note
- Kimi K2 的預訓練階段使用 MuonClip 優化器實現萬億參數模型的穩定高效訓練,在人類高質量數據成為瓶頸的背景下,有效提高 Token 利用效率。MuonClip Optimizer優化器,解決隨著scaling up時的不穩定性。
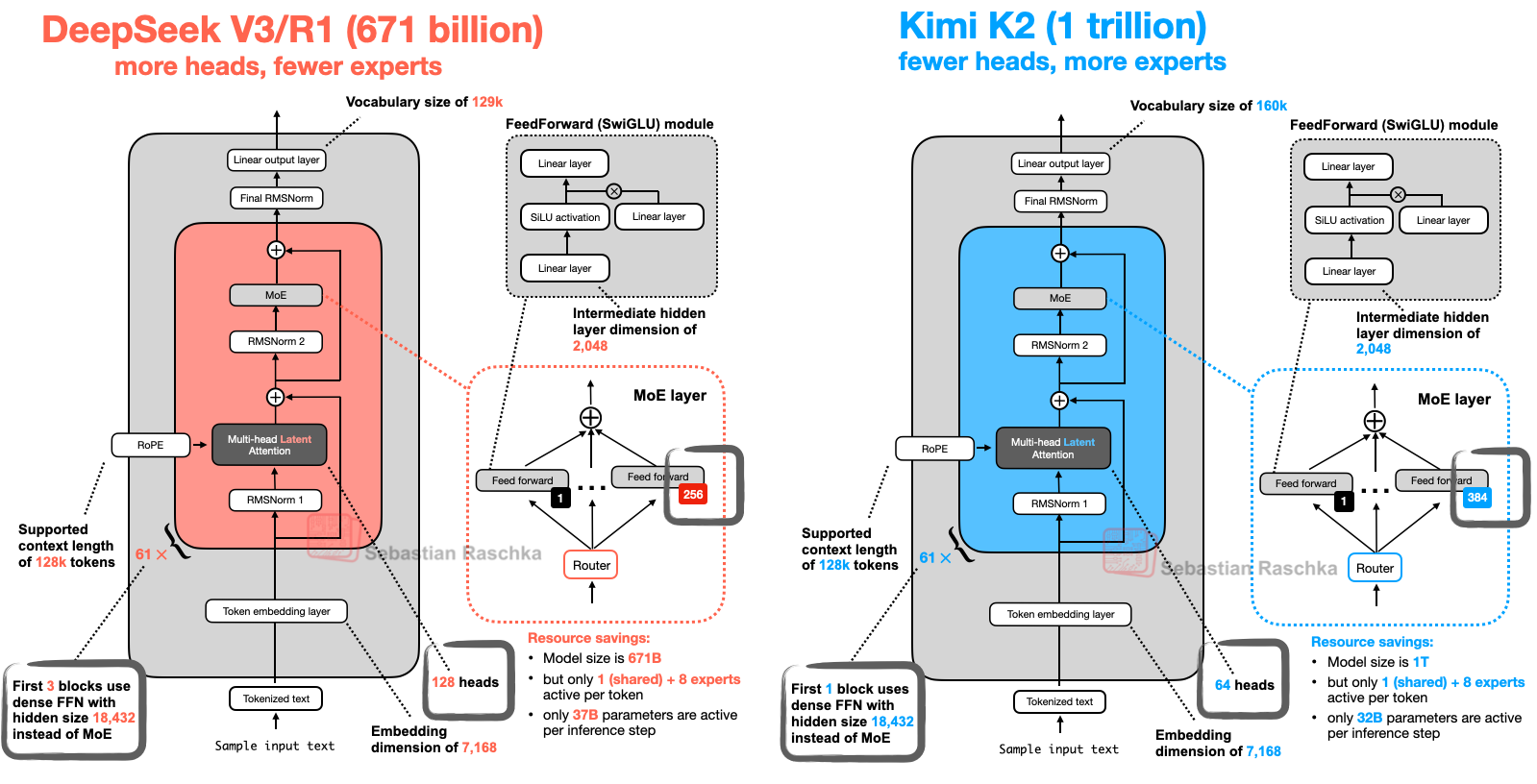
- Kimi-K2 與 DeepSeek-R1 架構對比,相比較下 Kimi-k2 增加了專家數量,減少了注意力頭的數量。這么設計的好處是,專家數量多無疑知識多,能記住更多東西,在知識廣度上表現很好。而減少注意力頭則能顯著減少顯存開銷,另外過多的注意力頭有時會學習到冗余或過于相似的注意力模式。通過減少頭的數量,模型可能被迫讓每個頭學習到更獨特、更關鍵的特征,這可能有助于防止過擬合,提升模型的泛化能力。
- Kimi K2 是一款具備更強代碼能力、更擅長通用 Agent 任務的 MoE 架構基礎模型,總參數 1T,激活參數 32B。
- Kimi K2 增強的智能體能力主要來源于兩個重要方面——大規模智能體數據合成 和 通用強化學習。
文章目錄
- note
- 一、Kimi-K2模型
- 1、Kimi-K2模型效果
- 2、Kimi-K2模型架構
- 3、MuonClip 優化器:
- 4、智能體能力(Agentic Capabilities)
- 5、 通用強化學習
- 二、其他模型架構比較
- Reference
一、Kimi-K2模型
大模型開源進展,kimi-k2量化版本發布,Unsloth 量化的 Kimi-K2 放出了,包括從 1.8bit 的 UD_IQ1 到 UD-Q5_K_XL等版本:https://github.com/unslothai/llama.cpp,
量化模型地址:https://huggingface.co/unsloth/Kimi-K2-Instruct-GGUF/tree/main
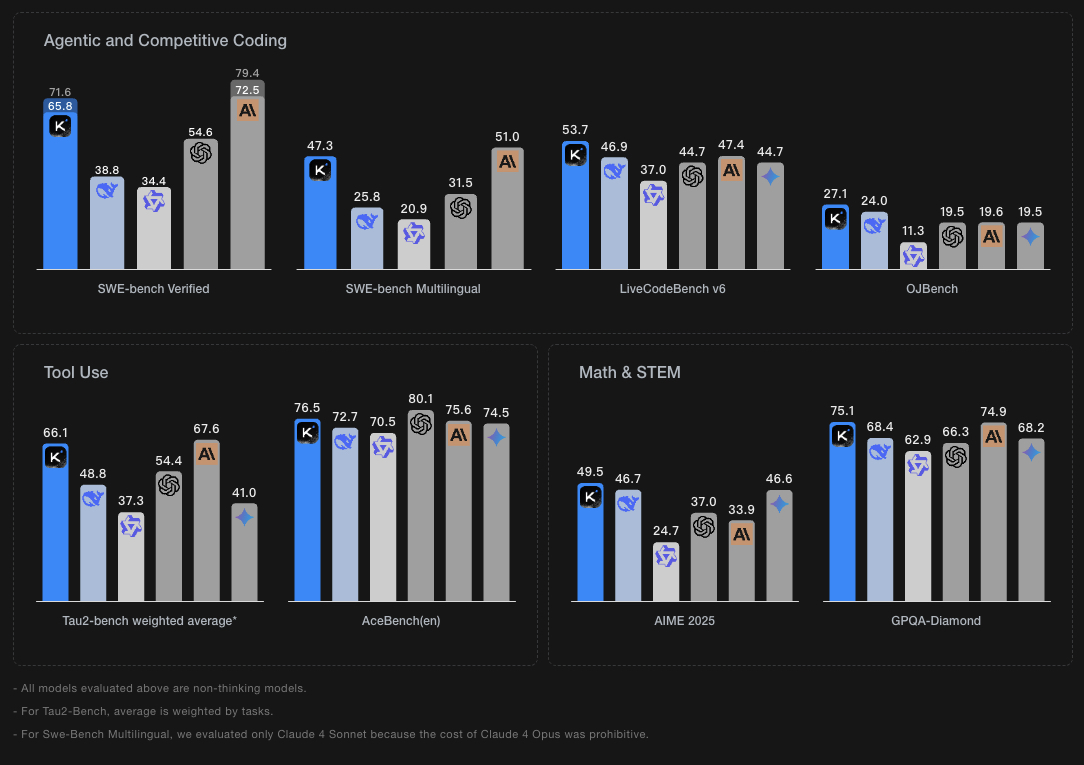
1、Kimi-K2模型效果
2、Kimi-K2模型架構
- Kimi-K2 與 DeepSeek-R1 架構對比,相比較下 Kimi-k2 增加了專家數量,減少了注意力頭的數量。這么設計的好處是,專家數量多無疑知識多,能記住更多東西,在知識廣度上表現很好。而減少注意力頭則能顯著減少顯存開銷,另外過多的注意力頭有時會學習到冗余或過于相似的注意力模式。通過減少頭的數量,模型可能被迫讓每個頭學習到更獨特、更關鍵的特征,這可能有助于防止過擬合,提升模型的泛化能力。
- Kimi K2 是一款具備更強代碼能力、更擅長通用 Agent 任務的 MoE 架構基礎模型,總參數 1T,激活參數 32B。Kimi K2 的預訓練階段使用 MuonClip 優化器實現萬億參數模型的穩定高效訓練,在人類高質量數據成為瓶頸的背景下,有效提高 Token 利用效率
3、MuonClip 優化器:
(1)之前的工作 Moonlight 已經證明,Muon 優化器在 LLM 訓練中顯著優于廣泛使用的 AdamW 優化器。Kimi K2 的設計目標是在 Moonlight 的基礎上進一步擴展模型規模,其架構類似于 DeepSeek-V3。基于擴展定律(scaling law)的分析,我們減少了注意力頭(head)數量以提升長上下文效率,并提高了混合專家(MoE)的稀疏性以增強 token 效率。在模型擴展過程中,我們遇到了一個持續性的挑戰:由于注意力 logits 爆炸導致的訓練不穩定問題。在我們的實驗中,這一問題在使用 Muon 優化器時比使用 AdamW 更為頻繁。現有的解決方案,如 logits 軟限制(logit soft-capping)和查詢-鍵歸一化(query-key normalization),被證明效果有限。為了解決這一問題,我們提出了 MuonClip 優化器,在 Muon 的基礎上引入了我們設計的 qk-clip 技術。具體來說,qk-clip 通過在 Muon 更新之后直接對查詢(query)和鍵(key)投影的權重矩陣進行重新縮放,從而從源頭上控制注意力 logits 的規模,達到穩定訓練的目的。
(2)MuonClip 能有效防止 logit 爆炸,同時保持下游任務的性能。在實際應用中,Kimi K2 使用 MuonClip 在 15.5T token 的數據上完成了預訓練,整個訓練過程未出現任何訓練尖峰(training spike),證明了 MuonClip 是一種適用于穩定、大規模 LLM 訓練的魯棒性解決方案。

具體細節可以看蘇神博客:QK-Clip:讓Muon在Scaleup之路上更進一步
4、智能體能力(Agentic Capabilities)
面向工具使用學習的大規模智能體數據合成: 為了教會模型復雜的工具使用能力,我們開發了一套受 ACEBench 啟發的綜合性數據生成流程,能夠大規模模擬現實世界中的工具使用場景。我們的方法系統性地演化出包含數百個領域、數千種工具(包括真實 MCP(Model Context Protocol)工具和合成工具)的環境,并生成擁有不同工具集的數百個智能體。
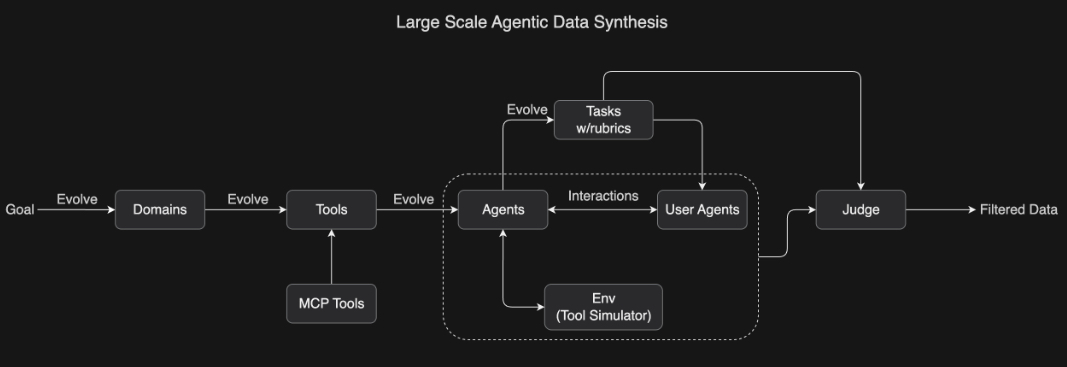
所有任務都基于評分標準(rubric-based)設計,從而實現一致的評估。智能體與模擬環境及用戶代理進行交互,構建出真實的多輪工具使用場景。隨后,一個大語言模型作為“評審員”根據任務評分標準評估模擬結果,并篩選出高質量的訓練數據。這一可擴展的數據生成流程能夠生成多樣化且高質量的數據,為大規模拒絕采樣(rejection sampling)和強化學習奠定了基礎。
5、 通用強化學習
關鍵挑戰在于如何將強化學習(RL)應用于具有可驗證獎勵(verifiable rewards)和不可驗證獎勵(non-verifiable rewards)的任務。典型的可驗證任務包括數學問題求解和競賽編程,而撰寫研究報告通常被視為不可驗證任務。
我們的通用強化學習系統不僅限于可驗證獎勵,還引入了一種自我評判機制(self-judging mechanism),其中模型自身充當評判者(critic),為不可驗證任務提供可擴展的、基于評分標準(rubric-based)的反饋。
同時,我們使用在策略(on-policy) rollout 技術處理具有可驗證獎勵的任務,并利用這些結果持續更新評判者,使其不斷提升對最新策略的評估準確性。這種方法可以被看作是利用可驗證獎勵來改進對不可驗證獎勵的估計。
二、其他模型架構比較
翻譯:從 DeepSeek-V3 到 Kimi K2:八種現代大語言模型架構設計
原文:https://magazine.sebastianraschka.com/p/the-big-llm-architecture-comparison
Reference
[1] https://moonshotai.github.io/Kimi-K2/
[2] https://github.com/MoonshotAI/Kimi-K2
[3] 關于kimi-k2的一個回顧帖子,里面提到的一些細節信息可看看:1)模型 Agent 能力的開發還在早期,有不少數據在預訓練階段是缺失的(比如那些難以言語描述的經驗/體驗),下一代預訓練模型仍然大有可為,也就是數據合成。2)關于“寫前端”的初衷,關乎產品邏輯。可看看:https://bigeagle.me/2025/07/kimi-k2/,此外,對于一些技術點,可看其中關于技術部分,技術架構等的選擇,差異性問題,可看看,https://www.zhihu.com/question/1927140506573435010/answer/1927892108636849910
[4] Kimi K2 發布并開源,擅長代碼與 Agentic 任務
[5] 從 DeepSeek-V3 到 Kimi K2:八種現代大語言模型架構設計
英文原版博客:https://sebastianraschka.com/blog/2025/the-big-llm-architecture-comparison.html
_組件與Vue的內置關系(原型鏈))





)



后端)



)
)



