

?博客主頁: https://blog.csdn.net/m0_63815035?type=blog
💗《博客內容》:.NET、Java.測試開發、Python、Android、Go、Node、Android前端小程序等相關領域知識
📢博客專欄: https://blog.csdn.net/m0_63815035/category_11954877.html
📢歡迎點贊 👍 收藏 ?留言 📝
📢本文為學習筆記資料,如有侵權,請聯系我刪除,疏漏之處還請指正🙉
📢大廈之成,非一木之材也;大海之闊,非一流之歸也?


目錄
- 前言
- 一、Hive的基本概念
- 1.1Hive的交互方式
- 1.2Hive與數據庫的比較
- 1.3Hive的優缺點
- 1.4Hive的應用場景
- 1.5思考題
- 二、Hive架構
- 2.1Hive架構概述
- 2.1.1客戶端提交SQL
- 2.1.2Beeline的安全性
- 2.1.3使用JDBC和ODBC連接Hive
- 2.2元數據存儲
- 2.3客戶端安全性
- 2.4HDFS與Hive集成
- 三、Driver的工作流程
- 四、Hive的工作原理
前言
Hive 的前生屬于 Facebook,用于解決海量結構化數據的統計分析,現在屬于 Apache 軟件基金會。Hive 是一個構建在Hadoop之上的數據分析工具(Hive 沒有存儲數據的能力,只有使用數據的能力),底層由 HDFS 來提供數據存儲,可以將結構化的數據文件映射為一張數據庫表,并且提供類似 SQL的査詢功能,本質就是將 HQL 轉化成 MapReduce 程序。說白了 Hive 可以理解為一個將 SOL轉換為 MapReduce 程序的工具,甚至更近一步說, Hive 就是一個 MapReduce 客戶端.
總結:交互方式采用 SOL,元數據存儲在 Derby或 MySOL,數據存儲在 HDFS,分析數據底層實現是 MapReduce,執行程序運行在 YARN 上。
一、Hive的基本概念
1.Hive的Logo:形狀像蜂巢,由Hadoop的頭部和蜜蜂的尾部組成,代表Hive搭建在Hadoop的HDFS之上。
2.Hive的本質:是一個計算框架,提供類似SQL的查詢功能,將SQL轉換為MapReduce程序。
3.Hive的歷史:由Facebook開發并開源貢獻給Apache,用于處理海量數據。

1.1Hive的交互方式
1.Hive的交互方式:通過SQL進行交互,類似于SQL Boy。
2.原數據存儲:存儲在Hadoop的HDFS中,文件形式存在。
3.底層計算框架:默認使用MapReduce,但可替換為Tez或Spark。
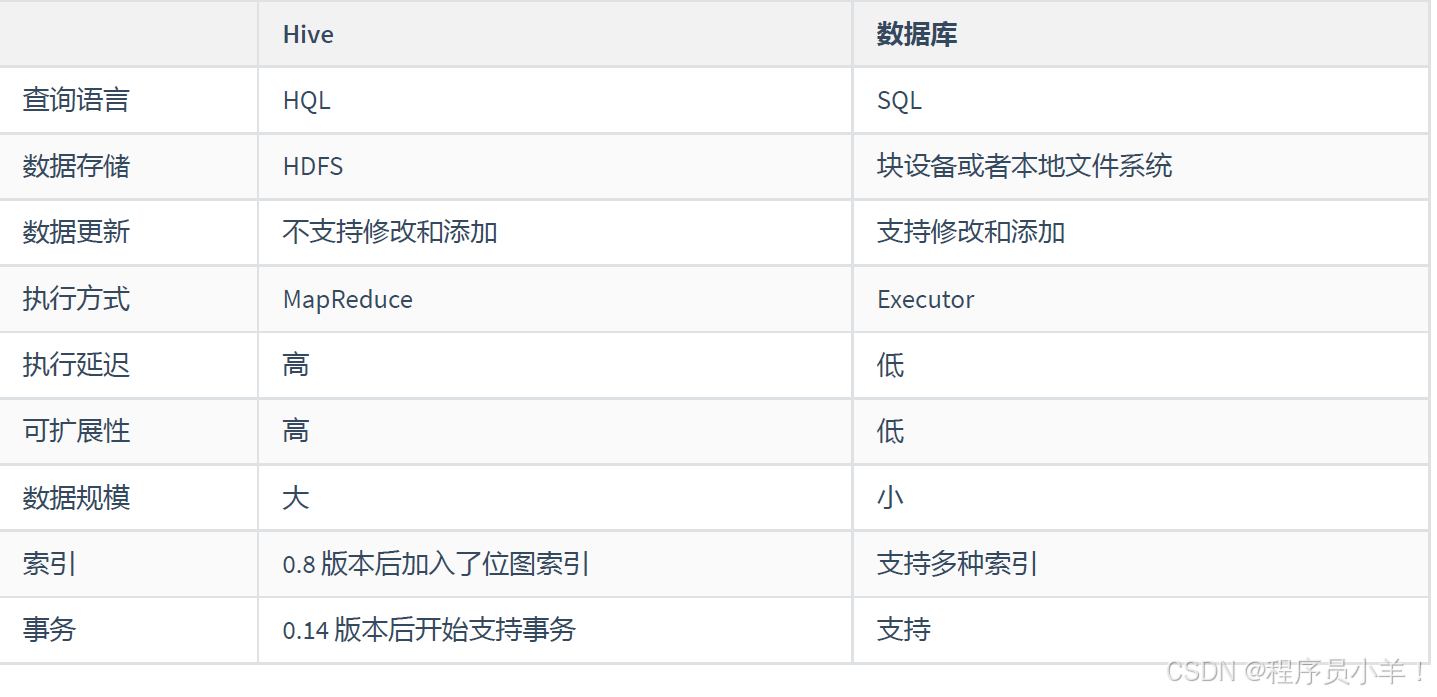
1.2Hive與數據庫的比較
1.數據存儲:Hive數據存儲在HDFS中,不支持修改和添加;數據庫支持CRUD操作。
2.執行延遲:Hive執行延遲高,適用于離線處理;數據庫執行延遲低,適用于實時處理。
3.可擴展性:Hive具有較高的可擴展性,支持底層計算引擎的替換;數據庫可擴展性較低。
4.數據規模:Hive適用于海量數據處理;數據庫適用于小規模數據。
1.3Hive的優缺點
1.優點:學習成本低,減少開發人員學習Java等語言的時間。
2.缺點:SQL表達能力有限,復雜查詢優化困難;底層基于MapReduce,執行延遲高,不適合交互式查詢。
1.4Hive的應用場景
1.日志分析:通過Hive進行海量日志數據的離線分析。
2.離線數倉:構建離線數據倉庫,處理海量結構化數據。
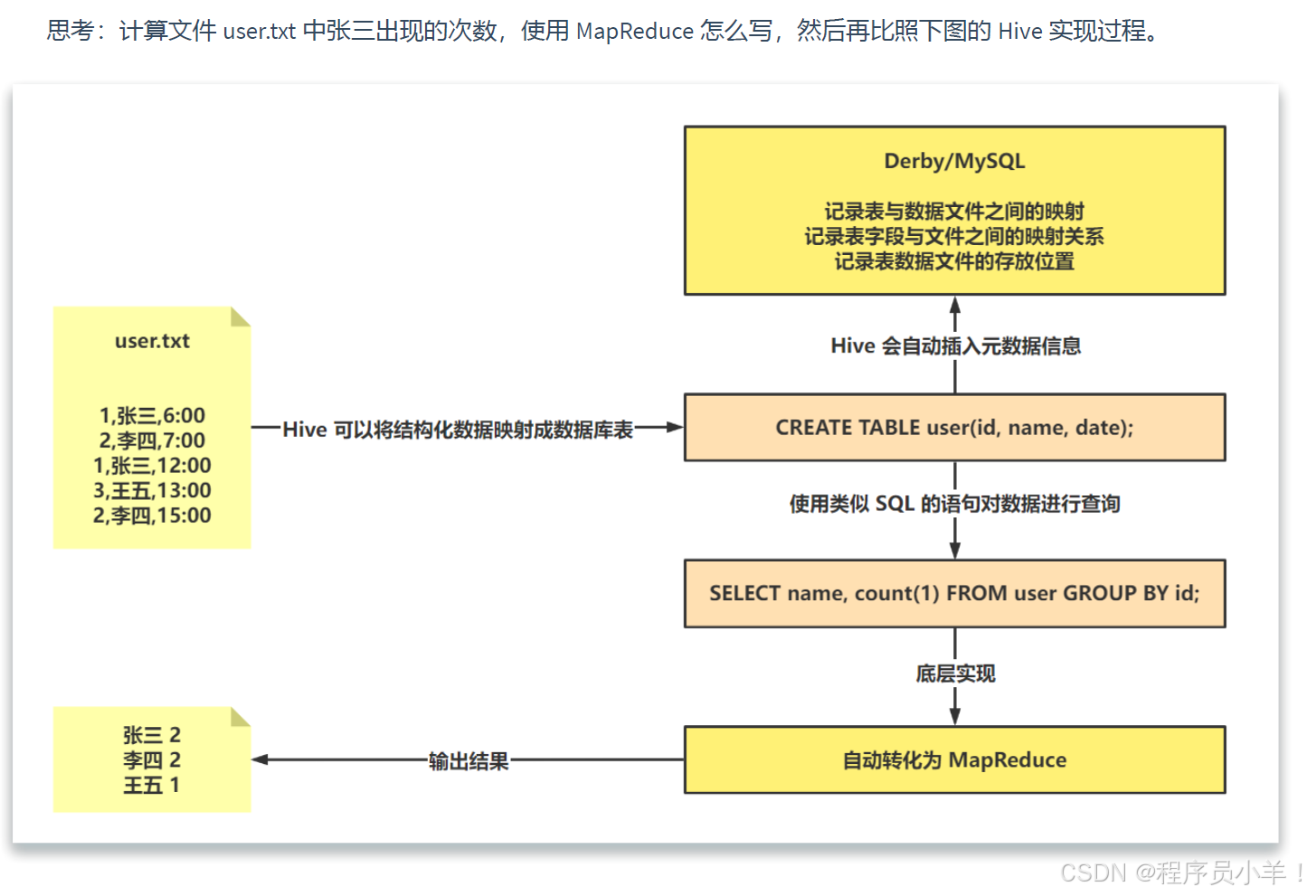
1.5思考題
二、Hive架構
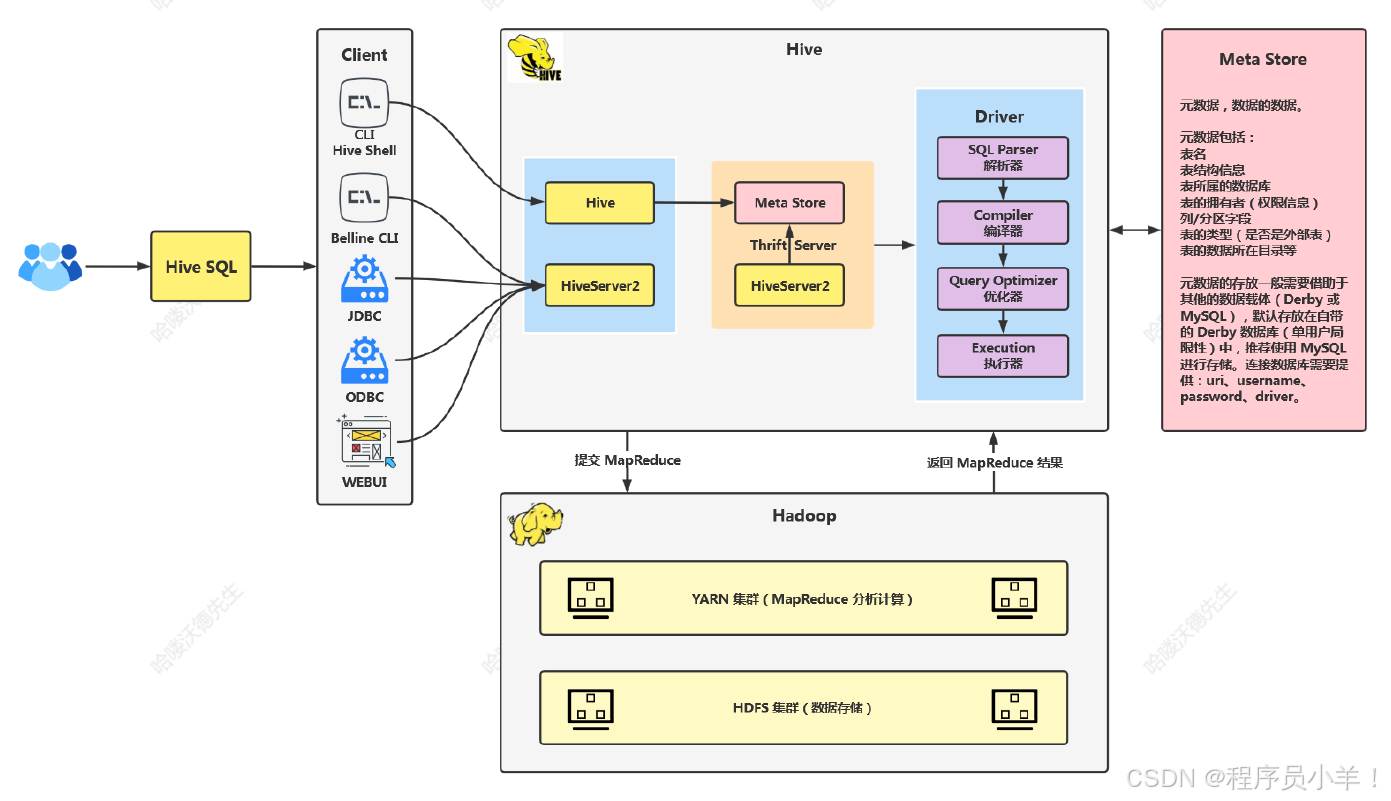
2.1Hive架構概述
1.Hive架構重要組成部分為Driver。
2.架構圖簡單,無需詳細拆解。

2.1.1客戶端提交SQL
1.大數據程序員通過客戶端提交SQL。
2.Hive提供Shell界面,可直接在界面中編寫和執行SQL。
3.Beeline是一個第三方工具,可用于提交SQL到Hive。
2.1.2Beeline的安全性
1.Beeline起到轉發作用,保護底層的Hive。
2.通過Beeline連接,不容易被攻擊者直接獲取Hive核心信息。
3.Beeline使用了一層額外的加密和轉發,增加了安全性。
2.1.3使用JDBC和ODBC連接Hive
1.使用JAVA代碼和C語言代碼通過JDBC和ODBC連接Hive。
2.可通過IDEA等工具添加Hive相關依賴,使用JDBC代碼連接。
3.Hive提供了Web UI,可通過HTTP協議訪問。
2.2元數據存儲
1.元數據存儲表名、列名、字段映射等信息。
2.學習環境中,Hive使用自帶的Derby數據庫存儲元數據。
3.生產環境中,推薦使用外部數據庫如MySQL、PostgreSQL等存儲元數據。
2.3客戶端安全性
1.客戶端連接元數據時需要輸入用戶名、密碼、URL等信息。
2.不安全的客戶端可能導致敏感信息泄露,被攻擊者利用。
3.Hive提供了安全的連接方式,如Hive over 2,增加了連接的安全性。
2.4HDFS與Hive集成
1.HDFS存儲Hive的數據文件。
2.Hive通過元數據與HDFS集成,找到數據文件的映射關系。
3.解析、編譯、優化和執行等步驟將SQL轉換為MapReduce任務在YARN集群上執行。
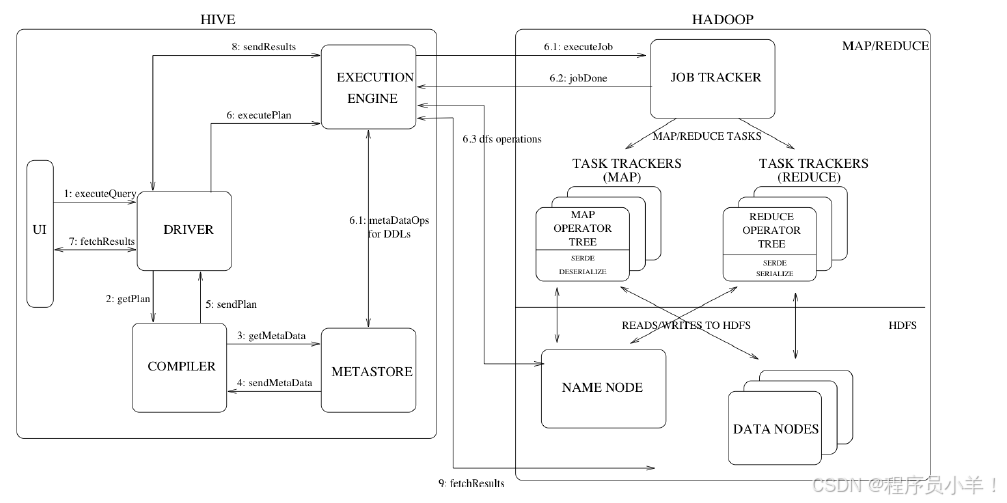
三、Driver的工作流程
1.Driver包含解析器、編譯器、優化器和執行器四大核心組件。
2.解析器校驗表名和列名是否存在。
3.編譯器將SQL編譯成執行語法樹。
4.優化器進行基于規則(RBU)和基于代價(CPU)的優化。
5.執行器將優化后的SQL轉換為MapReduce任務在YARN集群上執行。
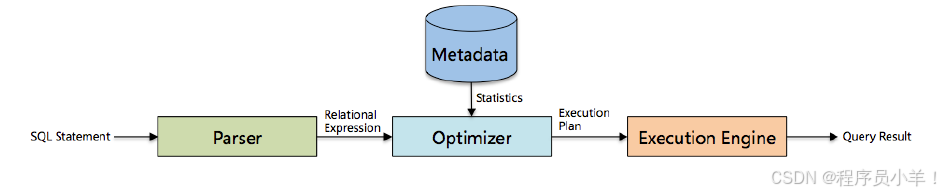
四、Hive的工作原理
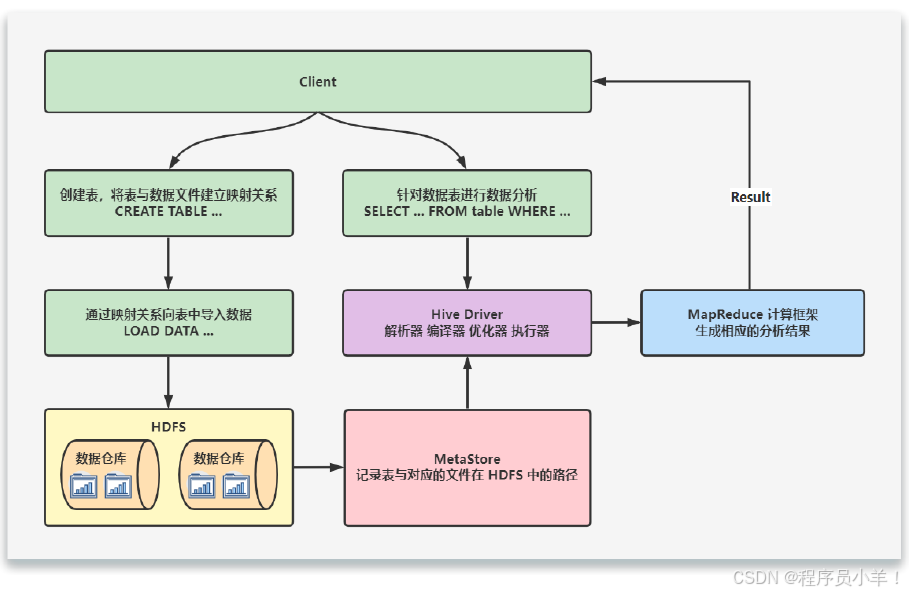
當創建表的時候,需要指定 HDFS 文件路徑,表和其文件路徑會保存到Metastore,從而建立表和數據的映射關系。當數據加載入表時,根據映射獲取到對應的 HDFS 路徑,將數據導入。
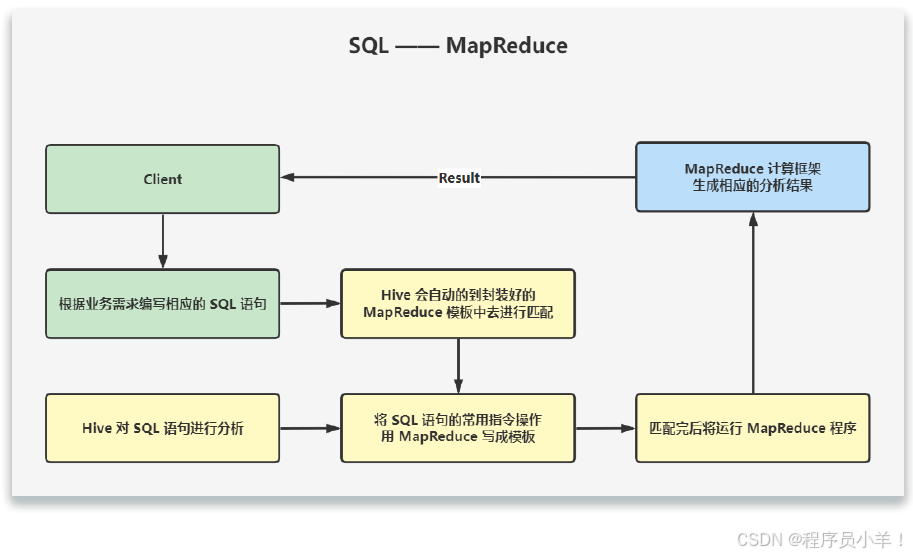
用戶輸入SQL后,Hive 會將其轉換成 MapReduce 或者 Spark 任務,提交到 YARN 上執行,執行成功將返回結果。

今天這篇文章就到這里了,大廈之成,非一木之材也;大海之闊,非一流之歸也。感謝大家觀看本文

詳解)
)








)








)