??孿生擴散模型,生成息肉圖像用于提升分割性能!
論文:Noise-Consistent Siamese-Diffusion for Medical Image Synthesis and Segmentation
代碼:https://github.com/Qiukunpeng/Siamese-Diffusion
0、摘要
??深度學習已徹底革新醫學影像分割,但其潛力仍受限于標注數據極度匱乏。盡管擴散模型被視為生成合成圖像-掩膜對以擴充數據的有前景手段,它們卻陷入“用少量數據解決數據稀缺”的悖論。(這個悖論有點意思哈哈)
??傳統僅生成掩膜的模型因難以刻畫精細解剖結構,常導致圖像保真度低,進而削弱分割模型的穩健性與可靠性。(當前不足)
??為此,本文提出 Siamese-Diffusion:一種由 Mask-Diffusion 和 Image-Diffusion 組成的雙組件框架。
??訓練階段,兩組件間通過噪聲一致性損失約束參數空間,顯著提升 Mask-Diffusion 的形態保真度;采樣階段僅調用 Mask-Diffusion,兼顧多樣性與可擴展性。
??大量實驗表明,Siamese-Diffusion 在 Polyps 數據集上將 SANet 的 mDice 和 mIoU 分別提升 3.6% 與 4.4%,在 ISIC2018 數據集上使 UNet 的 mDice 和 mIoU 分別提升 1.52% 與 1.64%。
1、引言
1.1、研究意義與當前挑戰
??(1)雖然生成模型旨在緩解分割模型的數據稀缺問題,但它們自身卻面臨著同樣的挑戰;(生成模型也沒有足夠的數據,???,)
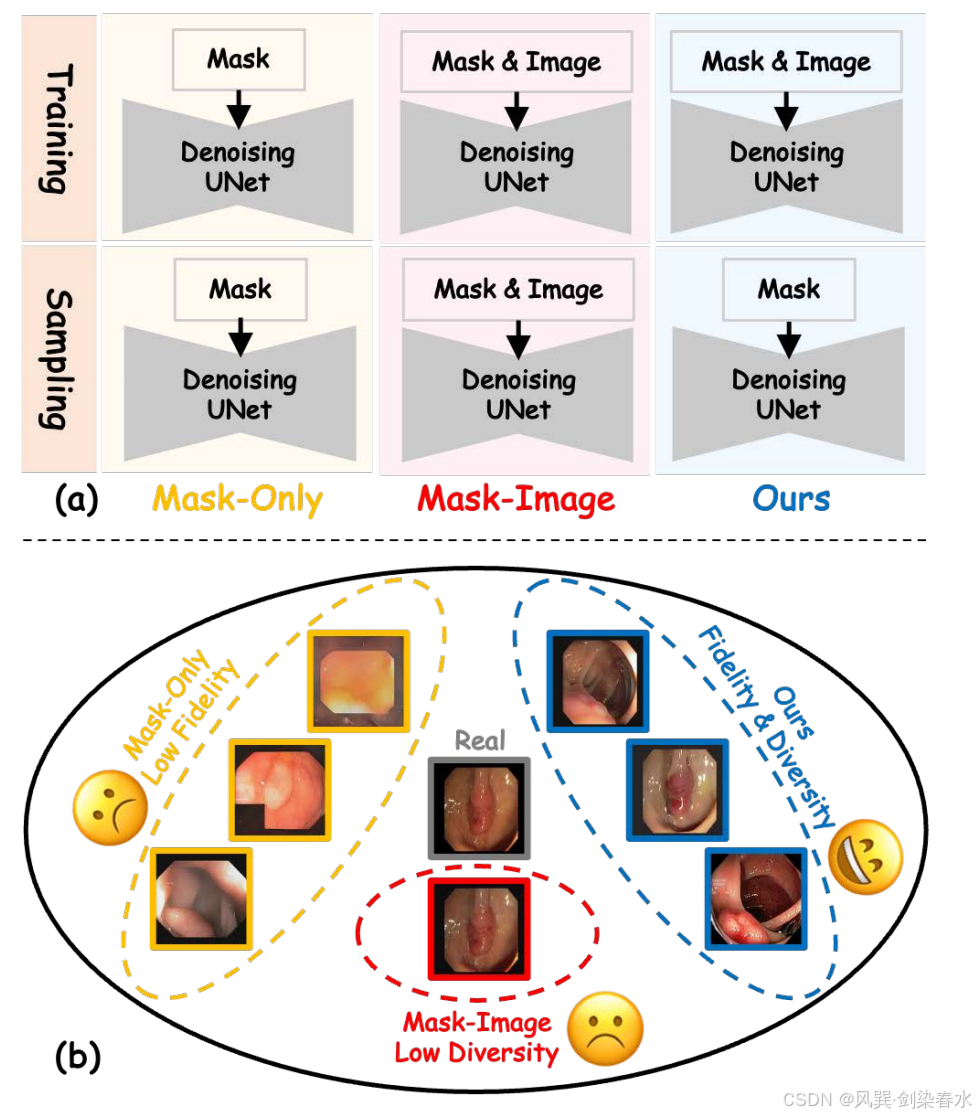
??(2)如 圖 1(a) 所示,僅生成掩膜的模型主要關注病灶形狀與掩膜的對齊,容易陷入局部極小值,導致形態保真度偏低;
??(3)如 圖 1(b) 黃色方框所示,合成醫學影像常缺失關鍵形態特征(如表面紋理),此類缺失使得分割模型難以學習具有辨識力的病灶特征,造成模型可解釋性不足且表現難以捉摸,顯著削弱了增強分割模型的可靠性;
??
Figure 1 | :(a)本文的方法與現有方法在訓練和采樣階段的工作流程對比;(b)各方法合成圖像的差異;僅使用掩膜的方法(黃色)缺乏形態特征(如表面紋理),導致保真度較低;掩膜-圖像方法(紅色)生成高保真圖像,但其依賴額外的圖像先驗控制導致多樣性不足且擴展性差;本文的方法(藍色)在保持多樣性的同時提升了形態特征的保真度;
1.2、本文貢獻
??(1)本文發現,當前的生成模型和醫學圖像分割模型都面臨著相同的數據稀缺問題,導致形態學保真度較低;本文認為,只有包含必要形態特征的合成醫學圖像,才能確保增強型分割模型的可靠性;
??(2)提出了一種名為“孿生擴散模型”的方法,該模型通過噪聲一致性損失和圖像擴散技術,引導掩模擴散算法在保持高形態保真度的前提下找到局部最優解;在采樣過程中,僅使用掩模擴散算法來合成具有真實形態特征的醫學圖像;
??(3)大量實驗表明,本文方法在圖像質量與分割性能方面均優于現有方法。SANet 在息肉數據集上使 mDice 和 mIoU 分別提升 3.6% 和 4.4%,而 UNet 在 ISIC2018 數據集上實現 1.52% 和 1.64% 的性能提升,充分彰顯了本方法的優越性;
2、方法
2.1、基礎
??原文略,可參考 【Diffusion綜述】醫學圖像分析中的擴散模型(一) 中的 2.2 節
2.2、孿生擴散模型結構
??ControlNet 和預訓練的 Stable Diffusion 構成了本文方法的基礎框架。Stable Diffusion 框架中的 VQ-VAE 模塊和去噪 U-Net 編碼器模塊均被凍結。
??在訓練階段,如 圖 2(a) 所示,圖像 x0x_0x0? 通過 VQ-VAE 編碼器 E\mathcal EE 被壓縮到潛在空間 z0z_0z0? 中。本文提出的密集提示輸入(DHI)與控制網絡(ControlNet)串聯組合形成特征提取網絡。該網絡將輸入圖像 x0x_0x0? 及其對應掩碼 y0y_0y0? 編碼為 cic_ici? 和 cmc_mcm?。隨后,不同的先驗控制參數 cmc_mcm? 和 cmixc_{mix}cmix? 被注入同一擴散模型的去噪 U-Net 解碼器(即圖2(a)中的“復制”模塊),用于分別預測噪聲 ?θm?^m_θ?θm? 和混合噪聲 ?θ′mix?^{mix}_{θ′}?θ′mix?,此處,cmixc_{mix}cmix? 是 cic_ici? 和 cmc_mcm? 的混合特征:
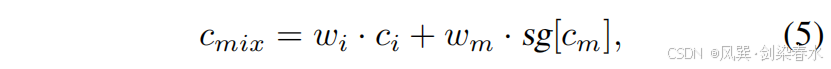
??其中,wi=k/Niterw_i = k/N_{iter}wi?=k/Niter? 與 wmw_mwm? 分別表示對圖像先驗與掩膜先驗的控制權重;NiterN_{iter}Niter? 為訓練總迭代次數,kkk 為當前迭代步數。為簡潔起見,僅利用掩膜(記為 cmc_mcm?)以及同時利用掩膜與圖像(記為 cmixc_{mix}cmix?)的兩種過程分別稱為 Mask-Diffusion 與 Image-Diffusion。式 (5) 中的 cmc_mcm? 與 Mask-Diffusion 所用項相同,并采用截斷梯度。
??該孿生架構與知識蒸餾模型不同,后者需同時訓練教師和學生網絡,計算開銷較大。最終,用于訓練 Siamese-Diffusion 的損失函數定義為:
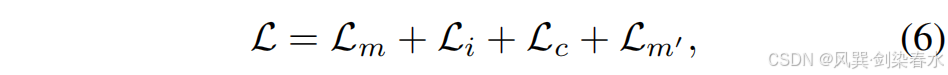
??其中,Lc\mathcal L_cLc? 是本文提出的噪聲一致性損失函數,Lm′\mathcal L_{m′}Lm′? 源自在線增強技術,這兩個部分將在后續內容中詳細闡述。Lm\mathcal L_mLm? 和 Li\mathcal L_iLi? 分別是針對 Mask-Diffusion 和 Image-Diffusion 的去噪損失函數:
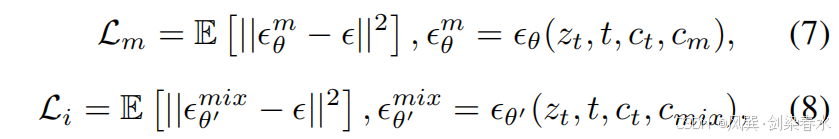
??其中 θθθ 是 Mask-Diffusion 的參數,而 θ′θ′θ′ 是 θθθ 的復制。公式(7)和(8)共享相同的 ?~N(0,I)?~\mathcal N(0,I)?~N(0,I)。
??在采樣階段,如 圖 2(b) 所示,僅使用 Mask-Diffusion 和任意掩模先驗控制來合成醫學圖像進行分割。
??
Figure 2 | :(a)本文方法在訓練階段的示意圖;(b)在采樣階段,僅使用 Mask-Diffusion 技術生成高保真度且多樣化的合成圖像;(c)通過將提示輸入(HI)模塊替換為提出的密集提示輸入(DHI)模塊,可有效增強圖像中先驗引導信息的提取效果;
2.3、噪聲一致性損失
??如前所述,在數據稀缺場景下,Mask-Diffusion 容易陷入低保真度的局部極小值,生成的醫學圖像會缺失表面紋理等關鍵形態特征。相比之下,Image-Diffusion 借助額外的圖像先驗控制項 x0x_0x0?,能更輕松地收斂到高保真度的局部最優解。
??然而,在采樣階段,來自圖像 x0x_0x0? 的強先驗控制導致合成圖像與真實圖像非常相似(如 圖 1(b) 所示),這限制了形態特征的多樣性,并由于配對樣本的稀缺性而限制了可擴展性。
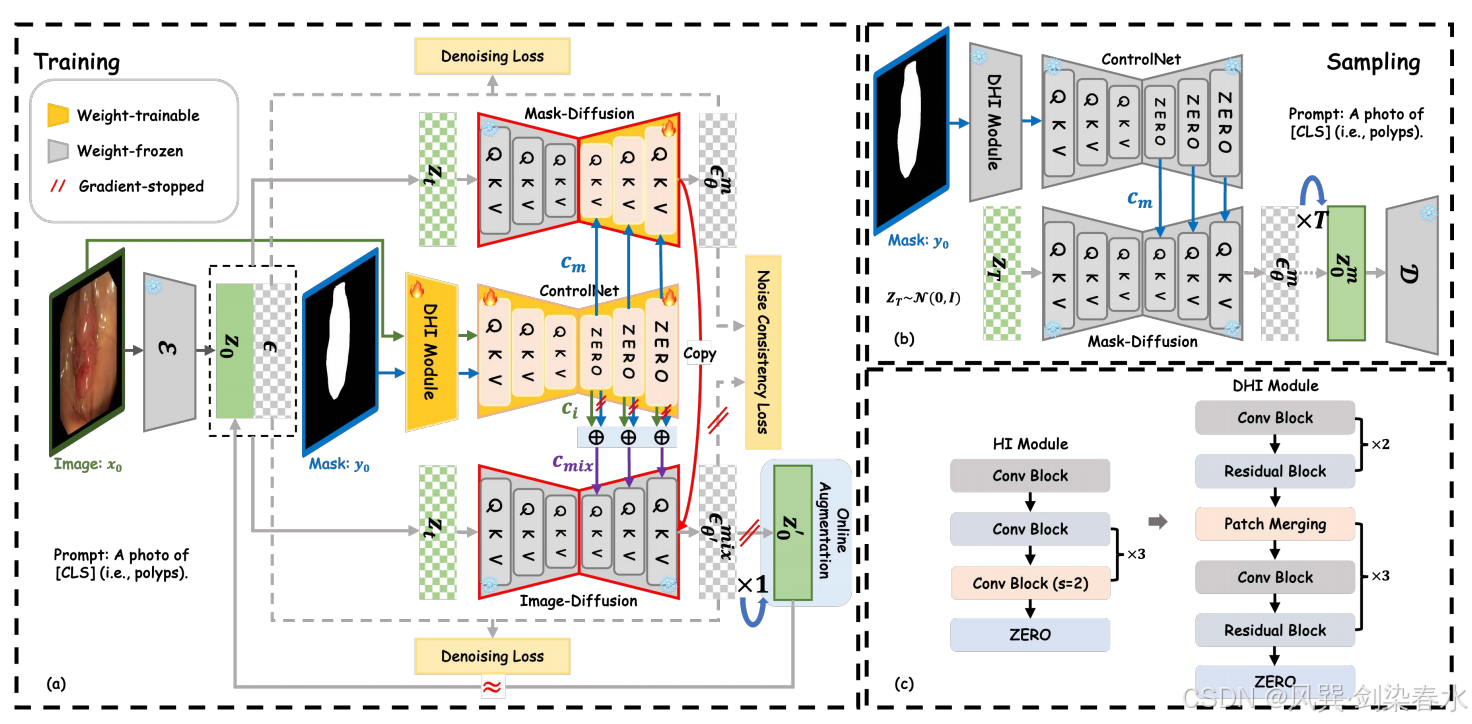
??為了幫助 Mask-Diffusion 從低保真度的局部極小值中逃逸,并向參數空間中更高保真度的區域移動,引入了噪聲一致性損失:
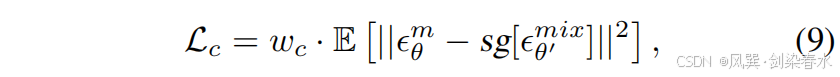
??其中,Image-Diffusion 預測的噪聲值 ?θ′mix?^{mix}_{θ′}?θ′mix? 比 Mask-Diffusion 預測的噪聲值 ?θm?^m_θ?θm? 更準確,這得益于圖像先驗控制的額外優勢。通過停止梯度操作 sgsgsg,更精確的 ?θ′mix?^{mix}_{θ′}?θ′mix? 可作為錨點,引導 Mask-Diffusion 的收斂軌跡向參數空間中更高保真的局部極小值方向發展。
??圖 2(a) 中的“復制”操作和等式(5)中的相同 cmc_mcm? 共同確保了附加圖像提供的強先驗控制成功傳播到 Mask-Diffusion。同時,wiw_iwi? 逐漸增加,去噪損失在早期階段起主導作用以確保穩定收斂。wcw_cwc? 控制轉向強度。
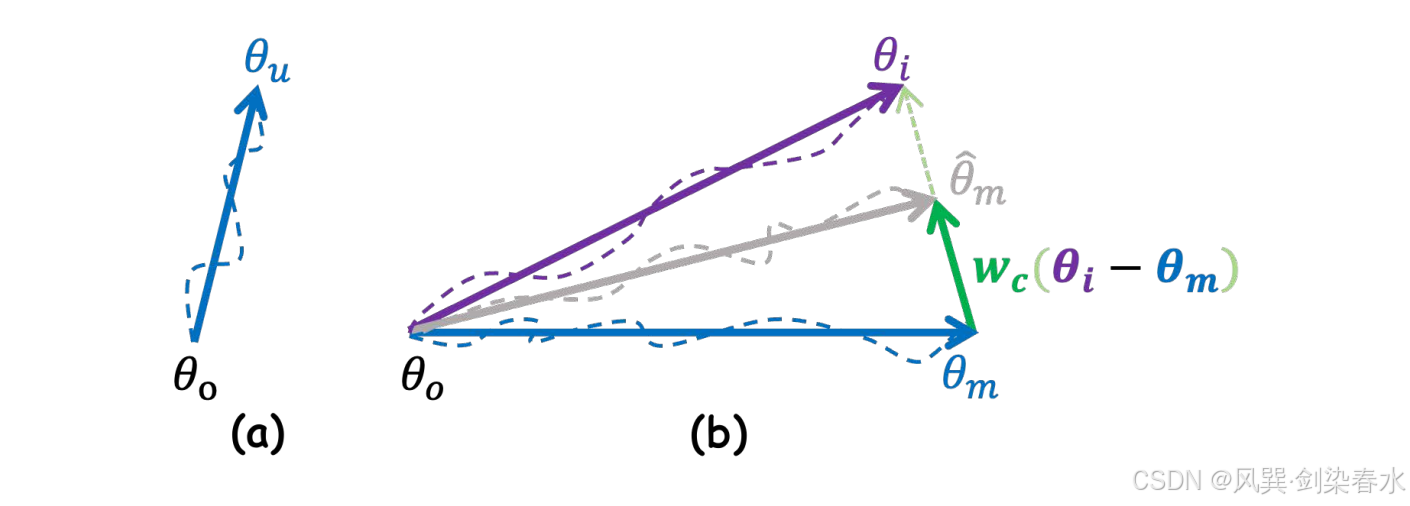
??圖 3 直觀展示了上述操作在參數空間中的表現。通過算術運算,參數的更新方向可以通過原始模型參數 θoθ_oθo? 與更新后模型參數 θuθ_uθu? 之間的差異來表示。因此,Mask-Diffusion 參數的最終更新方向可近似表示為:
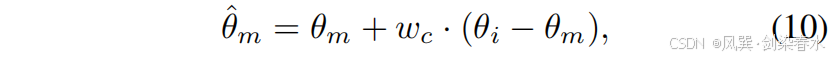
??其中 θmθ_mθm? 和 θiθ_iθi? 是 Mask-Diffusion 與 Image-Diffusion 的參數,而 θ^m\hat θ_mθ^m? 則是優化后的 Mask-Diffusion 參數。在整個過程中,特征提取網絡與擴散模型的協同更新確保了掩碼特征 cmc_mcm? 與含噪圖像特征 ztz_tzt? 在潛在空間中的對齊關系,從而保證融合后的潛在特征位于合適的流形內。因此,Mask-Diffusion 在采樣階段能夠獨立運行。
??
Figure 3 | :(a) 參數更新方向;(b) Mask-Diffusion 參數更新方向,按噪聲一致性損失進行縮放;
??如 圖 1(b) 所示,通過改進的 Mask-Diffusion 技術增強了合成圖像的形態特征,使得這些圖像與 Image-Diffusion 合成的圖像具有競爭力。
??通過這些圖像增強的分割模型能確保結果的可解釋性和可靠性。與通過調整樣本空間中引導強度來提升保真度的無分類器引導(CFG)不同,本文提出的孿生擴散(Siamese Diffusion)方法在參數空間內增強了形態學保真度。這種創新設計有效解決了采樣過程中依賴配對對照數據所帶來的局限性。
2.4、密集提示輸入模塊
??現有方法通常使用低密度語義圖像作為先驗控制,例如分割掩膜、深度圖和草圖,這類圖像的特征可通過稀疏提示輸入(HI)模塊輕松提取。然而,對于高密度的醫學圖像,原始稀疏 HI 模塊難以捕捉紋理、顏色等細節信息。為此,本文引入密集提示輸入(DHI)模塊。如 圖 2(c) 所示,DHI 在主干網絡中堆疊了通道數分別為 16、32、64、128 和 256 的密集殘差塊,并集成更先進的 patch 合并單元,從而能夠同時兼容圖像先驗和掩膜先驗。
2.5、在線增強
??基于孿生擴散訓練范式的優點,引入了在線增強技術來擴展掩模擴散訓練集(如 圖 2 (a) 所示)。通過引入額外的圖像先驗控制項 x0x_0x0?,有效提升了圖像擴散對噪聲預測的準確性,從而實現單步采樣在線生成 z0′z_0^{′}z0′?。
??在第一步中,z0′z_0^{′}z0′? 通過加噪的逆過程獲得,其中 xtx_txt? 被替換為 ztz_tzt?,具體如下:
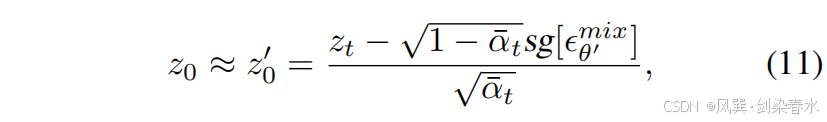
??其中,sg[?θ′mix]sg[?^{mix}_{θ′}]sg[?θ′mix?] 表示通過帶有截斷梯度的 Image-Diffusion 預測的噪聲。在第二步中,z0′z_0^{′}z0′? 用于近似 z0z_0z0?,并與 cmc_mcm? 結合以訓練 Mask-Diffusion:
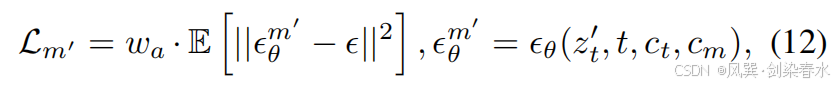
??其中 ??? 與公式等式(7)中的相同,waw_awa? 控制 z0′z_0^{′}z0′? 與 cmc_mcm? 之間的對齊關系:
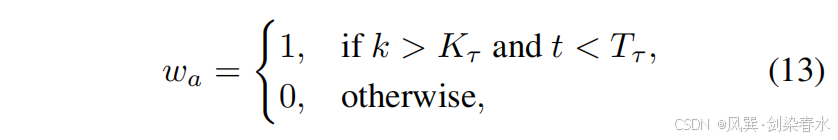
??其中 kkk 表示當前迭代次數,KτK_τKτ? 是迭代閾值,ttt 是時間步長,TτT_τTτ? 是時間步長閾值。
3、實驗與結果
3.1、數據集與評價指標
??在三個公共醫療數據集——Polyps、ISIC2016 和 ISIC2018——以及兩個內部數據集,Stain 和 Faeces 上進行了實驗;
??(1)生成模型訓練集:息肉數據集共 1450 例,其中 900 例來自 Kvasir,550 例來自 CVC-ClinicDB。ISIC2016 含 900 例,ISIC2018 含 2 594 例。Stain 數據集共 500 例,Faeces 數據集共 458 例,二者均按 3∶1∶1 劃分為訓練、驗證與測試集,對應訓練集分別為 300 例與 275 例。
??(2)分割模型訓練集:醫學數據集使用由其原訓練集掩膜生成的合成圖像,與原始圖像合并后構成新的訓練集。Stain 與 Faeces 數據集的原掩膜經過縮放等變換擴充至 1 000 例,用于訓練。
??(3)評估指標:圖像質量采用 FID、KID、CLIP-I、LPIPS、CMMD 及平均主觀評分(MOS,由 3 位資深臨床醫師評定,詳見附錄)。分割性能以 mDice 和 mIoU 度量,使用 CNN 與 Transformer 基線模型的默認設置。
3.2、實施細節
??Siamese-Diffusion 以預訓練的 Stable Diffusion V1.5 為骨干,在五個數據集上統一采用 AdamW 優化器繼續微調:學習率 1×10?51×10??1×10?5,權重衰減 1×10?21×10?21×10?2。Polyps、ISIC2016 與 ISIC2018 的最大迭代次數設為 3000;Stain 和 Faeces 設為 1500。式 (5) 中掩膜損失權重 wmw_mwm? 取 1.0。式 (13) 的迭代閾值 KτK_τKτ? 經驗性地設為 Niter/3N_{iter}/3Niter?/3,時間步閾值 TτT_τTτ? 設為 200(遵循公開實現)。經實驗驗證,wcw_cwc? 的最佳值為 1.0。所有圖像統一縮放至 384×384,并在訓練中以 5% 的概率使用空提示。訓練在 8 張 NVIDIA RTX 4090 上進行,單卡批次大小 6,全局批次大小 48。采樣階段采用 DDIM(η=0η=0η=0),共 50 步,指導尺度 λ=9λ=9λ=9,與已有設置一致。
4、評估與結果
4.1、圖像質量評價
??
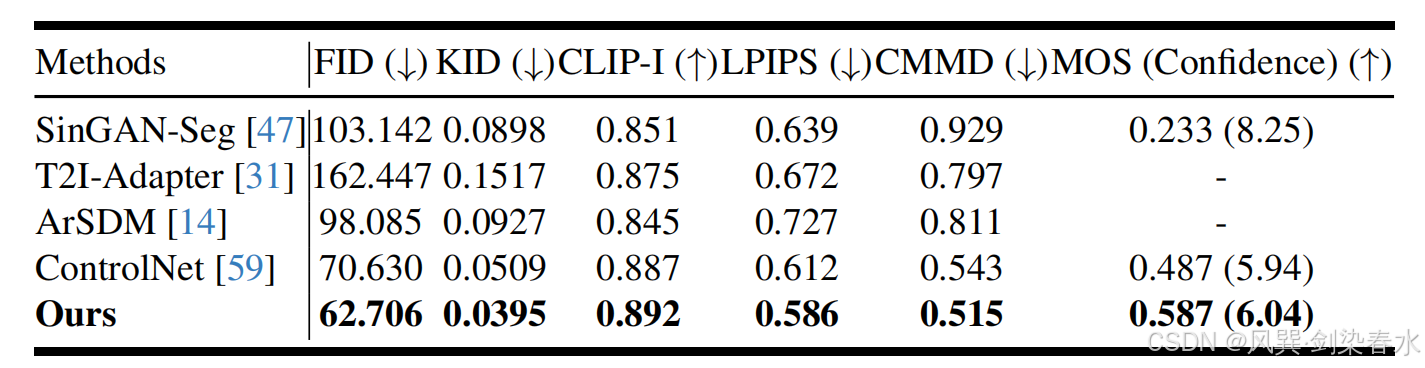
Table 1 | 僅使用掩膜生成息肉合成圖像的質量比較,采用 FID、KID、CLIP-I、LPIPS、CMMD 及 MOS 指標進行評估:
??
Figure 4 | 數據分布的 t-SNE 可視化: (a)-(e) 展示了真實息肉圖像與各掩模方法合成圖像的分布差異,本文方法生成的息肉圖像分布幾乎與真實數據完全重合,充分展現了其生成高度逼真息肉圖像的卓越能力;
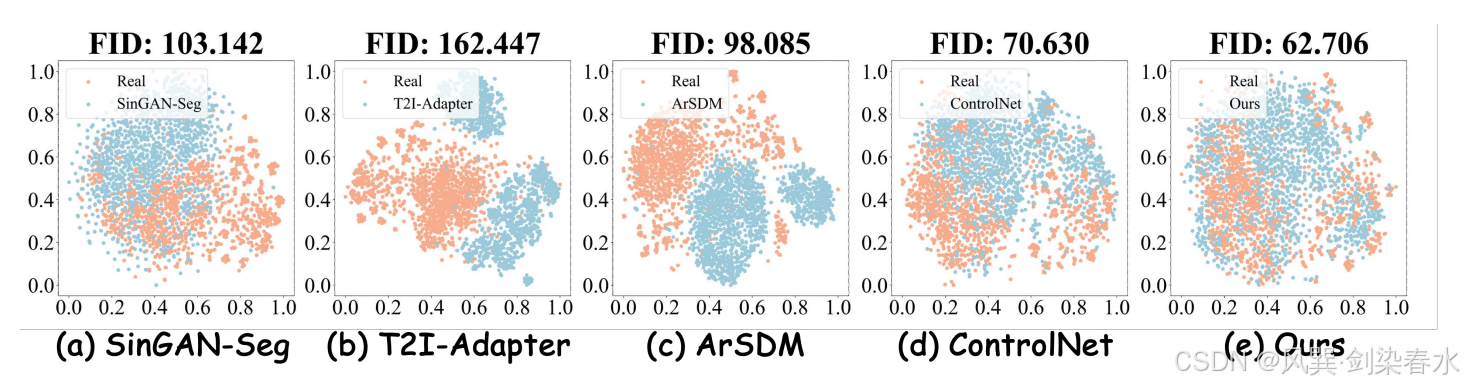
??
Figure 5 | 數據分布的 t-SNE 可視化:(a)實際息肉圖像示例;(b)-(g)各方法生成的合成息肉圖像對比;其中 “M” 表示僅使用掩膜先驗控制,“M+I” 則采用掩膜-圖像聯合先驗控制,本方法生成的合成息肉圖像不僅保持了良好的形態學保真度,還展現出豐富的形態多樣性;
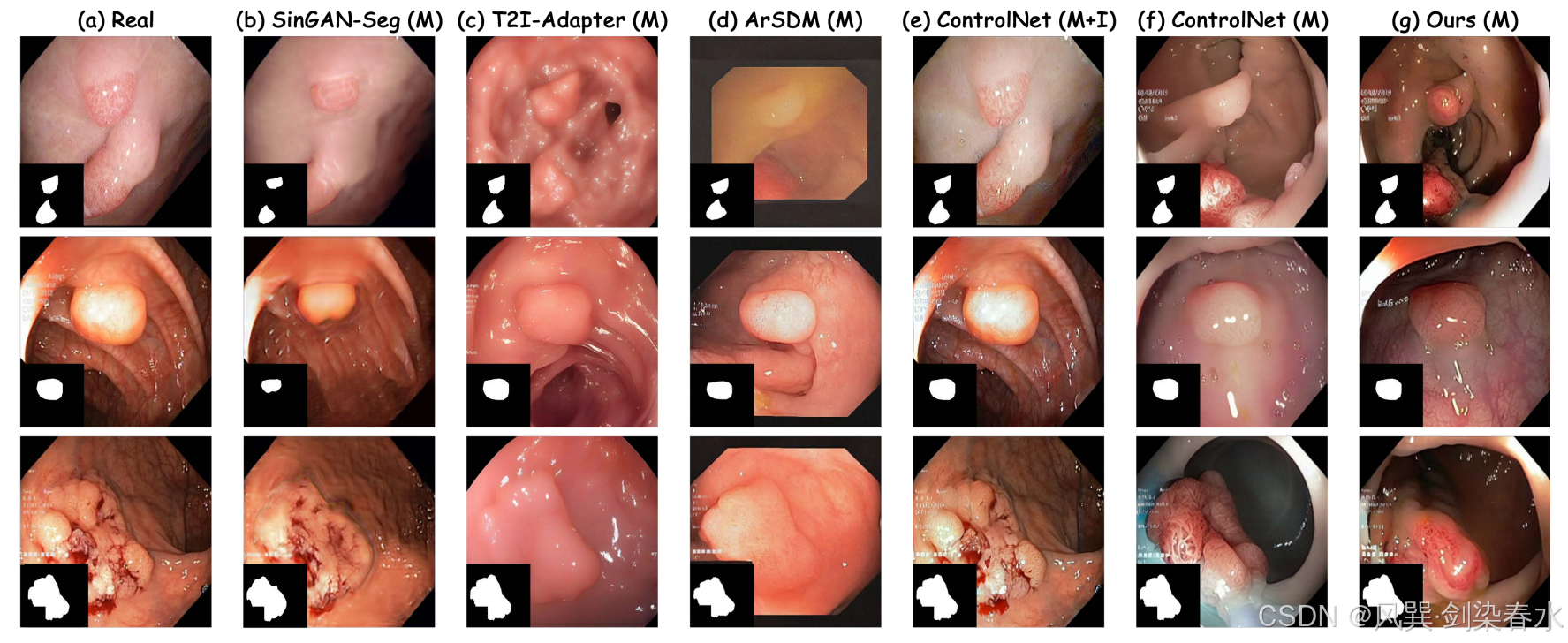
??
4.2、分割性能比較
??
Table 2 | 以 mDice(%) 與 mIoU(%) 為指標,比較 SANet、Polyp-PVT 與 CTNet 的性能:“+” 表示訓練集同時包含真實息肉圖像及各方法生成的合成息肉圖像;“M” 指僅用掩膜先驗控制,“M+I” 指掩膜-圖像聯合先驗控制;
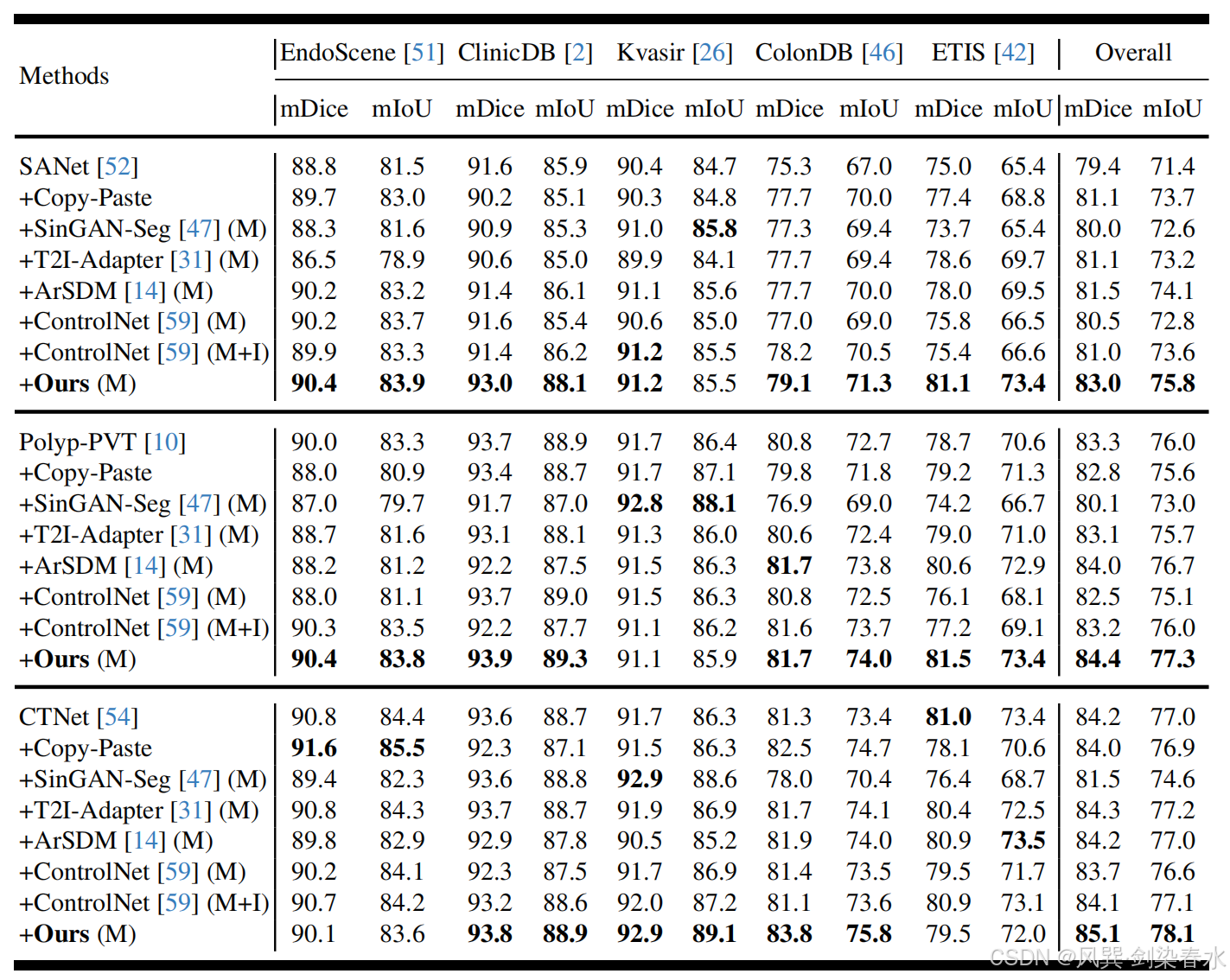
??
Table 3 | 以 mDice(%) 與 mIoU(%) 為指標,比較 UNet 與 SegFormer 的性能:“+” 表示訓練集同時包含真實皮膚病變圖像及各掩膜驅動方法生成的合成圖像;“Real” 指掩膜來自真實數據,“Random” 指對真實掩膜進行變換(如縮放)后所得;
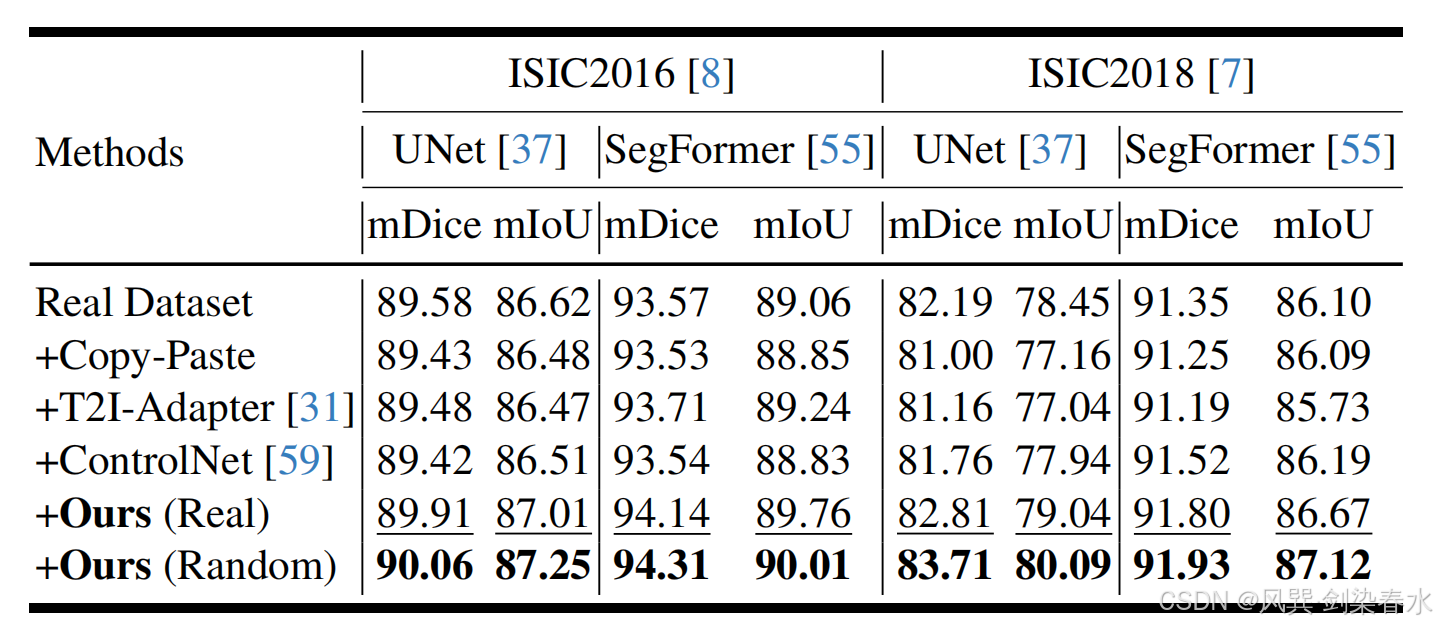
??
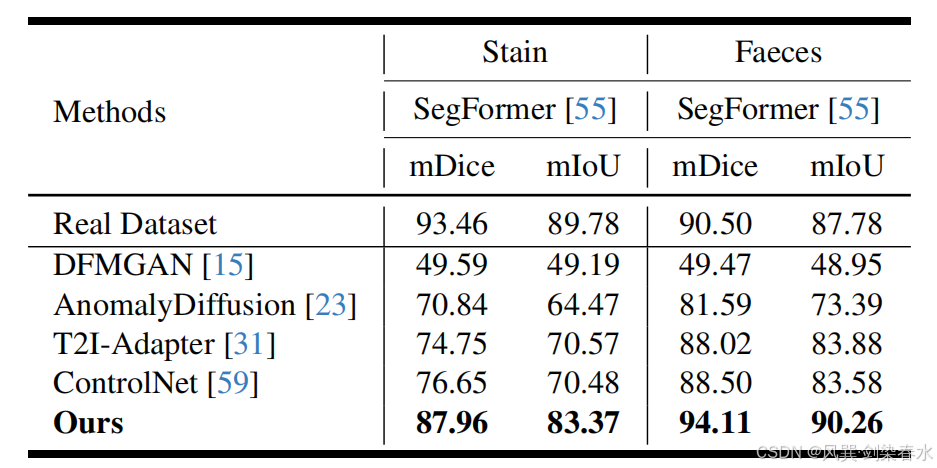
Table 4 | 以 mDice(%) 與 mIoU(%) 為指標,評估 SegFormer 的性能:訓練集包含各掩膜驅動方法生成的 1000 張 Stain/Faeces 合成圖像;
??
4.3、消融實驗
??
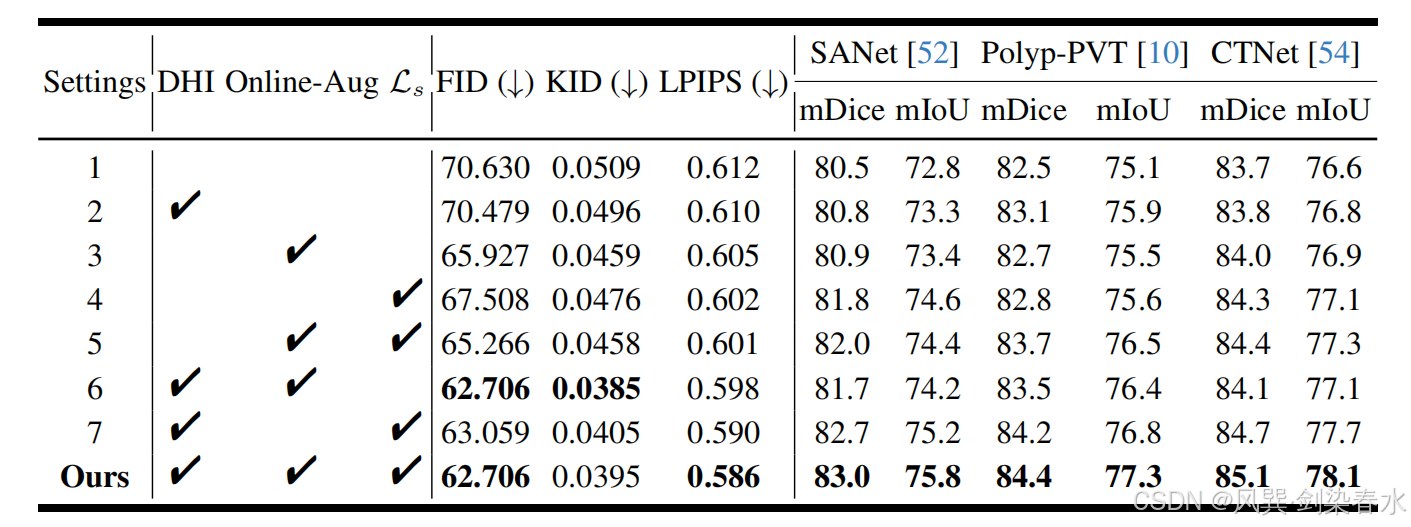
Table 5 | 不同模塊對息肉圖像質量及分割性能的影響比較:圖像質量以 FID、KID 和 LPIPS 評估;分割性能以加權 mDice(%) 與 mIoU(%) 在五個公共測試集上衡量;訓練集由真實息肉圖像與本方法在對應設置下生成的合成圖像共同構成;
??
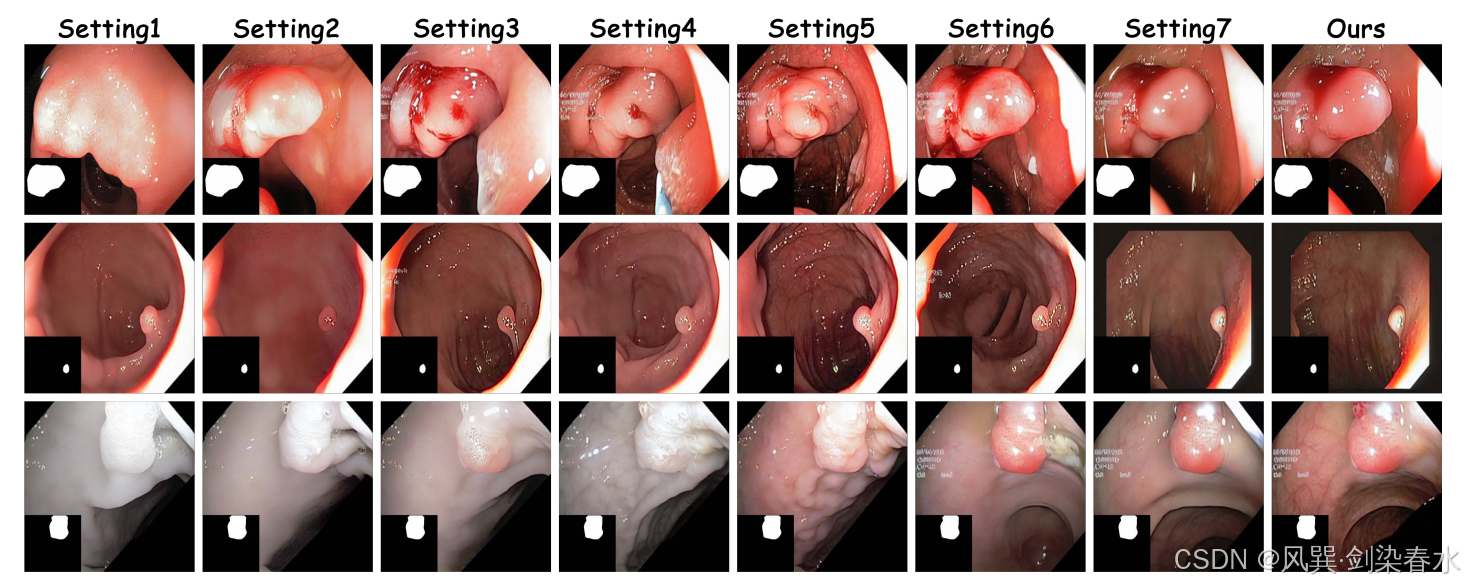
Figure 6 | 可視化不同組件對息肉圖像合成的影響:
??
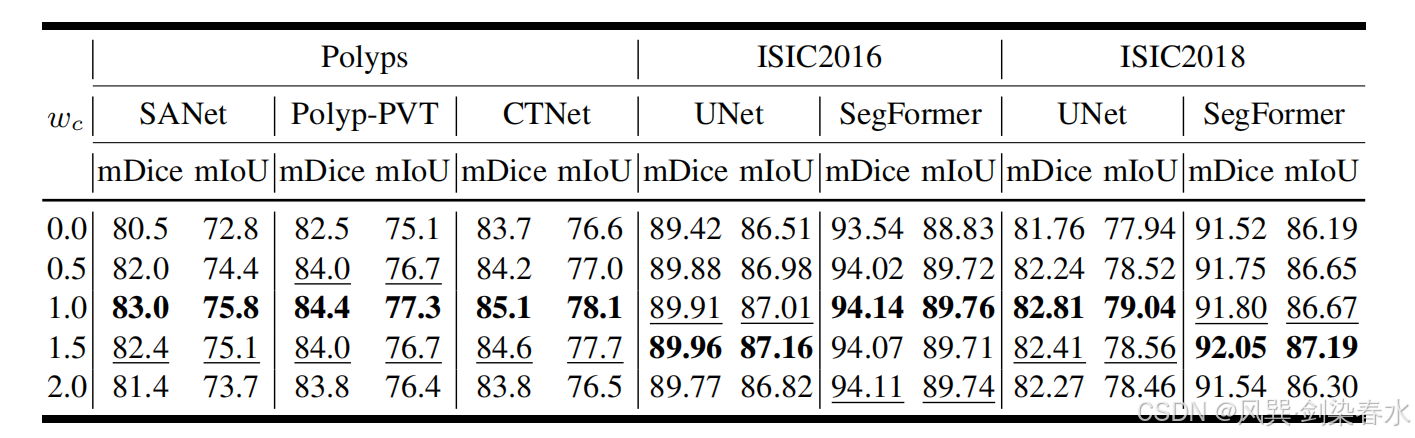
Table 6 | 以加權 mDice(%) 和 mIoU(%) 為指標,在三個數據集上比較不同 wcw_cwc? 取值對醫學圖像分割性能的影響:訓練集由真實圖像與本方法在相應 wcw_cwc? 下生成的合成圖像共同構成;
4.4、討論
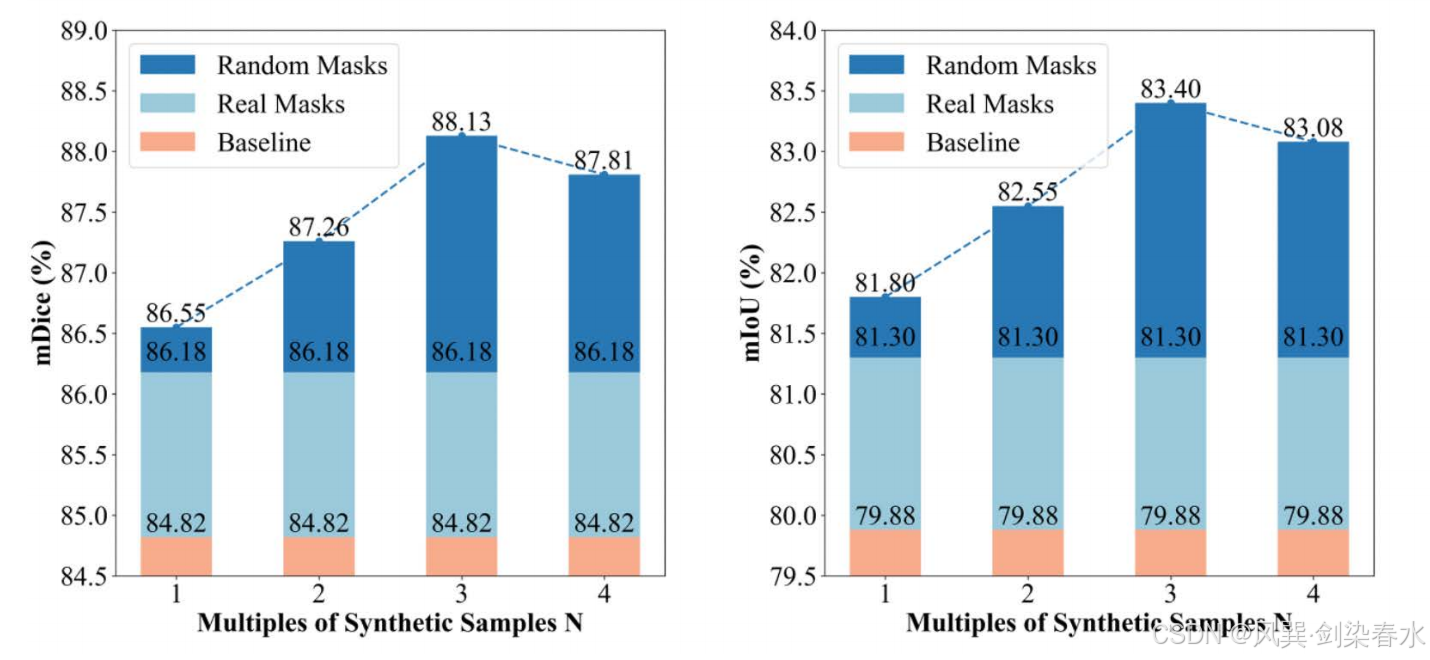
??可擴展性和形態多樣性是分割任務的關鍵因素。然而當增強數據量增至四倍時,性能提升效果出現下降。這一有趣現象可能源于息肉訓練集和測試集中復雜分布所引發的獨特“長尾效應”。
??
Figure 7 | 可視化 SegFormer 的 mDice(%) 與 mIoU(%) 變化趨勢:訓練集由真實息肉圖像與本方法按不同倍數生成的合成息肉圖像共同構成;
??核心問題還是如何生成更優質的數據(●’?’●)





)









)

)

