一、大模型的崛起與概念解析
在人工智能技術飛速迭代的當下,大模型已成為驅動行業發展的核心引擎。從技術定義來看,大模型(Large Model) 是指基于深度學習架構、具備海量參數規模(通常數十億至數萬億級別),并通過大規模數據預訓練實現通用能力的 AI 模型。
1.1 核心技術特征
-
參數規模:以經典模型為例,GPT-3 參數量達 1750 億,而最新的 Qwen3-235B 等模型已突破 2000 億參數,參數規模直接決定模型對復雜模式的學習能力。
-
訓練模式:采用 “預訓練 + 微調” 雙階段模式,預訓練階段在通用數據集中學習基礎語義與知識,微調階段針對特定任務優化。
-
能力邊界:支持自然語言處理、多模態交互等復雜任務,核心優勢在于上下文理解與生成邏輯連貫性。
1.2 技術本質
大模型的本質是通過神經網絡模擬人類認知邏輯,其核心流程可分為編碼、推理、解碼三個階段,整體邏輯如圖 1 所示:
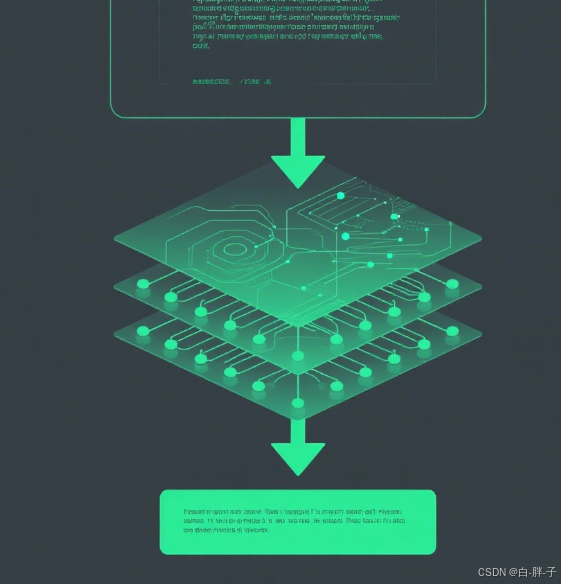
其核心邏輯可簡化為如下代碼:
\# 大模型核心邏輯抽象def large\_model(input\_text, params, knowledge\_base):  \# 1. 語義編碼:將輸入文本轉化為向量  text\_embedding = encoder(input\_text)  \# 2. 上下文推理:基于參數與知識庫計算輸出  output\_logits = neural\_network(text\_embedding, params, knowledge\_base)  \# 3. 生成解碼:將向量轉化為自然語言  return decoder(output\_logits)
其中,params(參數)是模型 “記憶” 知識的載體,knowledge_base是預訓練過程中沉淀的通用認知。
二、大模型在文本生成式 AI 產品中的核心架構地位
文本生成式 AI 產品(如豆包、騰訊元寶、百度文心)的架構可概括為 “大模型 + 應用層 + 調度層”,其中大模型是決定產品能力的核心模塊。
2.1 基礎架構示意圖
- 核心流程:用戶輸入經功能解析后,由調度層匹配對應模型(輕量模型處理簡單任務,大模型處理復雜任務),最終通過輸出優化層返回結果。
2.2 主流產品架構解析
2.2.1 字節跳動豆包(基于云雀模型)
云雀模型作為豆包的核心引擎,采用 Transformer 架構,其推理流程中 RLHF 優化模塊的作用如圖 3 所示:
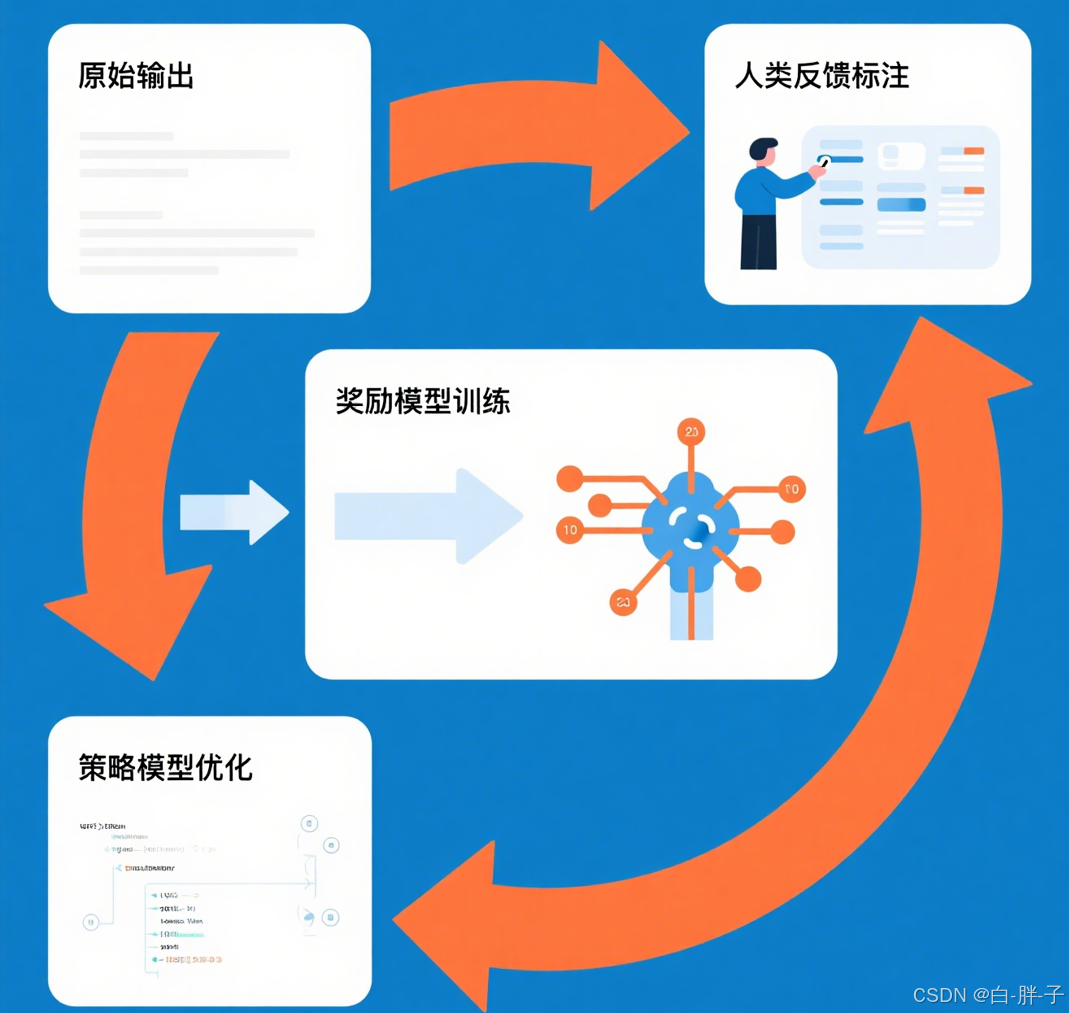
核心推理代碼如下:
\# 豆包核心推理流程示例class DoubaoEngine:  def \_\_init\_\_(self):  self.base\_model = "云雀-7B" # 基礎大模型  self.rlhf\_optimizer = RLHFModule() # 強化學習優化模塊  def generate(self, user\_query, context):  \# 1. 上下文拼接  full\_context = self.\_merge\_context(user\_query, context)  \# 2. 大模型推理  raw\_output = self.base\_model.generate(  input\_ids=full\_context,  max\_length=2048,  temperature=0.7 # 控制生成隨機性  )  \# 3. RLHF優化輸出  optimized\_output = self.rlhf\_optimizer.optimize(raw\_output)  return optimized\_output
- 技術亮點:通過 RLHF(基于人類反饋的強化學習)優化生成結果,提升對話自然度。
2.2.2 騰訊元寶(雙模型架構)
采用 “輕量模型 + 大模型” 協同模式,其模型調度策略如圖 4 所示:
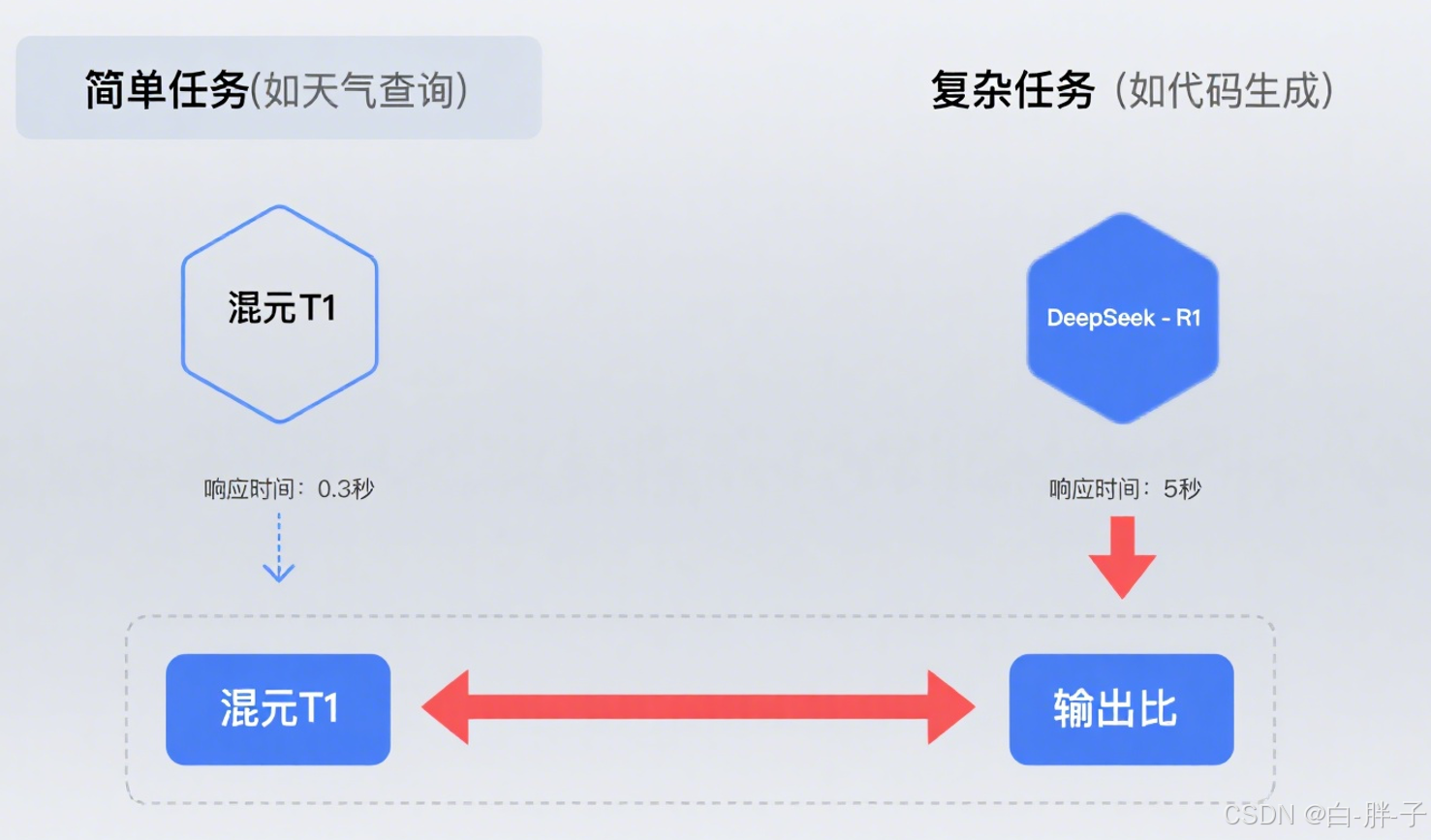
核心調度邏輯如下:
\# 騰訊元寶雙模型調度示例class YuanBaoEngine:  def route\_request(self, user\_query):  \# 任務復雜度判斷  if self.\_is\_simple\_task(user\_query): # 天氣查詢、短句問答等  return "混元T1" # 3B輕量模型,低延遲  else: # 代碼生成、長文本創作等  return "DeepSeek-R1" # 13B大模型,高準確率  def \_is\_simple\_task(self, query):  \# 基于關鍵詞與語義向量判斷任務類型  return len(query) < 20 and "查詢" in query
- 優勢:通過 Spring Cloud Gateway 實現動態路由,支持千萬級請求并發處理。
三、大模型技術演進與產品適配案例
3.1 近期主流模型對比
| 模型名稱 | 參數量 | 核心優勢 | 產品適配案例 |
|---|---|---|---|
| Kimi K2 | 萬億級(激活 32B) | 低功耗復雜任務處理 | 代碼生成工具、智能文檔分析 |
| Qwen3-235B | 2350 億 | 數學與工程能力突出 | 科研輔助系統 |
| DeepSeek-R1 | 13B | 長上下文支持(32K Token) | 法律合同解析 |
3.3 技術趨勢:混合推理架構
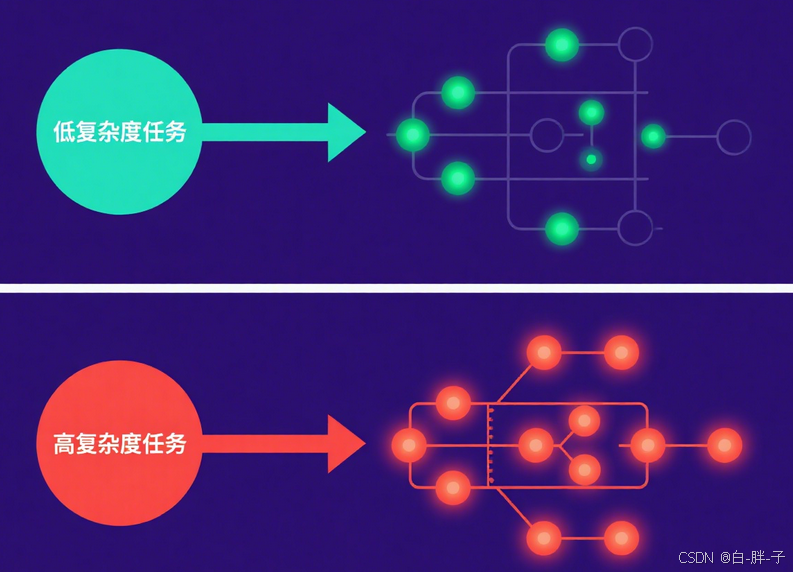
最新的模型設計采用 “混合推理” 模式,通過動態激活參數實現效率優化,其原理如圖 6 所示:
核心邏輯代碼如下:
\# 混合推理架構核心邏輯def hybrid\_inference(model, input, complexity):  \# 根據任務復雜度動態激活參數  if complexity == "low":  return model.activate\_layers(input, layers=1-10) # 輕量推理  else:  return model.activate\_layers(input, layers=1-48) # 全量推理
該架構已應用于騰訊元寶的 “混元 T1+DeepSeek-R1” 雙模型系統,使平均響應延遲降低 60%。
四、總結與展望
大模型作為文本生成式 AI 產品的 “中樞神經”,其技術演進直接決定產品能力邊界。從當前趨勢來看,參數效率優化(如激活參數動態調節)與垂直領域適配(如法律、代碼生成)將成為核心方向。對于開發者而言,需重點關注:
-
模型調用接口的性能優化(如批量推理、緩存策略)
-
基于業務場景的微調策略(LoRA 等輕量微調技術)
-
多模型協同調度的工程實現
未來,隨著大模型與邊緣計算的結合,文本生成式 AI 產品將在移動端、嵌入式設備等場景實現更廣泛的落地。


![[MarkdownGithub] 使用塊引用高亮顯示“注意“和“警告“和其他注意方式的選項](http://pic.xiahunao.cn/[MarkdownGithub] 使用塊引用高亮顯示“注意“和“警告“和其他注意方式的選項)

)
車牌字符的分割定位)




_軟硬鏈接)



)

)


