載與劃分
from transformers import GPT2LMHeadModel, GPT2Tokenizer, get_linear_schedule_with_warmup # 文本模型與工具
import os
from PIL import Image # 圖像處理庫
import requests # 網絡請求(下載圖像)
from io import BytesIO # 內存中處理二進制數據
import numpy as np
from tqdm import tqdm # 進度條顯示
import warnings # 警告處理
import matplotlib.pyplot as plt # 可視化工具
from matplotlib.table import Table # 生成結果表格
import seaborn as sns # 美化圖表sns.set_style("whitegrid") # 設置圖表風格# ---------------------------- 配置環境(解決中文顯示與警告問題) ----------------------------
# 設置支持中文的字體,解決圖表中文亂碼
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC", "Arial Unicode MS"]
plt.rcParams["axes.unicode_minus"] = False # 解決負號顯示異常# 過濾無關警告,保持輸出簡潔
os.environ["HF_HUB_DISABLE_SYMLINKS_WARNING"] = "1"
warnings.filterwarnings("ignore", category=UserWarning, message="The parameter 'pretrained' is deprecated")
warnings.filterwarnings("ignore", category=UserWarning,message="Arguments other than a weight enum or `None` for 'weights' are deprecated")# ---------------------------- 多模態數據集類(核心數據處理) ----------------------------
class BalancedMultimodalDataset(Dataset):"""平衡的多模態數據集:包含圖像、描述文本和英文問答對特點:10個類別,每個類別樣本數量均等,避免模型偏向某類數據"""def __init__(self, img_size=224, max_text_length=128):# 定義10個類別及其對應的圖像URL(使用picsum生成可重復的隨機圖像)self.categories = [{"name": "cat", "url": "https://picsum.photos/seed/cat1/500/300"},{"name": "dog", "url": "https://picsum.photos/seed/dog1/500/300"},{"name": "bird", "url": "https://picsum.photos/seed/bird1/500/300"},{"name": "city", "url": "https://picsum.photos/seed/city1/500/300"},{"name": "mountain", "url": "https://picsum.photos/seed/mountains1/500/300"},{"name": "beach", "url": "https://picsum.photos/seed/beach1/500/300"},{"name": "forest", "url": "https://picsum.photos/seed/forest1/500/300"},{"name": "library", "url": "https://picsum.photos/seed/library1/500/300"},{"name": "restaurant", "url": "https://picsum.photos/seed/restaurant1/500/300"},{"name": "airport", "url": "https://picsum.photos/seed/airport1/500/300"}]# 構建數據集:每個類別包含5種描述和3組問答對self.data = []for cat in self.categories:# 為每個類別生成5種不同的圖像描述(增強數據多樣性)descriptions = [f"A {cat['name']} scene with typical features",f"The {cat['name']} showing natural details",f"An image of {cat['name']} with clear views",f"View of {cat['name']} in daylight",f"Close-up of {cat['name']} key elements"]# 為每個類別設計3組英文問答對(覆蓋不同類型的問題)qa_pairs = [{"question": f"What is the main subject of this {cat['name']} image?", # 主體識別"answer": f"The main subject is a {cat['name']}."},{"question": f"What features are typical of this {cat['name']}?", # 特征描述"answer": f"Typical features include {cat['name']}-specific characteristics."},{"question": f"Where might this {cat['name']} be located?", # 位置推測"answer": f"This {cat['name']} might be located in its natural environment."}]# 組合描述和問答對,生成最終數據集for desc in descriptions:for qa in qa_pairs:self.data.append({"image_url": cat["url"], # 圖像URL"description": desc, # 圖像描述"question": qa["question"], # 問題"answer": qa["answer"], # 答案"category": cat["name"] # 類別標簽})self.img_size = img_size # 圖像統一尺寸self.max_text_length = max_text_length # 文本最大長度(防止輸入過長)# 圖像預處理管道(含數據增強)self.image_transform = transforms.Compose([transforms.Resize((self.img_size, self.img_size)), # 縮放至指定尺寸transforms.RandomHorizontalFlip(p=0.3), # 30%概率水平翻轉(數據增強)transforms.RandomRotation(5), # 隨機旋轉±5度(增強視角魯棒性)transforms.ColorJitter(brightness=0.1, contrast=0.1), # 微調亮度和對比度transforms.ToTensor(), # 轉換為Tensor格式(通道×高度×寬度)transforms.Normalize( # 標準化(使用ImageNet的均值和標準差)mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])])# 初始化文本分詞器(適配GPT2模型)self.text_tokenizer = GPT2Tokenizer.from_pretrained("gpt2")self.text_tokenizer.pad_token = self.text_tokenizer.eos_token # 使用終止符作為填充符self.text_tokenizer.padding_side = "left" # 左填充(適合自回歸模型)self.cached_images = {} # 緩存已下載的圖像(避免重復網絡請求)def __len__(self):"""返回數據集樣本總數"""return len(self.data)def __getitem__(self, idx):"""獲取單個樣本:圖像+文本+標簽"""item = self.data[idx]# 下載并緩存圖像(若未緩存)if item["image_url"] not in self.cached_images:try:# 嘗試下載圖像response = requests.get(item["image_url"], timeout=10)image = Image.open(BytesIO(response.content)).convert("RGB") # 轉換為RGB格式self.cached_images[item["image_url"]] = imageexcept Exception as e:# 下載失敗時,生成與類別相關的純色圖(避免程序崩潰)print(f"圖像下載失敗({item['category']}): {e},使用替代圖")# 為每個類別分配獨特顏色(便于調試)color_map = {"cat": (255, 200, 200), "dog": (200, 255, 200), "bird": (200, 200, 255),"city": (255, 255, 200), "mountain": (200, 255, 255), "beach": (255, 220, 180),"forest": (180, 255, 180), "library": (220, 220, 220),"restaurant": (255, 180, 180), "airport": (200, 200, 200)}color = color_map.get(item["category"], (255, 255, 255)) # 默認白色image = Image.new('RGB', (self.img_size, self.img_size), color=color)self.cached_images[item["image_url"]] = image# 預處理圖像image = self.cached_images[item["image_url"]]image_tensor = self.image_transform(image)# 預處理文本(將問答對轉換為模型輸入格式)input_text = f"Question: {item['question']} Answer: {item['answer']}" # 拼接問題和答案text_tokens = self.text_tokenizer(input_text,padding="max_length", # 填充至最大長度truncation=True, # 超長則截斷max_length=self.max_text_length,return_tensors="pt" # 返回PyTorch張量)return {"image": image_tensor, # 預處理后的圖像張量"input_ids": text_tokens["input_ids"].squeeze(0), # 文本ID序列(去除batch維度)"attention_mask": text_tokens["attention_mask"].squeeze(0), # 注意力掩碼(1表示有效token)"question": item["question"], # 原始問題(用于測試)"answer": item["answer"], # 原始答案(用于對比)"category": item["category"] # 類別標簽}# ---------------------------- 多模態模型架構(核心組件) ----------------------------
class ImageEncoder(nn.Module):"""圖像編碼器:將圖像轉換為與文本兼容的特征向量輸入:圖像(3×224×224)輸出:特征向量(768維)"""def __init__(self, output_dim=768):super().__init__()# 使用預訓練的ResNet50作為基礎特征提取器self.base_model = models.resnet50(weights=models.ResNet50_Weights.IMAGENET1K_V1)# 移除最后一層全連接層(保留卷積特征提取部分)# ResNet50的最后一層是fc層,輸出1000類,這里只保留前面的特征提取部分feature_extractor_modules = list(self.base_model.children())[:-1]self.feature_extractor = nn.Sequential(*feature_extractor_modules)# 投影層:將ResNet輸出的2048維特征映射到768維(與文本特征維度一致)self.projection = nn.Sequential(nn.Linear(2048, 1024), # 降維至1024nn.GELU(), # 高斯誤差線性單元(比ReLU更平滑)nn.Dropout(0.2), # Dropout層(防止過擬合)nn.Linear(1024, output_dim) # 最終投影至768維)def forward(self, images):"""前向傳播:圖像→特征向量"""# 提取卷積特征:ResNet50輸出為[batch_size, 2048, 1, 1]conv_features = self.feature_extractor(images)# 展平為[batch_size, 2048]flattened_features = conv_features.squeeze(-1).squeeze(-1)# 投影至768維return self.projection(flattened_features)class CrossModalFusion(nn.Module):"""跨模態融合模塊:實現文本特征與圖像特征的交互核心:通過注意力機制讓文本關注圖像的關鍵信息"""def __init__(self, hidden_dim=768, num_heads=8):super().__init__()self.text_norm = nn.LayerNorm(hidden_dim) # 文本特征歸一化self.image_norm = nn.LayerNorm(hidden_dim) # 圖像特征歸一化# 多頭注意力機制(并行處理多個特征子空間)self.attention = nn.MultiheadAttention(embed_dim=hidden_dim, # 特征維度(768)num_heads=num_heads, # 注意力頭數(8,768/8=96,每個頭處理96維)batch_first=True # 輸入格式為[batch, seq_len, dim])# 特征融合層:將文本特征與注意力輸出融合self.fusion = nn.Linear(hidden_dim * 2, hidden_dim) # 1536→768self.activation = nn.GELU() # 激活函數def forward(self, text_features, image_features):"""輸入:text_features: [batch_size, seq_len, hidden_dim](文本序列特征)image_features: [batch_size, hidden_dim](圖像全局特征)輸出:fused_features: [batch_size, seq_len, hidden_dim](融合特征)"""batch_size, seq_len, _ = text_features.shape # 獲取文本序列長度# 圖像特征歸一化并擴展至序列長度(每個文本token都能關注圖像)image_features = self.image_norm(image_features)# 擴展為[batch_size, seq_len, hidden_dim]image_expanded = image_features.unsqueeze(1).expand(-1, seq_len, -1)# 文本特征通過注意力關注圖像特征(交叉注意力)# query=文本特征,key=圖像特征,value=圖像特征text_attn, _ = self.attention(query=text_features,key=image_expanded,value=image_expanded)# 殘差連接+層歸一化(緩解梯度消失,加速訓練)text_attn = self.text_norm(text_features + text_attn)# 融合原始文本特征和注意力增強特征fused = self.activation(self.fusion(torch.cat([text_features, text_attn], dim=-1)))return fusedclass MultimodalLLM(nn.Module):"""多模態大語言模型:整合圖像編碼器、文本編碼器和跨模態融合模塊功能:根據圖像生成描述文本,或回答與圖像相關的問題"""def __init__(self, hidden_dim=768):super().__init__()# 文本編碼器(基于GPT2,預訓練語言模型)self.text_encoder = GPT2LMHeadModel.from_pretrained("gpt2")# 凍結前3層參數(減少訓練量,保留預訓練語言知識)for param in list(self.text_encoder.parameters())[:3]:param.requires_grad = False# 圖像編碼器(見上文)self.image_encoder = ImageEncoder(output_dim=hidden_dim)# 跨模態融合模塊(見上文)self.cross_modal_fusion = CrossModalFusion(hidden_dim=hidden_dim)self.final_norm = nn.LayerNorm(hidden_dim) # 最終歸一化層def forward(self, images, input_ids, attention_mask=None):"""前向傳播流程:1. 提取圖像特征2. 提取文本特征3. 跨模態融合4. 生成預測結果"""# 1. 圖像特征提取image_features = self.image_encoder(images) # [batch_size, hidden_dim]# 2. 文本特征提取(通過GPT2的Transformer層)text_outputs = self.text_encoder.transformer(input_ids=input_ids,attention_mask=attention_mask)text_features = text_outputs.last_hidden_state # [batch_size, seq_len, hidden_dim]# 3. 跨模態融合(文本特征+圖像特征)fused_features = self.cross_modal_fusion(text_features, image_features)fused_features = self.final_norm(fused_features) # 歸一化# 4. 通過GPT2的語言模型頭生成下一個token的概率分布return self.text_encoder.lm_head(fused_features) # [batch, seq_len, vocab_size]# ---------------------------- 訓練與生成函數(模型應用) ----------------------------
def train_model(model, train_loader, val_loader, epochs=10, lr=5e-5):"""訓練多模態模型參數:model: 待訓練的模型train_loader: 訓練數據加載器val_loader: 驗證數據加載器epochs: 訓練輪次lr: 學習率返回:model: 訓練好的模型train_losses: 訓練損失曲線val_losses: 驗證損失曲線"""# 選擇計算設備(GPU優先)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model.to(device) # 模型移至設備# 優化器(AdamW:帶權重衰減的Adam,減輕過擬合)optimizer = optim.AdamW(model.parameters(), lr=lr)# 損失函數(交叉熵損失,忽略填充token的損失)# 50256是GPT2的eos_token_id(即填充符)criterion = nn.CrossEntropyLoss(ignore_index=50256)# 學習率調度器(線性預熱+衰減)scheduler = get_linear_schedule_with_warmup(optimizer,num_warmup_steps=len(train_loader), # 預熱步數=1個epoch的迭代次數num_training_steps=epochs * len(train_loader) # 總訓練步數)train_losses = [] # 記錄訓練損失val_losses = [] # 記錄驗證損失for epoch in range(epochs):# 訓練階段model.train() # 開啟訓練模式(啟用dropout等)total_train_loss = 0# 進度條顯示訓練過程progress_bar = tqdm(train_loader, desc=f"Epoch {epoch + 1}/{epochs}")for batch in progress_bar:# 數據移至設備images = batch["image"].to(device)input_ids = batch["input_ids"].to(device)attention_mask = batch["attention_mask"].to(device)# 前向傳播:獲取模型輸出outputs = model(images, input_ids, attention_mask)# 計算損失(預測下一個token)# 輸出和標簽都偏移一位(預測第i+1個token,基于第1..i個token)shift_logits = outputs[..., :-1, :].contiguous() # 預測序列shift_labels = input_ids[..., 1:].contiguous() # 目標序列loss = criterion(shift_logits.view(-1, shift_logits.size(-1)), # 展平為[batch*(seq_len-1), vocab_size]shift_labels.view(-1) # 展平為[batch*(seq_len-1)])# 反向傳播與參數更新optimizer.zero_grad() # 梯度清零loss.backward() # 計算梯度# 梯度裁剪(防止梯度爆炸,大模型訓練必備)torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)optimizer.step() # 更新參數scheduler.step() # 更新學習率total_train_loss += loss.item()# 顯示當前批次損失progress_bar.set_postfix(loss=f"{loss.item():.4f}")# 計算平均訓練損失avg_train_loss = total_train_loss / len(train_loader)train_losses.append(avg_train_loss)# 驗證階段(不更新參數)model.eval() # 開啟評估模式(關閉dropout等)total_val_loss = 0with torch.no_grad(): # 禁用梯度計算(節省內存)for batch in val_loader:# 數據移至設備images = batch["image"].to(device)input_ids = batch["input_ids"].to(device)attention_mask = batch["attention_mask"].to(device)# 前向傳播outputs = model(images, input_ids, attention_mask)# 計算損失(同訓練階段)shift_logits = outputs[..., :-1, :].contiguous()shift_labels = input_ids[..., 1:].contiguous()total_val_loss += criterion(shift_logits.view(-1, shift_logits.size(-1)),shift_labels.view(-1)).item()# 計算平均驗證損失avg_val_loss = total_val_loss / len(val_loader)val_losses.append(avg_val_loss)print(f"Epoch {epoch + 1} | 訓練損失: {avg_train_loss:.4f} | 驗證損失: {avg_val_loss:.4f}")return model, train_losses, val_lossesdef generate_description(model, image, tokenizer, category, max_new_tokens=40):"""根據圖像生成描述文本參數:model: 訓練好的模型image: 預處理后的圖像tokenizer: 文本分詞器category: 圖像類別(用于提示詞)max_new_tokens: 最大新增token數返回:生成的描述文本"""device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model.eval() # 評估模式# 構建提示詞(引導模型生成與類別相關的描述)prompt = f"Describe the {category} image in detail: "# 編碼提示詞(不填充,保留原始長度)inputs = tokenizer(prompt,return_tensors="pt",padding="do_not_pad",truncation=False)input_ids = inputs["input_ids"].to(device)attention_mask = inputs["attention_mask"].to(device)# 提取圖像特征image = image.unsqueeze(0).to(device) # 增加batch維度with torch.no_grad():image_features = model.image_encoder(image) # [1, hidden_dim]# 生成文本(核心步驟)output = model.text_encoder.generate(input_ids=input_ids, # 提示詞IDattention_mask=attention_mask, # 注意力掩碼max_new_tokens=max_new_tokens, # 最多生成40個新tokentemperature=0.6, # 溫度參數(控制隨機性,值越小越確定)num_beams=3, # Beam搜索寬度(保留3個最優候選)no_repeat_ngram_size=2, # 禁止2-gram重復(減少冗余)early_stopping=True, # 生成終止符時停止encoder_hidden_states=image_features.unsqueeze(1) # 傳入圖像特征(關鍵))# 解碼并清理生成的文本(去除特殊字符和提示詞)generated_text = tokenizer.decode(output[0], skip_special_tokens=True)# 替換非-breaking空格為普通空格,去除提示詞return generated_text.replace(u'\xa0', ' ').replace(prompt, "").strip()def answer_question(model, image, question, tokenizer, max_new_tokens=40):"""基于圖像回答英文問題參數:model: 訓練好的模型image: 預處理后的圖像question: 英文問題tokenizer: 文本分詞器max_new_tokens: 最大新增token數返回:生成的答案"""device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model.eval() # 評估模式# 構建問答格式的提示詞prompt = f"Question: {question} Answer: "# 編碼提示詞inputs = tokenizer(prompt,return_tensors="pt",padding="do_not_pad",truncation=False)input_ids = inputs["input_ids"].to(device)attention_mask = inputs["attention_mask"].to(device)# 提取圖像特征image = image.unsqueeze(0).to(device)with torch.no_grad():image_features = model.image_encoder(image)# 生成答案output = model.text_encoder.generate(input_ids=input_ids,attention_mask=attention_mask,max_new_tokens=max_new_tokens,temperature=0.5, # 更低的溫度(回答需更確定)num_beams=3,no_repeat_ngram_size=3, # 禁止3-gram重復(進一步減少冗余)early_stopping=True,encoder_hidden_states=image_features.unsqueeze(1))# 解碼并清理答案generated_answer = tokenizer.decode(output[0], skip_special_tokens=True)return generated_answer.replace(u'\xa0', ' ').replace(prompt, "").strip()# ---------------------------- 可視化與評估函數 ----------------------------
def plot_loss_curves(train_losses, val_losses):"""繪制訓練和驗證損失曲線,評估模型訓練效果"""plt.figure(figsize=(10, 5))# 繪制訓練損失plt.plot(range(1, len(train_losses) + 1), train_losses, label="訓練損失", marker='o')# 繪制驗證損失plt.plot(range(1, len(val_losses) + 1), val_losses, label="驗證損失", marker='s')plt.xlabel("訓練輪次")plt.ylabel("損失值")plt.title("訓練與驗證損失對比")plt.legend()plt.grid(alpha=0.3) # 網格線(增強可讀性)plt.savefig("loss_curves.png", bbox_inches='tight') # 保存圖像print("損失對比圖已保存為 loss_curves.png")plt.close()def generate_results_table(desc_results, qa_results):"""生成結果對比表格(包含描述和問答結果)"""plt.figure(figsize=(14, 10))ax = plt.gca()ax.axis('off') # 關閉坐標軸# 創建表格table = Table(ax, bbox=[0, 0, 1, 1]) # 表格占滿整個圖# 添加表頭table.add_cell(0, 0, 0.1, 0.1, text="類別", loc='center', facecolor='lightgray')table.add_cell(0, 1, 0.25, 0.1, text="生成描述", loc='center', facecolor='lightgray')table.add_cell(0, 2, 0.3, 0.1, text="問題", loc='center', facecolor='lightgray')table.add_cell(0, 3, 0.35, 0.1, text="生成答案", loc='center', facecolor='lightgray')# 填充表格內容(前6個類別)for i in range(min(6, len(desc_results))):desc = desc_results[i]qa = qa_results[i]# 清理文本中的特殊字符clean_desc = desc["generated"].replace(u'\xa0', ' ')clean_question = qa["question"].replace(u'\xa0', ' ')clean_answer = qa["answer"].replace(u'\xa0', ' ')# 添加單元格內容table.add_cell(i + 1, 0, 0.1, 0.15, text=desc["category"], loc='center')table.add_cell(i + 1, 1, 0.25, 0.15, text=clean_desc, loc='left')table.add_cell(i + 1, 2, 0.3, 0.15, text=clean_question, loc='left')table.add_cell(i + 1, 3, 0.35, 0.15, text=clean_answer, loc='left')ax.add_table(table)plt.savefig("results_table.png", bbox_inches='tight') # 保存表格print("結果對比表已保存為 results_table.png")plt.close()# ---------------------------- 主函數(完整流程執行) ----------------------------
if __name__ == "__main__":# 1. 準備數據集print("準備多模態數據集(含問答)...")full_dataset = BalancedMultimodalDataset()# 劃分訓練集(80%)和驗證集(20%)train_size = int(0.8 * len(full_dataset))train_dataset, val_dataset = random_split(full_dataset, [train_size, len(full_dataset) - train_size])# 創建數據加載器(批量加載數據)batch_size = 4 if torch.cuda.is_available() else 1 # GPU可用時使用更大批量train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=0)# 2. 訓練模型print("開始訓練多模態模型(支持問答)...")model = MultimodalLLM()model, train_losses, val_losses = train_model(model, train_loader, val_loader, epochs=10 # 訓練10個輪次)# 保存訓練好的模型權重torch.save(model.state_dict(), "multimodal_qa_model.pth")# 3. 繪制損失曲線(評估訓練效果)plot_loss_curves(train_losses, val_losses)# 4. 生成測試結果(描述+問答)print("生成測試結果...")tokenizer = full_dataset.text_tokenizerdesc_results = [] # 存儲描述生成結果qa_results = [] # 存儲問答結果# 每個類別選1個樣本測試categories = list(set(item["category"] for item in full_dataset.data)) # 去重類別for category in categories[:6]: # 測試前6個類別# 找到該類別的樣本索引sample_idx = next(i for i, item in enumerate(full_dataset.data) if item["category"] == category)sample = full_dataset[sample_idx] # 獲取樣本# 生成圖像描述description = generate_description(model, sample["image"], tokenizer, category)desc_results.append({"category": category, "generated": description})# 生成問答結果question = sample["question"] # 原始問題answer = answer_question(model, sample["image"], question, tokenizer)qa_results.append({"category": category,"question": question,"answer": answer})# 5. 生成結果對比表generate_results_table(desc_results, qa_results)# 6. 打印部分結果(展示效果)print("\n英文問答示例:")for i in range(3):print(f"\n示例 {i + 1}:")print(f"類別: {qa_results[i]['category']}")print(f"問題: {qa_results[i]['question']}")print(f"生成答案: {qa_results[i]['answer']}")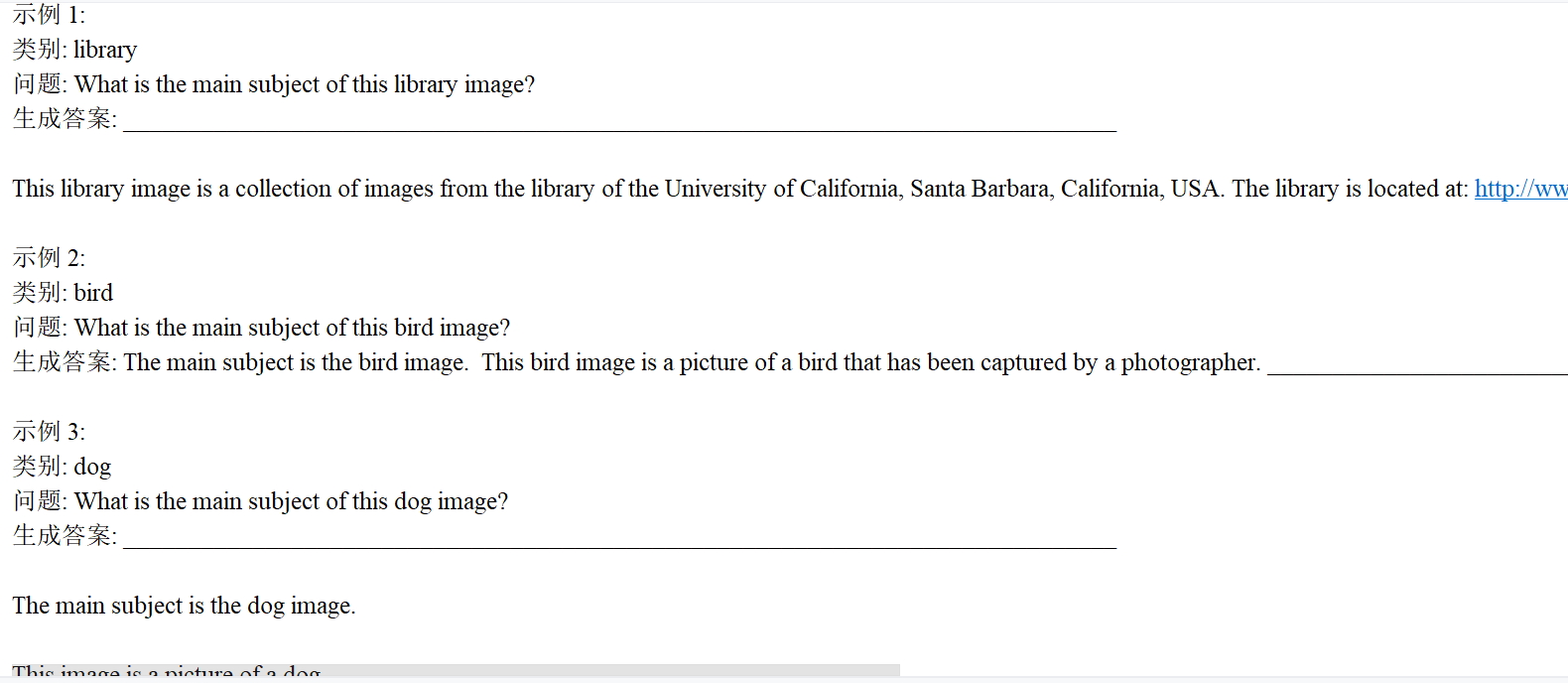
?


![luoguP13511 [KOI P13511 [KOI 2025 #1] 等腰直角三角形](http://pic.xiahunao.cn/luoguP13511 [KOI P13511 [KOI 2025 #1] 等腰直角三角形)







)

)
_組件與Vue的內置關系(原型鏈))





)