待補充
已知表頭元素為c的單鏈表在內存中的存儲狀態如下表所示
| 地址 | 元素 | 鏈接地址 |
| 1000H | a | 1010H |
| 1004H | b | 100CH |
| 1008H | c | 1000H |
| 100CH | d | NULL |
| 1010H | e | 1004H |
| 1014H |
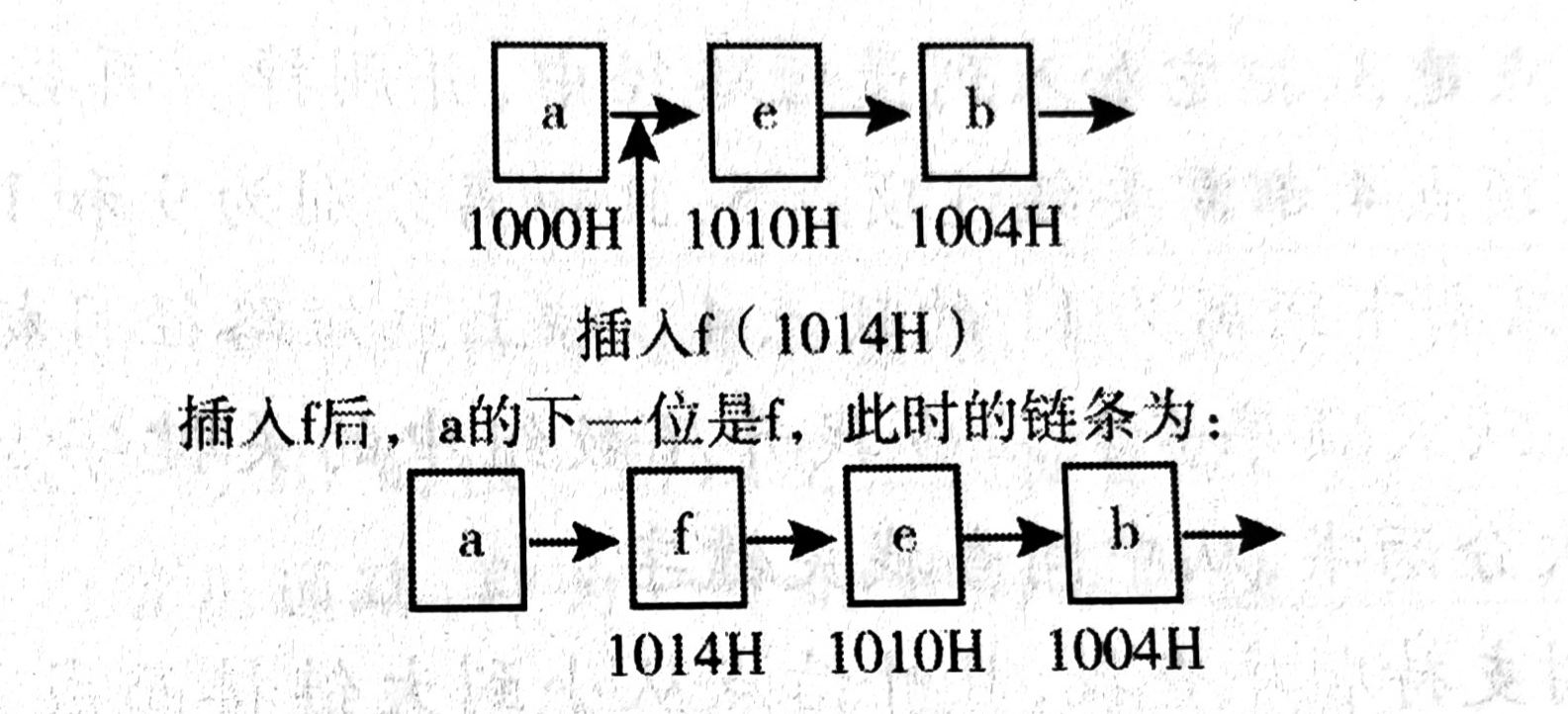
現將f存放于1014H處并插入到單鏈表中,若f在邏輯上位于a和e之間,則a, e, f的“鏈接地址”依次是( )。
A. 1010H, 1014H, 1004H
B. 1010H, 1004H, 1014H
C. 1014H, 1010H, 1004H
D. 1014H, 1004H, 1010H
D
l鏈接地址,即每一個元素的下一個地址
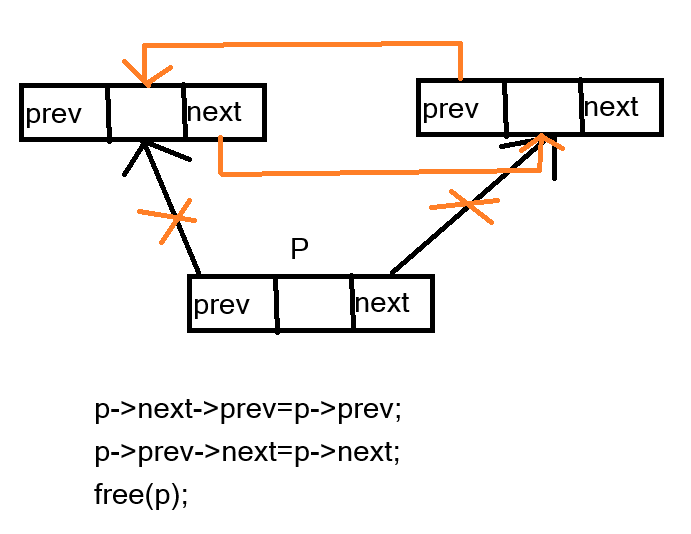
2.已知一個帶有表頭結點的雙向循環鏈表L,結點結構為prev|data|next,prev和next分別是指向其直接前驅和直接后繼結點的指針。現要刪除指針p所指的結點,正確的語句序列是( )。
A. p->next->prev = p->prev; p->prev->next = p->prev; free(p);
B. p->next->prev = p->next; p->prev->next = p->next; free(p);
C. p->next->prev = p->next; p-> prev->next = p->prev; free(p);
D. p->next->prev = p->prev; p->prev->next = p->next; free(p);
D
3.設有下圖所示的火車車軌,入口到出口之間有?n?條軌道,列車的行進方向均為從左至右,列車可駛入任意一條軌道。現有編號為1~9的9列列車,駛入的次序依次是8, 4, 2, 5, 3, 9, 1, 6, 7。若期望駛出的次序依次為1~9,則?n?至少是( )
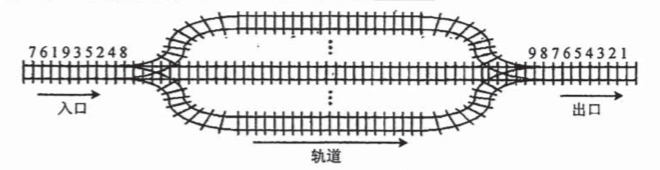
A. 2
B. 3
C. 4
D. 5
C
隊列
9 8? 7 6 5 4 3 2 1
4.有一個100階的三對角矩陣M?,其元素?mi,j(1≤i≤100,1≤j≤100)?按行優先依次壓縮存入下標從0開始的一維數組?N?中。元素?m30,30?在數組?N?中的下標是( )。
A. 86
B. 87
C. 88
D. 89
B
公式法 k=2i+j-3
a11? N=0=3*(1-1)
a22 N=3=3*(2-1)
a33 N=6=3*(3-1)
某元素前元素總個數=3*(元素所在的行數-1)
3*(30-1)=87
5.若森林F有15條邊、25 個結點,則F包含樹的個數是( )。
A. 8
B. 9
C. 10
D. 11
C
n個結點的樹有n-1條邊(每棵樹的結點數比邊數多1)
題中森林F中結點數比邊數多25-15=10個,即共有10棵樹?
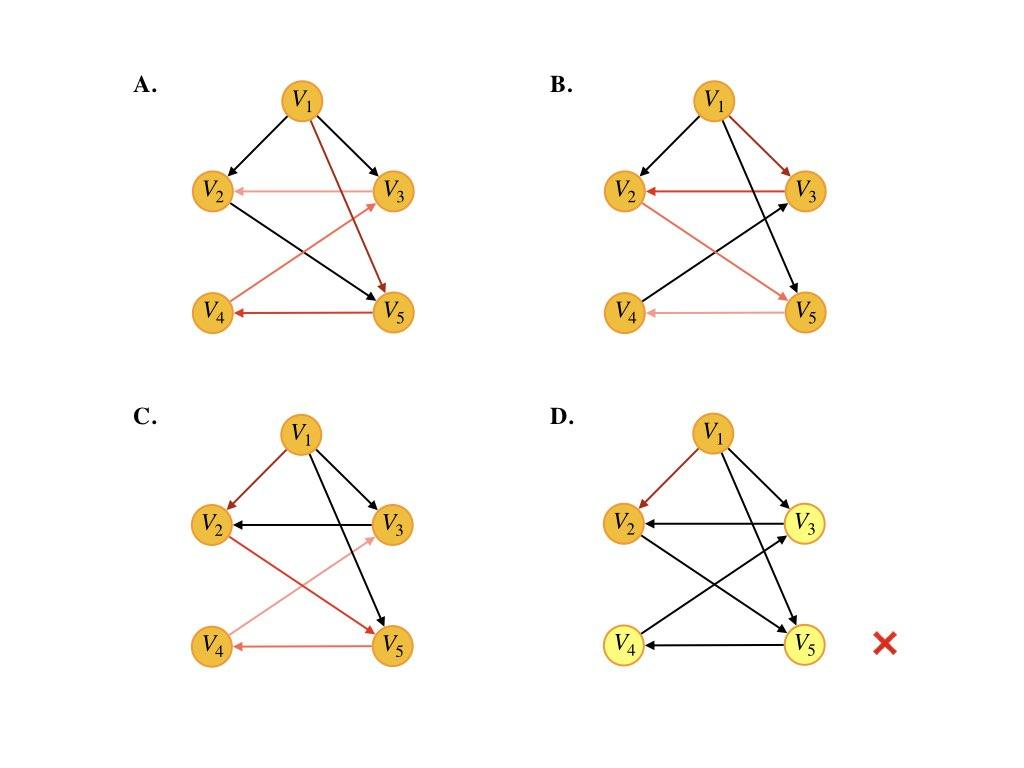
6.下列選項中,不是下圖深度優先搜索序列的是( )
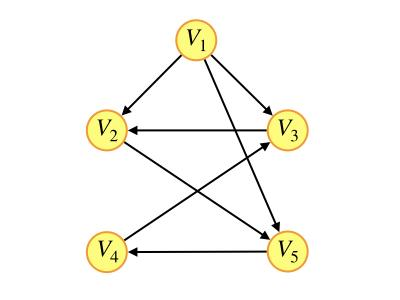
A.?V1,V5,V4,V3,V2
B.?V1,V3,V2,V5,V4
C.?V1,V2,V5,V4,V3
D.?V1,V2,V3,V4,V5
D
深度優先搜索,從V1開始,可以先訪問V2(V3或V5也可以),但V2到V3與圖中箭頭正好相反,無法訪問,D錯誤
深度優先搜索就是一個“一條路走到黑”的搜索策略,直到無路可走才開始回溯,找到前一個能夠繼續搜索的結點重復上述步驟
7.若將?n?個頂點?e?條弧的有向圖采用鄰接表存儲,則拓撲排序算法的時間復雜度是( )。
A.?O(n)
B.?O(n+e)
C.?O(n2)
D.?O(ne)
B
把整個鏈接表都遍歷一遍,遍歷n個頂點和邊,且n個頂點,一共e條邊,逐個遍歷一遍,時間復雜度為O(n+e)
撲排序需要輸出圖中所有頂點,也就是意味著必須要對圖進行遍歷,圖的遍歷最常用的就是深度優先搜索和廣度優先搜索。
- 深度優先搜索算法是一種自底向上 (bottom up)?的算法,即按照逆拓撲排序的順序遍歷圖。
- 廣度優先搜索算法是一種自頂向下 (top down)?的算法,即按照拓撲排序的順序遍歷圖。
而深度優先搜索和廣度優先搜索都是完全遍歷的具體實現,可以忽略算法實現細節,從整體入手
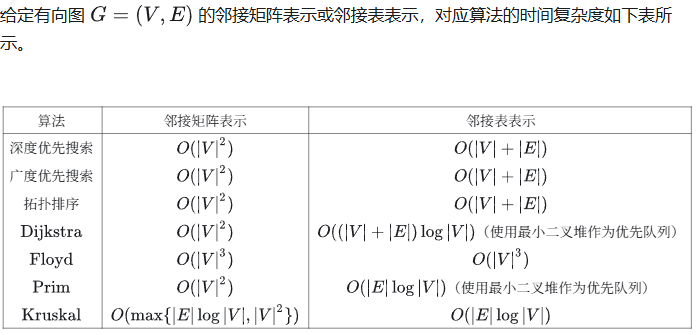
8.使用迪杰斯特拉(Djkstra)算法求下圖中從頂點?1?到其他各頂點的最短路徑,依次得到的各最短路徑的目標頂點是( )
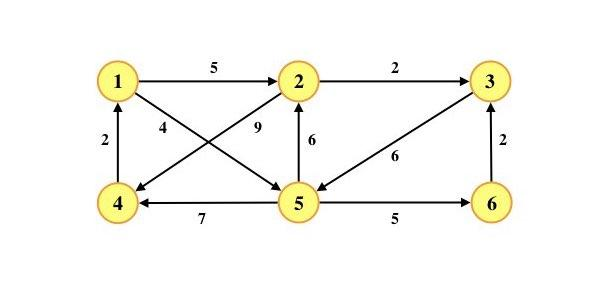
A. 5, 2, 3, 4, 6
B. 5, 2, 3, 6, 4
C. 5, 2, 4, 3, 6
D. 5, 2, 6, 3, 4
B
V1? ? ? ? V5? ? ? ? V2? ? ? ? V3? ? ? ? V6????????V4
1 2 3 4 5 6 S 0 {1} 0 5 11 4 9 {1,5} 0 5 11 4 9 {1,5,2} 0 5 7 11 4 9 {1,5,2,3} 0 5 7 11 4 9 {1,5,2,3,6} 0 5 7 11 4 9 {1,5,2,3,6,4}
9.在有?n(n>1000)?個元素的升序數組?A?中查找關鍵字?x?。查找算法的偽代碼如下所示。
k = 0;
while (k < n 且 A[k] < x) k = k + 3;
if (k < n 且 A[k] == x) 查找成功;
else if (k - 1 < n 且 A[k - 1] == x) 查找成功;
else if (k - 2 < n 且 A[k - 2] == x) 查找成功;
else 查找失敗;
本算法與折半查找算法相比,有可能具有更少比較次數的情形是( )。
A. 當?x?不在數組中
B. 當?x?接近數組開頭處
C. 當?x?接近數組結尾處
D. 當?x?位于數組中間位置
B
采用跳躍式順序查找法查找升序數組中的關鍵字x,x越靠前,比較次數越少
折半查找就是把數組每次分成兩半,從中間查找關鍵字
10.B+樹不同于B樹的特點之一是( )。
A. 能支持順序查找
B. 結點中含有關鍵字
C. 根結點至少有兩個分支
D. 所有葉結點都在同一層上
A
B+樹支持順序查找,且葉結點從小到大鏈接而成,B樹不能支持順序查找,只支持多路查找
B+樹和B樹的區別主要有兩點:
- B+樹的非葉結點不存儲關鍵字,只作為索引使用,而B樹的非葉結點存儲關鍵字,所以B+樹的所有葉結點中包含了全部的關鍵字信息,但B樹不一定
- B+樹上的葉結點存儲關鍵字以及相應記錄的指針,葉結點中將關鍵字按大小順序排列,并且相鄰葉結點按大小順序互相鏈接起來。所以B+樹支持兩種查找運算:一種是從最小關鍵字開始的順序查找,另一種是從根結點開始的多路查找。但B樹只支持從根節點開始的多路查找
11.對 10 TB 的數據文件進行排序,應使用的方法是( )。
A. 希爾排序
B. 堆排序
C. 快速排序
D. 歸并排序
D
希爾排序、堆排序、快速排序都是內部排序
由題可知是要對磁盤或外存里較大的數據進行排序,使用外部排序,外部排序通常使用歸并排序(將所有數據切分成多個歸并段,首先對每個歸并段進行內部排序得到較短的有序序列,然后將多個歸并段合并得到更長的有序序列,重復合并步驟最終可以得到完整的有序序列)

—— 變形技巧)

:前后臺環境搭建)




分析)


介紹)







