PDF作為廣泛使用的文檔格式,轉換為輕量級標記語言Markdown后,可無縫集成到技術文檔、博客平臺和版本控制系統中,提高內容的可編輯性和可訪問性。本文將詳細介紹如何使用國產Spire.PDF for Python 庫將 PDF 文檔轉換為 Markdown 格式。
技術優勢:
- 精準保留原始文檔結構(段落/列表/表格)
- 完整提取文本和圖像內容
- 無需?Adobe?依賴的純?Python?實現
- 支持?Linux/ Windows/ macOS?全平臺
安裝依賴
在使用之前,需要先安裝該庫。可以通過 pip 命令進行安裝,具體步驟如下:
打開命令提示符(CMD)或終端,輸入以下命令并回車:
pip install Spire.Pdf等待安裝完成即可。
要移除水印,可申請免費授權后再應用:
from spire.pdf.common import *
from spire.pdf import *# 應用授權pdfLicense.SetLicenseKey(key)PDF轉Markdown - Python代碼
僅需以下5行核心代碼就可以將PDF文檔轉換為Markdown格式:
from spire.pdf.common import *
from spire.pdf import *# 加載PDF文檔
pdf = PdfDocument()
pdf.LoadFromFile("測試.pdf")# 將PDF轉換為Markdown文件
pdf.SaveToFile("PDF轉Markdown.md", FileFormat.Markdown)
pdf.Close()
功能特點詳解:
1. 文本轉換
- 準確提取PDF中的文本內容
- 保留段落結構和換行
2. 格式保留
- 樣式識別:自動檢測字體樣式(加粗、斜體)
- 列表處理:有序列表和無序列表轉換
3. 表格轉換
- 自動檢測表格結構
- 保留行列對齊關系
4. 圖像處理
- 圖像默認會以Base64格式內嵌在Markdown文件中
提示:對于掃描版PDF,建議先使用OCR工具進行文本識別再轉換。
轉換效果:
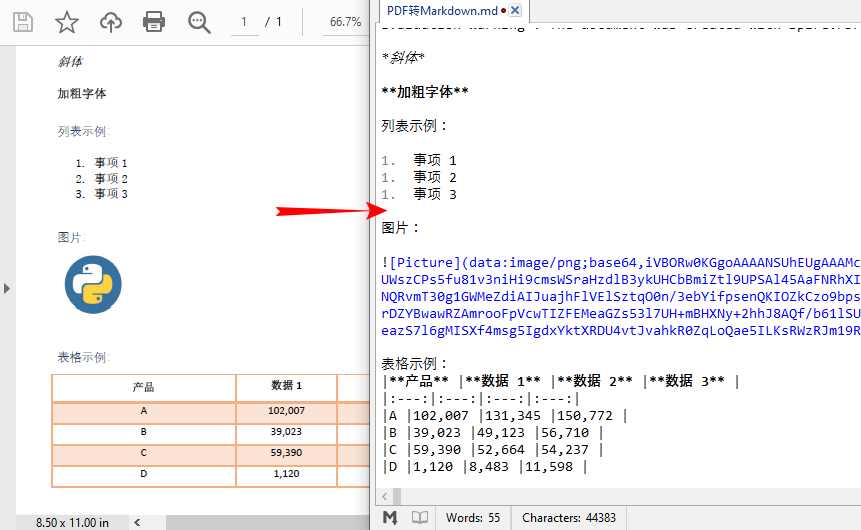
注意事項
- 轉換后的 Markdown 文件可能需要進行一些微調,因為 PDF 的格式較為復雜,有時轉換后的內容可能會存在一些格式上的小問題。
- 對于包含復雜布局或特殊格式的 PDF 文件,轉換效果可能會受到一定影響,建議轉換后仔細檢查并進行必要的編輯。
- 確保輸入的 PDF 文件路徑和輸出的 Markdown 文件路徑正確,避免因路徑錯誤導致轉換失敗。
- 當 PDF 文件較大或內容較多時,轉換過程可能需要一定的時間,請耐心等待。
結論:通過Spire.PDF for Python,開發者可快速構建自動化文檔轉換工作流。雖然復雜排版可能需要微調,但其代碼友好性簡化了很多操作需求。
---------- 👇?技術問題?----------


)





)

)
day04--手寫數字識別項目實戰)
)

)




![[數據結構]#6 樹](http://pic.xiahunao.cn/[數據結構]#6 樹)