文章目錄
- ==有需要本項目的代碼或文檔以及全部資源,或者部署調試可以私信博主==
- 一、項目背景與目標
- 二、數據概覽與預處理
- 2.1 數據導入與初步分析
- 2.2 缺失值與重復值處理
- 2.3 目標變量分布
- 三、探索性數據分析(EDA)
- 3.1 數值變量分布
- 3.2 類別變量分布
- 3.3 特征關系分析
- 3.4 高級可視化分析
- 四、特征工程與數據準備
- 4.1 特征提取與轉換
- 4.2 數據集拆分與標準化
- 五、模型訓練與評估
- 5.1 模型訓練與預測流程
- 5.2 評估指標與可視化
- 5.3 模型保存
- 六、模型推理與實戰應用
- 七、總結與展望
- 7.1 項目成果總結
- 7.2 項目亮點
- 7.3 后續優化方向
- 每文一語
有需要本項目的代碼或文檔以及全部資源,或者部署調試可以私信博主
一、項目背景與目標
隨著在線廣告的普及,如何精準地判斷用戶是否可能點擊廣告成為數字營銷中的關鍵問題。通過分析用戶的日常行為、人口屬性和上網習慣,我們可以利用機器學習模型預測廣告的點擊率,進而優化廣告投放策略,提高轉化率和廣告效益。
本項目旨在基于一份包含10000條用戶行為記錄的數據集,構建多個分類模型,預測用戶是否會點擊廣告。通過數據探索、特征工程、模型訓練和評估,我們希望選出性能最佳的模型并用于后續實際推理。
二、數據概覽與預處理
2.1 數據導入與初步分析
原始數據位于 CSV 文件中,共包含以下特征字段:
Daily Time Spent on Site:每日在網站上停留時間Age:用戶年齡Area Income:所在地區收入水平Daily Internet Usage:每日互聯網使用時間Ad Topic Line、City、Country:文本類信息Timestamp:用戶活動的時間戳Gender:性別Clicked on Ad:目標變量(是否點擊廣告)
通過 df.info() 和 df.describe() 等函數,我們對數據結構和變量范圍有了初步了解。
2.2 缺失值與重復值處理
為保證數據質量,我們進行了以下清洗步驟:
- 使用
dropna()刪除所有缺失值記錄; - 使用
drop_duplicates()去除重復記錄。
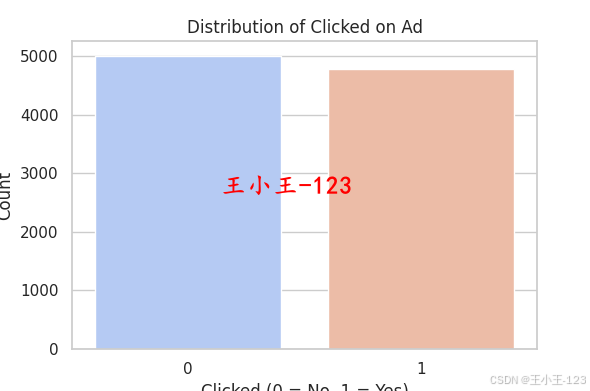
2.3 目標變量分布
通過柱狀圖和餅狀圖分析發現,點擊廣告(1)和未點擊廣告(0)的數量基本持平,表明數據集是平衡數據集,無需進一步處理不均衡問題。
三、探索性數據分析(EDA)
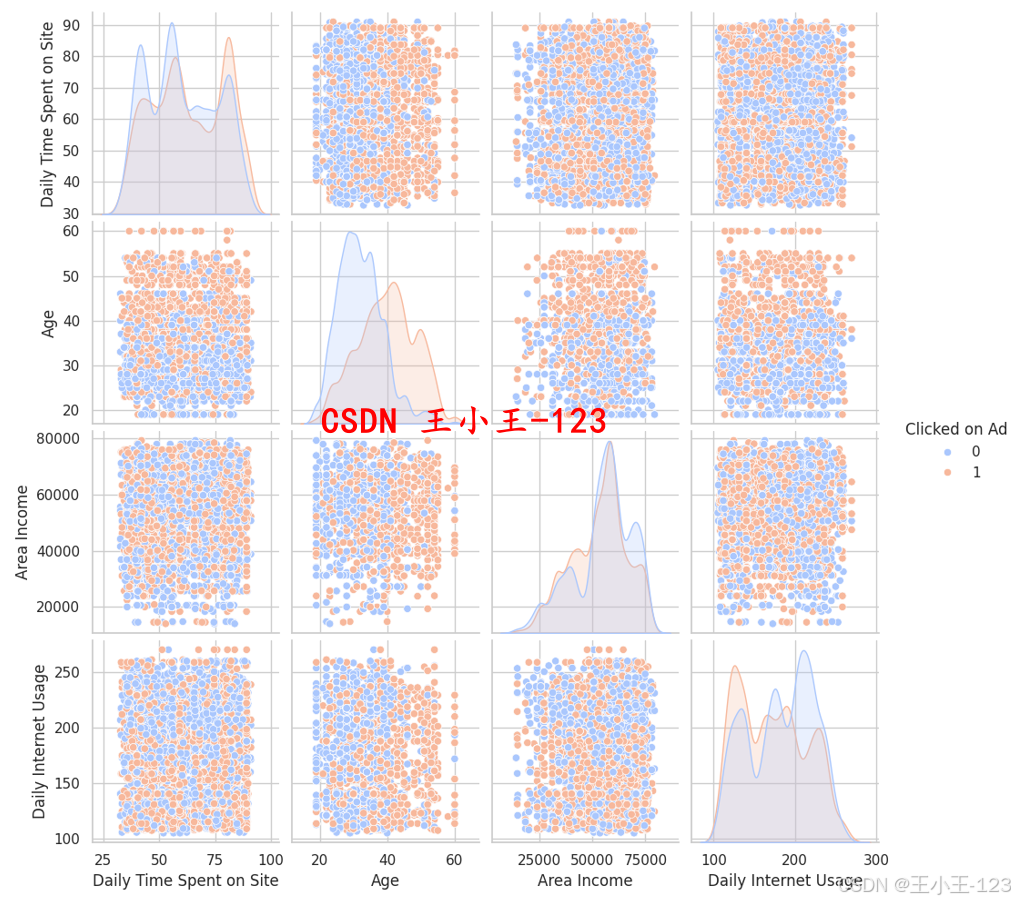
我們對多個特征進行了單變量和多變量分析,以更好地理解它們與廣告點擊行為的關系。
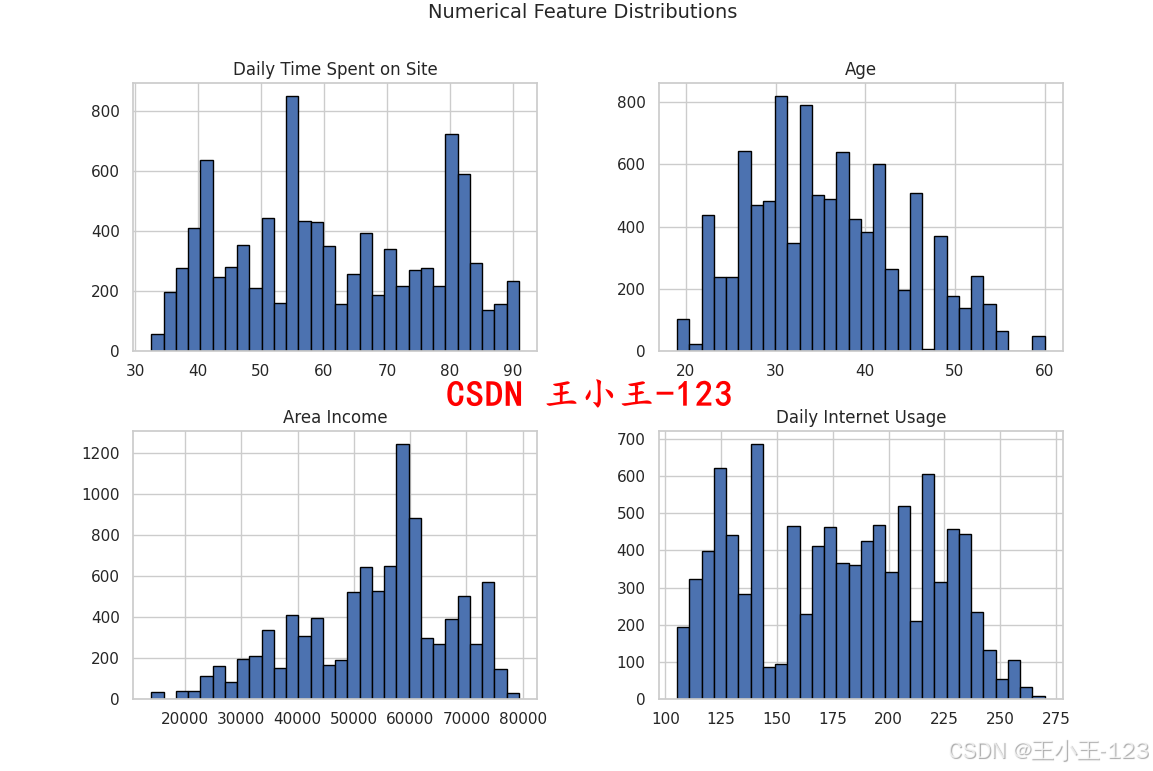
3.1 數值變量分布
通過直方圖觀察可知:
- 大多數用戶在網站停留時間在32到55分鐘之間;
- 年齡主要集中在27到40歲之間;
- 日常互聯網使用時間多為180~240分鐘;
- 地區收入大致分布在30000~80000之間。
3.2 類別變量分布
- 性別分布:男女用戶數量大致相等;
- 國家分布:國家類別眾多,但前幾個國家的數據量明顯較高;
- 性別與點擊的關系:男性點擊廣告的比例略高于女性。
3.3 特征關系分析
使用散點圖和相關性熱力圖分析變量間的相關性:
Age和Daily Time Spent on Site與是否點擊廣告存在顯著模式;Daily Internet Usage與廣告點擊呈負相關;- 特征之間的線性相關性總體不高,適合用于機器學習模型。
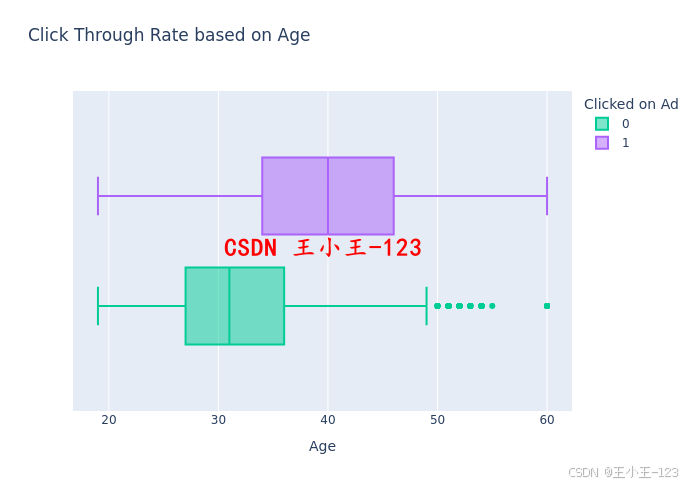
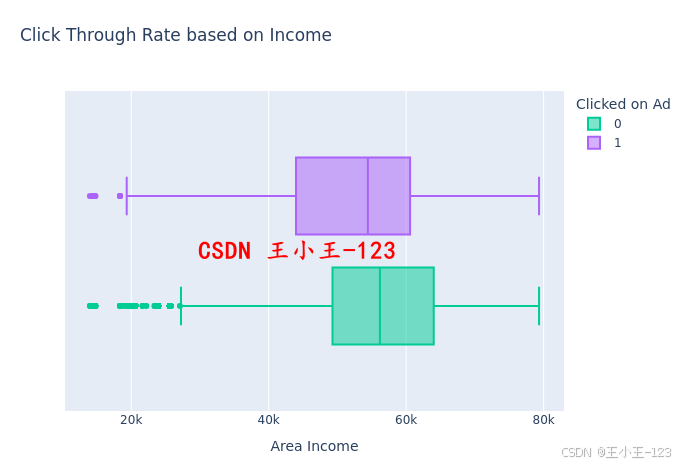
3.4 高級可視化分析
我們還使用 Plotly 繪制了多個交互式箱型圖,進一步觀察數值型特征和目標變量之間的關系:
- 花更多時間在網站上的用戶更可能點擊廣告;
- 年齡在40歲上下的用戶點擊廣告的概率高于年輕用戶;
- 高收入用戶點擊廣告的傾向略低。
四、特征工程與數據準備
4.1 特征提取與轉換
- 從
Timestamp中提取Hour、DayOfWeek和Month; - 將
Gender映射為 0(Male)和 1(Female); - 刪除冗余或無關列如
Ad Topic Line、City、Country和原始Timestamp。
4.2 數據集拆分與標準化
使用 train_test_split() 將數據按7:3拆分為訓練集和測試集。由于邏輯回歸模型對特征尺度敏感,我們使用 StandardScaler 對數值特征進行標準化處理并保存了標準化器以供后續使用。
五、模型訓練與評估
本項目采用以下四種主流分類模型進行建模:
- 邏輯回歸(Logistic Regression)
- 隨機森林(Random Forest)
- 梯度提升樹(Gradient Boosting)
- XGBoost 分類器
5.1 模型訓練與預測流程
對于邏輯回歸,我們使用標準化后的數據,其余模型使用原始特征值。訓練完成后,每個模型都輸出了預測類別和預測概率。
5.2 評估指標與可視化
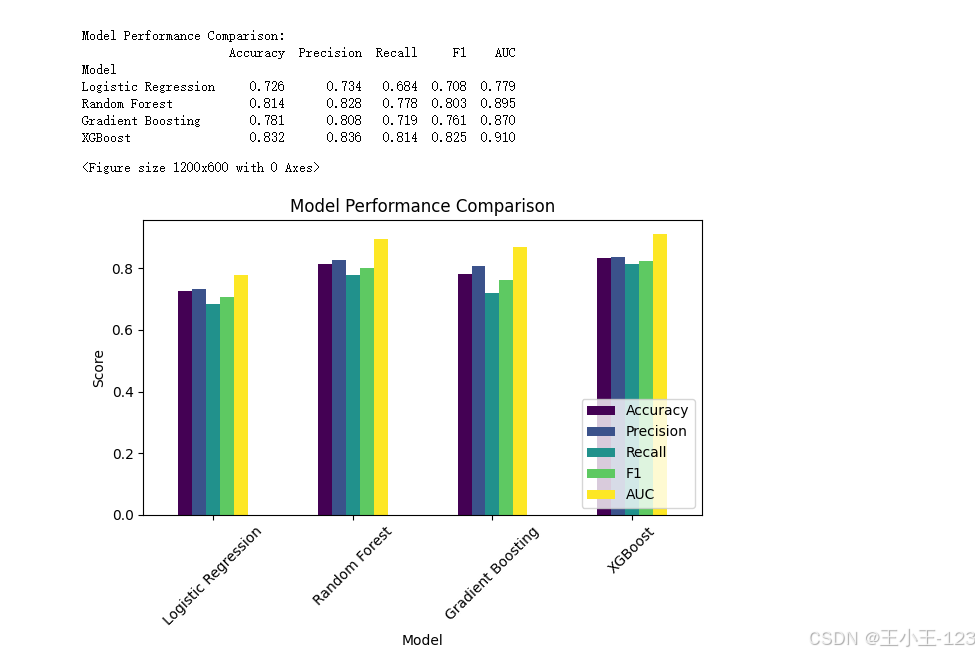
我們采用多種評價指標進行模型評估:
- Accuracy(準確率)
- Precision(精確率)
- Recall(召回率)
- F1 Score
- AUC(ROC曲線下面積)
此外,我們還繪制了:
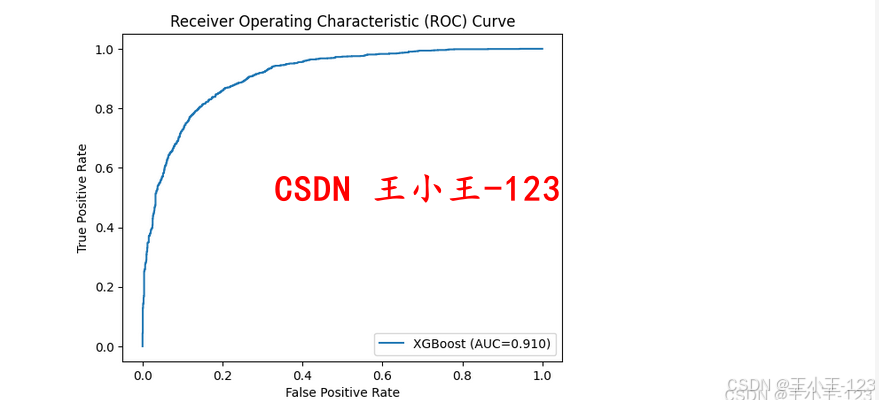
- ROC曲線用于比較分類性能;
- 混淆矩陣直觀展示各類預測的準確性;
- 柱狀圖對比各模型在5項指標上的得分。
5.3 模型保存
使用 joblib 將每個模型保存為 .pkl 文件,便于后續推理使用。
六、模型推理與實戰應用
我們通過以下步驟完成模型預測流程:
-
加載指定的模型(如 Logistic Regression)和標準化器;
-
構建輸入樣本,例如:
{'Daily Time Spent on Site': [60.0],'Age': [35],'Area Income': [60000],'Daily Internet Usage': [200.0],'Gender': [1],'Hour': [14],'DayOfWeek': [2],'Month': [4] } -
對數據進行標準化(如使用邏輯回歸);
-
進行預測并輸出類別與點擊概率。
例如某個預測結果為:
- 預測類別:1(點擊廣告)
- 預測概率:0.85
說明該用戶點擊廣告的可能性為85%。
七、總結與展望
7.1 項目成果總結
- 構建了從數據探索到模型推理的完整機器學習流程;
- 成功訓練并評估了四個分類模型;
- 選出了表現最佳的模型(如XGBoost在AUC上表現最優);
- 實現了可復用的模型預測接口。
7.2 項目亮點
- 使用多種可視化手段深入理解特征與目標之間的關系;
- 采用交叉驗證和多指標綜合評估模型效果;
- 完善的數據預處理和特征工程流程提高了模型魯棒性;
- 提供了模型保存與加載接口,具備實際應用潛力。
7.3 后續優化方向
- 可引入更多行為數據或用戶畫像提升模型表現;
- 使用深度學習方法(如多層感知機)進一步優化;
- 實現線上API接口進行實時廣告點擊預測;
- 增加模型調參流程(如GridSearchCV)提升精度。
廣告點擊預測問題本質上是一個典型的二分類任務,具備數據清晰、目標明確、應用場景廣泛的特征。通過本項目,不僅提升了我們對數據建模全過程的理解,也為未來在數字廣告、精準營銷等領域的實戰落地打下了堅實的基礎。

每文一語
要有自己的生活
)

)
_組件與Vue的內置關系(原型鏈))





)



后端)



)
)
