從自然語言監督中學習可遷移的視覺模型
雖然有點data/gpu is all you need的味道,但是整體實驗和談論豐富度上還是很多的,非常長的原文和超級多的實驗討論,隔著屏幕感受到了實驗的工作量之大。
Abstract
最先進的計算機視覺系統被訓練來預測一組固定的預定對象類別。 這種受限制的監督形式限制了它們的通用性和可用性,因為需要額外的標記數據來指定任何其他視覺概念。 直接從原始文本中學習圖像是一種很有前途的選擇,它利用了更廣泛的監督來源。 我們證明了預測哪個標題與哪個圖像相匹配的簡單預訓練任務是一種有效且可擴展的方法,可以在從互聯網收集的4億對(圖像,文本)數據集上從頭開始學習SOTA圖像表示。 在預訓練之后,使用自然語言來參考學習到的視覺概念(或描述新的概念),從而實現模型向下游任務的零樣本轉移。我們通過對30多個不同的現有計算機視覺數據集進行基準測試來研究這種方法的性能,這些數據集涵蓋了OCR、視頻中的動作識別、地理定位和許多類型的細粒度對象分類等任務。 該模型不平凡地轉移到大多數任務,并且通常與完全監督的基線競爭,而不需要任何數據集特定的訓練。 例如,我們在ImageNet zero-shot上匹配原始ResNet-50的精度,而不需要使用它所訓練的128萬個訓練樣本中的任何一個。
Introduction and Motivating Work
在過去幾年中,直接從原始文本中學習的預訓練方法徹底改變了NLP
與任務無關的目標,如自回歸和masked語言建模,已經在計算、模型容量和數據方面擴展了許多數量級,穩步提高了能力。“文本到文本”作為標準化輸入輸出接口的發展使任務無關架構能夠零射傳輸到下游數據集,從而消除了對專門輸出頭或數據集特定定制的需要。 像GPT-3在使用定制模型的許多任務中具有競爭力,而幾乎不需要特定數據集的訓練數據。
這些結果表明,在網絡規模的文本集合中,現代預訓練方法可獲得的總體監督優于高質量的人群標記NLP數據集。然而,在計算機視覺等其他領域,在人群標記數據集(如ImageNet)上預訓練模型仍然是標準做法(Deng et al., 2009)。 直接從網絡文本中學習的可擴展預訓練方法能否在計算機視覺領域取得類似的突破? 先前的工作令人鼓舞。
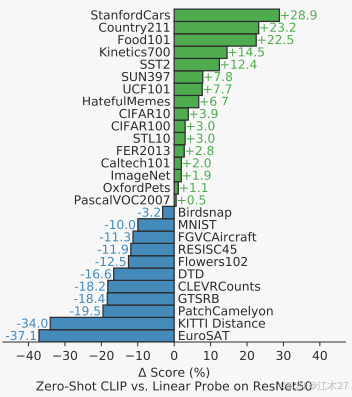
總之可以整理為,之前的很多工作其實并不是方法不行而是數據不夠多,所以效果不好,并且泛化性能非常有限,而作者提出的方法稱為CLIP(Contrastive LanguageImage Pre-training)在各個數據集上都表現出了很高的指標,有更強的魯棒性。例如在ImageNet上,CLIP同監督訓練的ResNet50達到了同等的水平。
通過4億數據在大量數據集表現出了優秀的效果,但是后文中對比中在MNIST效果卻很差,作者后文給出的原因是發現數據集很少有和MNIST相似的數據。所以后續文章作者也總結了很多CLIP的局限性,但是他依舊在很多數據集表現的很好這也是不能忽視的。
Approach
2.1 自然語言監督
以自然語言為(標簽)指導模型學習具有很多優勢。
首先,不需要人工標注,可以快速規模化。可以充分利用互聯網上的信息。
其次,強大的zero-shot遷移學習能力。傳統的機器學習對輸入標簽格式有特殊要求,在推理階段需要遵循相同的格式。數據集的格式限制了模型的使用范圍。傳統的機器學習模型不能在數據集定義的格式之外的任務上使用。使用自然語言作為監督信號,能夠處理任何以自然語言作為輸入的任務。而自然語言是最直觀、通用的輸入格式。所以模型可以方便地遷移到其它場景。
第三,讓CV模型學習到視覺概念的自然語言描述。將“蘋果”圖片和“蘋果”單詞建立聯系,也就真正學習到了圖片的語義信息。
第四,多模態。以自然語言作為橋梁,用一個大模型學習文本、圖片甚至視頻的理解。
2.2 創建足夠大的數據集
現有數據集主要有3個,MS-COCO、Visual Genome、YFCC100M。前兩者是人工標注的,質量高但是數據量小,大約只有0.1M。YFCC100M大約有100M圖片,但是質量堪憂,有些標題只有無意義的名字,過濾后,這個數據集縮小至15M,大約和ImageNet差不多大。(顯然這個數據量是不夠的)
OpenAI自己構建了一個400M的數據集,使用500K個查詢進行搜索,每個查詢大約有20K個“圖像—文本“對。該數據集被稱為WIT(webimagetext),數據量和GPT-2使用的差不多。
2.3 有效的預訓練方法
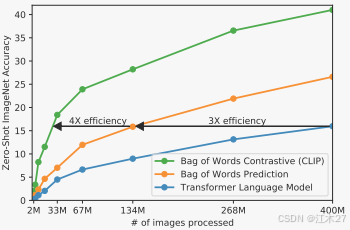
OpenAI的第一個嘗試類似于VirTex,將基于CNN的圖片編碼器和文本transformer從頭訓練,去預測圖片的標題。然而這個方法很快遇到了困難。從下圖中可以看出,一個63M的語言模型,使用了基于ResNet50的圖片編碼器的兩倍計算量,但是效率卻是預測詞袋的1/3(3x efficiency)。
很快,OpenAI嘗試了第二種方案——對比學習。將文本和圖片的embedding進行相似度比較,從圖片2可以看出訓練速度是預測詞袋的4倍。
對方法的描述:給定一個大小為N的batch,CLIP需要預測這NxN個對是否屬于同一語義。CLIP利用圖片和文本編碼器將圖片和文本的embedding進行基于cosine距離的打分,使N個成對的分數變大,使N^2-N個非成對的分數減小。模型訓練是基于對稱的交叉熵說損失。下圖展示了訓練的偽代碼:

代碼過程描述:
第1-2行:利用圖片編碼器和文本編碼器提取圖片和文本的高維表征。
第3-4行:利用可學習線性變換(無偏置)將圖片和文本表達映射到同一語義空間
第5行:內積進行相似度比較,同時乘上溫度系數 exp(\tau) 。
第6-9行:分別沿圖像(每一條文本同不同圖片的相似度)和文本軸(每一條圖片同文本的相似度)計算交叉熵,相加處以2得到對稱損失。
第一個是我們從頭開始訓練CLIP,而不使用ImageNet權重初始化圖像編碼器或使用預訓練權重初始化文本編碼器。
第二個我們只使用線性投影將每個編碼器的表示映射到多模態嵌入空間。 我們沒有注意到兩個版本之間的訓練效率差異,并推測非線性投影可能僅在自監督表示學習方法中與當前圖像的細節共同適應。本文沒有使用非線性變換;
第三個是直接利用原始文本即單個句子;
第四個是圖片的預處理只有大小變換后隨機方形剪切;
最后,控制softmax中對數范圍的溫度參數τ在訓練過程中被直接優化為對數參數化的乘法標量,以避免變成超參數。
2.4 選擇和縮放模型
視覺:resnet或者transformer
文本:transformer
2.5 訓練
訓練了8個模型,不同的深度、寬度、patch等,32epoch、adam、batchsiz=32768、混合精度訓練
訓練完后對模型用更大的size進行了一個fintune了1epoch稱其為CLIP模型
本文構造了一個更簡單的學習任務。利用對比學習的思想,只預測哪段文本作為一個整體是和圖片成對出現的,不需要預測文本的確切內容。用對比學習的目標( contrastive objective)代替了預測學習的目標(predictive objective)。這個約束放寬了很多,學習需要的算力減少很多。
作者發現,僅僅把訓練目標任務從預測型換成對比性,訓練的效率就能提升4倍。如圖所示。
2.6 使用CLIP
在下游任務測試時,有兩種使用CLIP的方法。第一種,利用文本prompt進行預測,將預測的embedding同類別的embedding進行相似度匹配,實現分類任務;第二種,額外訓練linear probe進行預測。
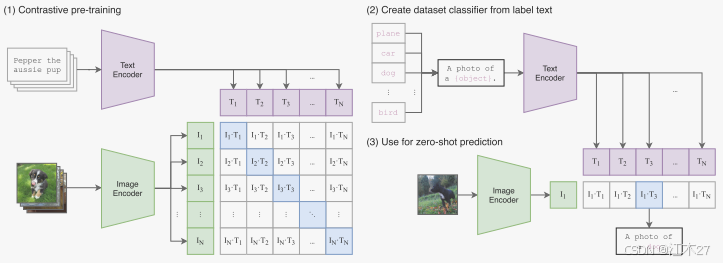
這張圖片展示了基于對比學習訓練(1)和使用零樣本預測(2&3)。對比學習是利用文本—圖像對數據,判別當前圖片是否于文本匹配,從而學習圖像的高維表征;零樣本預測時,利用prompt構建不同類別的embedding,然后同圖片匹配從而進行分類。
生成句子例如這是一張xx照片,然后通過text encoder 編碼得到文本特征,然后用文本特征和圖像特征進行cosine 相似度 進入softmax得到概率分布
總之,我認為的一個重要貢獻是它打通了文本和圖片理解的界限,催生了后面多模態的無限可能。后續的“以圖生文”,“以文搜圖”都有賴這一點。
Experiments
3.1 zero-short 遷移
作者動機:解決之前工作遷移其他任務困難的問題。
3.1.3對比其他方法
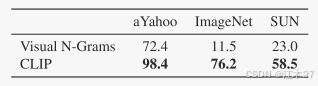
CLIP在零樣本遷移效果和有監督的res50相當。CLIP同Visual N-Grams進行了橫向對比。如Table1中所示,幾乎在所有數據集上CLIP都遠超過Visual N-Grams(體現CLIP的zero-shot能力)
3.1.4提示工程與集成
a photo of a {label}這種方法可以提升在imagenet上1.3%的準確率,prompt對于分類的性能很重要。因此OpenAI自己嘗試了很多prompt去提升分類的準確率。比如在Oxford-IIIT Pet數據集中,使用prompt “A photo of a {label}, a type of pet.”就好于單單使用“A photo of a {label},”。還講了一些在Food101、FGVC、OCR、satellite數據集上的經驗。
3.2特征學習
特征學習是指在下游任務數據集上用全部的數據重新訓練。有兩種方式衡量預訓練階段學習到的特征好不好:
linear prob將預訓練好的模型“凍住”,不改變其參數,在之上訓練一個分類頭。
finetune整個網絡參數都可以調整,端到端地學習。微調一般更靈活,效果更好。
本文采用linear prob的方式。不需要大量調參,評測流程可以標準化。
總結
這里還有很多數據分布問題、模型不足、實驗討論、和人類對比等等,實驗非常豐富,就不一一展開, 總的來說,花這么多人、gpu、數據實現的CLIP想必在gpt 4中也有很多該實驗的影子和貢獻,openai的這篇文章也給后續很多文章和領域提供了思路,值得一讀吧。
參考:
史上最全OpenAI CLIP解讀:簡單的想法與被低估的實驗
李沐-clip










)






)
)
