前言:
大家好啊,我們上一篇文章已經講解了關于線程同步的一種辦法:運用條件變量cond。
今天,我們就來學習一下線程同步的另外一種方法,信號量!!
信號量呢有System V 信號量與POSIX 信號量,我們這里主要還是講POSIX信號量,System V主要還是用于進程間通信的比較多一些。
一、生產者消費者模型再理解
我們在上篇文章講的生產者消費者模型大家還記得嗎?
生產者申請鎖,開始生產,如果此時為滿,就通知消費者的條件變量,讓消費者開始動起來。
這整體過程不是串行的嗎?那我們說生產者消費者模型的高效性?從何談起呢?
我們不能單一的去看這個過程,這個效率問題要從整體上來看待。為什么說他高效?關鍵在“并行化重疊”?。
大家注意,生產者生產數據,那么這個數據從哪里來呢?
是不是也需要有人傳給生產者?此時生產者是不需要鎖進入臨界區的。那么這個時候消費者在干什么呢?消費者是不是就可以持有鎖,讀取臨界區資源啊!!那么消費者讀取完了還會干什么?他會把鎖解鎖,然后對拿到的資源進行處理。此時生產者就可以對臨界區進行生產了。
生產者和消費者,不就并行起來了嗎?
所以,我們這里有個緩沖隊列,就是為了解耦生產者和消費者的速度差異,允許兩者并行執行。
二、 什么是信號量Sem
信號量是一種用于協調多線程/多進程對共享資源訪問的同步機制,由計算機科學家?Edsger Dijkstra?在1965年提出。它的核心是一個計數器?+?等待隊列,通過原子操作控制資源分配,解決并發編程中的競態條件和死鎖問題。
我們該如何理解信號量的概念呢?
在面對需要對臨界區資源整體的使用時,我們提出來互斥鎖的概念。
如果我們對臨界區資源不是整體使用的時候呢?我們還是使用鎖嗎?
為了方便大家理解,我們可以舉一個電影院的例子。
這個電影院的每一個房間的座位是不是固定的啊?
就相當于有固定的這么多份的資源。信號量,就相當于是電影票。
你申請信號量,就是購買電影票,無論你今天是否到了現場去看電影,這個座位都只會是你的,而不能被被人使用。
這就是信號量保護不是整體使用臨界區資源的效果。
信號量可以看作是一個計數器,申請信號量本質上是對資源的預定機制。我們有這么多的座位,就可以放這么多數量的票。
三、信號量接口與原子性問題
?我們接下來介紹一下信號量的相關接口,system信號量是系統級接口,所以使用十分復雜。
但我們的Sem信號量是用戶級的,所以接口的使用就像之前的條件變量,鎖一樣簡單,主要常用的幾個接口如下:
int sem_init(sem_t *sem, int pshared, unsigned int value);
這是用來初始化一個信號量的函數,就跟我們之前的鎖與條件變量一樣,也是需要先定義一個sem_t類型的變量,隨后調用該函數對他進行初始化。
sem:信號量變量指針。
pshared:為0,線程間共享(同一進程內)。非0:進程間共享(需放在共享內存中)。
value:信號量初始值(如資源初始數量,就跟電影票的數量一樣)。
?
int sem_destroy(sem_t *sem);
負責信號量的銷毀。
注意:
必須確保信號量未被任何線程/進程等待,且無名信號量(sem_init創建)必須顯式銷毀。
int sem_wait(sem_t *sem); // 阻塞等待 int sem_trywait(sem_t *sem); // 非阻塞嘗試 int sem_timedwait(sem_t *sem, const struct timespec *abs_timeout); // 超時等待?
?等待一個信號量,我們通常使用第一個。這個等待操作我們后面統稱為P操作。
int sem_post(sem_t *sem);
釋放一個信號量,讓他的值加一,并喚醒一個等待的信號量(如果有)。
int sem_getvalue(sem_t *sem, int *sval);?
獲取當前信號量的值,就是查看還剩多少票。注意,這個sval是一個輸出型參數,結果就是剩余的票。
這里我們要特別說明一下,我們之前說過,申請一個信號量就相當于讓 信號量的值減一,釋放一個信號量就相當于讓一個信號量的值加一,這里我們得特別注意,這里的加一減一的操作不可能是--或者++。
為什么呢?
我們之前說過,++與--并不是原子性的操作,我們信號量是保證臨界區資源安全的操作,所以大家都會看到信號量,所以信號量本身跟鎖一樣,也是一個共享資源,他是共享資源,想要保護別人,誰來保護她??
所以,他自己本身就必須具備原子性,否則連自己的安全都顧不了,怎么顧及別人。
所以他的加一減一是通過?硬件級原子指令(如CAS、TSL)實現的。
四、基于環形隊列的消費者生產者模型
我們現在就來實現一下這個環形隊列的消費者生產者模型,因為這個很貼近我們剛剛講的信號量內容,他滿足里面的數據時是分隔開可以錯開被訪問的。
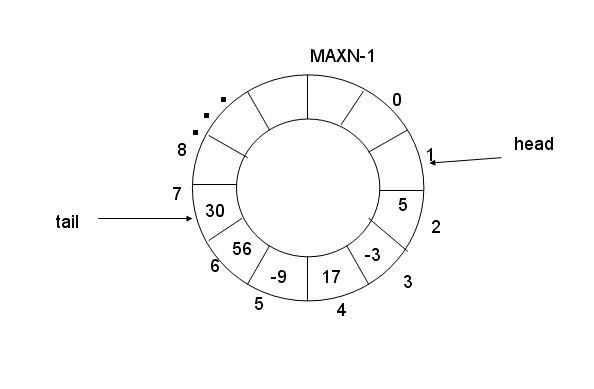
之前講的隊列存在許多弊端,比如高強度的pop與push的內存釋放,以及激烈的鎖競爭關系。
而我們的環形隊列是怎么解決的呢?
我們選擇底層使用數組來實現環形(這個方法在C++中應該用過吧,通過控制數組的下標來實現環形結構),這樣我們只需要更改數據就行了。
我們保存的最大數據容量是數組的大小,使用了信號量來記錄消費者與生產者的位置,所以我們可以知道是否滿了,從而防止新增數據時替換我們還沒被消費者使用的數據。
總的來說,對于這個模型而言,一共有如下幾種情況:
1、訪問數據時生產者與消費者訪問到了同一個位置。雖然我們說整個臨界區可以錯開使用,但是如果此時你沒有錯開,是不是就要串行使用了啊?
沒錯,此時我們有兩種情況:
? ? ? ? 1、訪問到同一個地方是因為數據為空了(我們默認消費者是按照生產者生產的順序訪問的數據)。既然為空,那我們的串行是不是要保證生產者先運行(你此時都沒數據消費者怎么消費呢?),那么具體要執行那些動作呢?? ? ??
????????是不是要先對生產者的信號量進行P操作(申請信號量,就是申請門票),隨后我們進行數據的填充,之后再讓我們的下標++,此時有數據了,我們就可以對消費者的信號量進行V操作,喚醒等待的消費者。
? ? ? ? 2、訪問到同一個地方,是因為數據滿了。既然滿了,那我們是不是先讓消費者消費數據?所以我們就對消費者的信號量值進行P操作(減一,注意,生產者的信號量值表示剩余的空間,消費者的信號量值表示剩余沒使用的數據),之后對數據進行提取操作,隨后讓下標移動,最后喚醒我們等待的消費者。
2、?訪問數據時,生產者與消費者沒有訪問到了同一個位置。這個時候就簡單了,此時他們沒有訪問同一個資源,自然就可以并發的執行了。
?
大家可以這樣理解以上過程:
我們有一個大小為20的環狀箱子。
生產者負責先放蘋果,消費者負責拿蘋果。=,二者都是放(拿)一個蘋果,才能移動到下一格。
如果此時里面一個蘋果都沒有,消費者是不是就走不動路,所以此時只能生成者放完蘋果消費者才能動。
如果全是蘋果,生產者就走不動了,只能等自己下一格的(環狀)消費者拿起來一個蘋果后才能移動。
相當于一個追逐游戲,一個放一個拿
我們永遠無法給對方套圈(跑步時超了別人一圈叫做套圈),如果我們訪問同一個位置,就串行,如果不是,就可以并發運行。
我們基于代碼實現一下上面的環形隊列,在此之前,我們可以先封裝一下我們的信號量接口,就跟封裝條件變量一樣:
#pragma once
#include <semaphore.h>namespace SemMudule
{const int defalutsemval = 1;class sem{public:sem(int semval = defalutsemval):_init_value(semval){::sem_init(&_sem,0,_init_value);}void P(){::sem_wait(&_sem);}void V(){::sem_post(&_sem);}~sem(){::sem_destroy(&_sem);}private:sem_t _sem;int _init_value;};
}所以這里我就不多說了。
而我們的環形隊列需要哪些變量呢?
首先,我們的底層是數組,所以需要一個數組,還需要一個整數來記錄數組大小。
另外我們的生產者與消費者的下標位置,也各自需要一個整形來記錄,還有生產者與消費者各自的信號量,所以代碼可以先寫成這樣:
#pragma once#include <iostream>
#include <vector>
#include <pthread.h>#include "sem.hpp"
#include "mutex.hpp"namespace RingBufferModule
{using namespace SemMudule;template<typename T>class ringbuffer{public:ringbuffer(){}~ringbuffer(){}private:std::vector<T> _buffer;//環形緩沖區size_t _size;//緩沖區大小sem _psem; //生產者信號量sem _csem; //消費者信號量size_t _p_step; //生產者下標size_t _c_step; //消費者下標}
}那我們接下來要做的就是完善我們的構造函數,并實現pop與equeue接口:
在構造函數中,我們需要對各個變量進行初始化:
ringbuffer(int cap)//cap為外界傳進來的環形隊列的大小:_size(cap),_buffer(cap),_psem(cap),_csem(0),_p_step(0),_c_step(0){}然后我們要實現我們的插入與取出數據,在前面我們已經說過細節,就是在插入新數據時,是生產者的動作,所以生產者對自己的信號量進行申請,使其減一(代表剩余空間減一),隨后進行替換數據操作,最后移動下標并喚醒阻塞的消費者(如果有阻塞的消費者)。
取出也是同理:
void Equeue(const T&in)//采取引用傳參,減少拷貝{_psem.P();_buffer[_p_step] = in;_p_step++;_p_step %= _size;_csem.V();}void Pop(T*out){_csem.P();*out = _buffer[_c_step];_c_step++;_c_step %= _size;_psem.V();}這里為什么不需要用if,while等條件判斷了呢?
因為信號量的值是數量,剩余空間為0和剩余數據為0會分別自動阻塞生產者與消費者。所以相當于自帶一個判斷。本身就是表示資源數目的,只要成功,就一定有,不需要判斷!
所以總的代碼:
#pragma once#include <iostream>
#include <vector>
#include <pthread.h>#include "sem.hpp"
#include "mutex.hpp"namespace RingBufferModule
{using namespace SemMudule;template<typename T>class ringbuffer{public:ringbuffer(int cap)//cap為外界傳進來的環形隊列的大小:_size(cap),_buffer(cap),_psem(cap),_csem(0),_p_step(0),_c_step(0){}void Equeue(const T&in)//采取引用傳參,減少拷貝{_psem.P();_buffer[_p_step] = in;_p_step++;_p_step %= _size;_csem.V();}void Pop(T*out){_csem.P();*out = _buffer[_c_step];_c_step++;_c_step %= _size;_psem.V();}~ringbuffer(){}private:std::vector<T> _buffer;//環形緩沖區size_t _size;//緩沖區大小sem _psem; //生產者信號量,代表的是剩余空間sem _csem; //消費者信號量,代表的是剩余數據size_t _p_step; //生產者下標size_t _c_step; //消費者下標}
}?我們可以寫個測試用例:
#include "RingBuffer.hpp"
#include <pthread.h>
#include <unistd.h>
#include <ctime>using namespace RingBufferModule;void *Consumer(void *args)
{ringbuffer<int> *ring_buffer = static_cast<ringbuffer<int> *>(args);while (true){sleep(1);// sleep(1);// 1. 消費數據int data;ring_buffer->Pop(&data);// 2. 處理:花時間std::cout << "消費了一個數據: " << data << std::endl;}
}void *Productor(void *args)
{ringbuffer<int> *ring_buffer = static_cast<ringbuffer<int> *>(args);int data = 0;while (true){// 1. 獲取數據:花時間// sleep(1);// 2. 生產數據ring_buffer->Equeue(data);std::cout << "生產了一個數據: " << data << std::endl;data++;}
}int main()
{ringbuffer<int> *ring_buffer = new ringbuffer<int>(5); // 共享資源 -> 臨界資源// 單生產,單消費pthread_t c1, p1;pthread_create(&c1, nullptr, Consumer, ring_buffer);pthread_create(&p1, nullptr, Productor, ring_buffer);pthread_join(c1, nullptr);delete ring_buffer;return 0;
}
可以看見,生產者與消費者是按照順序進行生產與歷史數據的取出的,當他們不訪問同一個空間,就會并發運行。
可是,這只是單消費者單生產者,如果有多個生產者與消費者呢?
其實這些問題,都可以轉化為單個消費者與單個生產者的關系:我們只需要讓多個生產者先競爭誰來生產,讓消費者競爭出一個消費者來消費不就又構成單個消費者與單個生產者的關系了嗎?
由于這些生產者想要訪問同一個信號量,消費者想訪問同一個消費者信號量,這就變成了對同一個資源的互斥問題,所以我們需要用鎖來保護我們的信號量:申請成功的線程進入下一個環節,沒申請成功的就進行等待。
所以面對多個消費者生產者,我們可以先定義兩個鎖,隨后更改我們代碼:
void Equeue(const T&in)//采取引用傳參,減少拷貝{LockGuard lockguard(_p_lock);//_p_lock是我們對生產者的鎖_psem.P();_buffer[_p_step] = in;_p_step++;_p_step %= _size;_csem.V();}我們的上鎖是在信號量P操作的前面還是后面呢?
實際上都可以,但我們想一下怎么做才能操作高。
我們之前說申請信號量就像是買票,而申請鎖就是排隊進入。
請問是你先一個一個排好隊了,等輪到你了才進行買票效率高?還是先買好票了,再進行排隊,輪到你了直接進去效率高?
答案肯定是后者:
所以應該為:
void Equeue(const T&in)//采取引用傳參,減少拷貝{_psem.P();LockGuard lockguard(_p_lock);_buffer[_p_step] = in;_p_step++;_p_step %= _size;_csem.V();}void Pop(T*out){_csem.P();LockGuard lockguard(_c_lock);*out = _buffer[_c_step];_c_step++;_c_step %= _size;_psem.V();}甚至于,為了顯式控制我們的lockguard的生命周期,我們可以加個大括號包裹起來:
#pragma once#include <iostream>
#include <vector>
#include <pthread.h>#include "sem.hpp"
#include "mutex.hpp"namespace RingBufferModule
{using namespace SemMudule;using namespace MutexModule;template <typename T>class ringbuffer{public:ringbuffer(int cap) // cap為外界傳進來的環形隊列的大小: _size(cap),_buffer(cap),_psem(cap),_csem(0),_p_step(0),_c_step(0){}void Equeue(const T &in) // 采取引用傳參,減少拷貝{_psem.P();{LockGuard lockguard(_p_lock);_buffer[_p_step] = in;_p_step++;_p_step %= _size;}_csem.V();}void Pop(T *out){_csem.P();{LockGuard lockguard(_c_lock);*out = _buffer[_c_step];_c_step++;_c_step %= _size;}_psem.V();}~ringbuffer(){}private:std::vector<T> _buffer; // 環形緩沖區size_t _size; // 緩沖區大小sem _psem; // 生產者信號量,代表的是剩余空間sem _csem; // 消費者信號量,代表的是剩余數據size_t _p_step; // 生產者下標size_t _c_step; // 消費者下標Mutex _p_lock;Mutex _c_lock;};
}
總結:
這就是我們今天關于信號量sem的內容了,希望大家能夠有所收獲!




)

)

)





(KRaft 版本3.7.0))




