一、FlashAttention
1、Tile-Based計算
將q,k,v分塊為小塊,每次僅處理一小塊:
- 利用gpu的片上SRAM完成QK^T和softmax
- 避免中間結果寫入HBM
標準attention的計算算法如下:

標準attention實現大量中間結果需要頻繁訪問HBM,而HBM的訪問速度遠遠低于GPU的SRAM。因此FlashAttention通過“tile計算+顯存訪問優化”方案,減少了對HBM的依賴,提高了整體執行效率。
softmax計算公式如下:
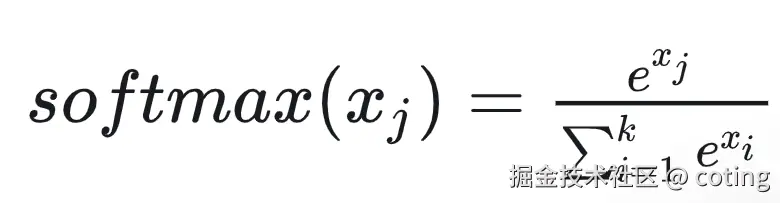
為了數值穩定性,FlashAttention采用Safe Softmax,對于向量x
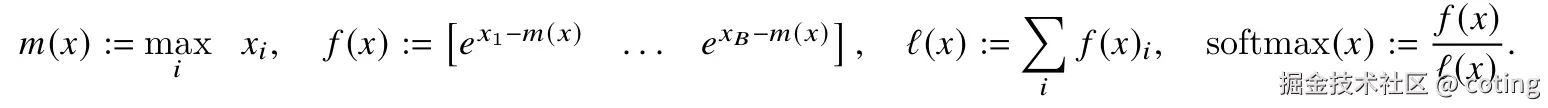
同理,對于向量x=[x1,x2],softmax可以分解計算:
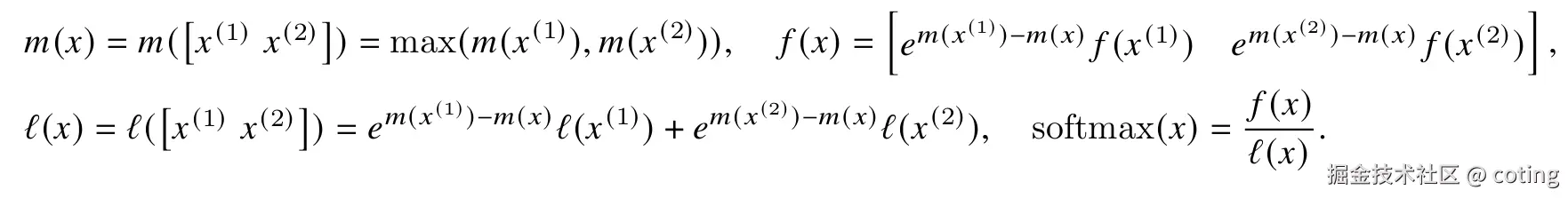
這就說明即使q,k,v被分成塊也可以計算softmax的。
2、Recomputation strategy
為了節省存儲中間的softmax權重,FlashAttention在需要時重新計算部分內容,避免保存完整矩陣。
標準attention的反向傳播算法如下,其中P代表softmax(QKTdk)softmax(\frac{QK^T}{\sqrt{d_k}})softmax(dk??QKT?),即注意力權重矩陣。
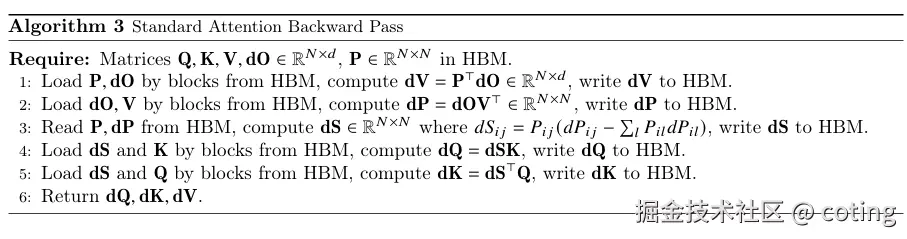
在標準attention的實現中,為了完成前向傳播和反向傳播,需要保存如下中間結果:
- QKTQK^TQKT
- softmax權重
- attention output(最終結果)
這些矩陣很大,尤其是在處理長序列時,顯存消耗會非常高。
FlashAttention為了降低顯存占用,采取了一種策略:
在前向傳播時不保留中間矩陣,而是到了反向傳播階段再把它們重新計算出來。
以softmax的attention score為例:
- 標準方法
QKTQK^TQKT -> softmax -> 換存在顯存中 ->用于乘v和反向傳播
- FlashAttention
QKTQK^TQKT -> softmax -> 直接用于乘V,不緩存
…
后面反向傳播要用到softmax->再計算一次QKTQK^TQKT和softmax
3、代碼
for i in range(0, N, block_size): #外層循環:按block_size步長遍歷所有token(處理query的分塊)q_block = q[:, i:i+block_size] #取出當前query塊[batch_size, block_size,dim]max_score = None #初始化當前query塊的最大注意力分數(用于數值穩定)row_sum_exp = None #初始化當前query塊的指數和(用于softmax分母)acc = torch.zeros_like(q_block) #初始化累積結果張量for j in range(0, N, block_size): #內層循環:遍歷所有k/v的分塊k_block = k[:, j:j+block_size]v_block = v[:, j:j+block_size]# 1.計算原始注意力分數scores = torch.bmm(q_block, k_block.transpose(1,2)) * scale #[batch, block_size, block_size]#bmm表示批量矩陣乘法,scale是縮放因子(通常為1/sqrt(dim))# 2.數值穩定處理(減去最大值后做指數計算)block_max = scores.max(dim=-1, keep_dims=True).values #當前塊每行的最大值 [batch, block_size, 1]scores = scores - block_maxexp_scores = socres.exp() #計算指數[batch, block_size, block_size]# 3.可選dropoutif dropout_p > 0.0:exp_scores = F.dropout(exp_scores, p=dropout_p,training=True)# 4.累積加權和(注意力權重 x value)acc += torch.bmm(exp_scores,v_block)# 5.維護softmax分母(log-sum-exp技巧)block_sum = exp_scores.sum(dim=-1,keep_dims=True) #當前塊的指數和 [batch, block_size, 1]if row_sum_exp is None: #第一次處理該query塊時row_sum_exp = block_sum #直接保存max_score = block_max #保存當前最大值else:row_sum_exp += block_summax_socre = torch.max(max_socre, block_max)output[:, i:i+block_size] = acc / (row_sum_exp + 1e-6)
return output
4、總結
(1)FlashAttention的關鍵設計
- 將q/k/v分成小塊,在SRAM中進行attention的計算
- 在計算softmax的過程中使用log-sum-exp技巧,確保數值穩定
- 將softmax后與V的乘法也集成進tile內的計算流程,避免生成大矩陣
- 利用recompilation:不存儲softmax權重P,而是在反向傳播時重算QKTQK^TQKT,換取顯存節省。
(2)FlashAttention的不足
- 線程并行效率不高:使用的是“1warp對應1Q行”的劃分方式,warp內線程空閑率高
【注:
在gpu并行計算中,warp是NVIDIA GPU的基本執行單位,通常由32個線程組成。這些線程在gpu上以SIMT(single instruction, multiple threads)方式執行,即所有線程在同一時刻執行相同指令,但可以處理不同的數據。
FlashAttention中的“1 warp對應1Q行”問題是指每個warp負責計算1行Q的注意力分數。但由于Q的行維度(seq_len)通常遠小于32,導致:
+ 線程利用率低:32個線程中,只有少數線程真正在計算,其余線程空閑
+ 并行效率不高:gpu的SIMT架構要求所有線程執行相同指令,但部分線程沒有實際工作,造成浪費。
】
- split-K導致頻繁HBM讀寫:每次分塊操作都要訪問Q和O,存在冗余累加
- 不支持MQA/GQA等高效注意力結構:僅適用于標準MHA
- 實現依賴Triton編譯器:對部屬平臺要求高,難以在pytorch,tensorflow等框架中原生集成
- 反向傳播內核較少優化:精度和性能兼顧方面還有改進空間。

)




![[數據結構]#6 樹](http://pic.xiahunao.cn/[數據結構]#6 樹)












:Pandas 高級數據結構與操作)