
📃個人主頁:island1314
?? 歡迎關注:👍點贊 👂🏽留言 😍收藏 💞 💞 💞
- 生活總是不會一帆風順,前進的道路也不會永遠一馬平川,如何面對挫折影響人生走向 – 《人民日報》
🔥 目錄
- 四、函數
- 4.1 聚合函數
- 4.2 分組查詢 -- group by
- HAVING
- 4.3 日期函數
- 4.4 字符串函數
- 4.5 日期函數
- 4.6 其他函數
- 五、復合查詢
- 5.1 多表查詢
- 5.2 自連接
- 5.3 子查詢
- 1, 行列子查詢
- 2, 在 from 子句中使用子查詢
- 3, 合并查詢
- 六、內外連接
- 6.1 內連接
- 6.2 外連接
四、函數
4.1 聚合函數
| 數 | 說明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查詢到的數據的數量 |
| SUM([DISTINCT] expr) | 返回查詢到的數據的總和 |
| AVG([DISTINCT] expr) | 返回查詢到的數據的平均值 |
| MAX([DISTINCT] expr) | 返回查詢到的數據的最大值 |
| MIN([DISTINCT] expr) | 返回查詢到的數據的最小值 |
-
這里是為
select分組查詢做準備的,聚合函數是以 查出來的記錄 為單位幫我們進行 數據聚合統計的。這種聚合統計方式通常是產出一個期望的結果,如個數、和、平均值、最大值、最小值。 -
mysql中其實也是有函數的,這個函數可以被直接調用,我們可以在mysql直接使用聚合函數直接對一組結果進行聚合統計。 -
聚合函數()里面可以是全列,可以是指定列。
【案例】:基于我們上面 Retrieve 那建的表 exam_result,同樣這里只寫指令,不寫結果
① 統計班級共有多少同學
select count(*) from exam_result;
② 統計班級去重后數學成績有多少
select count(distinct math) from exam_result;
③ 統計數學總分
select sum(math) from exam_result;
④ 統計評價總分
select avg(math+chinese+english) from exam_result;
⑤ 返回 > 70 分以上的數學最低分
select min(math) from exam_result where math>70;
假設我們表中數學 > 70 分以上的最低分為 73 分,但是有幾個同學都是這個分,如果我們不僅想知道分數還想把名字也帶上,結果會怎樣呢?如下:
mysql> select name, min(math) from exam_result where math > 70;
ERROR 1140 (42000): In aggregated query without GROUP BY, expression #1 of SELECT list contains nonaggregated column 'learn2.exam_result.name'; this is incompatible with sql_mode=only_full_group_by
聚合統計的前提條件,一定是你先把我要聚合的數據先拿出來,然后才能聚合。
- 做 聚合 的時候必須保證你要顯示的或者你要查詢的數據列是 被允許聚合 的。
- 最低成績只有一個,但
name每個人都不一樣沒有辦法做聚合,例如兩個人都是 73,那返回誰的名字呢
4.2 分組查詢 – group by
- 分組是對表中的數據進行分組,分完組之后,在對表中每一組進行相關聚合統計。
- 而分組的目的是為了進行分組之后,方便進行聚合統計。
- 如班級里有男生女生,我們相對男生女生成績分別統計,所以可以對性別進行分組然后在進行成績的聚合統計。
- 在
select中使用group by子句可以對指定列進行分組查詢。 - 我們也可以把數據篩選之后再進行分組然后再聚合統計。
語法:
select column1, column2, .. from table group by column;
【案例】:
- 需求是按照組來統計的,根據的 emp 表中 role 列來進行分組。

- 再次強調
group by不是你想用就能用,一定要結合需求。 group by的核心作用是讓我們繼續分組聚合統計的,所以你要把需求分清楚然后和group by功能對上,才能用group by。- 我們在進行分組統計的時候,
group by后面指定列名,指明我們要分組的列是誰,但實際分組是用 該列的不同的行數據是否相同 進行分組的!(相同的列可以進行壓縮聚合) - 當我們分完組之后,那分組的條件(role),組內一定是相同的,因此可以被聚合壓縮。
理解:
- 分組,不就是把一組按照條件拆分多個組,進行各組內的統計。
- 分組(" 分表 "),不就是把一張表按照條件在邏輯上拆成多個子表,然后分別對各自的子表進行 聚合統計
- 拆成各個組不就是在邏輯上拆成各個表,然后分別在每個表里做聚合統計,以前我們做的聚合統計是在一張表里進行的
- 換句話說,只要掌握在一張表里查詢,在查詢之前先做好分組,后面的工作和思路理解上和之前單表上的聚合統計是一模一樣的。
HAVING
🍅 GROUP BY 子句進行分組以后,需要對分組結果再進行條件過濾時,不能使用 WHERE 語句,而需要用HAVING
- having經常和group by搭配使用
- 作用:對聚合后的統計數據,進行條件篩選

having 和 where 區別理解?執行順序?構建對 “結果” 的理解。?
首先having和where都是夠進行條件篩選,但是它們兩個是完全不同的篩選。
where是對具體的任意列進行條件篩選having對分組聚合之后的結果進行條件篩選**。**
它們倆的應用場景是完全不同的。換句話說where是先對原始表進行條件過濾,對過濾后的結果在進行分組
題目訓練 如下:
牛客:批量插入數據
牛客:找出所有員工當前(to_date=‘9999-01-01’)具體的薪水salary情況,對于相同的薪水只顯示一次,并按照逆
序顯示
牛客:查找最晚入職員工的所有信息
牛客:查找入職員工時間排名倒數第三的員工所有信息
牛客:查找薪水漲幅超過15次的員工號emp_no以及其對應的漲幅次數t
leetcode: duplicate-emails
leetcode: big-countries
leetcode: nth-highest-salary
4.3 日期函數
| 函數名稱 | 描述 |
|---|---|
current_date() | 獲取當前日期 |
current_time() | 獲取當前時間 |
current_timestamp() | 獲取當前時間戳 |
date(datetime) | 返回 datetime 參數的日期部分 |
date_add(date, interval d_value_type) | 在 date 中添加日期或時間,interval 后的數值單位可以是 year、minute、second、day |
date_sub(date, interval d_value_type) | 在 date 中減去日期或時間,interval 后的數值單位可以是 year、minute、second、day |
datediff(date1, date2) | 計算兩個日期之間的差值,單位是天 |
now() | 獲取當前日期時間 |
【案例】:
① 獲取當前日期
SELECT current_date();
② 獲取當前時間
SELECT current_time();
③ 獲取當前時間戳
SELECT current_timestamp();
④ 獲取當前日期時間
SELECT now();
⑤ 截斷當前時間,只獲得日期部分
SELECT date(now());
⑥ 在日期的基礎上加日期
SELECT date_add(now(), interval 10 year);
⑦ 在日期的基礎上減去時間
SELECT date_sub(now(), interval 10 minute);
⑧ 計算兩個日期之間相差多少天
SELECT datediff(now(), '1949-10-01'); # 前面減后面
這些函數有什么用呢,下面有兩個案例
**案例 1 **:創建一張記錄生日的表
create table tmp(id int primary key auto_increment, birthday date); # 建表
insert into tmp (birthday) values (current_date()); # 插入數據mysql> select * from tmp;
+----+------------+
| id | birthday |
+----+------------+
| 1 | 2025-02-08 |
+----+------------+
雖然 current_time() 這里顯示的是時分秒,實際上插入的時候也能插入,所有的時間在獲取的時候都是年月日 時分秒,只不過顯示時是不一樣的。
**案例 2 **:創建一張記錄生日的表
create table msg(id int primary key auto_increment, sendtime datetime);
insert into msg values(1, now());mysql> select id, date(sendtime) from msg; # 顯示所有留言信息
+----+----------------+
| id | date(sendtime) |
+----+----------------+
| 1 | 2025-02-08 |
+----+----------------+mysql> select * from msg; # 顯示所有留言信息
+----+---------------------+
| id | sendtime |
+----+---------------------+
| 1 | 2025-02-08 19:53:08 |
+----+---------------------+-- 查詢在2分鐘內發布的帖子
mysql> select * from msg where date_add(sendtime, interval 2 minute) > now();
+----+---------------------+
| id | sendtime |
+----+---------------------+
| 1 | 2025-02-08 19:53:08 |
+----+---------------------+
4.4 字符串函數
| 函數名稱 | 描述 |
|---|---|
charset(str) | 返回字符串字符集(編碼集) |
concat(string [,…]) | 連接字符串 |
instr(string, substring) | 返回子字符串在字符串中的位置,無則返回0(mysql 起始從 1 開始) |
ucase(string) | 轉換成大寫 |
lcase(string) | 轉換成小寫 |
left(string, length) | 從字符串左邊起取 length 個字符 |
right(string, length) | 從字符串右邊起取 length 個字符 |
length(string) | 字符串長度 |
replace(str, search_str, replace_str) | 在字符串中用 replace_str 替換 search_str |
strcmp(string1, string2) | 逐字符比較兩個字符串大小 |
substring(str, position [,length]) | 從字符串的 position 開始,取 length 個字符 |
ltrim(string), rtrim(string), trim(string) | 去除前后空格 |
【案例】:
① 獲取某個表的某列的 字符集
mysql> select charset(id) from msg;
+-------------+
| charset(id) |
+-------------+
| binary |
+-------------+
② 連接字符串
SELECT concat(name, '的語文是', chinese, '分,', '數學', math, '分,', '英語', english, '分') from exam_result;
+-------------------------------------------------------------------------------------------------+
| concat(name, '的語文是', chinese, '分,', '數學', math, '分,', '英語', english, '分') |
+-------------------------------------------------------------------------------------------------+
| 唐三藏的語文是67分,數學98分,英語56分 |
| 孫權的語文是70分,數學73分,英語78分 |
| 宋公明的語文是75分,數學65分,英語30分 |
| zs的語文是88分,數學73分,英語80分 |
+-------------------------------------------------------------------------------------------------+
③ 求學生表中姓名占用的字節數
select name,length(name) from exam_result;
+-----------+--------------+
| name | length(name) |
+-----------+--------------+
| 唐三藏 | 9 |
| 孫權 | 6 |
| 宋公明 | 9 |
| zs | 2 |
+-----------+--------------+
以前說過 mysql 的字符真的就是一個字符,utf8中一個漢字占 3 個字節
length函數返回字符串長度,以 字節為單位。- 如果是多字節字符則計算多個字節數;如果是單字節字符則算作一個字節。
- 比如:字母,數字算作一個字節,中文表示多個字節數(與字符集編碼有關)
④ 查詢學生表名字的第二個到第三個字符
mysql> select id, substring(name, 2, 2) from exam_result;
+----+-----------------------+
| id | substring(name, 2, 2) |
+----+-----------------------+
| 1 | 三藏 |
| 2 | 權 |
| 3 | 公明 |
| 4 | s |
+----+-----------------------+
⑤ 以首字母小寫的方式顯示所有學生的姓名
select name, concat(lcase(substring(name, 1, 1)), substring(name, 2)) FROM exam_result;
4.5 日期函數
| 函數名稱 | 描述 |
|---|---|
abs(number) | 絕對值函數 |
bin(decimal_number) | 十進制轉二進制 |
hex(decimalNumber) | 轉換成十六進制 |
conv(number, from_base, to_base) | 進制轉換 |
ceiling(number) | 向上去整(數據變大) |
floor(number) | 向下去整 |
format(number, decimal_places) | 格式化,保留小數位數 |
rand() | 返回隨機浮點數,范圍 [0.0, 1.0) |
mod(number, denominator) | 取模,求余 |
ceiling(number)向上去整floor(number)向下去整
一般我進行取整的時候是進行四舍五入取整,但是除了 四舍五入 還有其他的取整方式。
- 我們把丟棄小數部分的取整方式稱為0向取整,以前我們在 C學的9/2=4 就是向 0 取整,還有向大的方向取的向上取整、向小的方向取的向下取整
4.6 其他函數
① 查詢當前用戶
SELECT user();
② 顯示當前正在使用的數據庫
SELECT database();
③ 對一個字符串進行 MD5 摘要
md5(str) 對一個字符串進行md5摘要,摘要后得到一個32位字符串
比如密碼在數據庫絕對不能是明文保存的。萬一表結構泄漏了,用戶信息就全部被泄漏了。
- 這里有一個細節
mysql對于sql里面涉及核心密碼password關鍵字之類的這個sql語句就不會被保存,不能上翻下翻了 - 密碼被變成固定32位字符串,就不用擔心密碼被泄漏了。但是登錄的時候也必須是數據庫的摘要密碼。
select md5("good"); # SELECT PASSWORD(str);
+----------------------------------+
| md5("good") |
+----------------------------------+
| 755f85c2723bb39381c7379a604160d8 |
+----------------------------------+
④ MySQL 密碼函數
除了md5進行保存密碼之外,數據庫還提供更復雜的密碼設定的函數 password(),MySQL數據庫使用該函數對用戶加密
select password('root'); # SELECT PASSWORD(str);
+-------------------------------------------+
| password('root') |
+-------------------------------------------+
| *81F5E21E35407D884A6CD4A731AEBFB6AF209E1B |
+-------------------------------------------+
**注意:**由于新版版本MySQL移除了 password(),在使用的時候是會發生語法報錯問題
之前我寫這里難怪一直說是語法錯誤?,檢查發現是我是的 MySQL 是
8.0,查看MySQL 8.0 Reference Manual已經移除了PASSWORD加密函數,因此8.0以后版本的加密壓縮函數只能采用以下函數
- MD5()
- SHA1()
- SHA()
**解決:**建議使用MD5()替代 password()函數即可解決 password() 不兼容問題。
⑤ 條件判斷函數
ifnull(val1, val2) 如果val1為null,返回val2,否則返回val1的值
類似于三目操作符 ? : 為真返回第一個,為假返回第二個
IFNULL(val1, val2) -- 如果 `val1` 為 `NULL`,返回 `val2`,否則返回 `val1` 的值mysql> select ifnull(null, 1);
+-----------------+
| ifnull(null, 1) |
+-----------------+
| 1 |
+-----------------+mysql> select ifnull(1, 2);
+--------------+
| ifnull(1, 2) |
+--------------+
| 1 |
+--------------+
五、復合查詢
5.1 多表查詢
在實際開發中,數據通常來自不同的表,需要進行多表查詢,顯示雇員名、雇員工資以及所在部門的名字如下:
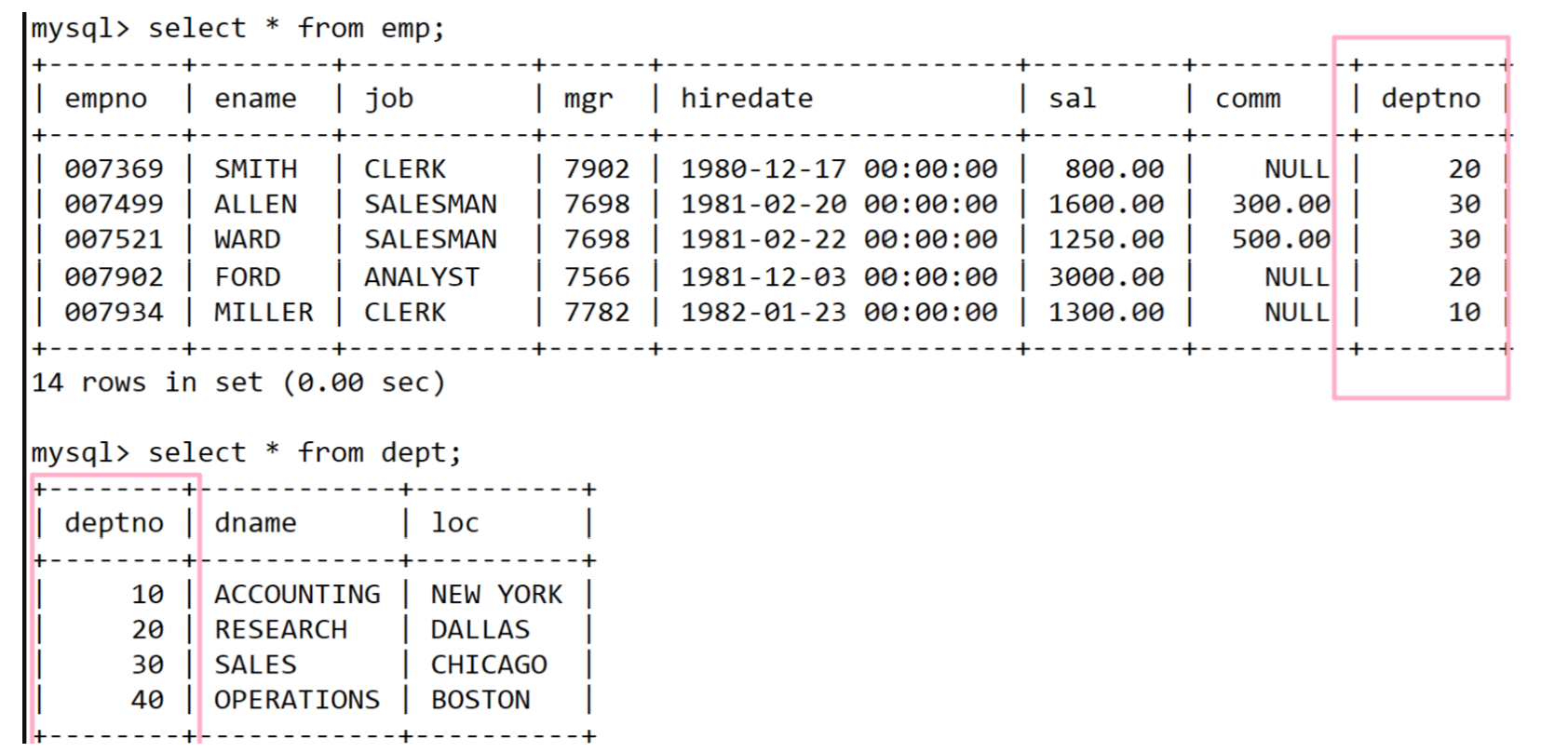
我們發現上面emp表中是沒有部門名稱的,換句話說要的數據是從兩張表來的。
- 員工名和員工工資來自于emp表,部門名稱來來自于dept表,因此需要我們要將 兩個表做整合然后在查詢
可以看到形成了一張大表,仔細觀察一下,將兩張表信息做整合的時候,就光SMITH這一條消息就和整個dept表做組合形成了更多的記錄,發現下面都是這樣的。

新形成表本質是將兩張表中數據進行窮舉組合的結果。我們把它稱之為 笛卡爾積
- 在我們看來這不就是把兩張表變成了一張表嘛。
- 所以未來在做數據的查找的時候,不就還是相當于單表的查找嗎!
- 然后就可以按照條件篩選出想要的信息。
注意 :窮舉 是把所有組合結果都放在一起了,但是有些信息是有無意義的,因此可以先去除無意義的信息(不過還是看具體情況在決定是否保留),然后在按條件查找
去除無效信息后篩選 如下:

在我們看來mysql一切皆表,換句話說這里做笛卡爾積之后,它形成的組合結果也是表結構,然后按照 條件篩選
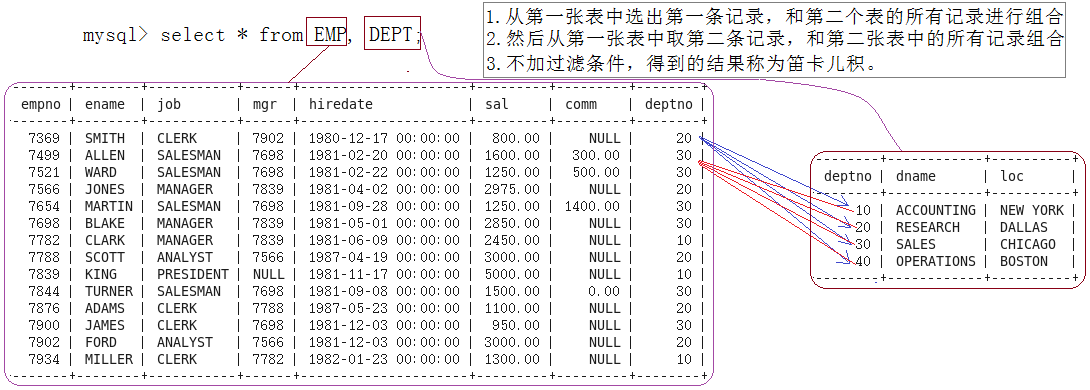
上面我們是將兩個不同的表做笛卡爾積,那可不可以把同一張表做笛卡爾積呢?
5.2 自連接
自連接是指同一張表進行 笛卡爾積
- 我們發現直接把同一張表做笛卡爾積是不行的。
- 主要原因:這是同一張表這樣不太好,字段名有重復不知道用的是那個表的字段名。
mysql> select * from msg, msg;
ERROR 1066 (42000): Not unique table/alias: 'msg'
因此我們可以給兩個表做重命名。
- 重命名也可以對表進行重命名,一旦對表進行重命名之后幾乎可以在這條sql語句任何地方出現。因為sql語句執行一定是先告訴是從那個表拿數據。
mysql> select * from msg t1, msg t2;
+----+---------------------+----+---------------------+
| id | sendtime | id | sendtime |
+----+---------------------+----+---------------------+
| 1 | 2025-02-08 19:53:08 | 1 | 2025-02-08 19:53:08 |
+----+---------------------+----+---------------------+
我們看到同一個表也是拿著前面的表每一條記錄去和后面的表中所有記錄做組合。所以哪怕是同一張表也可以做笛卡爾積,只不過是對表名重新命名一下即可。
比如:要查找 某個員工的上級領導的編號和姓名,方法如下:
- 通過子查詢找到FORD的領導編號,然后根據這個編號找到領導信息
- 我們可以通過自連接來查找,相比于上面方法就更加方便
5.3 子查詢
之前編寫的時候,子查詢 之前也寫了一些。現在來正式說一下查詢的概念。除了剛才的 笛卡爾積 是一種整合表的做法,子查詢 也是多表查詢或者一張表中復雜查詢時常用的做法。
- 子查詢是指嵌入在其他sql語句中的
select語句,也叫 嵌套查詢
一般我們在子查詢時依賴的永遠都是子查詢查出來的結果,根據結果我們可以把子查詢劃分為
單列單行子查詢、單列多行子查詢、多列單行子查詢、多列多行子查詢
1, 行列子查詢
① 單行子查詢
查詢數學成績和孫權相同的同學,如下:
select * from exam_result where math = (select math from exam_result where name = '孫權');
+----+--------+---------+------+---------+
| id | name | chinese | math | english |
+----+--------+---------+------+---------+
| 6 | 孫權 | 70 | 73 | 78 |
| 8 | zs | 88 | 73 | 80 |
+----+--------+---------+------+---------+
② 多行子查詢
in關鍵字: 表示相同,判斷一個列值是否在集合中。all關鍵字: 表示全部any關鍵字: 表示任意
查詢和10號部門的工作崗位相同的雇員的名字、崗位、工資、部門號,但不包含10號部門:

我們不僅僅用子查詢把要的結果篩選出來,我想說的是,一個SQL整體的查詢結果本身就是表結構,mysql一切皆表,所以不要認為只有物理上真實存在的表才可以做笛卡爾積,我們可以將一個查出來的表結構也可以和其他表或者其他查詢結果做笛卡爾積。
- 其次,子查詢不僅能出現在
where后面充當判斷條件,而且也能出現在from后面充當笛卡爾積。
③ 多列子查詢
單行子查詢是指子查詢只返回單列,單行數據;
多行子查詢是指返回單列多行數據,都是針對單列而言的,而多列子查詢則是指查詢返回多個列數據的 子查詢語句
查詢和SMITH的部門和崗位完全相同的所有雇員,但不包含SMITH本人:

2, 在 from 子句中使用子查詢
子查詢不僅可以出現 where 中充當判斷條件,也可以出現在 from 中,from 是在sql中告訴數據庫去那個表里拿數據。
在這里說一下任意查出來的表結構在我看來全都是表結構。
- 子查詢語句出現在
from子句中,把一個子查詢結果當做一個臨時表使用,可以解決很多問題。
顯示每個高于自己部門平均工資的員工的姓名、部門、工資、平均工資
-- 首先統計每個部門的平均工資
SELECT deptno, AVG(sal) AS myavg FROM emp GROUP BY deptno;-- 然后與員工表進行笛卡爾積,并篩選出符合條件的記錄
SELECT ename, emp.deptno, sal, myavg FROM emp, (SELECT deptno, AVG(sal) AS myavg FROM emp GROUP BY deptno) tmp WHERE emp.deptno = tmp.deptno AND sal > myavg;
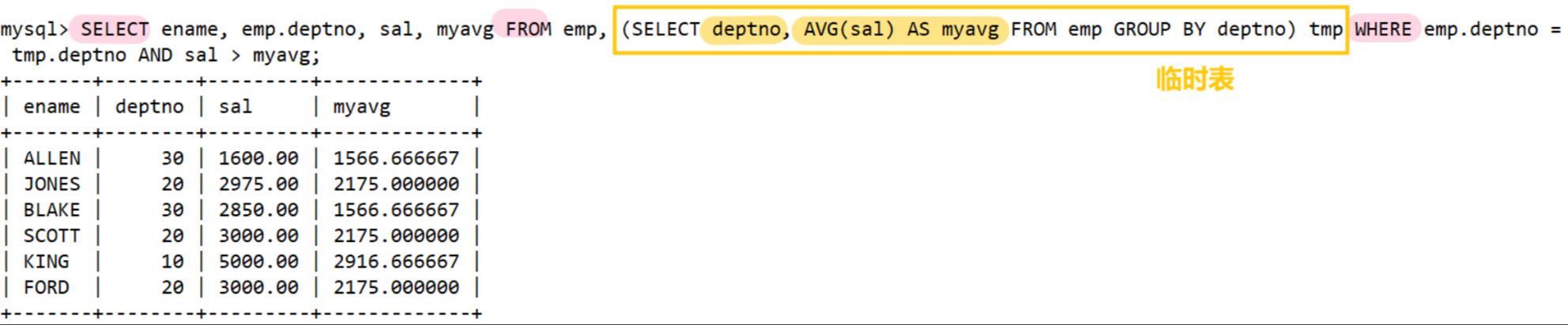
子查詢做表必須要給一個別名
只要你想做還可以在笛卡爾積。所以我們面對非常復雜的查詢本質上都是在任務分解,復雜問題是由簡單問題構成的。
查找每個部門工資最高的人的姓名、工資、部門、最高工資
- 首先也是要分組聚合統計找每個部門的最高工資,只不過只能統計到部門號和部門工資,這個人其他信息是沒有辦法在group by找到的。
- 然后我們把這個臨時表結構和emp做笛卡爾積。
- 最后在篩選出來部門號相同的,這個時候不有我們想要的信息的一張表了嗎,然后在篩選自己想要的信息。
- 然后篩選出部門號相同的信息,最后找出自己要的數據就可以了

記住mysql一切皆表,所謂的一切皆表就意味著可以把查詢出來的臨時結果在from后面也充當表。
總結一下:
mysql在我的心里是沒有多表結構的,永遠就是一張表,group by在我看來也是一張表,分組就是分表。
只要解決一個問題其他都是解決,多張表我可以在where中充當 判斷條件,在from中也做一個 臨時表表然后和其他表做笛卡爾積。
所以根本就沒有多表問題。
? 解決多表問題的本質:想辦法將多表轉化成為單表,所以mysql中,所有select的問題全部都可以轉成單表問題!這就是我們多表查詢的指導思想!
3, 合并查詢
在實際應用中,為了合并多個 select 的執行結果,可以使用集合操作符 union ,union all
- 合并并不是笛卡爾積,笛卡爾積是將兩個表的信息窮舉。合并就是單純的合起來。
union把兩條sql合并起來并且去掉重復的- 不想去重使用
union all,就會把所有信息保留
union
該操作符用于取得兩個結果集的并集。當使用該操作符時,會 自動去掉結果集中的重復行
- 注意合并時,兩個表結構列必須是一樣的才能把兩個表合并起來
mysql> select * from exam_result where math > 90;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 唐三藏 | 67 | 98 | 56 |
| 3 | 豬悟能 | 88 | 98 | 90 |
+----+-----------+---------+------+---------+mysql> select * from exam_result where english > 70;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 2 | 孫悟空 | 87 | 78 | 77 |
| 3 | 豬悟能 | 88 | 98 | 90 |
| 6 | 孫權 | 70 | 73 | 78 |
| 8 | zs | 88 | 73 | 80 |
+----+-----------+---------+------+---------+-- 結合上面兩個表進行合并,如下:mysql> select * from exam_result where math > 90 UNION select * from exam_result where english > 70;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 唐三藏 | 67 | 98 | 56 |
| 3 | 豬悟能 | 88 | 98 | 90 |
| 2 | 孫悟空 | 87 | 78 | 77 |
| 6 | 孫權 | 70 | 73 | 78 |
| 8 | zs | 88 | 73 | 80 |
+----+-----------+---------+------+---------+mysql> select * from exam_result where math > 90 UNION ALL select * from exam_result where english > 70;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 唐三藏 | 67 | 98 | 56 |
| 3 | 豬悟能 | 88 | 98 | 90 |
| 2 | 孫悟空 | 87 | 78 | 77 |
| 3 | 豬悟能 | 88 | 98 | 90 |
| 6 | 孫權 | 70 | 73 | 78 |
| 8 | zs | 88 | 73 | 80 |
+----+-----------+---------+------+---------+
六、內外連接
表的連接分為內連接和外連接。
6.1 內連接
內連接實際上是利用 WHERE 子句對兩個表形成的 笛卡爾積 進行篩選。我們前面學習的查詢都是內連接,這也是開發過程中最常用的連接查詢。
- 除了使用
FROM逗號連接兩個表然后用WHERE篩選有效信息,還可以使用INNER JOIN連接兩個表,并用ON和AND(更推薦where) 級聯多個篩選條件來對笛卡爾積進行篩選。 - 之前學到的其實就是內連接的一種。
語法:
SELECT 字段 FROM 表1 INNER JOIN 表2 ON 連接條件 AND 其他條件;
示例:
之前的寫法:顯示SMITH的名字和部門名稱,如下:
SELECT ename, emp.deptno, dname FROM emp, dept where emp.deptno = dept.deptno and ename = 'SMITH';
標準內連接寫法:
select ename, emp.deptno, dname from emp innet join dept ON emp.deptno = dept.deptno where ename = 'SMITH';

- 兩種寫法都可以得到同樣的數據
- 換句話說這種標準寫法可以讓我們的sql邏輯更清楚 ,哪一個部分是要形成笛卡爾積的,那一部分是進一步做條件篩選的。
- 內連接中后面的條件也可以用
and連接,不過還是建議用where,邏輯更清楚。
6.2 外連接
外連接分為 左外連接 和 右外連接
左外連接
如果多表查詢,我們想讓左側的表完全顯示不要過任何過濾篩選,如果和右側的表配不上,讓右側的都為空也可以。必須保持左側表的全貌。叫做左外連接。
語法:
SELECT 字段名 FROM 表名1 LEFT JOIN 表名2 ON 連接條件
示例:
- 查詢所有學生的成績,如果這個學生沒有成績,也要將學生的個人信息顯示出來如果用 ID 做內連接,只有1號和2號學生符合條件,而我們需要保留左側表結構的完整性,因此使用左外連接:
SELECT * FROM stu LEFT JOIN exam ON stu.id = exam.id;
左側表完全保留,右側表按條件拼接,條件滿足直接拼上,條件不滿足拼 NULL。
右外連接
右外連接用于讓右側的表完全顯示。如果右側表的記錄在左側表中找不到匹配項,則左側表的字段顯示為 NULL。必須保持右側表的全貌。
語法:
SELECT 字段 FROM 表名1 RIGHT JOIN 表名2 ON 連接條件;
示例:
對 stu 表和 exam 表聯合查詢,把所有的成績都顯示出來,即使這個成績沒有學生與之對應,也要顯示出來
SELECT * FROM stu RIGHT JOIN exam ON stu.id = exam.id;







(表結構的操作、數據類型、約束))



:核心流程剖析之服務啟動、請求處理與選舉協議)



![[spring6: Mvc-函數式編程]-源碼解析](http://pic.xiahunao.cn/[spring6: Mvc-函數式編程]-源碼解析)




