????????我們學習編程語言的時候,第一個程序就是打印一下 “hello world” ,對于大數據領域的第一個任務則是wordcount。那我們就開始我們的第一個spark任務吧!
下載spark
官方下載地址:Apache Download Mirrors?下載完畢以后,直接tar解壓即可。
本地啟動spark集群
環境只是為了讓我們能夠運行我們的程序,所以我們的任務是寫任務而不是搭建環境。搭建環境的部分,可能運維比我們更專業。
安裝官網我們啟動一個standalon模式 ,Spark Standalone Mode - Spark 4.0.0 Documentation。
啟動完以后master我們就可以在8080端口上看到我們的spark集群了。
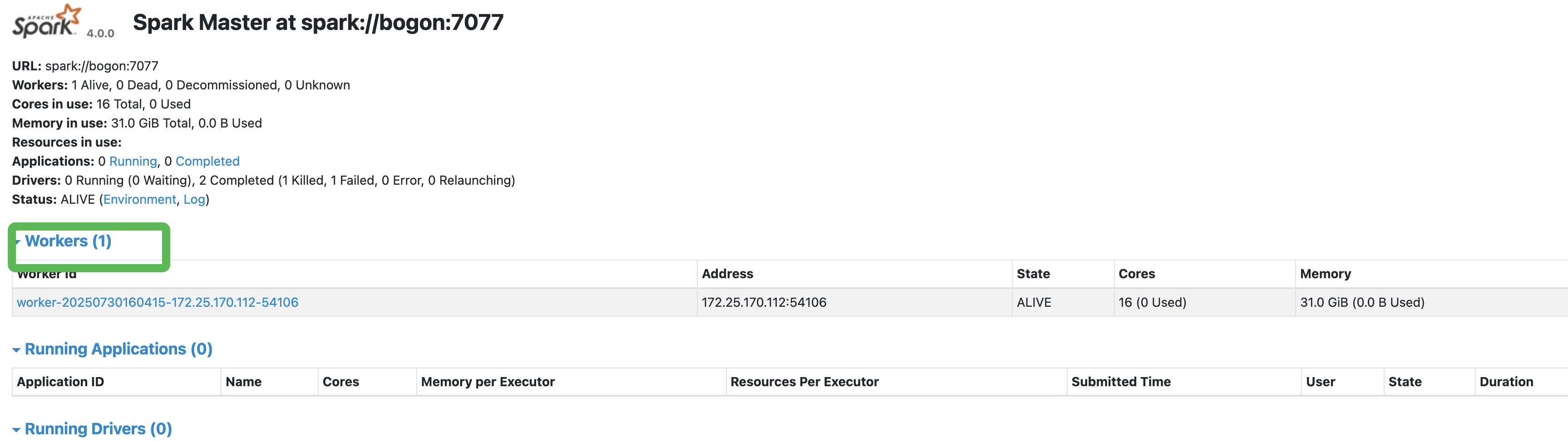
接著啟動一個worker,啟動的時候需要master的地址。我們本地啟動的,所以localhost就可以了。./sbin/start-worker.sh ?spark://bogon:7077? ,master的url可以從master 8080的界面看到,這個記得一定要寫正確,要不啟動worker的時候就有問題了。否則這個worker節點不現實worker個數的。
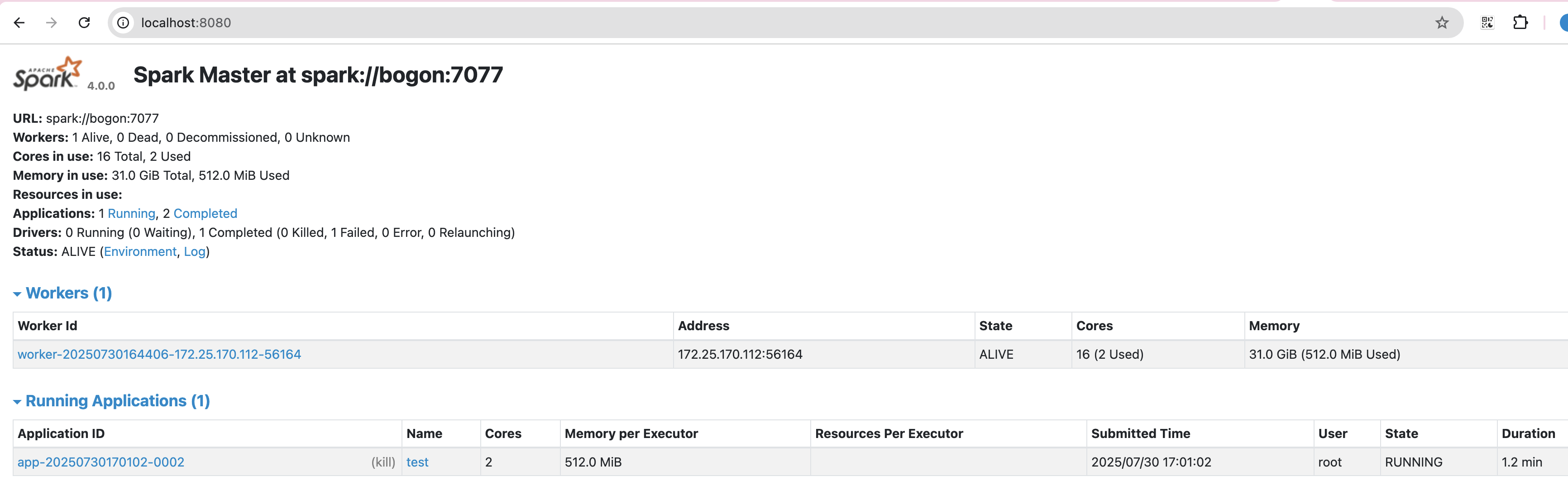
構建我們的jar程序
我們直接參考官網的代碼(注意:這是學習的方式方法,看到別人博客直接寫的入門代碼。其實官方是第一手資料)Spark Streaming - Spark 4.0.0 Documentation?
代碼
def main(args: Array[String]): Unit = {println("======== start ==========")val conf = new SparkConf().setAppName("test")val ssc = new StreamingContext(conf, Seconds(1))val source = ssc.socketTextStream("localhost", 9999)val words = source.flatMap(_.split(","))val paris = words.map(word => (word, 1))val wordCounts = paris.reduceByKey(_ + _)wordCounts.print()ssc.start()ssc.awaitTermination()}編譯打包jar,然后提交submit
./bin/spark-submit \--class demo.WordCount \--executor-memory 512M \--total-executor-cores 2 \--master spark://localhost:7077 \--deploy-mode client \--verbose \/path/spark-task-1.0-SNAPSHOT.jar Submitting Applications - Spark 4.0.0 Documentation
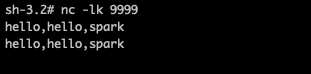
查看日志打印

總結
????????小結一下,其實看似很簡單的一個demo。過程也是遇到了很多的問題,1、是啟動 worker的時候需要制定master的url地址,這個需要從8080端口查看。2、發現自己的代碼無法提交到集群中,結果發現是代碼里面setMaster了,所以去掉。3、打包的時候提示找不到class,因為是maven構建的java程序。自己添加的scala包,所以需要打包的時候指定一下scala路徑,把下面的class打包進去。
? ? ? ? 多實踐才能發現問題,有時候只是知道了理論,看似懂了,其實離懂了還是差了一些。

介紹)











![[工具類] 網絡請求HttpUtils](http://pic.xiahunao.cn/[工具類] 網絡請求HttpUtils)
)
變換矩陣中的齊次坐標推導與幾何理解)



