
-
作者:Diankun Wu, Fangfu Liu, Yi?Hsin Hung, Yueqi Duan
-
單位:清華大學
-
論文標題:Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence
-
論文鏈接:https://arxiv.org/pdf/2505.23747
-
項目主頁:https://diankun-wu.github.io/Spatial-MLLM/
-
代碼鏈接:https://github.com/diankun-wu/Spatial-MLLM
主要貢獻
-
提出了Spatial-MLLM,一種能夠顯著提升現有視頻多模態大語言模型(MLLM)在基于視覺的空間智能方面的能力的方法,無需任何3D或2.5D數據輸入,即可實現強大的空間理解和推理能力。
-
設計了雙編碼器架構和連接器,有效整合了標準2D視覺編碼器提取的語義信息和空間編碼器提取的結構信息,空間編碼器是基于前饋視覺幾何基礎模型初始化的。
-
充分利用前饋視覺幾何模型提供的額外信息,設計了一種空間感知的幀采樣策略,在輸入長度受限的情況下,能夠選擇具有空間信息的幀,從而提升模型性能。
-
構建了Spatial-MLLM-120k數據集,并采用兩階段訓練流程對其進行訓練。大量實驗表明,該方法在一系列基于視覺的空間理解和推理任務中均取得了最先進的性能。
研究背景
-
多模態大語言模型(MLLM)在處理多模態輸入以生成上下文相關且語義連貫的響應方面取得了顯著進展,尤其在2D視覺任務上表現出色。然而,它們在空間智能方面,即對3D場景的感知、理解和推理能力仍然有限。
-
現有的3D MLLM通常依賴額外的3D或2.5D數據(如點云、相機參數或深度圖)來增強空間感知能力,這限制了它們在只有2D輸入(如圖像或視頻)的場景中的應用。
-
視頻MLLM的視覺編碼器主要在圖像-文本數據上進行預訓練,遵循CLIP范式,擅長捕捉高級語義內容,但在只有2D視頻輸入時缺乏結構和空間信息,導致其在空間推理任務上的表現不如在其他任務上,且與人類能力仍有較大差距。
研究方法
Spatial-MLLM架構
Spatial-MLLM的架構基于Qwen2.5-VL-3B模型,通過引入雙編碼器架構和連接器來增強其空間理解能力。
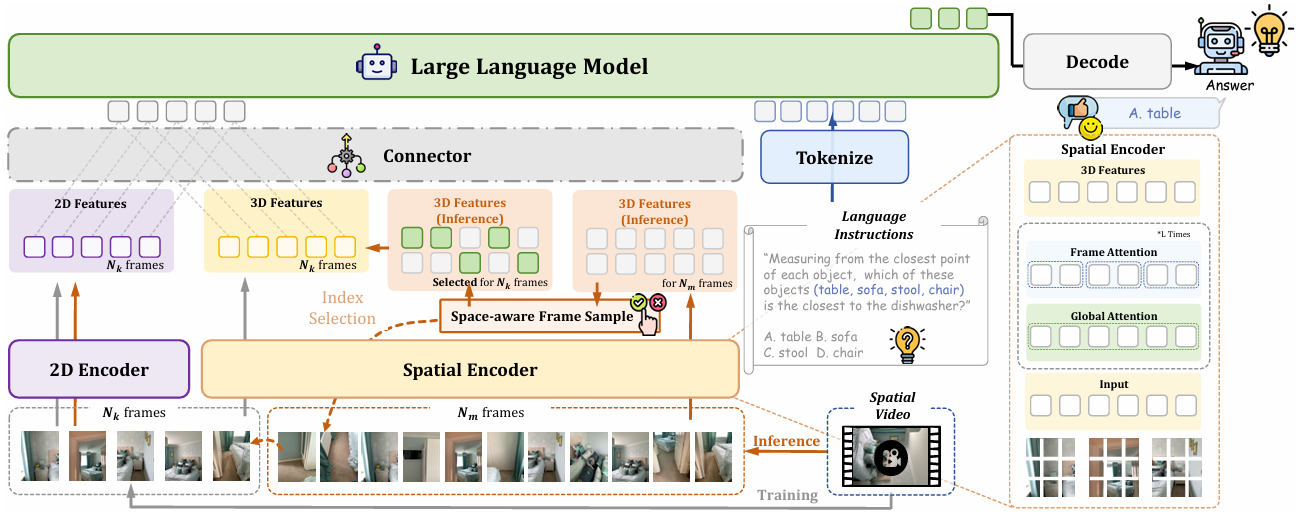
雙編碼器架構
-
2D編碼器(E2D):采用Qwen2.5-VL的視覺編碼器,負責從輸入視頻幀中提取語義豐富的特征。它將輸入幀編碼為2D特征,這些特征在空間和時間維度上對齊,以便與3D特征進行融合。
-
空間編碼器(ESpatial):基于VGGT模型的特征提取器,從2D視頻輸入中恢復隱含的3D結構信息。它通過交替的幀內自注意力和全局自注意力,聚合不同幀之間的空間信息,生成密集的3D特征。
-
連接器(Connector):將2D特征和3D特征融合為統一的視覺標記。通過兩個輕量級的多層感知機(MLP),將2D和3D特征相加,生成最終的視覺標記,供大型語言模型(LLM)使用。
空間感知幀采樣策略
由于GPU內存限制,視頻MLLM通常只能處理有限的幀數。因此,論文提出了一種空間感知的幀采樣策略,以選擇最具空間信息的幀。
-
預處理:從原始視頻中均勻采樣一定數量的候選幀(例如128幀)。
-
特征提取:利用空間編碼器提取這些幀的3D特征和相機特征。
-
體素化和覆蓋計算:將場景的3D點云離散化為體素,并計算每個幀覆蓋的體素。
-
最大覆蓋問題:將幀選擇問題轉化為最大覆蓋問題,即選擇覆蓋最多獨特體素的幀。通過貪婪算法加速求解,最終選擇出最具空間信息的幀(例如16幀)。
訓練
為了訓練Spatial-MLLM,論文構建了一個新的數據集Spatial-MLLM-120k,并采用兩階段訓練流程。
數據集構建
-
數據集包含約12萬對問答,涵蓋多種空間理解和推理任務。
-
數據來源包括ScanQA、SQA3D以及自創建的問答數據。
-
問答對的生成基于ScanNet的場景和語義注釋,覆蓋了目標計數、目標尺寸、房間尺寸、絕對距離、出現順序、相對距離和相對方向等任務。
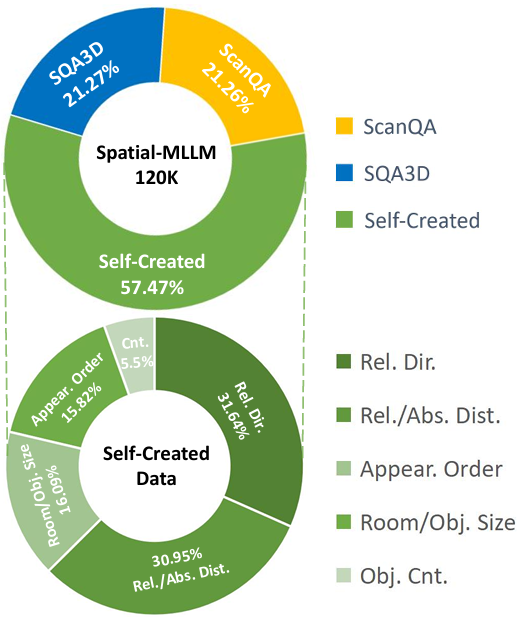
訓練流程
-
監督微調(SFT):在Spatial-MLLM-120k數據集上進行監督微調,凍結2D和空間編碼器,訓練連接模塊和LLM骨干網絡。采用標準的交叉熵損失函數,優化模型對空間任務的理解和推理能力。
-
冷啟動(Cold Start):在強化學習訓練之前,通過生成少量的推理路徑和答案,篩選出正確的推理路徑,幫助模型適應正確的推理格式。
-
強化學習(RL)訓練:采用組相對策略優化(GRPO)訓練,增強模型的長鏈推理能力。通過設計任務相關的獎勵函數,確保模型的預測結果與真實答案盡可能接近。
實驗
實現細節
-
Spatial-MLLM基于Qwen2.5-VL和VGGT構建,總參數量約為4B。
-
訓練時,視頻幀的分辨率為640×480,輸入幀數限制為16幀。
-
在SFT階段,使用Adam優化器訓練一個epoch,學習率峰值為1e-5。
-
在RL階段,進行8次rollout,學習率為1e-6,訓練1000步。
VSI-Bench基準測試對比
-
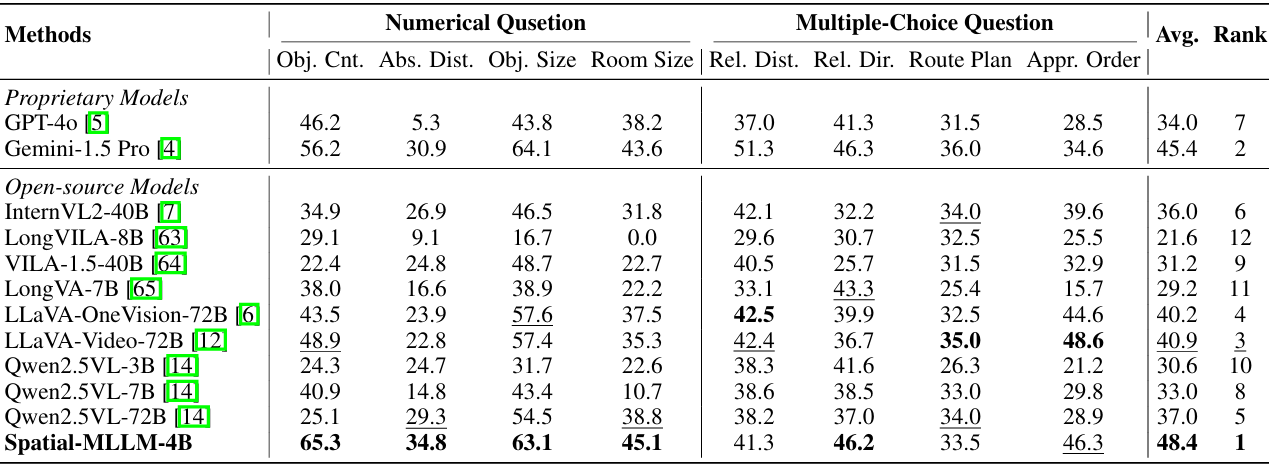
基準測試介紹:VSI-Bench包含超過5000對問答,涵蓋多種任務類型,包括多項選擇題和數值題。
-
對比結果:Spatial-MLLM在VSI-Bench上的表現顯著優于其他專有和開源MLLM,包括參數量更大的模型。例如,與Gemini-1.5 Pro相比,Spatial-MLLM在平均準確率上高出3.0%,盡管其輸入幀數較少。
ScanQA和SQA3D基準測試對比
-
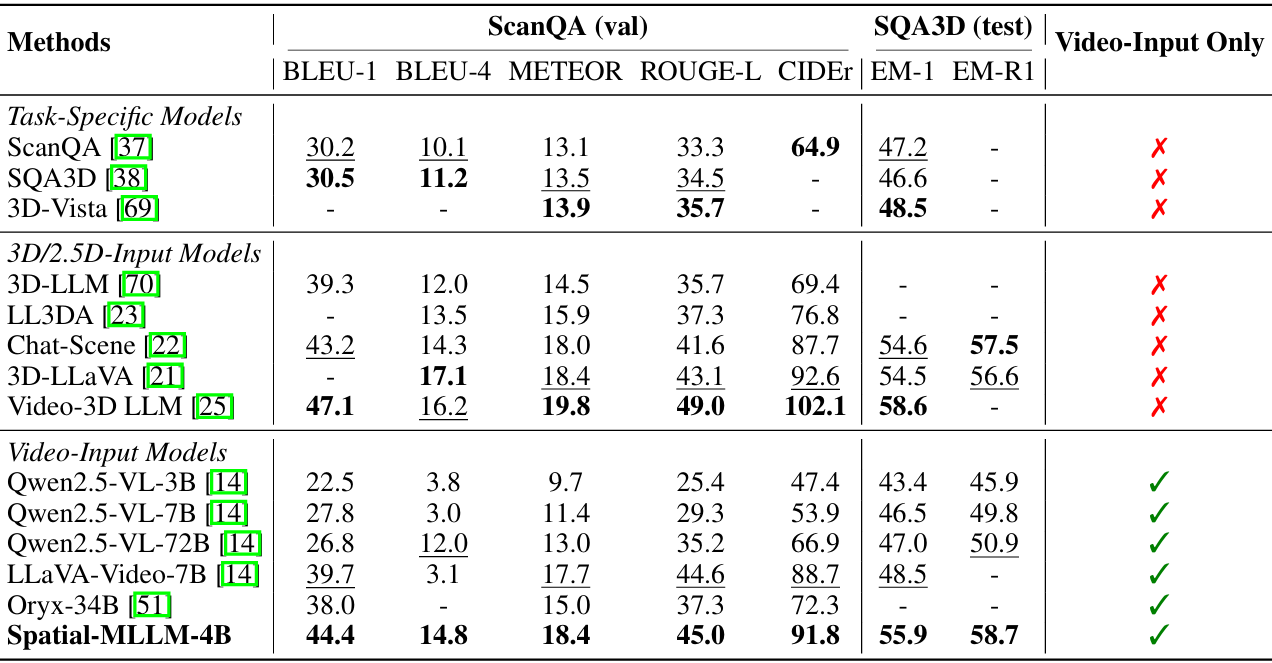
基準測試介紹:ScanQA和SQA3D是基于ScanNet構建的3D問答基準測試,包含大量的問答對,涉及空間關系理解和3D場景中的目標識別。
-
對比結果:Spatial-MLLM在ScanQA和SQA3D上均取得了優異的成績,顯著優于所有僅使用視頻輸入的模型,甚至超過了部分依賴額外3D或2.5D輸入的模型。
消融研究與分析
-
強化學習訓練的有效性:通過對比監督微調版本和最終版本的Spatial-MLLM,驗證了強化學習訓練對提升模型性能的作用。
-
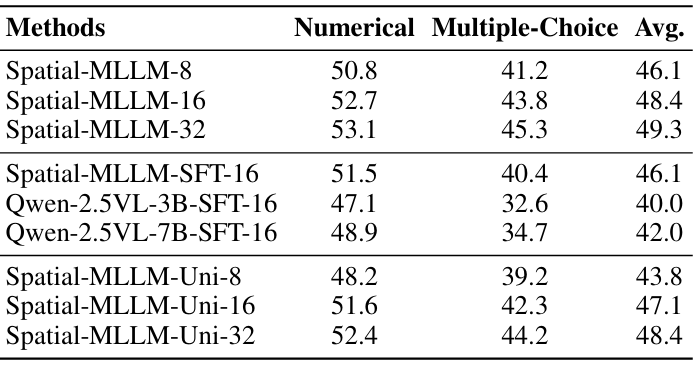
空間感知幀采樣策略的有效性:通過對比不同幀采樣策略下的性能,證明了空間感知幀采樣策略在有限輸入幀數下優于均勻采樣。
-
架構的有效性:通過在相同數據集上訓練Qwen2.5-VL模型,驗證了Spatial-MLLM架構在提升空間推理能力方面的優勢。
結論與未來工作
- 結論:
-
Spatial-MLLM通過結合語義2D編碼器和結構感知的空間編碼器,能夠從純2D視覺輸入中有效實現空間理解和推理。
-
其雙編碼器設計能夠捕捉語義和空間線索,空間感知幀采樣策略在輸入受限的情況下進一步提升了性能。
-
在多個基準測試中,Spatial-MLLM均取得了最先進的結果。
-
- 未來工作:
-
盡管Spatial-MLLM在視覺空間智能方面取得了顯著進展,但仍存在擴展模型規模和訓練數據的潛力。
-
此外,未來工作可以探索將空間結構信息整合到更廣泛的視頻理解和推理任務中,以進一步提升模型的性能和泛化能力。
-





)
驅動學習筆記)






)






