內容來自@浙大疏錦行python打卡訓練營
@浙大疏錦行
- 回調函數
- lambda函數
- hook函數的模塊鉤子和張量鉤子
- Grad-CAM的示例
作業:理解下今天的代碼即可
在深度學習中,我們經常需要查看或修改模型中間層的輸出或梯度。然而,標準的前向傳播和反向傳播過程通常是一個黑盒,我們很難直接訪問中間層的信息。PyTorch 提供了一種強大的工具——hook 函數,它允許我們在不修改模型結構的情況下,獲取或修改中間層的信息。它的核心價值在于讓開發者能夠動態監聽、捕獲甚至修改模型內部任意層的輸入 / 輸出或梯度,而無需修改模型的原始代碼結構。
常用場景如下:
1. 調試與可視化中間層輸出
2. 特征提取:如在圖像分類模型中提取高層語義特征用于下游任務
3. 梯度分析與修改: 在訓練過程中,對某些層進行梯度裁剪或縮放,以改變模型訓練的動態
4. 模型壓縮:在推理階段對特定層的輸出應用掩碼(如剪枝后的模型權重掩碼),實現輕量化推理。
我們之前介紹過機器學習可解釋性工具,例如 SHAP、PDPBox 等,這些工具在處理結構化數據時,能夠有效揭示模型內部的決策邏輯。而在深度學習領域,同樣存在一系列方法來解析模型的決策過程:以圖像分類任務為例,我們不僅可以通過可視化特征圖,直觀觀察不同層對圖像特征的提取程度;還能進一步借助 Grad-CAM 等技術生成特征熱力圖,清晰展現模型在預測過程中對圖像不同區域的關注重點,從而深入理解其決策機制。

一、 前置知識
1.1 回調函數
Hook本質是回調函數,所以我們先介紹一下回調函數
回調函數是作為參數傳遞給其他函數的函數,其目的是在某個特定事件發生時被調用執行。這種機制允許代碼在運行時動態指定需要執行的邏輯,實現了代碼的靈活性和可擴展性。
回調函數的核心價值在于:
1. 解耦邏輯:將通用邏輯與特定處理邏輯分離,使代碼更模塊化。
2. 事件驅動編程:在異步操作、事件監聽(如點擊按鈕、網絡請求完成)等場景中廣泛應用。
3. 延遲執行:允許在未來某個時間點執行特定代碼,而不必立即執行。
其中回調函數作為參數傳入,所以在定義的時候一般用callback來命名,在 PyTorch 的 Hook API 中,回調參數通常命名為 hook
# 定義一個回調函數
def handle_result(result):"""處理計算結果的回調函數"""print(f"計算結果是: {result}")# 定義一個接受回調函數的函數
def calculate(a, b, callback): # callback是一個約定俗成的參數名"""這個函數接受兩個數值和一個回調函數,用于處理計算結果。執行計算并調用回調函數"""result = a + bcallback(result) # 在計算完成后調用回調函數# 使用回調函數
calculate(3, 5, handle_result) # 輸出: 計算結果是: 8是不是看上去很類似于裝飾器的寫法,我們回顧下裝飾器
def handle_result(result):"""處理計算結果的回調函數"""print(f"計算結果是: {result}")def with_callback(callback):"""裝飾器工廠:創建一個將計算結果傳遞給回調函數的裝飾器"""def decorator(func):"""實際的裝飾器,用于包裝目標函數"""def wrapper(a, b):"""被裝飾后的函數,執行計算并調用回調"""result = func(a, b) # 執行原始計算callback(result) # 調用回調函數處理結果return result # 返回計算結果(可選)return wrapperreturn decorator# 使用裝飾器包裝原始計算函數
@with_callback(handle_result)
def calculate(a, b):"""執行加法計算"""return a + b# 直接調用被裝飾后的函數
calculate(3, 5) # 輸出: 計算結果是: 8回調函數核心是將處理邏輯(回調)作為參數傳遞給計算函數,控制流:計算函數 → 回調函數,適合一次性或動態的處理需求(控制流指的是程序執行時各代碼塊的執行順序)
裝飾器實現核心是修改原始函數的行為,在其基礎上添加額外功能,控制流:被裝飾函數 → 原始計算 → 回調函數,適合統一的、可復用的處理邏輯
兩種實現方式都達到了相同的效果,但裝飾器提供了更優雅的語法和更好的代碼復用性。在需要對多個計算函數應用相同回調邏輯時,裝飾器方案會更加高效。
關鍵區別:回調 vs 裝飾器
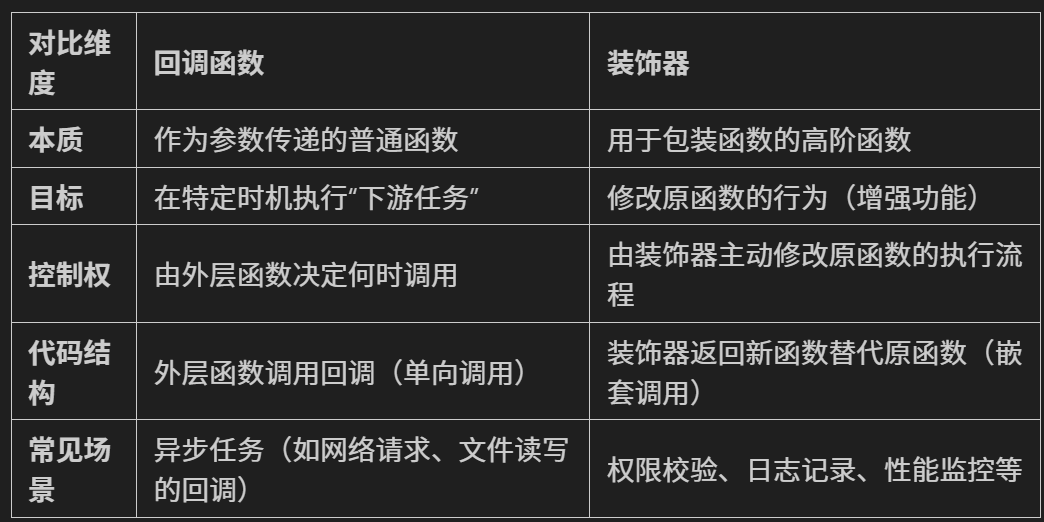 總結:從回調到裝飾器的思維升級
總結:從回調到裝飾器的思維升級
1. 回調函數是“被動響應”的工具,核心是“傳遞函數作為參數,等待觸發”。 ?
2. 裝飾器是“主動改造”的工具,核心是“用新函數包裝原函數,修改行為”。 ?
3. Hook 函數是兩者的靈活結合,既可以通過回調參數實現(如 PyTorch),也可以通過裝飾器機制實現(如某些框架的生命周期鉤子)。 ?
Hook 的底層工作原理
PyTorch 的 Hook 機制基于其動態計算圖系統:
1. 當你注冊一個 Hook 時,PyTorch 會在計算圖的特定節點(如模塊或張量)上添加一個回調函數。
2. 當計算圖執行到該節點時(前向或反向傳播),自動觸發對應的 Hook 函數。
3. Hook 函數可以訪問或修改流經該節點的數據(如輸入、輸出或梯度)。
這種設計使得 Hook 能夠在不干擾模型正常運行的前提下,靈活地插入自定義邏輯。
理解這兩個概念后,再學習 Hook 會更輕松——Hook 本質是在程序流程中預留的“可插入點”,而插入的方式可以是回調函數、裝飾器或其他形式。
1.2 lamda匿名函數
在hook中常常用到lambda函數,它是一種匿名函數(沒有正式名稱的函數),最大特點是用完即棄,無需提前命名和定義。它的語法形式非常簡約,僅需一行即可完成定義,格式如下:
lambda 參數列表: 表達式
- 參數列表:可以是單個參數、多個參數或無參數。
- 表達式:函數的返回值(無需 return 語句,表達式結果直接返回)。
# 定義匿名函數:計算平方
square = lambda x: x ** 2# 調用
print(square(5)) # 輸出: 25這種形式很簡約,只需要一行就可以定義一個函數,lambda 的核心價值在于用極簡語法快速定義臨時函數,避免為一次性使用的簡單邏輯單獨命名函數,從而減少代碼冗余,提升開發效率。
與普通函數的對比

二、 hook函數
Hook 函數是一種回調函數,它可以在不干擾模型正常計算流程的情況下,插入到模型的特定位置,以便獲取或修改中間層的輸出或梯度。PyTorch 提供了兩種主要的 hook:
1. Module Hooks:用于監聽整個模塊的輸入和輸出
2. Tensor Hooks:用于監聽張量的梯度
下面我們將通過具體的例子來學習這兩種 hook 的使用方法。
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt# 設置隨機種子,保證結果可復現
torch.manual_seed(42)
np.random.seed(42)2.1 模塊鉤子 (Module Hooks)
模塊鉤子允許我們在模塊的輸入或輸出經過時進行監聽。PyTorch 提供了兩種模塊鉤子:
- `register_forward_hook`:在前向傳播時監聽模塊的輸入和輸出
- `register_backward_hook`:在反向傳播時監聽模塊的輸入梯度和輸出梯度
2.1.1 前向鉤子 (Forward Hook)
前向鉤子是一個函數,它會在模塊的前向傳播完成后立即被調用。這個函數可以訪問模塊的輸入和輸出,但不能修改它們。讓我們通過一個簡單的例子來理解前向鉤子的工作原理。
import torch
import torch.nn as nn# 定義一個簡單的卷積神經網絡模型
class SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()# 定義卷積層:輸入通道1,輸出通道2,卷積核3x3,填充1保持尺寸不變self.conv = nn.Conv2d(1, 2, kernel_size=3, padding=1)# 定義ReLU激活函數self.relu = nn.ReLU()# 定義全連接層:輸入特征2*4*4,輸出10分類self.fc = nn.Linear(2 * 4 * 4, 10)def forward(self, x):# 卷積操作x = self.conv(x)# 激活函數x = self.relu(x)# 展平為一維向量,準備輸入全連接層x = x.view(-1, 2 * 4 * 4)# 全連接分類x = self.fc(x)return x# 創建模型實例
model = SimpleModel()# 創建一個列表用于存儲中間層的輸出
conv_outputs = []# 定義前向鉤子函數 - 用于在模型前向傳播過程中獲取中間層信息
def forward_hook(module, input, output):"""前向鉤子函數,會在模塊每次執行前向傳播后被自動調用參數:module: 當前應用鉤子的模塊實例input: 傳遞給該模塊的輸入張量元組output: 該模塊產生的輸出張量"""print(f"鉤子被調用!模塊類型: {type(module)}")print(f"輸入形狀: {input[0].shape}") # input是一個元組,對應 (image, label)print(f"輸出形狀: {output.shape}")# 保存卷積層的輸出用于后續分析# 使用detach()避免追蹤梯度,防止內存泄漏conv_outputs.append(output.detach())# 在卷積層注冊前向鉤子
# register_forward_hook返回一個句柄,用于后續移除鉤子
hook_handle = model.conv.register_forward_hook(forward_hook)# 創建一個隨機輸入張量 (批次大小=1, 通道=1, 高度=4, 寬度=4)
x = torch.randn(1, 1, 4, 4)# 執行前向傳播 - 此時會自動觸發鉤子函數
output = model(x)# 釋放鉤子 - 重要!防止在后續模型使用中持續調用鉤子造成意外行為或內存泄漏
hook_handle.remove()# # 打印中間層輸出結果
# if conv_outputs:
# print(f"\n卷積層輸出形狀: {conv_outputs[0].shape}")
# print(f"卷積層輸出值示例: {conv_outputs[0][0, 0, :, :]}")在上面的例子中,我們定義了一個簡單的模型,包含卷積層、ReLU激活函數和全連接層。然后,我們在卷積層上注冊了一個前向鉤子。當前向傳播執行到卷積層時,鉤子函數會被自動調用。
鉤子函數接收三個參數:
- module:應用鉤子的模塊實例
- input:傳遞給模塊的輸入(可能包含多個張量)
- output:模塊的輸出
我們可以在鉤子函數中查看或記錄這些信息,但不能直接修改它們。如果需要修改輸出,可以使用 register_forward_pre_hook?或 register_forward_hook_with_kwargs(PyTorch 1.9+)。
最后,我們使用 hook_handle.remove()?釋放了鉤子,這一點很重要,因為未釋放的鉤子可能會導致內存泄漏。
# 讓我們可視化卷積層的輸出
if conv_outputs:plt.figure(figsize=(10, 5))# 原始輸入圖像plt.subplot(1, 3, 1)plt.title('輸入圖像')plt.imshow(x[0, 0].detach().numpy(), cmap='gray') # 顯示灰度圖像# 第一個卷積核的輸出plt.subplot(1, 3, 2)plt.title('卷積核1輸出')plt.imshow(conv_outputs[0][0, 0].detach().numpy(), cmap='gray')# 第二個卷積核的輸出plt.subplot(1, 3, 3)plt.title('卷積核2輸出')plt.imshow(conv_outputs[0][0, 1].detach().numpy(), cmap='gray')plt.tight_layout()plt.show()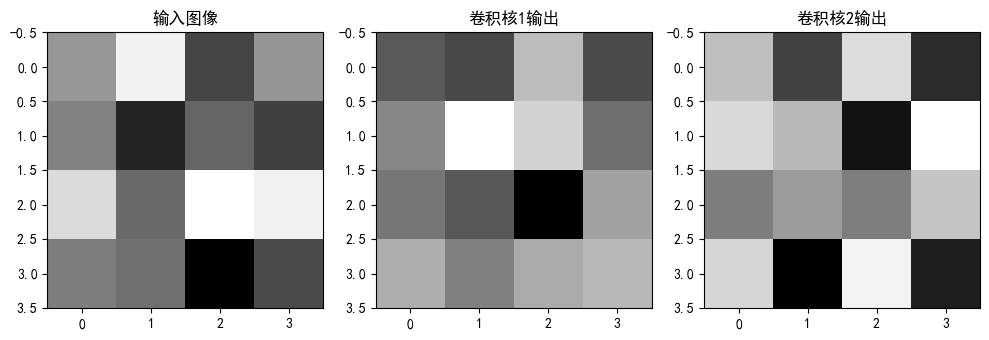
2.1.2 反向鉤子 (Backward Hook)
反向鉤子與前向鉤子類似,但它是在反向傳播過程中被調用的。反向鉤子可以用來獲取或修改梯度信息。
# 定義一個存儲梯度的列表
conv_gradients = []# 定義反向鉤子函數
def backward_hook(module, grad_input, grad_output):# 模塊:當前應用鉤子的模塊# grad_input:模塊輸入的梯度# grad_output:模塊輸出的梯度print(f"反向鉤子被調用!模塊類型: {type(module)}")print(f"輸入梯度數量: {len(grad_input)}")print(f"輸出梯度數量: {len(grad_output)}")# 保存梯度供后續分析conv_gradients.append((grad_input, grad_output))# 在卷積層注冊反向鉤子
hook_handle = model.conv.register_backward_hook(backward_hook)# 創建一個隨機輸入并進行前向傳播
x = torch.randn(1, 1, 4, 4, requires_grad=True)
output = model(x)# 定義一個簡單的損失函數并進行反向傳播
loss = output.sum()
loss.backward()# 釋放鉤子
hook_handle.remove()?2.2 張量鉤子 (Tensor Hooks)
除了模塊鉤子,PyTorch 還提供了張量鉤子,允許我們直接監聽和修改張量的梯度。張量鉤子有兩種:
- register_hook:用于監聽張量的梯度
- register_full_backward_hook:用于在完整的反向傳播過程中監聽張量的梯度(PyTorch 1.4+)
# 創建一個需要計算梯度的張量
x = torch.tensor([2.0], requires_grad=True)
y = x ** 2
z = y ** 3# 定義一個鉤子函數,用于修改梯度
def tensor_hook(grad):print(f"原始梯度: {grad}")# 修改梯度,例如將梯度減半return grad / 2# 在y上注冊鉤子
hook_handle = y.register_hook(tensor_hook)# 計算梯度
z.backward()print(f"x的梯度: {x.grad}")# 釋放鉤子
hook_handle.remove()在這個例子中,我們創建了一個計算圖 z = (x^2)^3。然后在中間變量 y?上注冊了一個鉤子。當調用 z.backward()?時,梯度會從 z?反向傳播到 x。在傳播過程中,鉤子函數會被調用,我們可以在鉤子函數中查看或修改梯度。
在這個例子中,我們將梯度減半,因此最終 x?的梯度是原始梯度的一半。
三、 Grad-CAM
Grad-CAM (Gradient-weighted Class Activation Mapping) 算法是一種強大的可視化技術,用于解釋卷積神經網絡 (CNN) 的決策過程。它通過計算特征圖的梯度來生成類激活映射(Class Activation Mapping,簡稱 CAM ),直觀地顯示圖像中哪些區域對模型的特定預測貢獻最大。
Grad-CAM 的核心思想是:通過反向傳播得到的梯度信息,來衡量每個特征圖對目標類別的重要性。
1. 梯度信息:通過計算目標類別對特征圖的梯度,得到每個特征圖的重要性權重。
2. 特征加權:用這些權重對特征圖進行加權求和,得到類激活映射。
3. 可視化:將激活映射疊加到原始圖像上,高亮顯示對預測最關鍵的區域。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image# 設置隨機種子確保結果可復現
# 在深度學習中,隨機種子可以讓每次運行代碼時,模型初始化參數、數據打亂等隨機操作保持一致,方便調試和對比實驗結果
torch.manual_seed(42)
np.random.seed(42)# 加載CIFAR-10數據集
# 定義數據預處理步驟,先將圖像轉換為張量,再進行歸一化操作
# 歸一化的均值和標準差是(0.5, 0.5, 0.5),這里的均值和標準差是對CIFAR-10數據集的經驗值,使得數據分布更有利于模型訓練
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])# 加載測試集,指定數據集根目錄為'./data',設置為測試集(train=False),如果數據不存在則下載(download=True),并應用上述定義的預處理
testset = torchvision.datasets.CIFAR10(root='./data', train=False,download=True, transform=transform
)# 定義類別名稱,CIFAR-10數據集包含這10個類別
classes = ('飛機', '汽車', '鳥', '貓', '鹿', '狗', '青蛙', '馬', '船', '卡車')# 定義一個簡單的CNN模型
class SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()# 第一個卷積層,輸入通道為3(彩色圖像),輸出通道為32,卷積核大小為3x3,填充為1以保持圖像尺寸不變self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)# 第二個卷積層,輸入通道為32,輸出通道為64,卷積核大小為3x3,填充為1self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)# 第三個卷積層,輸入通道為64,輸出通道為128,卷積核大小為3x3,填充為1self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)# 最大池化層,池化核大小為2x2,步長為2,用于下采樣,減少數據量并提取主要特征self.pool = nn.MaxPool2d(2, 2)# 第一個全連接層,輸入特征數為128 * 4 * 4(經過前面卷積和池化后的特征維度),輸出為512self.fc1 = nn.Linear(128 * 4 * 4, 512)# 第二個全連接層,輸入為512,輸出為10(對應CIFAR-10的10個類別)self.fc2 = nn.Linear(512, 10)def forward(self, x):# 第一個卷積層后接ReLU激活函數和最大池化操作,經過池化后圖像尺寸變為原來的一半,這里輸出尺寸變為16x16x = self.pool(F.relu(self.conv1(x))) # 第二個卷積層后接ReLU激活函數和最大池化操作,輸出尺寸變為8x8x = self.pool(F.relu(self.conv2(x))) # 第三個卷積層后接ReLU激活函數和最大池化操作,輸出尺寸變為4x4x = self.pool(F.relu(self.conv3(x))) # 將特征圖展平為一維向量,以便輸入到全連接層x = x.view(-1, 128 * 4 * 4)# 第一個全連接層后接ReLU激活函數x = F.relu(self.fc1(x))# 第二個全連接層輸出分類結果x = self.fc2(x)return x# 初始化模型
model = SimpleCNN()
print("模型已創建")# 如果有GPU則使用GPU,將模型轉移到對應的設備上
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)# 訓練模型(簡化版,實際應用中應該進行完整訓練)
def train_model(model, epochs=1):# 加載訓練集,指定數據集根目錄為'./data',設置為訓練集(train=True),如果數據不存在則下載(download=True),并應用前面定義的預處理trainset = torchvision.datasets.CIFAR10(root='./data', train=True,download=True, transform=transform)# 創建數據加載器,設置批量大小為64,打亂數據順序(shuffle=True),使用2個線程加載數據trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,shuffle=True, num_workers=2)# 定義損失函數為交叉熵損失,用于分類任務criterion = nn.CrossEntropyLoss()# 定義優化器為Adam,用于更新模型參數,學習率設置為0.001optimizer = torch.optim.Adam(model.parameters(), lr=0.001)for epoch in range(epochs):running_loss = 0.0for i, data in enumerate(trainloader, 0):# 從數據加載器中獲取圖像和標簽inputs, labels = data# 將圖像和標簽轉移到對應的設備(GPU或CPU)上inputs, labels = inputs.to(device), labels.to(device)# 清空梯度,避免梯度累加optimizer.zero_grad()# 模型前向傳播得到輸出outputs = model(inputs)# 計算損失loss = criterion(outputs, labels)# 反向傳播計算梯度loss.backward()# 更新模型參數optimizer.step()running_loss += loss.item()if i % 100 == 99:# 每100個批次打印一次平均損失print(f'[{epoch + 1}, {i + 1}] 損失: {running_loss / 100:.3f}')running_loss = 0.0print("訓練完成")# 訓練模型(可選,如果有預訓練模型可以加載)
# 取消下面這行的注釋來訓練模型
# train_model(model, epochs=1)# 或者嘗試加載預訓練模型(如果存在)
try:# 嘗試加載名為'cifar10_cnn.pth'的模型參數model.load_state_dict(torch.load('cifar10_cnn.pth'))print("已加載預訓練模型")
except:print("無法加載預訓練模型,使用未訓練模型或訓練新模型")# 如果沒有預訓練模型,可以在這里調用train_model函數train_model(model, epochs=1)# 保存訓練后的模型參數torch.save(model.state_dict(), 'cifar10_cnn.pth')# 設置模型為評估模式,此時模型中的一些操作(如dropout、batchnorm等)會切換到評估狀態
model.eval()# Grad-CAM實現
class GradCAM:def __init__(self, model, target_layer):self.model = modelself.target_layer = target_layerself.gradients = Noneself.activations = None# 注冊鉤子,用于獲取目標層的前向傳播輸出和反向傳播梯度self.register_hooks()def register_hooks(self):# 前向鉤子函數,在目標層前向傳播后被調用,保存目標層的輸出(激活值)def forward_hook(module, input, output):self.activations = output.detach()# 反向鉤子函數,在目標層反向傳播后被調用,保存目標層的梯度def backward_hook(module, grad_input, grad_output):self.gradients = grad_output[0].detach()# 在目標層注冊前向鉤子和反向鉤子self.target_layer.register_forward_hook(forward_hook)self.target_layer.register_backward_hook(backward_hook)def generate_cam(self, input_image, target_class=None):# 前向傳播,得到模型輸出model_output = self.model(input_image)if target_class is None:# 如果未指定目標類別,則取模型預測概率最大的類別作為目標類別target_class = torch.argmax(model_output, dim=1).item()# 清除模型梯度,避免之前的梯度影響self.model.zero_grad()# 反向傳播,構造one-hot向量,使得目標類別對應的梯度為1,其余為0,然后進行反向傳播計算梯度one_hot = torch.zeros_like(model_output)one_hot[0, target_class] = 1model_output.backward(gradient=one_hot)# 獲取之前保存的目標層的梯度和激活值gradients = self.gradientsactivations = self.activations# 對梯度進行全局平均池化,得到每個通道的權重,用于衡量每個通道的重要性weights = torch.mean(gradients, dim=(2, 3), keepdim=True)# 加權激活映射,將權重與激活值相乘并求和,得到類激活映射的初步結果cam = torch.sum(weights * activations, dim=1, keepdim=True)# ReLU激活,只保留對目標類別有正貢獻的區域,去除負貢獻的影響cam = F.relu(cam)# 調整大小并歸一化,將類激活映射調整為與輸入圖像相同的尺寸(32x32),并歸一化到[0, 1]范圍cam = F.interpolate(cam, size=(32, 32), mode='bilinear', align_corners=False)cam = cam - cam.min()cam = cam / cam.max() if cam.max() > 0 else camreturn cam.cpu().squeeze().numpy(), target_classimport warnings
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
# 設置中文字體支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解決負號顯示問題
# 選擇一個隨機圖像
# idx = np.random.randint(len(testset))
idx = 102 # 選擇測試集中的第101張圖片 (索引從0開始)
image, label = testset[idx]
print(f"選擇的圖像類別: {classes[label]}")# 轉換圖像以便可視化
def tensor_to_np(tensor):img = tensor.cpu().numpy().transpose(1, 2, 0)mean = np.array([0.5, 0.5, 0.5])std = np.array([0.5, 0.5, 0.5])img = std * img + meanimg = np.clip(img, 0, 1)return img# 添加批次維度并移動到設備
input_tensor = image.unsqueeze(0).to(device)# 初始化Grad-CAM(選擇最后一個卷積層)
grad_cam = GradCAM(model, model.conv3)# 生成熱力圖
heatmap, pred_class = grad_cam.generate_cam(input_tensor)# 可視化
plt.figure(figsize=(12, 4))# 原始圖像
plt.subplot(1, 3, 1)
plt.imshow(tensor_to_np(image))
plt.title(f"原始圖像: {classes[label]}")
plt.axis('off')# 熱力圖
plt.subplot(1, 3, 2)
plt.imshow(heatmap, cmap='jet')
plt.title(f"Grad-CAM熱力圖: {classes[pred_class]}")
plt.axis('off')# 疊加的圖像
plt.subplot(1, 3, 3)
img = tensor_to_np(image)
heatmap_resized = np.uint8(255 * heatmap)
heatmap_colored = plt.cm.jet(heatmap_resized)[:, :, :3]
superimposed_img = heatmap_colored * 0.4 + img * 0.6
plt.imshow(superimposed_img)
plt.title("疊加熱力圖")
plt.axis('off')plt.tight_layout()
plt.savefig('grad_cam_result.png')
plt.show()# print("Grad-CAM可視化完成。已保存為grad_cam_result.png")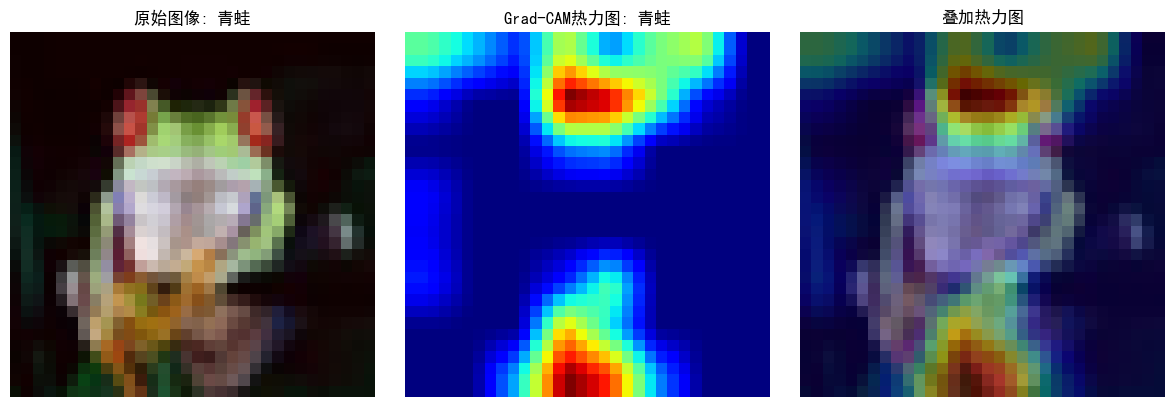
可以看到通過腿和頭部判斷是青蛙
)






)
)






自動領積分腳本部署——基于python和Selenium(附源碼))
—狀態管理》)


