前言:
今天結合黑馬點評這個項目,講下有關Redis緩存的一些內容,例如緩存更新策略,緩存穿透,雪崩和擊穿等。
今日所學:
- 什么是緩存
- 緩存更新策略
- 緩存穿透
- 緩存雪崩
- 緩存擊穿
- 緩存工具封存
目錄
1.什么是緩存
1.1 概念
1.2 Java項目中添加緩存
2.緩存更新策略
2.1 介紹
2.2 分類
2.3 數據不一致性解決方案
3. 緩存穿透
3.1 介紹
3.2 代碼實現
3.3 總結
4. 緩存雪崩
5. 緩存擊穿
5.1 介紹
5.2 互斥鎖解決
5.2.1 具體項目操作思路
5.3 邏輯過期解決
5.3.1 具體項目操作思路
5.4 總結
6. 封裝Redis工具類
需求分析:
6.1 方法1實現
6.2 方法2實現
6.3 方法3實現
6.4 方法4實現
1.什么是緩存
1.1 概念
緩存就是數據交換的緩沖區(稱作Cache [ k?? ] ),是存貯數據的臨時地方,一般讀寫性能較高。
緩存的優點:
- 降低后端負載
- 提高讀寫效率,降低響應時間
緩存的缺點:
- 數據一致性成本
- 代碼維護成本
- 運維成本
如何使用緩存:
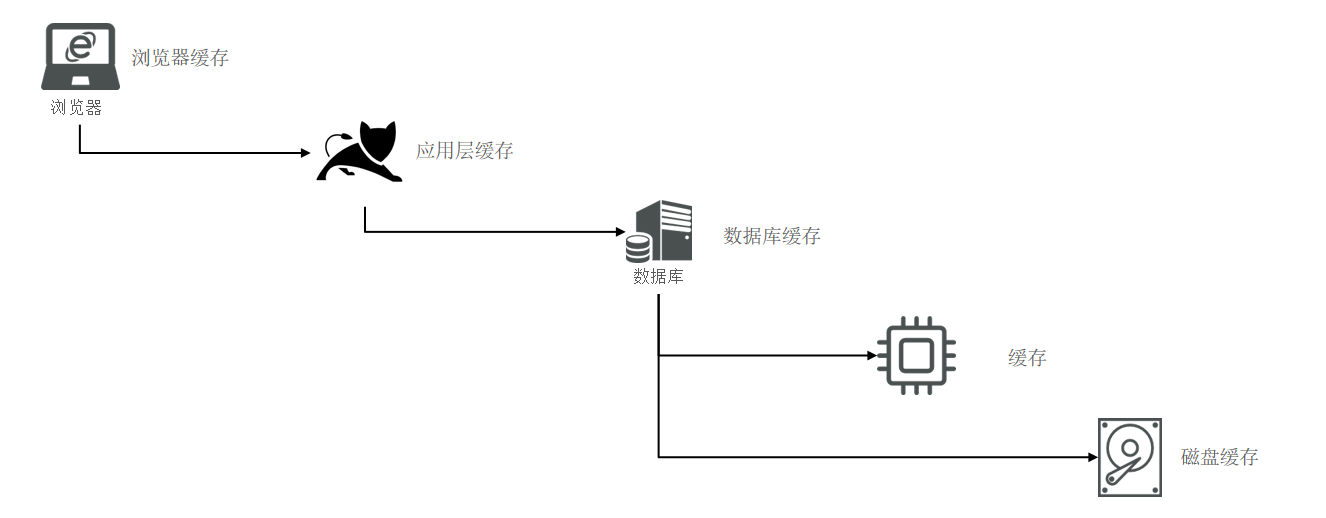
實際開發中,會構筑多級緩存來使系統運行速度進一步提升,例如:本地緩存與redis中的緩存并發使用。
- 瀏覽器緩存:主要是存在于瀏覽器端的緩存
- 應用層緩存:可以分為tomcat本地緩存,比如之前提到的map,或者是使用redis作為緩存
- 數據庫緩存:在數據庫中有一片空間是 buffer pool,增改查數據都會先加載到mysql的緩存中
- CPU緩存:當代計算機最大的問題是 cpu性能提升了,但內存讀寫速度沒有跟上,所以為了適應當下的情況,增加了cpu的L1,L2,L3級的緩存
1.2 Java項目中添加緩存
緩存作用模型:
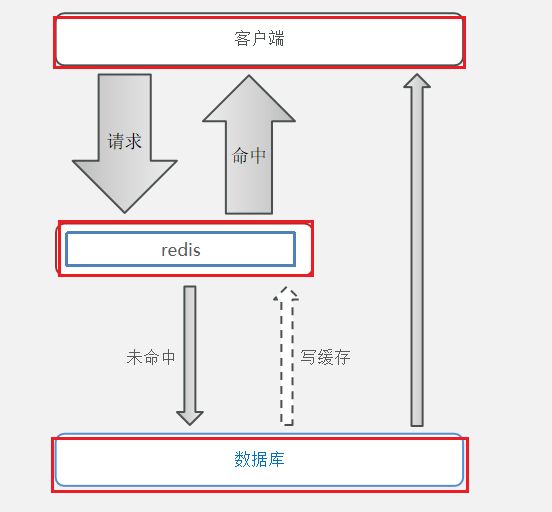
客戶端也請求redis,如果命中,直接返回結果。如果沒有命中,才去查詢數據庫。并把數據庫返回的結果寫入到redis中,以方便下次查詢
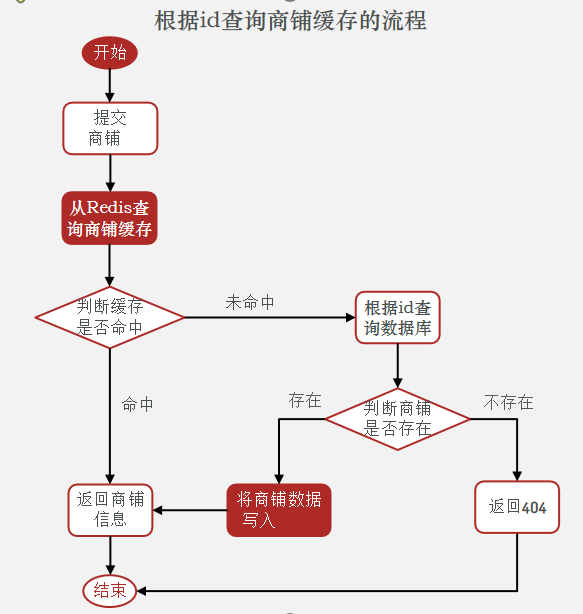
具體項目邏輯:
2.緩存更新策略
2.1 介紹
緩存更新是redis為了節約內存而設計出來的一個東西,主要是因為內存數據寶貴,當我們向redis插入太多數據,此時就可能會導致緩存中的數據過多,所以redis會對部分數據進行更新,或者把他叫為淘汰更合適。
2.2 分類
緩存更新策略分為以下幾類:
-
內存淘汰:redis自動進行,當redis內存達到咱們設定的max-memery的時候,會自動觸發淘汰機制,淘汰掉一些不重要的數據(可以自己設置策略方式)
-
超時剔除:當我們給redis設置了過期時間ttl之后,redis會將超時的數據進行刪除,方便咱們繼續使用緩存
-
主動更新:我們可以手動調用方法把緩存刪掉,通常用于解決緩存和數據庫不一致問題
| 內存淘汰 | 超時剔除 | 主動更新 | |
| 一致性 | 差 | 一般 | 好 |
| 維護成本 | 無 | 低 | 高 |
可以看到,數據一致性越好,維護成本就越高,那么我們該怎么去決定使用哪個緩存更新策略呢?
這里我們分為低一致性需求和高一致性需求:
- 低一致性需求:使用內存淘汰機制。例如店鋪類型的查詢緩存
- 高一致性需求:主動更新,并以超時剔除作為兜底方案。例如店鋪詳情查詢的緩存
2.3 數據不一致性解決方案
什么是數據不一致性?
是由于我們的緩存的數據源來自于數據庫,而數據庫的數據是會發生變化的,因此,如果當數據庫中數據發生變化,而緩存卻沒有同步,此時就會有一致性問題存在。
有什么后果?
用戶使用緩存中的過時數據,就會產生類似多線程數據安全問題,從而影響業務,產品口碑等
怎么解決呢(尤其針對高一致性需求業務):
-
Cache Aside Pattern 人工編碼方式:緩存調用者在更新完數據庫后再去更新緩存,也稱之為雙寫方案
-
Read/Write Through Pattern : 由系統本身完成,數據庫與緩存的問題交由系統本身去處理
-
Write Behind Caching Pattern :調用者只操作緩存,其他線程去異步處理數據庫,實現最終一致
其中我們采用第一種人工編碼方式,即在更新完數據庫后手動更新緩存。
那么問題又來了:
第一.當數據庫數據有變更時,我們是更新緩存數據呢還是直接刪除相應緩存呢?這時候我們不得不考慮,如果我們在一段時間頻繁的進行了更新,但是中間并沒有用戶進行訪問,那么這個更新動作實際上只有最后一次生效,中間的更新動作意義并不大,以此我們可以把緩存刪除,等待再次查詢時,將緩存中的數據加載出來
第二.如何保證緩存和數據庫操作同時成功或者失敗?這里在單體系統,我們將緩存與數據庫操作放在一個事務。在分布式系統,利用TCC等分布式事務方案。
第三.我們是先操作緩存還是先操作數據庫?這里我們考慮兩種方案。
- 先刪除緩存,再操作數據庫
- 先操作數據庫,再刪除緩存
該選擇哪個,我們只要考慮一點就行了:更新所耗費的時間要大于查詢時間
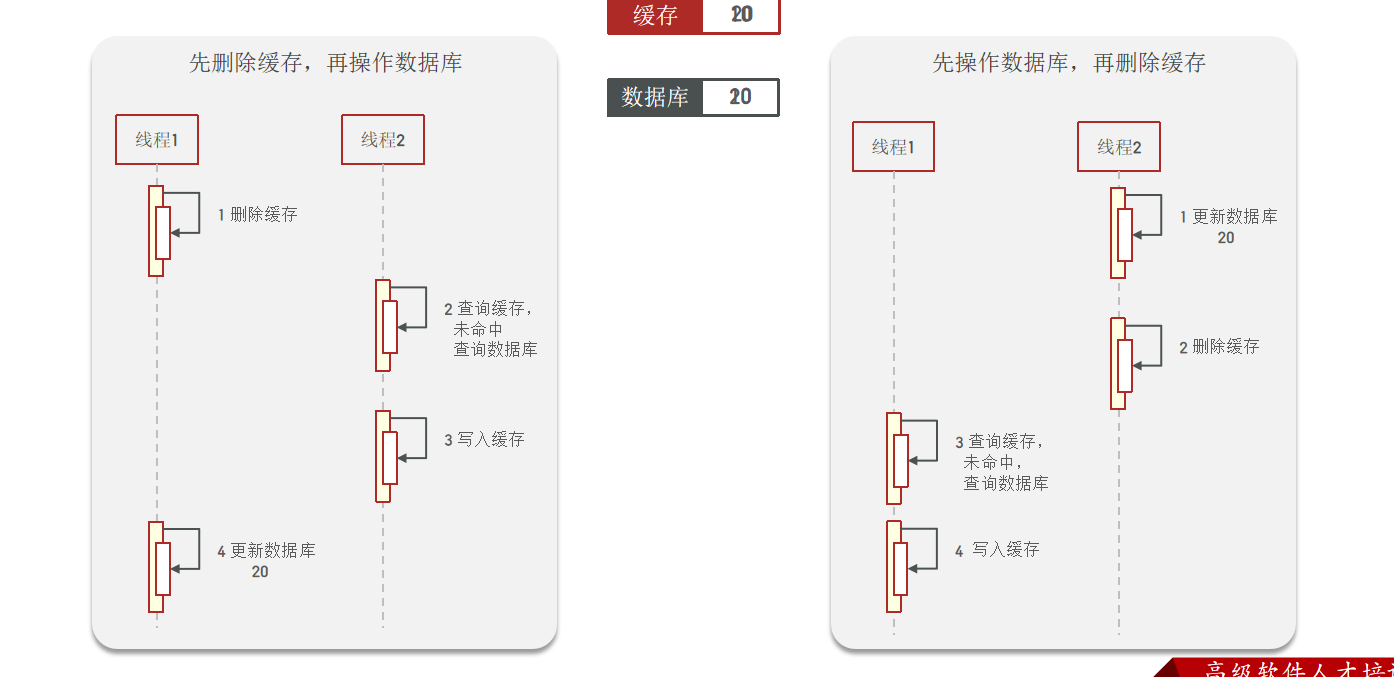
如果我們先刪除緩存,在更新數據庫。那么在更新的途中,有線程2過來查詢數據庫。此時數據庫未更新完成。就會導致將舊數據寫入緩存
反之,如果我們先操作數據庫,再操作緩存的話,雖然也會導致一定的問題,但是總體上概率比先刪除再操作要低的多。
因此,綜上,我們選擇人工編碼方式。先操作數據庫,再刪除緩存。
3. 緩存穿透
3.1 介紹
緩存穿透 :緩存穿透是指客戶端請求的數據在緩存中和數據庫中都不存在,這樣緩存永遠不會生效,這些請求都會打到數據庫.
就比如說,客戶隨機輸入一個ID,因為緩存中不存在,就會一直查詢數據庫。如果在一定時間內,這樣的ID多了,就會給數據庫造成巨大的壓力
怎么解決緩存穿透呢?
常見的解決方案有兩種:
1.緩存空對象
優點是:實現簡單,維護方便
缺點:可能找到額外的內存消耗,和短期的數據不一致
2.布隆過濾
這個原理是給redis和數據庫中儲存的數據設置一個哈希值(二進制數據),輸入數據的哈希值只有在過濾器中存在,才會訪問redis層
?優點:內存占用較少,沒有多余key
?缺點:?實現復雜,?存在誤判可能(比如說哈希沖突)
這里我們使用緩存空對象的方法解決緩存穿透的問題
3.2 核心思路
核心思路如下:
在原來的邏輯中,我們如果發現這個數在Mysql中不存在,就直接返回404了,這是會導致緩存穿透問題的(沒有將空值儲存在緩存中)
現在的邏輯中,如果數據不存在,我們不會返回404,還是會把數據寫入到redis中,并且把value設置為null,當再次發生查詢時,我們發現如果命中后,判斷這個value是否是null,如果是Null,則是之前寫過的數據,證明是緩存穿透數據,如果不是,則直接返回數據.
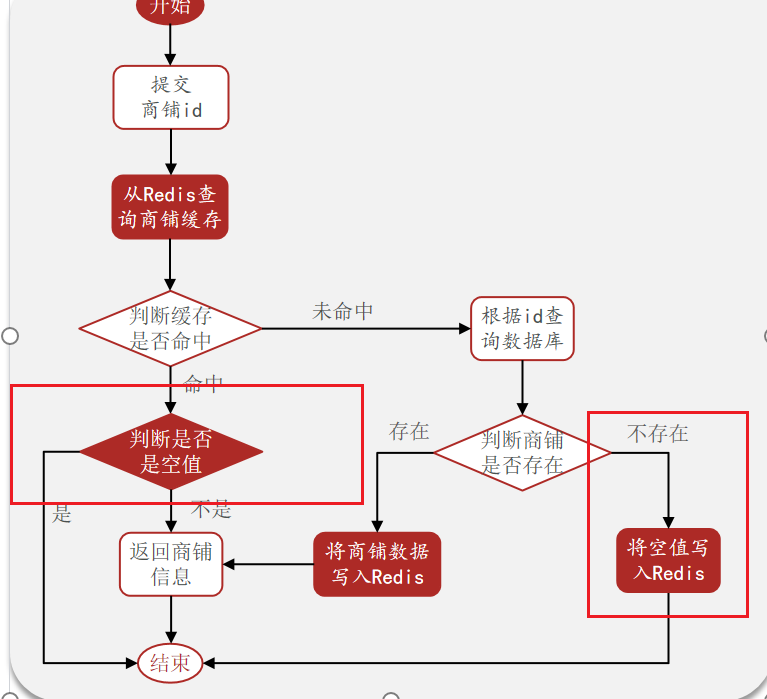
3.2 代碼實現
具體邏輯思路:
1.從redis中查詢數據,如果查詢到了,直接返回結果(注意這里isNotBlank將空字符串“”也是視為false的,所以如果查到,一定是真實的數據,而不是儲存的空值)
2.判斷是不是儲存的空值,是的話就直接返回(第一次沒有查詢到數據,直接null和""兩種情況)
3.進一步的查詢數據庫,如果不存在,在redis中設置空值(value=“”)
4.存在,向redis中寫入數據,返回?
public Shop queryPassThrough(Long id){String key = CACHE_SHOP_KEY + id;// 1.從redis查詢商鋪緩存String shopJson = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);// 2.判斷是否存在if (StrUtil.isNotBlank(shopJson)) {// 3.存在,直接返回Shop shop = JSONUtil.toBean(shopJson, Shop.class);return null;}// 判斷是否是空值if(shopJson != null){return null;}// 4.不存在,根據id查詢數據庫Shop shop = getById(id);// 5.不存在,返回錯誤if(shop == null) {// 向redis中儲存null值stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);return null;}// 6.存在,寫入redisstringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);// 7.返回return shop;
}
3.3 總結
緩存穿透產生的原因是什么?
?用戶請求的數據在緩存中和數據庫中都不存在,不斷發起這樣的請求,給數據庫帶來巨大壓力
緩存穿透的解決方案有哪些?
- ?緩存null值
- ?布隆過濾
- ?增強id的復雜度,避免被猜測id規律
- ?做好數據的基礎格式校驗
- ?加強用戶權限校驗
- ?做好熱點參數的限流
4. 緩存雪崩
緩存雪崩是指在同一時段大量的緩存key同時失效或者Redis服務宕機,導致大量請求到達數據庫,帶來巨大壓力
解決方案:
* 給不同的Key的TTL添加隨機值
* 利用Redis集群提高服務的可用性
* 給緩存業務添加降級限流策略
* 給業務添加多級緩存
5. 緩存擊穿
5.1 介紹
緩存擊穿問題也叫熱點Key問題,就是一個被高并發訪問并且緩存重建業務較復雜的key突然失效了,無數的請求訪問會在瞬間給數據庫帶來巨大的沖擊。
問題分析:
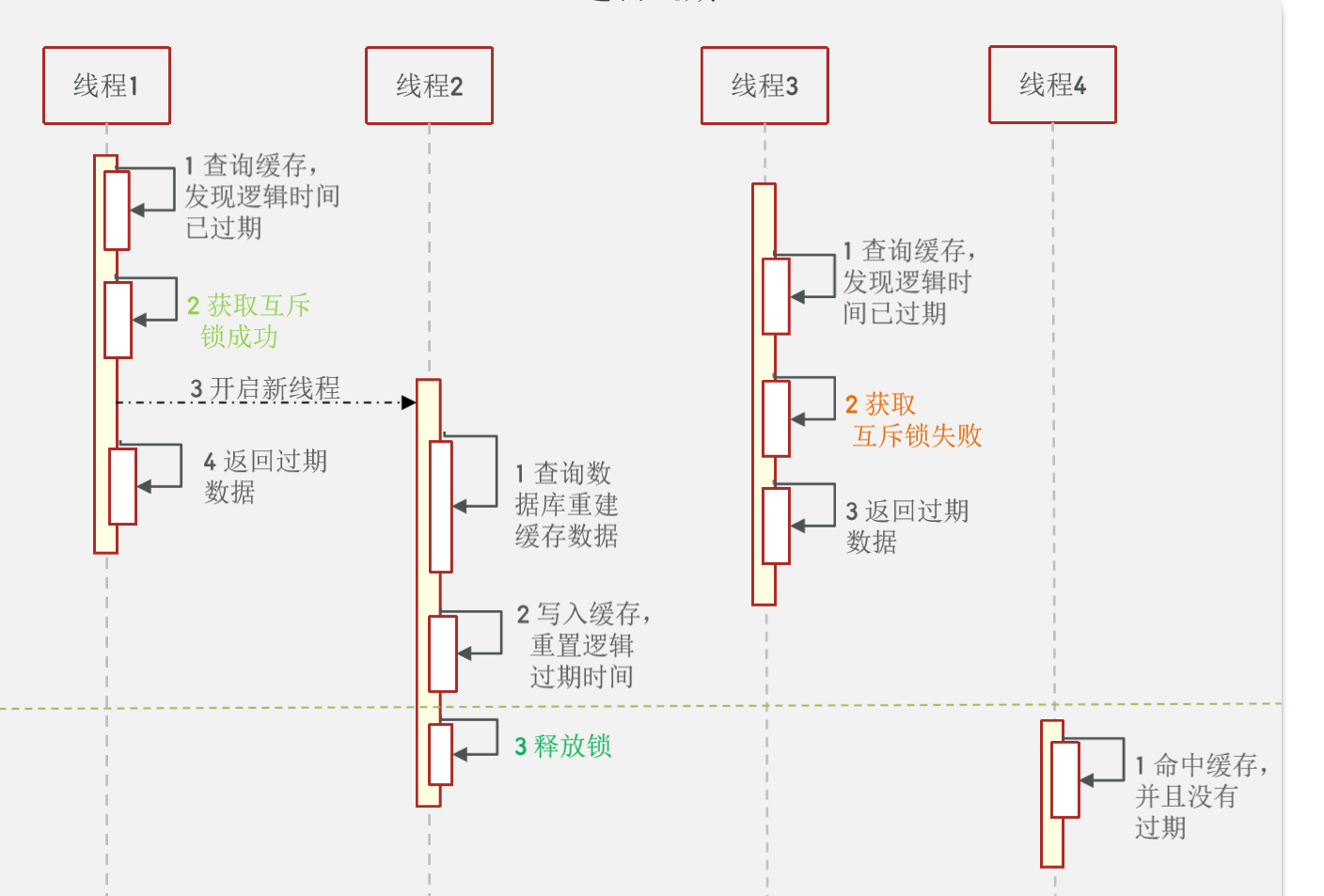
假設線程1在查詢緩存之后,本來應該去查詢數據庫,然后把這個數據重新加載到緩存的,此時只要線程1走完這個邏輯,其他線程就都能從緩存中加載這些數據了,但是假設在線程1沒有走完的時候,后續的線程2,線程3,線程4同時過來訪問當前這個方法, 那么這些線程都不能從緩存中查詢到數據,那么他們就會同一時刻來訪問查詢緩存,都沒查到,接著同一時間去訪問數據庫,同時的去執行數據庫代碼,對數據庫訪問壓力過大
常見的解決方案有兩種:
* 互斥鎖
* 邏輯過期
接下來我們將逐一介紹這兩種解決方法
5.2 互斥鎖解決
解決思路:
因為鎖能實現互斥性。假設線程過來,只能一個人一個人的來訪問數據庫,從而避免對于數據庫訪問壓力過大,但這也會影響查詢的性能,因為此時會讓查詢的性能從并行變成了串行,我們可以采用tryLock方法 + double check來解決這樣的問題。
假設現在線程1過來訪問,他查詢緩存沒有命中,但是此時他獲得到了鎖的資源,那么線程1就會一個人去執行邏輯,假設現在線程2過來,線程2在執行過程中,并沒有獲得到鎖,那么線程2就可以進行到休眠,直到線程1把鎖釋放后,線程2獲得到鎖,然后再來執行邏輯,此時就能夠從緩存中拿到數據了。
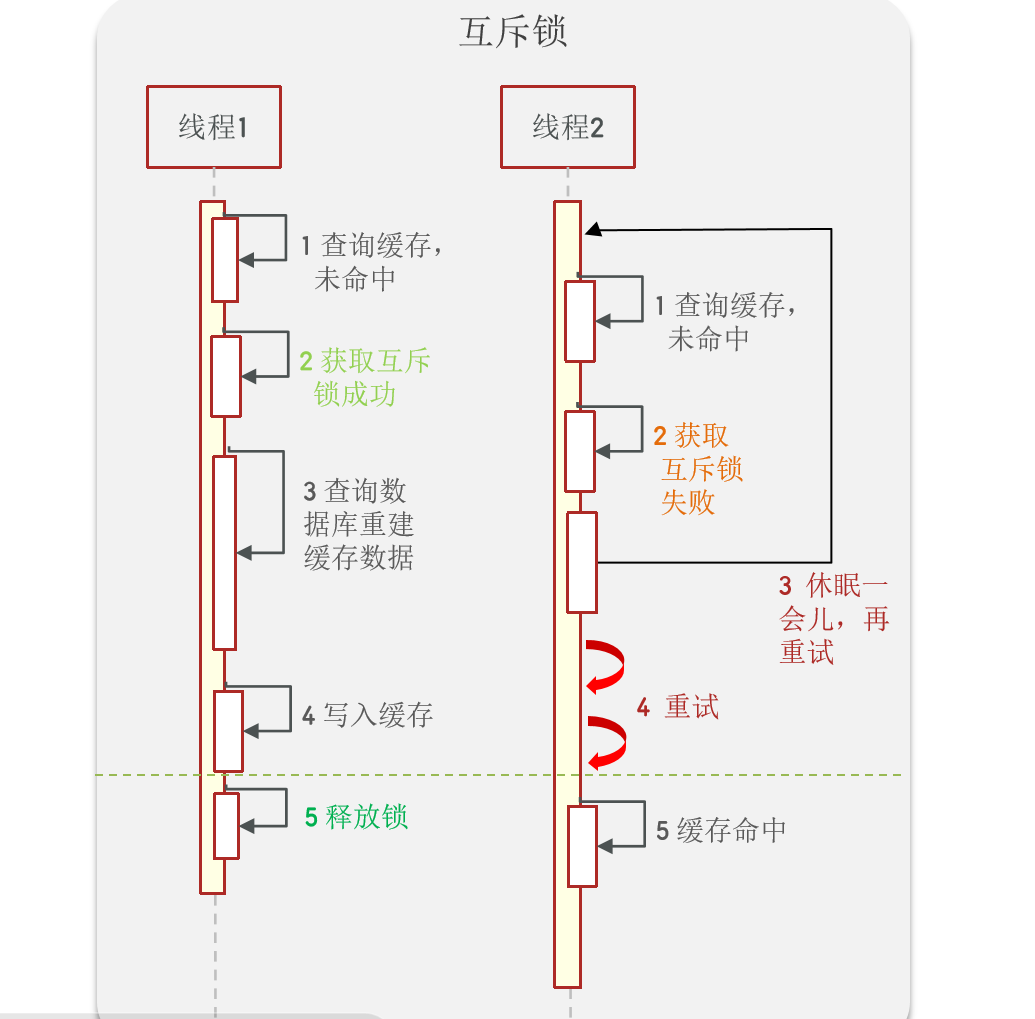
那么這么去模擬這種互斥鎖呢
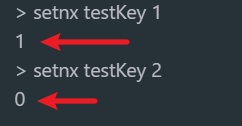
核心思路就是利用redis的setnx方法來表示獲取鎖,該方法含義是redis中如果沒有這個key,則插入成功,返回1,在stringRedisTemplate中返回true, ?如果有這個key則插入失敗,則返回0,在stringRedisTemplate返回false,我們可以通過true,或者是false,來表示是否有線程成功插入key,成功插入的key的線程我們認為他就是獲得到鎖的線程。
代碼:
private boolean tryLock(String key) {
? ? Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);
? ? return BooleanUtil.isTrue(flag);
}
private void unlock(String key) {
? ? stringRedisTemplate.delete(key);
}
5.2.1 具體項目操作思路
核心思路:相較于原來從緩存中查詢不到數據后直接查詢數據庫而言,現在的方案是 進行查詢之后,如果從緩存沒有查詢到數據,則進行互斥鎖的獲取,獲取互斥鎖后,判斷是否獲得到了鎖,如果沒有獲得到,則休眠,過一會再進行嘗試,直到獲取到鎖為止,才能進行查詢
如果獲取到了鎖的線程,再去進行查詢,查詢后將數據寫入redis,再釋放鎖,返回數據,利用互斥鎖就能保證只有一個線程去執行操作數據庫的邏輯,防止緩存擊穿
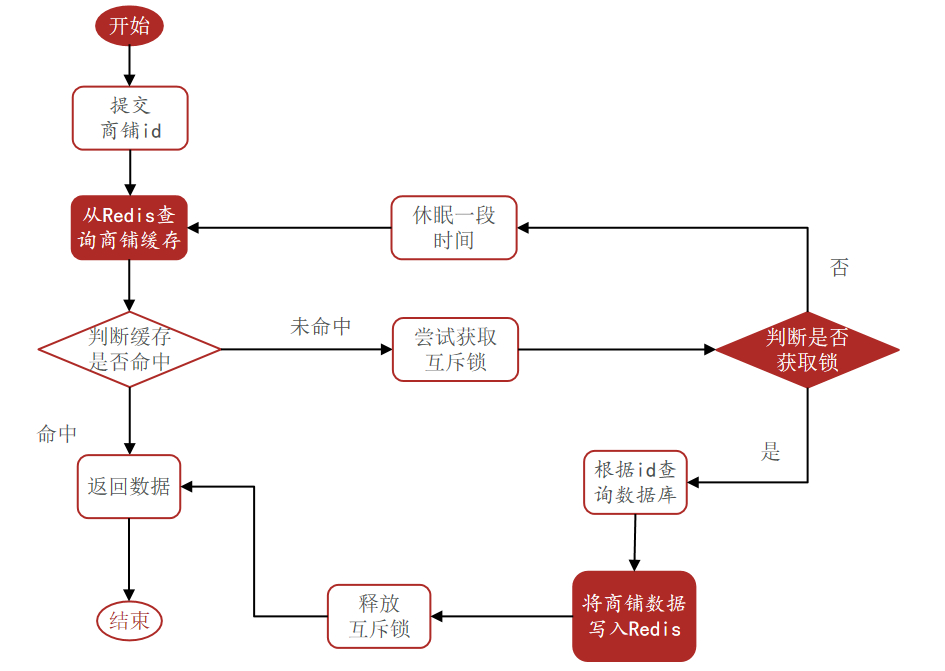
代碼邏輯:
1.查詢redis,判斷是否命中(有數據)
2.命中直接返回數據
3.如果未命中,查看是否是空值(緩存穿透)
4.不是,則嘗試獲取互斥鎖
5. 獲取失敗,休眠,遞歸重復上面的過程,試著重新獲取互斥鎖
6. 獲取成功,先進行double check,判斷是否已經寫入緩存,寫入的話直接返回(考慮到線程1完成后其他線程獲得鎖就不用再緩存重建了)
7.如果沒有,再查詢數據庫,不存在,設空值(穿透)
8.存在,寫入redis中,釋放鎖
public Shop queryWithMutex(Long id){String key = CACHE_SHOP_KEY + id;// 1.從redis查詢商鋪緩存String shopJson = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);// 2.判斷是否存在if (StrUtil.isNotBlank(shopJson)) {// 3.存在,直接返回Shop shop = JSONUtil.toBean(shopJson, Shop.class);return null;}// 判斷是否是空值if(shopJson != null){return null;}// 4. 實現緩存重建// 4.1 獲取互斥鎖String lockKey = LOCK_SHOP_KEY + id;boolean isLock = tryLock(lockKey);Shop shop = null;try {// 4.2 判斷是否獲取成功if(!isLock){// 4.3 失敗,則休眠并重試Thread.sleep(50);return queryWithMutex(id);}// 4.4 進行double checkString shopJson1 = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);if(StrUtil.isNotBlank(shopJson1)){return JSONUtil.toBean(shopJson1, Shop.class);}// 4.5 成功,根據id查詢數據庫shop = getById(id);// 5.不存在,返回錯誤if(shop == null) {// 向redis中儲存null值stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);return null;}// 6.存在,寫入redisstringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);} catch (InterruptedException e) {e.printStackTrace();} finally {// 7.釋放鎖unlock(lockKey);}
5.3 邏輯過期解決
方案分析:我們之所以會出現這個緩存擊穿問題,主要原因是在于我們對key設置了過期時間,假設我們不設置過期時間,其實就不會有緩存擊穿的問題,但是不設置過期時間,這樣數據不就一直占用我們內存了嗎,我們可以采用邏輯過期方案。
我們把過期時間設置在 redis的value中,注意:這個過期時間并不會直接作用于redis,而是我們后續通過邏輯去處理。假設線程1去查詢緩存,然后從value中判斷出來當前的數據已經過期了,此時線程1去獲得互斥鎖,那么其他線程會進行阻塞,獲得了鎖的線程他會開啟一個 線程去進行 以前的重構數據的邏輯,直到新開的線程完成這個邏輯后,才釋放鎖, 而線程1直接進行返回,假設現在線程3過來訪問,由于線程線程2持有著鎖,所以線程3無法獲得鎖,線程3也直接返回數據,只有等到新開的線程2把重建數據構建完后,其他線程才能走返回正確的數據。
這種方案巧妙在于,異步的構建緩存,缺點在于在構建完緩存之前,返回的都是臟數據。
5.3.1 具體項目操作思路
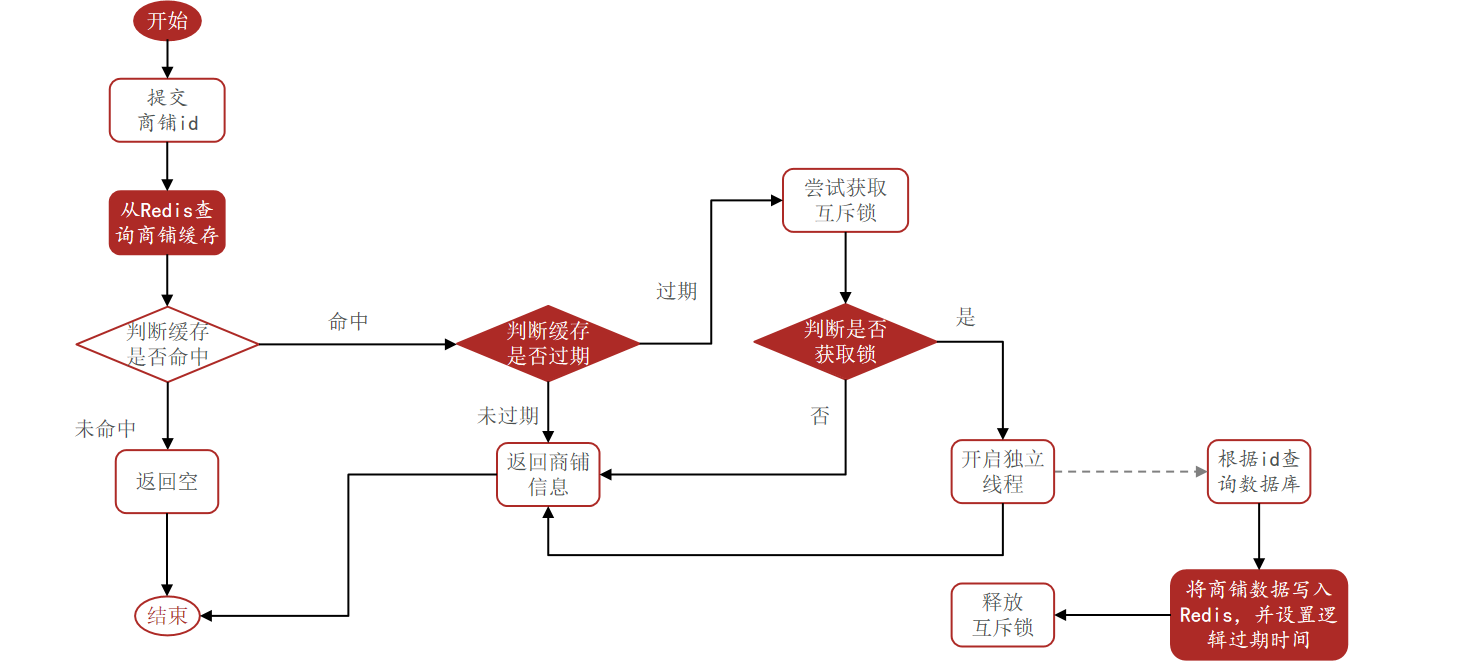
思路分析:當用戶開始查詢redis時,判斷是否命中,如果沒有命中則直接返回空數據,不查詢數據庫,而一旦命中后,將value取出,判斷value中的過期時間是否滿足,如果沒有過期,則直接返回redis中的數據,如果過期,則在開啟獨立線程后直接返回之前的數據,獨立線程去重構數據,重構完成后釋放互斥鎖。
但是問題來了,我們該如何給value設置上過期時間呢,我們知道原來的實體類shop是沒有過期時間這個字段的。但是如果直接修改實體類,對原本的代碼也有影響,不好管理。這里我們可以再建造一個類,用來儲存過期時間還有數據data
@Data
public class RedisData {
? ? private LocalDateTime expireTime;
? ? private Object data;
}
代碼邏輯:
1.判斷redis是否命中(有數據)
2.如果沒有,直接返回null,結束(所以這樣不用判斷是否有緩存穿透的問題,采用這個方法,在redis中存儲的數據是一直存在的)
3.命中,將傳入的expireTime和shop的數據封裝到redisData類中,判斷是否過期
4. 未過期,直接返回店鋪信息
5.已過期,獲取互斥鎖(原理跟互斥鎖解決的原理是一樣的)
6.沒有獲取到,直接返回舊數據
7.獲取到了,開啟一個新線程,由他執行redis的數據更新(這里不用加check double,舊數據是存在于redis中的,加了check第一個搶到鎖的線程拿到直接就是返回舊數據了,不會進行后續邏輯)
8.更新完后釋放鎖,后續線程返回的就是新數據了
private static final ExecutorService executorService = Executors.newFixedThreadPool(10);public Shop queryWithLogicalExpire(Long id){String key = CACHE_SHOP_KEY + id;// 1.從redis查詢商鋪緩存String shopJson = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);// 2.判斷是否存在if (StrUtil.isBlank(shopJson)) {// 3.未命中,直接返回return null;}// 命中,需要先把JSON反序列成對象RedisData redisData = JSONUtil.toBean(shopJson, RedisData.class);JSONObject data = (JSONObject) redisData.getData();Shop shop = JSONUtil.toBean(shopJson, Shop.class);LocalDateTime expireTime = redisData.getExpireTime();// 判斷是否過期if(expireTime.isAfter(LocalDateTime.now())) {// 未過期,直接返回店鋪信息return shop;}// 已過期, 嘗試獲取互斥鎖String lockKey = LOCK_SHOP_KEY + id;boolean isLock = tryLock(lockKey);if(isLock) {// 獲得鎖,開啟線程executorService.submit(() -> {try {// 重建緩存this.saveShop2Redis(id, 20L);} catch (Exception e) {throw new RuntimeException(e);}finally {// 釋放鎖unlock(lockKey);}});}// 沒有獲得鎖,返回店鋪信息return shop;
}
下面是具體執行數據更新的方法:
查詢數據庫,更新data,更新邏輯時間
public void saveShop2Redis(Long id, Long expireSeconds) throws InterruptedException {// 查看店鋪數據Shop shop = getById(id);Thread.sleep(200);// 分裝邏輯過期時間RedisData redisData = new RedisData();redisData.setData(shop);redisData.setExpireTime(LocalDateTime.now().plusSeconds(expireSeconds));// 寫入RedisstringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, JSONUtil.toJsonStr(redisData));}
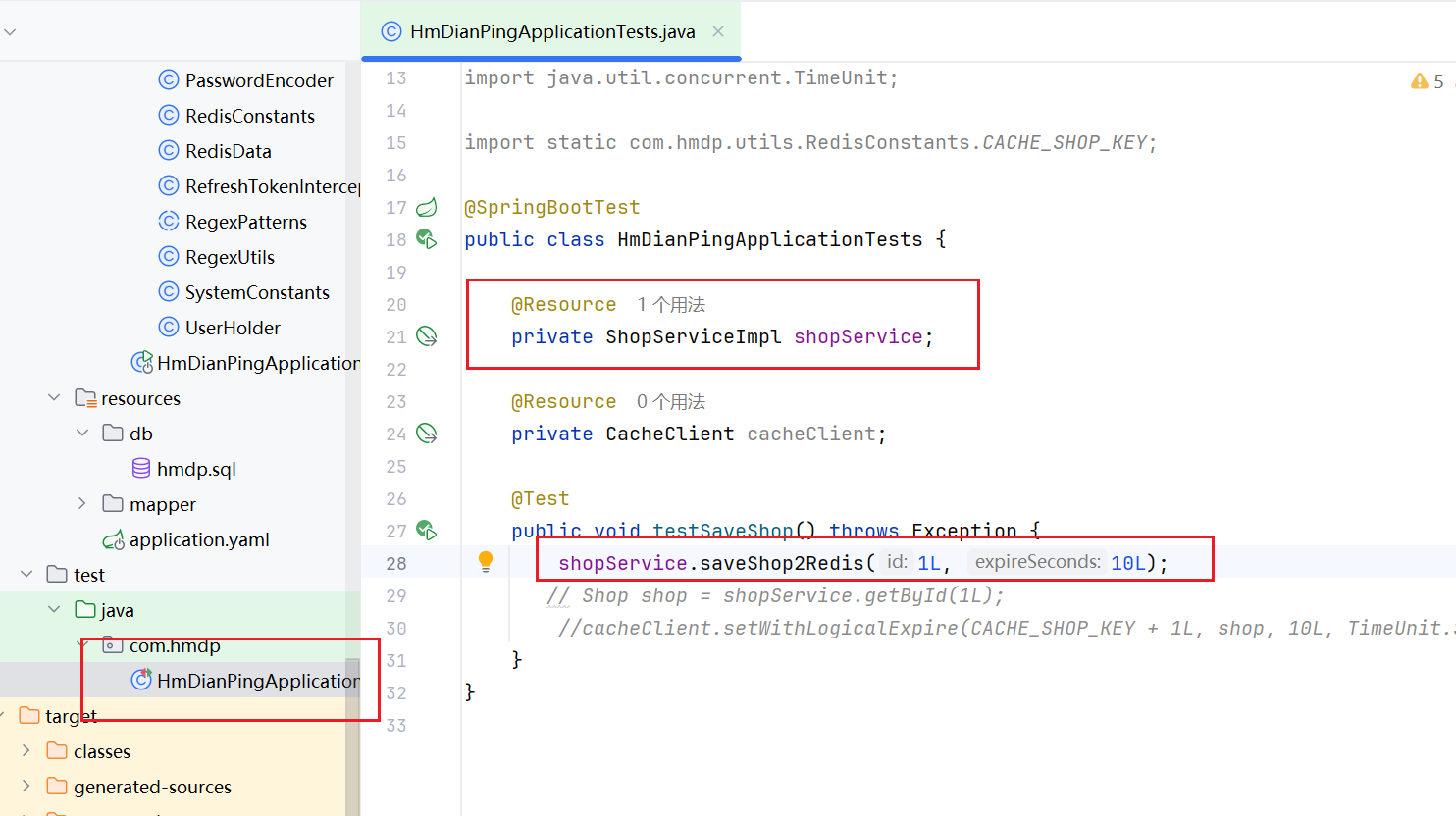
需要注意的是,如果要測試邏輯過期解決緩存擊穿的代碼,我們先需要有這個緩存數據,所以要先在測試類中把數據添加好
為了方便測試,這里邏輯時間設置的是添加10s后過期
5.4 總結
**互斥鎖方案:由于保證了互斥性,所以數據一致,且實現簡單,因為僅僅只需要加一把鎖而已,也沒其他的事情需要操心,所以沒有額外的內存消耗,缺點在于有鎖就有死鎖問題的發生,且只能串行執行性能肯定受到影響
**邏輯過期方案:?線程讀取過程中不需要等待,性能好,有一個額外的線程持有鎖去進行重構數據,但是在重構數據完成前,其他的線程只能返回之前的數據,且實現起來麻煩
6. 封裝Redis工具類
需求分析:
基于StringRedisTemplate封裝一個緩存工具類,滿足下列需求:
* 方法1:將任意Java對象序列化為json并存儲在string類型的key中,并且可以設置TTL過期時間
* 方法2:將任意Java對象序列化為json并存儲在string類型的key中,并且可以設置邏輯過期時間,用于處理緩存擊穿問題
* 方法3:根據指定的key查詢緩存,并反序列化為指定類型,利用緩存空值的方式解決緩存穿透問題
* 方法4:根據指定的key查詢緩存,并反序列化為指定類型,需要利用邏輯過期解決緩存擊穿問題
先創建一個redisClient類,交給IOC容器管理,必要一些方法寫好
@Component
@Slf4j
public class CacheClient {private final StringRedisTemplate stringRedisTemplate;public CacheClient(StringRedisTemplate stringRedisTemplate) {this.stringRedisTemplate = stringRedisTemplate;}private boolean tryLock(String key){Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);return BooleanUtil.isTrue(flag); // 做一個拆箱,防止返回空值}private void unlock(String key){stringRedisTemplate.delete(key);}
}
6.1 方法1實現
實現目標:將任意Java對象序列化為json并存儲在string類型的key中,并且可以設置TTL過期時間
實現邏輯:很簡單的redis添加功能,這邊傳入的value值是不確定的,所以傳入Object
public void set(String key, Object value, Long time, TimeUnit timeUnit) {stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(value), time, timeUnit);
}
6.2 方法2實現
實現目標:將任意Java對象序列化為json并存儲在string類型的key中,并且可以設置邏輯過期時間,用于處理緩存擊穿問題
實現邏輯:這里比方法1多的一步是要設置一個邏輯過期時間,并跟value值一起封裝進redisData,最后寫入redis
public void setWithLogicalExpire(String key, Object value, Long time, TimeUnit timeUnit) {// 設置邏輯過期RedisData redisData = new RedisData();redisData.setData(value);redisData.setExpireTime(LocalDateTime.now().plusSeconds(timeUnit.toSeconds(time)));// 寫入redisstringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(redisData));
}
6.3 方法3實現
實現目標:根據指定的key查詢緩存,并反序列化為指定類型,利用緩存空值的方式解決緩存穿透問題
實現邏輯:跟目錄3.緩存穿透的邏輯實現是一樣的。
這里我主要講下用到的泛型和方法設計。
1.<R, ID>這是方法級別的泛型聲明,表示這個方法使用了兩個泛型類型參數
2.后一個R表示方法的返回類型,例如,如果調用時傳入Class<User>,那么返回的就是User類型
3.ID參數id的類型是ID,這是一個泛型類型,表示可以接受任意類型的ID(如Long、String、Integer等)。
4.Class<R> type,這是一個Class對象,表示返回類型R的運行時類型信息。例如,如果R是User,那么type就是User.class
5.Function<ID, R> dbFallback這是一個函數式接口參數,表示一個從ID到R的轉換函數。例如,如果ID是Long,R是User,那么dbFallback就是一個能根據Long id查詢并返回User的函數。
public <R, ID> R queryWithThrough(String keyPrefix, ID id, Class<R> type,Function<ID, R> dbFallback, Long time, TimeUnit timeUnit){String key = keyPrefix + id;// 從redis查詢商鋪緩存String json = stringRedisTemplate.opsForValue().get(key);// 判斷是否存在if(StrUtil.isNotBlank(json)){// 存在,直接返回return JSONUtil.toBean(json, type);}// 判斷是否為空值if(json != null){return null;}// 不存在,根據id查詢數據庫R r = dbFallback.apply(id);// 不存在,返回錯誤if(r == null){// 將空值寫入redisstringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);// 返回錯誤信息return null;}// 存在,寫入redisthis.setWithLogicalExpire(key, r, time, timeUnit);return r;
}
調用傳參如下
// 緩存穿透 Shop shop1 = cacheClient.queryWithThrough(CACHE_SHOP_KEY, id, Shop.class, this::getById, CACHE_SHOP_TTL, TimeUnit.MINUTES);
6.4 方法4實現
實現目標:根據指定的key查詢緩存,并反序列化為指定類型,需要利用邏輯過期解決緩存擊穿問題
實現邏輯:跟目錄5.緩存擊穿的邏輯過期實現那一樣的,方法參數傳遞跟方法3是一樣的
private static final ExecutorService executorService = Executors.newFixedThreadPool(10);public <R,ID> R queryWithLogicalExpire(String keyPrefix, ID id, Class<R> type,Function<ID, R> dbFallback, Long time, TimeUnit timeUnit){String key = keyPrefix + id;// 1.從redis查詢商鋪緩存String shopJson = stringRedisTemplate.opsForValue().get(key);// 2.判斷是否存在if (StrUtil.isBlank(shopJson)) {// 3.未命中,直接返回return null;}// 命中,需要先把JSON反序列成對象RedisData redisData = JSONUtil.toBean(shopJson, RedisData.class);JSONObject data = (JSONObject) redisData.getData();R r = JSONUtil.toBean(data, type);LocalDateTime expireTime = redisData.getExpireTime();// 判斷是否過期if(expireTime.isAfter(LocalDateTime.now())) {// 未過期,直接返回店鋪信息return r;}// 已過期, 嘗試獲取互斥鎖String lockKey = LOCK_SHOP_KEY + id;boolean isLock = tryLock(lockKey);if(isLock) {
// String shopJson1 = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);
// if(StrUtil.isNotBlank(shopJson1)){
// return JSONUtil.toBean(shopJson1, type);
// }// 獲得鎖,開啟線程executorService.submit(() -> {try {// 重建緩存Thread.sleep(200);// 先查數據庫R r1 = dbFallback.apply(id);// 再寫入redisthis.setWithLogicalExpire(key, r1, time, timeUnit);} catch (Exception e) {throw new RuntimeException(e);}finally {// 釋放鎖unlock(lockKey);}});}// 沒有獲得鎖,返回店鋪信息return r;}
最后:
今天的分享就到這里。如果我的內容對你有幫助,請點贊,評論,收藏。創作不易,大家的支持就是我堅持下去的動力!(?`・?・′?)



![2025年滲透測試面試題總結-匿名[校招]安全服務工程師(題目+回答)](http://pic.xiahunao.cn/2025年滲透測試面試題總結-匿名[校招]安全服務工程師(題目+回答))



首頁靜態頁面)
)


)
)



)

)
