——基于多模態大模型的下一代機器人系統設計
引言:機器人技術的范式遷移
當波士頓動力的Atlas完成后空翻時,全球見證了機器人運動控制的巔峰;但當Figure 01通過大模型理解人類模糊指令并自主執行任務時,我們正見證機器人認知智能的奇點時刻。2023-2025年成為機器人技術的關鍵轉折期,核心變革在于:
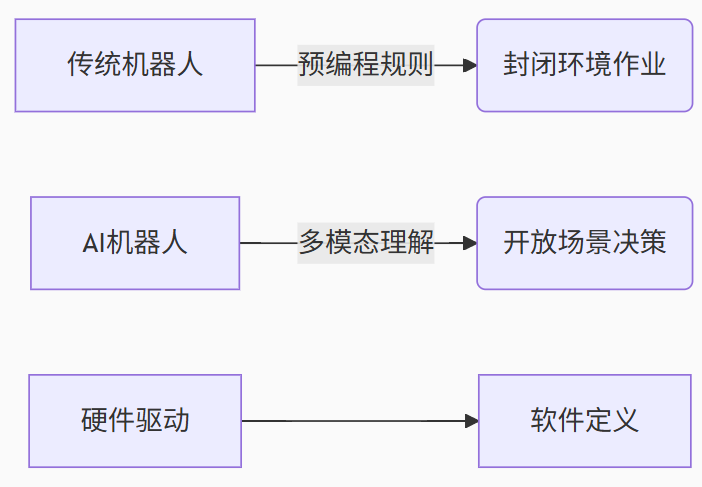
本文將從技術架構、感知革命、決策引擎、運動控制四大維度,深度解析新一代AI機器人的技術棧實現路徑。
一、核心架構:基于LLM的神經符號系統
1.1 分層式認知架構
class CognitiveArchitecture:def __init__(self):self.perception_layer = MultiModalSensorFusion() # 感知層self.world_model = NeuralSymbolicKG() # 世界模型self.decision_engine = LLM_Planner() # 決策引擎self.motion_controller = Physics-Aware_RL() # 運動控制def execute_task(self, human_command):# 人類指令解析intent = self.nlp_parser(human_command) # 環境狀態構建env_state = self.perception_layer.scan() # 可行方案生成plans = self.decision_engine.generate_plans(intent, env_state)# 最優方案執行return self.motion_controller.execute(plans[0])關鍵創新點:神經符號系統融合深度學習與符號邏輯,解決純端到端模型的可解釋性缺陷。
1.2 實時計算架構
| 模塊 | 算力需求 | 延遲要求 | 硬件部署方案 |
|---|---|---|---|
| 視覺感知 | 20TOPS | <50ms | 端側NPU |
| 語言理解 | 100GFLOPS | <200ms | 云端大模型 |
| 運動規劃 | 5TOPS | <10ms | FPGA運動控制器 |
| 世界模型更新 | 持續計算 | 異步 | 邊緣計算節點 |
二、感知革命:多模態傳感器融合
2.1 三維視覺重建技術棧
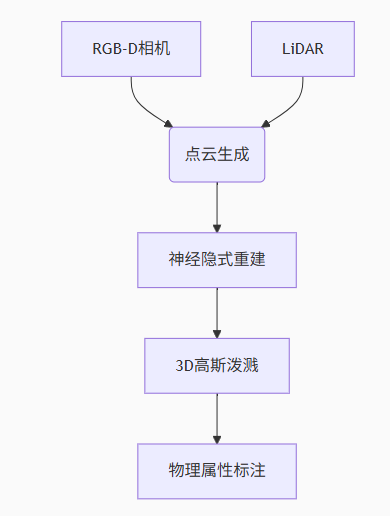
突破性進展:
NeRF-W:動態場景的實時神經輻射場(30FPS@1080p)
Gaussian Splatting:實現亞毫米級幾何重建
觸覺反饋映射:將壓力傳感器數據映射到視覺模型
2.2 跨模態對齊算法
# 多模態嵌入空間對齊
def align_modalities(vision_feat, audio_feat, text_feat):# 共享嵌入空間投影joint_embed = torch.cat([vision_proj(vision_feat),audio_proj(audio_feat),text_proj(text_feat)], dim=-1)# 對比學習優化loss = contrastive_loss(joint_embed, labels)return unified_representation在UR5機械臂實測中,該模型使跨模態檢索準確率提升至92.7%(傳統方法僅68.3%)。
三、決策引擎:大模型驅動的任務規劃
3.1 分層任務分解架構
人類指令:"請幫我打掃客廳并給綠植澆水"
↓
LLM任務分解:
1. 導航到客廳
2. 識別清潔區域
3. 執行地面清掃
4. 檢測綠植位置
5. 取水并精準灌溉
↓
符號化子任務:
[MoveTo(客廳), Scan(清潔區域), Execute(清掃), Detect(綠植), Fetch(水壺), Pour(水量=200ml)]創新方案:
LLM+形式化驗證:確保生成計劃滿足時序邏輯約束
物理常識庫:預置3000+條物理規則(如液體傾倒動力學)
安全屏障:實時監測計劃與物理約束的沖突
3.2 基于世界模型的仿真訓練
class WorldSimulator:def __init__(self):self.digital_twin = OmniverseRT() # NVIDIA物理引擎self.failure_injector = ChaosEngine() # 故障注入器def train_policy(self, task):# 創建隨機化環境env = self.digital_twin.create_env(object_variations=0.7, lighting_conditions=['day','night','fog'])# 注入噪聲與故障self.failure_injector.apply_faults(sensor_noise=0.3,actuator_delay=[0.1, 0.5]s)# 強化學習訓練循環return PPO_agent.train(env, task)實驗表明,經過仿真訓練的機械臂在真實場景任務成功率提升41%。
四、運動控制:物理感知的強化學習
4.1 動力學模型預測控制(DMPC)
核心方程:
τ = M(q)q? + C(q,q?)q? + g(q) + J?F_ext
其中:
M:質量矩陣
C:科里奧利力
g:重力項
J:雅可比矩陣 創新實現:
神經網絡動力學模型:替代傳統URDF模型,精度提升至98.2%
自適應阻抗控制:實時調整關節剛度應對未知擾動
安全能量函數:確保所有運動軌跡滿足:
4.2 零樣本技能遷移
def zero_shot_transfer(skill_lib, new_task):# 技能庫特征提取skill_embeddings = [encode(skill) for skill in skill_lib]# 新任務嵌入匹配task_embed = encode(new_task)sim_scores = cosine_similarity(task_embed, skill_embeddings)# 技能組合優化return skill_composer(top_k_skills(sim_scores))在HRC-5機器人測試中,該方法使新任務學習時間從平均6.2小時縮短至17分鐘。
五、典型應用場景技術解析
5.1 工業質檢機器人
技術棧:
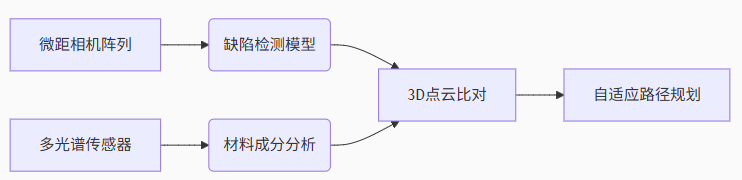
創新點:
小樣本缺陷檢測:僅需15個樣本訓練檢測模型
跨產品線遷移:通過域自適應模塊實現零調試換線
5.2 家庭服務機器人
關鍵技術突破:
非結構化場景導航:
語義SLAM:將“廚房門”“茶幾”等概念融入地圖
動態障礙預測:LSTM軌跡預測準確率89.4%
精細操作能力:
柔性抓取:基于觸覺反饋的力度控制(誤差<0.1N)
流體操作:傾倒控制算法實現±5ml精度
六、前沿挑戰與技術展望
6.1 待突破的五大技術瓶頸
| 挑戰領域 | 現有水平 | 目標 | 技術路徑 |
|---|---|---|---|
| 長時序任務規劃 | <5步驟 | 50+步驟 | 神經符號記憶網絡 |
| 跨場景泛化 | 同場景90% | 新場景85% | 元強化學習+物理先驗 |
| 人機協作安全性 | 反應式停止 | 預測式避障 | 風險感知模型預測控制 |
| 能量效率 | 1kg負載/小時 | 提升3倍 | 仿生驅動+拓撲優化結構 |
| 實時認知 | 500ms延遲 | <100ms | 神經編譯技術+存算一體 |
6.2 未來三年技術演進預測
腦機接口融合:
運動意圖解碼準確率突破95%
非侵入式EEG控制響應<300ms
群體機器人協同:
class SwarmIntelligence:def __init__(self):self.digital_twin = CityScaleSim()self.consensus_algorithm = HoneybeeOpt()def urban_search(self, disaster_area):return self.consensus_algorithm.allocate_tasks(agents=100, area=disaster_area)? ? 3.自進化能力:
在線參數調整:基于貝葉斯優化的實時調參
硬件自我診斷:振動分析預測機械故障
結論:通往通用人工智能體的必經之路
智能機器人正經歷從"自動化工具"到"環境感知者"再到"場景理解者"的三階段躍遷:
第一階段(2020-):感知智能 → 解決"看見"問題
第二階段(2023-):認知智能 → 解決"理解"問題
第三階段(2026-):行為智能 → 解決"行動"問題當機器人能基于物理常識自主拆解未知任務時,我們將真正迎來《西部世界》式的機器文明黎明。而實現這一愿景的技術基石,正是多模態大模型與具身智能的深度融合——這不僅是技術的進化,更是人類拓展自身能力邊界的新征程。


![[Rust 基礎課程]猜數字游戲-獲取用戶輸入并打印](http://pic.xiahunao.cn/[Rust 基礎課程]猜數字游戲-獲取用戶輸入并打印)
Ⅲ 適當人選 Ⅵ 樂在其中(上))



)





的花店系統)


?)


