性能優化轉載
https://www.cnblogs.com/tengzijian/p/17858112.html
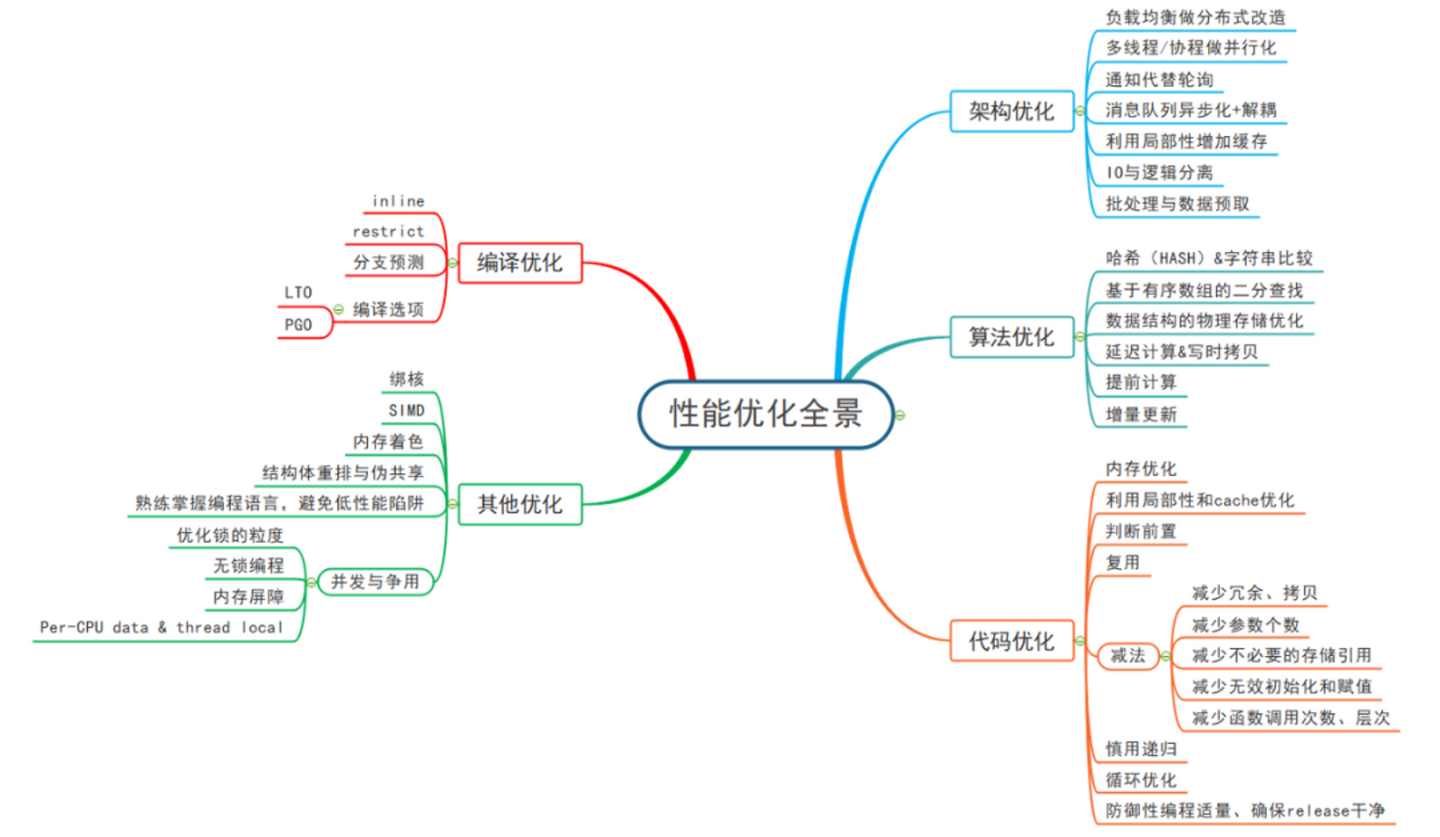
性能優化的一般策略及方法
簡言之,非必要,不優化。先保證良好的設計,編寫易于理解和修改的整潔代碼。如果現有的代碼很糟糕,先清理重構,然后再考慮優化。
常見性能問題元兇
a. 輸入/輸出操作
不必要的 I/O 操作是最常見的導致性能問題的罪魁禍首。比如頻繁讀寫磁盤上的文件、通過網絡訪問數據庫等。
b. 缺頁
c. 系統調用
系統調用需要進行上下文切換,保存程序狀態、恢復內核狀態等一些步驟,開銷相對較大。對磁盤的讀寫操作、對鍵盤、屏幕等外設的操作、內存管理函數的調用等都屬于系統調用。
Linux 系統調用可以通過 strace 查看,qnx 也有 tracelogger 等工具
d. 解釋型語言
一般來說,C/C++/VB/C# 這種編譯型語言的性能好于 Java 的字節碼,好于 PHP/Pyhon 等解釋型語言。
e. 錯誤
還有很大很一部分導致性能問題的原因可以歸為錯誤:忘了把調試代碼(如保存 trace 到文件)關閉,忘記釋放資源/內存泄漏、數據庫表設計缺陷(常用表沒有索引)等。
常見操作的相對開銷
| 操作 | 示例 | 相對耗時(C++) |
|---|---|---|
| 整數賦值(基準) | i = j | 1 |
| 函數調用 | ||
| 普通函數調用(無參) | foo() | 1 |
| 普通函數調用(單參) | foo(i) | 1.5 |
| 普通函數調用(雙參) | foo(i,j) | 2 |
| 類的成員函數調用 | bar.foo() | 2 |
| 子類的成員函數調用 | derivedBar.foo() | 2 |
| 多態方法調用 | abstractBar.foo() | 2.5 |
| 對象解引用 | ||
| 訪問對象成員(一級/二級) | i = obj1.obj2.num | 1 |
| 整數運算 | ||
| 整數賦值/加/減/乘 | i = j * k | 1 |
| 整數除法 | i = j / k | 5 |
| 浮點運算 | ||
| 浮點賦值/加/減/乘 | x = y * z | 1 |
| 浮點除法 | x = y / z | 4 |
| 超越函數 | ||
| 浮點根號 | y = sqrt(x) | 15 |
| 浮點 sin | y = sin(x) | 25 |
| 浮點對數 | y = log(x) | 25 |
| 浮點指數 | y = exp(x) | 50 |
| 數組操作 | ||
| 一維/二維整數/浮點數組下標訪問 | x = a[3][j] | 1 |
注:上表僅供參考,不同處理器、不同語言、不同編譯器、不同測試環境所得結果可能相差很大!
測量要準確
- 用專門的 Profiling 工具或者系統時間
- 只測量你自己的代碼部分
- 必要時需要用 CPU 時鐘 tick 數來替代時間戳以獲得更準確的測量結果
調優一般方法
- 程序設計良好,易于理解和修改(前提)
- 如果性能不佳:
a. 保存當前狀態
b. 測量,找出時間主要消耗在哪里
c. 分析問題:是否因為高層設計、數據結構、算法導致的,如果是,返回步驟 1
d. 如果設計、數據結構、算法沒問題,針對上述步驟中的瓶頸進行代碼調優
e. 每進行一項優化,立即進行測量
f. 如果沒有效果,恢復到 a 的狀態。(大多數的調優嘗試幾乎不會對性能產生影響,甚至產生負面影響。代碼調優的前提是代碼設計良好,易于理解和修改。Code tuning 通常會對設計、可讀性、可維護性產生負面影響,如果 tuning 改良了設計或者可讀性,那么不應該叫 tuning,而是屬于步驟 1) - 重復步驟 2
并發轉載
https://www.cnblogs.com/tengzijian/p/a-tour-of-cpp-modern-cpp-concurrency-1.html
多線程/并發
不要把并發當作靈丹妙藥:如果順序執行可以搞定,通常順序會比并發更簡單、更快速!
標準庫還在頭文件 <future> 中提供了一些機制,能夠讓程序員在更高的任務的概念層次上工作,而不是直接使用低層的線程、鎖:
future和promise:用于從另一個線程中返回一個值packaged_task:幫助啟動任務,封裝了future和promise,并且建立兩者之間的關聯async():像調用一個函數那樣啟動一個任務。形式最簡單,但也最強大!
future 和 promise
future 和 promise 可以在兩個任務之間傳值,而無需顯式地使用鎖,實現了高效地數據傳輸。其基本想法很簡單:當一個任務向另一個任務傳值時,把值放入 promise,通過特定的實現,使得值可以通過與之關聯的 future 讀出(一般誰啟動了任務,誰從 future 中取結果)。
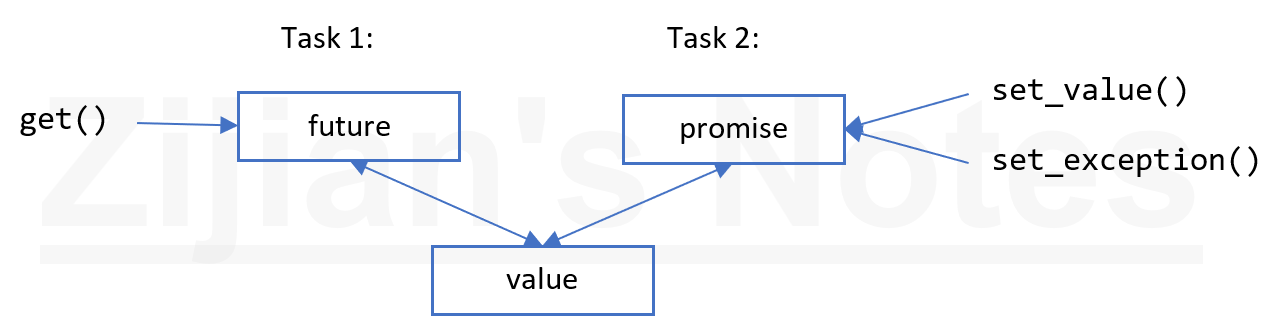
packaged_task
packaged_task 可以簡化任務的設置,關聯 future/promise。packaged_task 封裝了把返回值或異常放入 promise 的操作,并且調用 packaged_task 的 get_future() 方法,可以得到一個與 promise 關聯的 future。
async()
把任務看成是一個恰巧可能和其他任務同時運行的函數。
C++ 高性能編程實戰轉載
https://zhuanlan.zhihu.com/p/533708198
一、整體視角
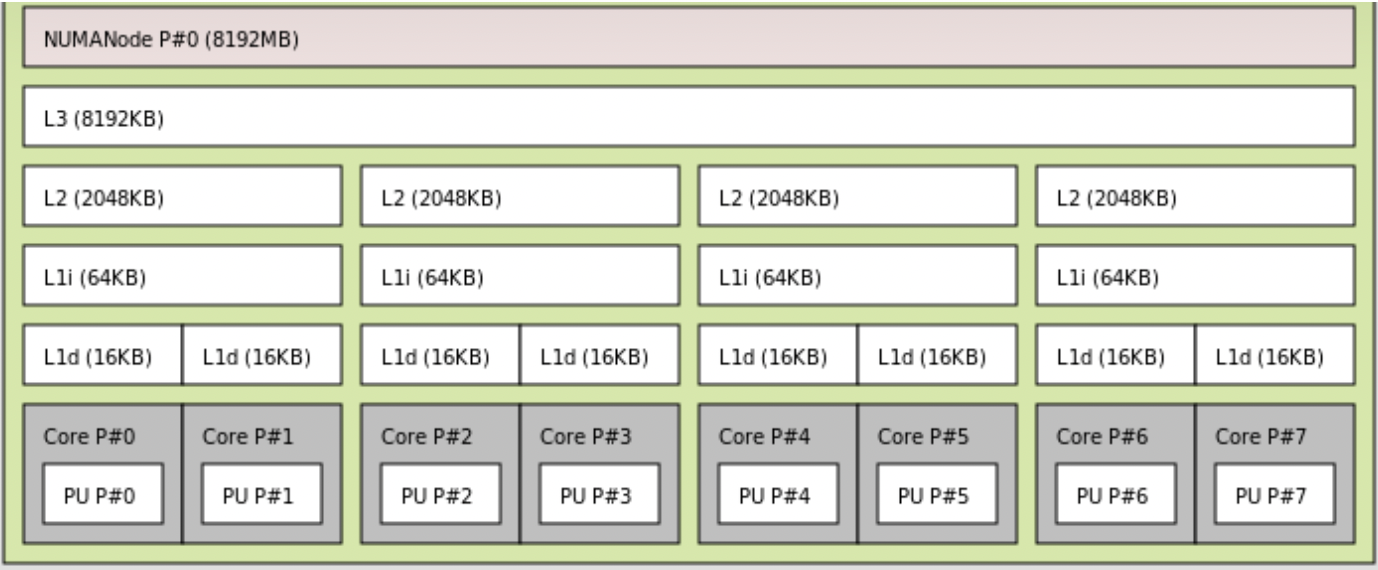
預置知識 - Cache
Cache line size
CPU 從內存 Load 數據是一次一個 cache line;往內存里面寫也是一次一個 cache line,所以一個 cache line 里面的數據最好是讀寫分開,否則就會相互影響。
Cache associative
全關聯(full associative):內存可以映射到任意一個 Cache line;
N-way 關聯:這個就是一個哈希表的結構,N 就是沖突鏈的長度,超過了 N,就需要替換。
Cache type
I-cache(指令)、D-cache(數據)、TLB(MMU 的 cache)
系統優化方法
1. Asynchronous
2.Polling
用于 輪詢 或 輪詢式檢查 外設或資源的狀態,通常用于 檢查是否有數據可用 或 某個事件是否發生。
Polling 是網絡設備里面常用的一個技術,比如 Linux 的 NAPI 或者 epoll。與之對應的是中斷,或者是事件。Polling 避免了狀態切換的開銷,所以有更高的性能。
3. 靜態內存池
靜態內存有更好的性能,但是適應性較差(特別是系統里面有多個 任務的時候),而且會有浪費(提前分配,還沒用到就分配了)。
4. 并發優化:lock-free 和 lock-less
lock-free 是完全無鎖的設計,有兩種實現方式:
? Per-CPU 數據(有時也叫 Thread-Local Storage, TLS)
? CAS based,CAS 是 compare and swap,這是一個原子操作(spinlock 的實現同樣需要 compare and swap,但區別是 spinlock 只有兩個狀態 LOCKED 和 UNLOCKED,而 CAS 的變量可以有多個狀態);其次,CAS 的實現必須由硬件來保障(原子操作),CAS 一次可以操作 32 bits,也有 MCAS,一次可以修改一塊內存。基于 CAS 實現的數據結構沒有一個統一、一致的實現方法,所以有時不如直接加鎖的算法那么簡單,直接,針對不同的數據結構,有不同的 CAS 實現方法。
lock-less 的目的是減少鎖的爭用(contention),而不是減少鎖。這個和鎖的粒度(granularity)相關,鎖的粒度越小,等待的時間就越短,并發的時間就越長。
鎖的爭用,需要考慮不同線程在獲取鎖后,會執行哪些不同的動作。比如多線程隊列,一般情況下,我們一把鎖鎖住整個隊列,性能很差。如果所有的 enqueue 操作都是往隊列的尾部插入新節點,而所有的 dequeue 操作都是從隊列的頭部刪除節點,那么 enqueue 和 dequeue 大部分時候都是相互獨立的,我們大部分時候根本不需要鎖住整個隊列,白白損失性能!那么一個很自然就能想到的算法優化方案就呼之欲出了:我們可以把那個隊列鎖拆成兩個:一個隊列頭部鎖(head lock)和一個隊列尾部鎖(tail lock)
5. 進程間通信 - 共享內存
對于本地進程間需要高頻次的大量數據交互,首推共享內存這種方案。
6. I/O 優化 - 多路復用技術
網絡編程中,當每個線程都要阻塞在 recv 等待對方的請求,如果訪問的人多了,線程開的就多了,大量線程都在阻塞,系統運轉速度也隨之下降。這個時候,你需要多路復用技術,使用 select 模型,將所有等待(accept、recv)都放在主線程里,工作線程不需要再等待。
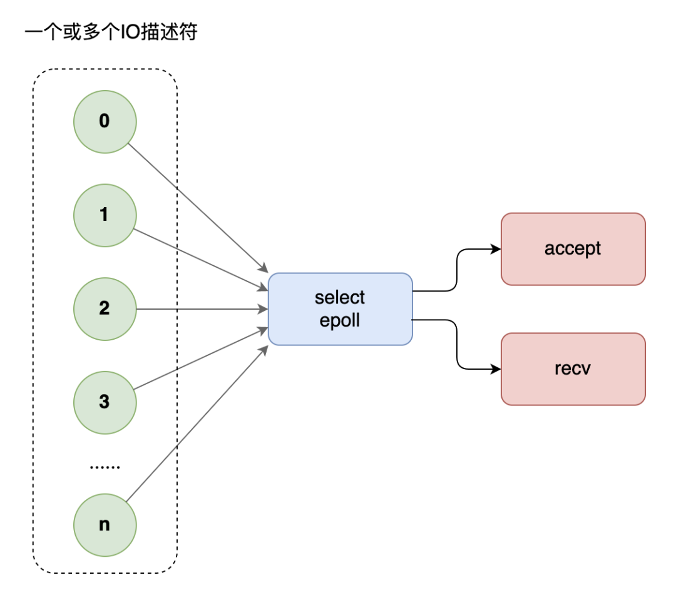
但是,select 不能應付海量的網站訪問。這個時候,你需要升級多路復用模型為 epoll。select 有三弊,epoll 有三優:
- select 底層采用數組來管理套接字描述符,同時管理的數量有上限,一般不超過幾千個,epoll使用樹和鏈表來管理,同時管理數量可以很大
- select不會告訴你到底哪個套接字來了消息,你需要一個個去詢問。epoll 直接告訴你誰來了消息,不用輪詢
- select進行系統調用時還需要把套接字列表在用戶空間和內核空間來回拷貝,循環中調用 select 時簡直浪費。epoll 統一在內核管理套接字描述符,無需來回拷貝
7. 線程池技術
使用一個公共的任務隊列,請求來臨時向隊列中投遞任務,各個工作線程統一從隊列中不斷取出任務來處理,這就是線程池技術。
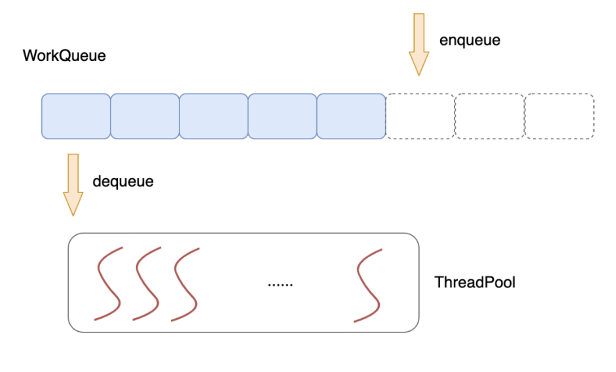
多線程技術的使用一定程度提升了服務器的并發能力,但同時,多個線程之間為了數據同步,常常需要使用互斥體、信號、條件變量等手段來同步多個線程。這些重量級的同步手段往往會導致線程在用戶態/內核態多次切換,系統調用,線程切換都是不小的開銷。
算法優化
代碼層次優化
1. I-cache 優化
一是相關的源文件要放在一起;二是相關的函數在object文件里面,也應該是相鄰的。這樣,在可執行文件被加載到內存里面的時候,函數的位置也是相鄰的。相鄰的函數,沖突的幾率比較小。而且相關的函數放在一起,也符合模塊化編程的要求:那就是 高內聚,低耦合。
如果能夠把一個 code path 上的函數編譯到一起(需要編譯器支持,把相關函數編譯到一起), 很顯然會提高 I-cache 的命中率,減少沖突。但是一個系統有很多個 code path,所以不可能面面俱到。不同的性能指標,在優化的時候可能是沖突的。所以盡量做對所以 case 都有效的優化,雖然做到這一點比較難。
常見的手段有函數重排(獲取程序運行軌跡,重排二進制目標文件(elf 文件)里的代碼段)、函數冷熱分區等。
2. D-cache相關優化
- Cache line alignment (cache 對齊)
數據跨越兩個 cacheline,就意味著兩次 load 或者兩次 store。如果數據結構是 cacheline 對齊的,就有可能減少一次讀寫。數據結構的首地址 cache line 對齊,意味著可能有內存浪費(特別是數組這樣連續分配的數據結構),所以需要在空間和時間兩方面權衡。
- 分支預測
likely/unlikely
-
Data prefetch (數據預取)
-
Register parameters (寄存器參數)
一般來說,函數調用的參數少于某個數,比如 3,參數是通過寄存器傳遞的(這個要看 ABI 的約定)。所以,寫函數的時候,不要帶那么多參數。
- Lazy computation (延遲計算)
延遲計算的意思是最近用不上的變量,就不要去初始化。通常來說,在函數開始就會初始化很多數據,但是這些數據在函數執行過程中并沒有用到(比如一個分支判斷,就退出了函數),那么這些動作就是浪費了。
變量初始化是一個好的編程習慣,但是在性能優化的時候,有可能就是一個多余的動作,需要綜合考慮函數的各個分支,做出決定。
延遲計算也可以是系統層次的優化,比如 COW(copy-on-write) 就是在 fork 子進程的時候,并沒有復制父進程所有的頁表,而是只復制指令部分。當有寫發生的時候,再復制數據部分,這樣可以避免不必要的復制,提供進程創建的速度。
- Early computation (提前計算)
有些變量,需要計算一次,多次使用的時候。最好是提前計算一下,保存結果,以后再引用,避免每次都重新計算一次。
- Allocation on stack (局部變量)
內存盡量在棧上分配,不要用堆
- Per-cpu data structure (非共享的數據結構)
比如并發編程時,給每個線程分配獨立的內存空間
- Move exception path out (把 exception 處理放到另一個函數里面)
只要引入了異常機制,無論系統是否會拋出異常,異常代碼都會影響代碼的大小與性能;未觸發異常時對系統影響并不明顯,主要影響一些編譯優化手段;觸發異常之后按異常實現機制的不同,其對系統性能的影響也不相同,不過一般很明顯。所以,不用擔心異常對正常代碼邏輯性能的影響,同時不要借用異常機制處理業務邏輯。現代 C++ 編譯器所使用的異常機制對正常代碼性能的影響并不明顯,只有出現異常的時候異常機制才會影響整個系統的性能。
另外,把 exception path 和 critical path 放到一起(代碼混合在一起),就會影響 critical path 的 cache 性能。而很多時候,exception path 都是長篇大論,有點喧賓奪主的感覺。如果能把 critical path 和 exception path 完全分離開,這樣對 i-cache 有很大幫助
- Read, write split (讀寫分離)
偽共享(false sharing):就是說兩個無關的變量,一個讀,一個寫,而這兩個變量在一個cache line里面。那么寫會導致cache line失效(通常是在多核編程里面,兩個變量在不同的core上引用)。讀寫分離是一個很難運用的技巧,特別是在code很復雜的情況下。需要不斷地調試,是個力氣活(如果有工具幫助會好一點,比如 cache miss時觸發 cpu 的 execption 處理之類的)
瓶頸定位手段
軟件性能瓶頸定位的常用手段有 perf(火焰圖)以及在 Intel CPU 上使用 pmu-tools 進行 TopDown 分析**(TMAM(Top-down Micro-architecture Analysis Methodology,自頂向下的微架構分析方法))**。
二、并發優化
單線程中的并發
1.SIMD 指令集優化
實際上單核單線程內也能利用上硬件細粒度的并發能力:SIMD(Single Instruction Multiple Data),與之相對的就是多核多線程中的 MIMD(Multiple Instruction Multiple Data)。CPU 指令集的發展經歷了 MMX(Multi Media eXtension)、SSE(Streaming SIMD Extensions)、AVX(Advanced Vector Extensions)、IMCI 等。
C/C++指令集介紹以及優化(主要針對SSE優化)
https://zhuanlan.zhihu.com/p/325632066
2.OoOE(Out of Ordered Execution)優化
經典 5 級 RISC 流水線如下圖所示,分為 5 個步驟:取指 -> 譯碼 -> 計算 -> 訪存 -> 寫回。
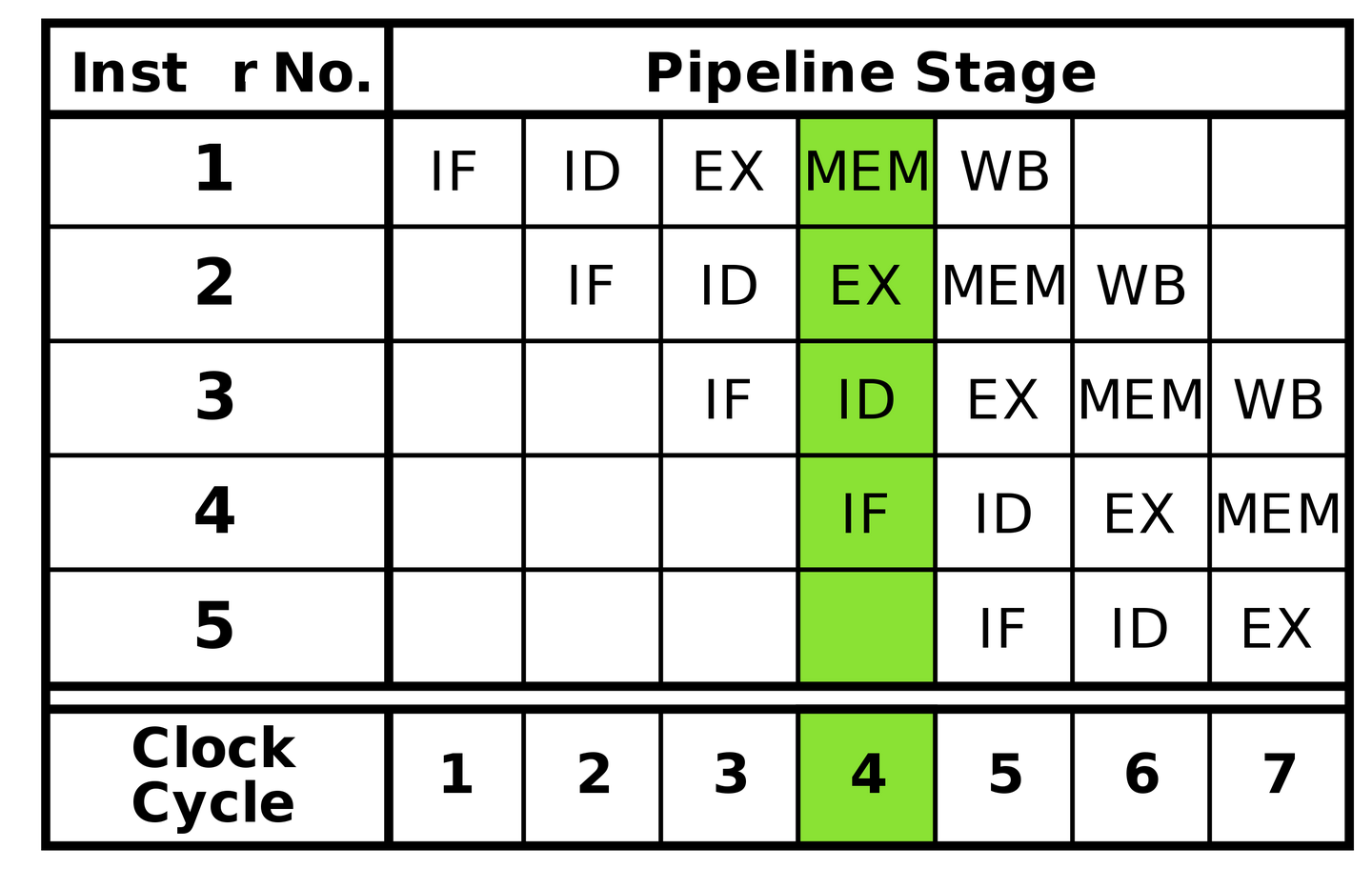
當執行環節遇到數據依賴,以及緩存未命中等場景,就會導致整體停頓的產生,其中 MEM 環節的影響尤其明顯,主要是因為多級緩存及多核共享帶來的單次訪存所需周期數參差不齊的現象越來越嚴重。為了減輕停頓的影響,現代 CPU 引入了亂序執行結合超標量的技術,一方面:對于重點執行部件,比如計算、訪存,增加多份來支持并行;另一方面:在執行部件前引入緩沖池/隊列機制。最終從流水線模式向類似"多線程"的方式靠攏。
3.TMAM(Top-down Micro-architecture Analysis Methodology,自頂向下的微架構分析方法)
TMAM 理論基礎就是將各類 CPU 微指令進行歸類從大的方面先確認可能出現的瓶頸,再進一步分析找到瓶頸點,該方法也符合我們人類的思維,從宏觀再到細節,過早的關注細節,往往需要花費更多的時間。這套方法論的優勢在于:
- 即使沒有硬件相關的知識也能夠基于 CPU 的特性優化程序
- 系統性的消除我們對程序性能瓶頸的猜測:分支預測成功率低?CPU 緩存命中率低?內存瓶頸?
- 快速的識別出在多核亂序 CPU 中瓶頸點
- Intel 提供分析工具:pmu-tools
TMAM 將各種 CPU 資源大致分為 4 類:
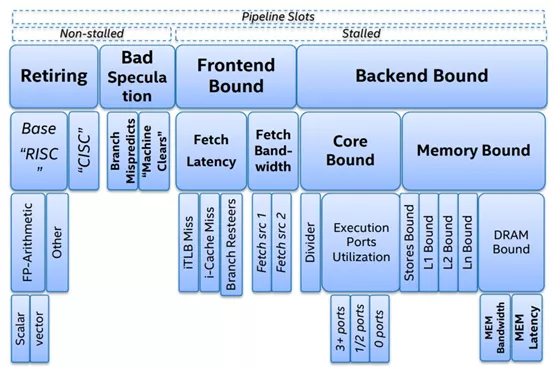
1.Retiring
Retiring 表示運行有效的 uOps 的 pipeline slot,即這些 uOps 最終會退出(注意一個微指令最終結果要么被丟棄、要么退出將結果回寫到 register),它可以用于評估程序對 CPU 的相對比較真實的有效率。理想情況下,所有流水線 slot 都應該是"Retiring"。100% 的 Retiring 意味著每個周期的 uOps Retiring數將達到最大化,極致的 Retiring 可以增加每個周期的指令吞吐數(IPC)。需要注意的是,Retiring 這一分類的占比高并不意味著沒有優化的空間。例如 retiring 中 Microcode assists 的類別實際上是對性能有損耗的,我們需要避免這類操作。
2.Bad Speculation
Bad Speculation 表示錯誤預測導致浪費 pipeline 資源,包括由于提交最終不會 retired 的 uOps 以及部分 slots 是由于從先前的錯誤預測中恢復而被阻塞的。由于預測錯誤分支而浪費的工作被歸類為"錯誤預測"類別。例如:if、switch、while、for等都可能會產生 bad speculation。
優化建議:
(1)在使用if的地方盡可能使用gcc的內置分支預測特性
#define likely(x) __builtin_expect(!!(x), 1) //gcc內置函數, 幫助編譯器分支優化
#define unlikely(x) __builtin_expect(!!(x), 0)if(likely(condition)) {// 這里的代碼執行的概率比較高}if(unlikely(condition)) {// 這里的代碼執行的概率比較高}// 盡量避免遠調用
(2)避免間接跳轉或者調用
在c++中比如switch、函數指針或者虛函數在生成匯編語言的時候都可能存在多個跳轉目標,這個也是會影響分支預測的結果,雖然BTB可改善這些但是畢竟BTB的資源是很有限的。
3.Front-End-Bound
- 取指令
- 將指令進行解碼成微指令
- 將指令分發給 Back-End,每個周期最多分發4條微指令
Front-End Bound 表示處理的 Front-End 的一部分 slots 沒法交付足夠的指令給 Back-End。Front-End 作為處理器的第一個部分其核心職責就是獲取 Back-End 所需的指令。在 Front-End 中由預測器預測下一個需要獲取的地址,然后從內存子系統中獲取對應的緩存行,在轉換成對應的指令,最后解碼成uOps(微指令)。Front-End Bound 意味著,會導致部分slot 即使 Back-End 沒有阻塞也會被閑置。例如因為指令 cache misses引起的阻塞是可以歸類為 Front-End Bound。
優化建議:
(1)盡可能減少代碼的 footprint:C/C++可以利用編譯器的優化選項來幫助優化,比如 GCC -O* 都會對 footprint 進行優化或者通過指定 -fomit-frame-pointer 也可以達到效果;
**(2)充分利用 CPU 硬件特性:**宏融合(macro-fusion)特性可以將2條指令合并成一條微指令,它能提升 Front-End 的吞吐。
(3)調整代碼布局(co-locating-hot-code)
- 充分利用編譯器的 PGO 特性:-fprofile-generate -fprofile-use
- 可以通過__attribute__ ((hot)) __attribute__ ((code)) 來調整代碼在內存中的布局,hot 的代碼在解碼階段有利于 CPU 進行預取。
(4)分支預測優化
- 消除分支可以減少預測的可能性能:比如小的循環可以展開比如循環次數小于64次(可以使用GCC選項 -funroll-loops)
- 盡量用if 代替:? ,不建議使用a=b>0? x:y 因為這個是沒法做分支預測的
- 盡可能減少組合條件,使用單一條件比如:if(a||b) {}else{} 這種代碼CPU沒法做分支預測的
- 對于多case的switch,盡可能將最可能執行的case 放在最前面
- 我們可以根據其靜態預測算法投其所好,調整代碼布局,滿足以下條件:前置條件,使條件分支后的的第一個代碼塊是最有可能被執行的
4.Back-End-Bound
- 接收 Front-End 提交的微指令
- 必要時對 Front-End 提交的微指令進行重排
- 從內存中獲取對應的指令操作數
- 執行微指令、提交結果到內存
Back-End Bound 表示部分 pipeline slots 因為 Back-End 缺少一些必要的資源導致沒有 uOps 交付給 Back-End。
Back-End 處理器的核心部分是通過調度器亂序地將準備好的 uOps 分發給對應執行單元,一旦執行完成,uOps 將會根據程序的順序返回對應的結果。例如:像 cache-misses 引起的阻塞(停頓)或者因為除法運算器過載引起的停頓都可以歸為此類。此類別可以在進行細分為兩大類:Memory-Bound 、Core Bound。
優化建議:
(1)調整算法減少數據存儲,減少前后指令數據的依賴提高指令運行的并發度
(2)根據cache line調整數據結構的大小
(3)避免L2、L3 cache偽共享
歸納總結一下就是:
Front End Bound = Bound in Instruction Fetch -> Decode (Instruction Cache, ITLB)
Back End Bound = Bound in Execute -> Commit (Example = Execute, load latency)
Bad Speculation = When pipeline incorrectly predicts execution (Example branch mispredict memory ordering nuke)
Retiring = Pipeline is retiring uops
一個微指令狀態可以按照下圖決策樹進行歸類:
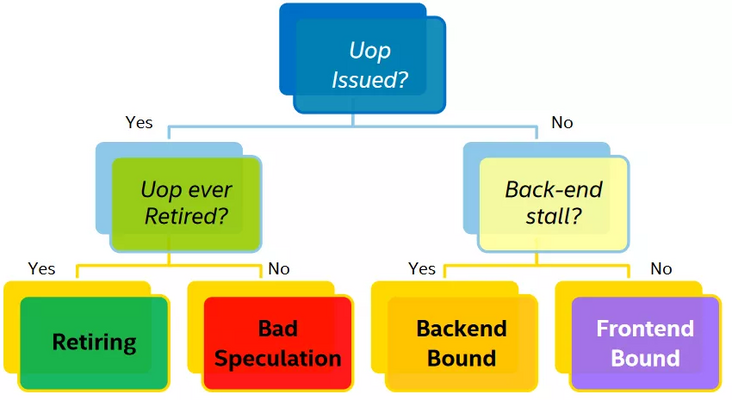
上圖中的葉子節點,程序運行一定時間之后各個類別都會有一個 pipeline slot 的占比,只有 Retiring 的才是我們所期望的結果,那么每個類別占比應該是多少才是合理或者說性能相對來說是比較好,沒有必要再繼續優化?Intel 在實驗室里根據不同的程序類型提供了一個參考的標準:
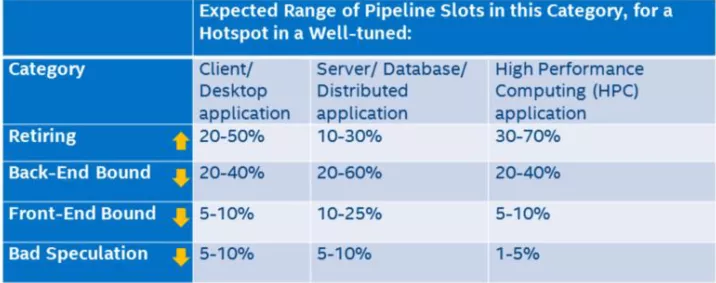
只有 Retiring 類別是越高越好,其他三類都是占比越低越好。如果某一個類別占比比較突出,那么它就是我們進行優化時重點關注的對象。
使用示例
https://segmentfault.com/a/1190000039650181
多線程中的并發
1.臨界區保護技術
- Mutual Execlusion(pessimistic locking):基本的互斥技術,如果多個線程競爭同一個鎖,存在某個時間周期,算法沒有任何實質進展,典型的悲觀鎖算法
- Lock Free (optimistic locking):因為沖突組成算法的一個線程沒有任何實質進展,基于 CAS 同步提交,若遇到沖突,回滾
- Wait Free:任意時間周期,算法的任意一個線程都有實質進展
**多線程累加,**上述三種技術對應以下實現方案:
-
上鎖后累加:簡單易懂,但會引入鎖的開銷和潛在的阻塞。
-
累加后 CAS 提交:無鎖的實現,使用 CAS 確保線程安全,適用于高并發場景。
-
累加后 FAA:使用 Fetch and Add 原子操作,簡潔且性能優越,適合頻繁的累加操作。
-
優先考慮 Wait Free 的方法,如果可以的話,在性能上接近完全消除了臨界區的效果
-
充分縮減臨界區
-
在臨界區足夠小,且無 Wait Free 方案時,不必對 Lock Free 過度執著,因為 Lock Free “無效預測執行” 以及支持撤銷回滾的兩階段提交算法非常復雜,反而會引起過多的消耗。鎖本身的開銷雖然稍重于原子操作,但其實可以接受的。真正影響性能的是臨界區被迫串行執行所帶來的并行能力折損。
2.并發隊列
3.偽共享
三、內存優化
內存分配器tcmalloc 和 jemalloc,分別來自 google 和 facebook
針對多線程競爭的角度,tcmalloc 和 jemalloc 共同的思路是引入線程緩存機制。通過一次從后端獲取大塊內存,放入緩存供線程多次申請,降低對后端的實際競爭強度。主要不同點是,當線程緩存被擊穿后,tcmalloc 采用了單一的 page heap(簡化了中間的 transfer cache 和 central cache) 來承載;而 jemalloc 采用了多個 arena(甚至超過了服務器 core 數)來承載。一般來講,在線程數較少,或釋放強度較低的情況下,較為簡潔的 tcmalloc 性能稍勝 jemalloc。在 core 數較多、申請釋放頻繁時,jemalloc 因為鎖競爭強度遠小于 tcmalloc,性能較好。
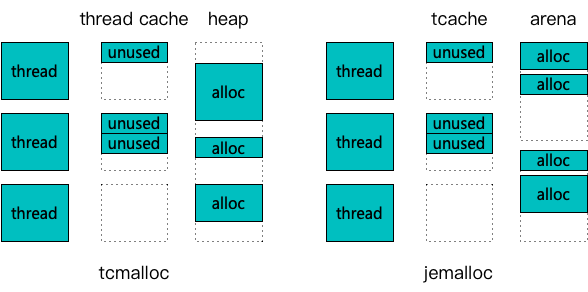
malloc 的核心要素,也就是競爭性和連續性。
線程池技術中,每個線程各司其職,完成一個一個的任務。在 malloc 看來,就是多個長生命周期的線程,隨機的在各個時間節點進行內存申請和內存釋放。基于這樣的場景,首先,盡量分配連續地址空間。其次,多線程下需要考慮分區隔離和減少競爭。
多態內存資源(Polymorphic Memory Resource)
std::pmr::memory_resource 是 C++17 引入的多態內存資源(Polymorphic Memory Resource)的核心概念,屬于 C++ 標準庫中的內存管理機制。它允許開發者使用不同的內存分配策略,以提高內存管理的靈活性和性能。
PMR 將內存的分配與內存管理解耦,memory_resource 負責內存的管理,而具體的內存分配則可以通過不同的資源實現,從而提供更大的靈活性。
使用示例
https://zhuanlan.zhihu.com/p/96089089
內存分配的具體策略,可以有14種之多哦!
C++性能優化轉載
https://www.cnblogs.com/qiangz/p/17085951.html
__builtin_prefetch()數據預讀
為了降低內存讀取的cache-miss延遲,可以通過gcc提供的這個內置函數來預讀數據。當知道數據的內存地址即將要被讀取(在下一個load & store指令到來之前),在數據被處理之前,就可以在代碼中通過指令通知目標,去讀取數據并放到緩存中。
需要注意,軟件預取是有代價的:我們的系統執行了更多的指令,并將更多的數據加載到緩存中,這在某些情況下可能會導致其他方面的性能下降。
for (int i = 0; i < n; i++) {__builtin_prefetch(&array[i + 16], 0, 1); // 預取未來第16項sum += array[i]; // 實際訪問當前項
}
likely和unlikely分支預測
通過先驗概率提示編譯器和CPU,提高分支預測準確率,降低預測錯誤帶來的性能損失。
likely,用于修飾if/else if分支,表示該分支的條件更有可能被滿足。而unlikely與之相反。
#define likely(x) __builtin_expect(!!(x), 1)
#define unlikely(x) __builtin_expect(!!(x), 0)
添加分支預測后,可以增加分支預測正確性,讓更大概率走到的分支對應指令順序排放在后面,可以減少jmp指令的調用,有助于提高性能。
C++語言層面
1. 使用const引用傳遞而非值傳遞
2. for循環中使用引用遍歷
3. 注意隱式轉換帶來的拷貝
隱式轉換,創建了臨時對象。
4. 定義即初始化
一次默認構造函數,一次賦值運算符函數》》》》》》》一次拷貝構造函數
5. 循環中復用臨時變量
6. 盡量使用復合運算符
復合運算符實現的形式會返回自身的引用。
7. 在構造函數中使用初始化列表
構造時即初始化。
8. 使用std::move()避免拷貝
9. 定義移動構造函數、移動賦值運算符函數或右值引用函數
10. 利用好Copy Elision
在C++17以后,編譯期默認啟用RVO(Return Value Optimization),不會對函數返回的局部變量值進行拷貝,直接在函數調用處進行構造,只要滿足以下兩個條件其一:
- URVO(Unnamed Return Value Optimization):函數的各分支都返回同一個類型的匿名變量。
- NRVO(Named Return Value Optimization):函數的各分支都返回同一個非匿名變量。
11. 容器預留空間
12. 容器內原地構造
| 容器類型 | emplace_back() | emplace() | 說明 |
|---|---|---|---|
std::vector | ? 支持 | ? 支持 | 在尾部原地構造元素,效率高 |
std::deque | ? 支持 | ? 支持 | 尾部或頭部插入均支持 |
std::list | ? | ? 支持 | emplace() 可插入任意位置 |
std::forward_list | ? | ? 支持 | 單向鏈表,只能 emplace_after() |
std::array | ? | ? | 固定大小,不支持動態插入 |
std::set / std::multiset | ? | ? 支持 | emplace() 插入有序元素 |
std::map / std::multimap | ? | ? 支持 | 用于插入 pair<key, value> |
std::unordered_set | ? | ? 支持 | 無序容器插入優化 |
std::unordered_map | ? | ? 支持 | 通常 emplace(k, v) |
std::stack / std::queue | ?(包裝容器支持) | ? | 取決于底層容器(如 deque) |
std::priority_queue | ?(包裝容器支持) | ? | 底層容器支持則支持 |
13. 容器存儲指針代替對象拷貝
14. 常量集合定義添加static
15. 減少重復查找和判斷
16. 利用好constexpr編譯期計算
矩陣乘法
優化手段:改進運算順序、SIMD、循環展開(減少循環控制(如跳轉、比較)開銷,暴露更多指令重排空間)、循環分塊(A0 和 B0 加載進 cache、等 C0 運算完,再寫回內存,避免 cache line 被反復換入換出)、多線程
改變運算順序的區別:https://blog.csdn.net/LxXlc468hW35lZn5/article/details/126912933
矩陣乘法優化過程(DGEMM):https://zhuanlan.zhihu.com/p/76347262
高并發
大流量、大規模業務請求的場景,比如春運搶票、電商“雙十一”搶購,秒殺促銷等。
高并發的衡量指標主要有兩個:一是系統吞吐率,比如 QPS(每秒查詢率)、TPS(每秒事務數)、IOPS(每秒磁盤進行的 I/O 次數)。另外一個就是時延,也就是從發出 Reques 到收到 Response 的時間間隔。一般而言,用戶體驗良好的請求、響應系統,時延應該控制在 250 毫秒以內。
高并發的設計思路
垂直方向:提升單機能力
最大化單臺服務器的性能,主要有兩個手段:一是提升硬件能力,比如采用核數更多、主頻更高的服務器,提升網絡帶寬,擴大存儲空間;二是軟件性能優化,盡可能榨干 CPU 的每一個 Tick。
水平方向:分布式集群
為了降低分布式軟件系統的復雜性,一般會用到“架構分層和服務拆分”,通過分層做“隔離”,通過微服務實現“解耦”,這樣做的一個主要目的就是為了方便擴容。然而一味地加機器擴容有時也會帶來額外的問題,比如系統的復雜性增加、垂直方向的能力受限等。
高并發的關鍵技術
層次劃分(垂直方向) + 功能劃分(水平方向)
負載均衡
| 方式 | 描述 | 優缺點 |
|---|---|---|
| DNS 負載均衡 | 根據域名返回多個 IP,客戶端隨機或就近訪問 | 簡單、但受限于緩存更新速度慢 |
| 硬件負載均衡 | 使用專業設備(如 F5)分發請求 | 性能強、成本高 |
| 軟件負載均衡 | NGINX、LVS 分發請求 | 成本低、靈活、易部署 |
數據庫層面:分庫分表 + 讀寫分離
| 技術 | What(做什么) | Why(為什么) | How(怎么做) |
|---|---|---|---|
| 分庫分表 | 拆分成多個數據庫/數據表 | 減輕單庫單表壓力 | 按用戶 ID、時間等進行 hash 或范圍劃分 |
| 讀寫分離 | 讀請求走從庫,寫請求走主庫 | 提升讀并發能力 | MySQL 主從復制 + 應用層路由 |
讀多寫少:緩存
| 類型 | 應用場景 | 實現方式 | 案例 |
|---|---|---|---|
| 本地緩存 | 單節點、高頻訪問 | Guava Cache, Caffeine | 用戶最近訪問記錄 |
| 分布式緩存 | 多節點共享數據 | Redis, Memcached | 商品詳情頁、排行榜、熱點文章等 |
| 緩存策略 | 控制數據生命周期 | LRU、TTL、雙寫一致性、Cache Aside | 讀寫流程設計應考慮緩存一致性問題 |
消息中間件(Why:系統間解耦 & 異步)
| 作用 | 舉例 | 常用中間件 |
|---|---|---|
| 削峰填谷 | 秒殺場景中先放入 MQ 排隊 | Kafka, RabbitMQ |
| 解耦微服務 | 用戶注冊后觸發多個動作 | 用戶注冊 → MQ → 發送郵件、積分服務等 |
| 重試機制 | 避免失敗操作立即失敗 | 消息可設置重試策略 |
流控:限制流量/控制優先級,避免雪崩效應
| 策略 | 描述 |
|---|---|
| Reject 策略 | 達上限立即拒絕 |
| Queue 策略 | 達上限排隊 |
| Token Bucket | 限流 + 平滑 |
| Leaky Bucket | 勻速出水 |
高并發實踐
| 維度 | Why(目的) | What(做法) | How(常用手段) |
|---|---|---|---|
| 1. 單機性能優化 | 榨干單臺服務器性能 | 代碼優化 + 系統優化 | 內存優化、鎖優化、零拷貝、epoll、線程池 |
| 2. 架構設計優化 | 讓系統可以水平擴展 | 分層、拆分、解耦、異步 | 微服務、消息隊列、限流、負載均衡、緩存、CDN |
| 3. 流量治理 | 控制壓力、防止系統被打爆 | 限流、降級、熔斷 | Sentinel、Hystrix、RateLimiter、令牌桶、漏桶算法 |
| 4. 數據層優化 | 避免 DB 成為性能瓶頸 | 分庫分表、讀寫分離、緩存、索引 | Redis 緩存、MySQL 主從、ElasticSearch、異步寫入 |
實踐經驗
1?? 接口層:網關 + 限流 + 緩存
| 實踐點 | 說明 |
|---|---|
| API網關限流 | 防止惡意訪問或突發流量壓垮后端,可設 QPS 閾值 |
| 靜態內容走 CDN | 圖片/視頻/JS 等資源,不占服務帶寬和 CPU |
| GET 接口緩存 | 查詢接口緩存結果,避免頻繁訪問數據庫 |
| 異步響應 | 返回結果慢的操作(如導出/視頻轉碼)用異步任務隊列 |
2?? 服務層:拆分 + 異步 + 降級 + 熔斷
| 實踐點 | 說明 |
|---|---|
| 微服務拆分 | 把大服務拆成小服務,按功能部署,避免“大而全”模塊互相拖慢 |
| MQ 解耦 + 削峰 | 秒殺、下單等請求先入隊列,后端慢慢消費,防止瞬時打掛數據庫 |
| 降級處理 | 非核心功能(如推薦/廣告)出錯時不影響主業務(如下單) |
| 熔斷保護 | 某服務異常時斷開調用鏈,防止雪崩擴散 |
3?? 數據層:緩存 + 索引 + 分表分庫
| 實踐點 | 說明 |
|---|---|
| 熱數據進緩存 | 用 Redis 緩存高頻訪問的數據(比如用戶 Token / 商品詳情) |
| 索引優化 | 查詢慢的 SQL 通常缺少合適索引,尤其是多表 JOIN / 排序字段 |
| 分表分庫 | 單表數據量大于千萬時影響性能,可根據用戶ID或時間做分片 |
| 讀寫分離 | 寫入主庫、讀取從庫,提高讀吞吐能力 |
4?? 系統層:連接池 + 多線程 + IO模型
| 實踐點 | 說明 |
|---|---|
| 數據庫連接池 | 用如 HikariCP、Druid 等連接池,避免頻繁建立/關閉連接 |
| 線程池復用 | 用線程池處理請求,避免頻繁創建線程 |
| IO 多路復用 | 使用 epoll / select 提高并發連接處理能力(如高性能 Web Server) |
5?? 其他高并發常用技巧
| 技巧名稱 | 作用 |
|---|---|
| 冪等性設計 | 保證請求重復不會重復處理(如重復下單) |
| 雪崩保護 | 關鍵緩存設置過期時間隨機 + 本地緩存備份 |
| 限流算法 | 令牌桶、漏桶算法,控制每秒請求量不超過閾值 |
| 熱點預熱 | 大促前將熱門商品、廣告位數據預加載到緩存中 |
| 多線程 + IO模型 |
| 實踐點 | 說明 |
|---|---|
| 數據庫連接池 | 用如 HikariCP、Druid 等連接池,避免頻繁建立/關閉連接 |
| 線程池復用 | 用線程池處理請求,避免頻繁創建線程 |
| IO 多路復用 | 使用 epoll / select 提高并發連接處理能力(如高性能 Web Server) |
5?? 其他高并發常用技巧
| 技巧名稱 | 作用 |
|---|---|
| 冪等性設計 | 保證請求重復不會重復處理(如重復下單) |
| 雪崩保護 | 關鍵緩存設置過期時間隨機 + 本地緩存備份 |
| 限流算法 | 令牌桶、漏桶算法,控制每秒請求量不超過閾值 |
| 熱點預熱 | 大促前將熱門商品、廣告位數據預加載到緩存中 |






)






)
)




