目錄
引言?
一.?基本知識
二.參數估計
三.數據平滑
一.加1法
二.減值法/折扣法
?編輯?1.Good-Turing 估計
?編輯?2.Back-off (后備/后退)方法?
3.絕對減值法?
?編輯4.線性減值法
5.比較?
三.刪除插值法(Deleted interpolation)?
?四.模型自適應
引言?

本章節講的知識主要是來解決以上這個問題:即如何計算一段話在我們日常生活中出現的概率。在學完本章節后,你可以嘗試解決下面的問題:

一.?基本知識
對于一段話,我們如何計算其在生活中出現的概率呢?首先我們可以把每一句話拆分成一個個詞,這些詞就是我們所說的“統計基元”,一個個統計基元組成了我們的一句話。而對于我們每一個統計基元來說,其前面的基元就是歷史基元。
?如何計算一段話的概率?
假設我們這段話是“我愛你”,我們該怎么計算呢?你可能會想到,“我愛你”這句話的概率,不就應該等于“我”出現的概率*“愛”出現的概率*“你”出現的概率。實際上來說,這樣算的話我們就忽略了詞與詞的關系,比如“愛”會不會影響“你”出現的概率,比如我們大部分人都會把“愛你”連起來說,這樣的話我們就不能把他們倆獨立開來了。這樣的話,就相當于我們計算概率的時候要參考一句話前面的基元。因此我們應該用下面的公式:

可以理解為:句子的概率 = 第 1 個詞的概率 × 第 2 個詞依賴第 1 個詞的概率 × 第 3 個詞依賴前兩個詞的概率 × … × 第 m 個詞依賴前 m - 1 個詞的概率
歷史基元數量爆炸問題
顯然隨著要預測的詞位置越靠后(i?越大 ),需要參考的 “歷史基元數量” 也越多(i?1?個 ),這樣的話很容易出現后面的歷史基元越來越多出現參數爆炸。即:

那我們該如何解決這個問題呢?
我們的解決辦法是等價類劃分:


舉個例子:“我愛你”和“石頭愛地”這兩句話,假設n等于2,則“你”前面的“我愛”和“地”前面的“石頭愛”,因為前n-1個基元,即“愛”?相同,則這倆句話為同一等價類。因此我們很容易看出來,這個n其實就是相當于縮減了我們的視野,我們只看前n-1個基元而看不到更前面的基元了。
因此:

但是,這樣的話,顯然我們的句子的第一個單詞沒有前置的選項讓我們看了,也就是說沒有歷史基元,這對我們是非常不方便的,因為我們無法統一編程,并且我們還丟失了其作為第一個單詞的位置信息。所以我們為這個句子加上了開頭和結尾符號來標識。
即:
這樣的話我們就非常好求解了,例題如下:

(下面三個分別是一元,二元,三元劃分) 那么我們的概率就是:


二.參數估計
好了,既然我們已經整出來了表示,那么我們模型里的這些參數是啥呢?就是說我們這里的P是什么呢?這就引出了我們下面的概念:


?
例題:


?那若是求一個句子里包含從沒出現的詞呢?這是很常見的,比如訓練語料不可能包含所有人的姓名,如果一個人的姓名比較生僻,比如叫“諸葛大力”,這樣的話是否“諸葛大力愛張偉”在日常生活中是不可能發生的呢?顯然不是。但是我們的計算下整個的概率是0。顯然是不合理的。于是我們便引出了數據平滑。
三.數據平滑
?

困惑度你就理解為這個句子的常見程度,如果困惑度很高,說明句子很罕見,讓人看著很“困惑”。
一.加1法

意思就是分子加1,分母加上詞匯庫的總量(不包含開始和結束字符)
例題:

二.減值法/折扣法
 ?1.Good-Turing 估計
?1.Good-Turing 估計


 ?舉例:
?舉例:

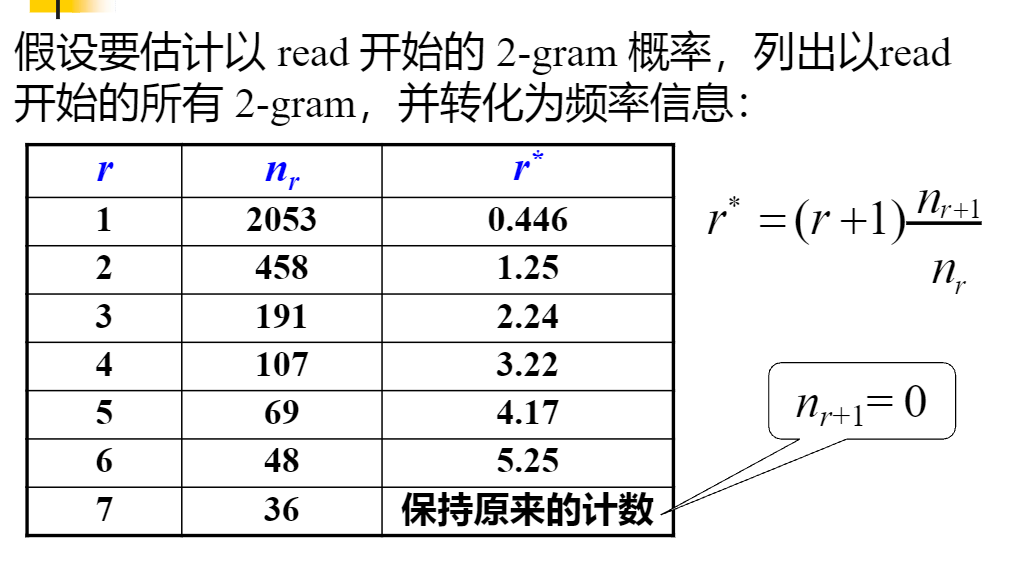 ?給你們算個一個吧。第一個r*,照著公式的話,r+1等于2,因為我們這里的r等于1,然后nr和nr+1直接看表的話就是2053和458,也就是說r*=2*(458/2053)約等于0.446,其他的你們照著我這樣做就行。
?給你們算個一個吧。第一個r*,照著公式的話,r+1等于2,因為我們這里的r等于1,然后nr和nr+1直接看表的話就是2053和458,也就是說r*=2*(458/2053)約等于0.446,其他的你們照著我這樣做就行。


 ?2.Back-off (后備/后退)方法?
?2.Back-off (后備/后退)方法?



3.絕對減值法?
 4.線性減值法
4.線性減值法

5.比較?

三.刪除插值法(Deleted interpolation)?


?四.模型自適應




?
 ?
?





)
)






自動領積分腳本部署——基于python和Selenium(附源碼))
—狀態管理》)




