?(本系列只需要modelsim即可完成數字圖像的處理,每個工程都搭建了全自動化的仿真環境,只需要雙擊top_tb.bat文件就可以完成整個的仿真,大大降低了初學者的門檻!!!!如需要該系列的工程文件請關注知識星球:成工fpga,https://t.zsxq.com/DMeqH,關注即送200GB學習資料,鏈接已置頂!)
上篇我們完成了車牌字符分割定位的預處理,本篇就完成車牌字符的分割。
車牌字符的上下邊界比較容易定位,其實在30課的圖像字符定位中基本完成了字符上下區域的定位,這兒進一步進行精細的定位。在車牌字符以外的區域,圖像數據全是0,在有字符的區域,相鄰圖像數據開始有0和1的變化,我們假設一行圖像數據中有threshold次相鄰圖像數據的變化,如果第一次達到這個要求,那這一行就是字符的上邊界,如果最后一次達到這個要求,那這一行就是字符的下邊界。

在\src\char_segmentation文件夾下新建char_horizontal_location.sv文件,完成字符上下邊界的定位。boarder_flag信號用來判斷上下邊界,當boarder_flag==0且jump_cnt達到threshold,那這一行就是上邊界,如果boarder_flag==1且jump_cnt達到threshold,那這一行就是下邊界,當然下邊界會一直更新,到最后一行我們把最后更新的那行當成下邊界。

車牌的字符有7個加一個點,左右邊界就是把這八個區域分割開。看圖片,把八個字符分開還是挺容易的,字符直接都是空白的區域,我們可以將每列的數據相加求和,最后對相鄰兩列的數據進行比對和判斷,如果上一列是0,這一列不是0,那這一列就是一個字符的左邊界;如果上一列不是0,這一列是0,那這一列就是一個字符的右邊界。同時要盤點一個字符左右邊界的寬度,如果寬度太小也可以是誤判,比如“川”“滬”“皖”等左右結構的字。
在\src\char_segmentation文件夾下新建char_vertical_location.sv文件,如下用組合邏輯實時計算字符的寬度和左右邊界。
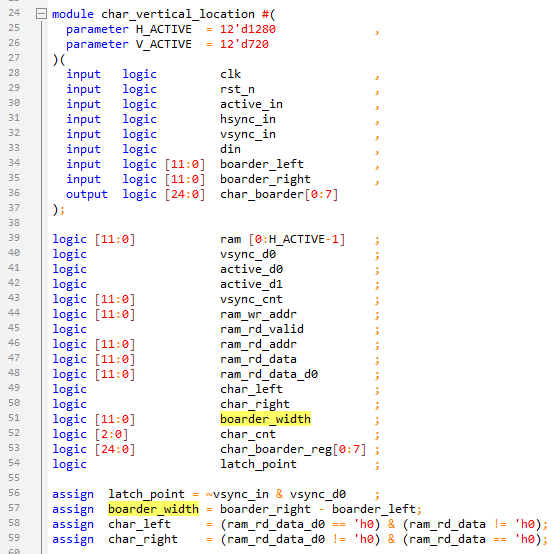
如下完成一幅圖像每列數據的求和,并在最后一行時候就求和的結果從數組中讀出來。
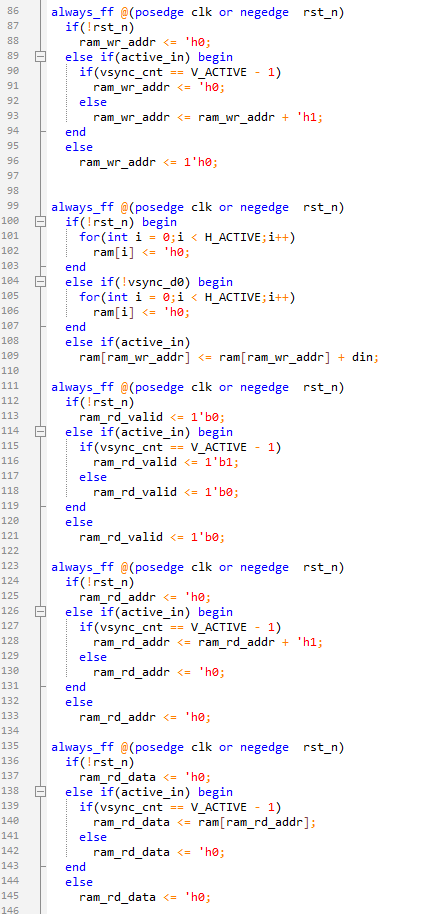
如下實現了一個字符左右邊界的判斷和記錄,需要注意的就是一些特殊的字符和第二字符點的判斷。

新建一個char_sgm_out.sv,用來實現將每個字符的區域在圖片上顯示出來。

在\src\char_segmentation文件夾下新建char_segmentation.sv,例化車牌字符分割相關的模塊。如下所示。

在top文件中例化plate_location模塊和char_segmentation模塊。

在tb_image_sim文件中,完成圖片的繪制。
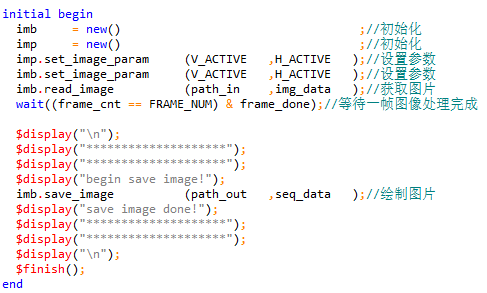
雙擊sim文件夾下的top_tb.bat文件,完成系統的自動化仿真。

最后打開img文件夾下的output文件夾,可以看到分割的圖片。

并不是所有的圖片的字符都能識別并正確的分割,如下的一幅圖片,由于底部的信號沒有完全消除,導致字符1左邊多識別了一個字符,從而將第一個字符“京”擠出來存儲的數組。

卷大多數圖片還是能正確分割的,如下所示。







_軟硬鏈接)



)

)








