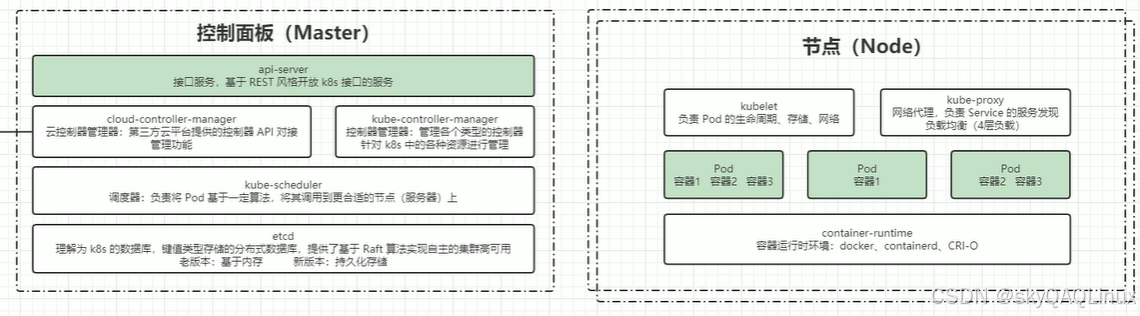
?1.k8s組成圖
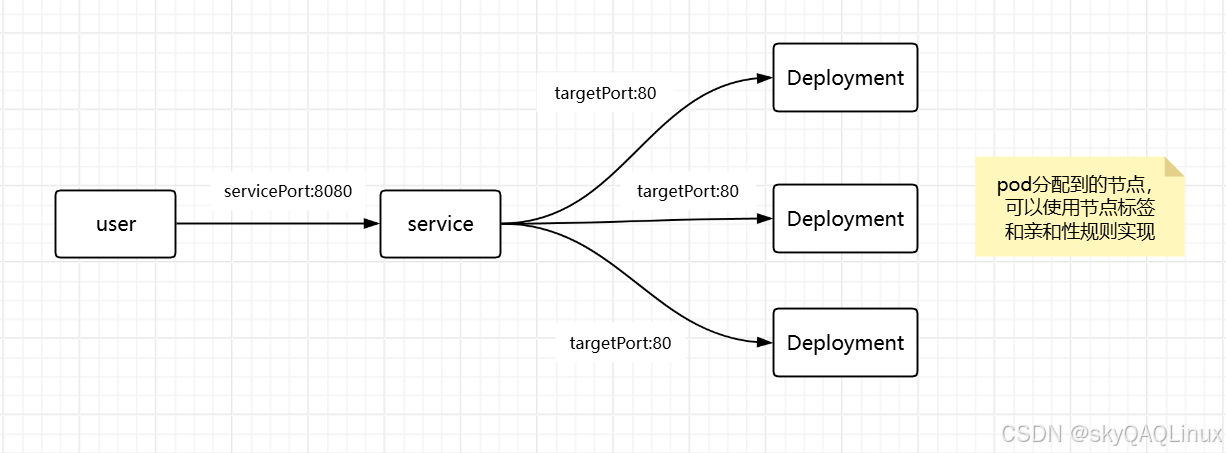
?2.service和deployment的流量轉發圖
# Deployment 定義容器端口
apiVersion: apps/v1
kind: Deployment
metadata:name: myapp
spec:template:spec:containers:- name: nginximage: nginxports:- containerPort: 80 # 容器監聽 80name: http # 端口命名(可選)---
# Service 定義端口映射
apiVersion: v1
kind: Service
metadata:name: my-service
spec:ports:- port: 8080 # Service 暴露 8080targetPort: http # 轉發到容器中名為 "http" 的端口(即80)selector:app: myapp3.pod的生命周期
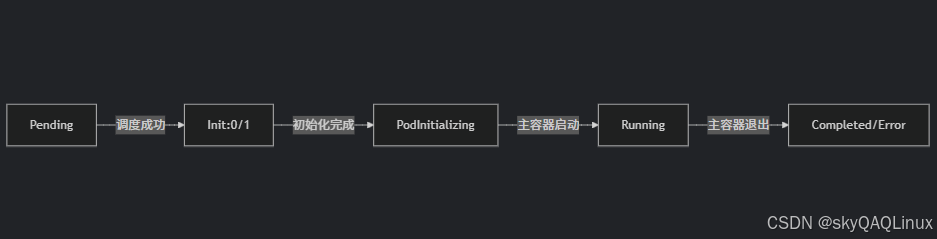
| - Pod 已被 API Server 接收,但尚未被調度到節點 |
|
| - 初始化容器正在執行(示例中總共有1個初始化容器,當前完成0個) | 檢查初始化容器的日志: |
| - 所有初始化容器已成功完成 | 通常短暫(秒級),若長時間卡在此狀態,檢查主容器的鏡像拉取或啟動命令問題 |
| - 主容器已成功啟動并持續運行 | 可通過? |
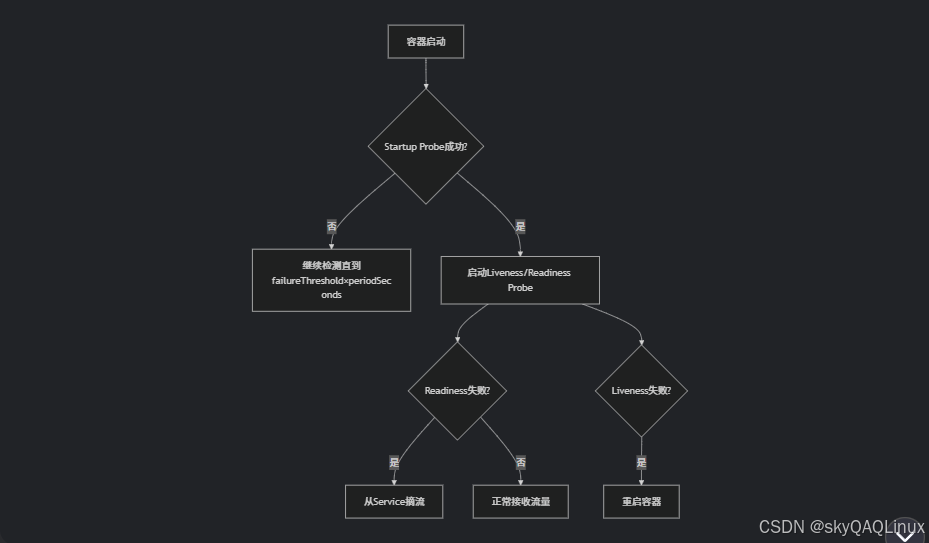
4.容器的探針執行流程
1. Deployment 的局限性
Deployment 主要解決以下問題:
副本管理:確保指定數量的 Pod 副本運行(通過?
replicas?字段)。滾動更新:支持無縫升級和回滾。
故障恢復:當 Pod?完全崩潰時,Deployment 會重新創建 Pod。
但它無法解決:
應用邏輯層面的健康狀態:Pod 進程可能正在運行,但應用內部已死鎖或無響應。
依賴就緒問題:Pod 已啟動,但依賴的數據庫/緩存尚未準備好。
啟動順序問題:應用需要較長時間初始化(如 Java 應用啟動慢)。
2. 探針的核心作用
探針彌補了 Deployment 的不足,提供細粒度的健康控制:
| 探針類型 | 解決的問題 | 示例場景 |
|---|---|---|
| Liveness Probe | 解決"進程在但服務掛"的問題,觸發重啟。 | 線程池耗盡、內存泄漏、死鎖等故障導致無響應 |
| Readiness Probe | 解決"臨時不可用"的問題,控制流量。 | 要加載大量的配置文件、建立數據庫連接池、初始化緩存等操作 |
| Startup Probe | 保護慢啟動應用,避免被 Liveness Probe 誤殺。 | 某個模型啟動需要較長的時間加載 |
containers:
- name: myapp# 存活探針(Liveness Probe):檢測容器是否處于運行但不可用的狀態(如死鎖),失敗時會重啟容器livenessProbe:httpGet: # 使用 HTTP GET 請求檢測path: /internal/health # 健康檢查接口路徑(需由應用實現)port: 8080 # 檢測的容器端口failureThreshold: 3 # 連續失敗 3 次才判定為故障(默認值)# initialDelaySeconds: 0 # (未顯式設置)容器啟動后立即開始檢測(生產環境建議設置緩沖時間)# periodSeconds: 10 # (未顯式設置)默認每10秒檢測一次# timeoutSeconds: 1 # (未顯式設置)默認檢測超時時間為1秒# 就緒探針(Readiness Probe):檢測容器是否準備好接收流量,失敗時從 Service 負載均衡中移除該 PodreadinessProbe:httpGet:path: /api/ready # 就緒檢查接口路徑(可與健康檢查分開)port: 8080periodSeconds: 5 # 每 5 秒檢測一次(比存活探針更頻繁)# successThreshold: 1 # (未顯式設置)默認成功1次即標記為就緒# failureThreshold: 3 # (未顯式設置)默認連續失敗3次才判定為未就緒# 啟動探針(Startup Probe):保護慢啟動應用,避免在初始化期間被存活探針誤殺startupProbe:httpGet:path: /internal/health # 通常與存活探針使用相同接口port: 8080failureThreshold: 30 # 允許的最大失敗次數(30次)periodSeconds: 10 # 每 10 秒檢測一次# 總啟動時間 = failureThreshold × periodSeconds = 30 × 10 = 300秒(5分鐘)# 在此期間,存活探針和就緒探針不會執行



![[ComfyUI] -入門1-ComfyUI 是什么?比 Stable Diffusion WebUI 強在哪?](http://pic.xiahunao.cn/[ComfyUI] -入門1-ComfyUI 是什么?比 Stable Diffusion WebUI 強在哪?)
![[python][flask]flask接受get或者post參數](http://pic.xiahunao.cn/[python][flask]flask接受get或者post參數)

)





— 第2章課后習題參考答案)

詳解)
)


