TitanFuzz 論文
深度學習庫(TensorFlow 和 Pytorch)中的 bug 對下游任務系統是重要的,保障安全性和有效性。在深度學習(DL)庫的模糊測試領域,直接生成滿足輸入語言(例如 Python )語法/語義和張量計算的DL API 輸入/形狀約束的深度學習程序具有挑戰性。此外,深度學習 API 可能包含復雜的輸入條件約束,難以在沒有人工干預的情況下生成符合條件的輸入用例。TitanFuzz 是首個直接利用大語言模型(LLM)生成測試程序來模糊測試DL庫的方法。
API 級模糊測試:僅針對孤立 API 進行測試,無法暴露由 API 調用鏈引發的缺陷;模糊級模糊測試:缺乏多樣化 API 序列,如 Muffin 需要手動注釋考慮的深度學習 API 的輸入/輸出限制,并使用額外的 reshaping 操作保證有效連接,以及無法生成任意代碼。

- log 函數應該為負數產生 NaN,CPU 調用 matrix_exp 時應該包含 NaN 值,但 GPU 調用時不輸出任何 NaN 值。
- Bug:在 CPU 上計算時分正負號,導致分別出現正無窮和負無窮。正常:在 GPU 上計算時不分正負號,1/0 為正無窮。
| 傳統 | LLM-based | |
|---|---|---|
| 基于規則/隨機變異 | 基于分布概率生成 | 規則->統計建模 |
| 結構化輸入 | 基于語義理解 | 語法->語義 |
| 人工設計策略 | Prompt | |
| 顯式定義張量/類型約束 | 隱式學習 API 約束 | 標注->推理 |
| 單 API | 任意組合 | 代碼覆蓋率 |
LLM 為差分測試提供語義合理、適配不同后端的測試輸入。

- 提供 step-by-step 的 prompt engineering,調用 codex 生成直接借用目標 API 的代碼片段。
- 使用進化模糊算法,生成新的代碼。
- 差分測試,在不同后端上執行,識別潛在錯誤。

Prompt 中包含了目標庫和目標 API 定義(爬蟲從官方文檔爬取)并設計了分布指令,按照 Task 的順序執行。原始種子程序從 Codex 中采樣得到。

通過 Codex 生成初始種子,用 InCoder 去預測 mask 的代碼片段以保持語義的連貫性,其中代碼片段通過 Multi-Armed Bandit(MAB) 算法動態學習操作符優先級策略,并用 < s p a n > <span> <span> 覆蓋,采樣策略選擇了 Top-N;
算子:
- 參數(augment):選擇目標 API 中的參數 Mask,可以是已寫的,也可以是未寫的;
- 前綴(prefix):在目標 API 調用前插入代碼段,并 Mask 掉一部分前綴;
- 后綴(suffix):在目標 API 調用后插入代碼段,并 Mask 掉一部分后綴;
- 方法(method):Mask API 調用,使用新的 API;
MAB:
f ( x ; α , β ) = Γ ( α + β ) Γ ( α ) Γ ( β ) x α ? 1 ( 1 ? x ) β ? 1 f(x;\alpha,\beta)=\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}x^{\alpha-1}(1-x)^{\beta-1} f(x;α,β)=Γ(α)Γ(β)Γ(α+β)?xα?1(1?x)β?1
- 初始化每個變異操作符 𝑚 的成功次數 𝑚.S 和失敗次數 𝑚.F 為1,即每個操作 𝑚 的先驗分布被假設為 Beta(1, 1),即均勻分布。
- 在觀察到 𝑚.S-1 次成功和 𝑚.F-1 次失敗后,更新操作 𝑚 的后驗分布為 Beta(𝑚.S, 𝑚.F)。
- 為了選擇一個操作(arm),從每個操作的后驗分布中抽取一個樣本 𝜃𝑚,然后選擇具有最大樣本值的操作(表示它具有最高的成功率概率)。
- 在使用 LLMs 生成代碼后,根據生成的程序的執行狀態,更新所選擇的變異操作的后驗分布。與隨機選擇變異操作相比,這種方法可以幫助識別有助于生成更有效和獨特代碼片段的變異操作。
- 需要注意的是,最佳的變異操作可能因不同的目標API而異,因此為每個針對一個API的演化模糊測試的端到端運行開始一個單獨的MAB游戲,并重新初始化操作符的先驗分布。
Fitness Score: F i t n e s s F u n c t i o n ( C ) = D + U ? R FitnessFunction(C)=D+U-R FitnessFunction(C)=D+U?R
- 數據流圖深度 (D):衡量代碼片段中數據依賴關系的復雜性。
- 唯一API調用數量 (U):鼓勵使用更多不同的庫API。
- 重復API調用懲罰 ?:減少重復API調用的影響,提高模糊測試的效率。
Differential Testing:
- Wrong Computation:在 CPU 和 GPU 上執行相同代碼,記錄所有中間變量,為了區分真正的錯誤和非關鍵差異,TitanFuzz 使用容差閾值來檢查值是否顯著不同。計算值的差異可能表明庫 API 的不同后端實現或不同 API 之間的交互存在潛在的語義錯誤。
- Crash:在程序執行過程中,監控是否有段錯誤、終止、INTERNAL_ASSERT_FAILED 等異常發生。
實驗
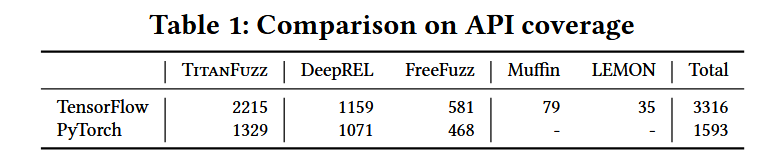
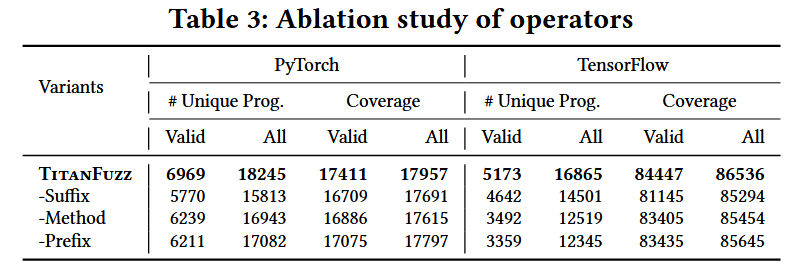
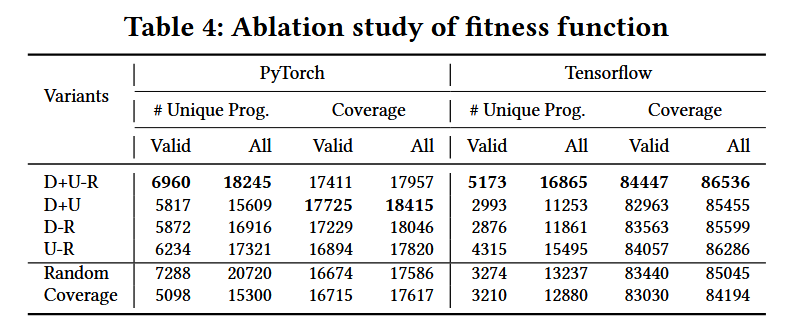
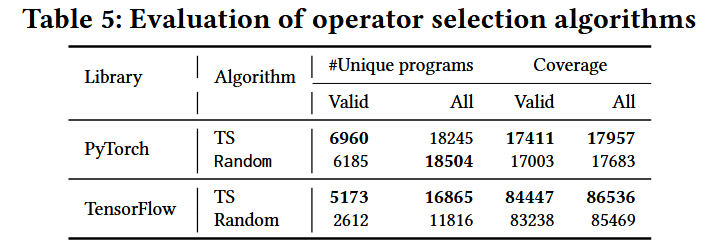
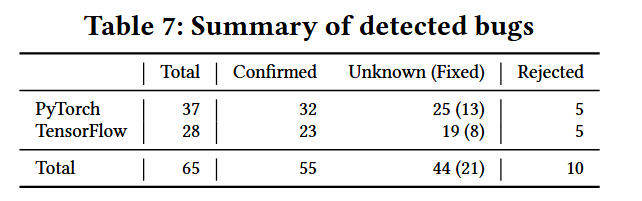
經過廣泛的評估,TitanFuzz在兩個流行的深度學習庫(PyTorch和TensorFlow)上表現出了顯著的改進,包括:
- 增加了庫API的數量和代碼覆蓋率。
- 直接利用現代大型預訓練語言模型進行模糊測試的前景。







)
![[藍橋杯]密碼脫落](http://pic.xiahunao.cn/[藍橋杯]密碼脫落)


)




,用于解決無人機三維路徑規劃問題,Matlab代碼實現)

![MCP:讓AI工具協作變得像聊天一樣簡單 [特殊字符]](http://pic.xiahunao.cn/MCP:讓AI工具協作變得像聊天一樣簡單 [特殊字符])
