問題描述
填寫問題的基礎信息。
| 系統名稱 | 數據庫集群 |
| IP地址 | xxxxxx |
| 操作系統 | Linux |
| 數據庫 | Oracle 11.2.0.4 |
癥狀表現
問題的癥狀表現如下
4月26號晚22點02分左右,HIS集群發生腦裂,十幾分鐘后(22.18)一節點集群率先獲得集群控制權,
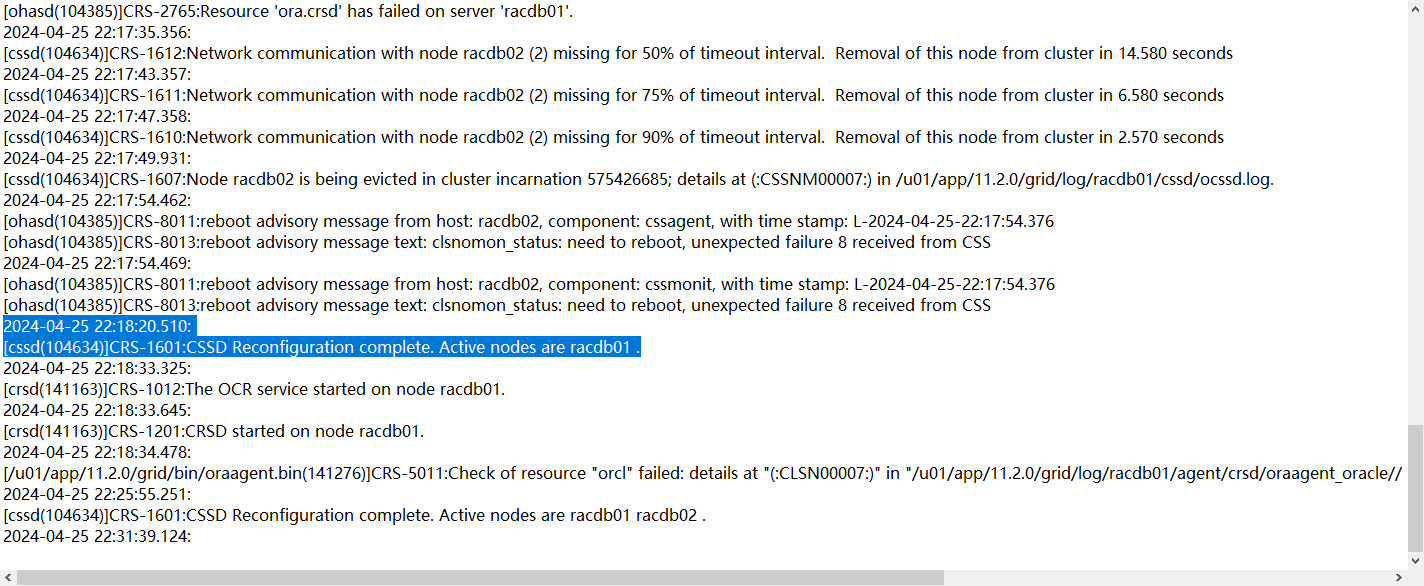
與此同時,一節點向而節點發起了member kill 以及 node kill請求
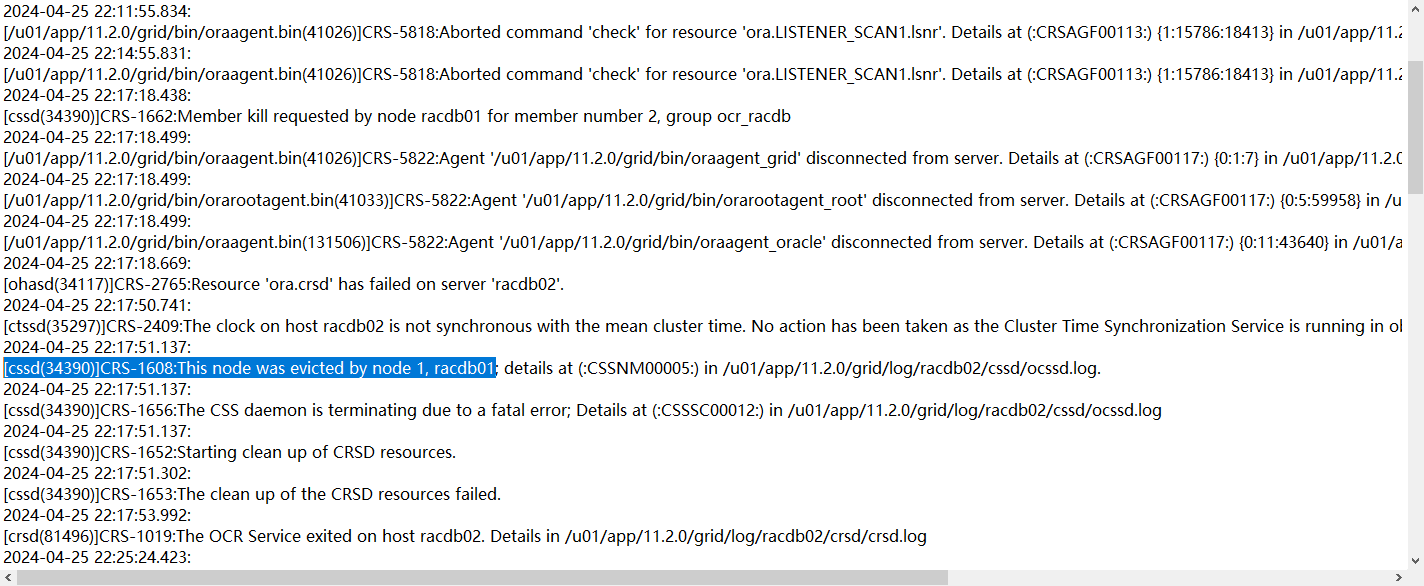
隨后,22.25分二節點以incomplete狀態node kill重啟集群件,并嘗試加入集群
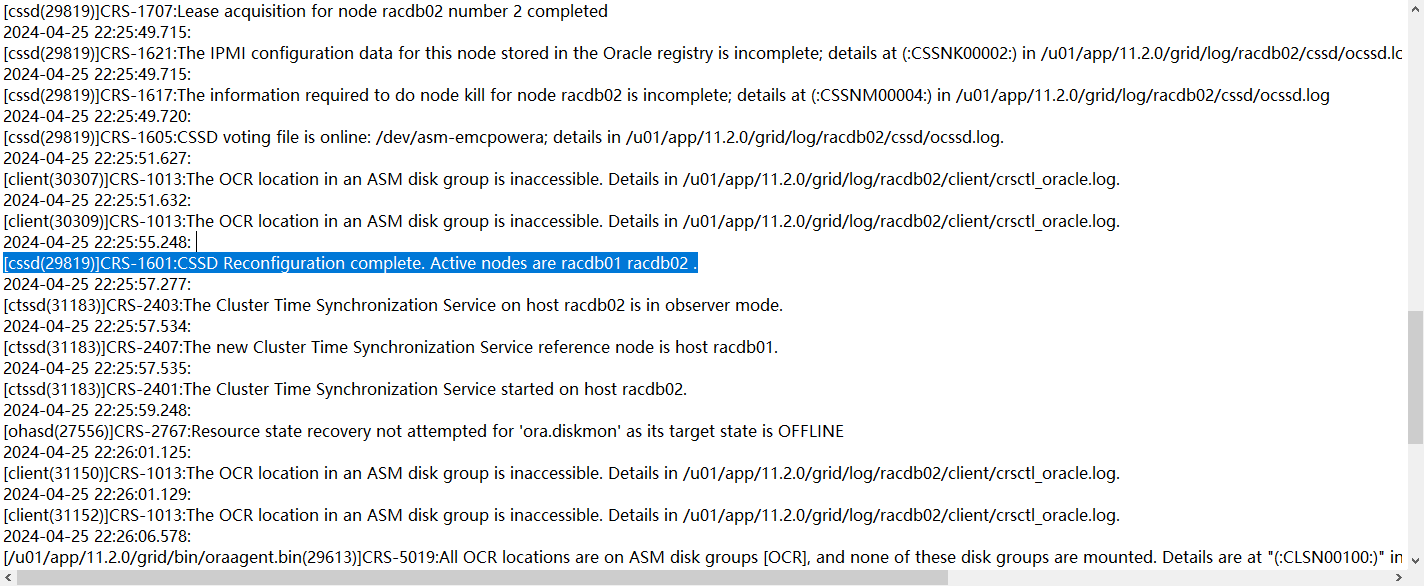
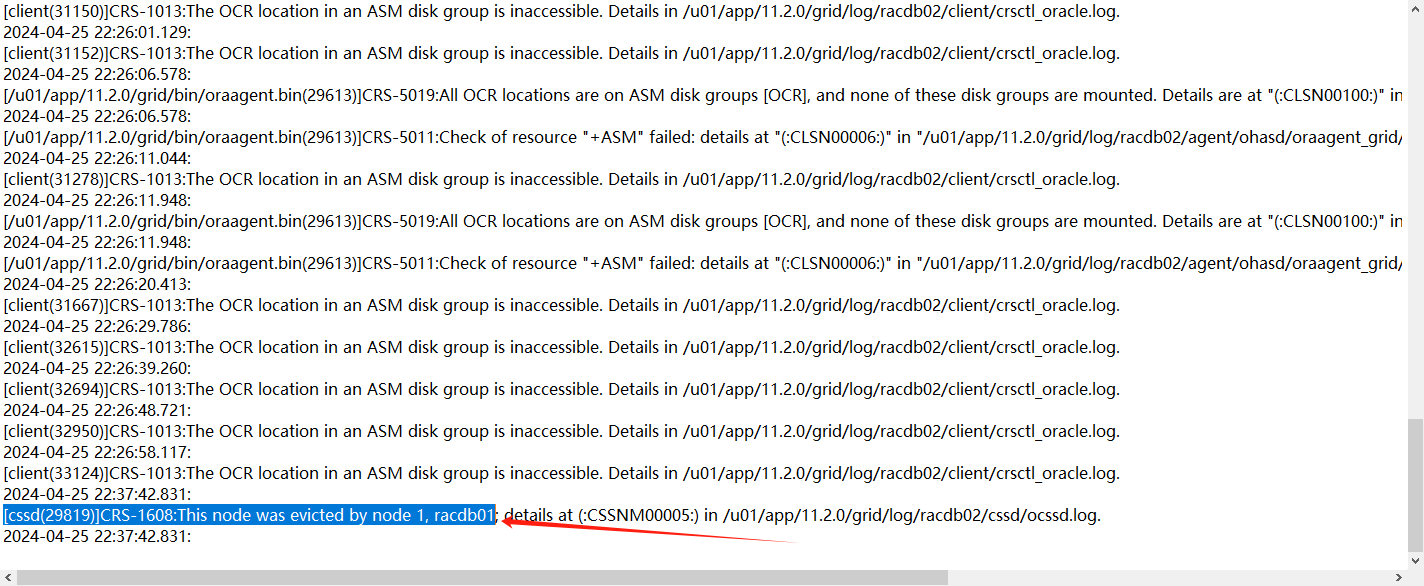
但是遇到了中裁盤不能訪問的故障,直到22.37分再次被節點1驅逐
處理過程
處理過程推薦按照時間以列表形式,將處理過程時間點,處理內容。
1、從集群日志來看,最開始的異常時來自二節點的check scan_listener失敗,大概在21.59分就發生:

2、查看對應的trace日志,看一下當時為什么check失敗了
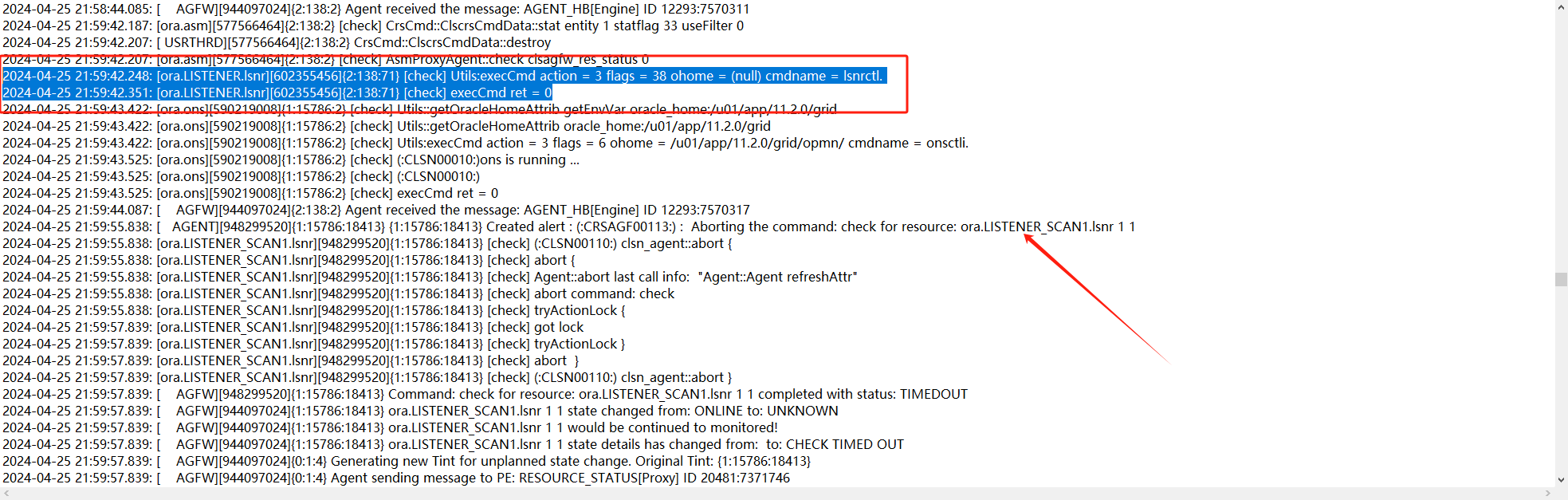
trace日志顯示21.59.42秒對scan的check都還是成功的,59分55秒check出現了timeout。
3、然后接著就是一節點上實例掛了,一節點集群日志顯示如下:
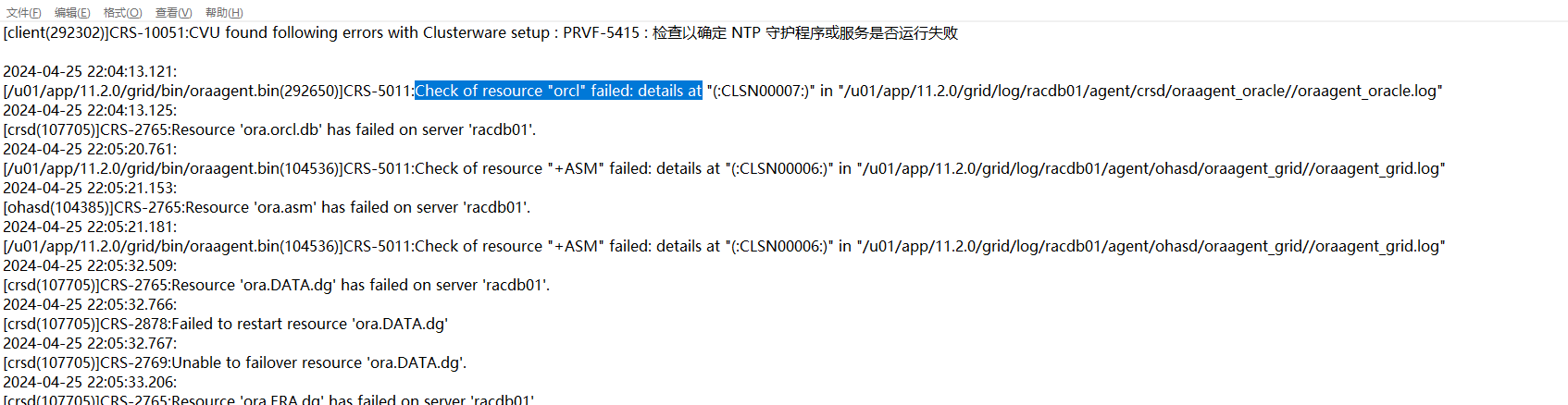
查看對應的trace日志發現就是當時的實例掛了,繼續查看當時的數據庫日志
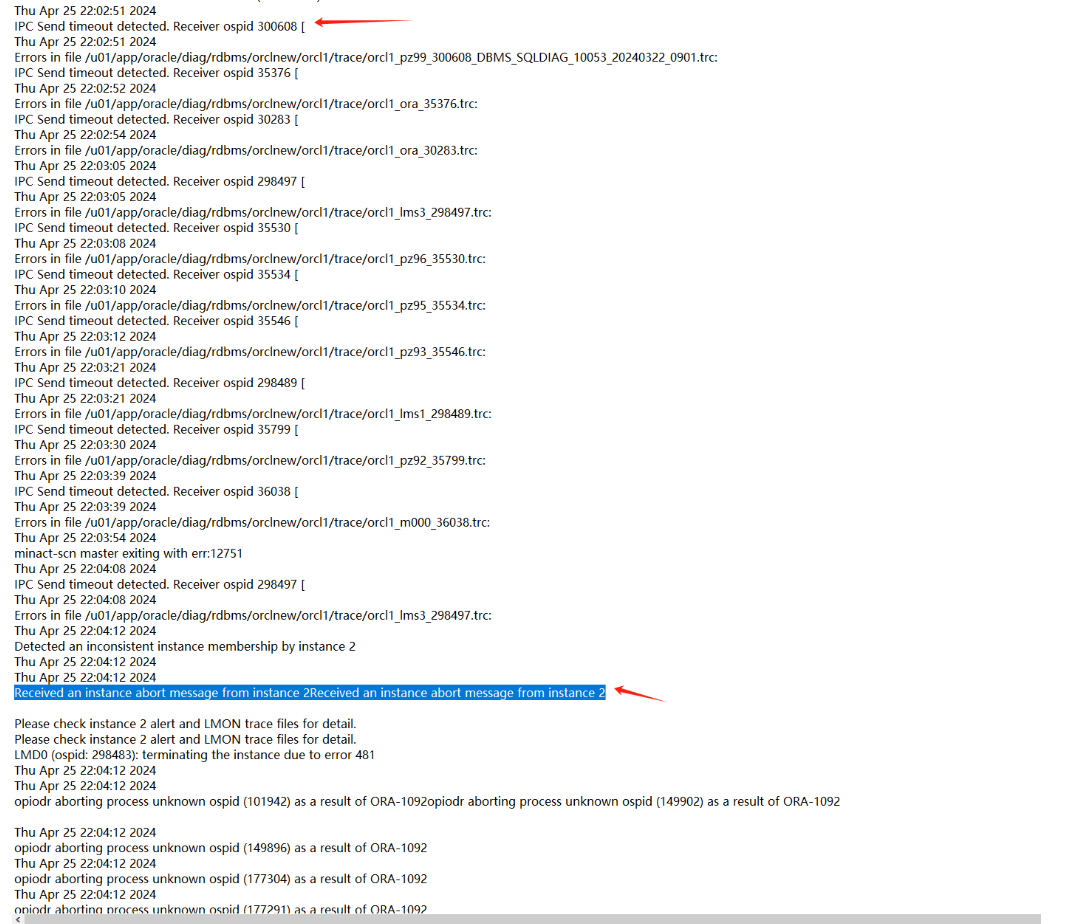
4、兩節點的數據庫日志顯示如下:
一節點:
二節點:
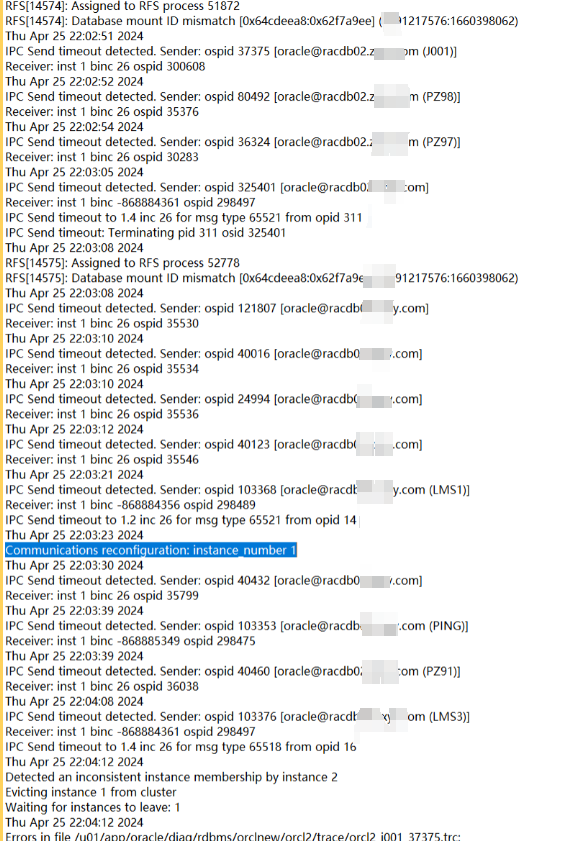
可以發現在22.02.51左右,二節點向一節點發送一些IPC請求出現timeout情況,過了一會(22.04)一節點實例被二節點驅逐(member kill),這個應該就是本次問題最開始的故障了。
4、繼續排查為什么實例會出現IPC Send Timeout原因,注意看當時二節點的IPC Send Timeout進程有很多(不是固定的某一個進程),有Oracle自己的并行進程,還有客戶的JDBC連接進程,懷疑這種Timeout問題應該是和私網性能有關,隨即查看對應時間私網心跳是否有延遲或者丟包,并未發現異常。但是在一節點服務器上發現對應時間段有大量的packet reassembles failed。
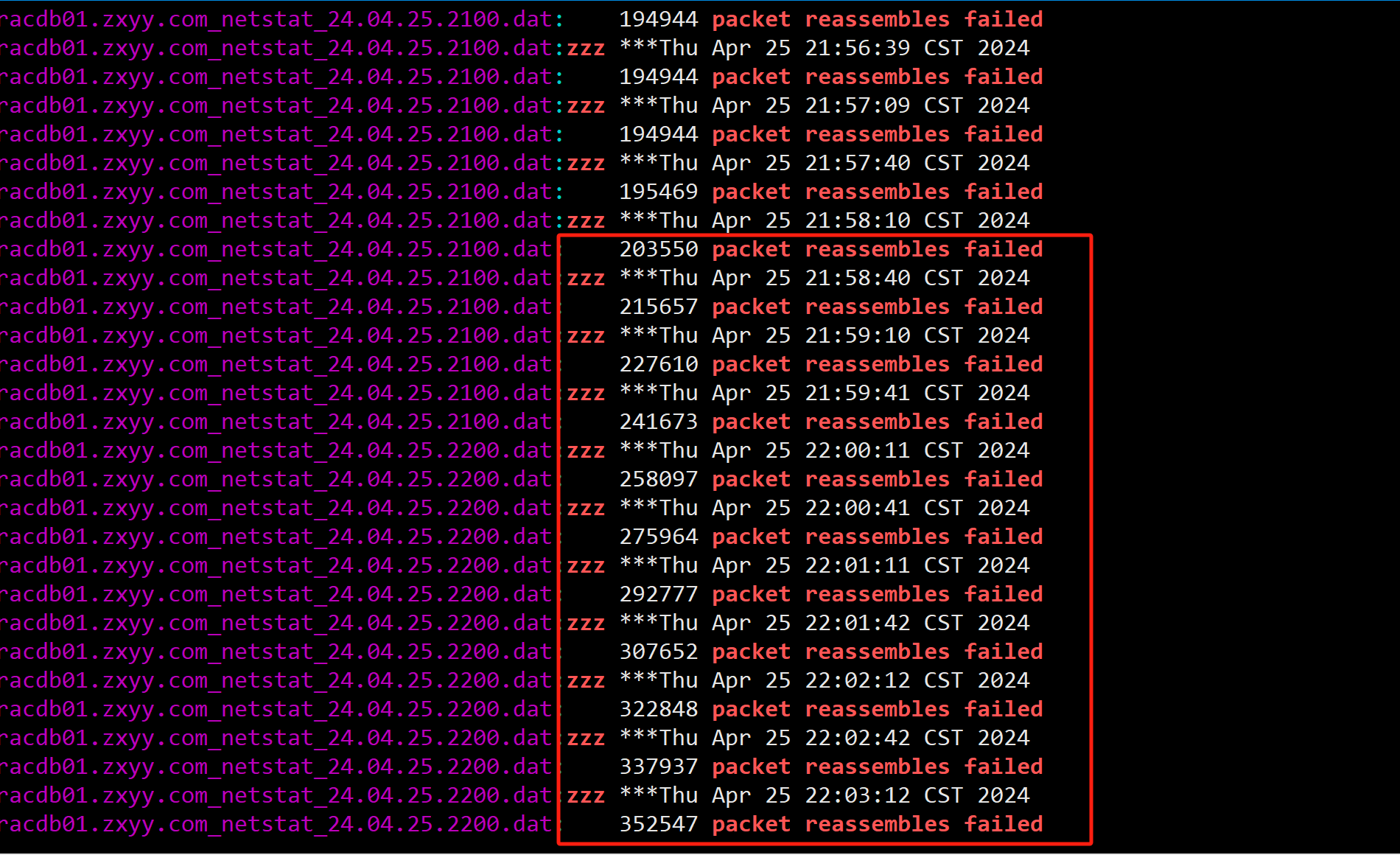
基本可以確認二節點向一節點發送IPC Timeout是由于一節點網絡包重組失敗造成的。(之前也有類似的案例)
什么是IP packet reassembles failed?
在linux平臺使用netstat -s命令時會看到packet reassembles failed項, 記錄的是IP重組包失敗的累計數據值,什么時候要重組呢?當IP包通信存在碎片時。在網絡通信協議中MTU(最大傳輸單元)限制了每次傳輸的IP 包的大小,一種是源端和目標端使用了不同的MTU時會交生碎片,這里需要先確認傳輸過程中的MTU大小配置,確認使用了相同的MTU;還有就是當傳送的數據大于MTU時,回分成多個分片傳遞。這時調整MTU就不可能解決所有的IP包碎片的問題,可以通過加大通信的buffer值,盡可能保留更多的數據在源端拆包,目標端緩存等接收完整后再重組校驗。 在LINUX系統中調整BUFFER使用ipfrag_low_thresh 和ipfrag_high_thresh參數,如果調整了這個參數仍有較大的重組失敗還可以加大ipfrag_time 參數控制IP 碎片包在內存中保留的秒數時間。
如果在ORACLE RAC環境中一個節點突然產生了大量的數據包輸送給另一個節點,如應用設計問題,如數據文件cache fusion或歸檔只能一個節點訪問時,都加大了網絡通信量,這里需要檢查網絡負載及丟包或包不一致的現象,因為ORACLE在網絡通信中使用了UDP和IP通信協議,這兩類信息都需要關注。
5、為什么一節點上會在對應時間出現大量的網絡包失敗呢?這一般有以下幾個原因:
A.節點之間有流量傳輸,并且有大量的巨幀包傳輸。
B.主機、交換機等網絡相關參數設置問題。
C.主機CPU、內存資源不足導致。
D.A條件和B條件的相互作用。
條件A:
繼續排查出問題前數據庫實例內部是否有異常,收集了對應時間段的ash、awr以及addm報告,報告顯示對應時間段數據庫出現了大量的gc等待事件
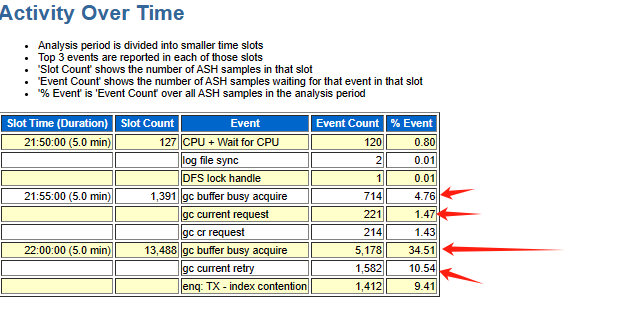
gc相關的等待事件一般都是和集群上的熱塊爭用有關,集群上的熱塊交換依賴于RAC的私網,當出現大量的GC相關等待事件說明當時有一些SQL需要跨界點訪問熱點數據塊,大量熱點數據塊的傳輸就滿足的條件A。
條件B:
查看主機上的規定reassembles buffer 尺寸的大小,發現如下:
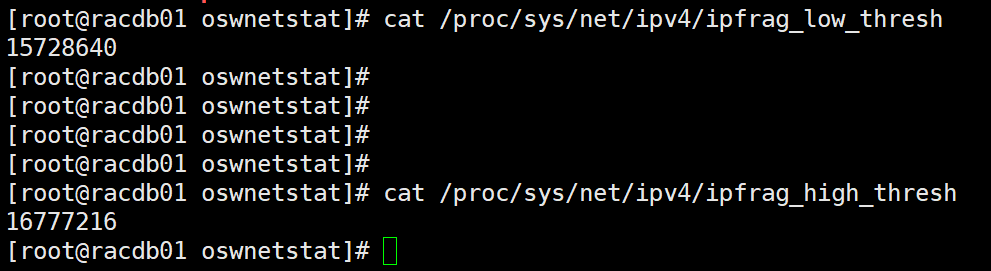
兩個節點都是滿足最佳實踐的要求的,但是如果還是出現大量的packet reassembles faile 問題,可以考慮開啟巨幀傳輸(調整MTU值),當然這個也需要交換機能夠支持。
條件C:
通過監控工具,未發現當時一節點主機有CPU\內存不足等問題。
條件D:
有些時候網絡流量不大,網絡帶寬沒有跑滿的情況下,條件A和條件B的相互作用也會導致大量的packet reassembles failed,就是當網絡傳輸的數據包都通過大量IP分片的方式進行傳輸,fragmentation rate比較高,那么主機網卡采用較小的MTU值進行傳輸(接收),當reassembles buffer滿,也會出現大量的packet reassembles failed,本次故障中通過監控工具發現是有大量的網絡包通過IP分片方式進行傳輸:
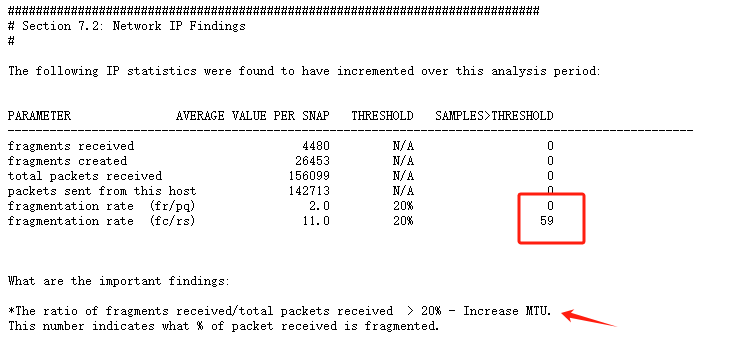
問題原因
問題原因如下
數據庫有SQL產生大量的GC等待事件,集群上的熱塊需要跨節點進行傳輸,有大量的網絡包采用IP分片的方式進行傳輸,目標端主機不能及時將接收到的巨幀包進行重組,誘發實例間IPC Send Timeout,進而出發集群member kill以及后續的node kill,最后集群需要花費一些時間完成重組。
問題解決
問題解決如下
1、對于容易產生大量GC的SQL盡量在一個節點運行,本次抓到的一些SQL如下:
抓到多個SQL如下:
📎addmrpt_2_78505_78506.txt
主要有如下SQL:
7r5mtbybcggnk
一節點執行次數:3347,平均時間1.03秒 ,二節點執行次數131次,平均時間10.71秒 764wd65m5y2sf 一節點執行次數:460 ,平均時間 3.69秒,二節點執行次數 453次,平均時間2.06秒2、如果可以,開啟私網心跳巨幀傳輸(需要交換機硬件支持)
)

)
















