哈希表深度剖析:原理、沖突解決與C++容器實戰
- 一. 哈希
- 1.1 哈希概念
- 1.2 哈希思想
- 1.3 常見的哈希函數
- 1.3.1 直接定址法
- 1.3.2 除留余數法
- 1.3.3 乘法散列法(了解)
- 1.3.4 平方取中法(了解)
- 1.4 哈希沖突
- 1.4.1 沖突原因
- 1.4.2 解決辦法
- 二. unordered_set / unordered_map詳細介紹
- 2.1 unordered_set使用
- 2.2 unordered_map使用
- 2.3 unordered_set vs set 對比
- 三. 最后
在當今數據處理的浪潮中,我們常常面臨海量信息的存儲與檢索挑戰。如何在海量數據中快速定位所需信息,成為提升效率的關鍵。此時,哈希技術應運而生,它如同一把神奇的鑰匙,能夠將復雜多樣的數據通過特定算法映射為簡潔的哈希值,從而實現高效的數據存儲與查詢。哈希技術不僅在計算機科學中占據重要地位,更廣泛應用于數據庫、網絡安全、分布式系統等諸多領域。今天,就讓我們深入探索哈希的奧秘,從它的基本概念、核心思想,到實際應用中的種種細節,一窺究竟。
一. 哈希
1.1 哈希概念
哈希(Hash),又稱散列,是一種將任意長度輸入數據通過特定算法映射為固定長度輸出值(哈希值)的核心技術。
1.2 哈希思想
- 核心思想:
哈希的核心思想是通過哈希函數將數據轉換為固定長度的哈希值,實現高效的數據處理與存儲。其設計遵循以下原則:
- 確定性:相同輸入必產生相同哈希值,確保結果可預測。
- 高效性:哈希函數計算速度快,適用于大規模數據處理。
- 均勻性:哈希值需均勻分布,減少不同輸入映射到同一值(哈希沖突)的概率。
個人理解:哈希使用vector容器存儲數據,就是將鍵值模上數組的大小,從而建立鍵值與位置的一一映射,不可避免的存在沖突,什么沖突?換句話說,難免會出現某些值通過上述的算法,會統一的映射到同一位置。
例如假設數組的大小為8,某些數據(如16,24等)進行映射,16%8=0,24%8=0,上述兩個數據都映射到了0這個下標,這就是沖突的表現。所以哈希函數就需要設計的合理,一個優秀的哈希函數需要盡可能減少這種沖突。
1.3 常見的哈希函數
哈希函數的種類特別繁多,常見的哈希函數如下:
1.3.1 直接定址法
函數原型:Hashi = a * key +b
- 優點:數據較為集中,均勻
- 缺點:當數據很散亂的時候,空間利用不充分,浪費空間資源
- 適應場景:當數據較為集中時,優選使用直接地址法,例如:存儲26個字母時,直接使用數組下標將鍵值進行一一映射,查詢效率O(1)。
1.3.2 除留余數法
除留余數法也稱為除法散列法思想:通過取余運算,實現鍵值與哈希值的映射。
函數原型:hashi = key % p(p是哈希表的大小,p必須小于哈希表的大小)
建議:p盡量不要取2的冪次方的數,建議p取不太接近2的整數次冪的?個質數(素數)。注意:不是不能使用,需根據特定的場景靈活使用。
- 優點:簡單易用,性能平衡。
- 缺點:哈希沖突的概率高,需借助沖突探測算法解決沖突問題。
- 使用場景:范圍不集中,數據分布散亂時,優先使用該方法。
1.3.3 乘法散列法(了解)
該哈希函數對哈希表的大小無要求,本質思想就是讓鍵值乘以一個比1小的數,取出該結果后面的小數部分即為S,再讓哈希表的大小M乘以S,這個結果一定小于M,實現鍵值與哈希值的映射。
函數原型:h(key) = floor(M × ((A × key)%1.0))
- 示例:S = A * key,M:哈希表的大小 ,這個A無明確規定,Knuth大佬認為A取黃金分割點較好。例如:假設M為1024,key為1234,A = 0.6180339887, Akey = 762.6539420558,取?數部分為0.6539420558, M×((A×key)%1.0) = 0.65394205581024 = 669.6366651392,那么h(1234) = 669。
- 優點:減少沖突,使用范圍廣,哈希表的長度靈活。
- 缺點:計算復雜,對數論要求高。
1.3.4 平方取中法(了解)
函數原型:hashi = mid(key * key)
- 適用場景:規模中等哈希,關鍵字分布均勻。
假設鍵值為 key=1234,其平方后 等于 1522756。截取中間3位227作為哈希表的鍵值。
補充:還有隨機數法,全域散列法,折疊法等,都是盡量減少哈希沖突,前面兩種最常見,也是最實用的。建議掌握它們即可。
1.4 哈希沖突
1.4.1 沖突原因
哈希值 是 鍵值 通過 哈希函數 計算得出的位置標識符,一個位置標識難以不被多個數據映射。
下面以示例來展示哈希沖突過程:
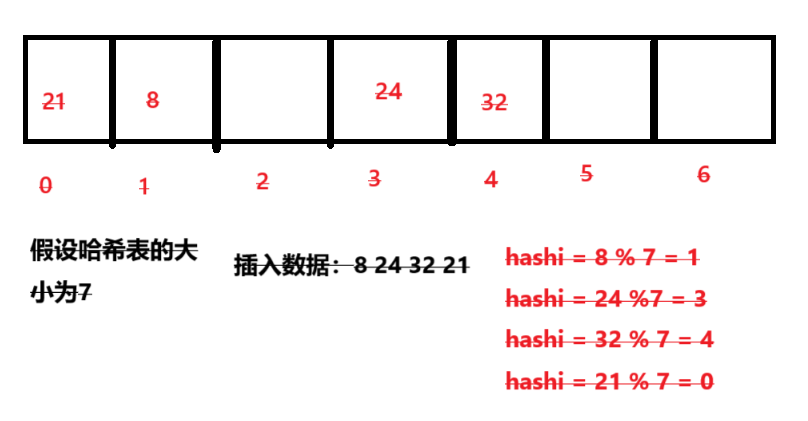
插入數據:8 24 32 21后的哈希表
在插入數據14后:
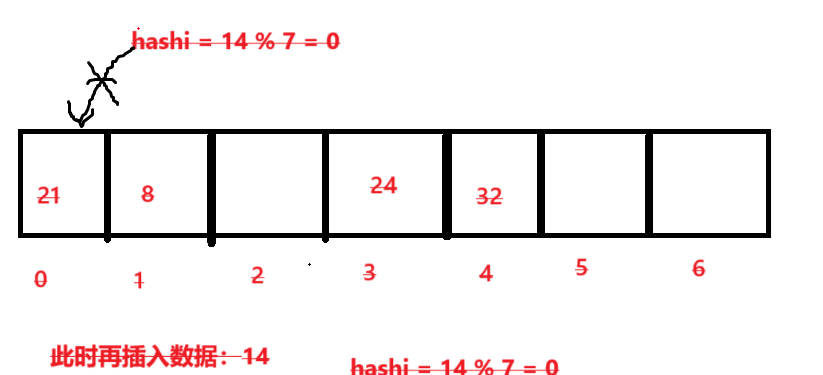
此時哈希值0位置已經有數據了,在插入就發生了哈希沖突,此時就需要解決該沖突問題。
1.4.2 解決辦法
常見的解決辦法:閉散列 與 開散列
開放地址法
很巧妙地思想:當哈希表中的實際存儲數據量 與 哈希表的長度大小比值,超過一定范圍,一般是0.7,會自動進行擴容,擴容后之前在舊的哈希表中數據需重新進行映射,可能之前沖突的數據在新表后就不沖突了,一定程度減少哈希沖突概率。所以插入數據前,哈希表的容量一定可以容納該數據。
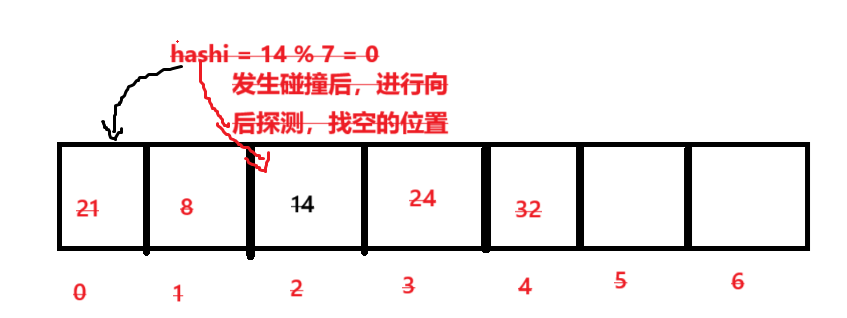
線性探測實際上可以解決哈希碰撞問題,會帶來新的問題就是:踩踏。
- 何為踩踏:
簡單點就是說一個數據本來就是存在該哈希值所在位置的,上面因為你發生了沖突,進行線性探測占有別人的位置,導致原來本應該在還位置的數據,也要進行線性探測,導致惡性循環,插入和查找效率大幅度下降。
**優化方案:**二次探測,發生沖突后,將鍵值+i的平方,再取余。碰撞的問題仍不可避免。效果不是很好。
開散列:鏈地址法,哈希桶
在哈希表中存儲一個單鏈表,發生沖突后,直接往后進行頭插,沖突問題就沒有了,也沒有踩踏問題了。
- 該方法是否需要負載因子???
不需要,因為是實際存儲的是鏈表,當存儲個數等于哈希表長度大小時,進行擴容,也需重新建立映射關系。
注意:哈希桶最壞時間復雜度O(N),平均是O(1)。
上面就是解決 哈希沖突 的常用方法,下面的文章將會用上面的理論方法模擬實現哈希表,敬請期待一下吧。
二. unordered_set / unordered_map詳細介紹
哈希表的優勢在于查找數據是否存在非常快。
前文已經提過set和map底層是用紅黑樹實現的,C++11標準使用 哈希表 重寫了,造就了今天的 unordered_set 和 unordered_map。
2.1 unordered_set使用
- 示例代碼:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<unordered_set>
#include<vector>
using namespace std;int main()
{vector<int> arr = { 2,5,7,1,1,9,8,10 };unordered_set<int> s(arr.begin(), arr.end());//迭代器遍歷cout << "迭代器遍歷后結果: ";unordered_set<int>::iterator it = s.begin();while (it != s.end()){cout << *it<<" ";++it;}cout << endl;//范圍for遍歷cout << "范圍for遍歷后結果: ";for (auto ch : s){cout << ch <<" ";}cout << endl;//負載因子cout << "當前s的負載因子,s.load_factor():" << s.load_factor() << endl;cout << "s最大負載因子, s.max_load_factor():" << s.max_load_factor() << endl;//判空 求大小cout << "======================" << endl;cout << "s.empty(): "s.empty() << endl;cout << "s.size(): "s.size() << endl;cout << "s.max_size(): "s.max_size() << endl;//插入元素cout << "======================" << endl;cout<<"s.insert(100): "<<endl;//pair<iterator, bool> ret = s.insert(100);error,迭代器需指定類域pair<unordered_set<int>::iterator, bool> ret = s.insert(100);cout << "插入后,對返回后的迭代器進行*后結果:";cout << *ret.first << endl;//查找,統計unordered_set<int>::iterator ret1 = s.find(1);//返回值是迭代器cout << "s.find(1): " << *ret1 << endl;cout << "s.count(1): " << s.count(1) << endl;//統計1出現的次數,默認會去重//刪除cout << "======================" << endl;cout << "s刪除10前: ";for (auto ch : s) cout << ch <<" ";cout << endl;s.erase(10);cout << "s刪除10后: ";for (auto ch : s) cout << ch <<" ";cout << endl;//交換unordered_set<int> s1;s1.swap(s);cout << "s1.clear()前:";for (auto ch : s1) cout << ch<<" ";cout << endl;cout << "交換后的s:";//數據清空了for (auto ch : s) cout << ch;cout << endl;//清理s1.clear();//清理s1后,數據也為空了cout << "對s1進行s1.clear()后: ";for (auto ch : s1) cout << ch;return 0;
}
**注意:**迭代器需要指定類域,否則會報錯。
原因:因為迭代器是容器類的內部類型,須通過類域進行限定。
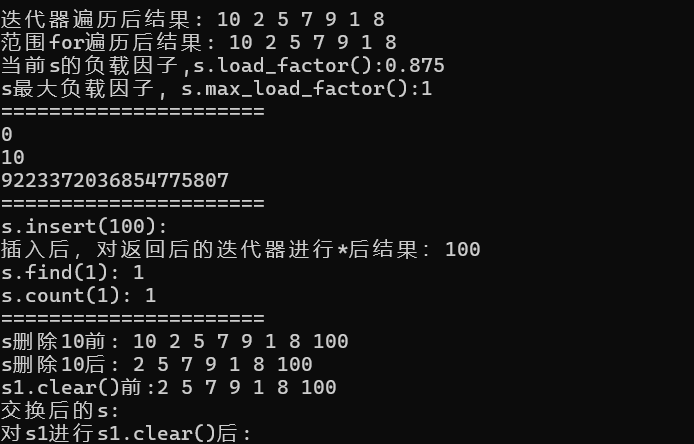
- 輸出結果:
2.2 unordered_map使用
- 示例代碼:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<unordered_map>
#include<vector>
#include<string>
using namespace std;int main()
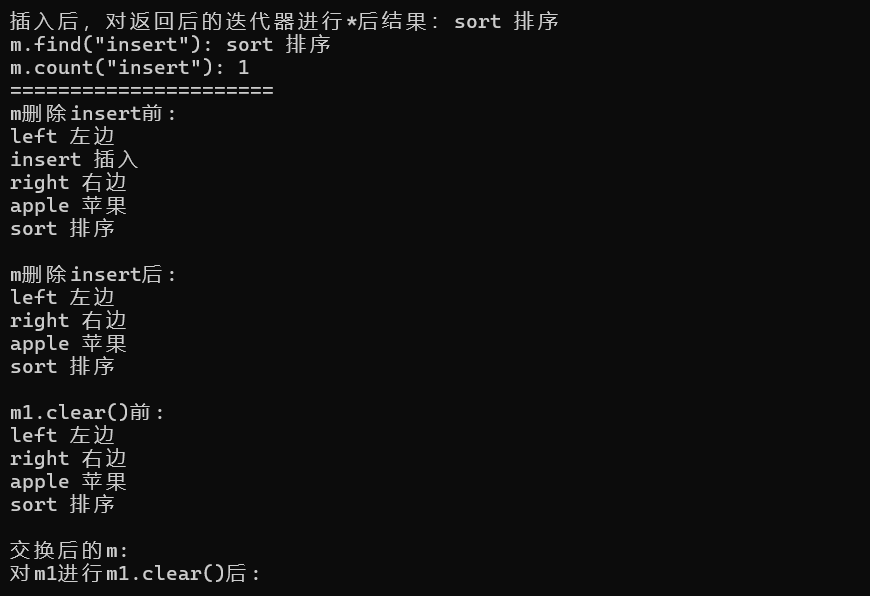
{//map使用pair存儲數據vector<pair<string, string>> arr{ make_pair("insert","插入"),make_pair("right","右邊") ,make_pair("apple","蘋果"),make_pair("left","左邊") };unordered_map<string, string> m(arr.begin(), arr.end());//迭代器遍歷cout << "迭代器遍歷后結果: " << endl;unordered_map<string, string>::iterator it = m.begin();while (it != m.end()){cout << it->first << " " << it->second << endl;++it;}cout << endl;//范圍for遍歷cout << "范圍for遍歷后結果: " << endl;for (auto ch : m){cout << ch.first << " " << ch.second;cout << endl;}cout << endl;//負載因子cout << "當前m的負載因子,m.load_factor():" << m.load_factor() << endl;cout << "m最大負載因子, m.max_load_factor():" << m.max_load_factor() << endl;//判空 求大小cout << "======================" << endl;cout << "m.empty(): "<<m.empty() << endl;cout << "m.size(): "<<m.size() << endl;cout << "m.max_size(): " << m.max_size() << endl;//插入元素cout << "======================" << endl;//cout << "m.insert(make_pair("sort","排序")): " << endl;errorcout << "m.insert(make_pair(\"sort\",\"排序\")): " << endl;pair<unordered_map<string, string>::iterator, bool> ret = m.insert(make_pair("sort", "排序"));cout << "插入后,對返回后的迭代器進行*后結果:";cout << ret.first->first << " " << ret.first->second << endl;//查找,統計unordered_map<string,string>::iterator ret1 = m.find("insert");//返回值是迭代器cout << "m.find(\"insert\"): " << ret.first->first << " " << ret.first->second << endl;cout << "m.count(\"insert\"): " << m.count("insert") << endl;//刪除cout << "======================" << endl;cout << "m刪除insert前: " << endl;for (auto ch : m){cout << ch.first << " " << ch.second;cout << endl;}cout << endl;m.erase("insert");cout << "m刪除insert后: " << endl;for (auto ch : m){cout << ch.first << " " << ch.second;cout << endl;}cout << endl;//交換unordered_map<string,string> m1;m1.swap(m);cout << "m1.clear()前:" << endl;for (auto ch : m1){cout << ch.first << " " << ch.second;cout << endl;}cout << endl;cout << "交換后的m:";//數據清空了for (auto ch : m){cout << ch.first << " " << ch.second;cout << endl;}cout << endl;//清理m1.clear();//清理m1后,數據也為空了cout << "對m1進行m1.clear()后: " << endl;for (auto ch : m1){cout << ch.first << " " << ch.second;cout << endl;}cout << endl;return 0;
}
注意:cout << “m.insert(make_pair(“sort”,“排序”)): " << endl; 這個是錯誤的

規則:要在字符串內包裹字符串必須使用雙反斜杠,編譯器會將這個 -> “m.insert(make_pair(”
作為字符串,后續的 -> sort”,“排序”)): " 會被當成無效字符串。最佳實踐:在字符串開始前加 \ 和 字符換結束后加 \ 。可以解決該問題。
正確寫法:
cout << "m.insert(make_pair(\"sort\",\"排序\")): " << endl;//true
這個問題也是小編第一次碰到,可能是小編實力還是不夠,很多大佬對這問題如同技壓群雄,既然碰到了,小編就將第一次記錄艱難險阻過程。
- 輸出結果:
2.3 unordered_set vs set 對比
相似點:
- 兩者增刪查的使用基本一致。
- 負載因子,交換接口一模一樣。
不同點:
- key值差異:因為set的底層是紅黑樹實現的,所以需要key支持嚴格的強弱對比,需要維護有序性。unordered_set底層是哈希表實現的,插入在哪里需要嚴格的等于比較,因為要取余,所以key值必須是整數,不是整數需通過仿函數支持比較。
- 迭代器差異:set的 iterator 是雙向迭代器,因為是樹,樹這個數據結構本身就支持正反向遍歷。unordered_set的 iterator 是單向迭代器,因為里面是用單鏈表存儲數據,單鏈表本身就不支持反向遍歷。
- 性能差異:哈希表的增刪查效率很快,時間復雜度為O(1),而紅黑樹性能沒有哈希表快,時間復雜度為O(logN)。
光說無憑:下面用一段代碼進行測試。
#include <iostream>
#include <iomanip>
#include <random>
#include <string>using namespace std;// 隨機數生成配置
struct PerformanceData {int insert;int erase;int find;
};PerformanceData generate_random_performance() {random_device rd;mt19937 gen(rd());uniform_int_distribution<> dist(10, 200); // 生成10-200ns范圍內的隨機值return {dist(gen), // 插入操作dist(gen), // 刪除操作dist(gen) // 查找操作};
}// 格式化輸出表格
void print_table(const string& header, const string& col1, const string& col2) {cout << "\n+" << string(50, '-') << "+\n";cout << "| " << left << setw(48) << header << " |\n";cout << "+" << string(50, '-') << "+\n";cout << "| " << left << setw(24) << col1 << "| " << left << setw(24) << col2 << " |\n";cout << "+" << string(50, '-') << "+\n";
}int main() {// 生成隨機性能數據PerformanceData set_perf = generate_random_performance();PerformanceData unordered_perf = generate_random_performance();// 輸出對比表格print_table("對比維度", "set", "unordered_set");// 底層結構print_table("底層數據結構", "紅黑樹(自動排序)", "哈希表(無序存儲)");// Key要求print_table("Key要求","需要嚴格弱序比較(默認使用<操作符)","需要哈希函數和相等比較(==操作符)");// 迭代器特性print_table("迭代器類型","雙向迭代器(支持反向遍歷)","單向前向迭代器");// 性能對比(帶隨機數)cout << "\n" << setw(50) << setfill('=') << "" << endl;cout << "| " << left << setw(22) << "操作類型" << "| " << setw(12) << "set" << "| " << setw(12) << "unordered_set" << " |\n";cout << "|" << string(48, '-') << "|\n";auto print_row = [](const string& op, int a, int b) {cout << "| " << left << setw(22) << op << "| " << setw(12) << a << "ns"<< "| " << setw(12) << b << "ns" << " |\n";};print_row("插入操作", set_perf.insert, unordered_perf.insert);print_row("刪除操作", set_perf.erase, unordered_perf.erase);print_row("查找操作", set_perf.find, unordered_perf.find);cout << "+" << string(50, '-') << "+\n";// 總結輸出cout << "\n對比總結:\n"<< "1. 當需要元素有序時選擇set,需要快速查找時優先選unordered_set\n"<< "2. unordered_set在平均情況下性能更優,但最壞情況可能退化到O(n)\n"<< "3. 兩者都要求key唯一,但實現機制不同導致性能特征差異\n";return 0;
}
輸出結果:
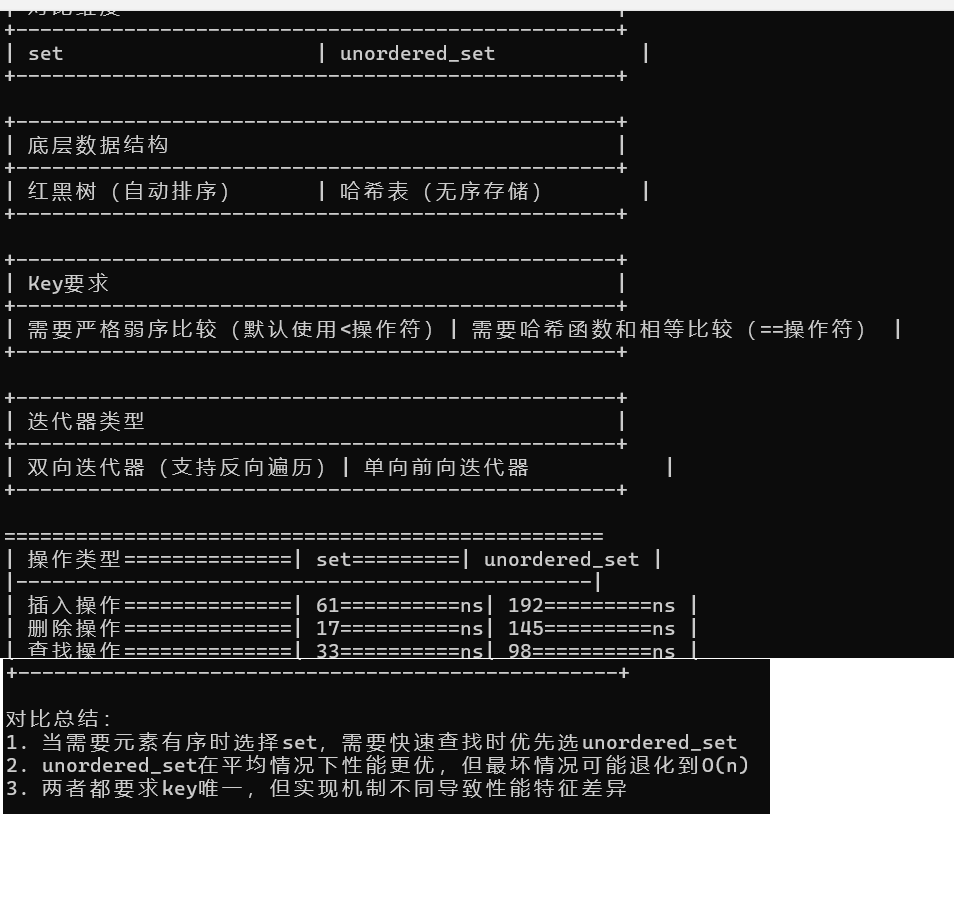
從結果可以看出哈希表在增刪查都比紅黑樹略勝一籌。
注:unordered_map 和 map 與上述兩個容器一模一樣,小編不再重復說了。
說明:上述四個容器都不支持冗余,即不允許插入相同的key值,插入已經存在的值會插入失敗。
如果要支持冗余下面這兩個容器:unordered_multiset 和 unordered_multimap 允許插入相同的key值。其它的相似點與差異以上述描述的差異基本一致的。但該兩個容器遍歷的順序不是有序的了。
- 示例代碼(測試性能):
#include <iostream>
#include <unordered_set>
#include <unordered_map>
#include <ctime>
#include <cstdlib>using namespace std;const int KEY_RANGE = 1000;
const int DATA_SIZE = 10000;void simple_performance_test(const string& container_name) {// 初始化隨機數srand(time(NULL));// 記錄開始時間clock_t start = clock();// 創建測試容器if (container_name == "unordered_multiset") {unordered_multiset<int> container;for (int i = 0; i < DATA_SIZE; ++i) {int key = rand() % KEY_RANGE;container.insert(key);}} else if (container_name == "unordered_multimap") {unordered_multimap<int, string> container;for (int i = 0; i < DATA_SIZE; ++i) {int key = rand() % KEY_RANGE;container.insert({key, "test"});}}// 記錄結束時間clock_t end = clock();double duration = double(end - start) / CLOCKS_PER_SEC * 1000;// 輸出簡單性能報告cout << container_name << " 插入耗時: " << duration << "ms" << endl;
}int main() {// 容器特性演示cout << "=== 容器特性演示 ===" << endl;// unordered_multiset 示例{unordered_multiset<int> ums;ums.insert(42);ums.insert(42);cout << "unordered_multiset 重復值測試: 大小=" << ums.size() << endl;}// unordered_multimap 示例{unordered_multimap<int, string> umm;umm.insert({1, "測試"});umm.insert({1, "數據"});cout << "unordered_multimap 重復key測試: 大小=" << umm.size() << endl;}// 簡化性能測試cout << "\n=== 性能對比測試 ===" << endl;simple_performance_test("unordered_multiset");simple_performance_test("unordered_multimap");// 特性總結cout << "\n=== 關鍵特性 ===" << endl;cout << "1. 允許重復key值\n"<< "2. 平均O(1)復雜度操作\n"<< "3. 無序存儲\n";return 0;
}
- 輸出結果:

可以看出unordered_multiset插入時間 比 unordered_multimap 更優。
三. 最后
本文主要介紹了哈希技術及其在C++中的應用。哈希通過哈希函數將數據映射為固定長度的值,常見的哈希函數包括直接定址法、除留余數法、乘法散列法和平方取中法。哈希沖突是不可避免的,但可以通過開放地址法(如線性探測、二次探測)和開散列(鏈地址法)等方法解決。C++中的unordered_set和unordered_map基于哈希表實現,具有快速查找、插入和刪除的特點,但不支持元素有序。與set和map相比,它們的性能在平均情況下更優,但最壞情況下可能退化。此外,unordered_multiset和unordered_multimap允許重復鍵值,適用于需要存儲重復數據的場景。


在線預覽)

)



)










