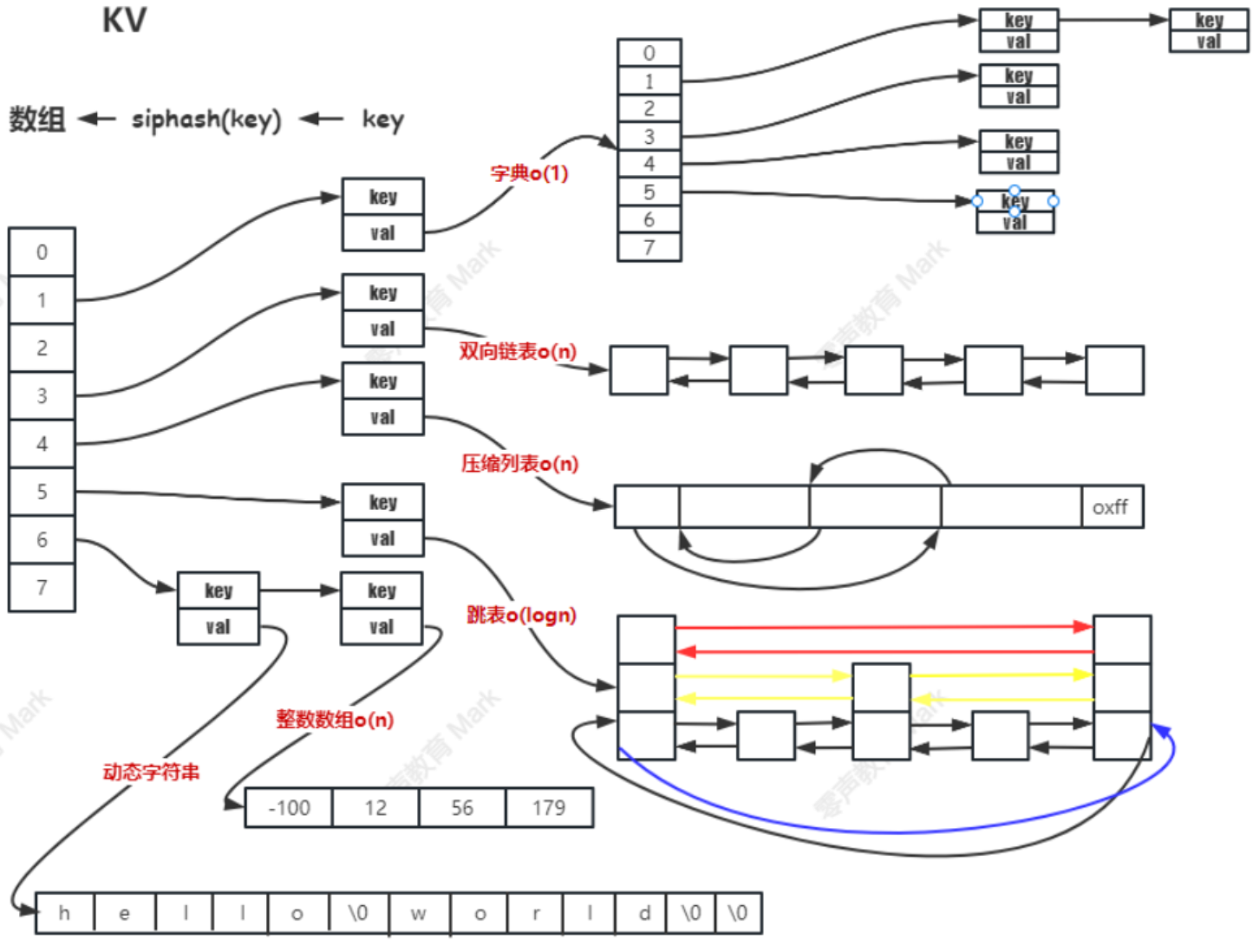
一、Redis 存儲結構
1.1 KV結構
-
Redis 本質上是一個 Key-Value(鍵值對,KV)數據庫,在它豐富多樣的數據結構底層,都基于一種統一的鍵值對存儲結構來進行數據的管理和操作
-
Redis 使用一個全局的哈希表來管理所有的鍵值對,這個哈希表就像是一個大字典,通過鍵(Key)能快速定位到對應的值(Value)。
-
從用戶視角看,用戶使用各種命令操作不同類型的數據結構(如 String、Hash、List 等),但從底層實現角度,它們都是以鍵值對形式存儲在這個哈希表中。
-
Redis的存儲分類的目的是,在數據量小的時候,追求存儲效率高;在數據量大的時候,追求運行速度快。
| 數據類型(Value 所屬類型) | 編碼方式 | 觸發條件 |
|---|---|---|
| string | int | 字符串長度 ≤ 20 且可轉換為整數(如 "123") |
embstr | 字符串長度 ≤ 44 | |
raw | 字符串長度 > 44 | |
| cpu 緩存行優化 | (補充邏輯,基于緩存行 64 字節設計,輔助提升訪問效率,非獨立編碼類型) | |
| list | quicklist | Redis 3.2+ 默認實現,是 ziplist + 雙向鏈表的混合結構(動態適配數據量) |
ziplist | 數據量小時被 quicklist 間接使用(緊湊存儲小列表) | |
| hash | ziplist | 節點數量 ≤ 512(hash-max-ziplist-entries)且字符串長度 ≤ 64(hash-max-ziplist-value) |
dict | 節點數量 > 512 或字符串長度 > 64 | |
| set | intset | 元素全為整數且數量 ≤ 512(set-max-intset-entries) |
dict | 元素含非整數或數量 > 512 | |
| zset | ziplist | 子節點數量 ≤ 128(zset-max-ziplist-entries)且字符串長度 ≤ 64(zset-max-ziplist-value) |
skiplist | 子節點數量 > 128 或字符串長度 > 64 |
1.2 字典(dict)
Redis 中的字典(dict) 是一種高效的鍵值對存儲結構,廣泛用于實現 Redis 核心的 KV 存儲(全局鍵值對)以及 Hash 類型在數據量較大時的底層存儲(當 Hash 節點數>512 或字符串長度>64 時)。其設計借鑒了哈希表的思想,通過鏈地址法處理沖突,并支持動態擴容(重哈希)以保證性能
字典數據結構組成
字典由三個核心結構體組成,層層嵌套實現哈希表的功能:
1. dictEntry哈希表節點
存儲單個鍵值對(key-value),next 指針用于連接哈希沖突的節點(形成鏈表)
typedef struct dictEntry {void *key; // 鍵(字符串類型)union { // 值(支持多種類型)void *val; // 指針類型(如復雜數據結構)uint64_t u64; // 無符號整數int64_t s64; // 有符號整數double d; // 浮點數} v;struct dictEntry *next; // 下一個節點指針(處理哈希沖突的鏈表)
} dictEntry;
2. dictht 哈希表
管理哈希表數組,table 是存放 dictEntry 指針的數組,sizemask 用于快速計算鍵的索引(替代取余運算)。
typedef struct dictht {dictEntry **table; // 哈希表數組(存儲dictEntry指針)unsigned long size; // 數組長度(必須是2的冪,如4、8、16...)unsigned long sizemask; // 掩碼,值為 size-1(用于計算數組索引)unsigned long used; // 已存儲的節點數量(key-value總數)
} dictht;
3. dict字典頂層結構
通過 ht[2] 支持漸進式重哈希(避免一次性擴容的性能波動),rehashidx 跟蹤重哈希進度。
typedef struct dict {dictType *type; // 字典類型(包含哈希函數、鍵值復制/釋放函數等)void *privdata; // 私有數據(供type中的函數使用)dictht ht[2]; // 兩個哈希表(ht[0]:當前使用;ht[1]:重哈希時使用)long rehashidx; // 重哈希索引(-1表示未進行重哈希;≥0表示當前遷移進度)int16_t pauserehash; // 重哈希暫停標記(>0表示暫停,避免遍歷期間干擾)
} dict;
哈希運算與索引映射
字典通過哈希函數將 key 映射到哈希表數組的索引,步驟如下:
-
計算哈希值:對 key(字符串)執行哈希函數(如
siphash),得到一個 64 位整數哈希值。- 特性:相同 key 必然得到相同哈希值(確定性);不同 key 可能得到相同哈希值(哈希沖突)。
-
映射到數組索引:利用
sizemask(size-1)對哈希值進行位運算(哈希值 & sizemask),得到數組索引。-
示例:若
size=4(2 的冪),則sizemask=3(二進制11)。哈希值5(二進制101)與3做 & 運算,結果為1(二進制01),即索引為 1。 -
優勢:位運算(&)比取余運算(%)效率更高,且當
size是 2 的冪時,哈希值 % size等價于哈希值 & sizemask。
-
哈希沖突的處理
由于哈希值范圍(64 位)遠大于哈希表數組長度(size),根據抽屜原理(n+1 個蘋果放入 n 個抽屜,至少一個抽屜有 2 個),必然存在不同 key 映射到同一索引的情況(哈希沖突)。
字典采用鏈地址法解決沖突:
- 每個
dictEntry節點通過next指針形成單向鏈表,同一索引的所有沖突節點串聯在鏈表中。 - 查找時:先通過索引定位到鏈表頭,再遍歷鏈表比較 key 以找到目標節點(時間復雜度:理想 O (1),沖突嚴重時 O (n))。
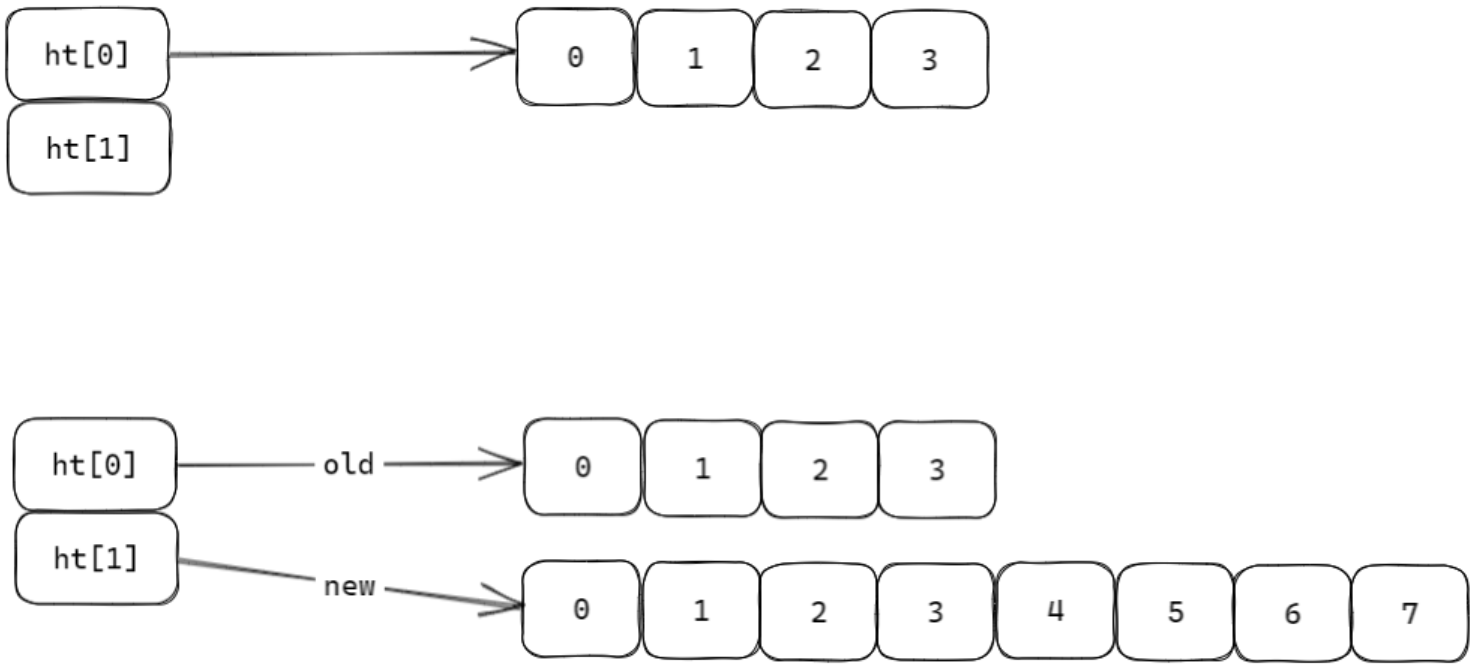
漸進式重哈希(擴容 / 縮容)
當哈希表的負載因子(used / size)過高(擴容)或過低(縮容)時,需要調整數組大小以優化性能:
- 擴容觸發:負載因子>1(默認),
size擴大為當前的 2 倍(仍為 2 的冪)。 - 縮容觸發:負載因子<0.1,
size縮小為大于used的最小 2 的冪。
為避免一次性遷移所有節點導致的性能阻塞,字典采用漸進式重哈希:
-
初始化:創建
ht[1]并設置新size(如擴容為ht[0].size * 2),rehashidx設為 0(開始重哈希)。 -
漸進式遷移:
- 每次對字典執行增刪改查時,順帶將
ht[0]中rehashidx索引的所有節點遷移到ht[1],并將rehashidx遞增 1。 - 遍歷操作(如
HGETALL)時,會暫停重哈希(pauserehash標記),避免遍歷期間節點遷移導致數據不一致。
- 每次對字典執行增刪改查時,順帶將
-
完成遷移:當
ht[0].used變為 0 時,釋放ht[0],將ht[1]賦值給ht[0],ht[1]重置為空,rehashidx設為 - 1(重哈希結束)。
scan
Redis 的 scan 命令是用于漸進式遍歷集合類數據(如鍵空間、哈希表、集合等)的命令,主要解決了 keys 命令因一次性全量遍歷導致服務器阻塞的問題
實現目標:
- 實現對 scan 開始時刻已存在的數據 進行遍歷,保證 不重復、不遺漏
- 不阻塞服務器,通過分批次、漸進式的方式遍歷,每次返回部分結果,避免一次性處理大量數據導致的性能波動。
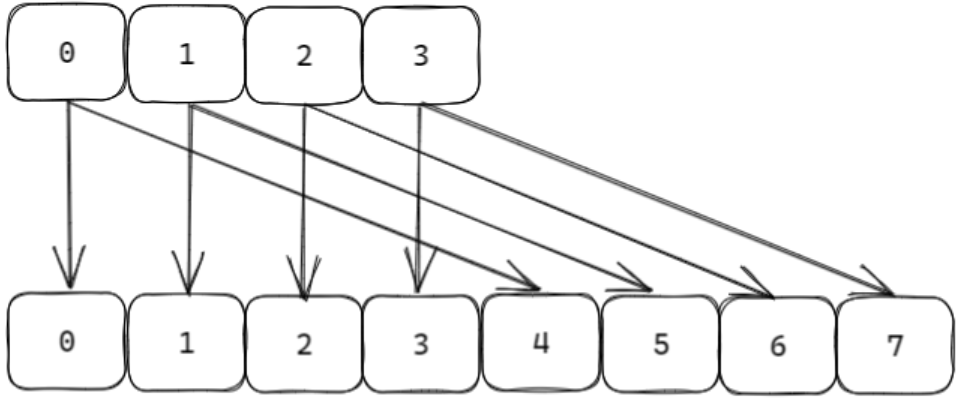
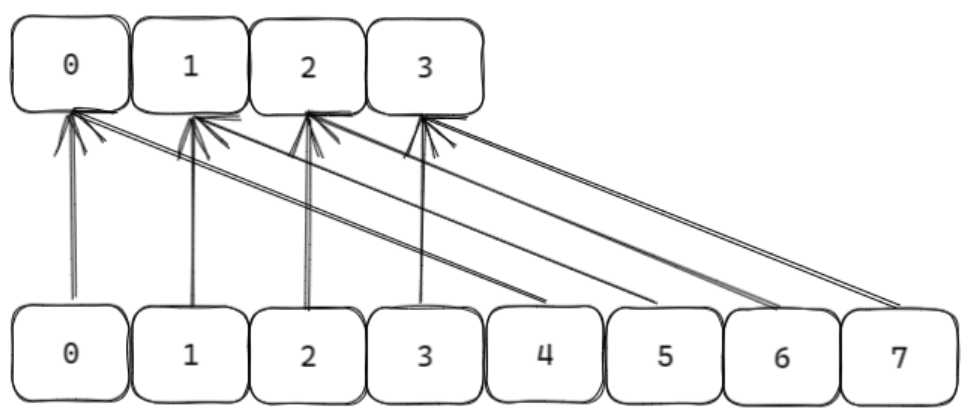
遍歷機制:
- 遍歷順序:采用 高位進位加法 的遍歷順序。這種方式的優勢是,在哈希表發生擴容 / 縮容(rehash)時,新舊哈希表的槽位在遍歷順序上是相鄰的,確保遍歷過程能適配哈希表結構的動態變化,維持遍歷的連續性。
- 游標機制:通過游標(cursor)記錄每次遍歷的位置。首次調用時游標為
0,每次返回部分元素和新游標,當游標為0時表示遍歷結束。

- Redis 的哈希表(如字典)會因數據量變化發生擴容或縮容(rehash),導致鍵的映射算法(槽位計算方式)改變。
- 借助 高位進位加法 的遍歷順序,即使 rehash 過程中映射關系變化,
scan仍能正確遍歷scan開始時已存在的數據,不會因 rehash 導致重復或遺漏。
1.3 Expire 機制
Redis 的 expire 機制用于管理設置了過期時間的鍵(key),通過兩種核心策略結合,在 “內存占用” 與 “性能消耗” 之間平衡,確保過期鍵能被及時清理
1. 惰性刪除(Lazy Expiration)
-
觸發時機:當執行任何涉及該 key 的命令(如
GET、SET等)時,Redis 會先檢查 key 是否過期。 -
執行邏輯:
- 若 key 已過期,立即刪除該 key,再執行后續命令;
- 若未過期,直接執行命令。
-
特點:
- 優勢:“按需刪除”,不占用額外 CPU 資源(僅在訪問時檢查);
- 劣勢:若過期 key 長期未被訪問,會占用內存(內存泄漏風險)。
-
適用范圍:僅支持對最外層 key 設置過期時間(如 Hash、List 等結構的內部字段無法單獨設置過期時間)。
-
相關命令:
expire key seconds:設置 key 的過期時間(秒);pexpire key milliseconds:設置 key 的過期時間(毫秒);ttl key:返回 key 剩余過期時間(秒,-1 表示永不過期,-2 表示已過期);pttl key:返回 key 剩余過期時間(毫秒)。
2. 定時刪除(Active Expiration)
為彌補惰性刪除的內存泄漏問題,Redis 同時采用定時刪除策略,主動清理部分過期 key。
-
觸發機制:由后臺定時器定期執行,每次檢查一定數量的過期 key。
-
核心配置與邏輯:
- 默認每次檢查 25 個 key(由
ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP定義); - 可通過
effort參數調整檢查強度(默認 1,最大 10),計算公式為:config_keys_per_loop = 20 + 20/4*effort(effort 越大,每次檢查的 key 越多); - 執行函數
activeExpireCycleTryExpire負責具體的過期檢查與刪除。
#define ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP 20 /* Keys for each DB loop. */ /*The default effort is 1, and the maximum configurable effort* is 10. */ config_keys_per_loop = ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP +ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP/4*effort, int activeExpireCycleTryExpire(redisDb *db, dictEntry *de, long long now); - 默認每次檢查 25 個 key(由
-
特點:
- 優勢:主動清理長期未訪問的過期 key,減少內存占用;
- 劣勢:若檢查過于頻繁,會消耗 CPU 資源(Redis 通過控制檢查頻率和數量避免性能波動)。
惰性刪除保證 “訪問時過期鍵必被清理”,避免無效數據干擾;定時刪除主動清理 “長期未訪問的過期鍵”,防止內存溢出。兩者結合,既保證了性能,又控制了內存占用
1.4 大Key
“大 Key” 指 Redis 中存儲的體積過大的對象(如包含數萬字段的 Hash、百萬元素的 ZSet 等),這類 key 會導致明顯的性能問題
1. 大 Key 的危害
- 擴容卡頓:大 Key 所在的哈希表或數據結構(如 Hash、ZSet)擴容時,需要一次性申請大量內存(如從 1MB 擴容到 2MB),可能導致 Redis 短暫阻塞;
- 刪除卡頓:刪除大 Key 時,Redis 需要一次性釋放大量內存,觸發內存回收機制,同樣會導致卡頓;
- 內存波動:大 Key 的創建 / 刪除會導致 Redis 內存使用 “大起大落”,容易觸發內存告警或 OOM(內存溢出)。
大Key 的檢測
通過 Redis 自帶的 redis-cli --bigkeys 命令檢測大 Key,該命令基于 SCAN 遍歷所有鍵,統計不同類型中體積最大的鍵。
redis-cli -h 127.0.0.1 --bigkeys -i 0.1
--bigkeys:開啟大 Key 檢測;-i 0.1:每執行 100 條SCAN命令后,暫停 0.1 秒,避免檢測過程阻塞 Redis 服務。
解決方案
- 拆分大 Key:將大 Hash 拆分為多個小 Hash,大 ZSet 按范圍拆分為多個小 ZSet;
- 避免批量操作:對大 Key 避免使用
HGETALL、ZRANGE 0 -1等全量查詢命令; - 異步刪除:Redis 4.0+ 支持
UNLINK命令(異步刪除),替代DEL,減少刪除時的卡頓。
1.5 跳表
Redis 中的跳表(Skiplist)是一種多層級有序鏈表結構,主要用于實現有序集合(ZSet),支持高效的范圍查詢(如 ZRANGE、ZREVRANGE)和排序操作。其設計兼顧了查詢性能與實現復雜度,通過 “空間換時間” 的思路,在保證平均時間復雜度接近平衡樹的同時,避免了復雜的節點分裂 / 重構操作
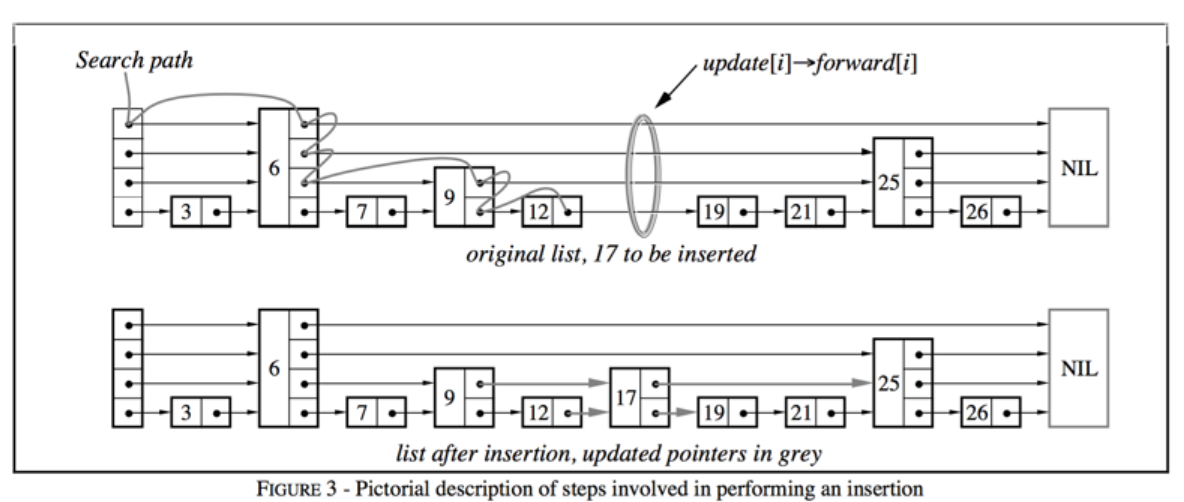
為什么使用跳表?
跳表的誕生是為了解決 “有序集合的高效查詢與修改” 問題:
-
有序數組通過二分查找可實現 O (logN) 查詢,但插入 / 刪除需移動元素(O (N) 復雜度);
-
平衡二叉樹(如 B+ 樹)可實現 O (logN) 操作,但節點分裂 / 合并邏輯復雜,不適合 Redis 對 “簡單高效” 的需求;
-
跳表通過多層級鏈表模擬 “跳躍式查詢”,兼顧查詢效率(接近 O (logN))和實現簡單性(插入 / 刪除無需復雜重構),成為 ZSet 的理想底層結構。
跳表時間復雜度分析
-
理想跳表的邏輯
理想情況下,跳表每間隔一個節點生成一個 “高層級節點”,模擬二叉樹結構(如第 1 層每 2 個節點有 1 個高層節點,第 2 層每 4 個節點有 1 個高層節點),此時查詢時間復雜度為 O(logN)。但這種結構在插入 / 刪除后難以維護(重構成本極高)。 -
概率化跳表(實際實現)
為避免重構,跳表采用概率化層級生成:- 每個新節點有 25%(Redis 中為
ZSKIPLIST_P=0.25)的概率增加 1 個層級,25%×25% 的概率增加 2 個層級,以此類推(最高層級有限制)。 - 當數據量足夠大(如 ≥128)時,概率化生成的跳表結構趨向于理想跳表,查詢、插入、刪除的平均時間復雜度仍為 O(logN),且無需復雜重構。
- 每個新節點有 25%(Redis 中為
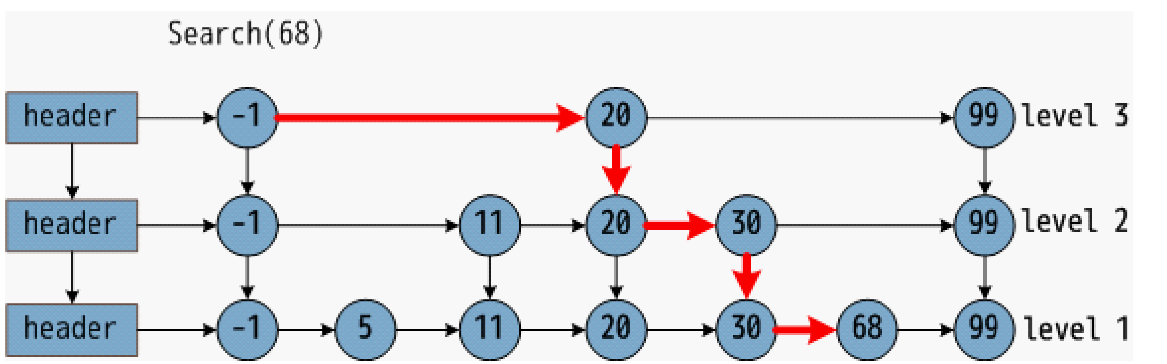
跳表的實現
- 最高層級:
ZSKIPLIST_MAXLEVEL=32(足夠支持 2^64 個元素),避免層級過高導致的內存浪費。 - 層級概率:
ZSKIPLIST_P=0.25(1/4),即每個節點晉升到下一層的概率為 25%,平衡層級數量與內存占用。
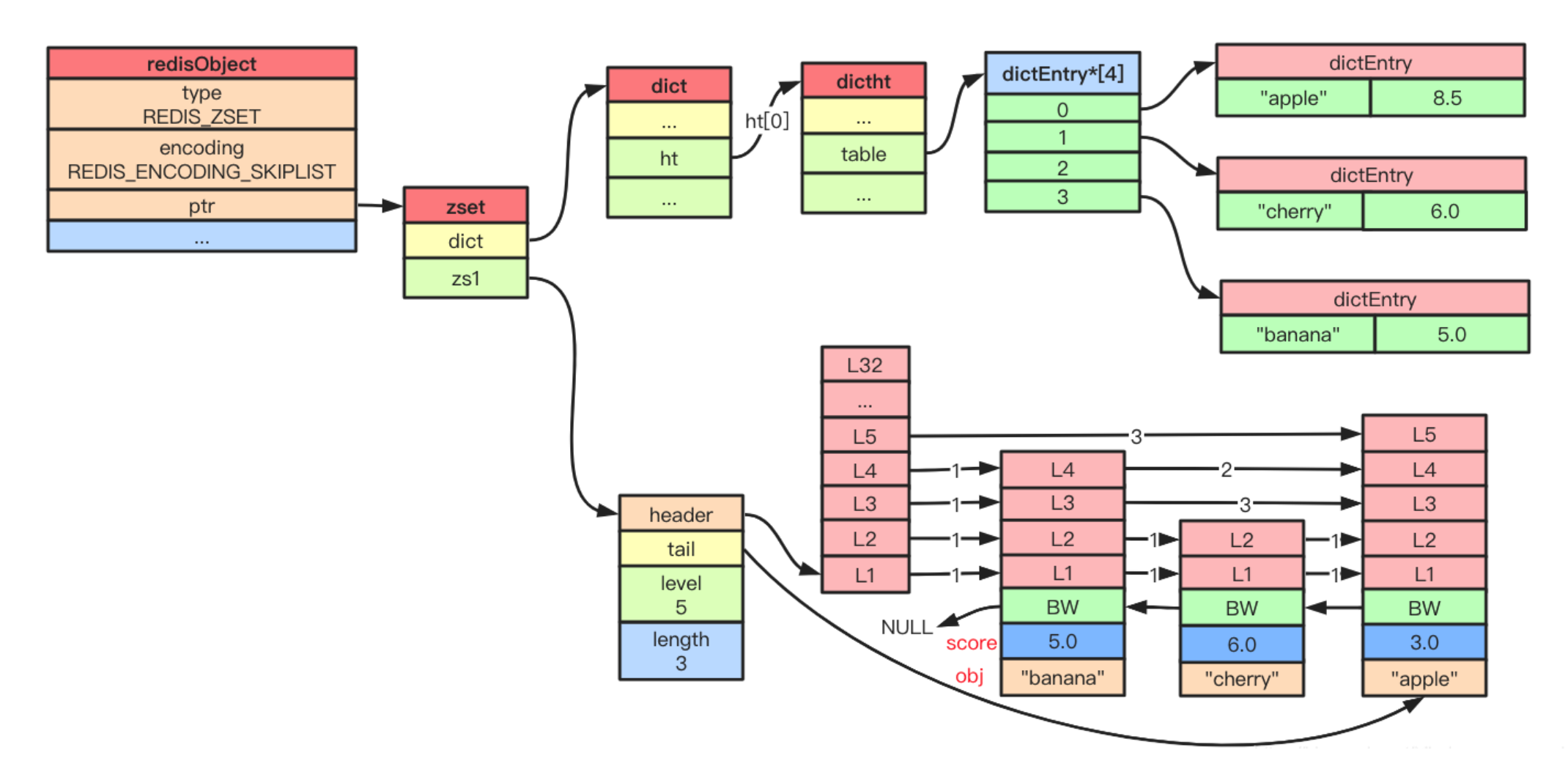
Redis 跳表通過 zskiplistNode(節點)和 zskiplist(跳表頂層結構)實現,配合 zset 結構體與字典(dict)協同工作
// 跳表節點
typedef struct zskiplistNode {sds ele; // 元素值(字符串)double score; // 排序分數(僅支持浮點數)struct zskiplistNode *backward; // 后退指針(用于反向遍歷)struct zskiplistLevel {struct zskiplistNode *forward; // 前進指針(當前層級的下一個節點)unsigned long span; // 跨度(當前節點到下一個節點的元素數量,用于計算排名 ZRANK)} level[]; // 動態層級數組(長度為節點實際層級)
} zskiplistNode;// 跳表頂層結構
typedef struct zskiplist {struct zskiplistNode *header, *tail; // 頭節點、尾節點unsigned long length; // 元素總數(對應 ZCARD 命令)int level; // 當前跳表的最高層級
} zskiplist;// ZSet 結構體(結合跳表與字典)
typedef struct zset {dict *dict; // 字典:key=元素值,value=分數(快速查詢元素分數)zskiplist *zsl; // 跳表:按分數排序,支持范圍查詢
} zset;
更多資料:https://github.com/0voice



)



)





)

)
day04--手寫數字識別項目實戰)
)

)