目錄
一、機器學習概念
1.1基本概念
1.2 主要類型
1.2.1?監督學習(Supervised Learning)
(1)基本介紹
(2)任務目標
(3)常見算法
(4)應用場景
1.2.2?無監督學習(Unsupervised Learning)
(1)基本概念
(2)應用任務
(3)常見算法
(4)應用場景
1.2.3?強化學習(Reinforcement Learning)
(1)基本概念
(2)經典方法
(3)應用場景
1.2.4?擴展類型
(1)半監督學習
(2)自監督學習
二、關于sklearn機器學習庫
2.1 基本介紹
2.1.1 簡單介紹
2.1.2 優點介紹
2.1.3 不足
2.2 主要模塊
2.3 流程概述
2.3.1 獲取數據階段(Data Acquisition)
(1)sklearn玩具數據集
(2)sklearn現實世界數據集
(3)sklearn加載玩具數據集
2.3.2 數據預處理階段(Data Preprocessing)
(1)MinMaxScaler 歸一化
(2)normalize歸一化
(3)StandardScaler 標準化
(4)相關注意補充
2.3.3?特征工程階段(Feature Engineering)
(1)特征選擇(Feature Selection)
(2)特征降維(Dimensionality Reduction)
2.3.4?模型構建階段(Modeling / Training)
2.3.5?模型評估階段(Evaluation)
(1)對于分類
(2)對于回歸
2.3.6?模型優化階段(Tuning)
(1)超參數調優(Hyperparameter Tuning)
(2)管道 (Pipeline)
(3)交叉驗證(Cross Validation)
2.3.7 部署與應用階段(deployment)
(1)模型保存與加載
(2)構建 API 接口(常用 Flask)
(3)打包發布的常見方式
三、文末總結
一、機器學習概念
1.1基本概念
機器學習(Machine Learning) 是人工智能的一個分支,主要研究讓計算機從數據中自動學習規律,并根據學習到的規律進行預測或決策。簡言之,它是“用數據訓練模型,再用模型處理任務”。
機器學習的核心思想是讓計算機通過數據 “自主學習” 規律,而非依賴人工編寫的固定規則。傳統編程是 “輸入規則→輸出結果”,而機器學習是 “輸入數據和結果→輸出規則”,再用學到的規則預測新數據。
1.2 主要類型
1.2.1?監督學習(Supervised Learning)
(1)基本介紹
- 模型在訓練時使用帶有標簽的數據集,學習“輸入 ? 輸出”的映射關系。
- 目的是在給定新輸入時預測對應的輸出。
(2)任務目標
-
分類:輸出是離散的類別標簽
-
回歸:輸出是連續的數值
(3)常見算法
- 分類算法:KNN算法,決策樹,支持向量機SVM,樸素貝葉斯
- 回歸算法:線性回歸,Lasso回歸,支持向量回歸 SVR,決策樹回歸
(4)應用場景
郵件分類,氣溫預測,圖像識別,人臉識別等
1.2.2?無監督學習(Unsupervised Learning)
(1)基本概念
- 訓練數據沒有標簽,算法通過分析數據的結構、自主發現隱藏模式或規律。
(2)應用任務
-
聚類:將數據自動分組
-
降維:壓縮特征維度,保持信息
(3)常見算法
- 聚類算法:K-Means,DBSCAN,層次聚類
- 降維算法:主成分分析(PCA),t-SNE(非線性降維),自編碼器(Autoencoder)
(4)應用場景
用戶分群(電商客戶畫像),異常檢測(信用卡欺詐),數據可視化
1.2.3?強化學習(Reinforcement Learning)
(1)基本概念
- 智能體(Agent)在環境中不斷試錯,通過“獎賞-懲罰”機制學習如何采取最優策略以最大化長期回報。
- 關鍵詞:狀態(State),動作(Action),獎勵(Reward),策略(Policy)
(2)經典方法
-
Q-learning(離線強化學習)
-
深度強化學習(Deep Q Network, DDPG, PPO)
(3)應用場景
游戲 AI(下棋、打 Atari),自動駕駛,機器人控制,股票交易策略優化等
1.2.4?擴展類型
(1)半監督學習
- 半監督學習(Semi-Supervised):結合少量有標簽數據 + 大量無標簽數據
- 應用場景:醫學影像(標簽難獲得)
(2)自監督學習
- 自行構造偽標簽從數據中學習表示
- 應用場景:應用于自然語言處理、圖像識別;如:BERT、SimCLR、GPT 等深度學習模型的預訓練階段
二、關于sklearn機器學習庫
2.1 基本介紹
2.1.1 簡單介紹
scikit-learn(簡稱sklearn)是 Python 中最流行的機器學習庫之一,其對初學者友好、功能完整、工程可用,是學習與應用機器學習的常用工具。我們現在就從sklearn開始學習。
2.1.2 優點介紹
| 優點 | 說明 |
|---|---|
| 豐富的算法庫 | 包含常用的分類、回歸、聚類、降維等算法(如 KNN、SVM、決策樹、隨機森林、KMeans、PCA) |
| 模塊化設計 | 拆分為預處理、建模、調參、評估等步驟,接口統一 |
| 一致的 API 設計 | 所有模型都支持 .fit()、.predict()、.score() 等方法,學習成本低 |
| 集成交叉驗證與調參工具 | 提供 GridSearchCV、cross_val_score 等方法簡化模型選擇 |
| 數據預處理與特征工程工具 | 如歸一化(Scaler)、特征選擇(SelectKBest)、降維(PCA)等 |
| 文檔豐富,社區活躍 | 有詳細文檔和大量教程,便于學習與查錯 |
| 兼容 NumPy / Pandas | 可與主流數據分析庫無縫銜接 |
2.1.3 不足
- 不適合大數據量分布式訓練(推薦用 PyTorch、TensorFlow、XGBoost 等工具搭配)
2.2 主要模塊
| 模塊 | 功能 |
|---|---|
sklearn.datasets | 提供常用數據集,如 load_iris()、load_digits() 等 |
sklearn.model_selection | 數據劃分、交叉驗證、網格搜索 |
sklearn.preprocessing | 數據預處理(標準化、歸一化、編碼等) |
sklearn.feature_selection | 特征選擇工具 |
sklearn.decomposition | 降維算法,如 PCA |
sklearn.neighbors | KNN 相關算法 |
sklearn.tree | 決策樹、隨機森林 |
sklearn.linear_model | 線性回歸、邏輯回歸等 |
sklearn.svm | 支持向量機 |
sklearn.metrics | 模型評估指標,如準確率、混淆矩陣等 |
2.3 流程概述
本文將以基本講解與代碼示例相結合的方式為讀者介紹,這里先簡單介紹一下各個階段:
2.3.1 獲取數據階段(Data Acquisition)
目標:獲取結構化的數據,形成特征矩陣 X 和標簽 y
(1)sklearn玩具數據集
- 數據量小,數據在sklearn庫的本地,只要安裝了sklearn,不用上網就可以獲取
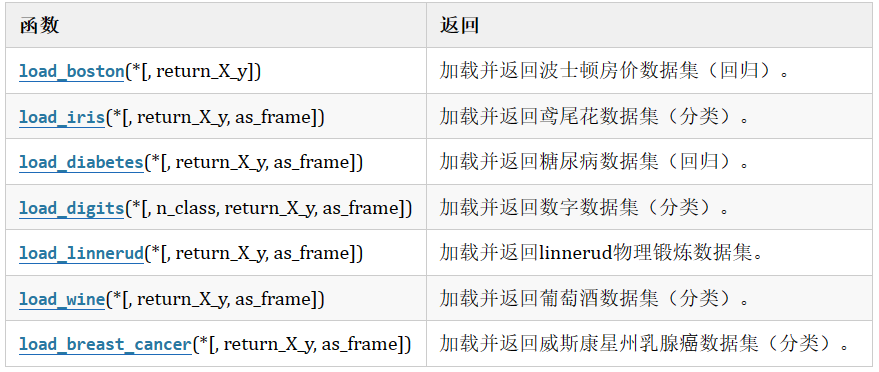
(2)sklearn現實世界數據集
- 數據量大,數據只能通過網絡獲取

(3)sklearn加載玩具數據集
1、以鳶尾花數據集為例:
from sklearn.datasets import load_iris
iris = load_iris()#鳶尾花數據
2、特征:
- 花萼長 sepal length
- 花萼寬sepal width
- 花瓣長 petal length
- 花瓣寬 petal width
3、分類:
- 0-Setosa山鳶尾
- 1-versicolor變色鳶尾
- 2-Virginica維吉尼亞鳶尾
4、相關代碼介紹:
print(iris.data) #得到特征
print(iris.feature_names) #特征描述
print(iris.target) #目標形狀
print(iris.target_names) #目標描述
print(iris.filename) #iris.csv 保存后的文件名
print(iris.DESCR) #數據集的描述2.3.2 數據預處理階段(Data Preprocessing)
目標:清洗數據,轉化為算法能接受的形式
(1)數據清洗(Data Cleaning)
使用 Pandas清洗數據:
- 去除重復數據:數據集中的重復記錄會影響模型的學習,可能導致過擬合。
- 處理異常值:例如,數值過大或過小的異常數據,這些值通常并不代表真實世界的情況。
- 數據類型轉換:確保每一列的數據類型正確,如數值型變量不應是文本類型。
(2)數據集劃分(Data Splitting)
使用 train_test_split 劃分數據:
-
訓練集:用于訓練模型,讓模型學習數據中的規律。
-
驗證集:用于調整模型的超參數,避免過擬合。
-
測試集:用于評估最終模型的性能。
(3)缺失值處理(Handling Missing Values)
- 刪除缺失值:對于缺失值較少的情況,可以直接刪除。
- 填充缺失值:使用均值、中位數、眾數或者通過模型預測來填充缺失值。
- 插補法:使用預測模型或插值方法填充缺失值。
(4)數據編碼(Encoding Categorical Variables)
許多機器學習算法無法直接處理文本數據(如分類變量),需要將其轉換為數值型數據。
- 標簽編碼(Label Encoding):將每個類別映射為一個唯一的數字,適用于有序類別。
- 獨熱編碼(One-Hot Encoding):將每個類別轉換為二進制列,適用于無序類別。
2.3.3?特征工程階段(Feature Engineering)
目的:構造/選擇/提取對模型有用的特征
(1)特征選擇(Feature Selection)
進行特征提取,比如字典特征提取,文本特征提取
- 過濾法(Filter):
SelectKBest,f_classif,選擇與目標變量最相關的 K 個特征 - 包裹法(Wrapper):RFE(遞歸特征消除)
- 嵌入法(Embedded):使用模型選擇特征,如 Lasso、樹模型
(2)特征轉換(Feature Transformation)
目的:對現有特征進行轉化,使其更適合用于訓練機器學習模型,或者更易于理解。
- 對數變換(Log Transformation):當數據呈現高度偏態分布時,使用對數變換來使其更接近正態分布。
- 多項式特征(Polynomial Features):生成現有特征的多項式特征,擴展特征空間,適用于非線性模型。
- 交互特征(Interaction Features):通過將特征之間的交互(乘積、比值)作為新的特征添加。
(3)特征縮放(Feature Scaling)
目的:調整特征的數值范圍,使其標準化或歸一化,避免某些特征在模型訓練中占主導地位。
- 歸一化(Normalization):將特征縮放到固定范圍(通常是 [0, 1]),適用于一些要求特征在同一尺度上的算法,如神經網絡。
- 標準化(Standardization):將特征轉換為均值為 0,標準差為 1 的分布,適用于大多數機器學習算法,尤其是基于距離的算法(如 KNN、SVM)
(4)特征構造(Feature Creation)
目的:基于現有的原始特征,創造新的、更具代表性的特征,提供給模型學習更多的模式。
(5)特征降維(Dimensionality Reduction)
目的:減少特征的數量,同時盡量保留原數據的信息,有助于減少計算復雜度和過擬合。
- 主成分分析 PCA:
sklearn.decomposition.PCA:將數據從高維空間映射到低維空間,保留盡可能多的方差信息。 - 線性判別分析 LDA(帶標簽):一種有監督的降維方法,適用于分類任務,最大化類間差異,最小化類內差異。
- t-SNE(可視化用):一種常用于高維數據降維的算法,特別是在數據可視化中,它可以將高維數據映射到二維或三維空間。
2.3.4?模型構建階段(Modeling / Training)
目標:使用算法對數據建模,尋找規律
經過上述的獲取數據、數據處理、特征工程后,就可以交給預估器進行機器學習,流程和常用API如下:
1.實例化預估器(估計器)對象(estimator), 預估器對象很多,都是estimator的子類
?? ?(1)用于分類的預估器
?? ??? ?sklearn.neighbors.KNeighborsClassifier k-近鄰
?? ??? ?sklearn.naive_bayes.MultinomialNB 貝葉斯
?? ??? ?sklearn.linear_model.LogisticRegressioon 邏輯回歸
?? ??? ?sklearn.tree.DecisionTreeClassifier 決策樹
?? ??? ?sklearn.ensemble.RandomForestClassifier 隨機森林
?? ?(2)用于回歸的預估器
?? ??? ?sklearn.linear_model.LinearRegression線性回歸
?? ??? ?sklearn.linear_model.Ridge嶺回歸
?? ?(3)用于無監督學習的預估器
?? ??? ?sklearn.cluster.KMeans 聚類
2.進行訓練,訓練結束后生成模型
?? ?estimator.fit(x_train, y_train)
3.模型評估
?? ?(1)方式1,直接對比
?? ??? ?y_predict = estimator.predict(x_test)
?? ??? ?y_test == y_predict
? ?? ?(2)方式2, 計算準確率
? ?? ??? ?accuracy = estimator.score(x_test, y_test)
4.使用模型(預測)
y_predict = estimator.predict(x_true)
2.3.5?模型評估階段(Evaluation)
目標:驗證模型的預測能力
(1)對于分類
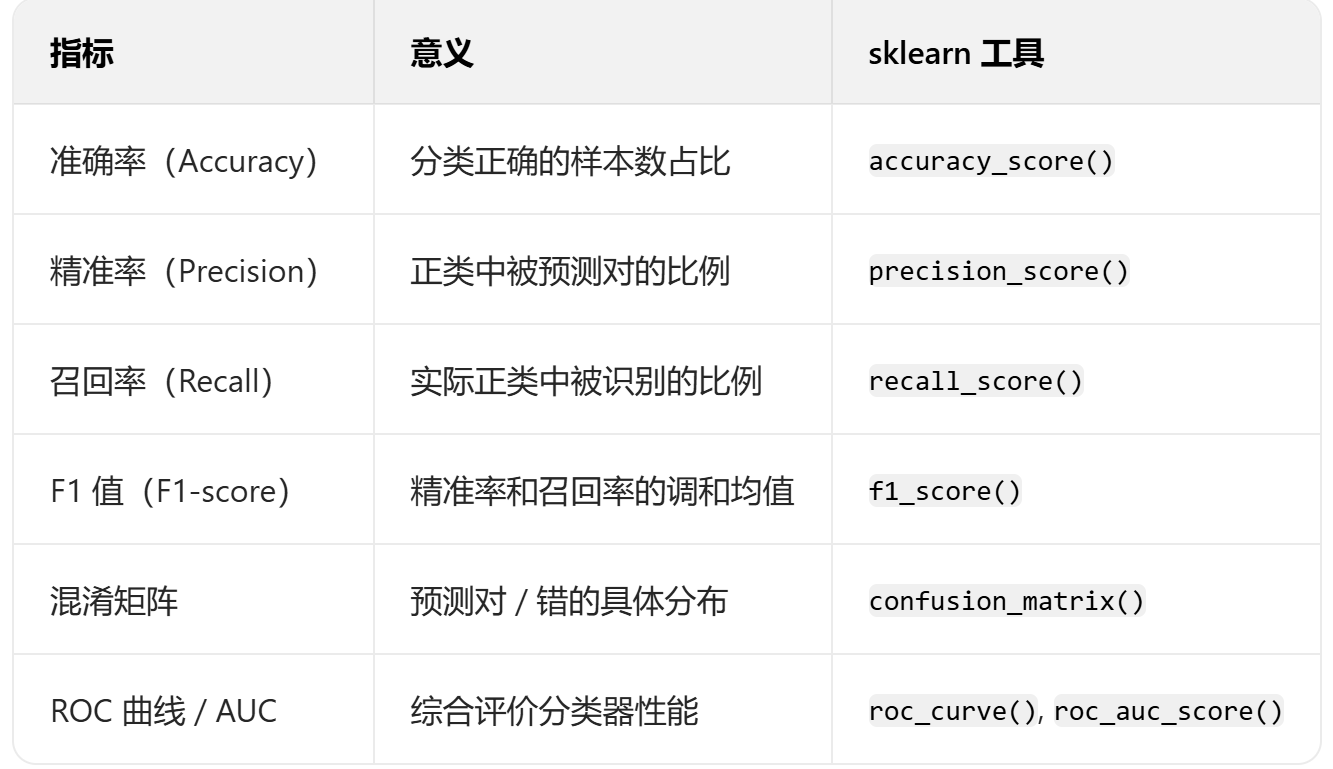
(2)對于回歸
| 指標 | 意義 | sklearn 工具 |
|---|---|---|
| 均方誤差(MSE) | 誤差平方平均 | mean_squared_error() |
| 平均絕對誤差(MAE) | 誤差絕對值平均 | mean_absolute_error() |
| 決定系數 R2 | 模型擬合程度 | r2_score() |
2.3.6?模型優化階段(Tuning)
目的:進一步提升模型性能,提高泛化能力,避免模型在某一特定訓練集上的過擬合或欠擬合
(1)超參數調優(Hyperparameter Tuning)
超參數(Hyperparameter)?是在模型訓練之前手動設置的參數,用于控制模型的結構、訓練過程或優化策略,其值無法通過訓練數據自動學習得到,需要通過人工調試、網格搜索、隨機搜索等方式確定。超參數是模型設計的核心,直接影響模型的性能。
1、方法:
- Grid Search(網格搜索):枚舉所有參數組合
- Randomized Search(隨機搜索):從參數分布中隨機選擇組合
- 貝葉斯優化等高級方法(用第三方庫如
optuna)
2、工具:
GridSearchCVRandomizedSearchCV
3、示例代碼:
這里以KNN算法作一個示例:在KNN算法中,k是一個可以人為設置的參數,所以就是一個超參數。使用網格搜索能自動的幫助我們找到最好的超參數值。
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_irisx,y = load_iris(return_X_y=True)knn = KNeighborsClassifier(n_neighbors=5)model = GridSearchCV(knn, param_grid={"n_neighbors": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]}, cv=5)model.fit(x, y)print("參數:", model.best_params_)
print("分數:", model.best_score_)
print("最佳K:",model.best_index_)
print("模型:", model.best_estimator_)
# print("結果:", model.cv_results_)# 模型model即可進行預測
model.predict(x)(2)管道 (Pipeline)
將多個步驟(預處理、特征選擇、模型)串聯起來自動執行,避免數據泄露。
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifierpipe = Pipeline([('scaler', StandardScaler()),('clf', RandomForestClassifier())
])
pipe.fit(X_train, y_train)
(3)交叉驗證(Cross Validation)
- 交叉驗證是一種評估模型泛化能力的核心方法,其核心目標是解決 “如何用有限數據更可靠地判斷模型是否能在新數據上表現良好” 的問題。
-
保留交叉驗證(HoldOut Cross-validation )
-
k 折交叉驗證(k-fold Cross-Validation)
-
分層 k 折交叉驗證(Stratified k-fold)
-
留一交叉驗證(Leave-One-Out CV, LOOCV)
-
時間序列交叉驗證(Time Series CV)
2.3.7 部署與應用階段(deployment)
目標:將訓練好的模型部署到生產環境中,比如放到 Web 頁面、API 接口中使用。
(1)模型保存與加載
- 保存模型:
import joblib# 保存模型到指定路徑
joblib.dump(model, "../src/modle/KNN.pkl")
# 保存轉換器(可選)
joblib.dump(transfer, "../src/modle/transfer.pkl")
- 加載模型:
import joblibmodel = joblib.load("../src/modle/KNN.pkl")
transfer = joblib.load("../src/modle/transfer.pkl")(2)構建 API 接口(常用 Flask)
簡單舉個例子:
from flask import Flask, request, jsonify
import joblibapp = Flask(__name__)
model = joblib.load('my_model.pkl')@app.route('/predict', methods=['POST'])
def predict():data = request.get_json()features = [data['feature1'], data['feature2']]result = model.predict([features])return jsonify({'prediction': int(result[0])})# 啟動服務:flask run
(3)打包發布的常見方式
| 部署方式 | 說明 |
|---|---|
| Flask / FastAPI | 構建 RESTful API,適合原型與小項目 |
| Web前端(React/Vue) | 調用 API 接口進行預測 |
| Docker 容器化 | 封裝成鏡像部署在任意服務器 |
| 云部署(阿里云、AWS、GCP) | 在云端創建可訪問服務 |
| 使用 Streamlit | 快速搭建交互式 Web 應用展示模型效果 |
三、文末總結
????????本篇文章的學習路線和標準流程的設計,旨在幫助初學者快速建立起一個知識架構,全面地理解機器學習項目的每個環節,并掌握從數據到部署的完整技術棧。每個階段都對應了機器學習的核心技能和思維方式,進而培養獨立解決實際問題的能力。從流程入手,逐個突破每個環節的核心技能,再通過完整項目串聯,是掌握機器學習的高效路徑。
? ? ? ? 在學習機器學習的過程中,需要注意幾點核心原則:首先是理論與實踐結合,在學習過程中我們會不斷接觸到高等數學的知識(線性代數、概率論等),要能夠將數學基礎與模型原理結合起來理解和學習,再通過具體項目進行實踐;其次是以業務為導向,所有步驟都需圍繞 “解決實際問題”,歸根到底我們是要面向應用、服務于實際生產的,在之后文章中也會著重體現這一點;再有就是要具備迭代思維,機器學習是 “數據→模型→評估→優化” 的循環,沒有 “完美模型”,只有 “更適合當前場景的模型”。暫時想到這么多。




)







)

)




