一、DB-GPT 簡介
????????DB-GPT 是一個開源的AI原生數據應用開發框架(AI Native Data App Development framework with AWEL(Agentic Workflow Expression Language) and Agents)。目的是構建大模型領域的基礎設施,通過開發多模型管理(SMMF)、Text2SQL效果優化、RAG框架以及優化、Multi-Agents 框架協作、AWEL (智能體工作流編排)等多種技術能力,讓圍繞數據庫構建大模型應用更簡單,更方便。?
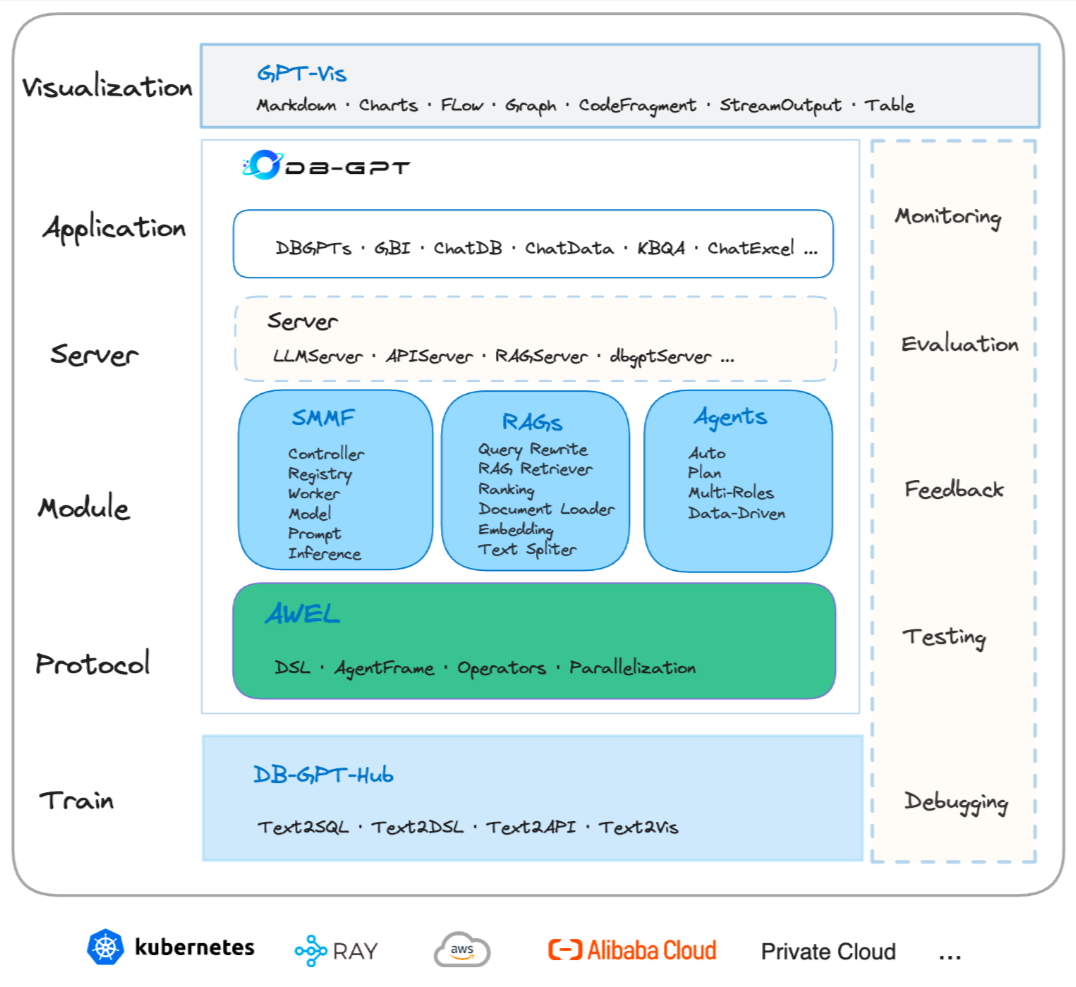
????????數據3.0 時代,基于模型、數據庫,企業/開發者可以用更少的代碼搭建自己的專屬應用。
????????官方英文文檔地址:http://docs.dbgpt.cn/docs/overview/
????????官方中文文檔地址:https://www.yuque.com/eosphoros/dbgpt-docs/bex30nsv60ru0fmx
????????官網快速部署地址:http://docs.dbgpt.cn/docs/next/installation/docker/
????????官網開源倉庫地址:https://github.com/eosphoros-ai/DB-GPT
????????截至目前,最新的版本:v0.7.1?
二、DB-GPT 安裝
????????首先,登錄 Ubuntu 24.04 LTS 系統終端;在安裝 DB-GPT 的目錄下進行代碼下載:
git clone https://github.com/eosphoros-ai/DB-GPT.git????????代碼下載好之后,可以進行安裝部署。目前有源碼安裝(最新版本不再支持 pip,而是采用 uv)、docker 安裝 、docker compose 安裝 等主流安裝方式。
2.1 Docker 快速安裝
# 拉取 dbgpt-openai 最新鏡像
docker pull eosphorosai/dbgpt-openai:latest
# ${SILICONFLOW_API_KEY} 替換成 硅基流動 的大模型調用 API 密鑰
docker run -it --rm -e SILICONFLOW_API_KEY=${SILICONFLOW_API_KEY} ?-p 5670:5670 --name dbgpt eosphorosai/dbgpt-openai
# 訪問地址 http://localhost:5670 驗證是否安裝正常可用
2.2 Docker Compose 安裝
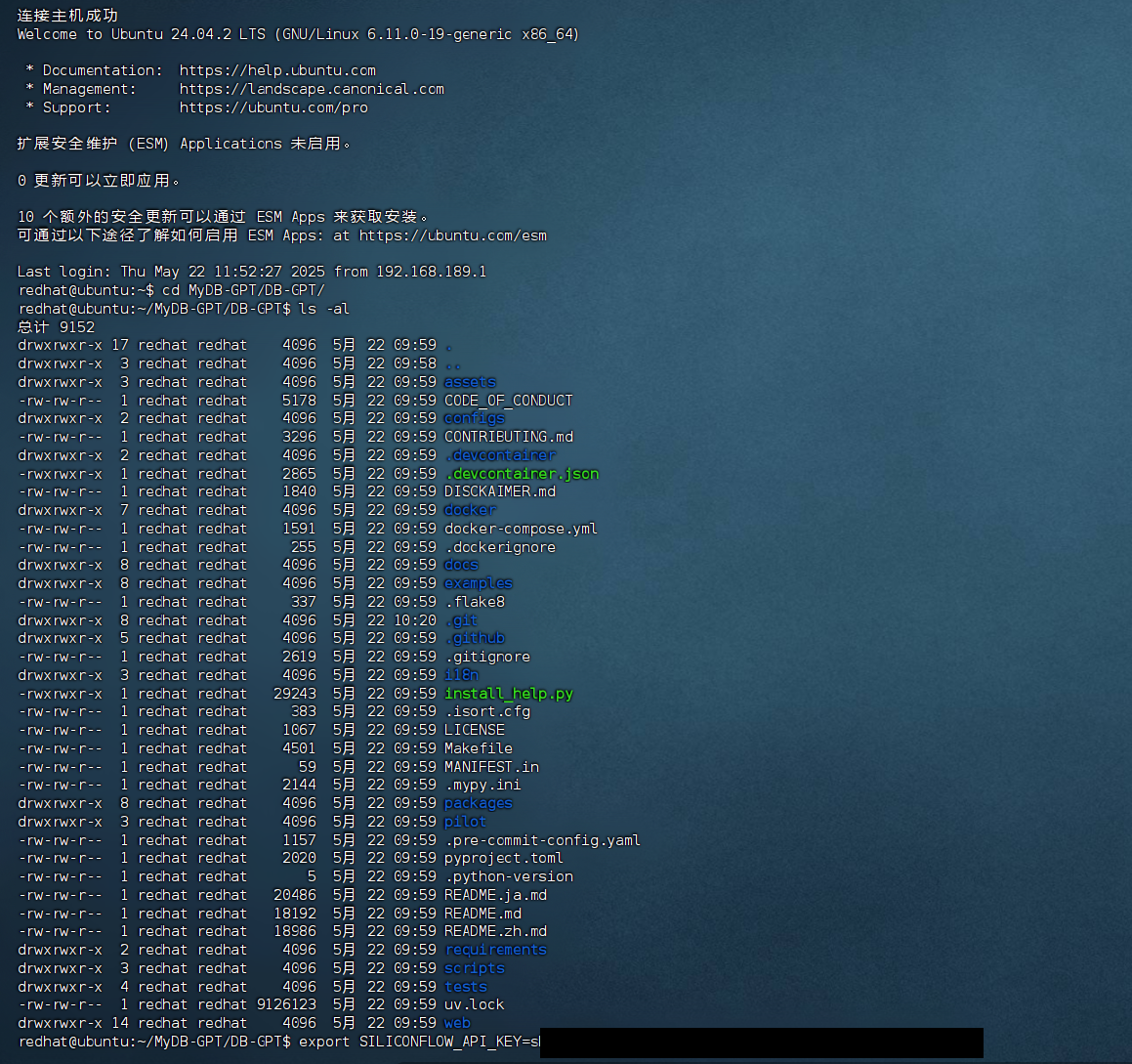
# 進行下載好的 DB-GPT 倉庫的根目錄
cd ~/MyDB-GPT/DB-GPT/# 維護${SILICONFLOW_API_KEY} 硅基流動的大模型調用 API 密鑰;${SILICONFLOW_API_KEY}替換成你自己的 API 密鑰,不要把下面傻傻的一字不差抄上去
SILICONFLOW_API_KEY=${SILICONFLOW_API_KEY}# 查看 DB-GPT 倉庫的根目錄的docker-compose.yml內容 (里面的應用端口如果和現有應用端口沖突,記得調整,否則忽略。例如:機子已經安裝了mysql占用了3306端口,如果不改啟動的是否就會報端口沖突)
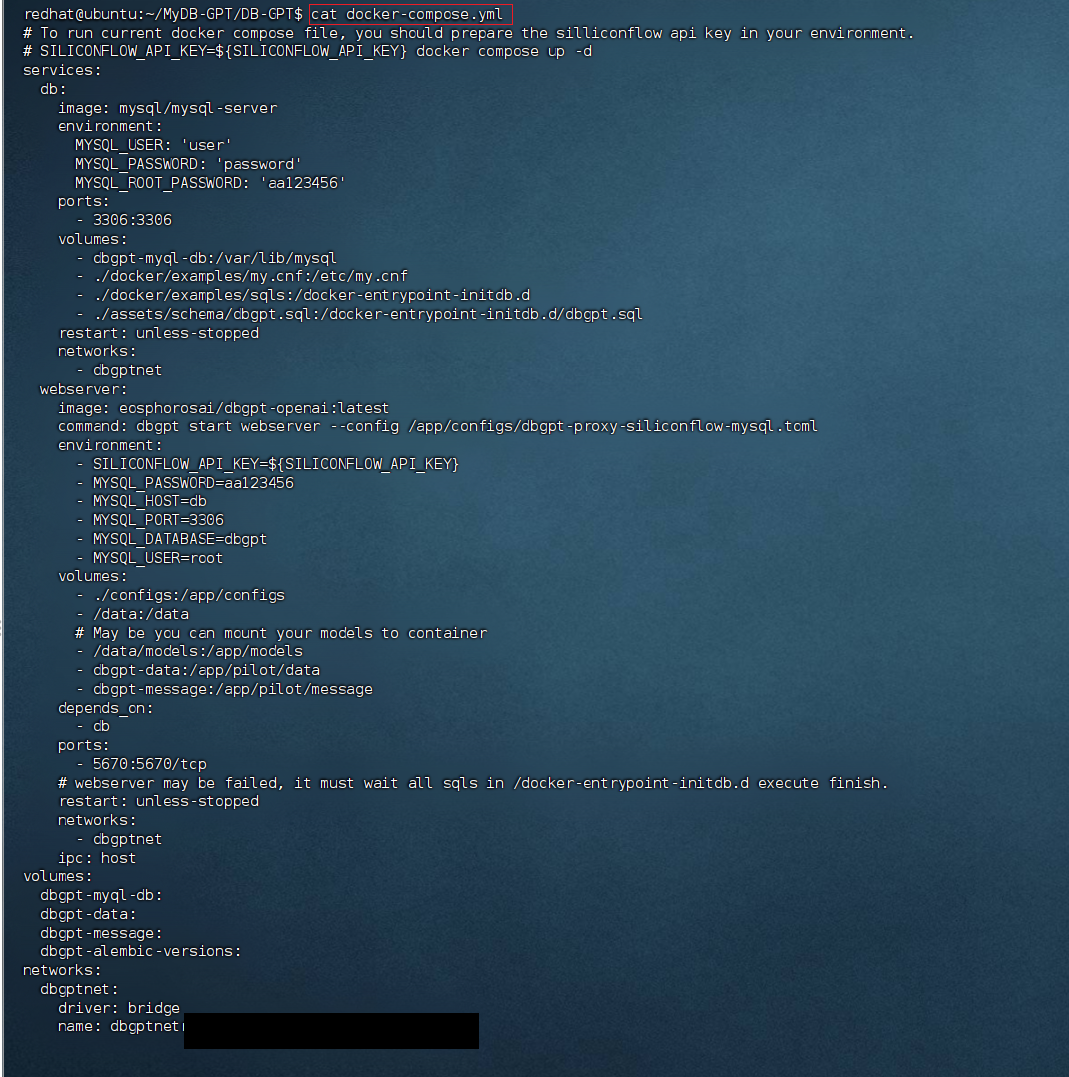
# 開始docker compose部署安裝
docker compose -f docker-compose.yml -p dbgptnet up -d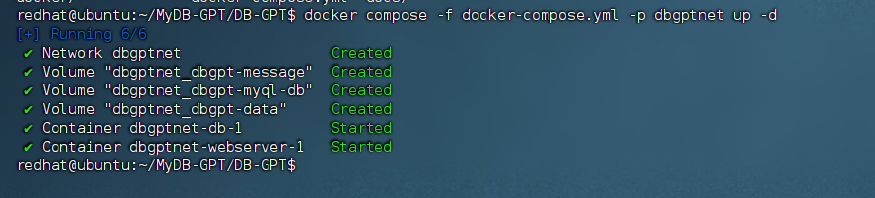
# 訪問地址 http://IP:5670 驗證是否安裝正常可用
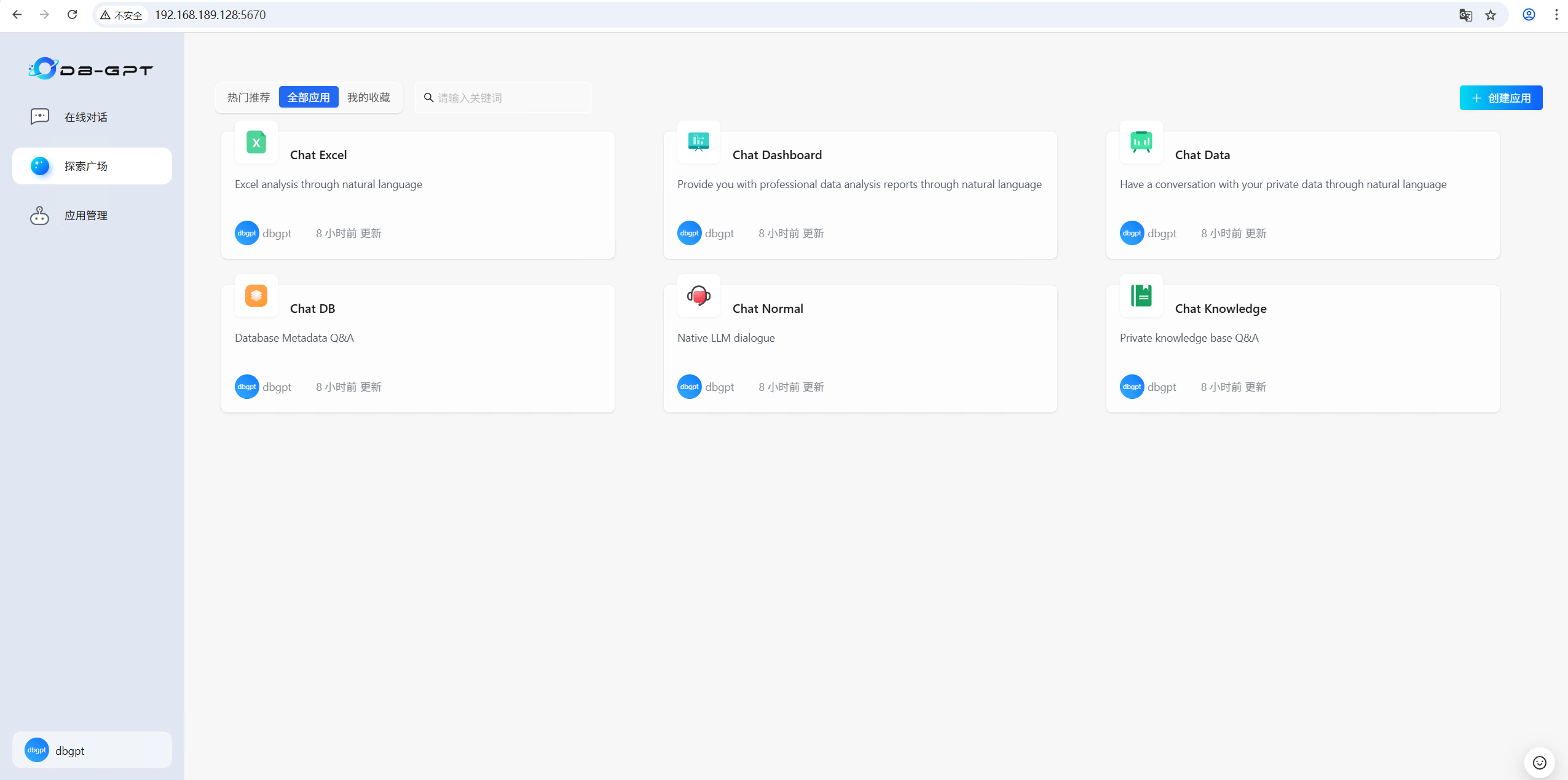
三、DB-GPT 入門使用
3.1 模型供應商與模型配置
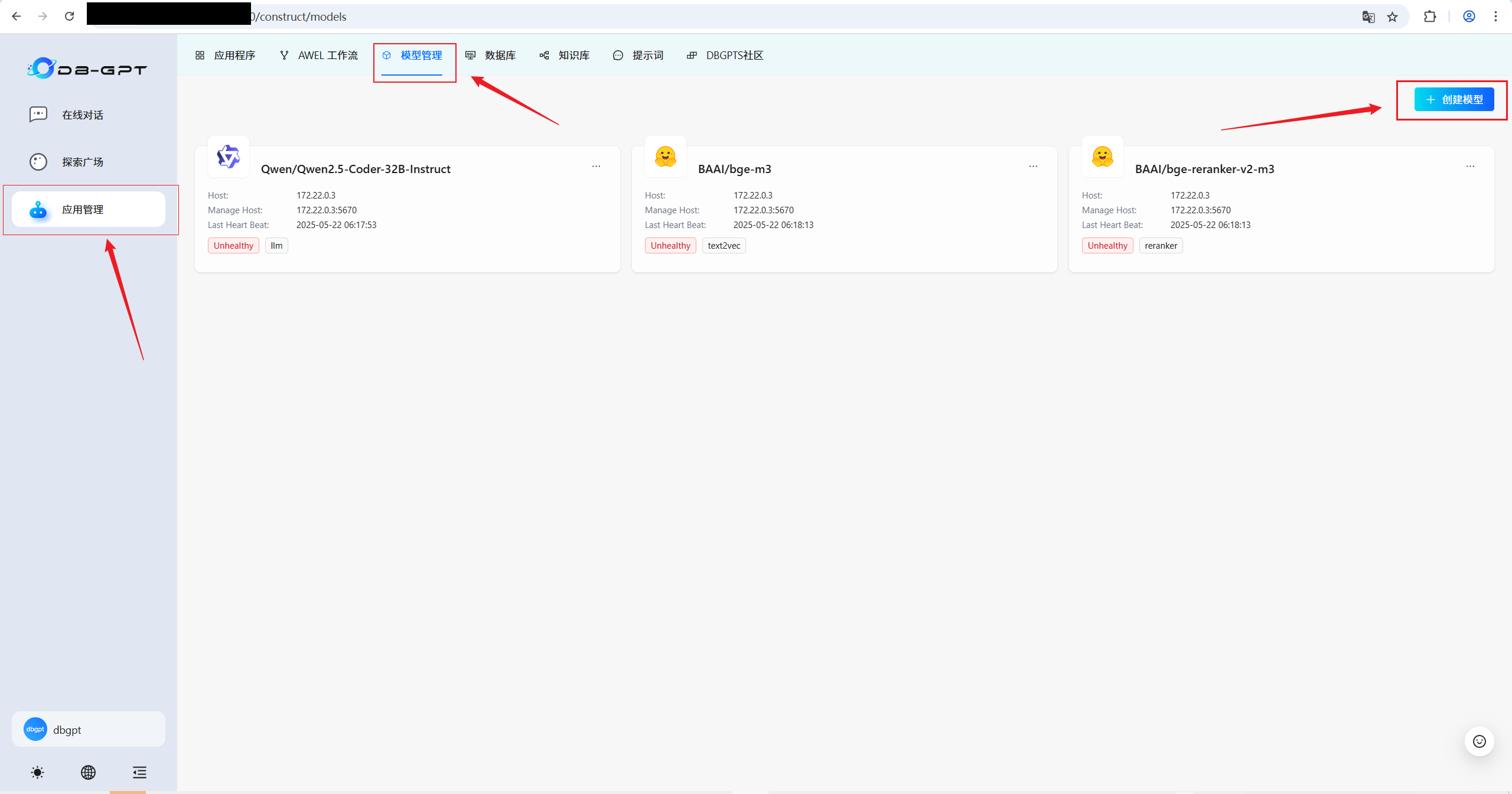
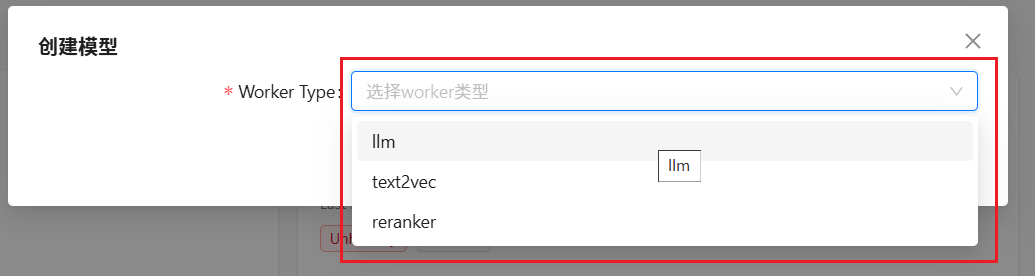
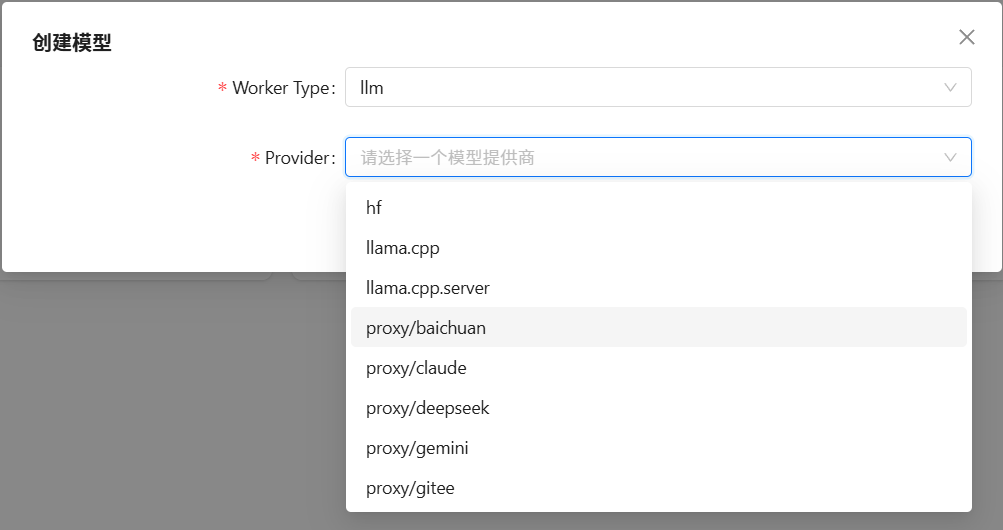
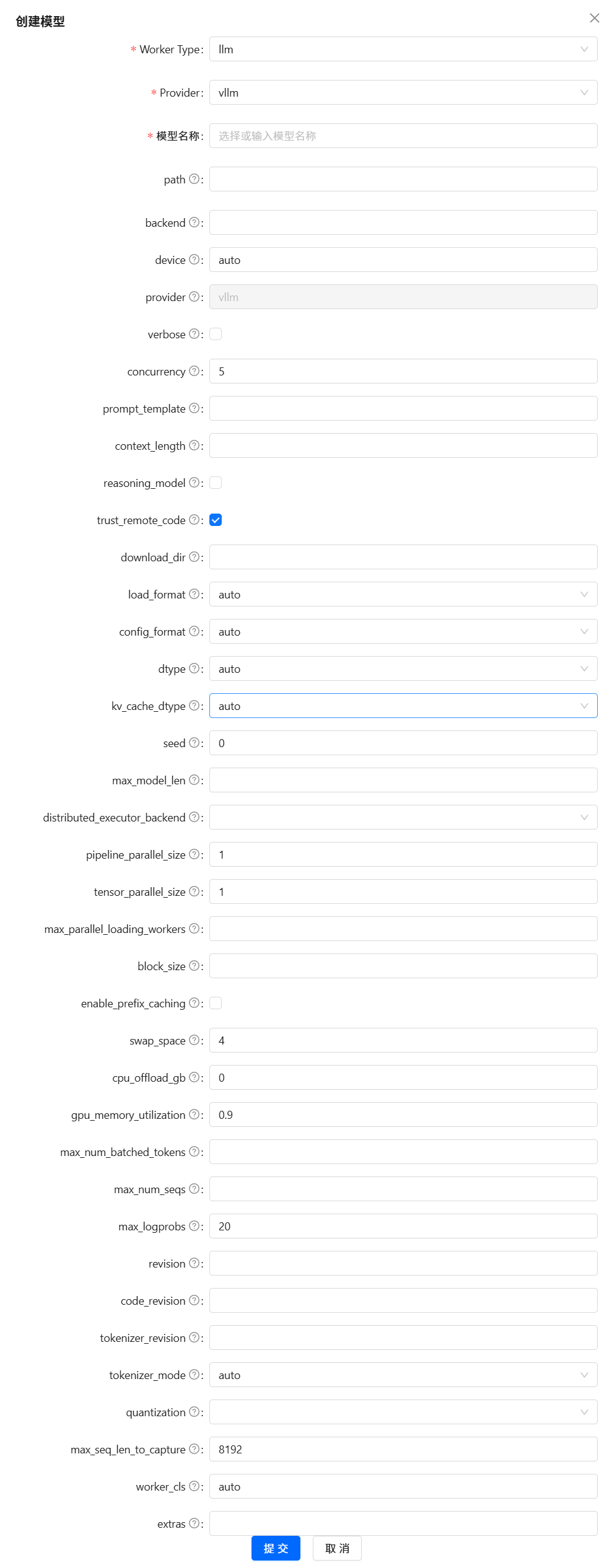
????????按照上面的步驟,依次添加 llm 、text2vec 和 reranker 三種類型的模型;然后,再選擇合適的模型供應商;并最后填寫添加的模型與相關調參。
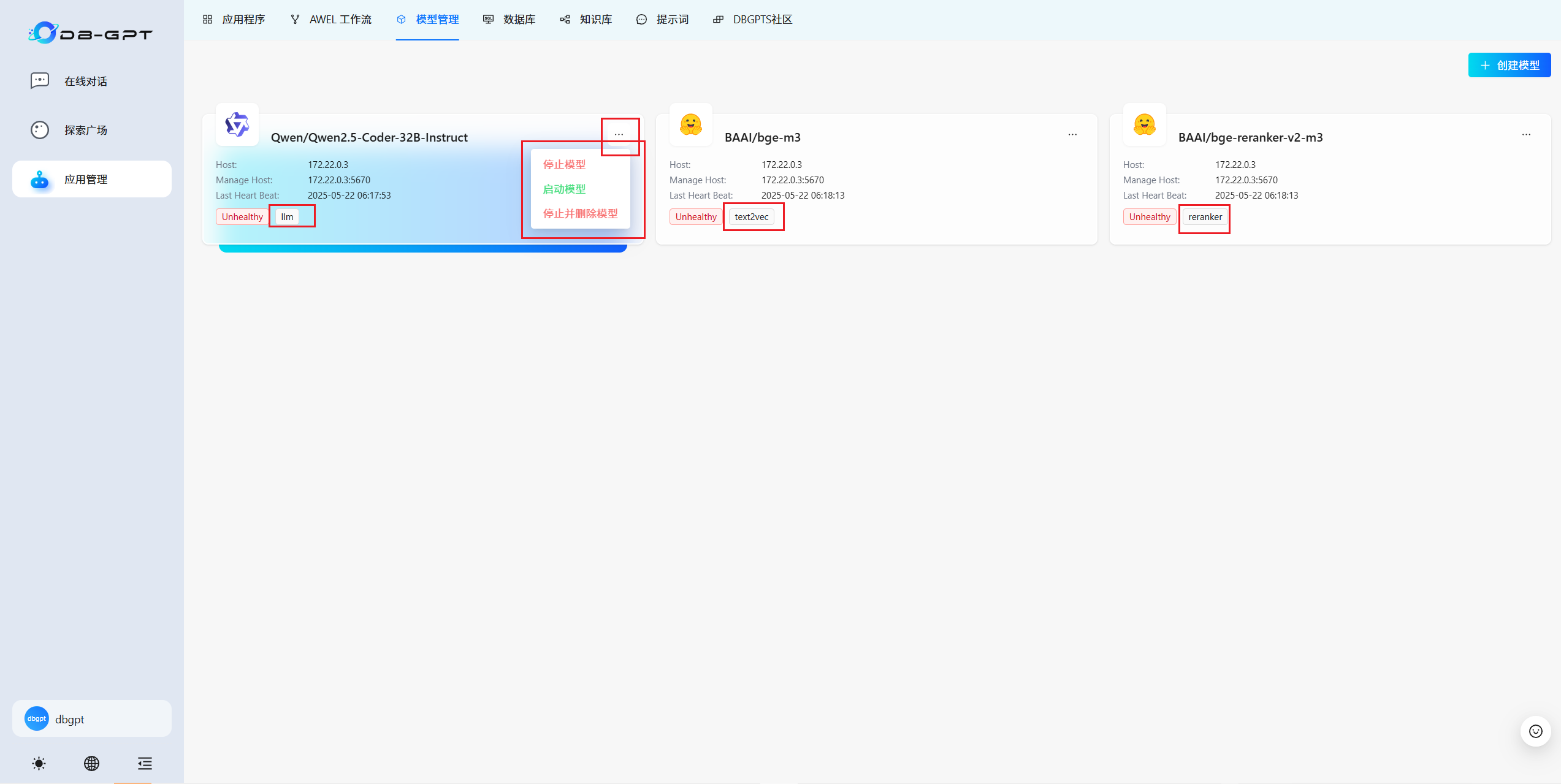
3.2 維護數據源
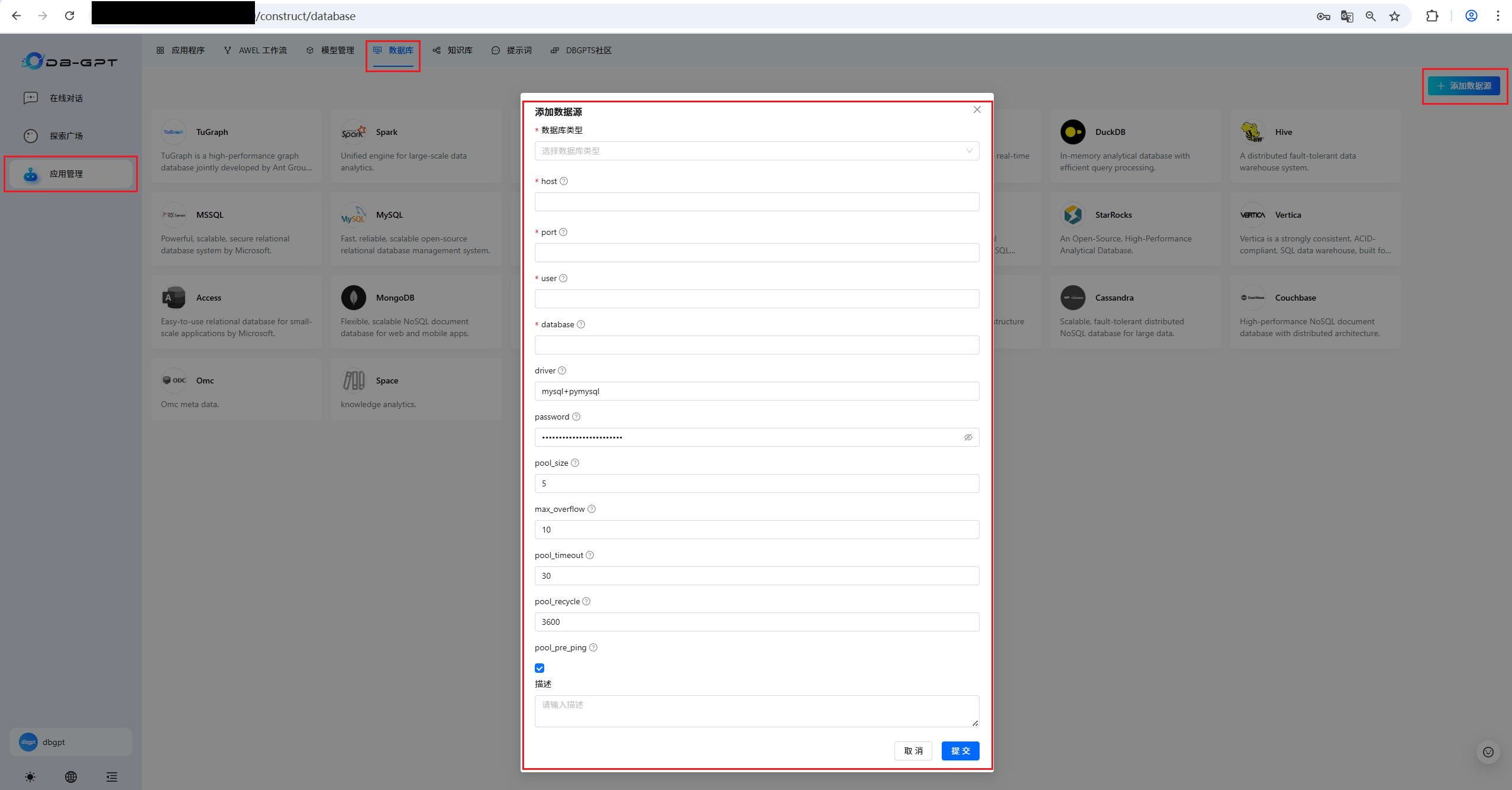
? ? ? ? 按照上面步驟,依次選擇數據庫類型與相關配置。
3.3 維護知識庫
????????Text2SQL中最重要的SQL業務背景知識的三大知識庫(每個單獨的數據源,都需要維護該數據源對應的三個獨立的 DDL 知識庫 、DB Description 知識庫 和 Q->SQL 知識庫):
????????第一類是 DDL(Data Definition Language)知識庫,它主要提供數據庫表結構信息,包括表名、列名、數據類型以及主鍵、外鍵等約束條件。
????????第二類是 DB Description 知識庫,用于說明數據庫中表和列的含義,這對于模型理解數據的語義非常重要。
????????第三類是 Q->SQL 知識庫,它包含了大量的參考 SQL,即自然語言問題與對應的 SQL 語句示例。這些語句主要是讓大模型學習如何在有背景知識的情況下學會寫SQL語句。這些叫做黃金語句,Golden statement,這些語句給的越多,大模型學習的越好,他能夠回答的問題越有不會出錯。正常情況下準備5000-10000個這樣的SQL語句就可以了。
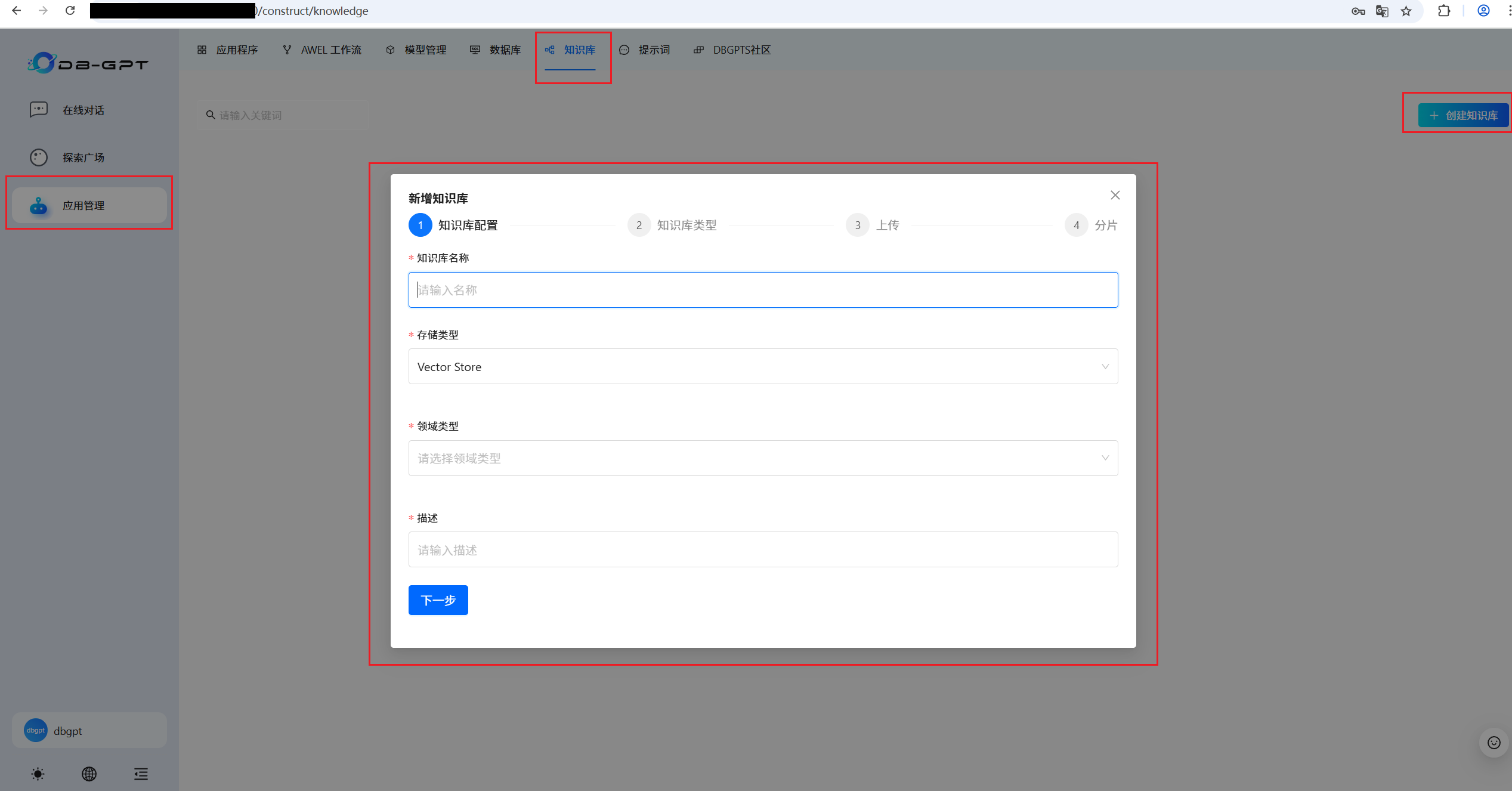
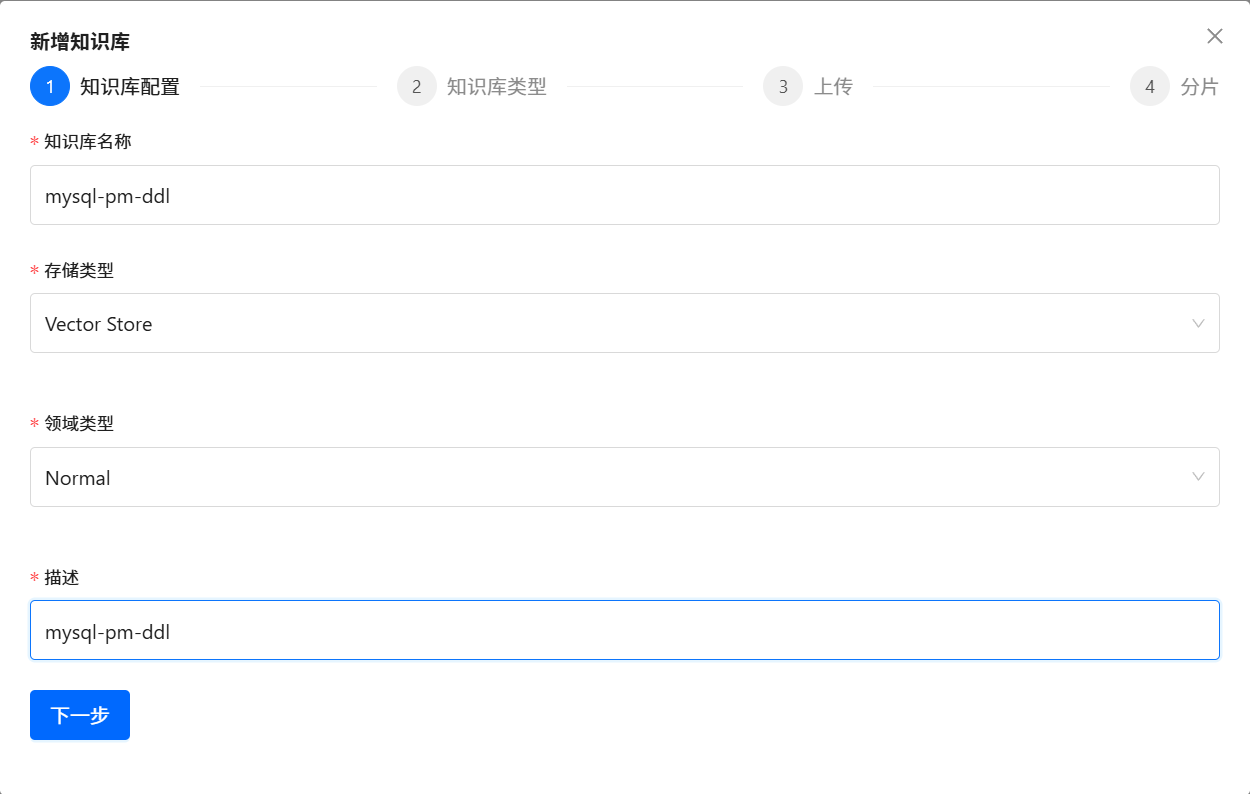
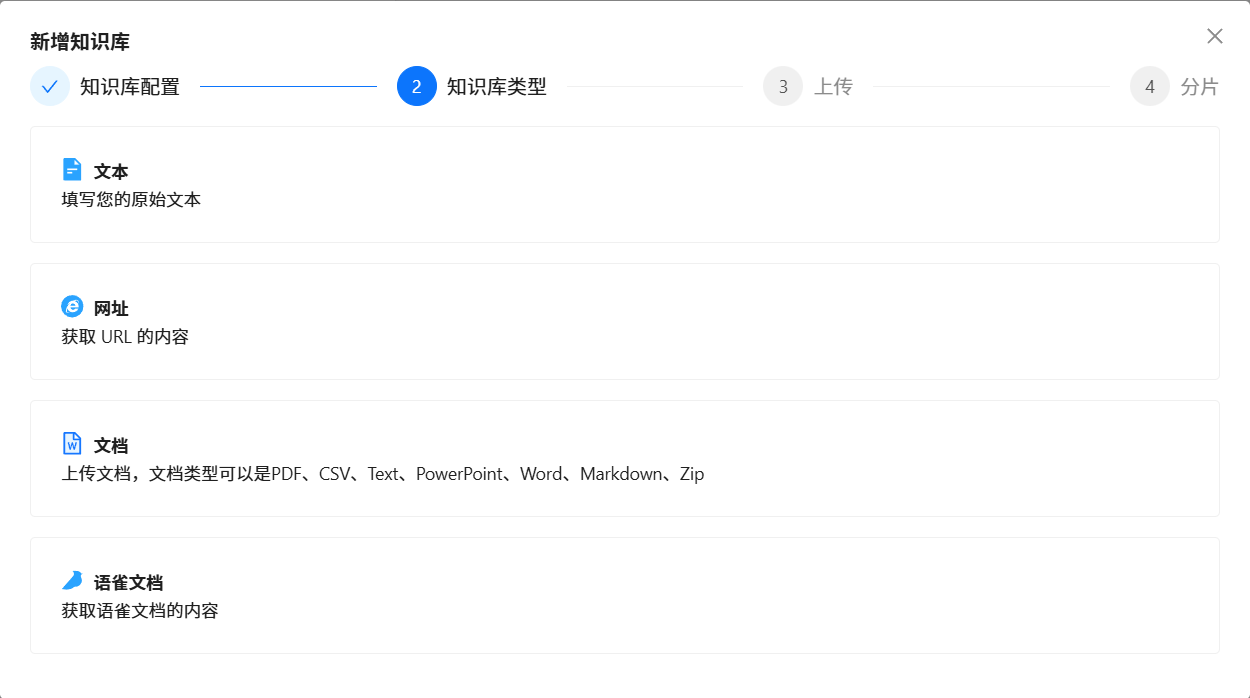
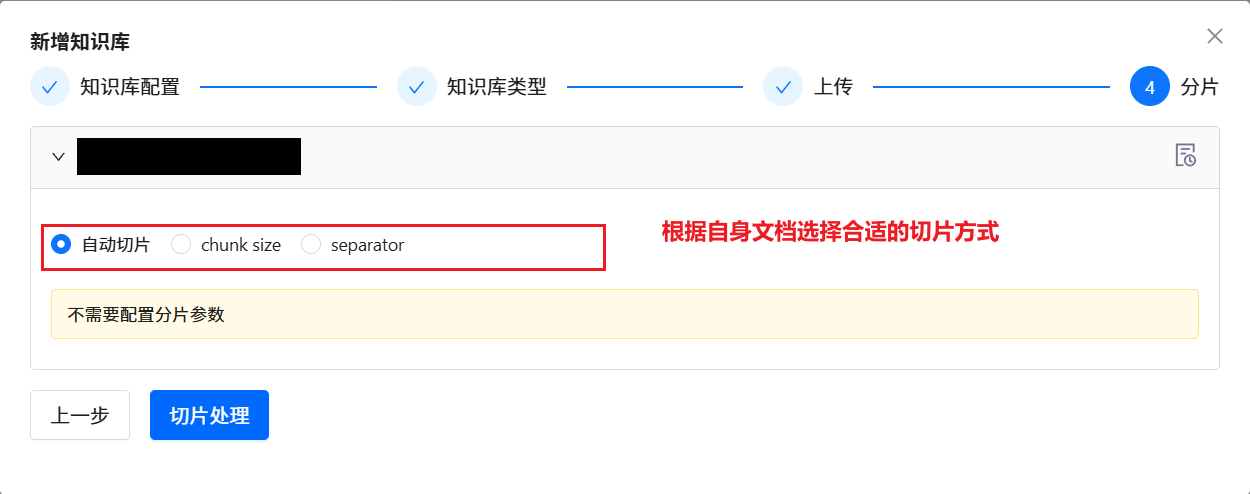
????????按照上面步驟,依次為每個單獨的數據源,維護該單獨數據源對應的三個獨立的 DDL 知識庫 、DB Description 知識庫 和 Q->SQL 知識庫。
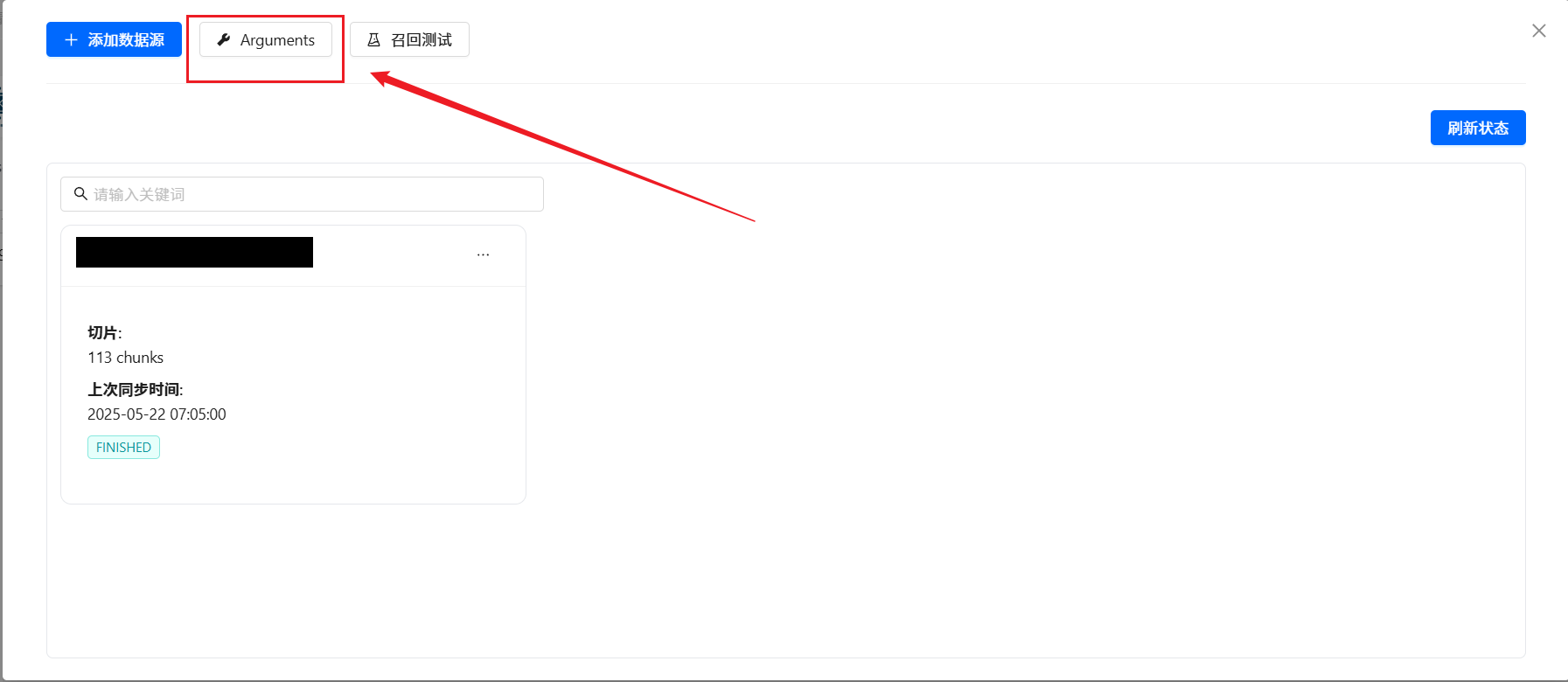
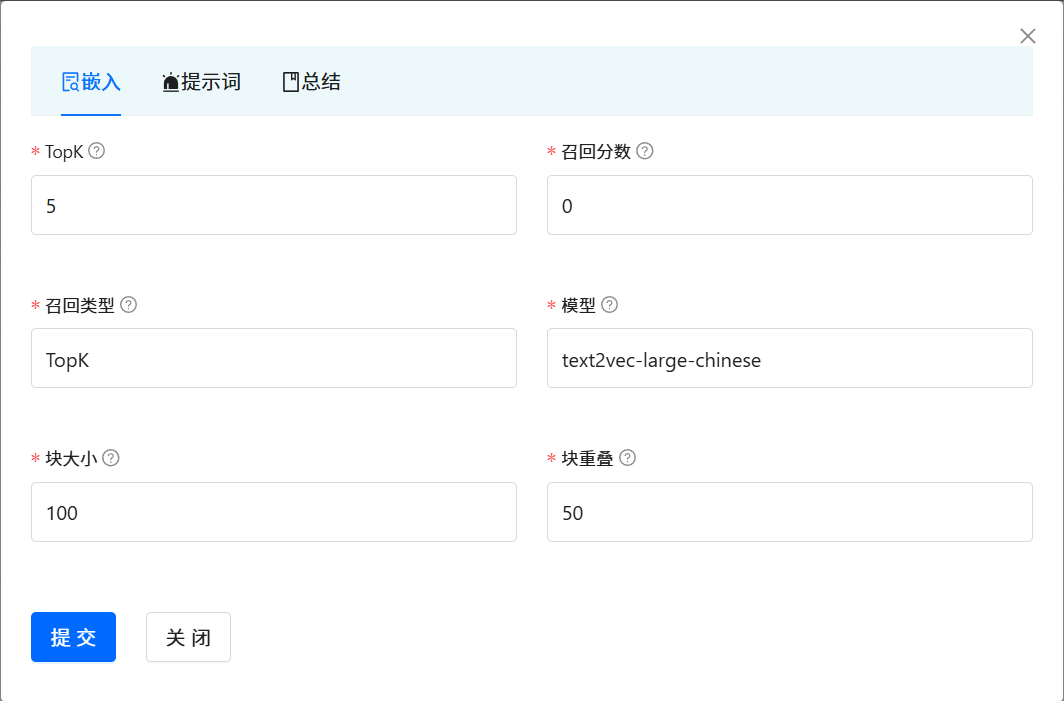
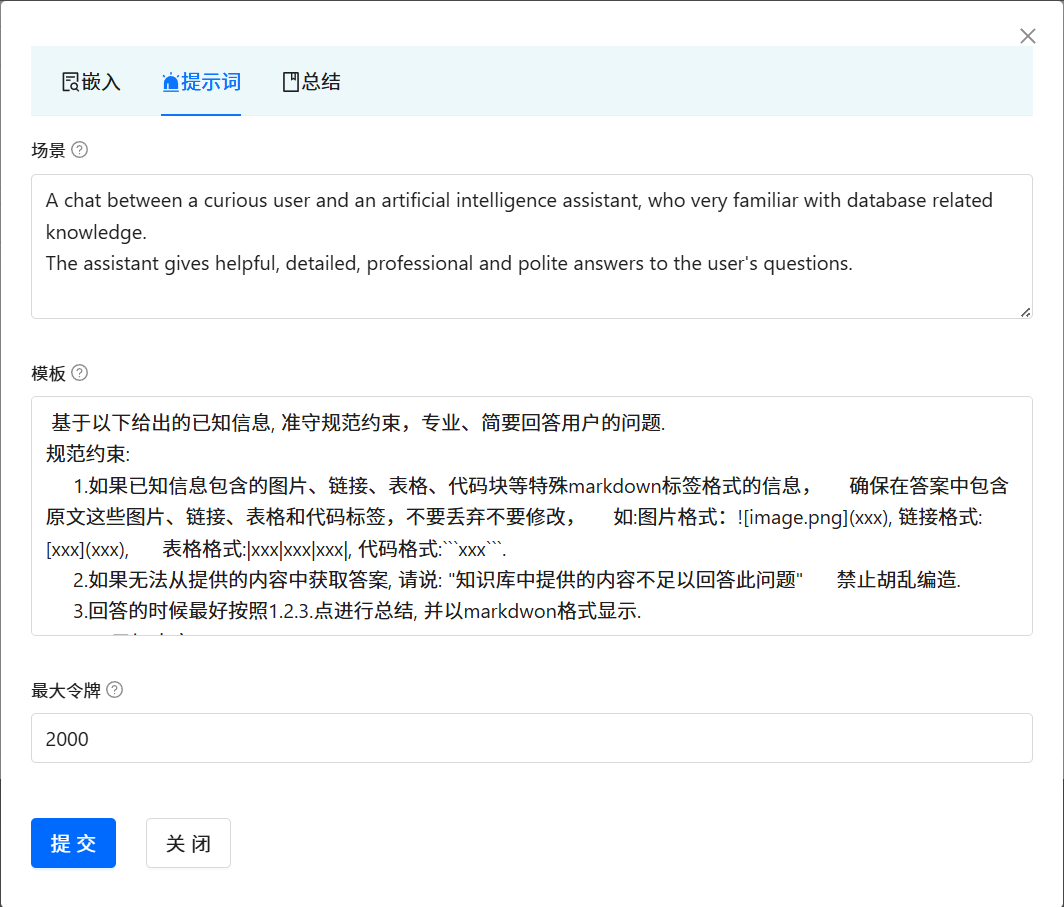
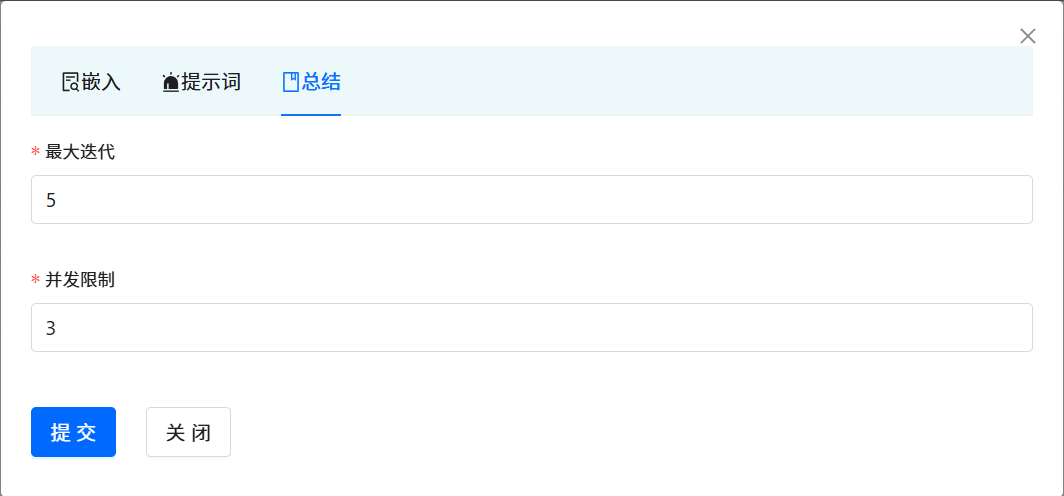
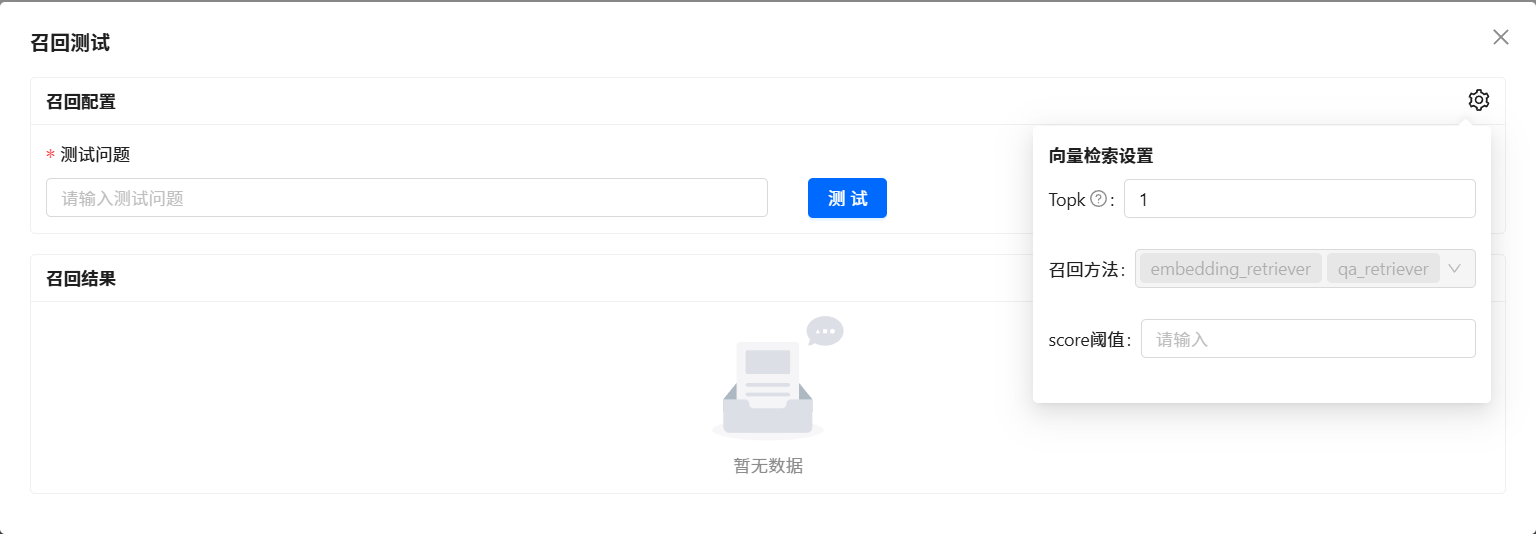
????????每一個知識庫空間支持參數定制,包括向量檢索的相關參數和知識問答提示的參數。 點擊對應的知識庫空間, ?會彈出對話框。 點擊 Arguments ?按鈕。即可進入到調參界面。

3.4 提示詞
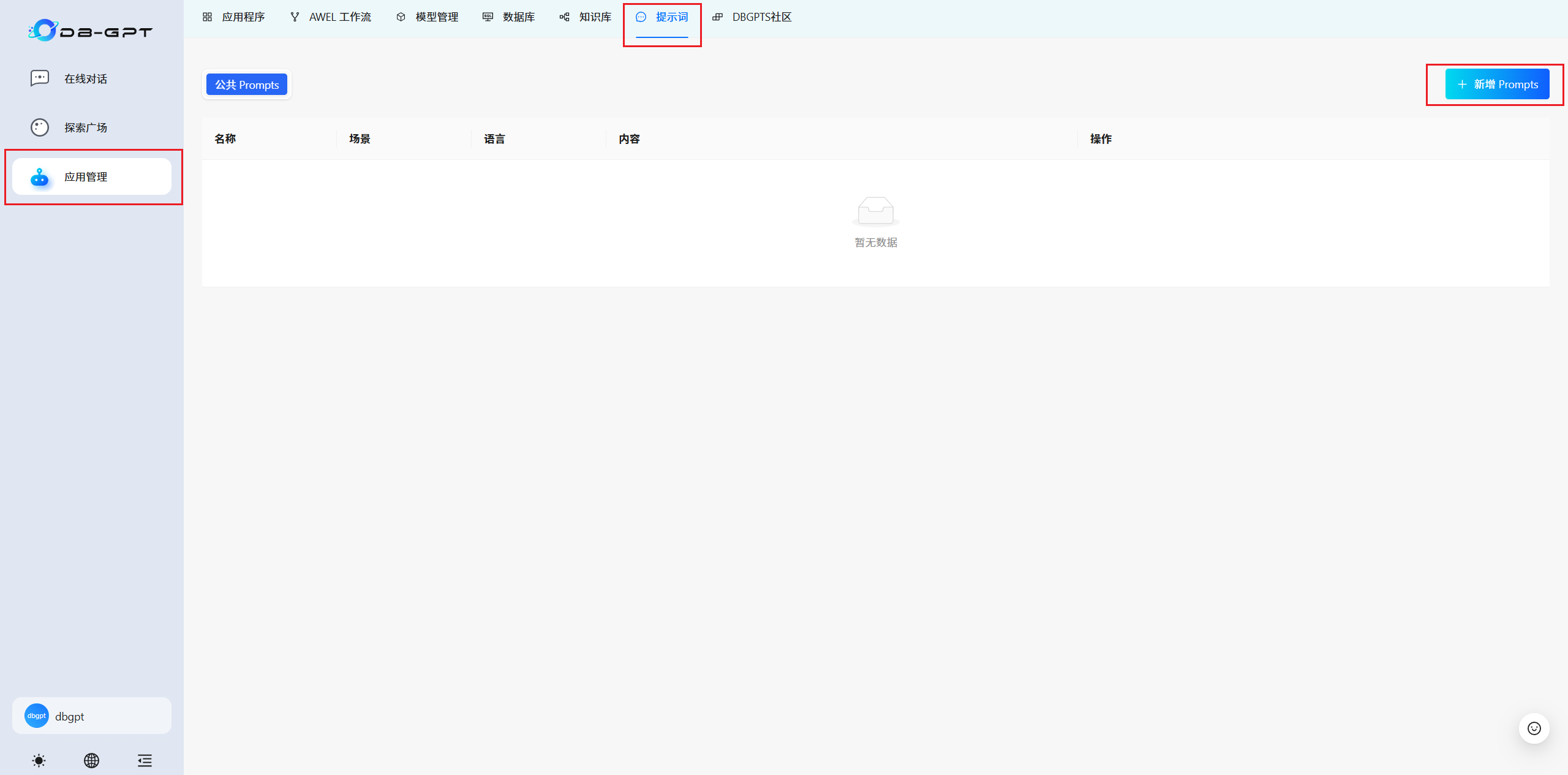
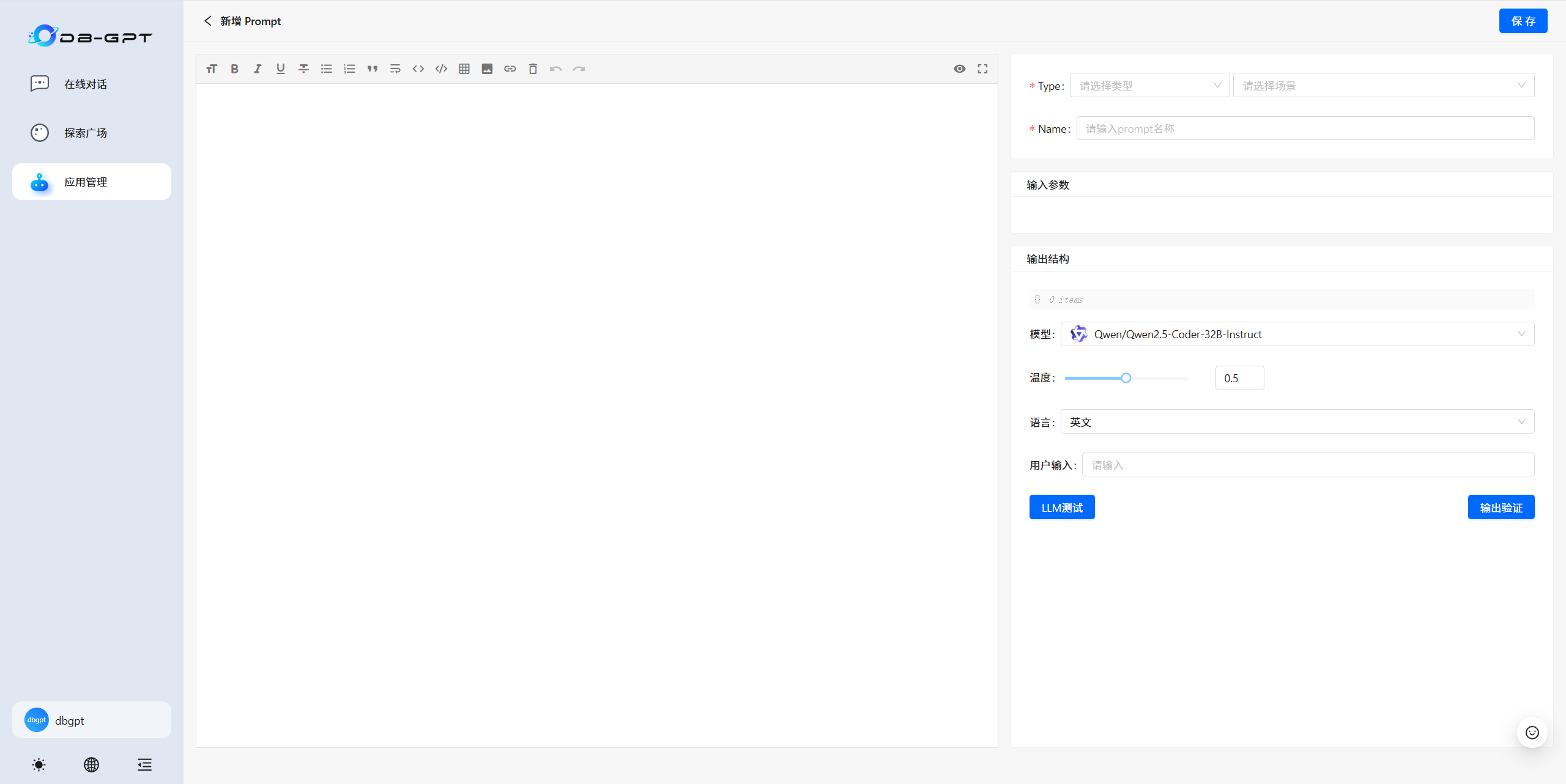
????????根據自身需要創建維護完善提示詞。
3.5 應用程序
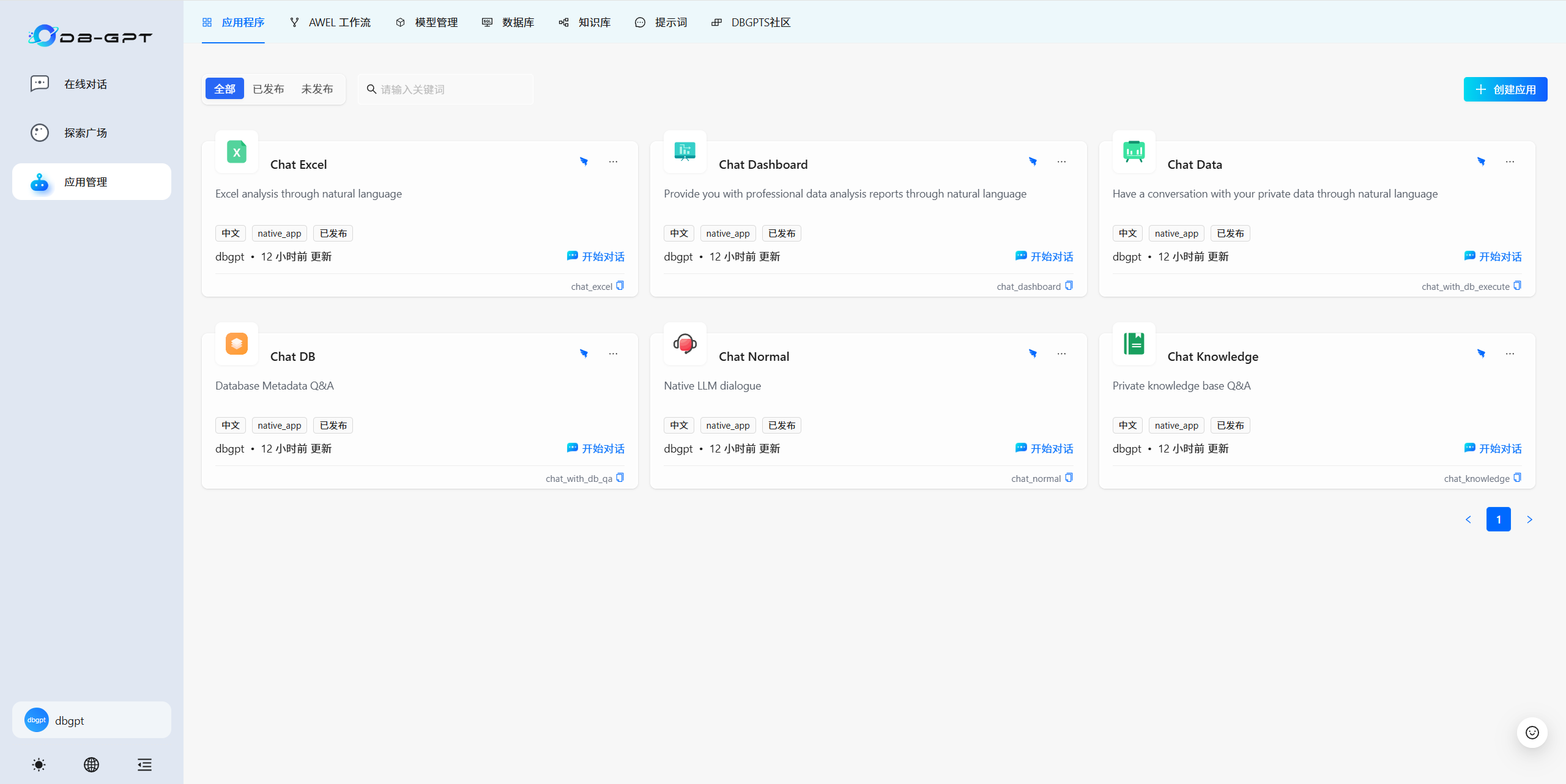
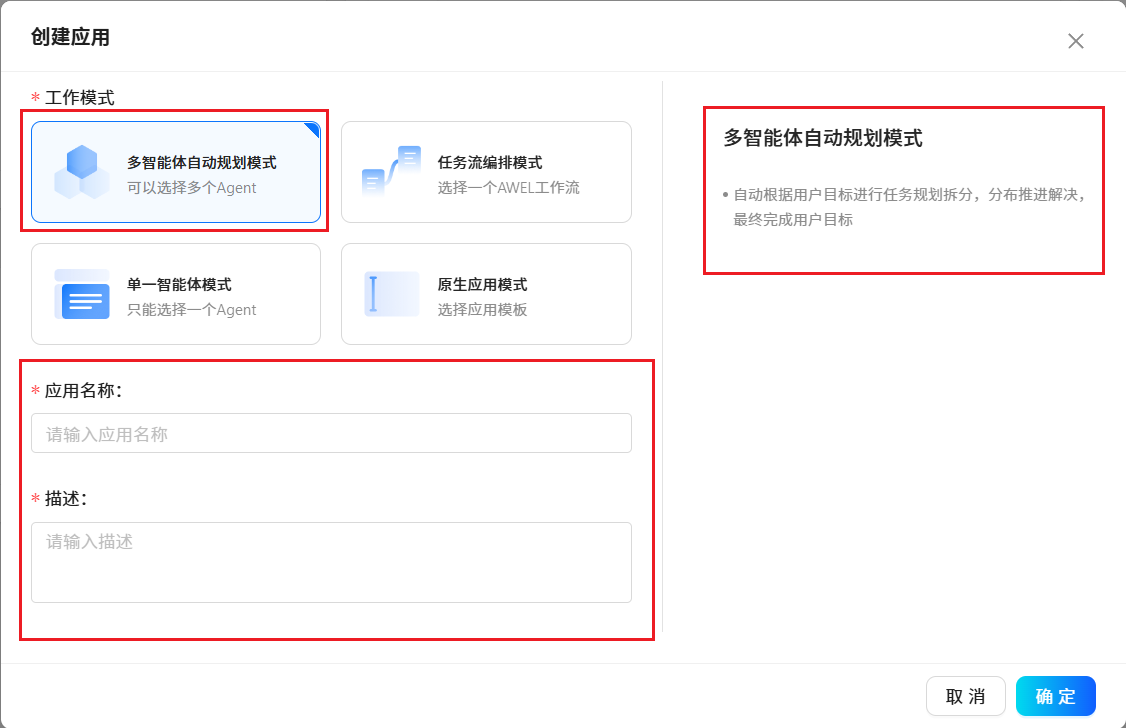
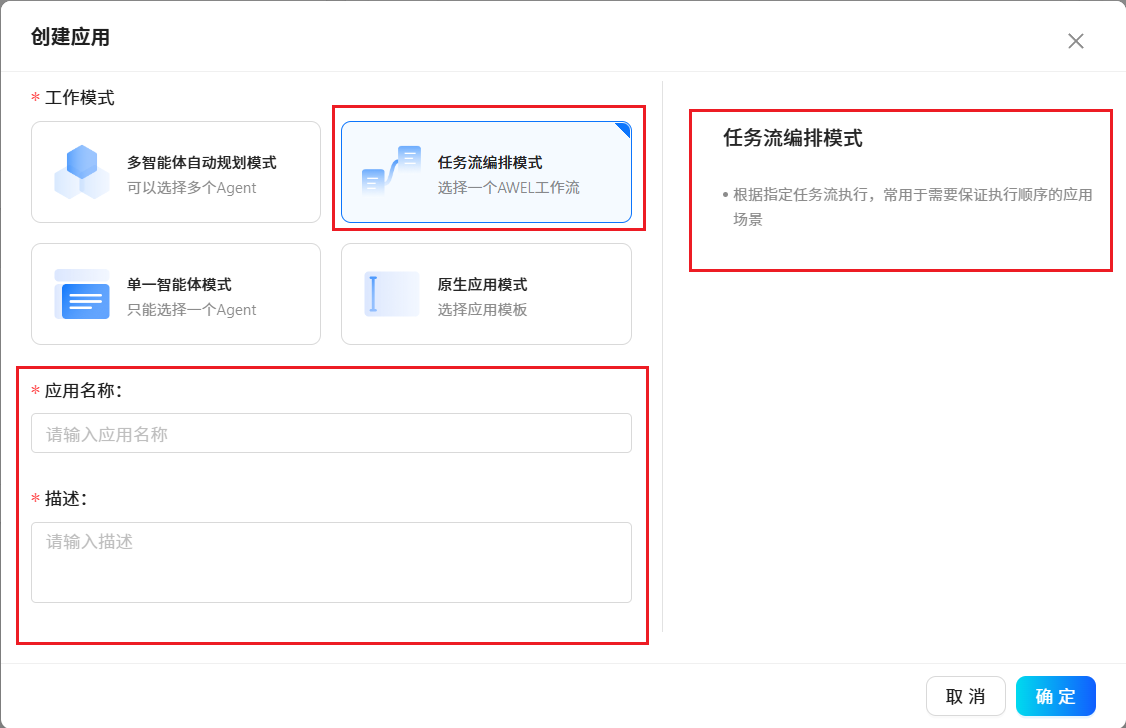
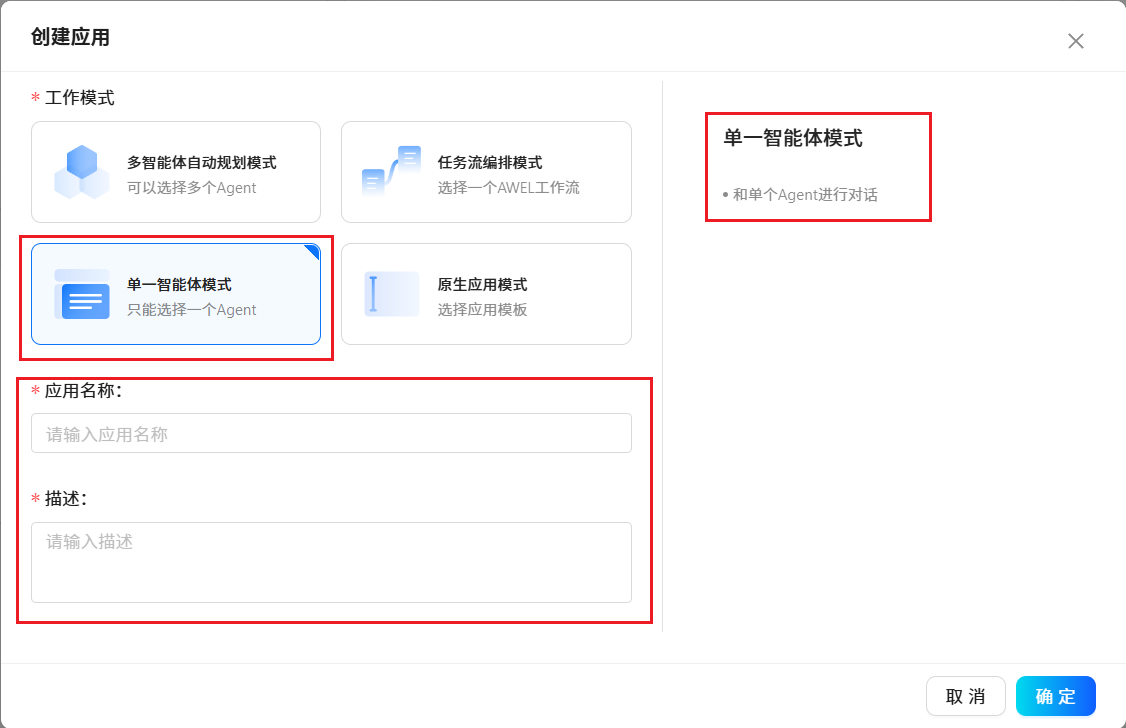
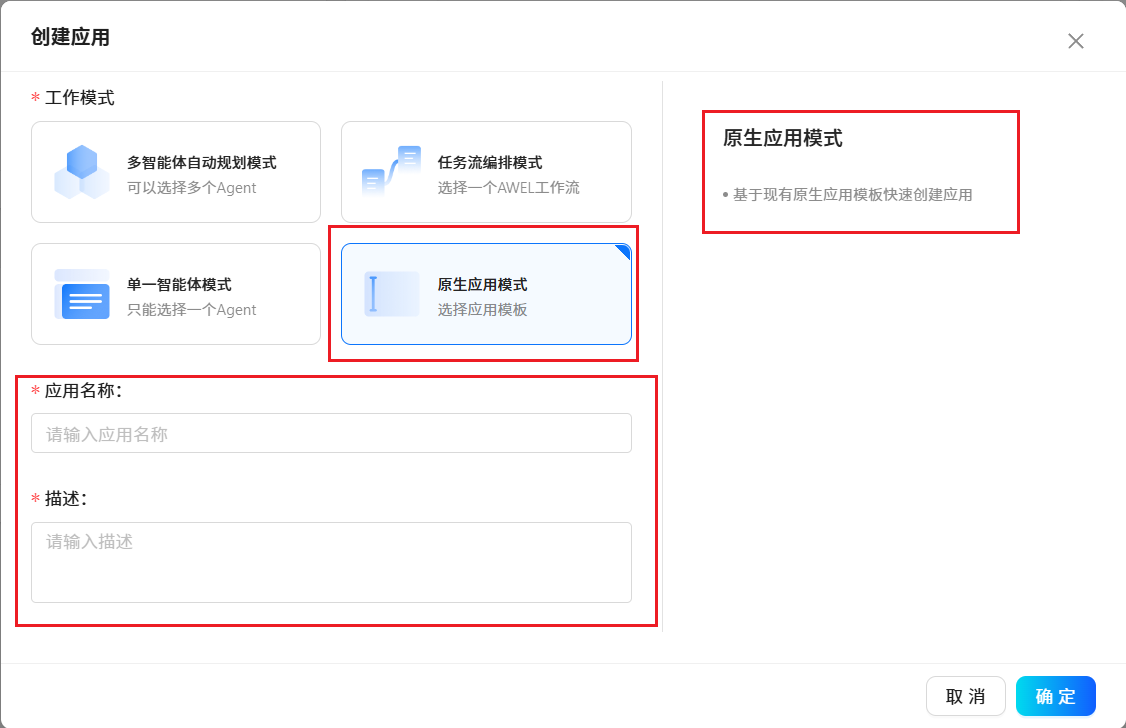
????????根據提示使用預置好的應用程序模板或創建屬于自己個性化的應用程序。
3.6 AWEL 工作流
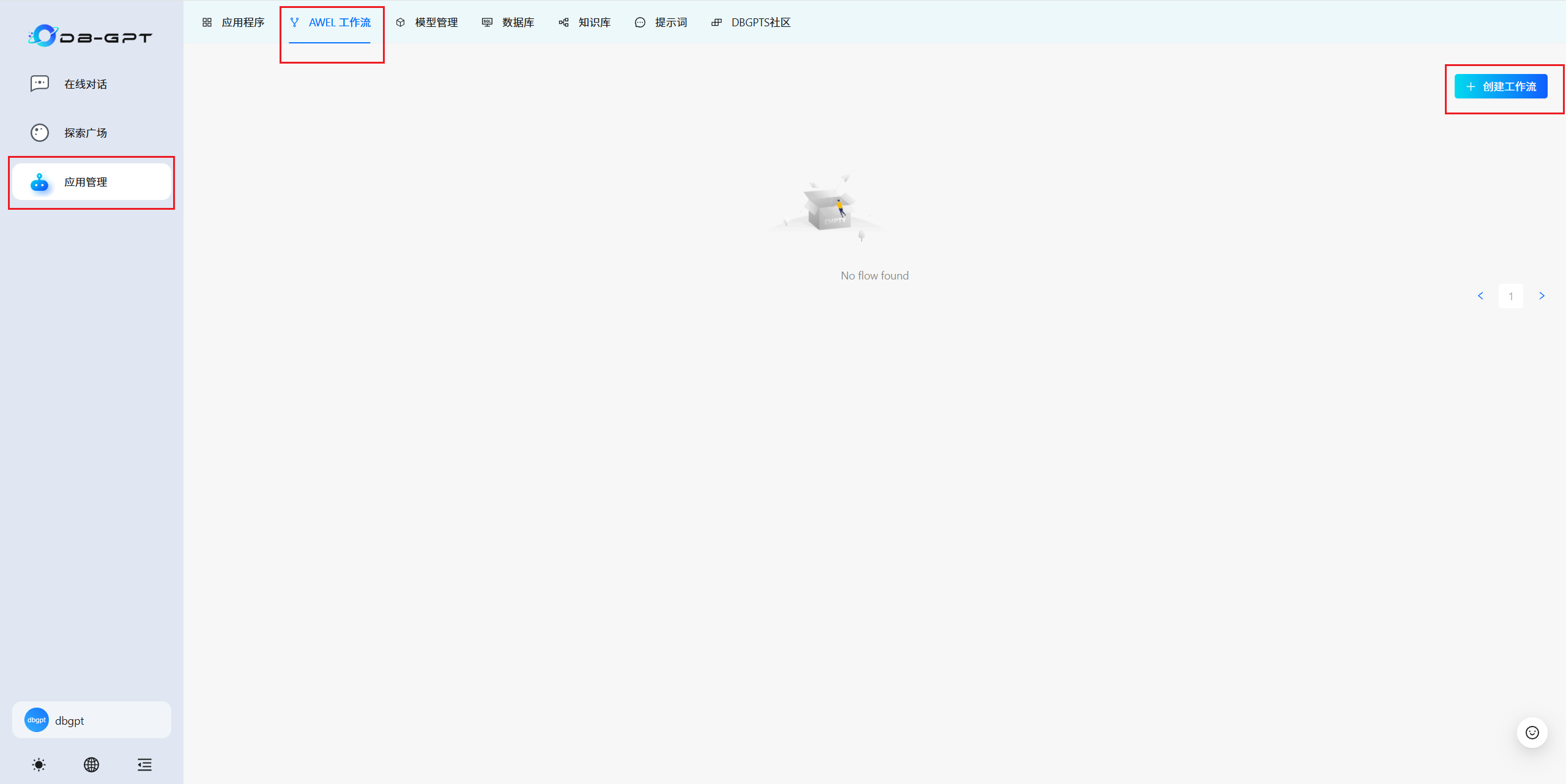
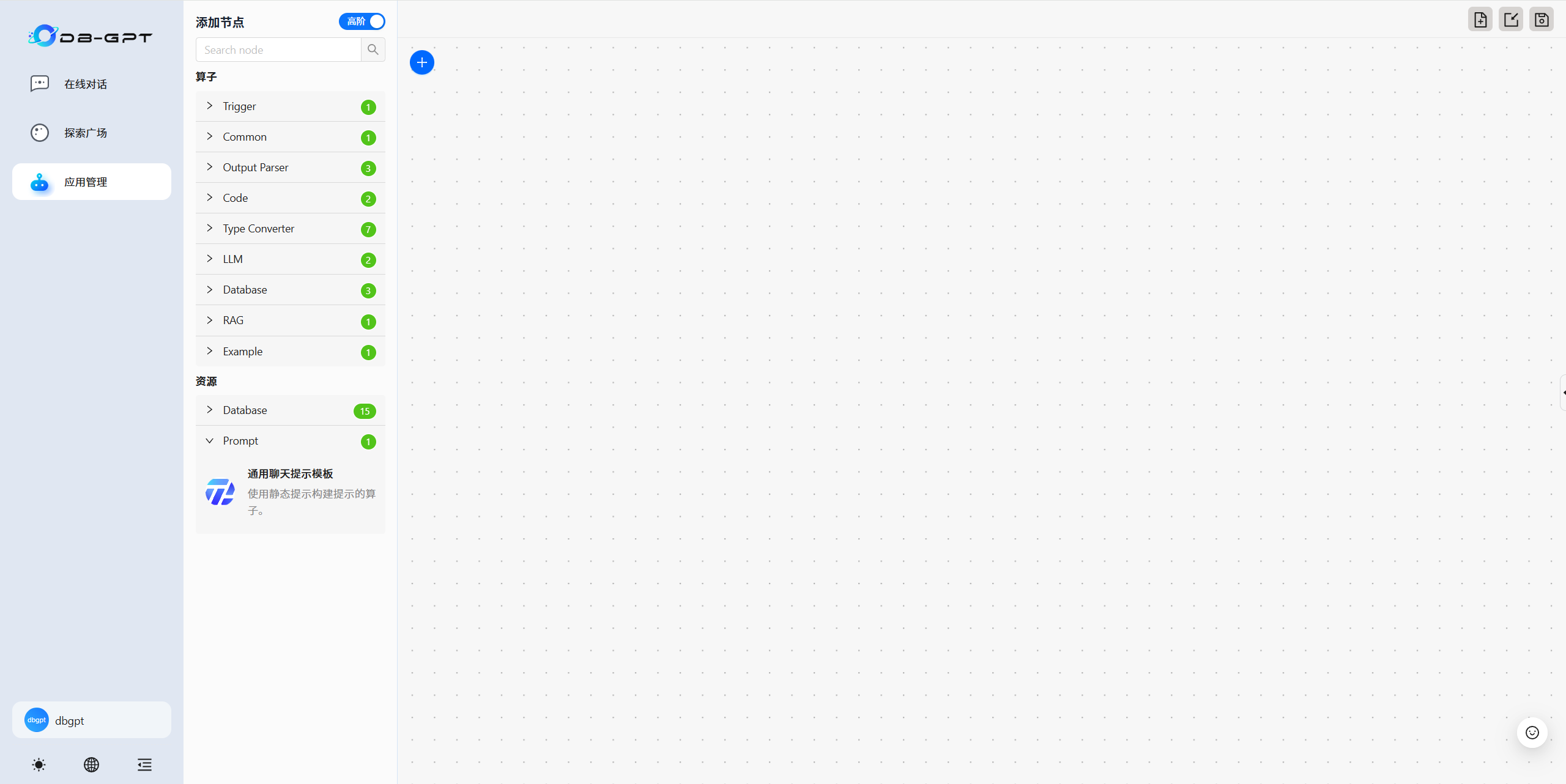
????????根據提示創建屬于自己個性化的工作流。
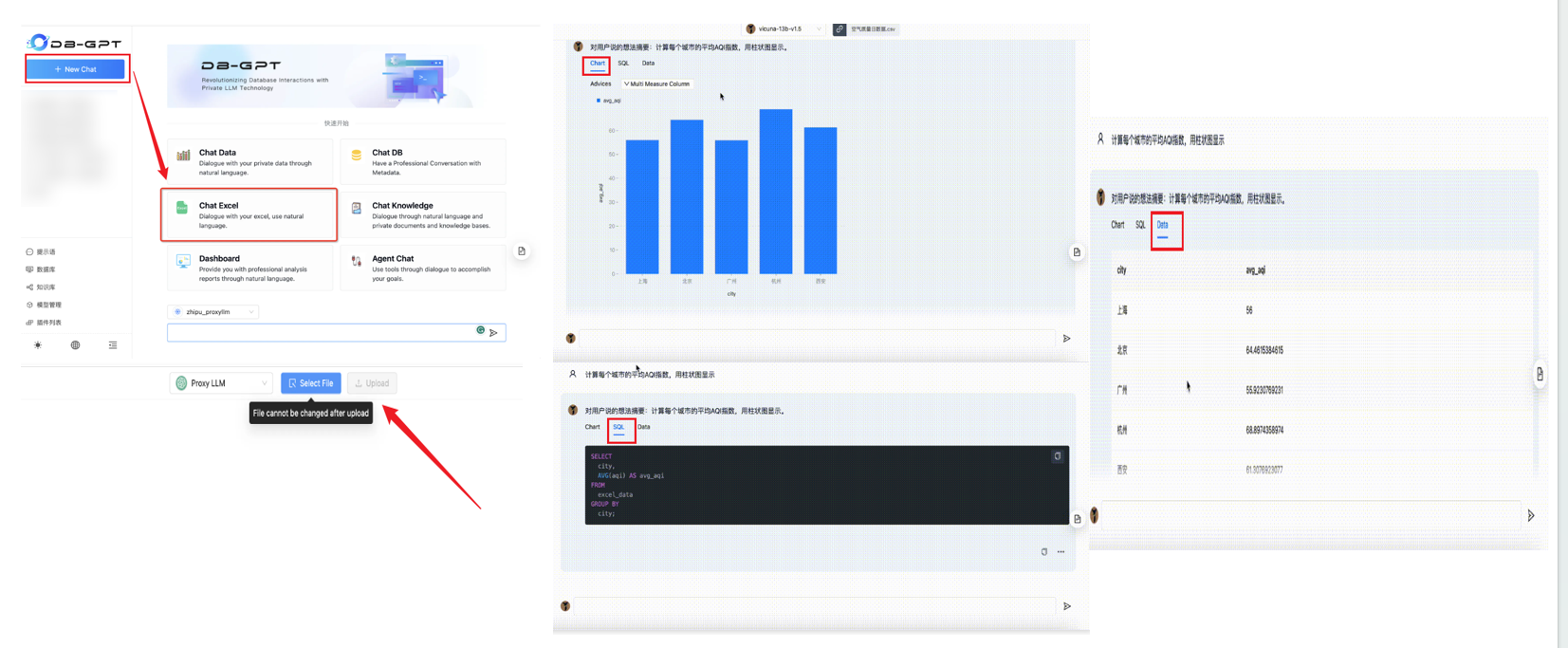
3.7 選擇對話模式開始對話
????????Excel對話(Chat Excel)是指可以通過自然語言對話的方式,實現Excel數據的解讀與分析。注意Excel文件格式轉換為.csv格式 。
????????對話儀表板(Chat Dashboard)可以通過自然語言進行智能的報表生成與分析。
????????數據對話(Chat Data)是通過自然語言與數據進行對話,目前主要是結構化與半結構化數據的對話,可以輔助做數據分析與洞察。
????????數據庫對話(Chat DB)是打造專業的數據庫專家,定位是 LLM As DBA ,可以通過與數據庫對話完成數據庫性能分析、優化等工作。
????????標準對話(Chat Normal)是用來本地LLM對話。
????????知識庫對話(Chat Knowledge)是用來基于指定知識庫進行RAG的 Q&A 問答。
????????選擇對話模式后,就可以開始對話。
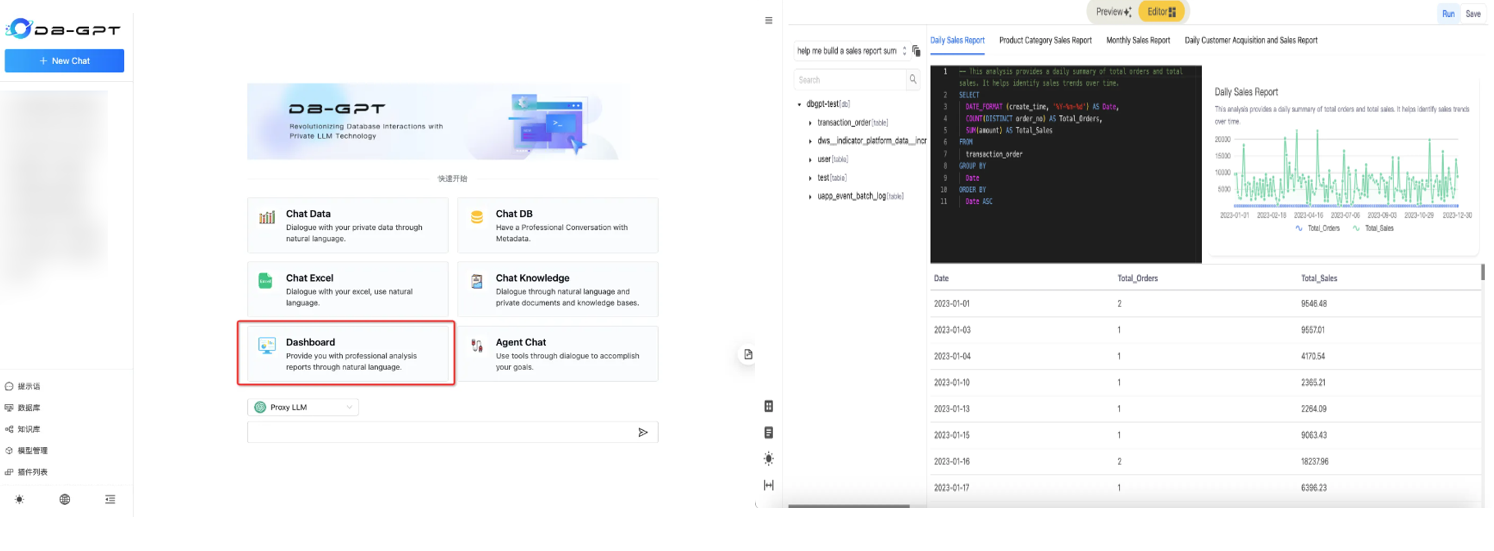
--------------------------------------
沒有自由的秩序和沒有秩序的自由,同樣具有破壞性。

————————————————
? ? ? ? ? ? ? ? ? ? ? ? ? ? 版權聲明:本文為博主原創文章,遵循 CC 4.0 BY-SA 版權協議,轉載請附上原文出處鏈接和本聲明。
? ? ? ? ? ? ? ? ? ? ? ??
原文鏈接:https://mp.csdn.net/mp_blog/creation/editor/148136773







深度講解)




:入門)






