一、概念
Keepalived 是一個用 C 語言編寫的、輕量級的高可用性和負載均衡解決方案軟件。?它的主要目標是在基于 Linux 的系統上提供簡單而強大的故障轉移功能,并可以結合 Linux Virtual Server 提供負載均衡。
1、Keepalived 主要提供兩大功能:
高可用性:
原理:?基于?VRRP 協議。
工作方式:
一組服務器(通常是兩臺或更多)運行 Keepalived 守護進程,形成一個?VRRP 實例。
這些服務器被配置為擁有一個或多個共享的虛擬 IP 地址。這個 VIP 是客戶端實際訪問的 IP 地址。
其中一臺服務器被選舉為?MASTER,其他服務器處于?BACKUP?狀態。
MASTER 節點:
持有共享的 VIP。
定期發送?VRRP 通告給組內的其他節點,宣告自己還活著。
負責處理所有發送到該 VIP 的流量。
BACKUP 節點:
監聽 MASTER 發來的 VRRP 通告。
如果在一段時間內(
advert_int?間隔 + 超時時間)沒有收到 MASTER 的通告,BACKUP 節點會認為 MASTER 發生了故障。此時,優先級最高的 BACKUP 節點會發起選舉,將自己提升為新的 MASTER,并通過 ARP 廣播宣告自己接管了 VIP。
故障轉移:?這個過程實現了自動故障轉移。當主服務器宕機時,備份服務器幾乎可以瞬間(毫秒級)接管 VIP 和服務,對客戶端來說服務幾乎是連續的(短暫中斷或 TCP 重連)。
優勢:?簡單、高效、切換速度快。
負載均衡:
原理:?集成并管理?LVS。
工作方式:
Keepalived 自身不直接處理負載均衡流量。
它利用 Linux 內核的?LVS?框架來實現第四層(傳輸層,如 TCP/UDP)的負載均衡。
Keepalived 負責:
配置 LVS 規則:?在 MASTER 節點上,根據配置文件自動設置 LVS 的虛擬服務器、后端真實服務器池、調度算法(如輪詢 rr、加權輪詢 wrr、最少連接 lc 等)和健康檢查機制。
管理 LVS 狀態:?當發生主備切換時,新的 MASTER 會接管并重新配置 LVS 規則,確保負載均衡服務不中斷。
健康檢查:?對后端真實服務器進行健康檢查(支持 TCP_CHECK, HTTP_GET, SSL_GET, MISC_CHECK 等多種方式)。如果檢測到某個真實服務器故障,Keepalived 會將其從 LVS 池中移除;當服務器恢復時,再將其添加回來。
架構:?Keepalived 節點(運行 VRRP 的 MASTER)通常作為?LVS Director,接收客戶端請求,并根據調度算法將請求轉發給后端的?Real Servers。客戶端訪問的是 Keepalived 節點持有的 VIP。
2、主要配置文件
/etc/keepalived/keepalived.conf: 核心配置文件,包含:global_defs:全局配置(如通知郵件)。vrrp_script:定義用于跟蹤接口或進程狀態的自定義腳本。vrrp_instance:定義 VRRP 實例(組 ID、虛擬路由器 ID、狀態、優先級、認證、VIP 等)。virtual_server:定義 LVS 虛擬服務器(VIP + 端口)及關聯的后端真實服務器池、調度算法和健康檢查配置。
二、實驗
1、前期的配置與安裝
安裝keepalived

安裝完后,先修改配置文件:

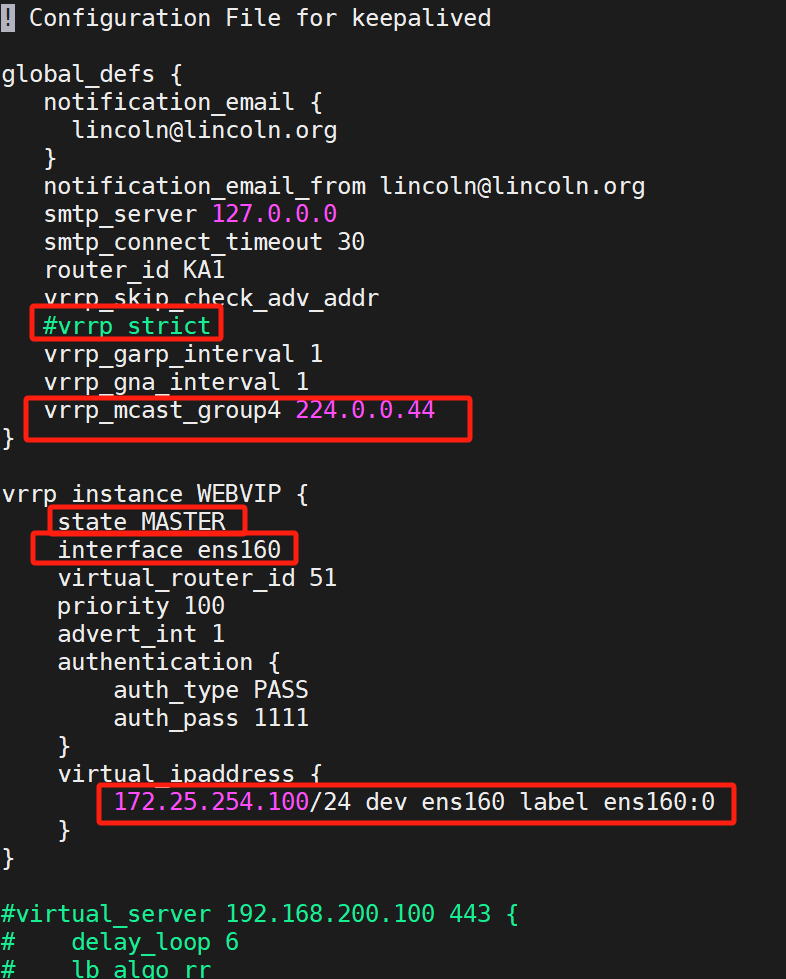
注意:interface那一行是寫你的網卡名字,可以ip a查看,寫錯了的話服務是起不來的
其后面的所有都注釋
wq保存?
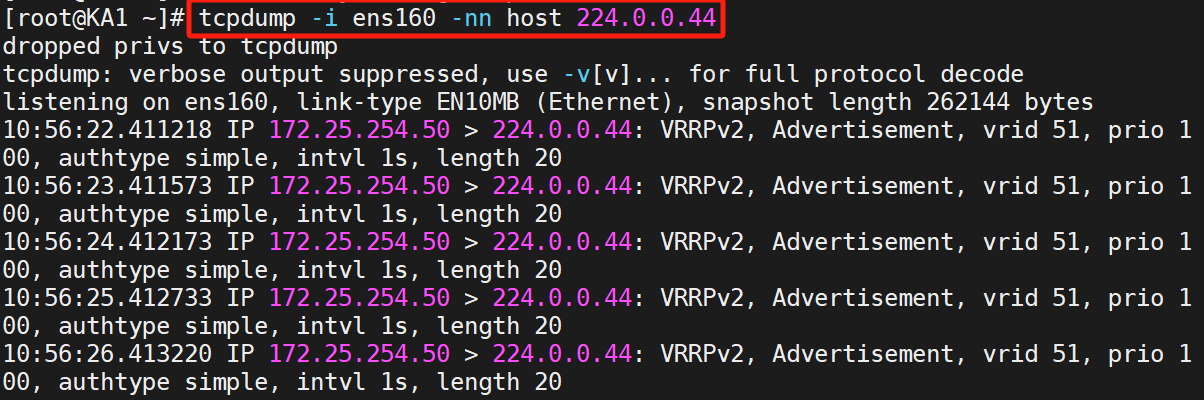
測試
2、獨立keepalived日志
將 Keepalived 日志從系統日志(如?/var/log/messages)中分離出來,是生產環境運維的關鍵實踐。
必配獨立日志的四大場景
| 場景 | 問題 | 獨立日志價值 |
|---|---|---|
| 高頻健康檢查 | 日志淹沒系統日志,掩蓋關鍵告警 | 避免?syslog?洪泛,精準定位問題 |
| 多節點集群排錯 | 跨服務器查日志效率低下 | 單節點完整日志流,加速故障定位 |
| 安全審計合規 | 混合日志無法滿足等保要求 | 獨立存儲VIP切換記錄,滿足審計追溯 |
| 性能瓶頸分析 | 無法統計VRRP報文延遲 | 記錄毫秒級事件,定位網絡抖動 |
?
(1)配置獨立
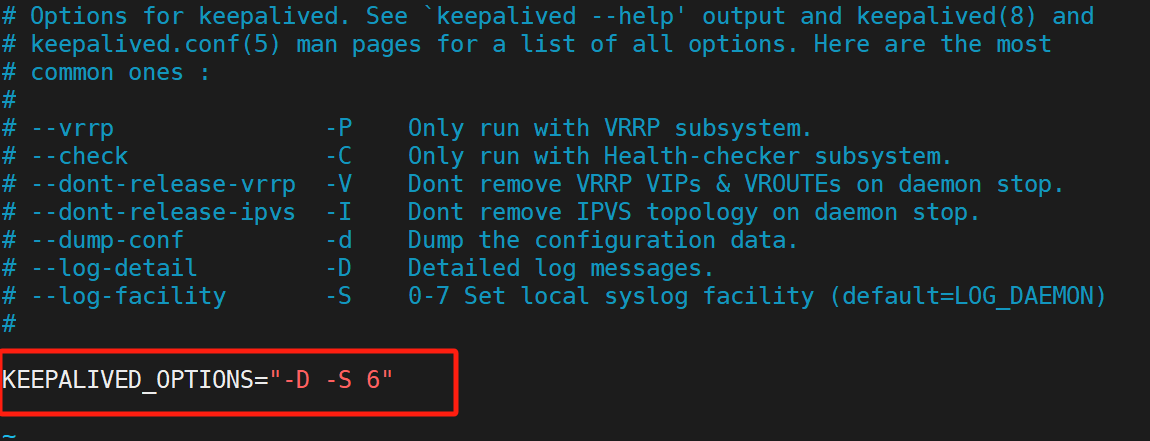
![]()
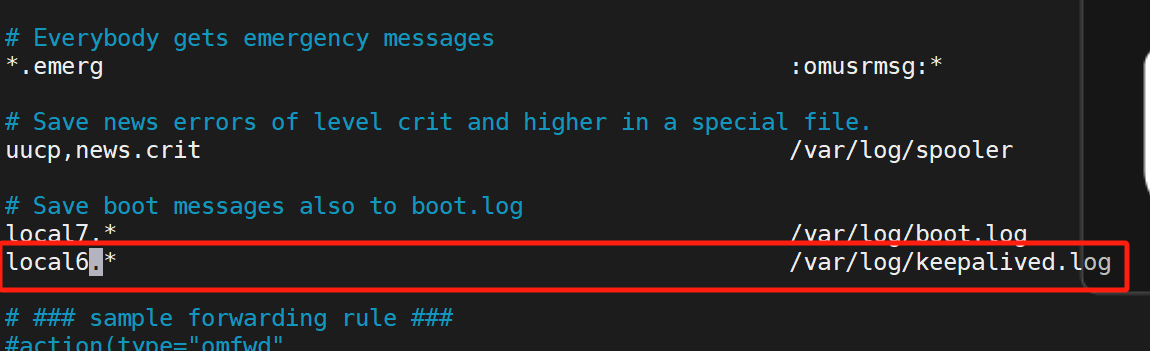

(2)測試
先連通測試,再查看日志
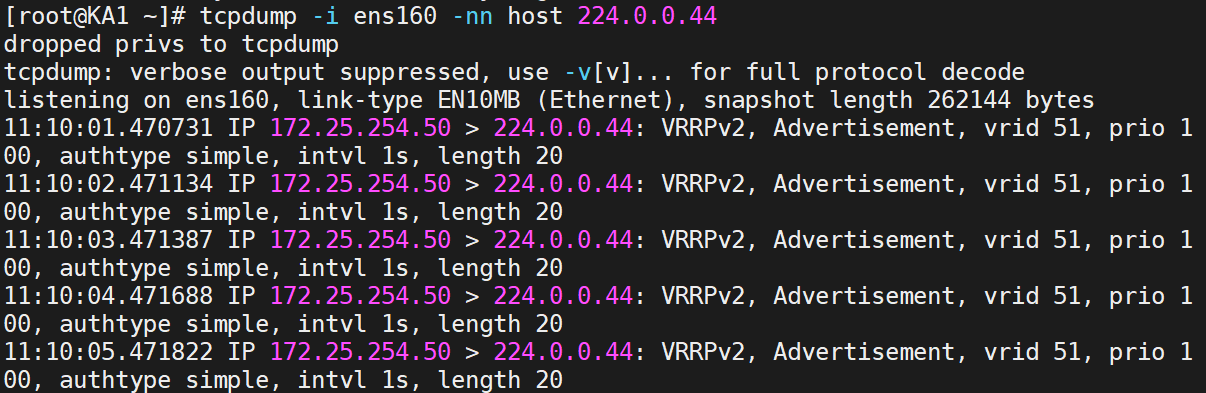
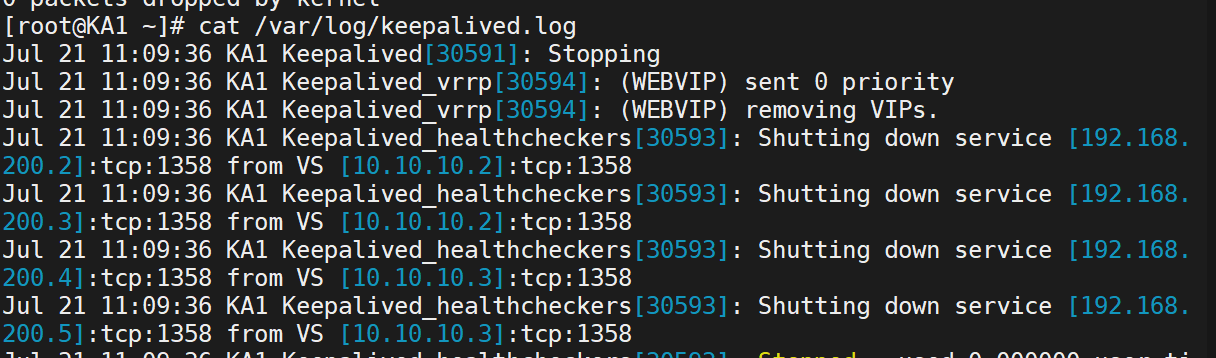
這就是獨立keepalived日志
3、獨立子配置文件
當生產環境復雜時, /etc/keepalived/keepalived.conf 文件中內容過多,不易管理
將不同集群的配置,比如:不同集群的VIP配置放在獨立的子配置文件中利用include 指令可以實現包含子配置文件
在 Keepalived 中配置獨立子配置文件是管理復雜架構的核心實踐,主要解決以下五大場景的配置痛點:
1.?多 VIP 多業務隔離
場景:單服務器承載多個業務(如 Web/DB 服務),需綁定不同 VIP
2.?多 VRRP 實例(雙主/多主)
場景:實現雙活架構(如跨機房雙主)
3.?差異化健康檢查策略
場景:不同業務需要獨立檢測機制
4.?環境差異化配置(開發/生產)
場景:不同環境使用不同檢測閾值
5.?團隊協作與權限分離
場景:網絡團隊管理 VIP,業務團隊管理健康檢查
子配置文件核心優勢
| 優勢 | 說明 |
|---|---|
| 故障隔離 | 單配置錯誤不會導致整個 keepalived 崩潰 |
| 部署效率提升 | 增刪 VIP 只需操作獨立文件,無需解析主配置 |
| 版本控制友好 | 可獨立對?db_vip.conf?進行 Git 管理,不影響其他配置 |
| 動態加載 | 支持?reload?時熱加載變更(需主配置開啟?enable_dynamic_reload) |
| 安全審計 | 精細化監控關鍵配置變更(如 VIP 綁定) |
?
(1)配置獨立
設置KA1的配置文件

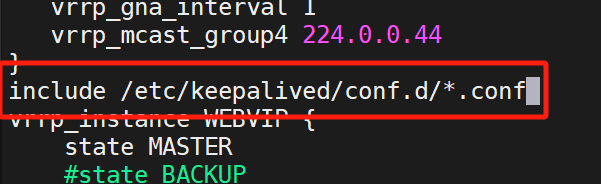

建立一個接收.conf文件的文件
![]()
進配置文件,把include下面的這一段(紅框框住的)復制,然后刪除(目的是為了設置獨立子配置文件)
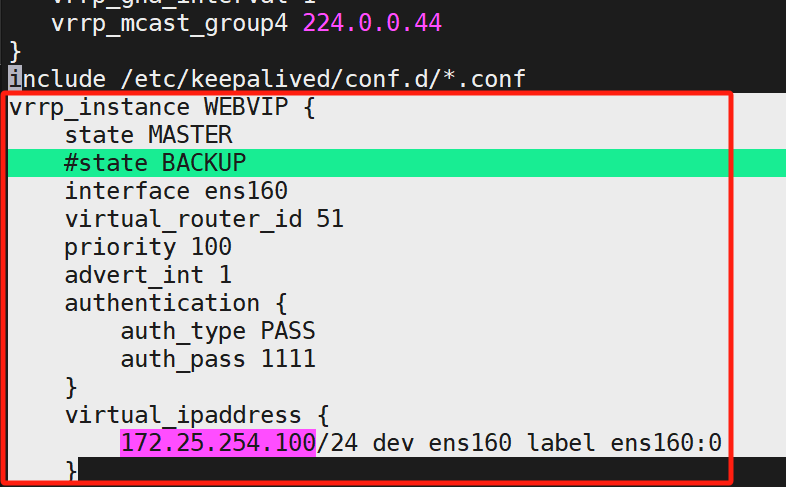
粘貼到這個里面:?

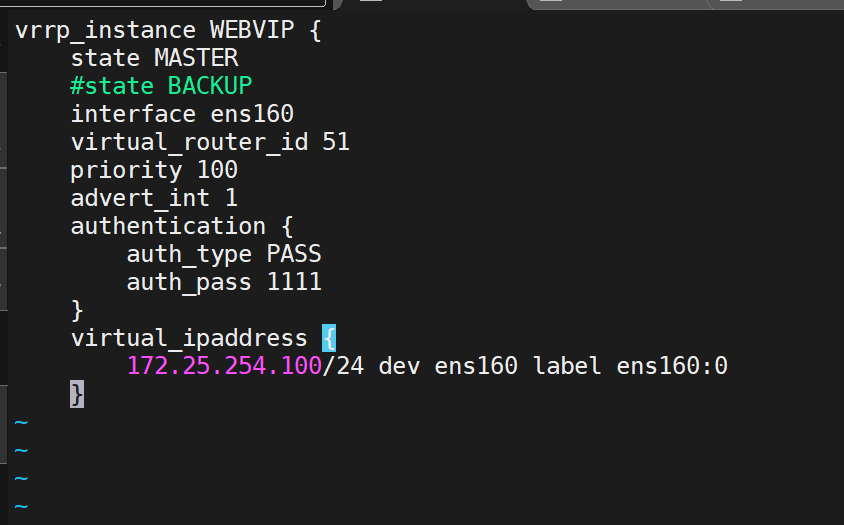
這樣就配置了獨立子配置文件
(2)還原實驗環境
把剛剛更改的全部還原(為了后續實驗方便)
全部隱掉?
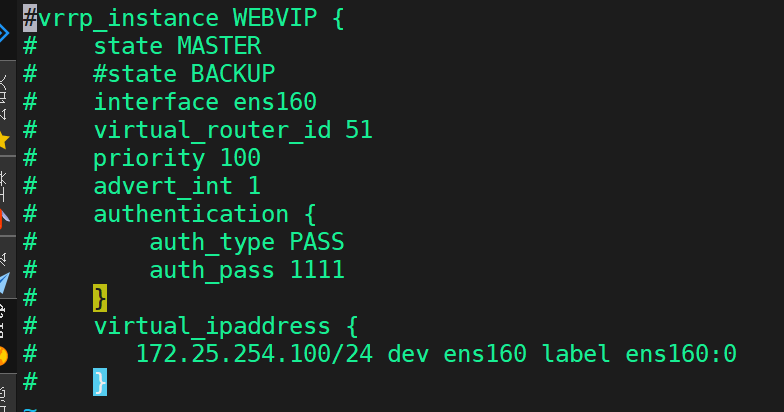
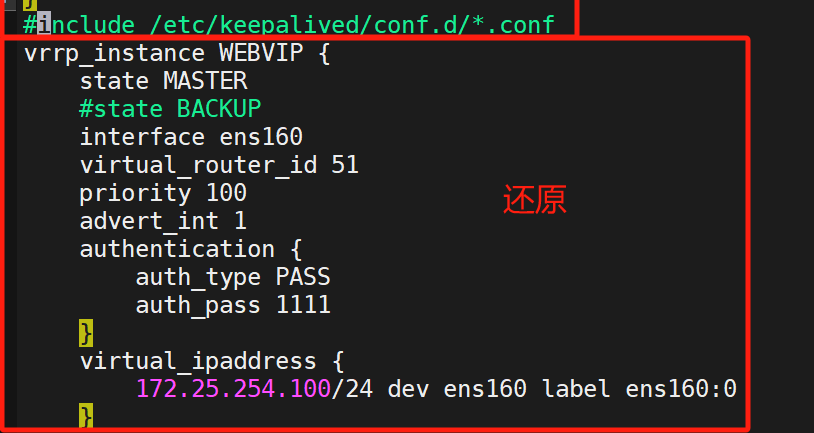
還原完重啟
![]()

這樣就沒啥問題了,還原成功
4、延遲搶占
Keepalived 的?延遲搶占(Delayed Preemption)?是一種精細化的故障恢復控制策略,用于解決主節點故障恢復后?立即切換(搶占)?可能引發的服務抖動問題。
搶占延遲模式,即優先級高的主機恢復后,不會立即搶回VIP,而是延遲一段時間(默認300s)再搶回VIP
1.?搶占(Preemption)
定義:高優先級節點恢復后,立即奪回 Master 角色。
風險:若服務尚未完全啟動,立即切換會導致二次中斷。
2.?延遲搶占
核心思想:節點恢復后,等待指定時間再發起搶占,確保服務就緒。
價值:提升故障恢復的平滑性。
?
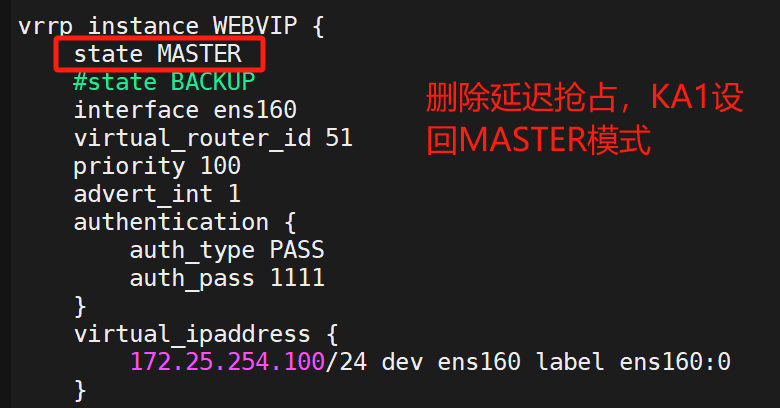
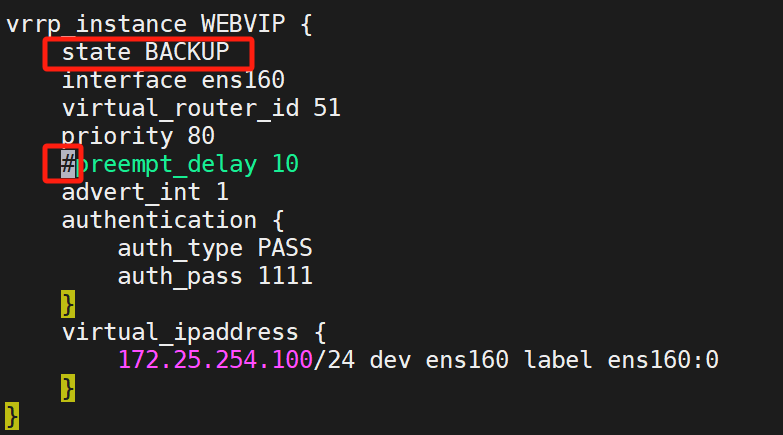
(1)設置配置
兩臺KA都做
都設置成BACKUP,非搶占模式?
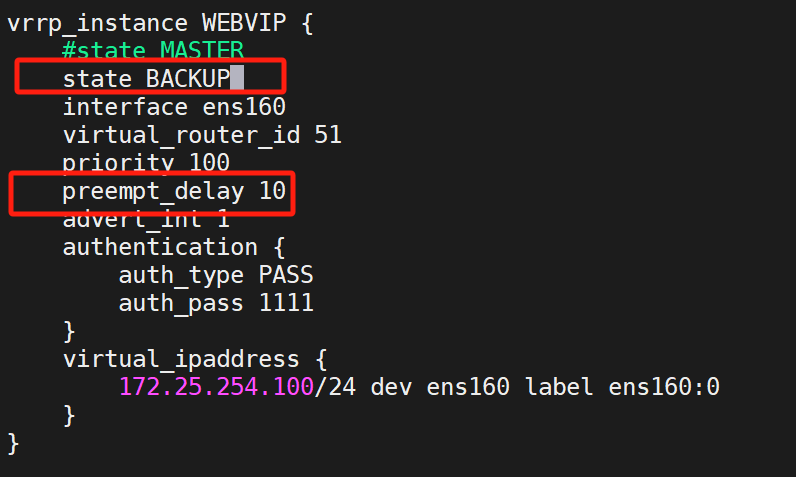
![]()
(2)測試
先關閉KA1的keepalived服務

然后開個監視器,監視KA2的變化

目前的監視器是這樣:
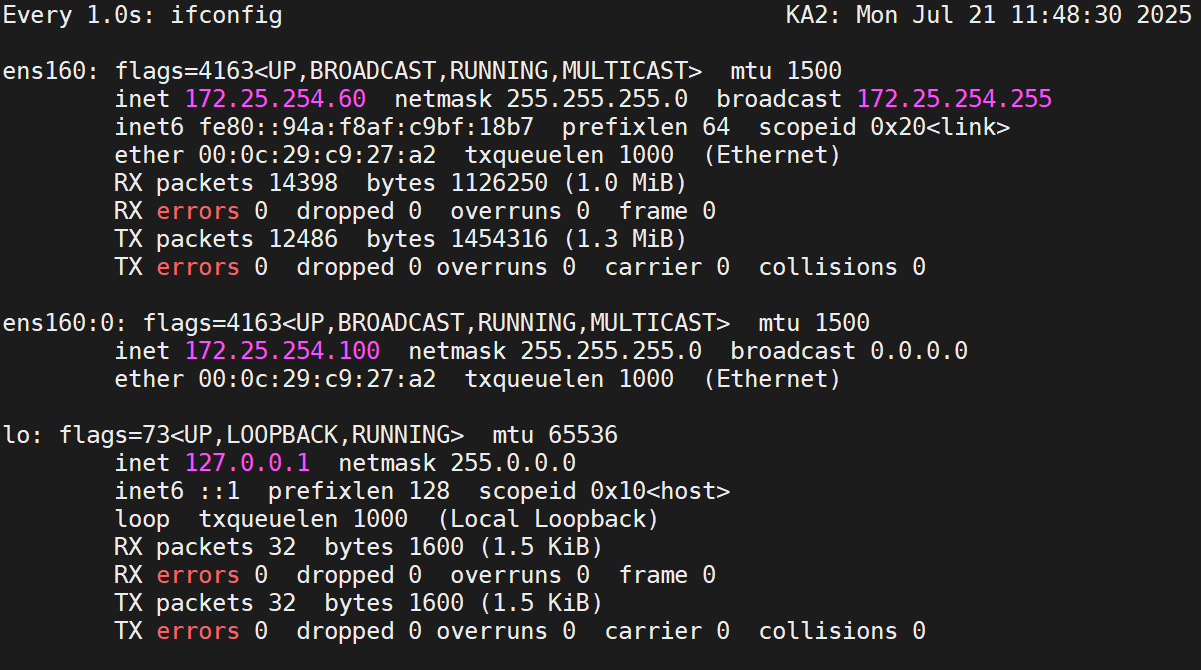
然后開多個窗口,在KA2上測試

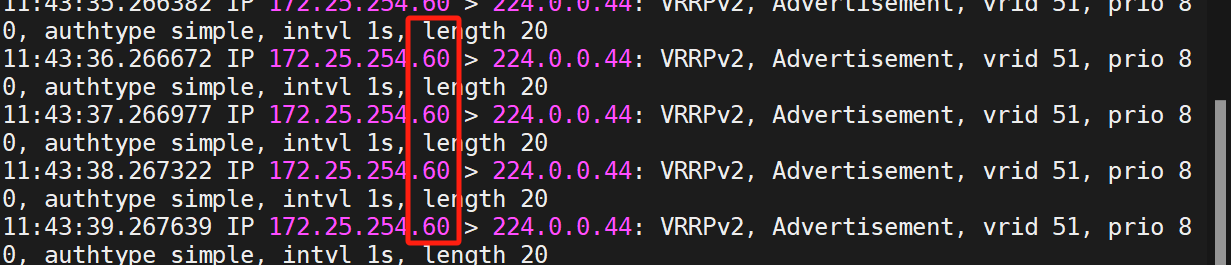
可以發現在KA1關閉的情況下,KA2正在承接服務(都是60)
這時我們再開啟KA1的keepalived服務

可以發現監視器變化了?
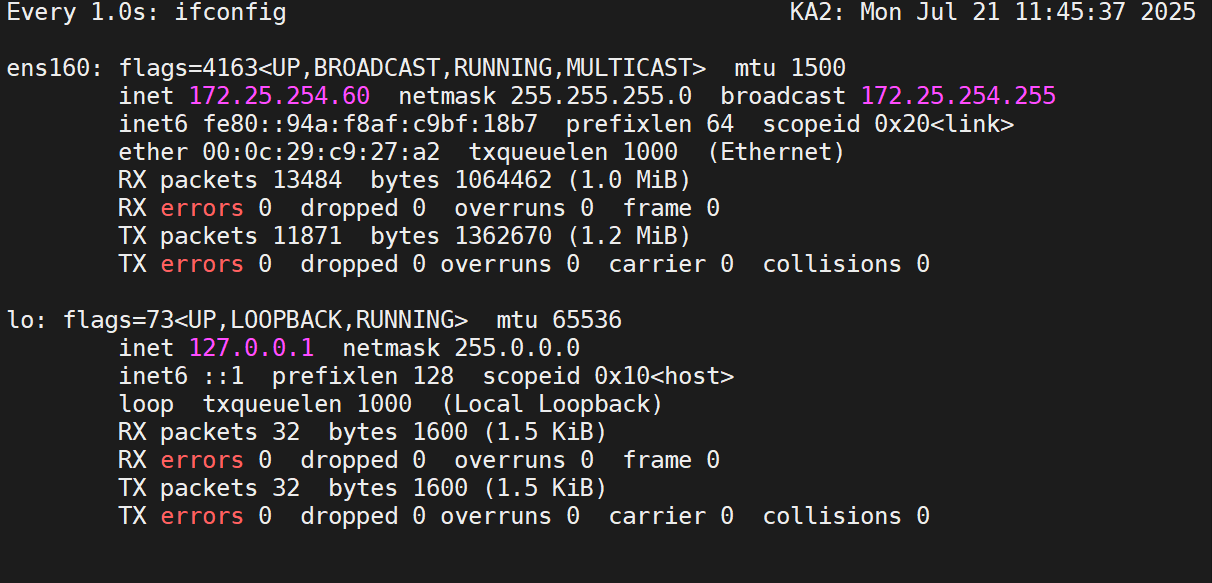
可以看到,10秒過后(即剛剛設定的延遲搶占)由60變成50了,即KA2變成KA1
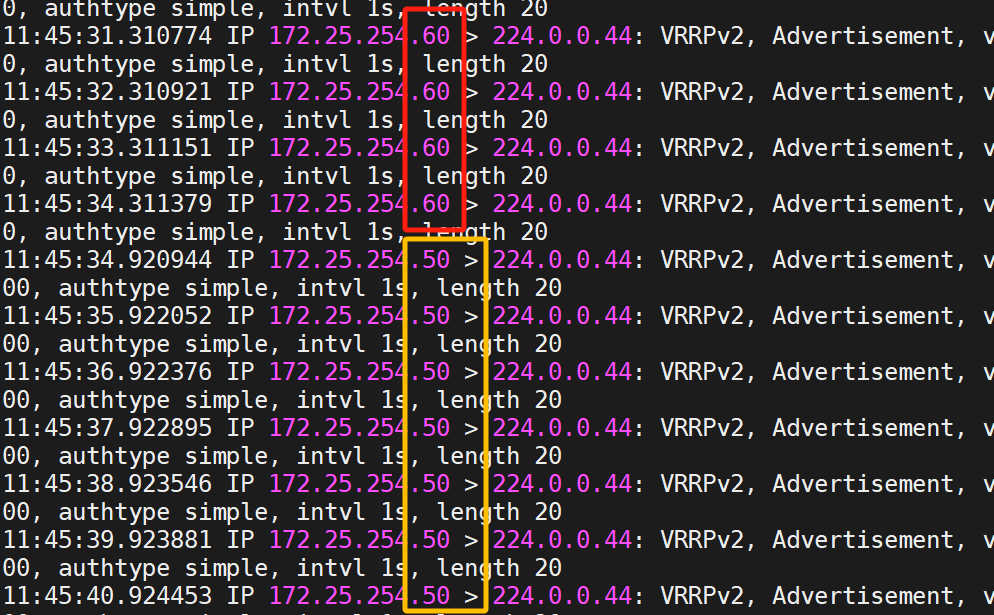
這就是延遲搶占
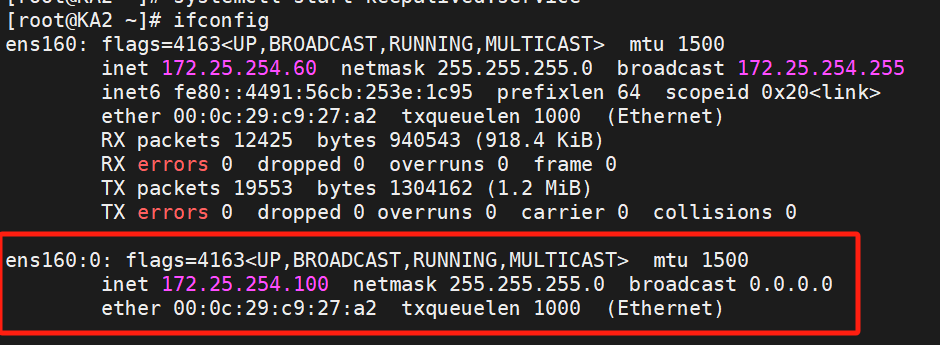
5、組播變單播
默認keepalived主機之間利用多播相互通告消息,會造成網絡擁塞,可以替換成單播,減少網絡流量
(1)還原實驗環境

KA2保持不變,就刪掉延遲搶占

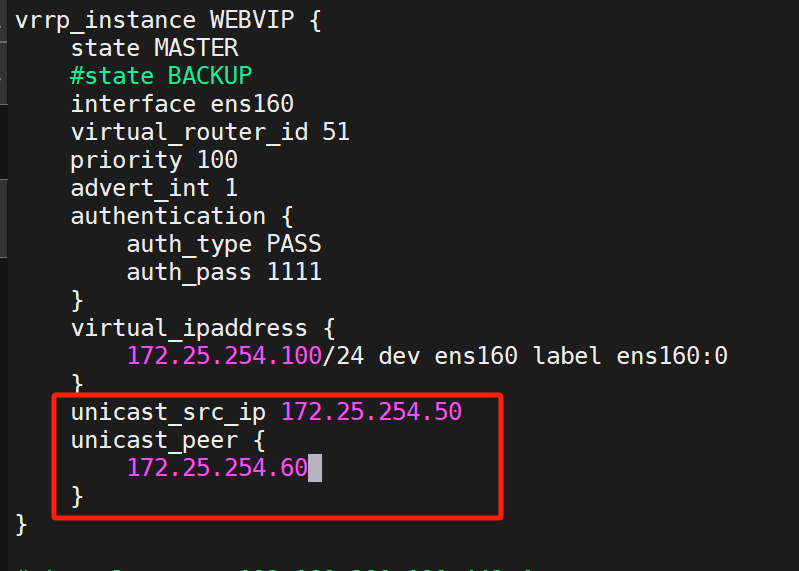
(2)設置單播
KA1與KA2設置單播:?
KA1:
![]()

KA2:
![]()
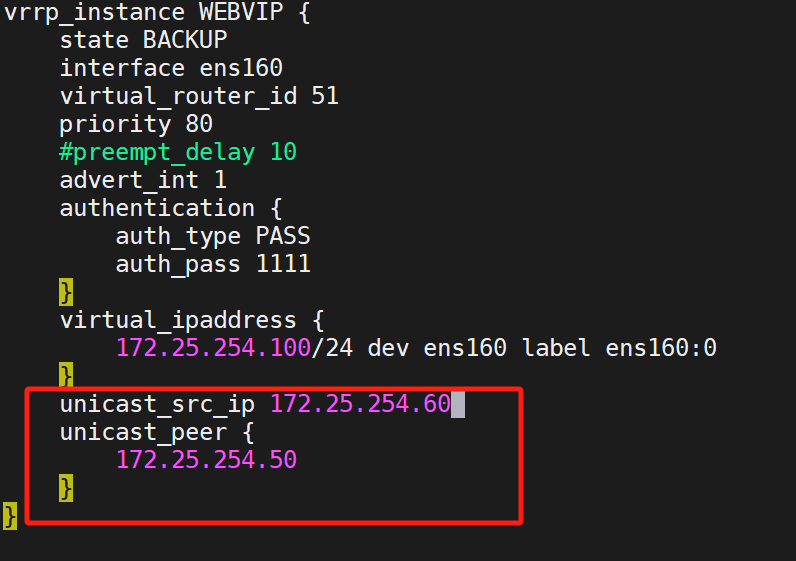

注意KA1與2ip不同,請注意
(3)測試
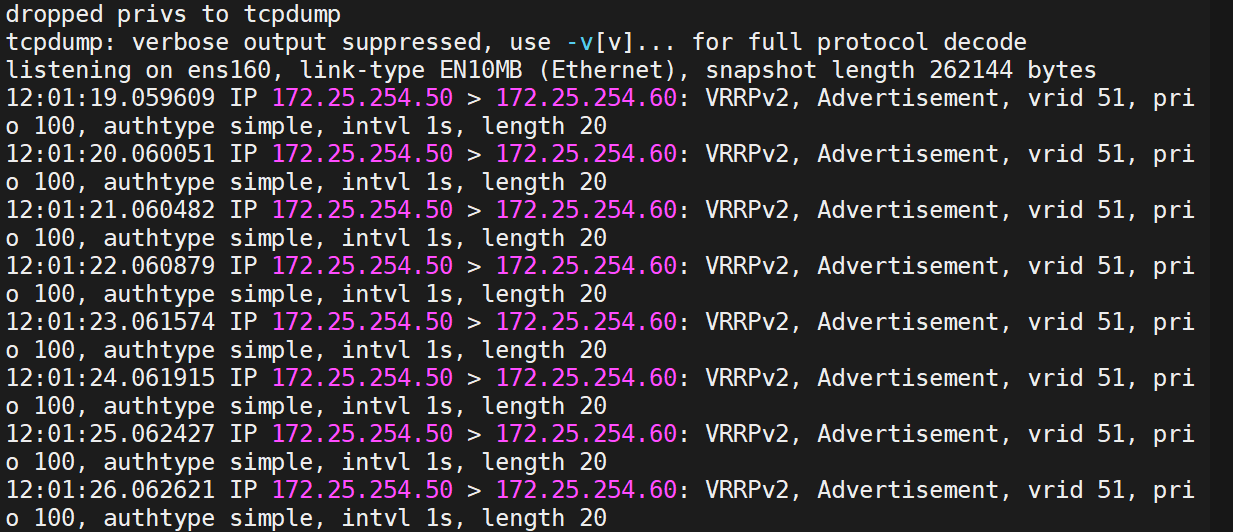
由此,組播變單播
6、郵箱配置
當keepalived的狀態變化時,可以自動觸發腳本的執行
所以我們做一個綜合實驗,此實驗目的是在兩臺KA切換主備、或者開啟停運時,通過郵箱來通知我們,告知我們他們的模式變化
(1)實驗

主機名設置成這種?


?![]()
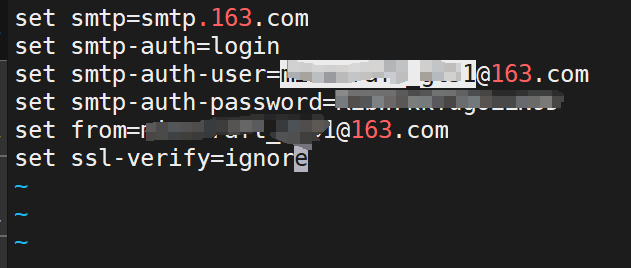
解釋:
- set smtp=smtp.163.com —— 這里的163是因為博主的郵箱是網易的,如果你的是別的,如qq,那就寫smtp.qq.com,其他郵箱類似
- set smtp-auth=login —— 登錄
- set smtp-auth-user=XXX@163.com —— 這里輸入自己的郵箱
- set smtp-auth-password=ABCDEFG1234567?—— 這里的碼是你自己的郵箱stmp認證得到的碼,待會詳細說明怎么獲得這個碼
- set from=XXX@163.com ——?這里輸入自己的郵箱
- set ssl-verify=ignore —— 忽略認證
如何獲取stmp認證得到的碼?(以網易為例)網頁登錄你的郵箱官網,點設置里的這個:
點開啟,這里博主啟動過了,所以顯示的是關閉,你們開啟上面的那個IMAP/SMTP的,不是紅框的那個
然后安裝他的提示繼續
之后就是輸入驗證碼那些,完成后就會出現那個碼了,復制到文件里

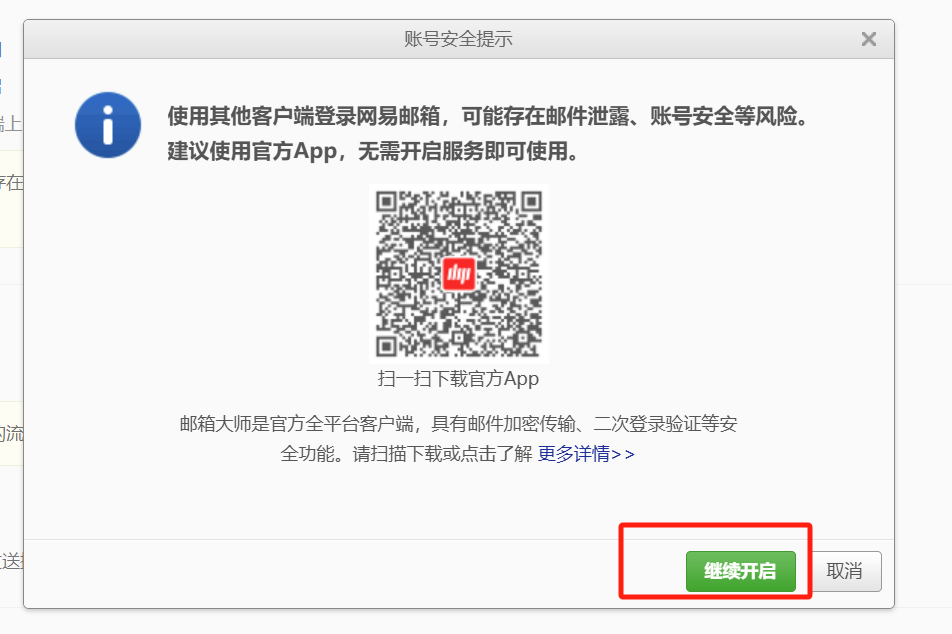
(3)測試
![]()
然后在自己的郵箱里找未讀
測試成功
(4)實戰例子:實現keepalived狀態切換的通知郵箱腳本

![]()
進入輸入這些:
#!/bin/bash
mail_dest='XXX@163.com'mail_send()
{mail_subj="$HOSTNAME to be $1 vip 轉移"mail_mess="`date +%F\ %T`: vrrp 轉移,$HOSTNAME 變為 $1"echo "$mail_mess" | mail -s "$mail_subj" $mail_dest
}
case $1 inmaster)mail_send master;;backup)mail_send backup;;fault)mail_send fault;;*)exit 1;;
esac
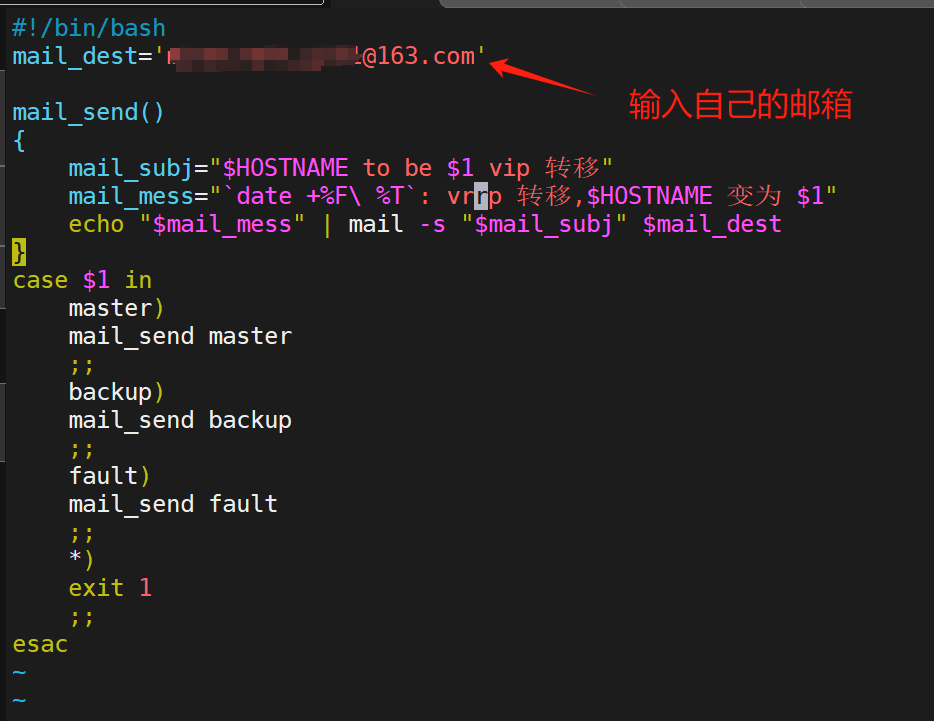
添加可執行權限
![]()
![]()
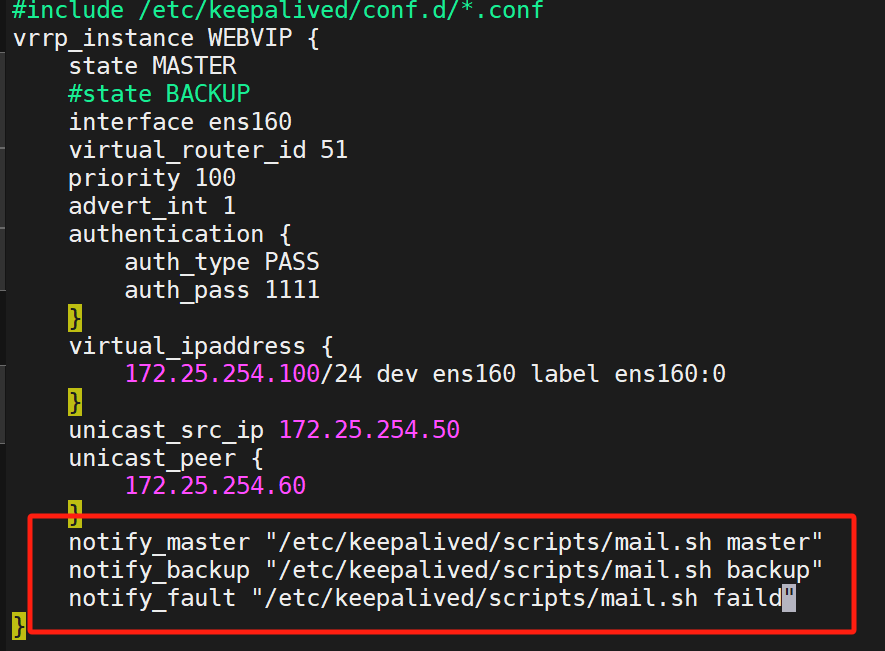
設完成之后,就會發現郵箱立馬收到了郵件:
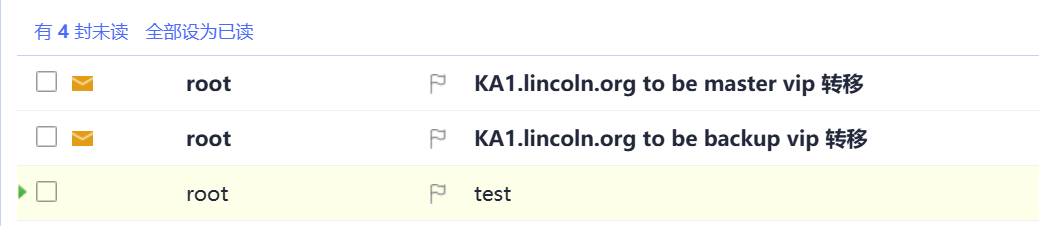
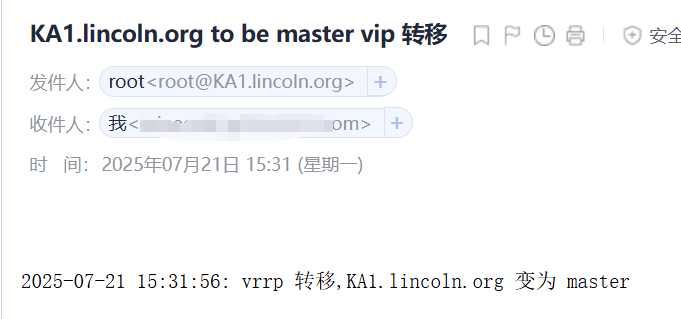
說明成功了,每當服務器主備轉換,還有開啟停機時,都會收到郵件
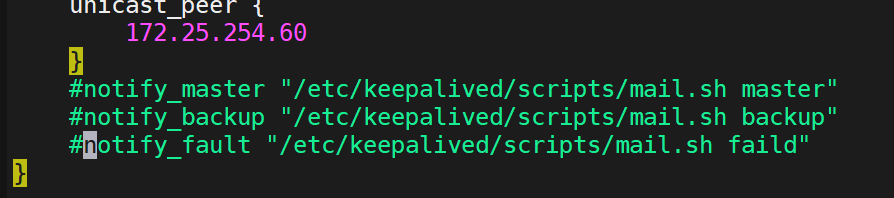
這個實驗完成后,建議把設置還原:
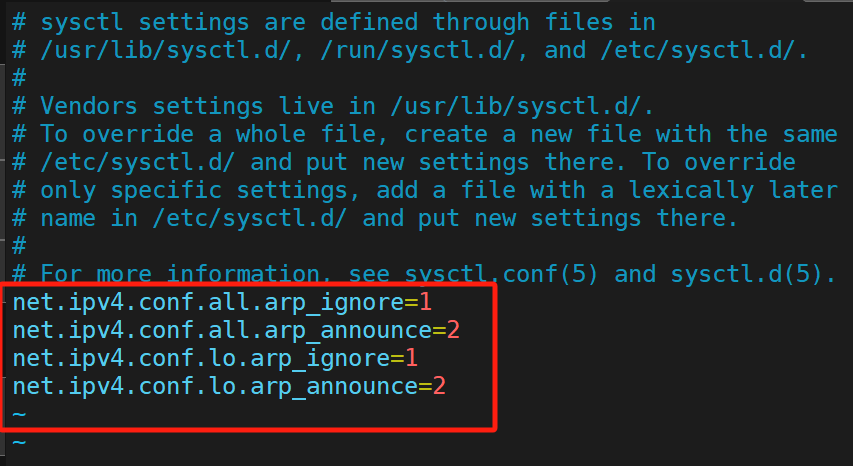
?7、RS的初步配置
我們介紹完了keepalived的基礎,準備開始搞Real Server的配置,且為了后面的實驗,我們也要把RS做了
(1)添加新ip
兩個RS都做:
![]()
![]()
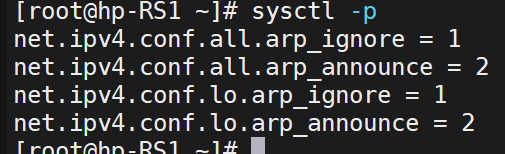
(2)配置KA1/2
兩個KA都要做:
?安裝ipvsadm(兩臺KA都要)?
![]()
![]()
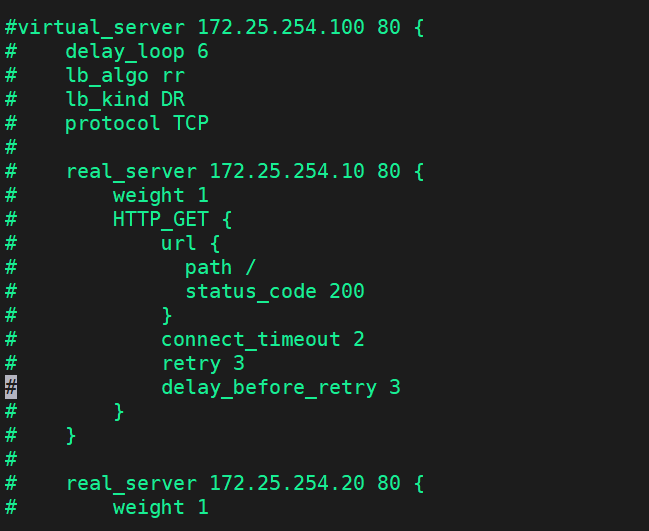
virtual_server 172.25.254.100 80 {delay_loop 6lb_algo rrlb_kind DRprotocol TCPreal_server 172.25.254.10 80 {weight 1HTTP_GET {url {path /status_code 200}connect_timeout 2retry 3delay_before_retry 3}}real_server 172.25.254.20 80 {weight 1TCP_CHECK {connect_timeout 2retry 3delay_before_retry 3connect_port 80}}
}
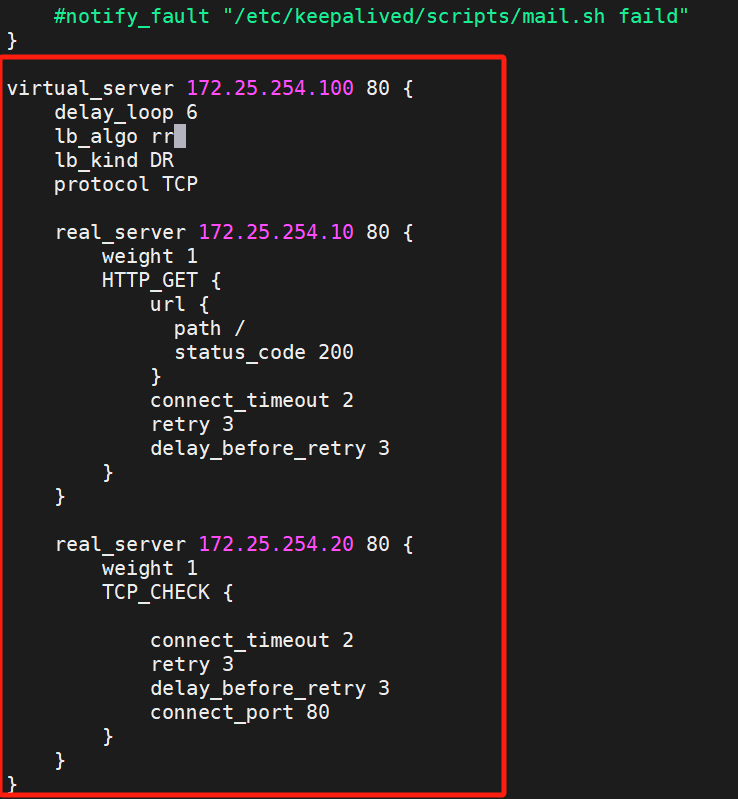
![]()
這樣就有策略了
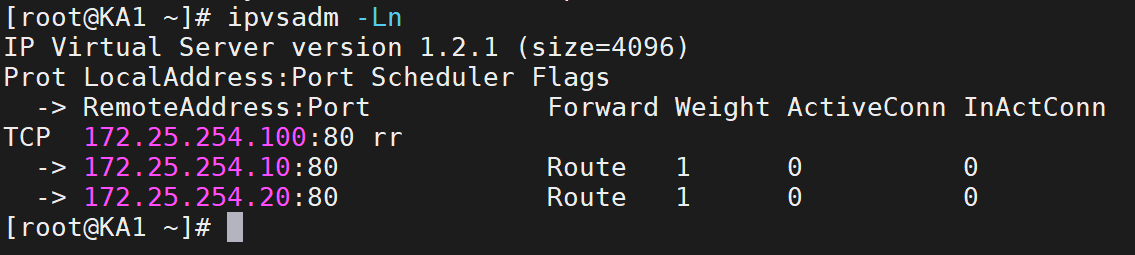
(3)測試
在KA1查看一下:
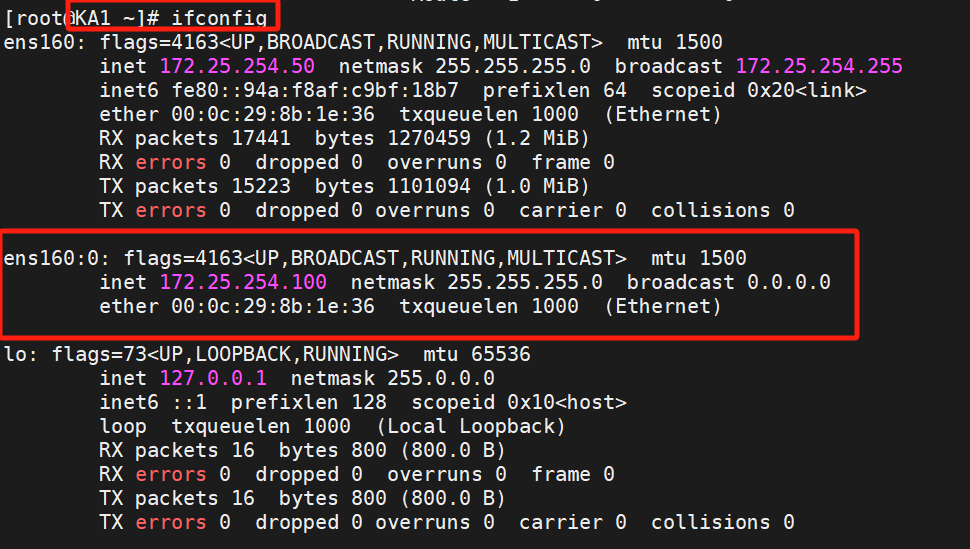
可以看到KA1是100ip的主,KA2是備
我們現在停掉KA1的keepalived,看它會不會自動轉到KA2這個備上:
![]()
可以看到100ip已經從KA1轉移到KA2這個備了
8、雙主架構
(1)概念
"雙主"(Dual-Master)在技術領域通常指兩種不同場景的高可用架構,需根據上下文區分理解。
master/slave的單主架構,同一時間只有一個Keepalived對外提供服務,此主機繁忙,而另一臺主機卻很空閑,利用率低下,可以使用master/master的雙主架構,解決此問題。
master/master 的雙主架構:
即將兩個或以上VIP分別運行在不同的keepalived服務器,以實現服務器并行提供web訪問的目的,提高服務器資源利用率
(2)實驗
我們做的是雙主組播,所以
關掉單播
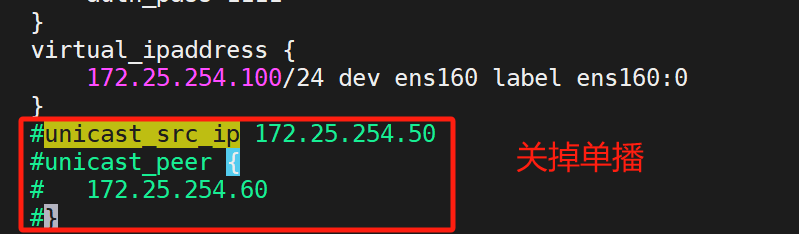
復制多一份上面的模板,改變這些:
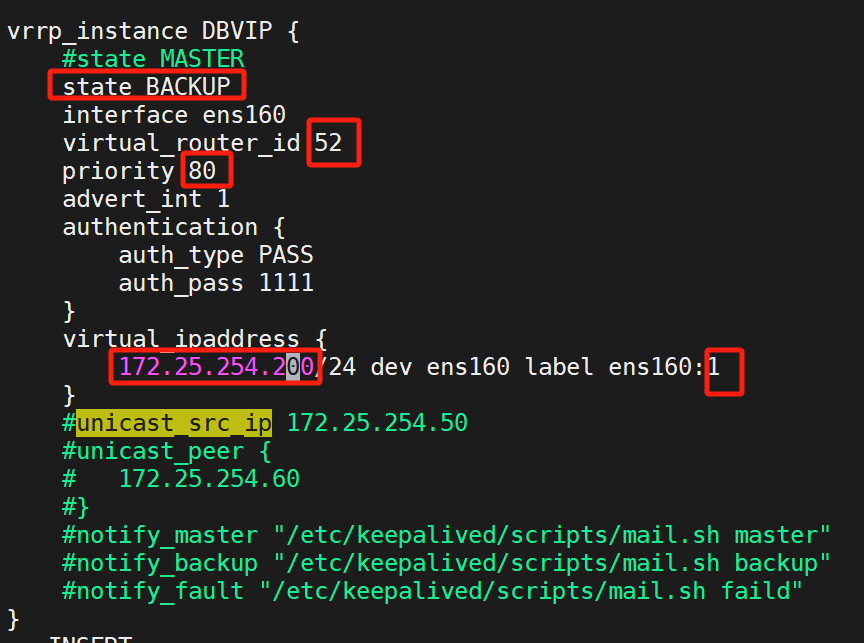
讓KA1做DBVIP的BACKUP
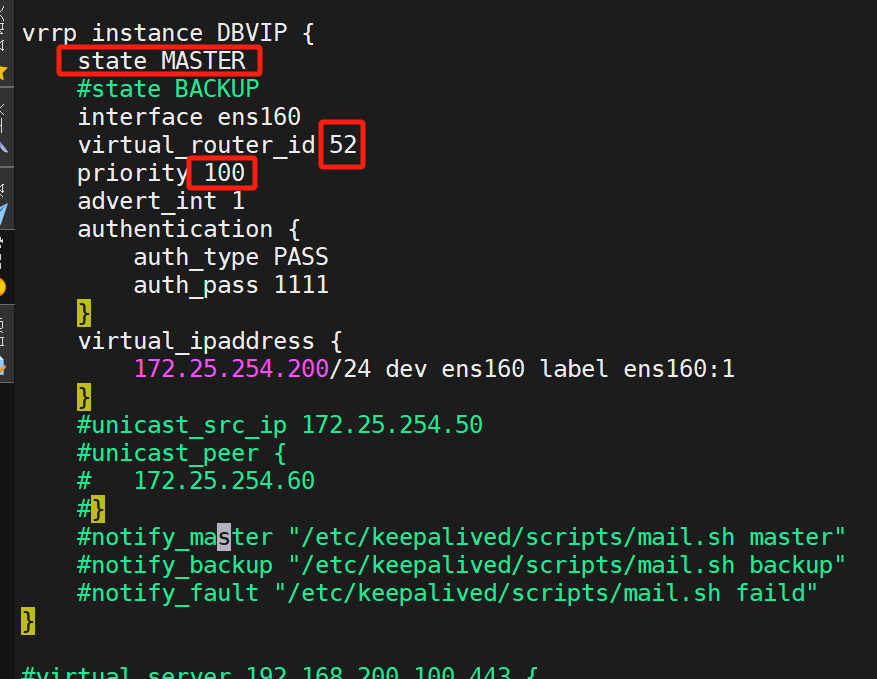
KA2是DBVIP的master:
(3)測試
在KA2上看,就能發現另一個組播,這就是雙主
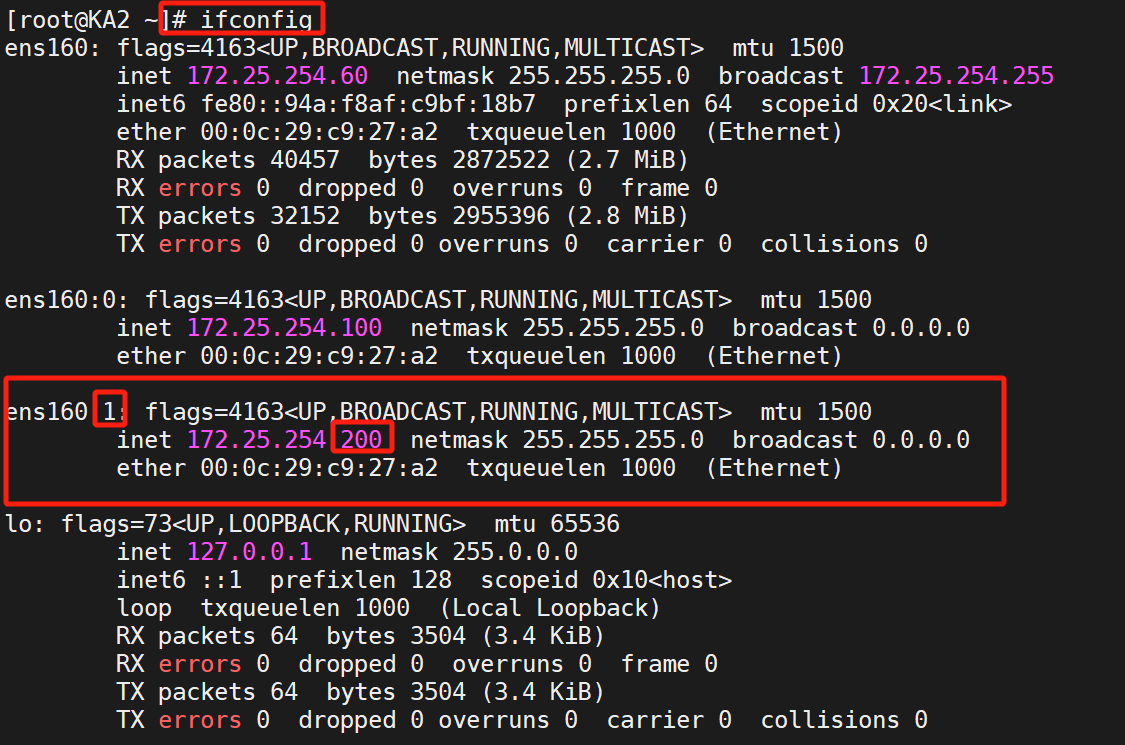
如果我們把KA2的keepalived關掉

那么就會變成KA1為MASTER:
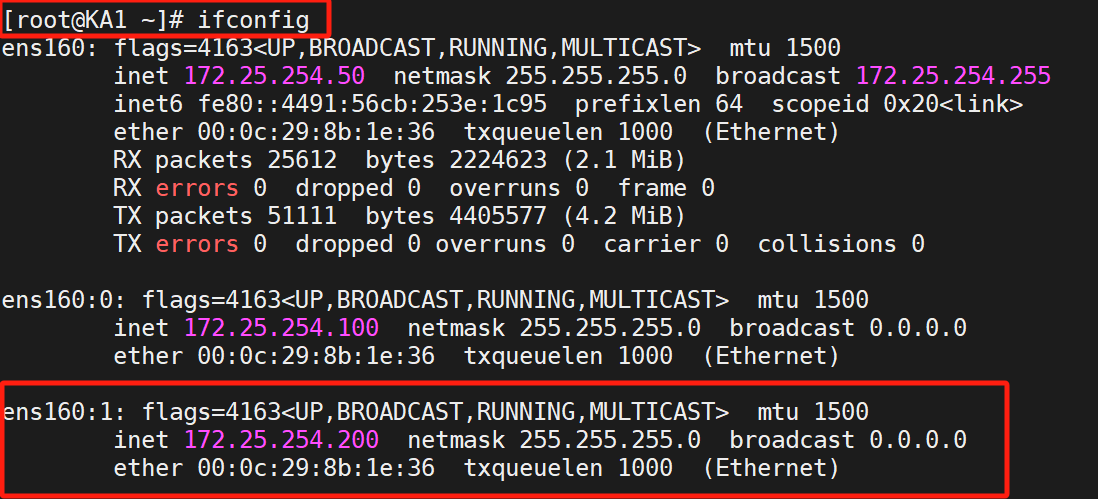
測試成功
(4)數據庫mariadb的雙主實驗
1)兩臺RS配置新的ip與啟動mariadb服務
兩臺RS都要做,配置命令相同

然后開啟兩臺RS的mariadb服務,最好systemctl status查看一下mariadb的服務是否開啟
兩臺RS都做,配置命令相同
![]()

再搞個開機自啟
兩臺RS都做,配置命令相同

2)兩臺KA配置數據庫雙主
兩臺KA都要做,配置命令相同
![]()
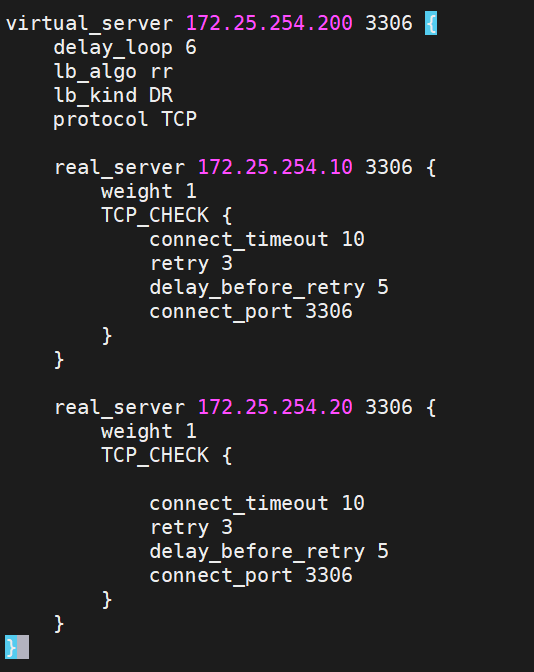
檢測一遍,然后重啟

查看一下策略
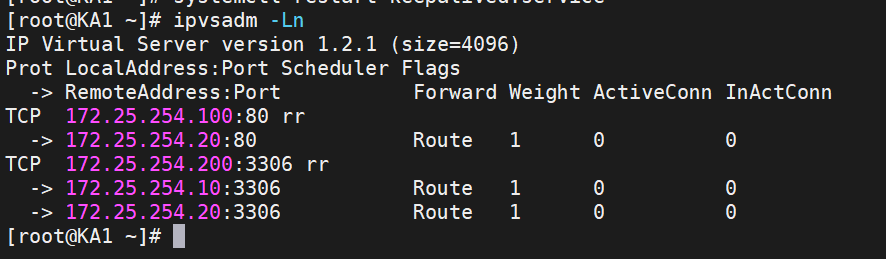
可以發現已有3306端口的策略
3)測試
在Client測試機上測試(該機子已經在先前博客出現過,配置了mariadb)
mysql -ulee -plee -h 172.25.254.200 -e 'select @@server_id'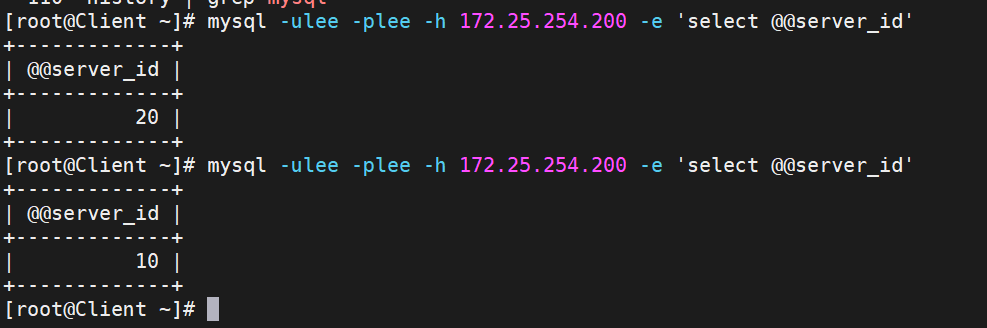
關掉RS2的mariadb服務再測試
![]()
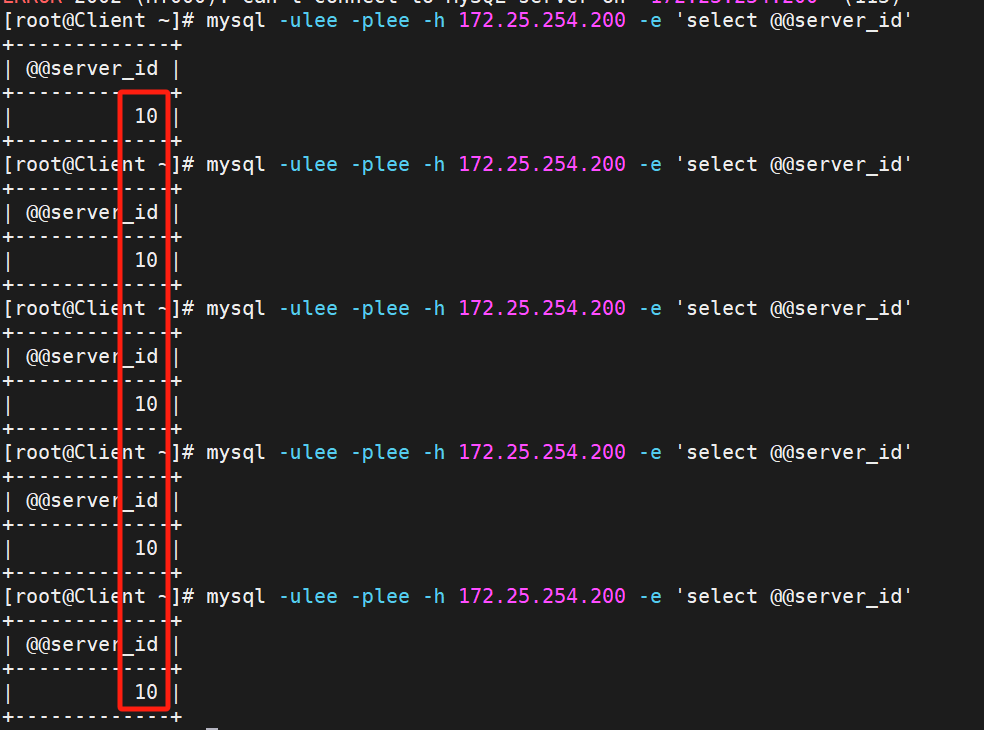
過一會,再測試就會發現只剩RS1的10
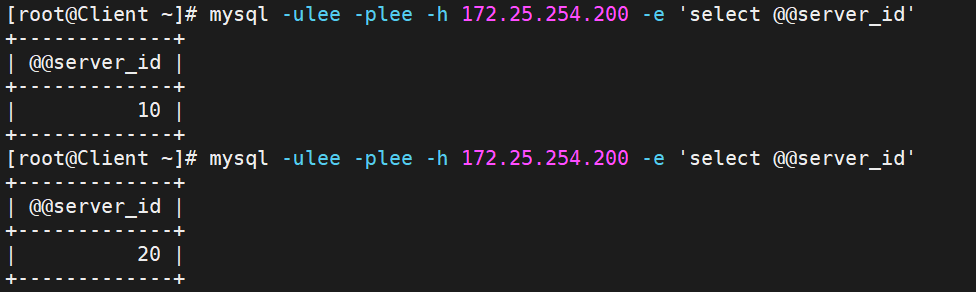
重新開開
![]()
就又能輪詢了
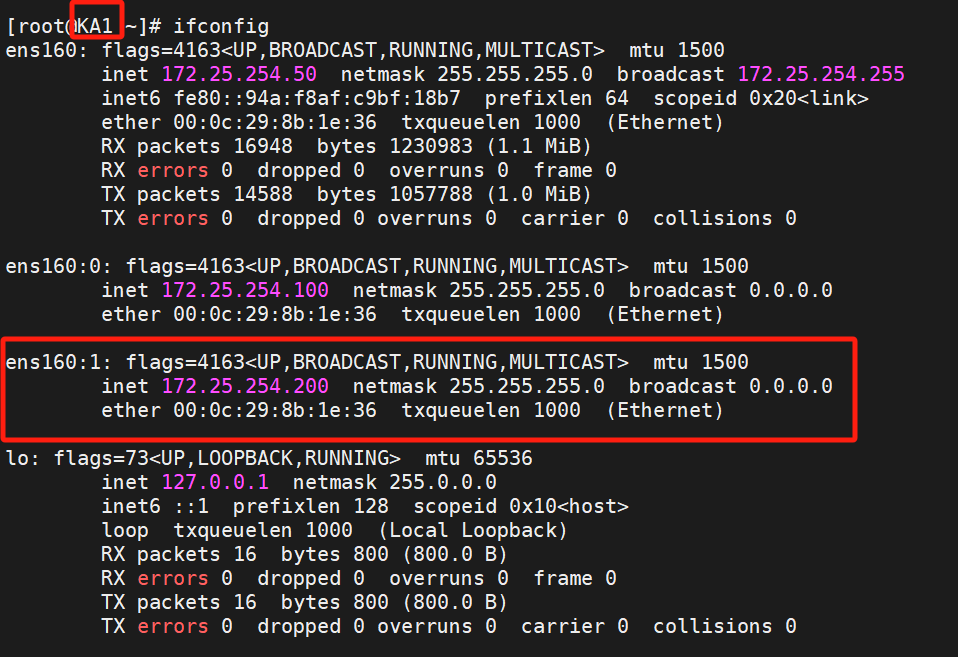
在KA2查看一下,就能看到200ip的主是KA2
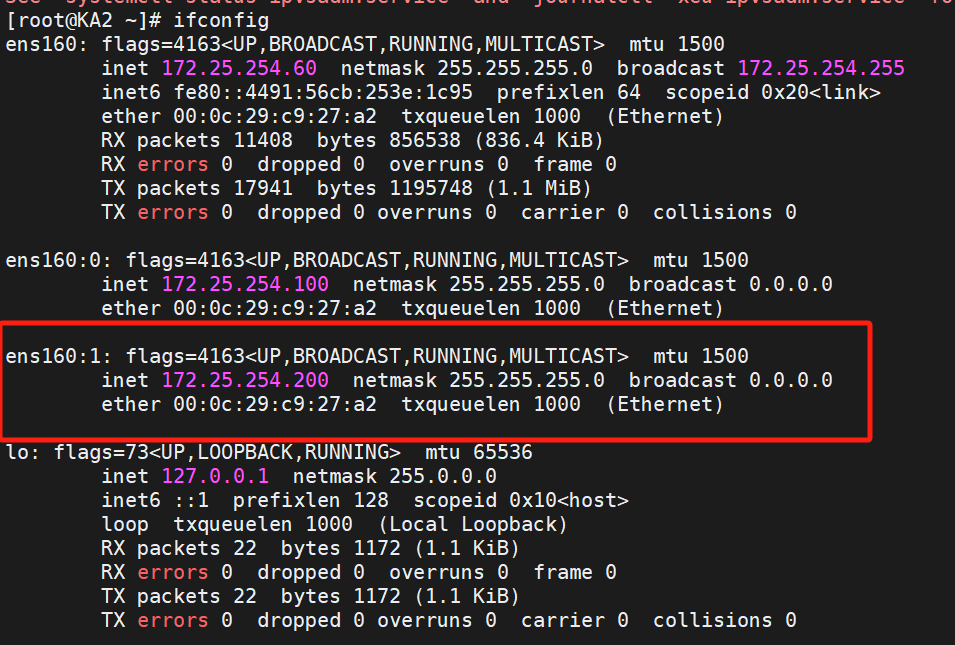
所以我們:
關閉KA2的keepalived服務再測試
![]()
這是我們發現服務能夠繼續,因為服務已經從主遷移到備了,不影響
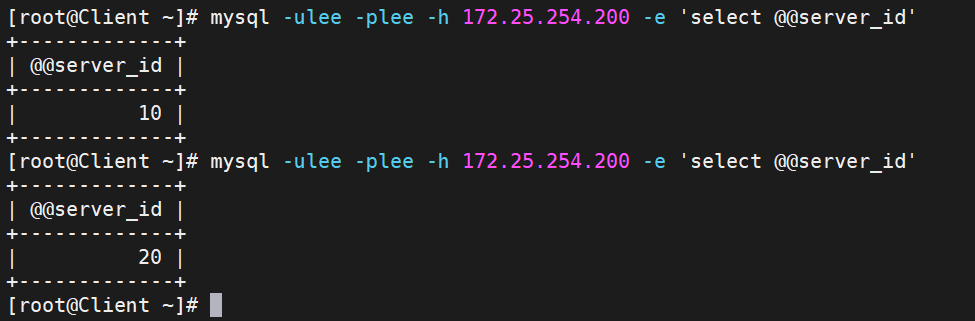
測試完記得重新起開
![]()
9、VRRP Script
(1)概念
VRRP Script 是?Keepalived?中一個極其重要的功能模塊,它允許你通過自定義腳本來動態監控系統狀態(如服務進程、資源利用率、網絡連通性等),并將監控結果反饋給 VRRP 協議棧,從而影響 Master 節點的選舉優先級或觸發狀態切換。它是實現基于應用健康狀態的高可用性(HA)?的核心機制。
1)核心作用與原理
擴展監控能力:
默認的 VRRP 只能監控 Keepalived 守護進程本身和網絡接口的存活狀態。
VRRP Script 讓你能夠監控任何你關心的東西:例如 Nginx/MySQL 進程是否在運行、Web 頁面是否可訪問、磁盤空間是否不足、CPU 負載是否過高、到某個關鍵服務的網絡是否通暢等。
動態調整優先級:
你定義一個腳本 (
vrrp_script?塊) 和一個監控間隔 (interval)。Keepalived 會周期性地(每隔?
interval?秒)執行這個腳本。腳本的退出狀態碼 (Exit Code)?決定了監控結果:
0?(成功 / OK): 表示被監控項健康。腳本可以什么都不做直接?exit 0。1?(警告 / WARN):?通常?也被視為健康(取決于配置),但可能用于記錄日志或輕微通知。(實踐中較少嚴格區分 1 和 0 的效果,主要關注非 0 是否觸發故障)>1?(錯誤 / FAIL): 表示被監控項不健康。
根據腳本的退出碼(特別是非 0),Keepalived 可以動態調整該節點在 VRRP 實例 (
vrrp_instance) 中的?priority?值。
觸發狀態切換:
當一個節點的優先級因為?
vrrp_script?檢測到故障而降低時:如果它原來是 Master,并且降低后的優先級低于某個 Backup 節點的優先級(通常是初始優先級),那么 Backup 節點會感知到 Master 優先級變低。
Backup 節點(現在擁有更高優先級)會發起選舉,將自己提升為新的 Master,并接管 Virtual IP (VIP)。
當故障恢復,腳本返回?
0?時:節點的優先級會恢復到初始值。
如果這個節點現在的優先級高于當前 Master 的優先級(通常是因為原 Master 可能也降權了或者這個節點初始優先級就很高),它可能會重新奪回 Master 身份(取決于?
nopreempt?配置)。
2)配置選項解釋?
vrrp_script <SCRIPT_NAME> {script "<COMMAND_OR_PATH_TO_SCRIPT>" # 要執行的命令或腳本的完整路徑interval <SECONDS> # 執行間隔(秒),如 2, 5, 10timeout <SECONDS> # 腳本執行超時時間(秒),超時視為失敗weight <-254 TO 254> # 權重值(最重要!決定優先級如何變化)fall <INTEGER> # 連續失敗多少次才認為故障 (默認 1)rise <INTEGER> # 連續成功多少次才認為恢復 (默認 1)user <USERNAME> [GROUPNAME] # 以哪個用戶(組)身份運行腳本(可選,默認 root)
}
script:?核心指令。可以是:
一個簡單的 shell 命令:
script "killall -0 nginx"?(檢查 nginx 進程是否存在)一個自定義腳本的完整路徑:
script "/usr/local/bin/check_mysql.sh" (路徑情況最普遍)腳本需要有可執行權限 (
chmod +x)。
interval:?多久執行一次監控腳本。太短增加負擔,太長延遲切換。常用 2-10 秒。
timeout:?腳本必須在此時長內完成,否則強制終止并視為失敗。應略大于腳本預期執行時間。
weight?(核心參數!):?腳本執行結果如何影響優先級 (priority)。
正值 (e.g.,?
weight 20):
腳本成功 (
exit 0): 給當前優先級?加上?weight?值。腳本失敗 (
exit > 0):?不改變?當前優先級。作用: 健康時提高本節點優先級,更容易成為/保持 Master。故障時只是失去“加分”,如果初始優先級夠高,可能還是 Master(需結合?
fall/rise?判斷)。負值 (e.g.,?
weight -20):
腳本成功 (
exit 0):?不改變?當前優先級。腳本失敗 (
exit > 0)): 給當前優先級?加上?weight?值(即減去絕對值)。作用:?健康是常態,不額外加分。故障時直接懲罰(降權)。這是最常用、最直觀的方式!故障時優先級降低,更容易被 Backup 超越。
值的大小:?絕對值通常設置為大于?VRRP 實例中 Master 和 Backup 之間初始優先級的差值。例如 Master 初始 prio=100, Backup=90,差值=10。那么?
weight -25?是合理的,這樣 Backup 在 Master 故障后優先級 (90) 會高于降權后的 Master (100 - 25 = 75)。如果?weight?絕對值太小(比如 -5),降權后 Master(95) 仍高于 Backup(90),就不會切換!
fall:?腳本連續失敗多少次才觸發降權操作(認為真的故障了)。默認為 1(一次失敗就降權)。設置為 2 或 3 可以防止短暫抖動導致的誤切換。
rise:?腳本連續成功多少次才觸發恢復操作(認為真的恢復了)。默認為 1(一次成功就恢復)。設置為 2 或 3 可以確保服務穩定恢復后才提升優先級/嘗試搶占。
user:?以非 root 用戶運行腳本,提高安全性(如果腳本不需要 root 權限)。
(2)實驗——通過腳本控制haproxy(實現HAProxy高可用)
1)注釋之前配置的virtual-server配置
兩臺KA都配置
![]()
![]()
只要是virtual-server開頭的都注釋掉,兩臺KA都配置
注釋后ipvsadm看一下

像這樣沒有策略就行
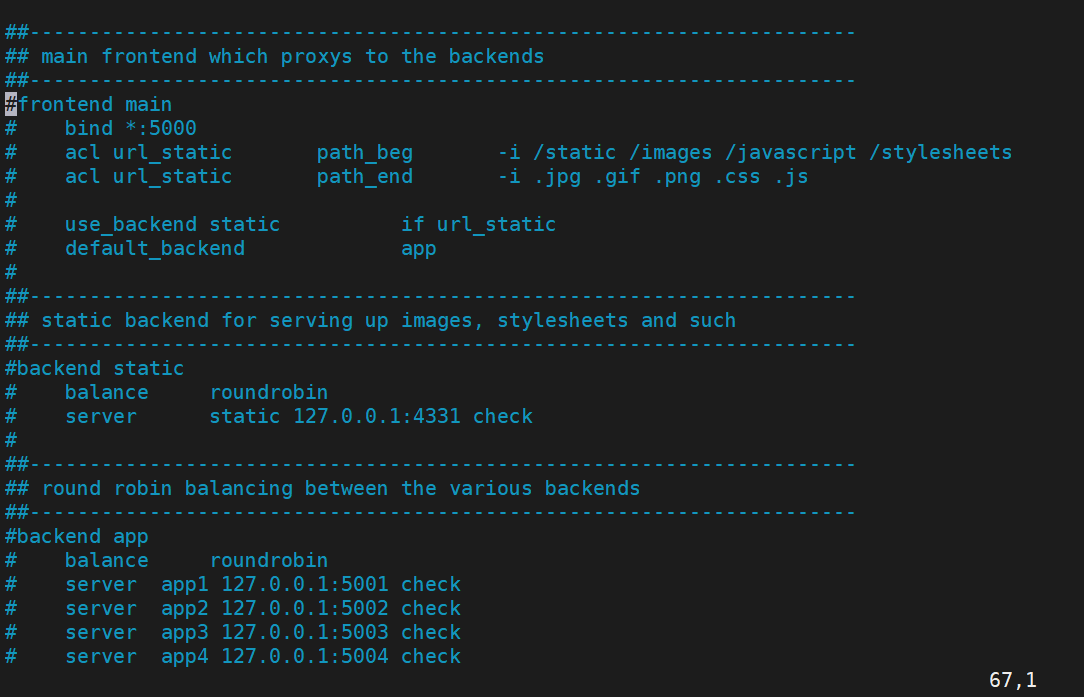
2)安裝haproxy和編輯其配置文件
兩臺KA都安裝
 ?
?
進入配置文件,修改編輯:
![]()
先注釋掉后面這些:
創建新的Listen
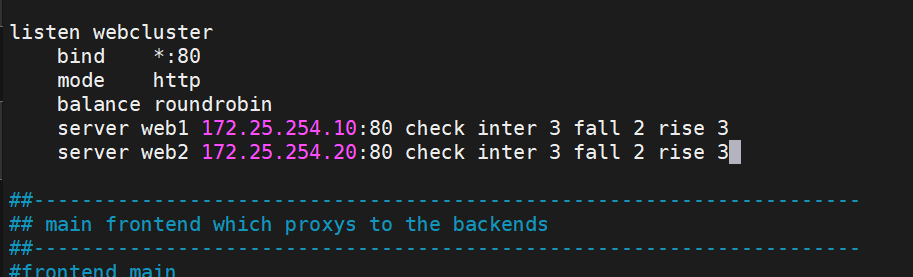
![]()
配置開機自啟

KA1與2配置命令相同,記得KA2也配置
2)配置非MASTER也有ip
兩臺KA都配置
復制紅框

然后echo寫進去:
![]()
執行一下

另一臺KA一樣配置
配置完后,查看一下haproxy的80端口


3)編寫腳本
![]()
注意:這個keepalived底下的scripts目錄是博主自己建立的,你們在做的時候自己記得建立
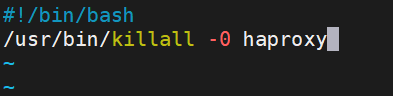
這個腳本寫的是檢測haproxy服務活不活的命令
wq
給腳本可執行權限

確保所有主機的SELinux和火墻是關閉狀態
進入keepalived配置文件配置腳本
在KA1上配置
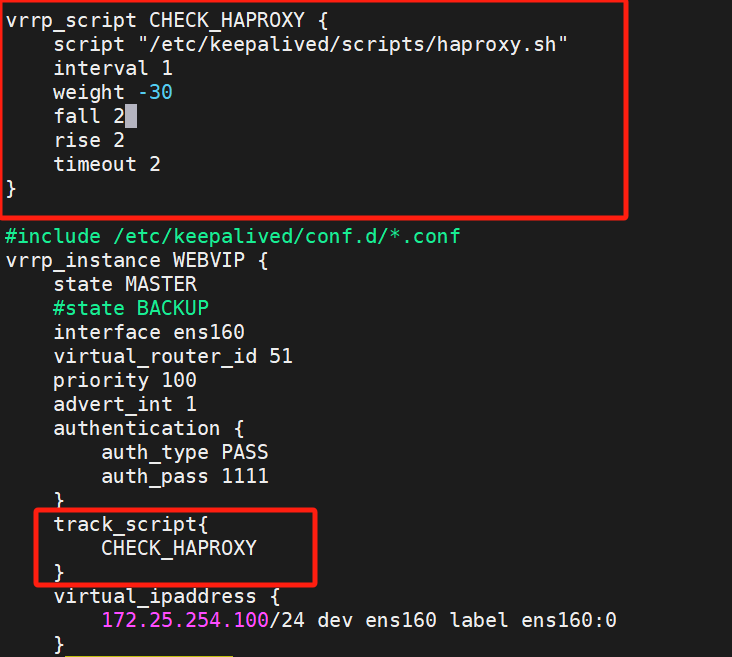
配置完重啟:

4)測試
然后運行腳本
![]()
此時我們沒停止KA1的haproxy時,腳本的返回值是正常,即為0

此時,我們關閉KA1的haproxy服務

腳本就會檢測到haproxy停止,這時腳本的返回值應該是變成1
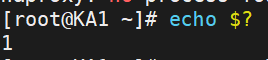
這樣就說明腳本運行成功
測試完記得把KA1的haproxy開回來







分布式事務)




)
詳解多回答筆記250722)
解析器)





