目錄
一、三級緩存和內存布局
二、CPU架構
(1)SMP對稱對處理器架構
(2)NUMA非統一內存架構
三、RCU機制在內核中的體現
四、內存優化屏障
(1)編譯器、CPU優化
(2)優化的問題和解決辦法
(3)volatile關鍵字
????????在學習Linux或者c++的時候,經常會看到緩存、內存、寄存器這樣的字眼。只知道他們都是用于存儲數據、指令的,且有效率之分,但是具體的框圖并不了解。本篇文章以此為基礎,延伸到CPU的架構等問題。
一、三級緩存和內存布局
? ? ? ? 我們知道當前主流的計算機是符合馮諾依曼體系架構的。內存位于所有結構的中心,任何外設想要進行數據交換都必須先把數據、指令交給內存,然后分別從內存中讀取。
? ? ? ? 如下圖所示: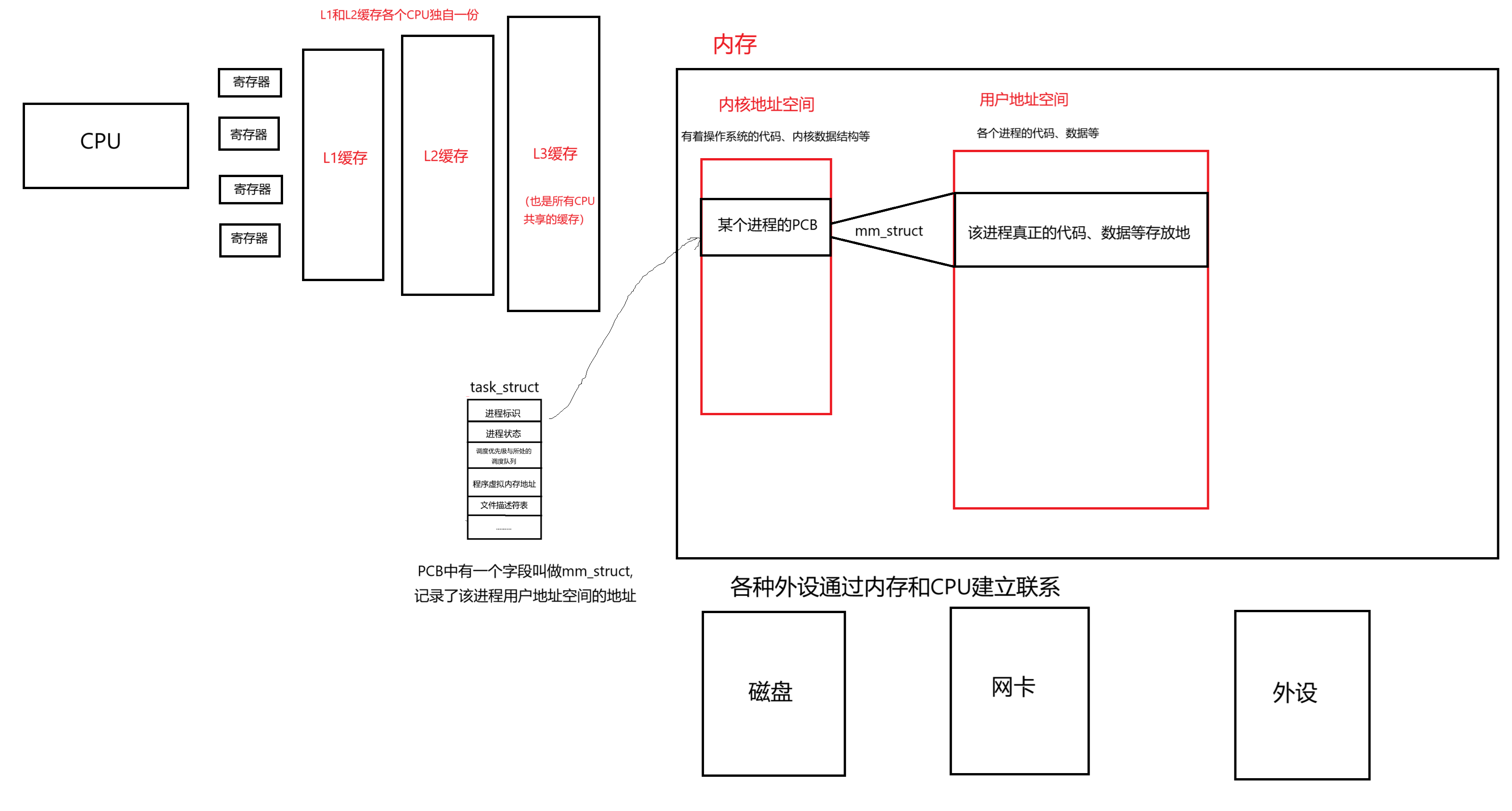
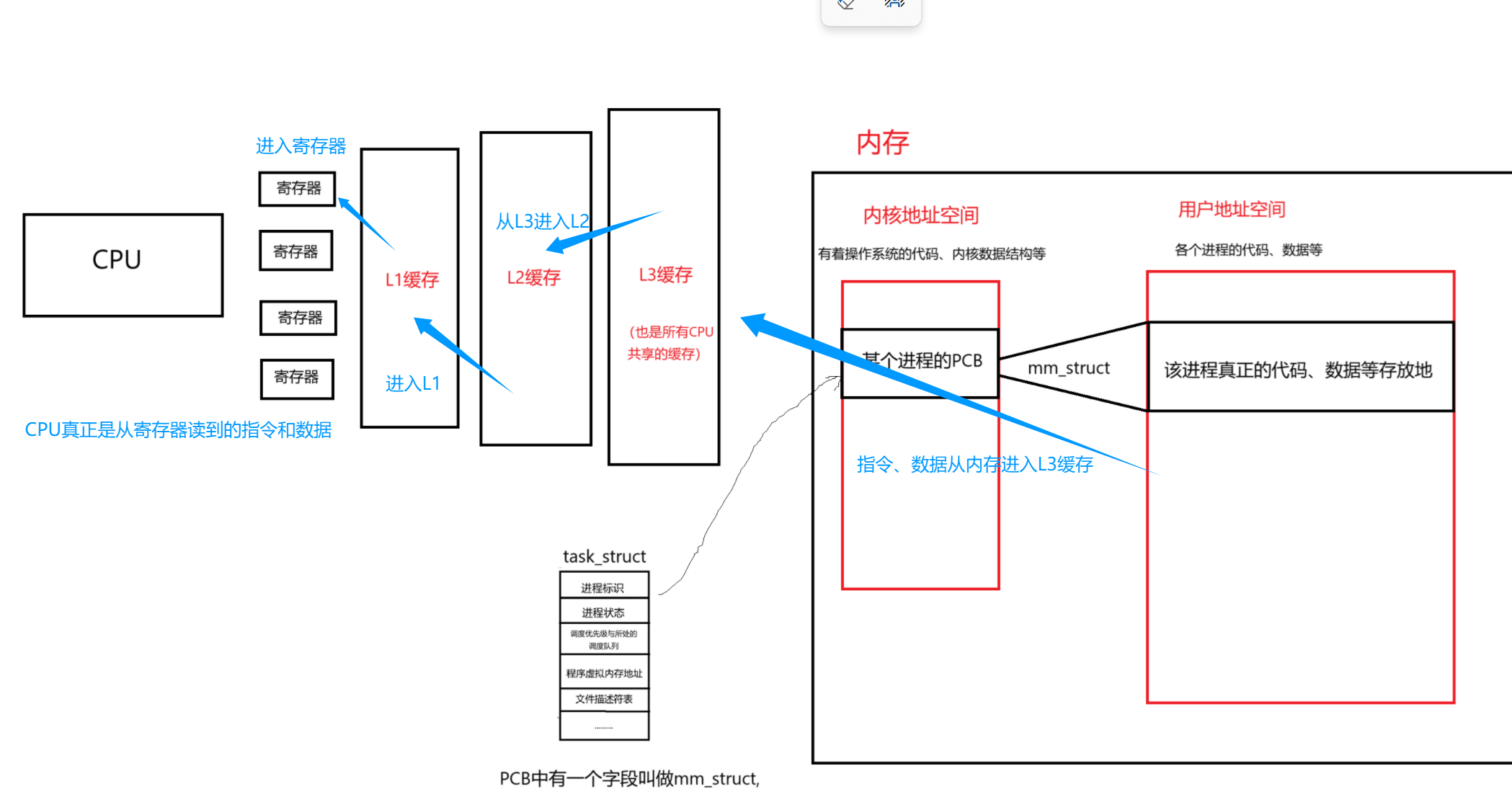
有了這樣一份基礎架構,我們就能更好的理解CPU運行的時候,是如何從內存得到指令和數據的。
????????即調度器把某個進程的PCB給到CPU,然后CPU根據PCB里面的地址找到物理內存要數據、指令,通過三級緩存和寄存器逐級交付,最終傳遞給CPU的過程。
二、CPU架構
(1)SMP對稱對處理器架構
????????SMP(Symmetric Multi - Processing)架構中,多個 CPU 核心共享統一的內存空間、I/O 設備等系統資源,并且所有 CPU 核心的地位平等,它們可以無差別地訪問內存、外設等,操作系統可以將任務動態分配到任意一個 CPU 核心上執行。
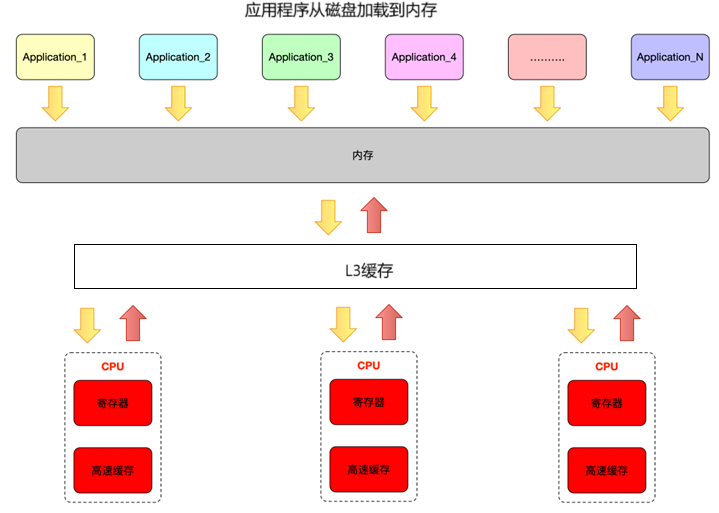
優點:
??
- 易于編程:對于開發者來說,SMP 架構下的編程模型相對簡單,因為所有 CPU 核心對系統資源的訪問方式基本相同,不需要考慮太多復雜的資源分配和訪問差異問題。
- 負載均衡:操作系統能夠方便地在各個 CPU 核心之間進行任務調度,實現負載均衡,充分利用各個核心的計算能力。
缺點:
?
- 內存訪問瓶頸:隨著 CPU 核心數量的增加,所有核心都訪問同一個內存空間,會導致內存總線的競爭加劇,從而形成性能瓶頸。
- 可擴展性受限:由于共享內存等資源的限制,當核心數量增加到一定程度時,性能提升不明顯甚至會下降。
(2)NUMA非統一內存架構
????????NUMA(Non - Uniform Memory Access)架構中,多個 CPU 核心被劃分成不同的節點,每個節點都有自己的本地內存,同時也可以訪問其他節點的內存,但訪問本地內存的速度要比訪問遠程(其他節點)內存的速度快。操作系統需要考慮內存分配與 CPU 核心的位置關系,以提高性能。
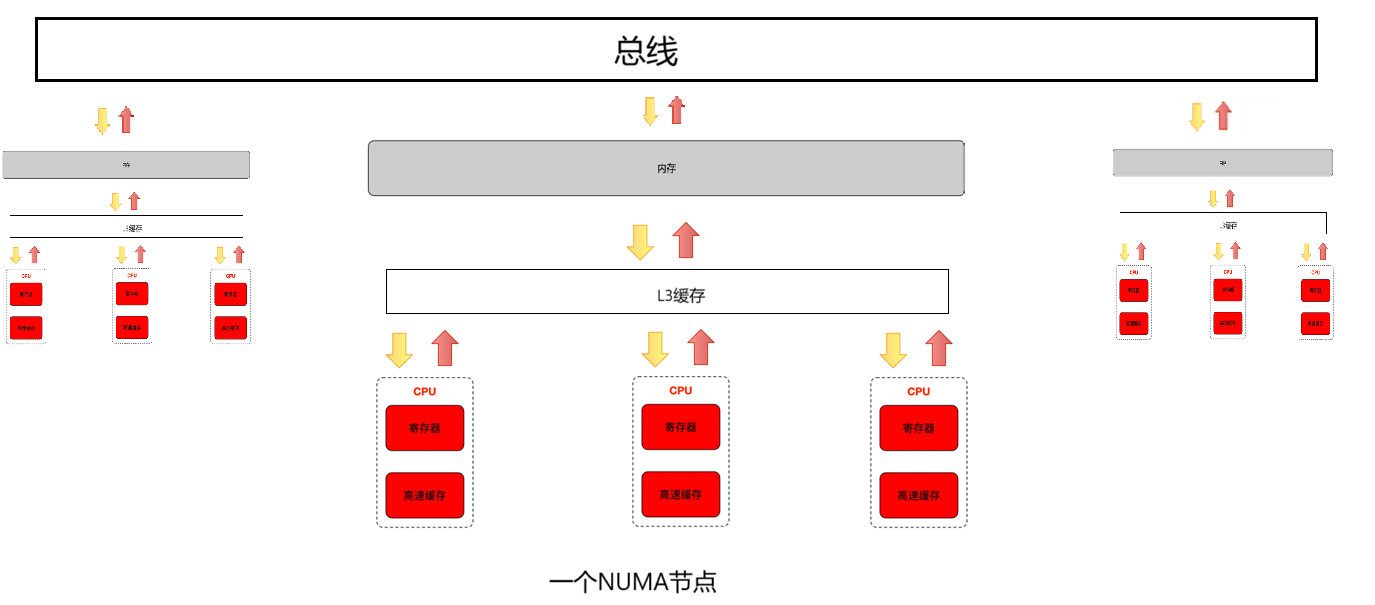
優點:
??
- 高可擴展性:通過將內存分配到不同節點,減少了內存訪問沖突,使得系統在增加 CPU 核心數量時,依然能夠保持較好的性能擴展性。
- 局部性原理利用:可以將數據和任務分配到對應的節點,充分利用本地內存訪問速度快的優勢,提高整體性能。
缺點:
?
- 編程復雜度增加:開發者需要考慮內存的本地性問題,在編程時需要手動管理內存分配,以確保數據在合適的節點上,否則可能導致性能下降。
- 管理復雜:操作系統需要更復雜的資源管理和調度策略,來平衡各個節點的負載和優化內存訪問。
三、RCU機制在內核中的體現
? ? ? ? RCU本質只是一種提高讀寫效率的鎖。但是在Linux中廣泛的用到。比如在task_struct中,我們曾說到有進程的ID、調度策略、用戶地址空間指針等等各種成員。內核中存在著大量的鏈表結構,無論是調度器就緒隊列,還是全局進程鏈表、子進程鏈表。這些鏈表操作往往涉及到大量的讀,而對寫性能要求不高。此時RCU機制就能發揮到極致。
? ? ? ? 下面我們來看看內核中的RCU機制引申出的鏈表rcu操作。
// 安全的節點插入(使用內存屏障)
void safe_add_node(struct my_node *new) {// 1. 完成所有數據初始化new->data = 100;// 2. 使用寫內存屏障(確保之前的寫操作對其他CPU可見)smp_wmb();// 3. 原子更新鏈表指針(使新節點對讀操作可見)list_add_tail_rcu(&new->list, &my_list);
}// 安全的節點刪除(使用內存屏障)
void safe_delete_node(struct my_node *node) {// 1. 原子更新鏈表指針(從鏈表移除節點)list_del_rcu(&node->list);// 2. 使用讀內存屏障(確保后續同步操作的順序)smp_rmb();// 3. 等待寬限期結束(確保沒有讀操作引用舊節點)synchronize_rcu();// 4. 安全釋放內存kfree(node);
}// 安全的鏈表遍歷(無鎖讀)
void safe_traverse(void) {struct my_node *node;rcu_read_lock(); // 標記讀臨界區開始// 使用 RCU 安全遍歷宏(確保指針解引用安全)list_for_each_entry_rcu(node, &my_list, list) {// 讀操作期間,數據可能被修改,但保證可見性順序printk("Data: %d\n", node->data);}rcu_read_unlock(); // 標記讀臨界區結束
}????????可以看到這個rcu插入鏈表節點的函數,不僅僅是更新了鏈表的節點,還調用了內存屏障函數,保證了編譯器和CPU的優化不會亂序,讓別的進程要么看到數據最新的新節點,要么看不到該節點,不存在已經插入到鏈表中而數據后更新的問題。
四、內存優化屏障
(1)編譯器、CPU優化
? ? ? ? 我們寫好了一個程序交給編譯器編譯、或者交給CPU運行的時候,可能與我們想象中一條條地執行不同,無論是編譯器還是CPU都會采取一定的優化策略,讓性能進一步提高。
? ? ? ? 比如編譯器優化:把顯而易見的代碼直接求出結果,編譯成二進制。這樣能減少CPU運行的時間。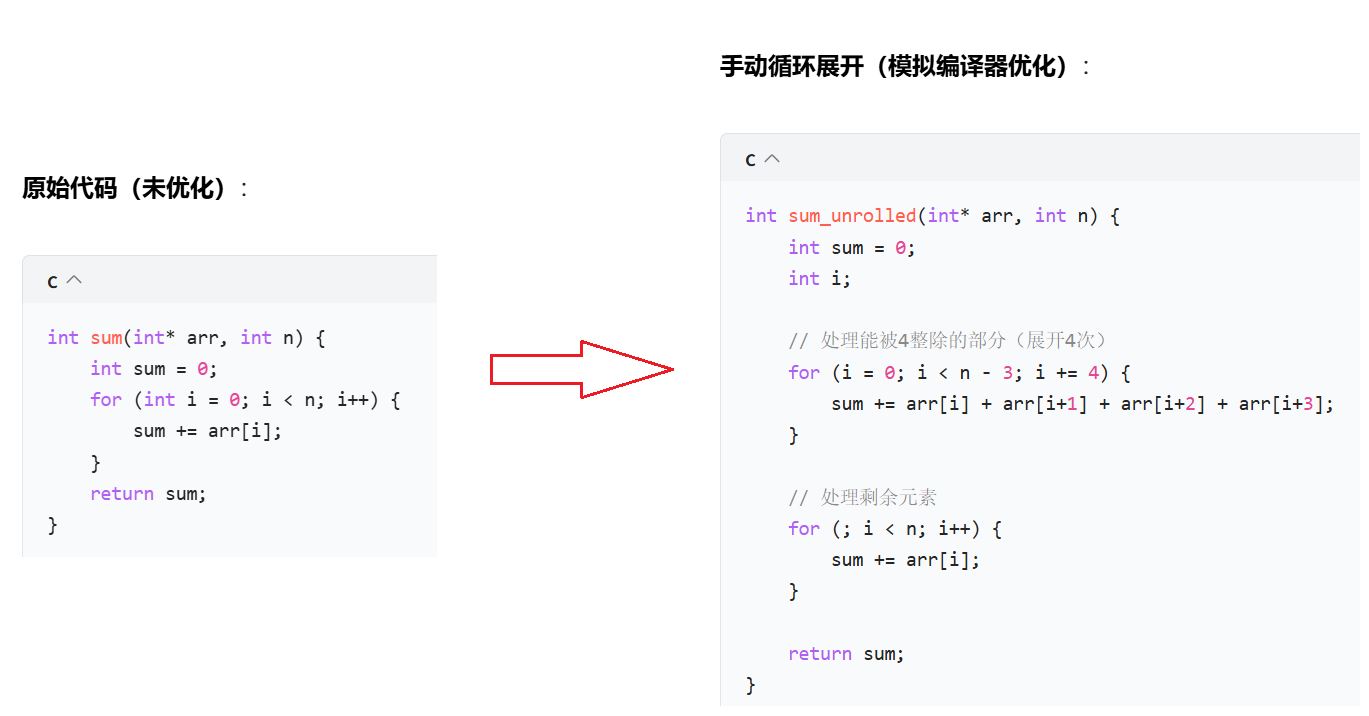
優化原理:
? ? ? ? 把顯而易見的步驟直接在編譯環節得到結果,減少CPU運行次數。
?
- 減少循環次數(原循環執行 n 次,展開后執行 n/4 次),降低分支預測失敗和循環開銷(如計數器更新、條件判斷)。
- 增加指令級并行(ILP):多條加法指令可同時在 CPU 流水線中執行。
????????再比如CPU運行優化:
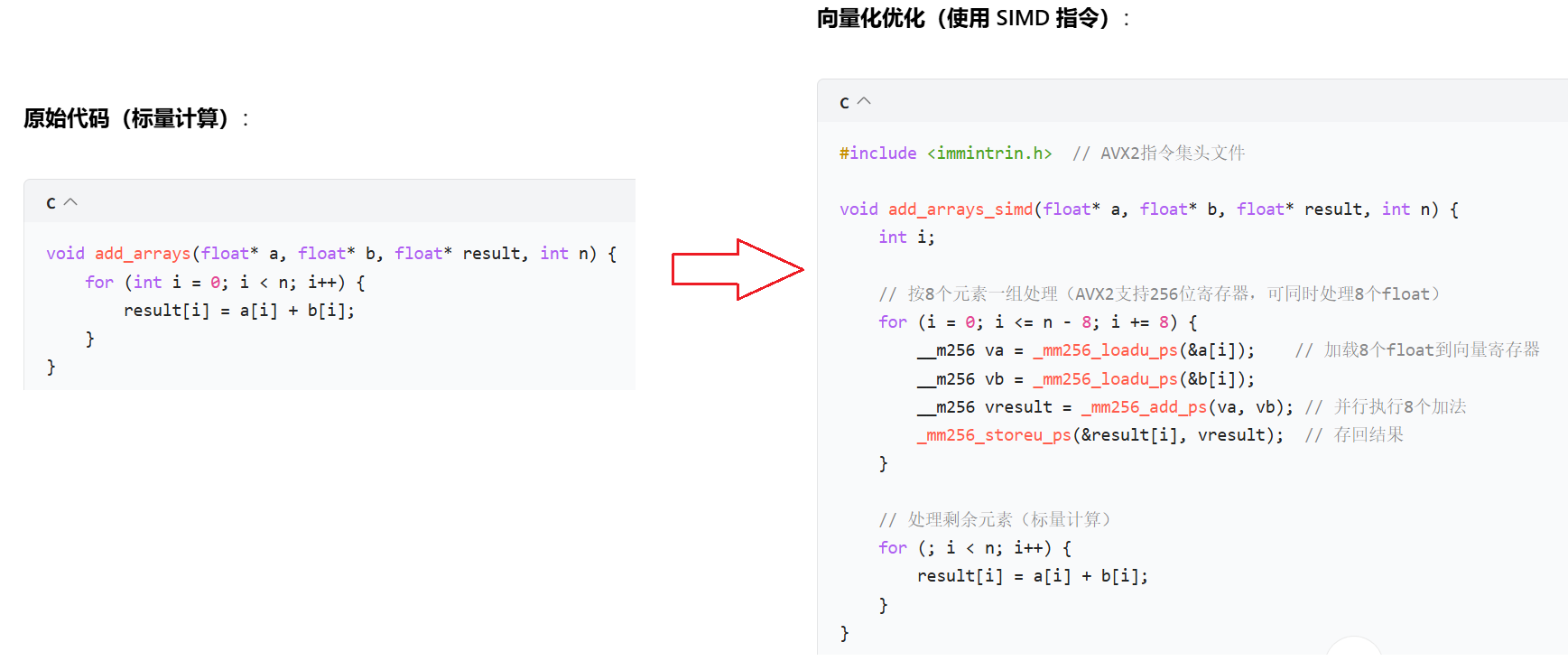
優化原理:
? ? ? ? CPU從內存讀取一個數據需要時間,這個時間如果傻等就白白浪費了,所以選擇同時讀取一堆,重疊掉這個等待時間。
?
- SIMD(單指令多數據):利用 CPU 的向量寄存器(如 AVX2 的 256 位寄存器)同時處理多個數據。
- 數據并行:一條指令完成 8 個浮點數加法,吞吐量提升 8 倍(理論值)。
(2)優化的問題和解決辦法
? ? ? ? CPU和編譯器的亂序優化,本質上是為了提高運行效率。但是也導致了一個結果:可能導致不同線程錯誤的讀到類似空指針的錯誤。
舉個例子:
// 期望的鏈表插入函數
void incorrect_add_node(struct my_node *new) {// 初始化新節點new->data = 42;// 設置數據字段(可能被重排序到指針更新之后)new->data = 100; // 危險:可能在節點可見后才被更新// 將新節點連接到鏈表中list_add_tail_rcu(&new->list, &my_list);}
被優化后的:
// 錯誤的鏈表插入函數(無內存屏障)
void incorrect_add_node(struct my_node *new) {// 初始化新節點new->data = 42;// 先將新節點連接到鏈表中list_add_tail_rcu(&new->list, &my_list);// 然后設置數據字段(可能被重排序到指針更新之后)new->data = 100; // 危險:可能在節點可見后才被更新
}即使關閉了所有的優化,還是有可能出現問題:
正確的做法是在中間部分添加內存屏障:這里保證了先初始化數據,再更新鏈表指針。讓其他線程要么看不到更新的鏈表節點,要么看到就是數據已經更新的完全體。
// 正確的鏈表插入函數(使用內存屏障)
void correct_add_node(struct my_node *new)
{// 1. 先完成所有數據初始化new->data = 100;// 2. 使用寫內存屏障確保數據初始化對其他CPU可見smp_wmb(); // 寫內存屏障,確保之前的寫操作都完成// 3. 最后更新鏈表指針,使新節點對讀操作可見list_add_tail_rcu(&new->list, &my_list);
}????????最后,Linux中的內存屏障有許多種,其中通用屏障開銷最大,我們最好根據請款選擇合適的內存屏障。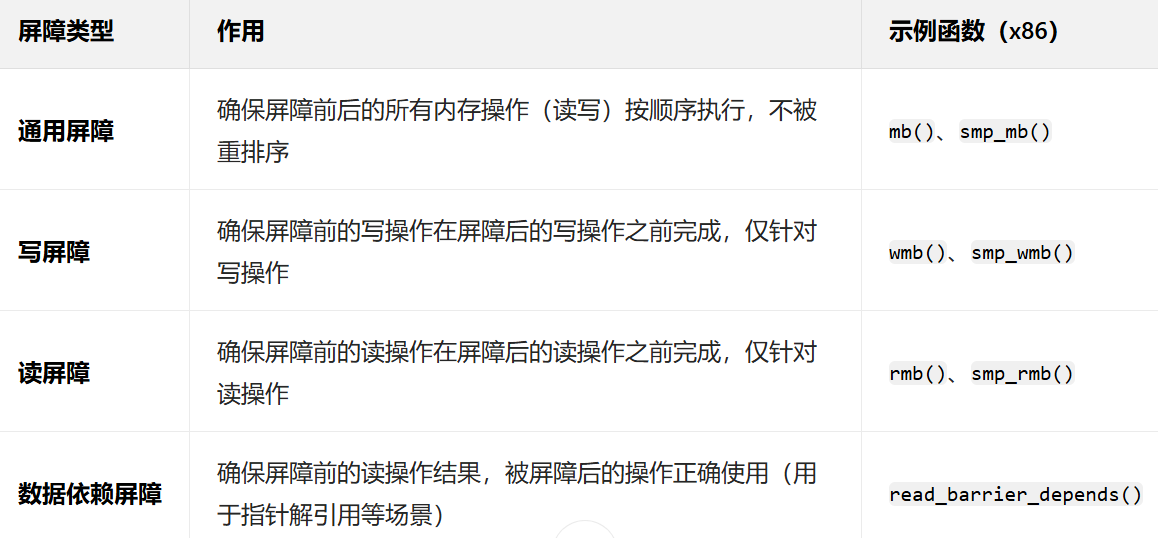
(3)volatile關鍵字
? ? ? ? 正如我們上面所說的優化有亂序的問題,CPU在讀取某個變量的值的時候也會存在優化。當寄存器中恰好存儲的就是該變量的值的時候(頻繁訪問某一個變量很有可能出現這種情況),cpu往往會直接從該寄存器中讀取。
? ? ? ? 而寄存器更新的原則是覆蓋式更新,即讀新的數據,寄存器中原本沒有,于是從L1、L2等緩存中覆蓋寫入到寄存器。如果該變量剛好就在寄存器,則可能讀到舊值(緩存中的值已經發生了改變)。
? ? ? ? volatile關鍵字的作用就是,禁止編譯器把變量緩存到寄存器中,強制要求cpu每次必須在內存/緩存中讀取該變量的值,從而保證了值的實時性。
????????不過他僅僅是解決?“編譯器和硬件緩存導致的舊值讀取”?的輕量級工具,但僅適用于簡單場景。復雜的多線程 / 硬件同步,必須用更強大的原語(原子操作、內存屏障、鎖)。
)
)
)



)


![[BrowserOS] Nxtscape瀏覽器核心 | 瀏覽器狀態管理 | 瀏覽器交互層](http://pic.xiahunao.cn/[BrowserOS] Nxtscape瀏覽器核心 | 瀏覽器狀態管理 | 瀏覽器交互層)


)





—— 多元素控件)
