寫在前面
本系列推文為《R for Data Science (2)》的中文翻譯版本。所有內容都通過開源免費的方式上傳至Github,歡迎大家參與貢獻,詳細信息見:
Books-zh-cn 項目介紹:
Books-zh-cn:開源免費的中文書籍社區
r4ds-zh-cn Github 地址:
https://github.com/Books-zh-cn/r4ds-zh-cn
r4ds-zh-cn 網站地址:
https://books-zh-cn.github.io/r4ds-zh-cn/
目錄
-
Whole game
-
1.1 介紹
-
1.2 第一步
-
1.3 ggplot2 調用
Whole game
在本書的這一部分,我們的目標是快速為您概述數據科學的主要工具:importing, tidying, transforming, visualizing data,如 Figure 1 所示。我們希望向您展示數據科學的”整個游戲”,只提供足夠的主要要素,讓您能夠處理真實的、簡單的數據集。本書的后續部分將更深入地涵蓋每個主題,擴大您能夠處理的數據科學挑戰的范圍。
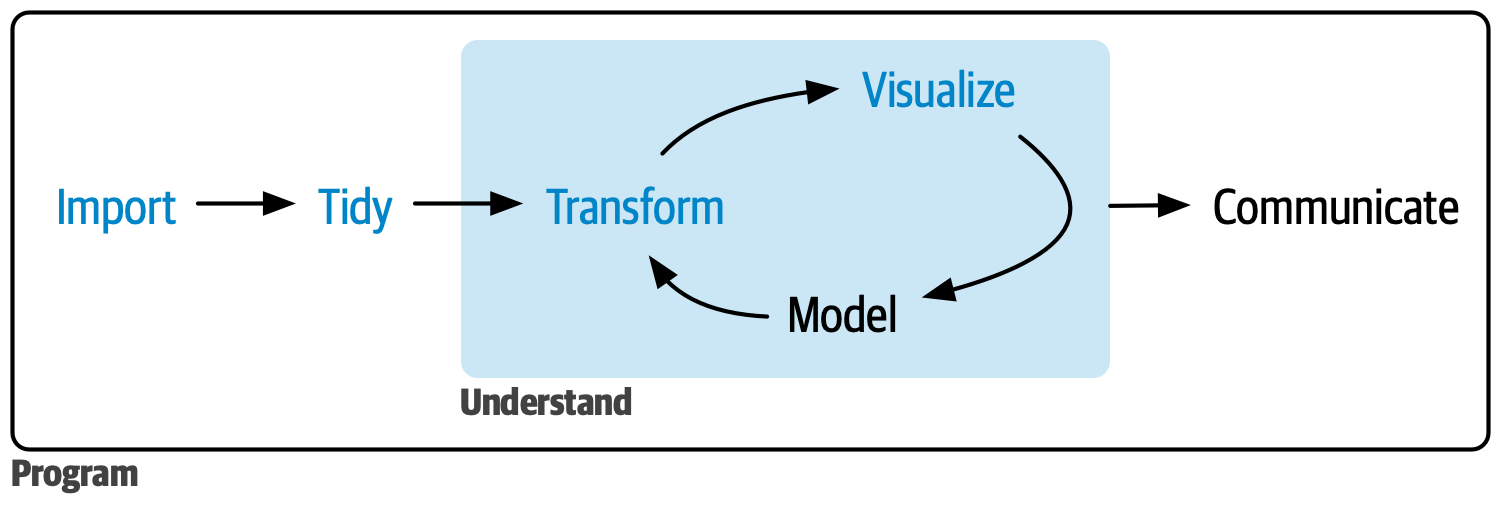
Figure 1: 在本書的這一部分,您將學習如何導入(import)、整理(tidy)、轉換(transform)、可視化(visualize)數據。
四個章節著重介紹數據科學的工具:
-
可視化(Visualization)是使用 R 編程的一個很好的起點,因為其收益非常明顯:您可以創建優雅且信息豐富的圖形,幫助您理解數據。在
1 Data visualization中,您將深入學習可視化,了解 ggplot2 plot 的基本結構,以及將數據轉化為圖形的強大技術。 -
僅僅進行可視化通常是不夠的,因此在
3 Data transformation,中,您將學習關鍵的動詞(verbs),這些動詞可以幫助您選擇重要的變量、過濾關鍵觀察結果、創建新變量和計算總結。 -
在
5 Data tidying中,您將學習關于整潔數據(tidy data)的知識,這是一種一致的存儲數據的方式,使轉換、可視化和建模變得更加容易。您將學習其基本原則,以及如何將數據整理成整潔的形式。 -
在您進行數據轉換和可視化之前,首先需要將數據導入 R 中。在
7 Data import中,您將學習如何將.csv文件導入 R 中的基礎知識。
除了這些章節之外,還有四個章節著重介紹您的 R 工作流程。在 2 Workflow: basics, 4 Workflow: code style, 6 Workflow: scripts and projects 中,您將學習編寫和組織 R 代碼的良好工作流程實踐。這些將為您的長遠成功奠定基礎,因為它們將為您在處理實際項目時保持組織提供工具。最后,8 Workflow: getting help 將教您如何獲取幫助和持續學習。
1.1 介紹
"The simple graph has brought more information to the data analyst's mind than any other device.” — John Tukey
R 有幾種用于制作圖形的系統,但 ggplot2 是最優雅和最多功能的之一。ggplot2 實現了圖形語法(grammar of graphics),這是一套一致的描述和構建圖形的系統。通過 ggplot2,你可以更多更快地學習一個系統,并在許多地方應用。
本章將教您如何使用 ggplot2 可視化數據。我們將從創建一個簡單的散點圖(scatterplot)開始,并使用它來介紹美學映射(aesthetic mappings)和幾何對象(geometric objects)– ggplot2 的基本構建塊。然后,我們將向您展示如何可視化單個變量的分布以及可視化兩個或多個變量之間的關系。最后,我們將介紹如何保存您的圖形并提供故障排除提示。
1.1.1 先決條件
本章重點介紹 ggplot2,它是 tidyverse 中的核心包之一。要訪問本章中使用的數據集、幫助頁面和函數,請運行以下命令加載 tidyverse:
library(tidyverse)
#>?──?Attaching?core?tidyverse?packages?─────────────────────?tidyverse?2.0.0?──
#>???dplyr?????1.1.4???????readr?????2.1.5
#>???forcats???1.0.0???????stringr???1.5.1
#>???ggplot2???3.5.2???????tibble????3.3.0
#>???lubridate?1.9.4???????tidyr?????1.3.1
#>???purrr?????1.0.4?????
#>?──?Conflicts?───────────────────────────────────────?tidyverse_conflicts()?──
#>???dplyr::filter()?masks?stats::filter()
#>???dplyr::lag()????masks?stats::lag()
#>???Use?the?conflicted?package?(<http://conflicted.r-lib.org/>)?to?force?all?conflicts?to?become?errors
這一行代碼加載了核心的 tidyverse,這些包在幾乎每個數據分析中都會使用。它還會告訴您 tidyverse 中的哪些函數與 base R(或其他已加載的包)中的函數存在沖突。
如果您運行此代碼并收到 there is no package called 'tidyverse' 的錯誤消息,則需要先安裝它,然后再次運行 library()。
install.packages("tidyverse")
library(tidyverse)
您只需要安裝一個包一次,但每次開始新會話時都需要加載(load)它。
除了 tidyverse 之外,我們還將使用 palmerpenguins 包,其中包含了 penguins 數據集,該數據集包含了帕爾默群島上三個島嶼上企鵝的身體測量數據。還有 ggthemes 包,它提供了一個適用于色盲的安全調色板。
library(palmerpenguins)
#>?
#>?Attaching?package:?'palmerpenguins'
#>?The?following?objects?are?masked?from?'package:datasets':
#>?
#>?????penguins,?penguins_raw
library(ggthemes)
1.2 第一步
企鵝的翼展較長的是否比翼展較短的體重更重還是更輕?您可能已經有了答案,但請盡量給出精確的回答。翼展長度和體重之間的關系是怎樣的?是正相關的嗎?還是負相關的?是線性的嗎?還是非線性的?這種關系是否因企鵝的物種而異?島嶼的差異是否會對關系產生影響?讓我們創建可視化圖表來回答這些問題。
1.2.1 penguins 數據框
您可以使用 palmerpenguins 包中的 penguins 數據框(data frame)來測試您對這些問題的回答(即 palmerpenguins::penguins)。一個 data frame 是一種由變量(列)和觀測(行)組成的矩形集合。penguins 包含 344 個觀測值,由 Dr. Kristen Gorman 和 Palmer Station, Antarctica LTER 搜集提供。
為了方便討論,讓我們定義一些術語:
-
variable 是可以進行測量的數量、特性或屬性。
-
value 是在測量時 variable 所處的狀態。variable 的 value 可能會在每次測量時發生變化。
-
observation 是在類似條件下進行的一組測量(通常在同一時間和同一對象上進行所有測量)。一個 observation 會包含多個 values,每個 value 與不同的 variable 相關聯。我們有時將一個 observation 稱為一個數據點。
-
Tabular data 是一組 values,每個 value 與一個 variable 和一個 observation 相關聯。如果每個 value 都放置在自己的”單元格”中,每個 variable 都在自己的列中,每個 observation 都在自己的行中,那么 Tabular data 就是整潔(tidy)的。
在這個案例中,variable 指的是所有企鵝的屬性,observation 指的是單個企鵝的所有屬性。
在控制臺中鍵入 data frame 的名稱,R 將打印出其內容的預覽。請注意,預覽的頂部顯示著 tibble。在 tidyverse 中,我們使用特殊的 data frames 稱為 tibbles,您很快將學到更多關于它的知識。
penguins
#>?#?A?tibble:?344?×?8
#>???species?island????bill_length_mm?bill_depth_mm?flipper_length_mm
#>???<fct>???<fct>??????????????<dbl>?????????<dbl>?????????????<int>
#>?1?Adelie??Torgersen???????????39.1??????????18.7???????????????181
#>?2?Adelie??Torgersen???????????39.5??????????17.4???????????????186
#>?3?Adelie??Torgersen???????????40.3??????????18?????????????????195
#>?4?Adelie??Torgersen???????????NA????????????NA??????????????????NA
#>?5?Adelie??Torgersen???????????36.7??????????19.3???????????????193
#>?6?Adelie??Torgersen???????????39.3??????????20.6???????????????190
#>?#???338?more?rows
#>?#???3?more?variables:?body_mass_g?<int>,?sex?<fct>,?year?<int>
該 data frame 包含 8 列。如果想要以另一種視圖查看所有變量和每個變量的前幾個觀察值,請使用 glimpse() 函數。或者,如果您在 RStudio 中運行,請使用 View(penguins) 打開一個交互式數據查看器。
glimpse(penguins)
#>?Rows:?344
#>?Columns:?8
#>?$?species???????????<fct>?Adelie,?Adelie,?Adelie,?Adelie,?Adelie,?Adelie,?A…
#>?$?island????????????<fct>?Torgersen,?Torgersen,?Torgersen,?Torgersen,?Torge…
#>?$?bill_length_mm????<dbl>?39.1,?39.5,?40.3,?NA,?36.7,?39.3,?38.9,?39.2,?34.…
#>?$?bill_depth_mm?????<dbl>?18.7,?17.4,?18.0,?NA,?19.3,?20.6,?17.8,?19.6,?18.…
#>?$?flipper_length_mm?<int>?181,?186,?195,?NA,?193,?190,?181,?195,?193,?190,?…
#>?$?body_mass_g???????<int>?3750,?3800,?3250,?NA,?3450,?3650,?3625,?4675,?347…
#>?$?sex???????????????<fct>?male,?female,?female,?NA,?female,?male,?female,?m…
#>?$?year??????????????<int>?2007,?2007,?2007,?2007,?2007,?2007,?2007,?2007,?2…
penguins 中的變量包括:
-
species: 一只企鵝的物種 (Adelie, Chinstrap, or Gentoo)。 -
flipper_length_mm: 企鵝的腳鰭長度,以毫米為單位。 -
body_mass_g: 企鵝的體重,以克為單位。
要了解更多關于 penguins 的信息,請運行 ?penguins 打開其幫助頁面。
1.2.2 最終目標
在本章中,我們的最終目標(ultimate goal)是重新創建以下可視化圖表,顯示企鵝的翼展長度(flipper lengths)和體重(body masses)之間的關系,并考慮企鵝的物種(species)差異。
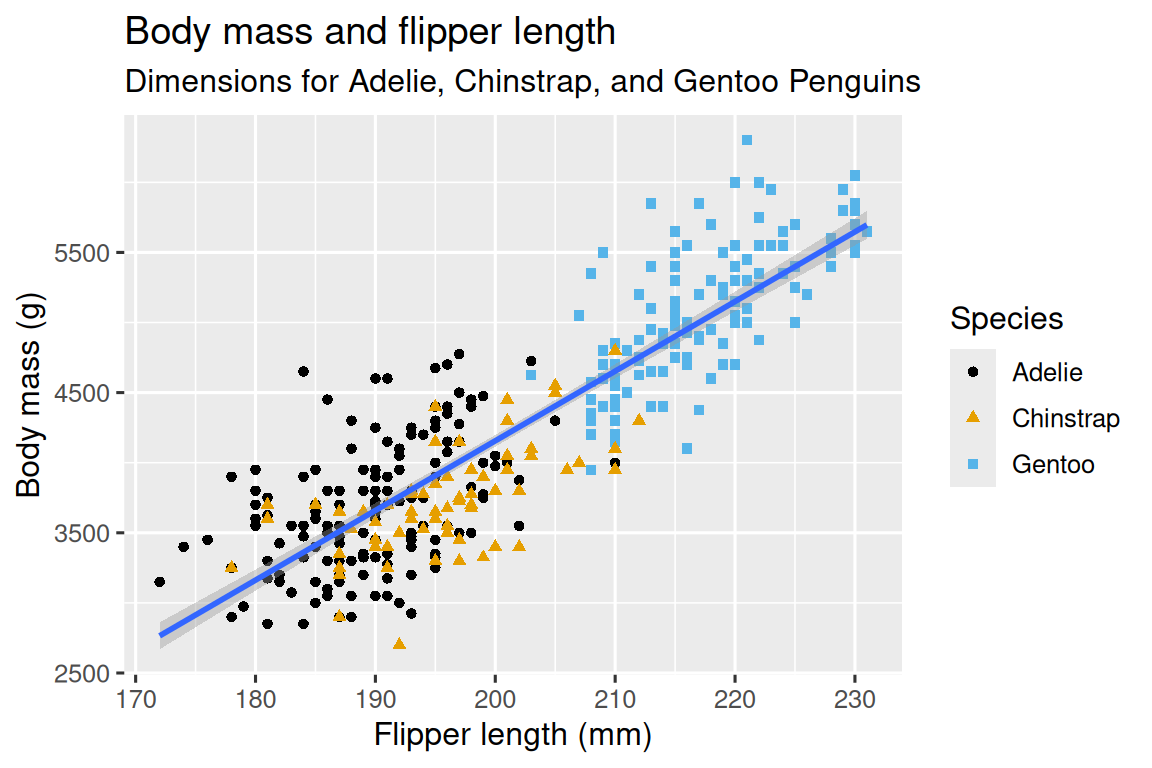
1.2.3 創建一個 ggplot
讓我們逐步重新創建這個圖表。
在 ggplot2 中,你可以使用函數 ggplot() 開始一個繪圖過程,定義一個繪圖對象,然后向其添加圖層(layers)。ggplot() 的第一個參數是要在圖表中使用的數據集(dataset),因此 ggplot(data = penguins) 創建了一個空圖表(empty graph),準備展示 penguins 數據集,但由于我們尚未告訴它如何進行可視化,所以目前它是空的。這并不是一個非常令人興奮的圖表,但你可以將其看作是一個空白的畫布,你將在其上繪制剩下的圖層。
ggplot(data?=?penguins)

接下來,我們需要告訴 ggplot() 如何將數據的信息進行可視化表示。ggplot() 函數的 mapping 參數定義了數據集中的變量如何映射到圖表的視覺屬性(aesthetics)。mapping 參數總是在 aes() 函數中定義,aes() 函數的 x 和 y 參數指定要映射到 x 軸和 y 軸的變量。目前,我們僅將翼展長度(flipper length)映射到 x aesthetic,將體重(body mass)映射到 y aesthetic。ggplot2 會在 data 參數中尋找映射的變量,此處為 penguins 數據集。
下面的圖展示了添加這些映射后的結果。
ggplot(data?=?penguins,mapping?=?aes(x?=?flipper_length_mm,?y?=?body_mass_g)
)
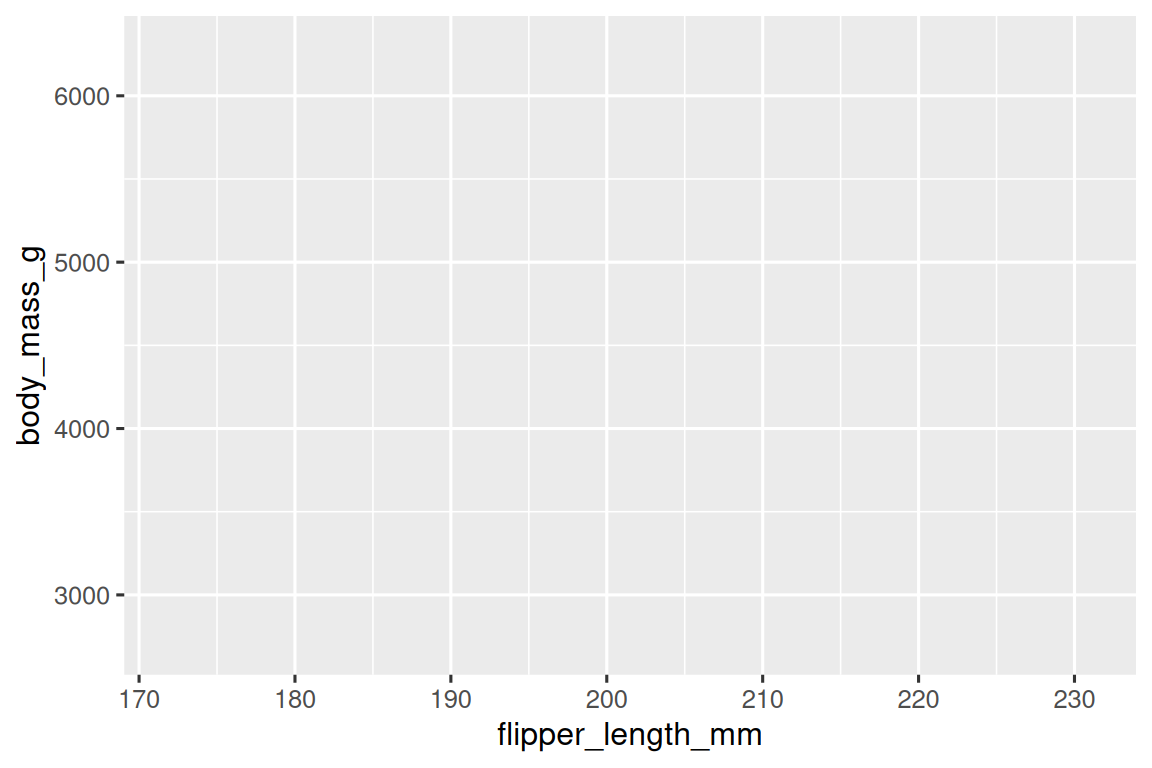
我們的空白畫布現在具有了更多的結構 – 可以清楚地看到翼展長度(flipper lengths)將顯示在 x-axis 上,體重(body masses)將顯示在 y-axis 上。但是企鵝的觀測值還沒有顯示在圖表上。這是因為我們在代碼中尚未明確指定如何在圖表上表示數據框中的觀測值。
為了實現這一點,我們需要定義一個幾何對象(geom):用于表示數據的圖表中的幾何對象。在 ggplot2 中,可以使用以 geom_ 開頭的函數來獲得這些幾何對象。人們通常通過圖表使用的幾何對象類型來描述圖表。例如,柱狀圖使用柱狀幾何對象(geom_bar()),折線圖使用線條幾何對象(geom_line()),箱線圖使用箱線幾何對象(geom_boxplot()),散點圖使用點幾何對象(geom_point()),等等。
函數 geom_point() 將一層點添加到您的圖表中,從而創建一個散點圖。ggplot2 提供了許多不同類型的幾何函數,每個函數都可以向圖表添加不同類型的圖層(layer)。在本書中,您將學習到許多不同的幾何函數,特別是在 Chapter 9 中。
ggplot(data?=?penguins,mapping?=?aes(x?=?flipper_length_mm,?y?=?body_mass_g)
)?+geom_point()
#>?Warning:?Removed?2?rows?containing?missing?values?or?values?outside?the?scale?range
#>?(`geom_point()`).
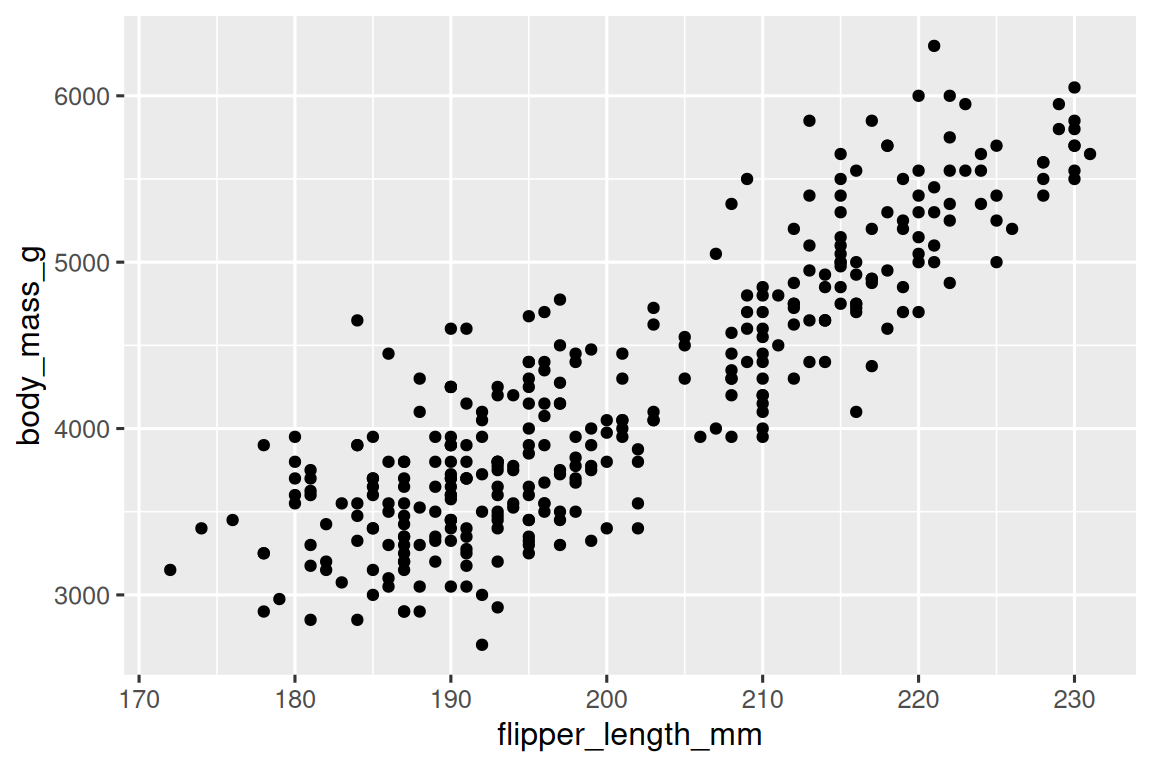
現在我們有了一個看起來像是”散點圖(scatterplot)”的圖表。它還不完全符合我們的”最終目標”圖表,但使用這個圖表,我們可以開始回答我們探索的問題:“翼展長度(flipper length)和體重(body mass)之間的關系是什么樣的?” 這個關系似乎是正向的(隨著翼展長度(flipper length)的增加,體重(body mass)也增加),相當線性(點圍繞在一條線附近而不是曲線上),并且中等強度(這條線附近沒有太多的散點)。翼展較長的企鵝通常在體重上也較大。
在我們為這個圖表添加更多圖層之前,讓我們暫停一下并回顧一下我們收到的警告信息(warning message):
Removed 2 rows containing missing values (
geom_point()).
我們看到這個警告信息是因為我們的數據集中有兩個企鵝的體重和/或翼展長度值缺失,而 ggplot2 沒有辦法在圖表上表示它們,因為需要同時具備這兩個值。與 R 一樣,ggplot2 遵循這樣的理念:缺失值永遠不應該悄悄地丟失。這種警告通常是您在處理實際數據時最常見的警告之一 – 缺失值是一個非常常見的問題,在本書中您將在 Chapter 18 中學到更多相關知識。在本章的其余圖表中,我們將禁止顯示這個警告信息,以免在每個圖表旁邊都打印出來。
1.2.4 添加美學和圖層
散點圖對于顯示兩個數值變量之間的關系非常有用,但是對于兩個變量之間的任何明顯關系,保持懷疑態度并詢問是否存在其他變量來解釋或改變這種明顯關系的性質總是一個好主意。例如,翼展長度(flipper length)和體重(body mass)之間的關系是否因物種(species)而異?讓我們將物種(species)信息加入到我們的圖表中,看看這是否揭示了這些變量之間明顯關系的其他洞察。我們將使用不同顏色的點來表示不同的物種(species)。
為了實現這一點,我們需要修改 aesthetic 或 geom 部分嗎?如果你猜到了”in the aesthetic mapping, inside of aes()“,那么你已經開始掌握使用 ggplot2 創建數據可視化的方法了!如果沒有,不用擔心。在本書中,你將制作更多的 ggplots,并有更多的機會在制作圖表時檢驗你的直覺。
ggplot(data?=?penguins,mapping?=?aes(x?=?flipper_length_mm,?y?=?body_mass_g,?color?=?species)
)?+geom_point()
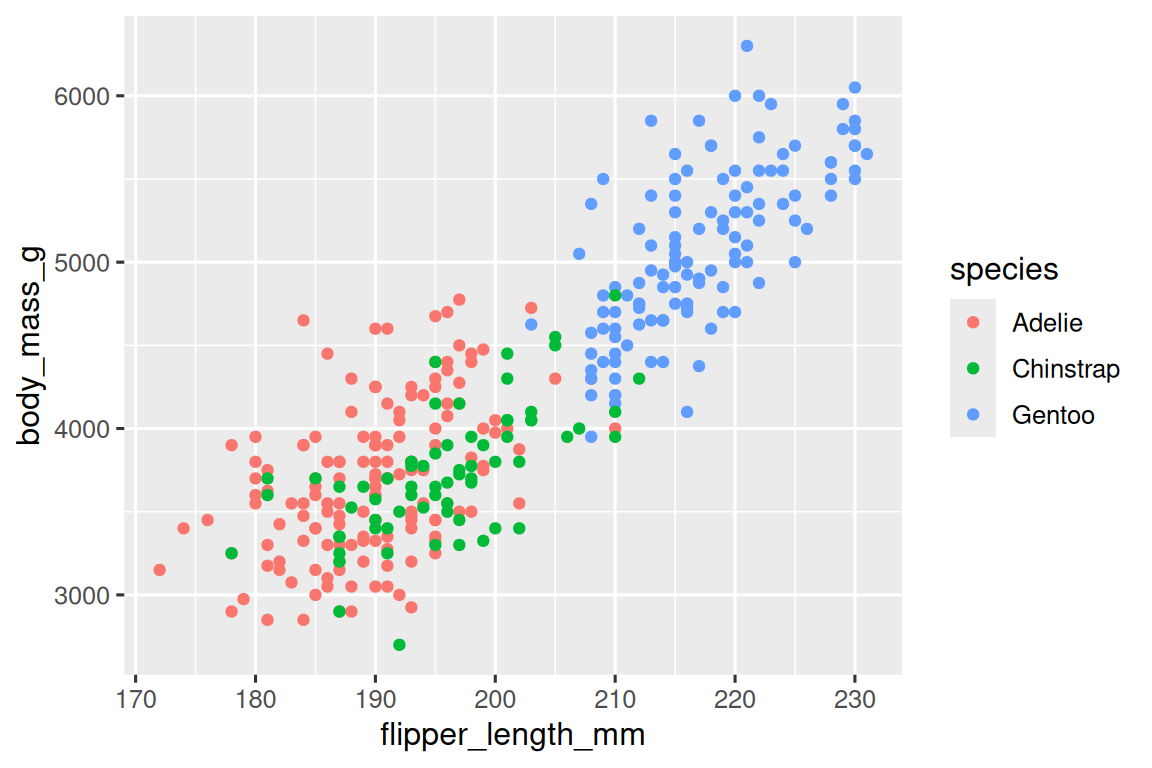
當將一個分類變量映射到一個 aesthetic 時,ggplot2 會自動為每個唯一的變量水平(每個物種)分配一個唯一的 aesthetic 值(這里是唯一的 color),這個過程被稱為縮放(scaling)。ggplot2 還會添加一個圖例(legend),解釋哪些值對應于哪些水平。
現在讓我們添加一個額外的圖層:一個顯示體重(body mass)和翼展長度(flipper length)之間關系的平滑曲線。在繼續之前,請回顧上面的代碼,并思考如何將其添加到我們現有的圖表中。
由于這是一個表示數據的新幾何對象,我們將在我們的 point geom 之上添加一個新的幾何層:geom_smooth()。我們將通過 method = "lm" 指定使用線性模型(linear model)來繪制最佳擬合線。
ggplot(data?=?penguins,mapping?=?aes(x?=?flipper_length_mm,?y?=?body_mass_g,?color?=?species)
)?+geom_point()?+geom_smooth(method?=?"lm")
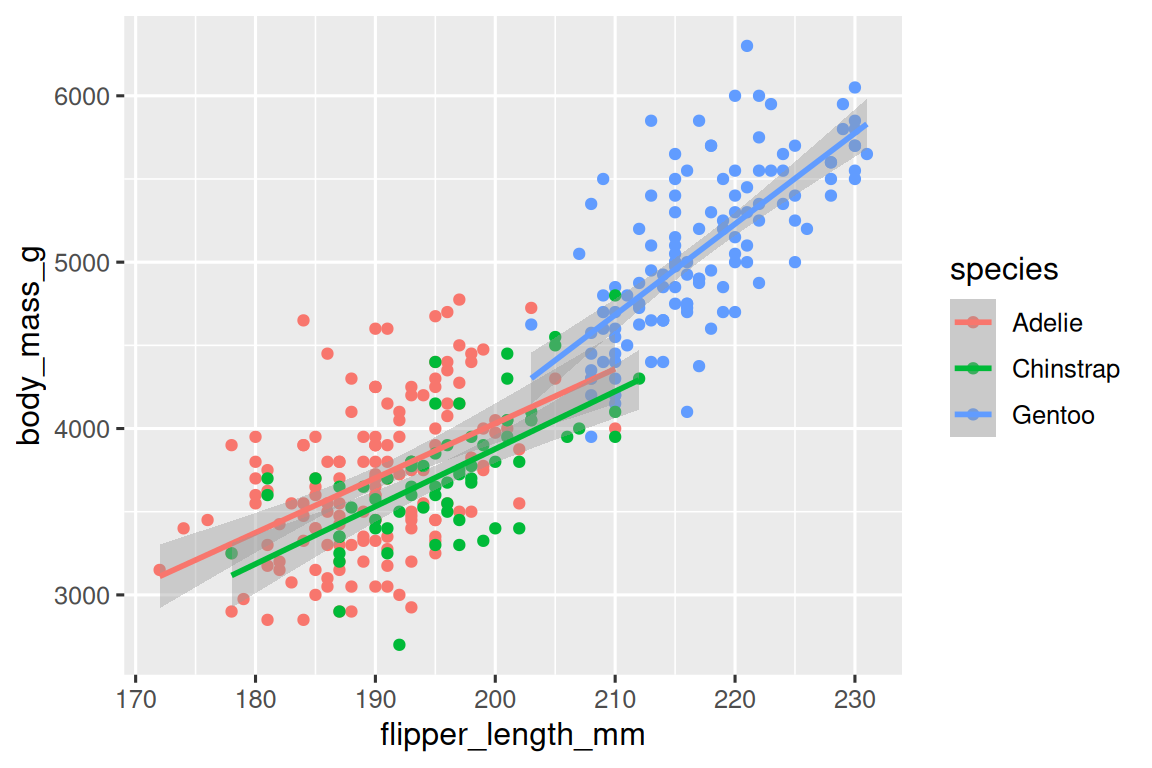
我們成功地添加了線條,但是這個圖形看起來與 Section 2.2.2 提供的圖形不同,Section 2.2.2 的圖形只有一條線表示整個數據集,而不是每個企鵝物種都有獨立的線條。
當在 ggplot() 中定義 aesthetic mappings 時,在全局級別(global level)上,它們會傳遞給繪圖的每個后續幾何層(geom layers)。然而,ggplot2 中的每個幾何函數也可以接受一個 mapping 參數,該參數允許在局部級別(local level)上進行 aesthetic mappings,并將其添加到從全局級別繼承的映射中。由于我們希望點的顏色根據物種進行著色,但不希望將線條分開顯示,所以我們應該僅對 geom_point() 指定 color = species。
ggplot(data?=?penguins,mapping?=?aes(x?=?flipper_length_mm,?y?=?body_mass_g)
)?+geom_point(mapping?=?aes(color?=?species))?+geom_smooth(method?=?"lm")
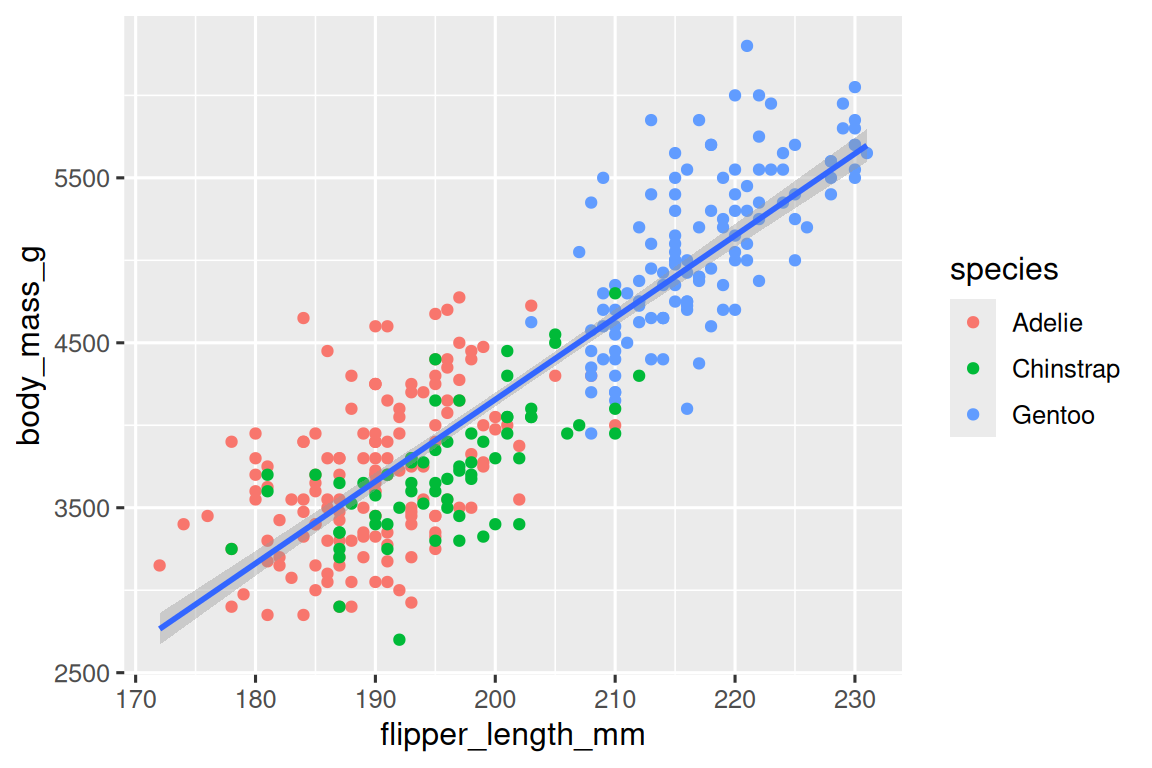
太棒了!我們已經接近我們的最終目標,盡管還不完美。我們仍然需要為每個企鵝物種使用不同的形狀,并改進標簽。
在繪圖中僅使用顏色來表示信息通常不是一個好主意,因為由于色盲或其他色覺差異,人們對顏色的感知有所不同。因此,除了顏色之外,我們還可以將 species 映射到 shape aesthetic 上。
ggplot(data?=?penguins,mapping?=?aes(x?=?flipper_length_mm,?y?=?body_mass_g)
)?+geom_point(mapping?=?aes(color?=?species,?shape?=?species))?+geom_smooth(method?=?"lm")
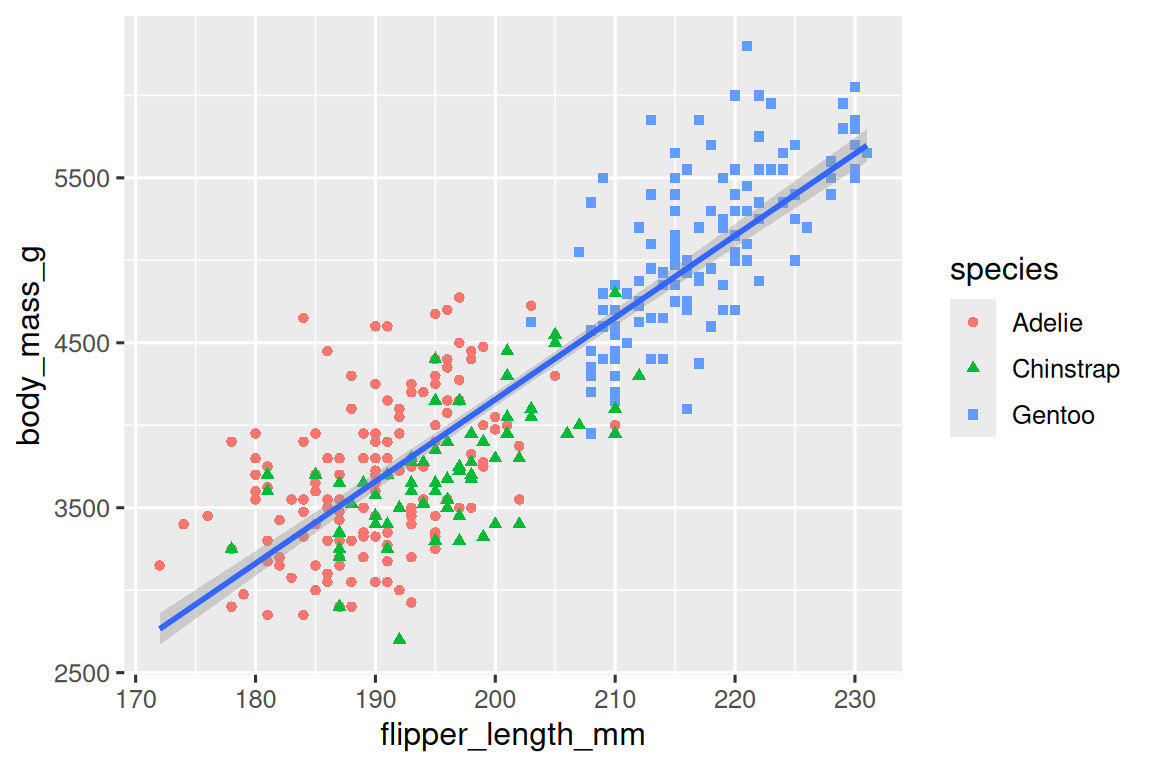
請注意,圖例(legend)會自動更新以反映點的不同形狀。
最后,我們可以使用 labs() 函數在新的圖層中改進我們繪圖的標簽。labs() 的一些參數可能是不言自明的:title 添加標題,subtitle 添加副標題到繪圖中。其他參數與美學映射相匹配,x 是 x 軸標簽,y 是 y 軸標簽,color 和 shape 定義圖例的標簽。此外,我們可以使用 ggthemes 包中的 scale_color_colorblind() 函數改進顏色調色板,使其適合色盲人士使用。
ggplot(data?=?penguins,mapping?=?aes(x?=?flipper_length_mm,?y?=?body_mass_g)
)?+geom_point(aes(color?=?species,?shape?=?species))?+geom_smooth(method?=?"lm")?+labs(title?=?"Body?mass?and?flipper?length",subtitle?=?"Dimensions?for?Adelie,?Chinstrap,?and?Gentoo?Penguins",x?=?"Flipper?length?(mm)",?y?=?"Body?mass?(g)",color?=?"Species",?shape?=?"Species")?+scale_color_colorblind()
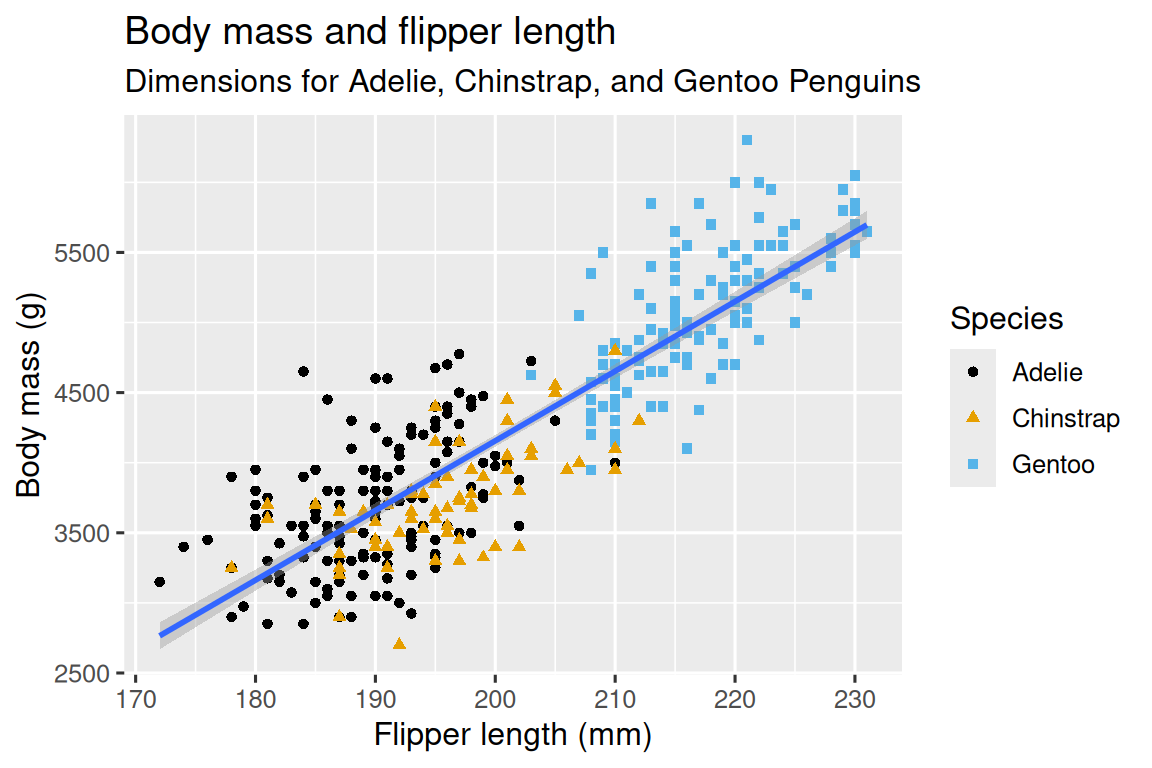
我們最終有了一個完全符合我們”最終目標”的圖!
1.2.5 練習
-
penguins有多少行(rows)?有多少列(columns)? -
penguins數據框中的bill_depth_mm變量描述了什么?請閱讀?penguins的幫助文檔來獲取答案。 -
創建一個
bill_depth_mmvs.bill_length_mm的散點圖。也就是說,在 y-axis 上繪制bill_depth_mm,在 x-axis 上繪制bill_length_mm。描述這兩個變量之間的關系。 -
如果你繪制
speciesvs.bill_depth_mm的散點圖,會發生什么?選擇什么樣的幾何圖形可能更好? -
為什么下面的代碼會出錯,如何修復它?
ggplot(data?=?penguins)?+?
geom_point()
-
在
geom_point()中,na.rm參數的作用是什么?這個參數的默認值是什么?創建一個散點圖,并成功地將該參數設置為TRUE。 -
在前面繪制的圖中添加以下說明:“Data come from the palmerpenguins package.” 提示:查看
labs()的文檔。 -
重新創建以下可視化圖形。
bill_depth_mm應該映射到哪個美學屬性?這個映射是應該在全局級別(global level)還是幾何級別(geom level)上完成?
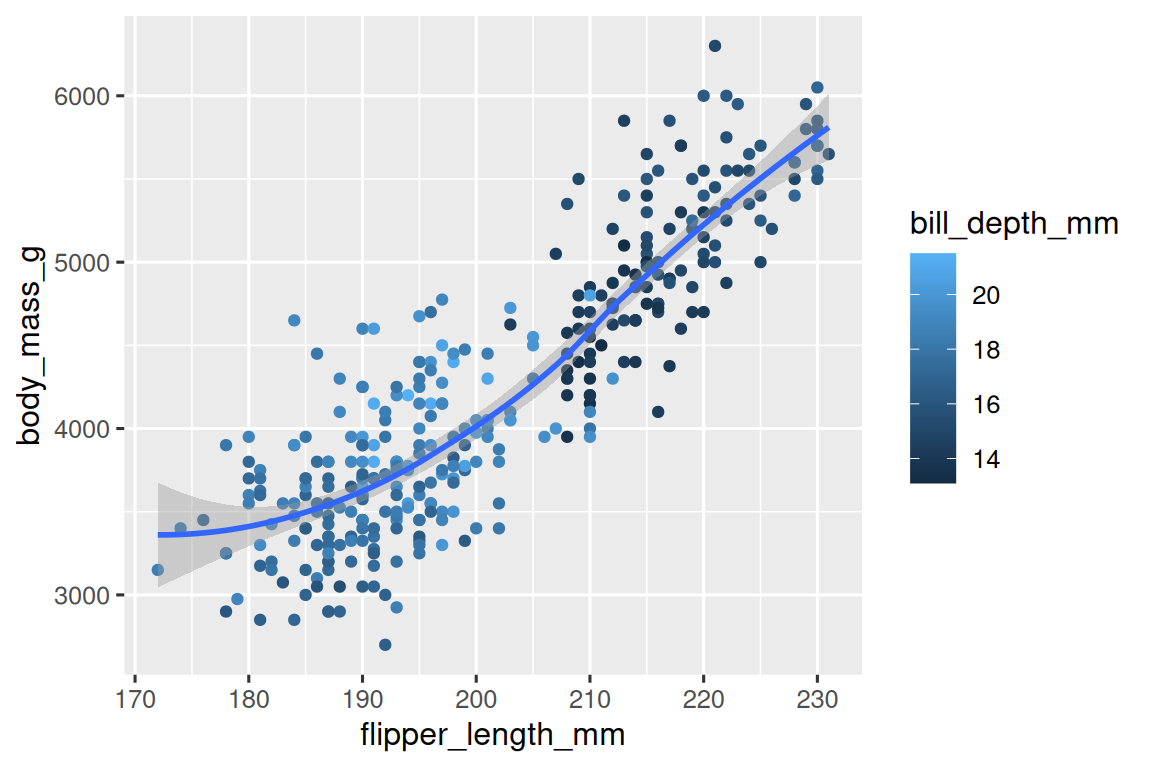
-
在腦海中運行此代碼并預測輸出結果。 然后,在 R 中運行代碼并檢查您的預測。
ggplot(data?=?penguins,mapping?=?aes(x?=?flipper_length_mm,?y?=?body_mass_g,?color?=?island)
)?+geom_point()?+geom_smooth(se?=?FALSE)
-
這兩張圖看起來會不一樣嗎?為 什么/為什么不?
ggplot(data?=?penguins,mapping?=?aes(x?=?flipper_length_mm,?y?=?body_mass_g)
)?+geom_point()?+geom_smooth()ggplot()?+geom_point(data?=?penguins,mapping?=?aes(x?=?flipper_length_mm,?y?=?body_mass_g))?+geom_smooth(data?=?penguins,mapping?=?aes(x?=?flipper_length_mm,?y?=?body_mass_g))
1.3 ggplot2 調用
隨著我們從這些介紹性部分繼續前進,我們將過渡到 ggplot2 代碼的更簡潔的表達。到目前為止,我們一直非常明確,這在學習過程中是很有幫助的:
ggplot(data?=?penguins,mapping?=?aes(x?=?flipper_length_mm,?y?=?body_mass_g)
)?+geom_point()
通常,函數的前一個或兩個參數非常重要,你應該熟記于心。ggplot() 函數的前兩個參數是 data 和 mapping,在本書的其余部分,我們不再提供這些參數的名稱。這樣做可以節省輸入的工作量,并通過減少額外文本的數量,更容易看出繪圖之間的區別。這是一個非常重要的編程問題,在 Chapter 25 中我們會再次涉及到這個問題。
對先前的繪圖進行更簡潔的重寫可以得到:
ggplot(penguins,?aes(x?=?flipper_length_mm,?y?=?body_mass_g))?+?geom_point()
在將來,您還將學習使用管道操作符 |> 來創建該繪圖,如下所示:
penguins?|>?ggplot(aes(x?=?flipper_length_mm,?y?=?body_mass_g))?+?geom_point()
--------------- 未完待續 ---------------
本期翻譯貢獻:
-
@TigerZ生信寶庫



)



安裝xfce桌面以及遠程環境)











