TL;DR
- 2024 年 Nvidia + MIT 提出的線性Transformer 方法 Gated DeltaNet,融合了自適應內存控制的門控機制(gating)和用于精確內存修改的delta更新規則(delta update rule),在多個基準測試中始終超越了現有的模型,如 Mamba2 和 DeltaNet。
Paper name
GATED DELTA NETWORKS : IMPROVING MAMBA 2 WITH DELTA RULE
Paper Reading Note
Paper URL:
- https://arxiv.org/pdf/2412.06464
Code URL:
- https://github.com/NVlabs/GatedDeltaNet
Introduction
背景
- 線性Transformer作為標準Transformer的高效替代方案已受到關注,但其在檢索任務和長上下文任務中的表現一直有限
- 為解決這些局限性,近期研究探索了兩種不同的機制:用于自適應內存控制的門控機制(gating)和用于精確內存修改的delta更新規則(delta update rule)。本文發現這兩種機制是互補的——門控機制能夠實現快速內存清除,而 delta 規則則有助于有針對性的更新。
本文方案
- 提出了 Gated DeltaNet(gated delta rule),并開發了一種針對現代硬件優化的并行訓練算法
- 提出的架構 Gated DeltaNet 在多個基準測試中始終超越了現有的模型,如 Mamba2 和 DeltaNet,涵蓋語言建模、常識推理、上下文檢索、長度外推和長上下文理解等任務。
- 進一步通過開發混合架構來提升性能,將 Gated DeltaNet 層與滑動窗口注意力機制或 Mamba2 層相結合,在提高訓練效率的同時實現了更優的任務表現
Methods
回顧
- linear attention 的一般形式
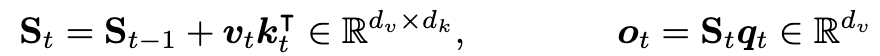
- mamba2 增加了一個 data-dependent decay 項
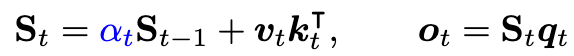
- delta net rule:動態擦除與當前輸入 kt 想關聯的 vold,然后寫入一個新值 vnew,后者是當前輸入值和舊值的線性組合
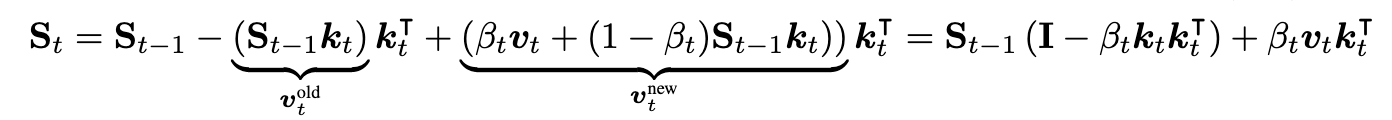
Gated Delta Net
- 本文提出的 Gated Delta Net
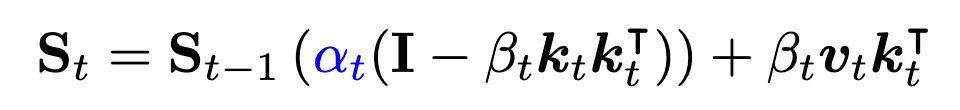
數據依賴的門控項 α t ∈ ( 0 , 1 ) \alpha_{t} \in (0, 1) αt?∈(0,1) 控制狀態的衰減
該公式統一了門控機制和 Delta 規則的優點,使模型能夠通過選擇性遺忘實現動態內存管理,在過濾無關信息方面具有潛在優勢:
- 門控項 α t \alpha_{t} αt? 實現自適應內存管理;
- Delta 更新結構有助于有效的鍵值關聯學習
單針在 haystack 中(S-NIAH)驗證
在 RULER(Hsieh 等,2024)提出的 Single Needle-In-A-Haystack(S-NIAH) 基準套件上進行案例分析。在這個任務中,一個鍵值對作為“針”隱藏在上下文(即 haystack)中,模型需要在給定鍵的情況下回憶出對應的值。

衰減機制損害記憶保持能力
在最簡單的 S-NIAH-1 設置中,使用重復的合成上下文,模型僅需記憶少量信息,測試的是長期記憶保留能力。
- DeltaNet 在所有序列長度下都接近完美表現;
- Mamba2 在超過 2K 長度時性能顯著下降,因為其衰減歷史信息過快;
- Gated DeltaNet 的性能下降較輕,得益于 Delta 規則的記憶保留能力。
門控機制有助于過濾無關信息
在 S-NIAH-2/3 使用真實世界文章作為上下文的任務中,模型需要存儲所有可能相關的信息,測試的是高效的內存管理能力。
- 固定狀態大小下,缺乏清除機制會導致“內存沖突”——信息疊加、難以區分;
- DeltaNet 在長序列中性能大幅下降,因其內存清除能力不足;
- Mamba2 和 Gated DeltaNet 則通過門控機制過濾無關信息,維持了更好的性能。
Delta 規則增強記憶能力
在 S-NIAH-3 中,值從數字變為 UUID,測試的是復雜模式的記憶能力。
- Mamba2 性能迅速下降;
- Gated DeltaNet 表現更優,驗證了 Delta 規則確實具備更強的記憶能力。
Gated DeltaNet 與混合模型設計
基本的 Gated DeltaNet 架構沿用 Llama 的宏觀架構,堆疊 token mixer 層和 SwiGLU MLP 層,但將自注意力替換為基于 Gated Delta 規則 的 token mixing 方法。
-
查詢、鍵和值 {q,k,v} 通過線性投影、短卷積和 SiLU 激活生成,且 q,k 經過 L2 歸一化以提升訓練穩定性。參數 α,β 僅通過線性投影生成。輸出經過歸一化和門控處理后再應用輸出投影
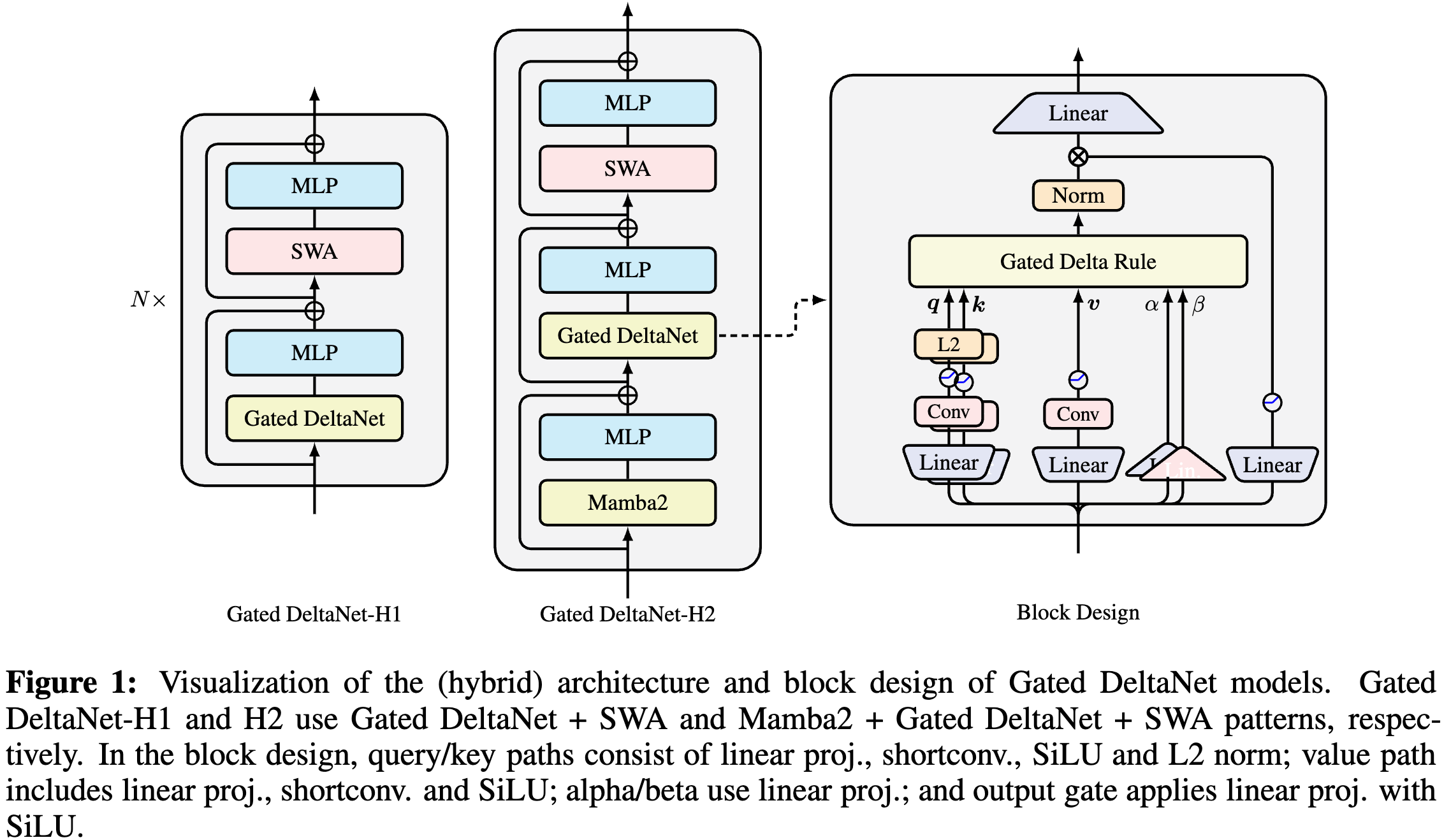
-
線性 Transformer 在建模局部變化和比較方面存在局限,固定的狀態大小也使得檢索任務困難。
- 將線性循環層與滑動窗口注意力(Sliding Window Attention, SWA)結合,構建了 GatedDeltaNet-H1
- 進一步堆疊 Mamba2、GatedDeltaNet 和 SWA,構建了 GatedDeltaNet-H2
Experiments
實驗配置
- 為了保證公平比較,所有模型均在相同條件下訓練,參數量均為 13 億(1.3B),訓練數據為從 FineWeb-Edu 數據集 (Penedo 等,2024)中采樣的 1000 億(100B)個 token
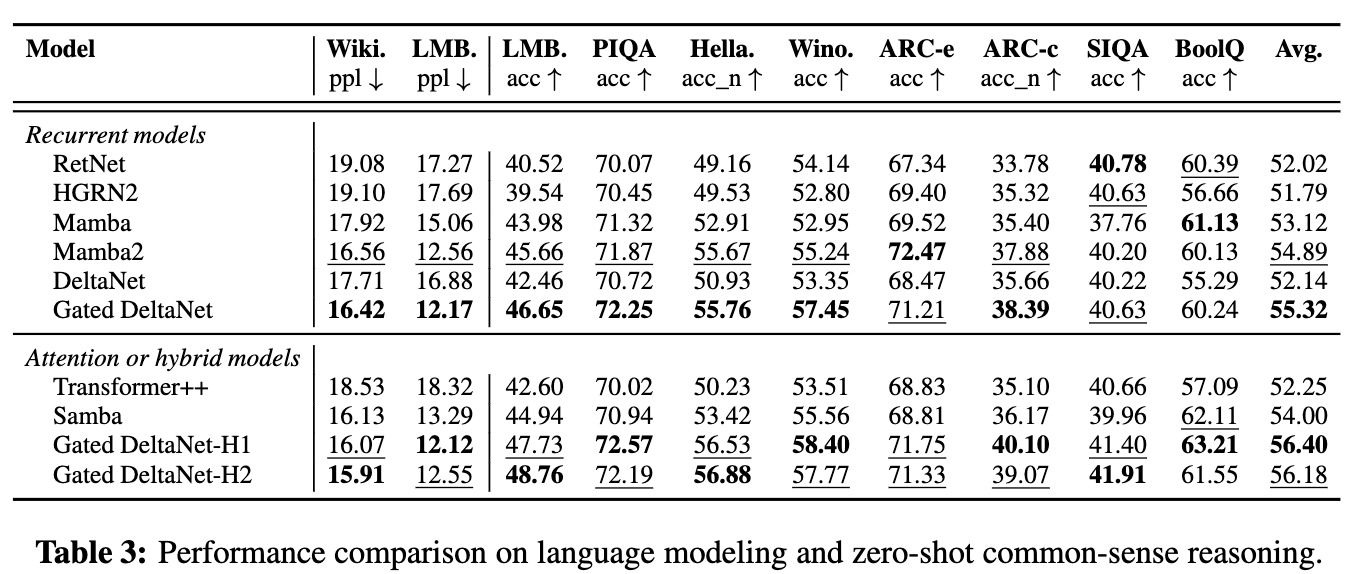
常識推理
- Gated DeltaNet 在兩個參數規模上均持續優于其他線性模型
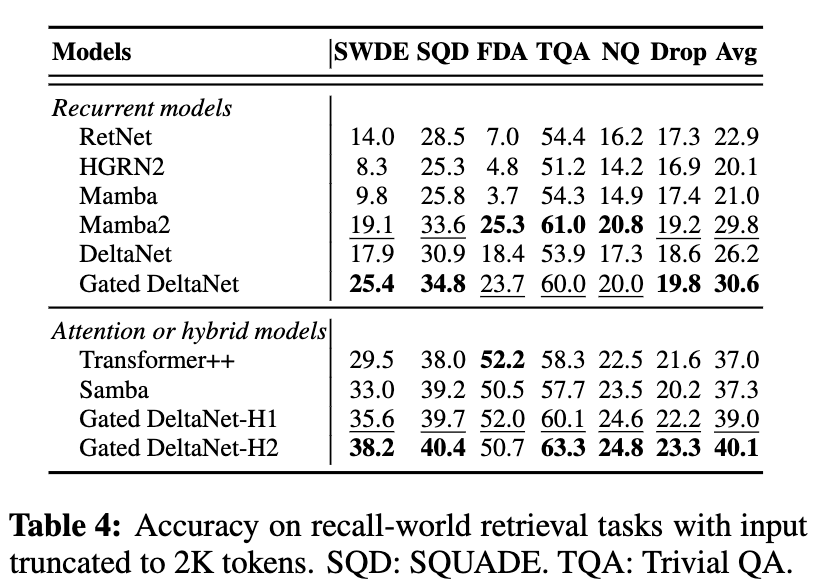
真實世界數據中的上下文檢索(In-Context Retrieval on Real-World Data)
- 與標準 Transformer 相比,純線性循環模型存在顯著性能差距;而將線性循環機制與注意力結合的混合模型在檢索任務中優于純注意力模型。
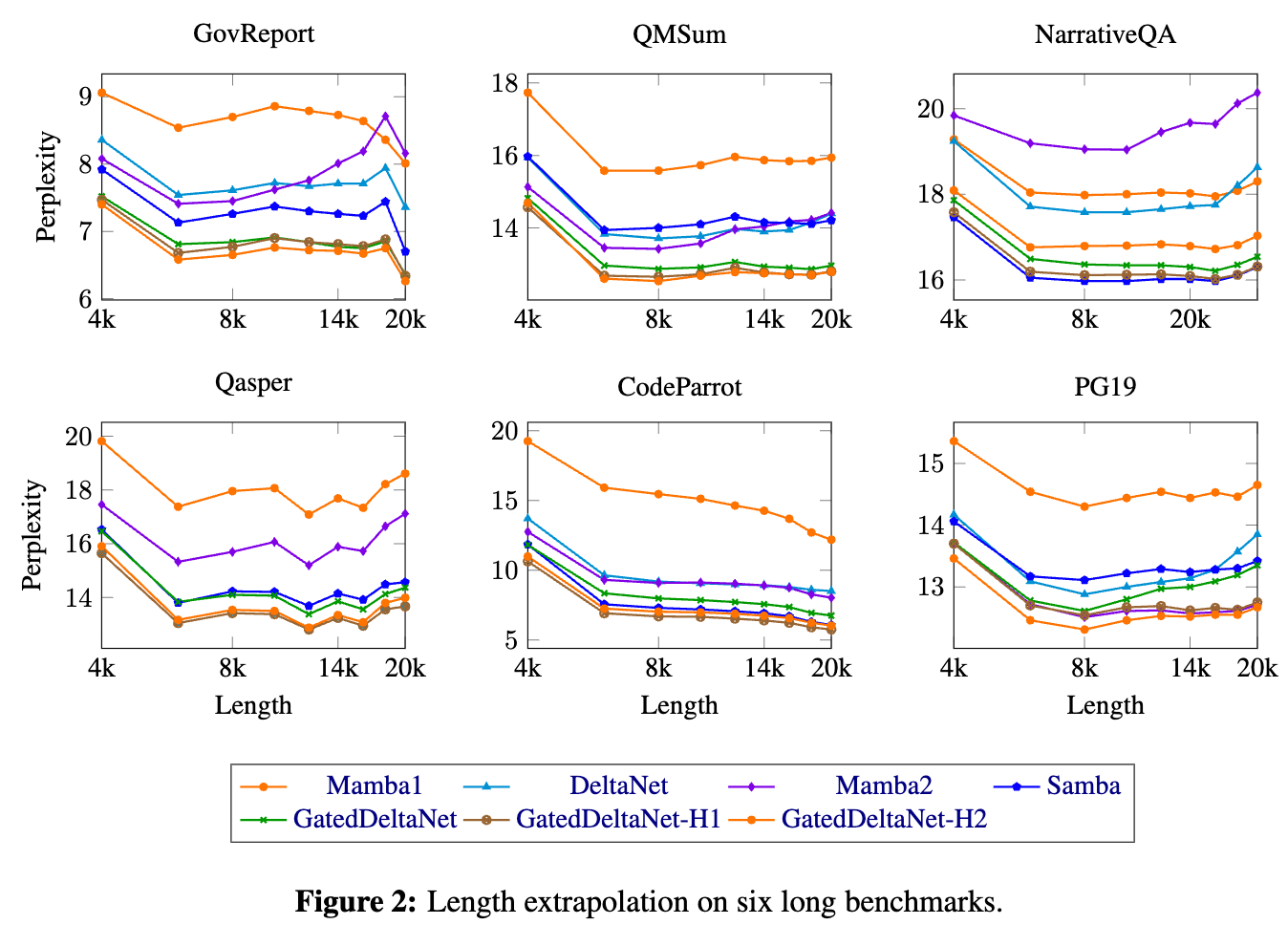
長序列上的長度外推能力(Length Extrapolation on Long Sequences)
- 在六個長上下文基準任務中評估了模型對長達 20K token 序列的外推能力。在所有 RNN 模型中,Gated DeltaNet 實現了最低的整體困惑度。
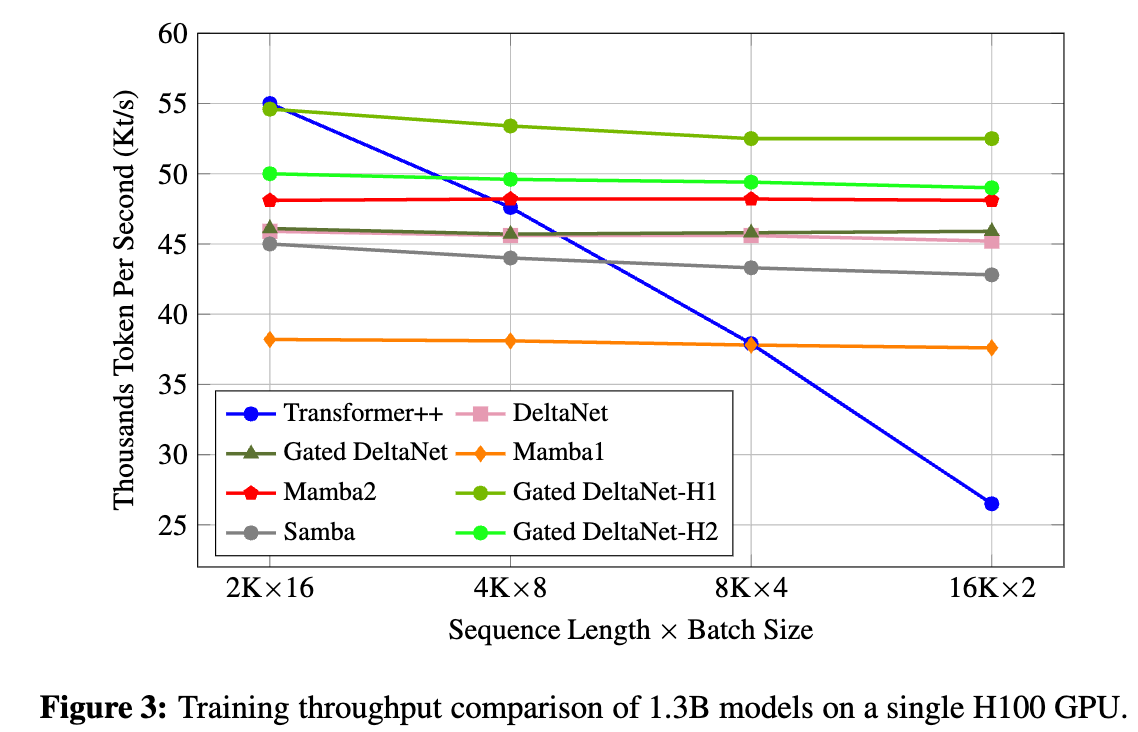
長上下文理解(Long Context Understanding)
- 基于 LongBench 測試,在線性循環模型中,Gated DeltaNet 展現出穩定優勢,特別是在單文檔問答(single-doc QA)、少量樣本上下文學習(few-shot in-context learning)和代碼任務(Code)中,分別體現了其在信息檢索、上下文學習和狀態追蹤方面的優越能力。
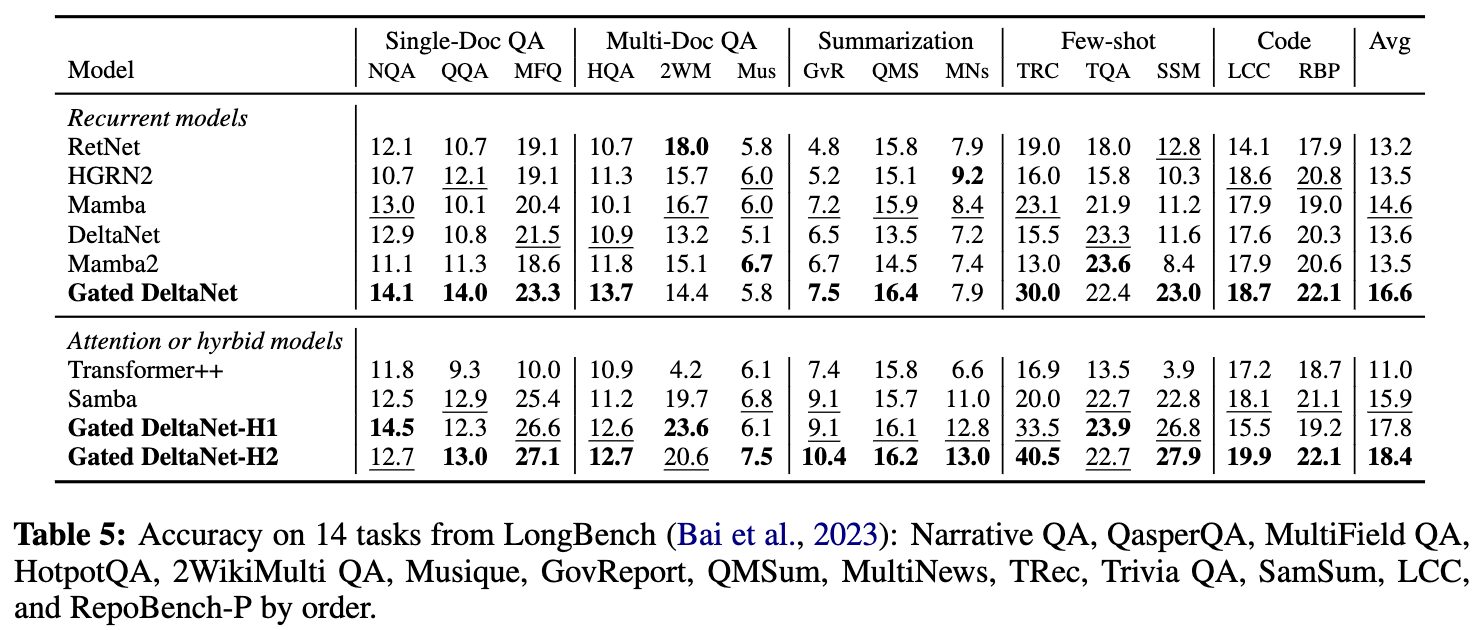
吞吐量對比(Throughput Comparison)
- 圖3展示了不同模型的訓練吞吐量對比。
- 相比原始 Delta 規則,提出的門控 Delta 規則僅引入了輕微的額外開銷,Gated DeltaNet 與 DeltaNet 的吞吐量基本相當。由于采用了更具表達力的狀態轉移矩陣,它們的訓練速度略慢于 Mamba2(約2–3K token/秒)。
- 滑動窗口注意力(SWA)能提速,Gated DeltaNet-H1 和 -H2 優于 Gated DeltaNet。
Conclusion
- 提出了 Gated DeltaNet ,相比 Mamba2 具備更強的鍵值關聯學習能力,相比 DeltaNet 具備更靈活的內存清除機制

)




處理)




)

)


)


