Step1X-Edit 論文
當前圖像編輯數據集規模小,質量差,由此構建了如下數據構造管線。

高質量三元組數據(源圖像、編輯指令、目標圖像)。
- 主體添加與移除:使用 Florence-2 對專有數據集標注,然后使用 SAM2 進行分割,再使用 ObjectRemovalAlpha 進行修復。編輯指令結合 Step-1o 和 GPT-4o 生成,然后人工審查有效性。
- 主體替換與背景更改:使用 Florence-2 對專有數據集標注,然后使用 SAM2 進行分割,再使用 Qwen-2.5VL 和 Recognize-Anything Model 識別目標對象和關鍵詞,使用 Flux-Fill 進行內容感知修復。指令由 Step-1o 生成并人工審查。
- 色彩更改與材質修改:在圖像中檢測到對象后,使用 Zeodepth 深度估計,使用帶擴散模型的 ControlNet 生成新圖像。
- 文本修改:使用 PPOCR 識別字符,以及 Step-1o 模型區分文本正確、錯誤區域。同樣生成編輯指令。
- 運動變化:使用 Koala-36M 的視頻,提取幀作為輸入,使用 BiRefNet 和 RAFT 進行前景-背景和光流估計,再用 GPT-4o 標記幀間運動變化作為編輯指令。
- 人像編輯與美化:對于動畫風格和真實圖像,先提取邊緣,再利用 ControlNet 進行風格遷移。
- 采用上下文、雙語標注。

之前的模態融合,FLUX-Fill 使用通道連接,但面對圖像編輯指令不夠靈活(難以處理局部調整、缺乏語義對齊、難以處理復雜指令);SeedEdit 引入額外的因果自注意力,但會犧牲圖像細粒度;DreamEngine 利用 Qwen 對圖像和文本模態對齊,建立了共享表征空間,難以完全捕捉圖像細粒度(更關注語義對齊)。
Step1X-Edit:
- 輸入的編輯指令和參考圖像首先通過MLLM進行處理。為了隔離和強調與編輯任務相關的語義元素,選擇性地丟棄與系統前綴相關的標記嵌入,僅保留與編輯信息直接對齊的嵌入。
- 提取的嵌入被輸入到輕量級的連接器模塊,重構為更緊湊的多模態特征表示,然后作為輸入傳遞給下游的DiT網絡。采用標記連接(token concatenation)的方式,平衡對編輯指令的響應性與對細粒度圖像細節的保留。這種方法比通道連接或額外的自注意力機制更有效。
- 在訓練過程中,聯合優化連接器模塊和下游的DiT,僅使用擴散損失進行訓練,確保穩定訓練而不依賴掩碼損失技巧。(采用 Rectified Flow 方式)
- 并且對 VLLM 輸出的有效嵌入計算均值,將其作為 DiT 的引導。
實驗
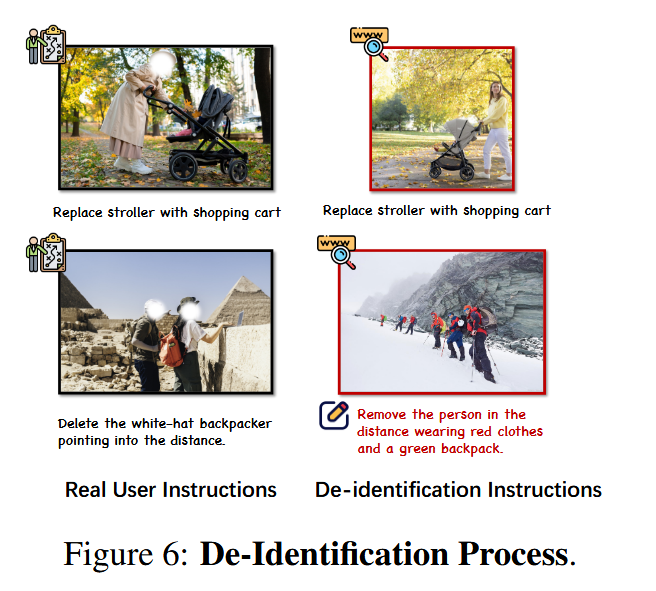
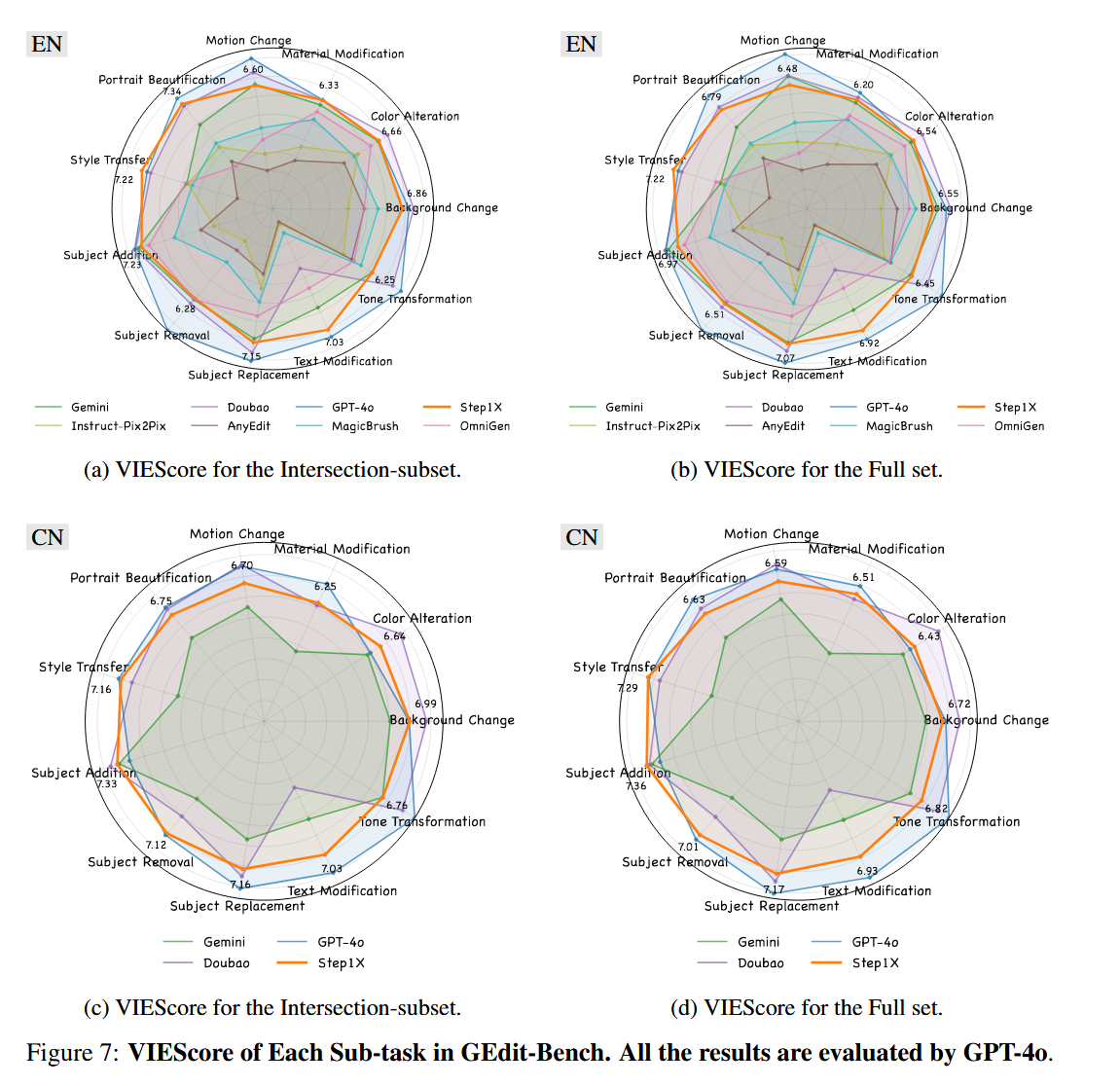
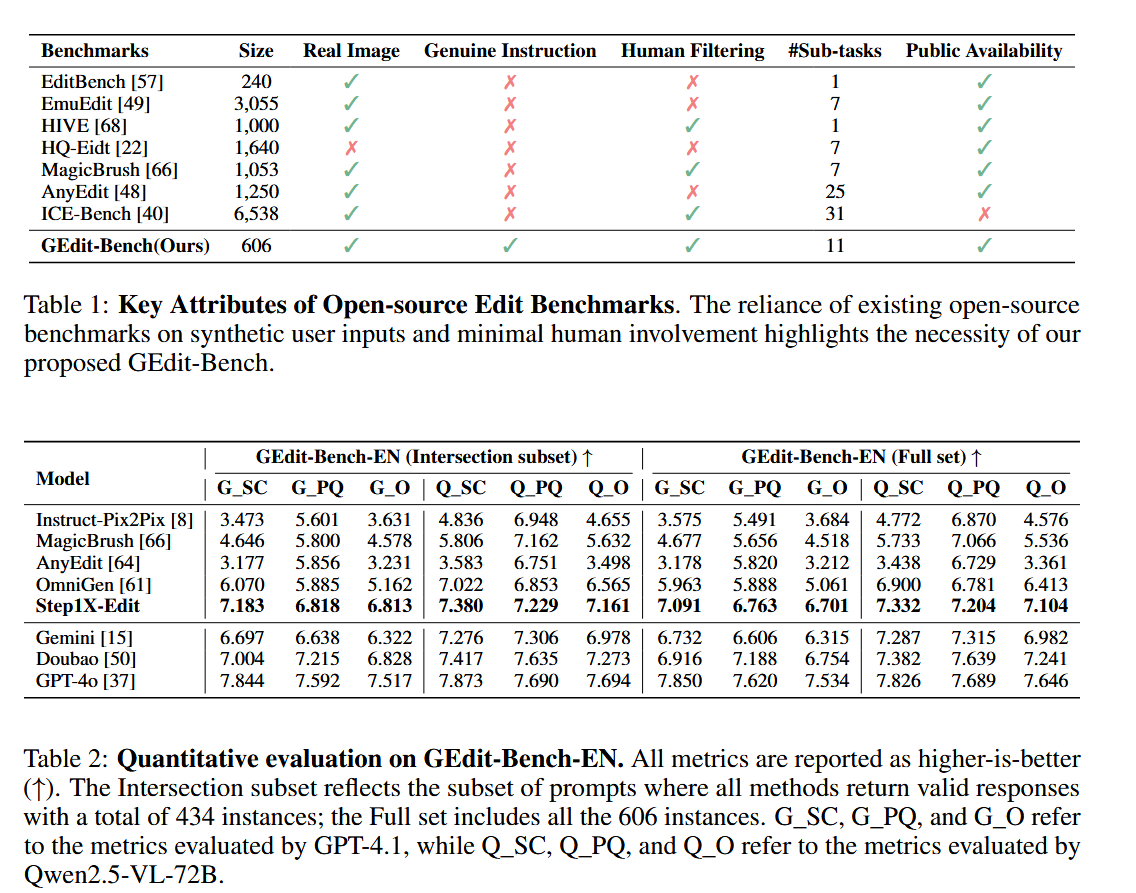
團隊從互聯網上收集了超過1K的用戶編輯實例,構建了GEdit-Bench,包含606個真實用戶編輯指令,覆蓋11類任務。為確保隱私,所有圖像經過去標識化處理。與其他基準(如EditBench和MagicBrush)相比,GEdit-Bench更貼近實際需求。
疑問:本文僅在自己構建的測試集上評估,并缺乏消融實驗驗證架構設計。

















 v1.29.6 中文綠色版)

