目錄
一、 ElasticSearch核心概念
1. 全文搜索(Full-Text Search)
2. 倒排索引(Inverted Index)
3. ElasticSearch常用術語
3.1?映射(Mapping)
3.2?索引(Index)
3.3?文檔(Document)
二、映射管理(Mapping)
三、索引管理(Index)
1. 索引的基本操作
1.1 創建索引
1.2 刪除索引
1.3 查詢索引
1.4 修改索引
2.?索引別名
如何為索引添加別名
多索引檢索的實現方案
四、文檔管理(Document)
1. 文檔的基本操作
1.1?新增文檔
1.2?查詢文檔
1.3 刪除文檔
1.4 更新文檔
五、Elasticsearch 多表關聯方案詳解?
1. 方案對比概覽
2. 嵌套對象 (Nested Object)
3. Join 父子文檔 (Parent-Child)
4. 寬表冗余存儲 (Denormalization)
5. 終極建議
一、 ElasticSearch核心概念
1. 全文搜索(Full-Text Search)
全文搜索是通過掃描文檔內容,為每個詞語建立包含出現次數和位置信息的索引。當用戶發起查詢時,系統根據預先構建的索引快速定位匹配結果并返回。
在Elasticsearch中,全文搜索專門針對文本類型(text)字段,能夠智能處理自然語言:它不僅匹配精確詞語,還會識別詞語變體和同義詞,并按相關性對結果進行排序。
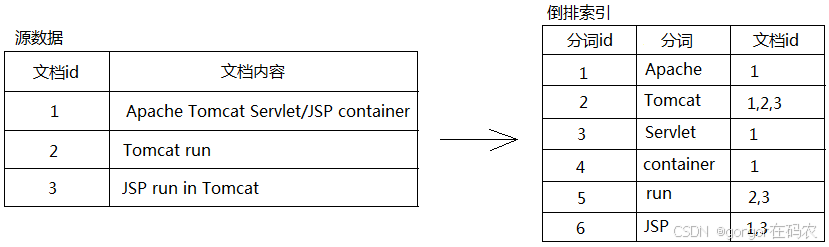
2. 倒排索引(Inverted Index)
倒排索引是全文檢索系統的核心數據結構。與傳統正排索引(通過文檔ID定位文檔內容)不同,倒排索引通過單詞(term)反向查找包含該詞的文檔。
倒排索引包含兩個關鍵組成部分:
- 詞典:存儲所有不重復單詞的列表
- 倒排列表:記錄每個單詞對應的所有文檔信息,包括出現位置、頻率等關鍵數據
3. ElasticSearch常用術語
我們可以對比MySQL來理解Elasticsearch,如下圖所示。左側是MySQL的基本概念,右側是Elasticsearch對應的相似概念的定義。借由這種對比,我們可以更直觀地看出Elasticsearch與傳統數據庫之間的關系及差異。
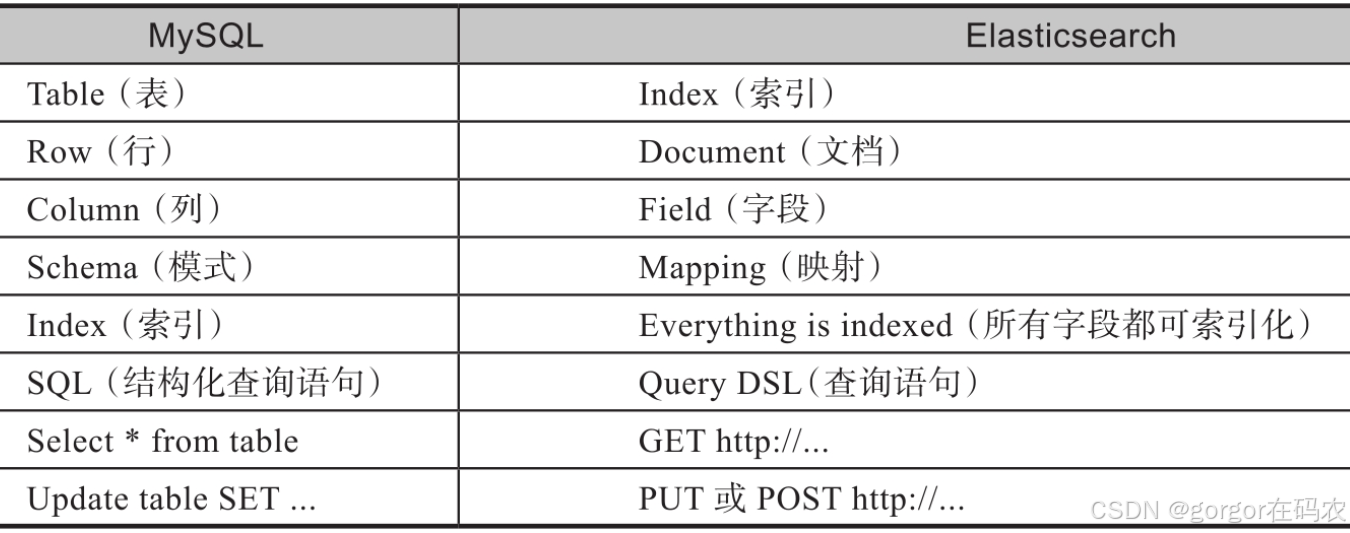
注意:在Elasticsearch 6.X之前的版本中,索引類似于SQL數據庫,而type(類型)類似于表。然而,從ES 7.x版本開始,類型已經被棄用,一個索引只能包含一個文檔類型。
3.1?映射(Mapping)
定義:
映射是索引的數據結構定義,相當于關系型數據庫的表結構(Schema)。
3.2?索引(Index)
定義:
索引是文檔的容器,相當于關系型數據庫中的表。
注意:在Elasticsearch 6.X之前的版本中,索引類似于SQL數據庫,從ES 7.x版本開始,一個索引只能包含一個文檔類型。
3.3?文檔(Document)
定義:
文檔是 Elasticsearch 中的基本數據單元,相當于關系型數據庫中的一行記錄。
二、映射管理(Mapping)
映射是索引的數據結構定義,相當于關系型數據庫的表結構(Schema)。創建表的時候,需要加上表結構,而在elasticSearch中,創建索引,也就需要映射。
創建索引基本語法
PUT /索引名稱
{"settings": {// 索引設置},"mappings": {"properties": {// 字段映射}}
}?詳細栗子
PUT /books
{"settings": {"analysis": { // 自定義分析器配置"analyzer": {"my_custom_analyzer": { // 自定義分析器"type": "custom","tokenizer": "ik_max_word", // 使用IK分詞器"filter": ["lowercase", "asciifolding"] // 轉小寫+去音標符號}}},"number_of_shards": 3, // 主分片數"number_of_replicas": 1 // 副本數},"mappings": {"dynamic": "strict", // 動態映射策略:strict=禁止未知字段"_source": { // 源數據存儲控制"enabled": true, // 存儲原始JSON"excludes": ["internal_notes"] // 排除敏感字段},"properties": {// 文本類型字段"title": { "type": "text","analyzer": "ik_max_word", // 索引時使用細粒度分詞"search_analyzer": "ik_smart", // 搜索時使用粗粒度分詞"fielddata": true, //啟用在 text 字段上的聚合(Aggregation)/啟動在 text 字段上的排序(Sorting)"fields": { // 多字段配置(多字段配置 - 為同一數據創建多種索引方式)"keyword": { // 子字段用于精確匹配"type": "keyword","ignore_above": 256 // 超過256字符不索引(意思就是大于256字符,就不會查詢得到)},"english": { // 英文分詞字段"type": "text","analyzer": "english"}},"norms": false, // 是否存儲長度信息"index_options": "positions" // 存儲位置信息用于短語查詢(存儲哪些內容)},// 關鍵詞類型字段"author": { "type": "keyword","null_value": "佚名", // 空值替換"ignore_above": 256 // 超長值處理},// 數值類型字段"price": { "type": "scaled_float", // 推薦數值類型"scaling_factor": 100, // 放大因子(存儲整數)"doc_values": true // 啟用聚合排序},"discount_rate": {"type": "float", // 標準浮點類型"index": false // 禁用索引},// 日期類型字段"publish_date": { "type": "date","format": "yyyy-MM-dd||epoch_millis", // 多格式支持"doc_values": false, // 禁用列式存儲"ignore_malformed": true // 忽略格式錯誤},// 復雜類型字段"tags": { "type": "keyword", // 標簽數組"index": true, // 啟用索引"boost": 2.0 // 權重提升},"metadata": { // 對象類型"type": "object","properties": {"isbn": {"type": "keyword"},"page_count": {"type": "integer"}}},"reviews": { // 嵌套類型"type": "nested", // 保持數組對象獨立"properties": {"user": {"type": "keyword"},"rating": {"type": "byte"},"comment": {"type": "text"}}},// 其他特殊類型"description": { "type": "text","index": false, // 僅存儲不索引"store": true // 單獨存儲},"cover_image": {"type": "binary", // 二進制類型"store": true},"last_access_ip": {"type": "ip" // IP地址類型},"coordinates": {"type": "geo_point" // 地理坐標},"embedding": { // 向量搜索(8.x+)"type": "dense_vector","dims": 128, // 向量維度"index": true,"similarity": "dot_product" // 相似度算法}}}
}字段類型定義(type)
-
文本類型:
text(全文搜索),?keyword(精確匹配) -
數值類型:
long,?integer,?float,?double -
日期類型:
date -
復雜類型:
object,?nested
具體關鍵配置詳解如下
-
字段類型定義
| 類型 | 配置參數 | 說明 | 適用場景 |
|---|---|---|---|
| text | analyzersearch_analyzer | 指定分詞器 | 中文內容、描述文本 |
| keyword | ignore_abovenull_value | 長度限制/空值處理 | ID、狀態碼、標簽 |
| scaled_float | scaling_factor | 數值縮放因子 | 價格、評分等小數 |
| date | formatignore_malformed | 格式/容錯處理 | 時間戳、日期 |
| nested | - | 保持數組對象獨立 | 評論、子文檔 |
| dense_vector | dimssimilarity | 維度/相似度算法 | AI向量搜索 |
-
?分析器配置
| 分析器類型 | 特點 | 示例值 |
|---|---|---|
standard | 單字拆分 | "中國" → ["中","國"] |
ik_smart | 最粗粒度 | "中國人民銀行" → ["中國人民銀行"] |
ik_max_word | 最細粒度 | "中國人民銀行" → ["中國人","中國","人民","銀行"] |
english | 英文處理 | "running" → ["run"] |
| 自定義分析器 | 組合處理 | IK分詞+小寫轉換 |
- 索引控制參數
| 參數 | 值范圍 | 作用 | 性能影響 |
|---|---|---|---|
index | true/false | 是否創建倒排索引 | 禁用可節省90%存儲 |
doc_values | true/false | 是否啟用列式存儲 | 禁用將無法聚合排序 |
store | true/false | 是否單獨存儲 | 增加存儲但加速檢索 |
norms | true/false | 是否存儲長度信息 | 節省5-10%空間 |
index_options | docs/freqs/positions | 索引內容粒度 | 位置信息支持短語查詢 |
ignore_above | 數字 | 超長值處理 | 避免大字段影響性能 |
null_value | 指定值 | 空值替換 | 保證數據完整性 |
index_options?參數詳解
index_options?是 Elasticsearch 中控制倒排索引內容粒度的關鍵參數,它決定了在索引過程中存儲哪些信息,直接影響搜索功能和性能。以下是深度解析:
可選值及含義:
| 值 | 存儲內容 | 支持功能 | 資源消耗 | 適用場景 | 限制 |
|---|---|---|---|---|---|
docs | 只存儲文檔ID | 僅能判斷文檔是否存在 | 最低 | 過濾型字段(如狀態標志) | ? 不支持相關性排序 ? 不支持短語查詢 |
freqs | 文檔ID + 詞頻 | 支持相關性評分 | 中等 | 簡單搜索(無需短語查詢) | ? 不支持短語查詢 ? 不支持高亮 |
positions?(默認) | 文檔ID + 詞頻 + 位置 | 支持短語/鄰近查詢 | 較高 | 常規文本字段 | ? 高亮效率較低 |
offsets | 文檔ID + 詞頻 + 位置 + 字符偏移 | 支持高亮顯示 | 最高 | 需要高亮的字段 | ?? 存儲開銷增加40% |
注:該參數僅適用于?
text?和?keyword?類型字段
-
高級特性
| 特性 | 配置 | 說明 |
|---|---|---|
| 多字段 | fields | 同一字段多種索引方式 |
| 動態映射 | dynamic: strict | 禁止未知字段自動映射 |
| 源數據過濾 | _source.excludes | 排除敏感字段 |
| 字段權重 | boost | 提升特定字段相關性 |
| 時間序列 | time_series | 優化時序數據存儲(8.10+) |
動態映射?dynamic?參數用于控制如何處理文檔中出現的未在映射中定義的字段(即動態字段)。它有?4 種可選值,每種值對應不同的處理策略:
| 值 | 行為 | 適用場景 | 風險/限制 |
|---|---|---|---|
true?(默認值) | 自動檢測新字段類型并添加到映射 | 開發環境、數據結構變化頻繁 | 映射膨脹、類型推斷錯誤 |
false | 忽略新字段(不索引),但保留在?_source | 日志類數據、未知字段不需搜索 | 無法搜索新字段 |
strict | 拒絕包含新字段的文檔 | 生產環境、嚴格數據管控 | 需預先定義完整映射 |
runtime?(7.11+) | 將新字段作為運行時字段處理 | 靈活查詢未定義字段 | 性能低于索引字段 |
三、索引管理(Index)
索引是文檔的容器,相當于關系型數據庫中的表。索引是具有相同結構的文檔的集合,由唯一索引名稱標定。一個集群中有多個索引,不同的索引代表不同的業務類型數據。
1. 索引的基本操作
1.1 創建索引
創建索引的基本語法如下:
PUT /index_name
{"settings": {// 索引設置},"mappings": {"properties": {// 字段映射}}
}- 索引名稱 (index_name):索引名稱必須是小寫字母,可以包含數字和下劃線。
- 索引設置 (settings)
-
分片數量 (number_of_shards):一個索引的分片數決定了索引的并行度和數據分布。
-
副本數量 (number_of_replicas):副本提高了數據的可用性和容錯能力。
-
-
映射 (mappings):字段屬性 (properties)定義索引中文檔的字段及其類型。
具體定義看映射管理。
實踐練習
創建一個名為 student_index 的索引,并設置一些以下自定義字段
- name(學生姓名):text 類型
- age(年齡):integer 類型
- enrolled_date(入學日期):date 類型
PUT /student_index
{"settings": {"number_of_shards": 1,"number_of_replicas": 1},"mappings": {"properties": {"name": {"type": "text"},"age": {"type": "integer"},"enrolled_date": {"type": "date"}}}
}插入一條文檔,方便下面進行測試
POST /student_index/_create/1
{"name": "John","age": 18,"enrolled_date": "2006-12-12"
}
1.2 刪除索引
DELETE /student_index // 謹慎操作!不可逆1.3 查詢索引
查詢操作可以分為兩類:檢索索引信息和搜索索引中的文檔。
1.3.1 檢索索引信息
基本語法如下:
GET /index_name栗子
GET student_index1.3.2 搜索索引中的文檔。
基本語法如下:
GET /index_name/_search
{ "query": { // 查詢條件 }
}栗子
# 搜索 name 字段包含 John 的文檔
GET /student_index/_search
{"query": {"match": {"name": "John"}}
}
1.4 修改索引
1.4.1 動態更新?settings
基本語法
PUT /index_name/_settings
{"index": {"setting_name": "setting_value"}
}
代碼示例
將 student_index 的副本數量更新為 2:
PUT /student_index/_settings
{"index": {"number_of_replicas": 2}
}
1.4.2 動態更新 mapping
基本語法
PUT /index_name/_mapping
{"properties": {"new_field": {"type": "field_type"}}
}
代碼示例
向 student_index 添加一個名為 grade 的新字段,類型為 integer:
PUT /student_index/_mapping
{"properties": {"grade": {"type": "integer"}}
}2.?索引別名
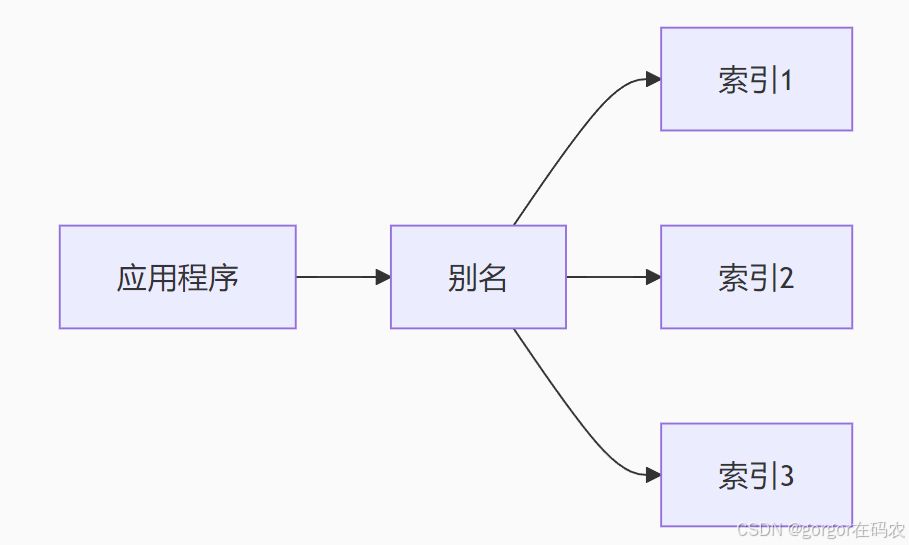
索引別名是 Elasticsearch 中一個強大的功能,它允許你為索引創建一個或多個替代名稱,類似于文件系統中的快捷方式或符號鏈接。下面我將全面解析索引別名的概念、用法和實戰場景。
-
一個邏輯名稱,可以指向一個或多個物理索引
-
提供抽象層,解耦應用和物理存儲結構
-
支持無縫切換索引(零停機維護)
如何為索引添加別名
- 創建索引的時候可以指定別名
PUT student_index
{"aliases": {"student_index_alias": {}},"settings": {"refresh_interval": "30s","number_of_shards": 1,"number_of_replicas": 0},"mappings": {"properties": {"name": {"type": "text"},"age": {"type": "integer"},"enrolled_date": {"type": "date"}}}
}- 為已有索引添加別名
POST /_aliases
{"actions": [{"add": {"index": "student_index","alias": "student_index_alias"}}]
}多索引檢索的實現方案
- 不使用別名的方案
- 方式一:使用逗號對多個索引名稱進行分隔
POST gorgor_logs_202501,gorgor_logs_202502,gorgor_logs_202503/_search- 方式二:使用通配符進行多索引檢索
POST gorgor_logs_*/_search- 使用別名的方案
PUT gorgor_logs_202501
PUT gorgor_logs_202502
PUT gorgor_logs_202503POST _aliases
{"actions": [{"add": {"index": "gorgor_logs_202501","alias": "gorgor_logs_2025"}},{"add": {"index": "gorgor_logs_202502","alias": "gorgor_logs_2025"}},{"add": {"index": "gorgor_logs_202503","alias": "gorgor_logs_2025"}}]
}POST gorgor_logs_2025/_search四、文檔管理(Document)
文檔是 Elasticsearch 中的基本數據單元,相當于關系型數據庫中的一行記錄。文檔是指存儲在Elasticsearch索引中的JSON對象。
1. 文檔的基本操作
1.1?新增文檔
在ES8.x中,新增文檔的操作可以通過POST或PUT請求完成,具體取決于是否指定了文檔的唯一性標識(即ID)。如果在創建數據時指定了唯一性標識,可以使用POST或PUT請求;如果沒有指定唯一性標識,只能使用POST請求。
簡單理解:PUT 必須指定唯一性標識,POST可以指定,也可以不指定,不指定則 elasticsearch 會幫忙生成一個。
1.1.1 使用POST請求新增文檔
當不指定文檔ID時,可以使用POST請求來新增文檔,Elasticsearch會自動生成一個唯一的ID。語法如下:
POST /<index_name>/_doc
{"field1": "value1","field2": "value2",// ... 其他字段
}
1.1.2 使用PUT請求新增文檔
當指定了文檔的唯一性標識(ID)時,可以使用PUT請求來新增或更新文檔。如果指定的ID在索引中不存在,則會創建一個新文檔;如果已存在,則會替換現有文檔。語法如下:
PUT /<index_name>/_doc/<document_id>
{"field1": "value1","field2": "value2",// ... 其他字段
}
在Elasticsearch 8.x中,批量新增文檔可以通過_bulk API來實現。這個API允許您將多個索引、更新或刪除操作組合成一個單一的請求,從而提高批量操作的效率。
- Index: 用于創建新文檔或替換已有文檔。
- Create: 如果文檔不存在則創建,如果文檔已存在則返回錯誤。
- Update: 用于更新現有文檔。
- Delete: 用于刪除指定的文檔。
以下是使用_bulk API的基本語法:
POST /<index_name>/_bulk
# index
{ "index" : { "_index" : "<index_name>", "_id" : "<optional_document_id>" } }
{ "field1" : "value1", "field2" : "value2", ... }# update
{ "update" : { "_index" : "<index_name>", "_id" : "<document_id>" } }
{ "doc" : {"field1" : "new_value1", "field2" : "new_value2", ... }, "_op_type" : "update" }# delete
{ "delete" : { "_index" : "<index_name>", "_id" : "<document_id>" } }# create
{ "create" : { "_index" : "<index_name>", "_id" : "<optional_document_id>" } }
{ "field1" : "value1", "field2" : "value2", ... }- 指定文檔ID:
- PUT請求在創建或更新文檔時必須指定文檔的唯一ID。如果指定的ID已經存在,PUT請求會替換現有文檔;如果不存在,則創建一個新文檔。
- POST請求在創建新文檔時可以指定ID,也可以不指定。如果不指定ID,Elasticsearch會自動生成一個唯一的ID。
- 冪等性:
- PUT請求是冪等的,這意味著多次執行相同的PUT請求,即使是針對同一個文檔,最終的結果都是一致的。
- POST請求不是冪等的,多次執行相同的POST請求可能會導致創建多個文檔。
- 更新行為:
- PUT請求在更新文檔時會替換整個文檔的內容,即使是文檔中未更改的部分也會被新內容覆蓋。
- POST請求在更新文檔時可以使用_update API,這樣可以只更新文檔中的特定字段,而不是替換整個文檔。
1.2?查詢文檔
1.2.1 根據id查詢文檔
在Elasticsearch 8.x中,根據文檔的ID查詢單個文檔的標準語法是使用GET請求配合文檔所在的索引名和文檔ID。以下是具體的請求格式:
GET /<index_name>/_doc/<document_id>1.2.2 根據id批量查詢文檔
在Elasticsearch 8.x中,使用Multi GET API可以根據ID查詢多個文檔。該API允許您在單個請求中指定多個文檔的ID,并返回這些文檔的信息。以下是Multi GET API的基本語法:
GET /<index_name>/_mget
{"ids" : ["id1", "id2", "id3", ...]
}1.2.3?根據搜索關鍵詞查詢文檔
在Elasticsearch 8.x中,查詢文檔通常使用Query DSL(Domain Specific Language),這是一種基于JSON的語言,用于構建復雜的搜索查詢。
以下是一些常用的查詢語法:
- 匹配所有文檔
GET /<index_name>/_search
{"query": {"match_all": {}}
}- 模糊匹配(分詞)
GET /<index_name>/_search
{"query": {"match": {"<field_name>": "<query_string>"}}
}- 精確匹配(不分詞)
GET /<index_name>/_search
{"query": {"term": {"<field_name>": {"value": "<exact_value>"}}}
}- ?范圍查詢
-
GET /<index_name>/_search {"query": {"range": {"<field_name>": {"gte": <lower_bound>,"lte": <upper_bound>}}} }
1.3 刪除文檔
1.3.1?刪除單個文檔
在Elasticsearch 8.x中,刪除單個文檔的基本HTTP請求語法是:
DELETE /<index_name>/_doc/<document_id>1.3.2?批量刪除文檔
- 使用 _bulk API_bulk API允許您發送一系列操作請求,包括刪除操作。每個刪除請求是一個獨立的JSON對象,格式如下:
POST /_bulk
{ "delete": {"_index": "{index_name}", "_id": "{id}"} }
{ "delete": {"_index": "{index_name}", "_id": "{id}"} }
{ "delete": {"_index": "{index_name}", "_id": "{id}"} }
- 使用 _delete_by_query API_delete_by_query API允許您根據查詢條件刪除文檔。如果您想刪除特定索引中匹配特定查詢的所有文檔,可以使用以下請求格式:
POST /{index_name}/_delete_by_query
{"query": {"<your_query>"}
}
1.4 更新文檔
1.4.1?更新單個文檔
在Elasticsearch 8.x版本中,更新操作通常通過_update接口執行,該接口允許您部分更新現有文檔的字段。以下是更新文檔的基本語法:
POST /{index_name}/_update/{id}
{"doc": {"<field>: <value>"}
}1.4.2?批量更新文檔
- 使用 _bulk API
POST /_bulk
{ "update" : {"_index" : "<index_name>", "_id" : "<document_id>"} }
{ "doc" : {"field1" : "new_value1", "field2" : "new_value2"}, "upsert" : {"field1" : "new_value1", "field2" : "new_value2"} }
...
在這個請求中,每個update塊代表一個更新操作,其中_index和_id指定了要更新的文檔,doc部分包含了更新后的文檔內容,upsert部分定義了如果文檔不存在時應該插入的內容。
- 使用 _update_by_query API_update_by_query API允許您根據查詢條件更新多個文檔。這個操作是原子性的,意味著要么所有匹配的文檔都被更新,要么一個都不會被更新。
POST /<index_name>/_update_by_query
{"query": {<!-- 定義更新文檔的查詢條件 -->},"script": {"source": "ctx._source.field = 'new_value'","lang": "painless"}
}
在這個請求中,是您要更新的索引名稱,query部分定義了哪些文檔需要被更新,script部分定義了如何更新這些文檔的字段。
并發場景下更新文檔如何保證線程安全
在Elasticsearch 7.x及以后的版本中,_seq_no和_primary_term取代了舊版本的_version字段,用于控制文檔的版本。_seq_no代表文檔在特定分片中的序列號,而_primary_term代表文檔所在主分片的任期編號。這兩個字段共同構成了文檔的唯一版本標識符,用于實現樂觀鎖機制,確保在高并發環境下文檔的一致性和正確更新。
當在高并發環境下使用樂觀鎖機制修改文檔時,要帶上當前文檔的_seq_no和_primary_term進行更新:
POST /employee/_doc/1?if_seq_no=13&if_primary_term=1
{"name": "小明","sex": 1,"age": 25
}如果_seq_no和_primary_term不對,會拋出版本沖突異常:
{ "error": { "root_cause": [ { "type": "version_conflict_engine_exception", "reason": "[1]: version conflict, required seqNo [13], primary term [1]. current document has seqNo [14] and primary term [1]", "index_uuid": "7JwW1djNRKymS5P9FWgv7Q", "shard": "0", "index": "employee" } ], "type": "version_conflict_engine_exception", "reason": "[1]: version conflict, required seqNo [13], primary term [1]. current document has seqNo [14] and primary term [1]", "index_uuid": "7JwW1djNRKymS5P9FWgv7Q", "shard": "0", "index": "employee" }, "status": 409 }
五、Elasticsearch 多表關聯方案詳解?
在 Elasticsearch 中實現類似關系型數據庫的多表關聯,主要有四種核心方案,各有適用場景和性能特點:
1. 方案對比概覽
| 方案 | 原理 | 優點 | 缺點 | 適用場景 |
|---|---|---|---|---|
| 嵌套對象 | 文檔內嵌子對象 | 查詢快、數據局部性 | 更新成本高 | 一對少、讀多寫少 |
| Join父子文檔 | 父子文檔跨存儲 | 支持一對多、獨立更新 | 查詢性能較低 | 頻繁更新子文檔 |
| 寬表冗余 | 字段冗余存儲 | 最佳性能、簡單 | 數據冗余、更新復雜 | 讀密集型場景 |
| 業務端關聯 | 應用層處理 | 靈活、無ES限制 | 網絡開銷大 | 復雜關聯關系 |
各項詳解:?
- 嵌套對象(Nested Object)
- Join父子文檔類型
- 寬表冗余存儲
- 業務端關聯
2. 嵌套對象 (Nested Object)
原理
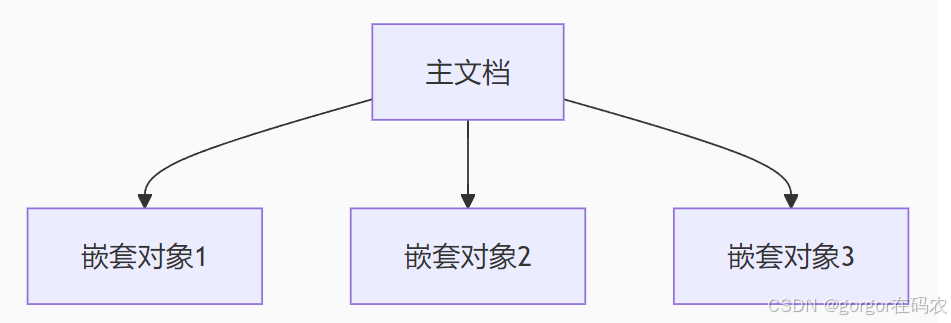
-
將關聯數據作為內嵌對象數組存儲
-
每個嵌套對象獨立索引和查詢
示例:訂單與商品
PUT /orders
{"mappings": {"properties": {"order_id": {"type": "keyword"},"order_date": {"type": "date"},"items": {"type": "nested", // 關鍵聲明"properties": {"product_id": {"type": "keyword"},"name": {"type": "text"},"price": {"type": "float"},"quantity": {"type": "integer"}}}}}
}查詢嵌套對象
GET /orders/_search
{"query": {"nested": {"path": "items","query": {"bool": {"must": [{"match": {"items.name": "手機"}},{"range": {"items.price": {"lt": 3000}}}]}}}}
}適用場景
-
訂單項與訂單
-
文章與評論
-
用戶與地址
3. Join 父子文檔 (Parent-Child)
原理
-
父子文檔獨立存儲在同一分片
-
通過?
join?類型字段建立關聯
示例:部門與員工
PUT /company
{"mappings": {"properties": {"relation": {"type": "join", // 聲明父子關系"relations": {"department": "employee" // 部門是父,員工是子}},"name": {"type": "text"},"budget": {"type": "float"}}}
}插入數據
// 父文檔(部門)
PUT /company/_doc/d001
{"name": "研發部","budget": 5000000,"relation": "department" // 類型標識
}// 子文檔(員工)
PUT /company/_doc/e001?routing=d001 // 必須指定路由
{"name": "張三","salary": 25000,"relation": {"name": "employee", // 類型標識"parent": "d001" // 父文檔ID}
}查詢父子文檔
// 1. 查詢部門下所有員工
GET /company/_search
{"query": {"parent_id": {"type": "employee","id": "d001"}}
}// 2. 查詢高薪員工的部門
GET /company/_search
{"query": {"has_child": {"type": "employee","query": {"range": {"salary": {"gte": 30000}}}}}
}適用場景
-
部門與員工
-
產品與評論
-
博客與點贊
4. 寬表冗余存儲 (Denormalization)
原理
-
將關聯數據直接復制到主文檔
-
通過應用層維護一致性
示例:用戶+最新訂單
PUT /users
{"mappings": {"properties": {"user_id": {"type": "keyword"},"name": {"type": "text"},"latest_order": { // 冗余訂單數據"properties": {"order_id": {"type": "keyword"},"amount": {"type": "float"},"items": {"type": "nested","properties": {...}}}}}}
}查詢包含特定商品的用戶
GET /users/_search
{"query": {"nested": {"path": "latest_order.items","query": {"bool": {"must": [{"match": {"latest_order.items.product_name": "手機"}}]}}}},"highlight": {"fields": {"latest_order.items.product_name": {}}}
}適用場景
-
用戶最新訂單
-
商品最新評論
-
實時統計指標
5. 終極建議
-
讀多寫少?→ 嵌套對象
-
頻繁更新?→ 父子文檔
-
極致性能?→ 寬表冗余
-
復雜關聯?→ 業務端處理



)

)


![OpenCV —— contours_matrix_()_[]](http://pic.xiahunao.cn/OpenCV —— contours_matrix_()_[])


 3487. 刪除后的最大子數組元素和 (哈希表))
)




![[Rust 基礎課程]猜數字游戲-獲取用戶輸入并打印](http://pic.xiahunao.cn/[Rust 基礎課程]猜數字游戲-獲取用戶輸入并打印)
Ⅲ 適當人選 Ⅵ 樂在其中(上))
