一、概述
Remote Dictionary Server(遠程字典服務)是完全開源的,使用ANSIC語言編寫遵守BSD協議,是一個高性能的Key-Value數據庫提供了豐富的數據結構,例如String、Hash、List、Set、sortedset等等。數據是存在內存中的,同時Redis文持事務、持久化、LUA腳本、發布/訂閱、緩存海汰、流技術等多種功能特性提供了主從模式、Redis Sentinel和Redis Cluster集群架構方案
1. Redis的好處
- 運行在內存上,效率高
- 除了K-V數據,其他數據也很類型豐富
- 自帶持久化功能,雖然運行在內存中,數據也會被保持在硬盤里
- 可以多臺Redis服務器鏈接配合,處理能力強
- 可以有類似Git同款的master-slave主從數據儲存
二、Redis 十大數據類型
類比javaSE的HashMap,鍵固定,但是對應的值的類型不固定
1. 總述
- String(字符串)
string是redis最基本的類型,一個key對應一個value。
string類型是二進制安全的,意思是redis的string可以包含任何數據,比如jpg圖片或者序列化的對象 。
string類型是Redis最基本的數據類型,一個redis中字符串value最多可以是512M
- List(列表)
Redis列表是簡單的字符串列表,按照插入順序排序。你可以添加一個元素到列表的頭部(左邊)或者尾部(右邊)
它的底層實際是個雙端鏈表,最多可以包含 2^32 - 1 個元素 (4294967295, 每個列表超過40億個元素)
- Redis hash
Redis hash 是一個 string 類型的 field(字段) 和 value(值) 的映射表,hash 特別適合用于存儲對象。
Redis 中每個 hash 可以存儲 2^32 - 1 鍵值對(40多億)
- Set(集合)
Redis 的 Set 是 String 類型的無序集合。集合成員是唯一的,這就意味著集合中不能出現重復的數據,集合對象的編碼可以是 intset 或者 hashtable。
Redis 中Set集合是通過哈希表實現的,所以添加,刪除,查找的復雜度都是 O(1)。
集合中最大的成員數為 2^32 - 1 (4294967295, 每個集合可存儲40多億個成員)
- Redis zset
Redis zset 和 set 一樣也是string類型元素的集合,且不允許重復的成員。
不同的是每個元素都會關聯一個double類型的分數,redis正是通過分數來為集合中的成員進行從小到大的排序。
zset的成員是唯一的,但分數(score)卻可以重復。
zset集合是通過哈希表實現的,所以添加,刪除,查找的復雜度都是 O(1)。 集合中最大的成員數為 2^32 - 1
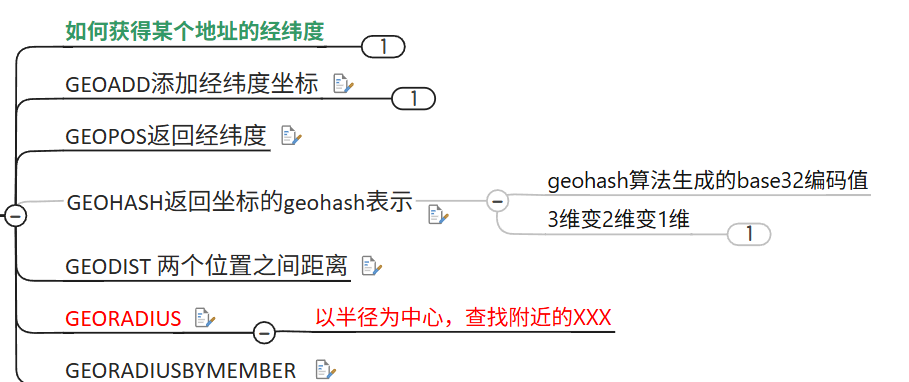
- Redis GEO
Redis GEO 主要用于存儲地理位置信息,并對存儲的信息進行操作,包括
添加地理位置的坐標。
獲取地理位置的坐標。
計算兩個位置之間的距離。
根據用戶給定的經緯度坐標來獲取指定范圍內的地理位置集合
- HyperLogLog
HyperLogLog 是用來做基數統計的算法,HyperLogLog 的優點是,在輸入元素的數量或者體積非常非常大時,計算基數所需的空間總是固定且是很小的。
在 Redis 里面,每個 HyperLogLog 鍵只需要花費 12 KB 內存,就可以計算接近 2^64 個不同元素的基 數。這和計算基數時,元素越多耗費內存就越多的集合形成鮮明對比。
但是,因為 HyperLogLog 只會根據輸入元素來計算基數,而不會儲存輸入元素本身,所以 HyperLogLog 不能像集合那樣,返回輸入的各個元素。
- bitmap
由0和1狀態表現的二進制位的bit數組

- bitfield
通過bitfield命令可以一次性操作多個比特位域(指的是連續的多個比特位),它會執行一系列操作并返回一個響應數組,這個數組中的元素對應參數列表中的相應操作的執行結果。
說白了就是通過bitfield命令我們可以一次性對多個比特位域進行操作。
- Stream
Redis Stream 是 Redis 5.0 版本新增加的數據結構。
?
Redis Stream 主要用于消息隊列(MQ,Message Queue),Redis 本身是有一個 Redis 發布訂閱 (pub/sub) 來實現消息隊列的功能,但它有個缺點就是消息無法持久化,如果出現網絡斷開、Redis 宕機等,消息就會被丟棄。
?
簡單來說發布訂閱 (pub/sub) 可以分發消息,但無法記錄歷史消息。
?
而 Redis Stream 提供了消息的持久化和主備復制功能,可以讓任何客戶端訪問任何時刻的數據,并且能記住每一個客戶端的訪問位置,還能保證消息不丟失
2. String 字符串
String是Redis中最重要的類型,可以說其他類型都是由String轉換而成的
Get Set指令
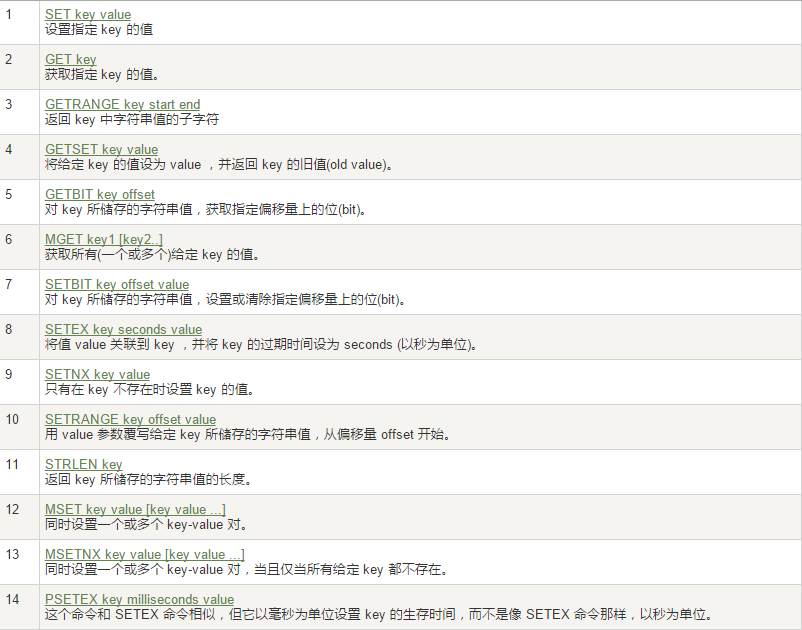
(1)基礎Get 指令
SET命令有EX、PX、N、xx以及KEEPTTL五個可選參數,其中KEEPTTL為6.0版本添加的可選參數,其它為2.6.12版本添加的可選參數。
GET key value [種種設置項]
| 設置項 | 參數 | 作用 |
| EX {} | 數字(代表秒) | 以秒為單位設置過期時間 |
| PX {} | 數字(代表毫秒) | 以毫秒為單位設置過期時間 |
| EXAT | UNIX時間戳(單位是秒) | 設置以秒為單位的UNIX時間戳所對應的時間為過期時間 |
| PXAT | UNIX時間戳(單位是毫秒) | 設置以毫秒為單位的UNIX時間戳所對應的時間為過期時間 |
| NX | 無 | 鍵不存在的時候設置鍵值 |
| XX | 無 | 鍵存在的時候設置鍵值 |
| KEEPTTL | 無 | 保留設置前指定鍵的生存時間 |
| GET | 無 | 返回指定鍵原本的值,若鍵不存在時返回nil |
(2)同時對多個K-V進行Get Set
- MSET key1 value1 key2 value2 ....
- MGET key1 key2 ......
- MSETNX key1 value1 key2 value2 ....
- 同時添加(如果已經存在則覆蓋原值)
- 同時獲取(會分段)
- 同時添加(如果已經存在則每一個設置都無法生效,如:key1存在,那么key2 key3都設置失敗)
(3)數值增加
雖然是String,但是對于純數值的String我們仍然可以對其增減
| 指令 | 作用 |
| INCR key | 增加整數1 |
| INCRBY key increment | 增加指定的整數increment |
| DECR key | 減少整數1 |
| DECRBY key decrement | 減少指定的整數decrement |
(4)獲取字符串長度和內容追加
| 指令 | 作用 |
| STRLEN key | 獲取字符串長度 |
| APPEND key value | 內容追加 |
(5)分布式鎖
暫時知道有即可
3. List 列表
在Redis中List是一個雙端鏈表,不過這個鏈表雖然是雙端的但只能從一邊進入(添加)
常用:
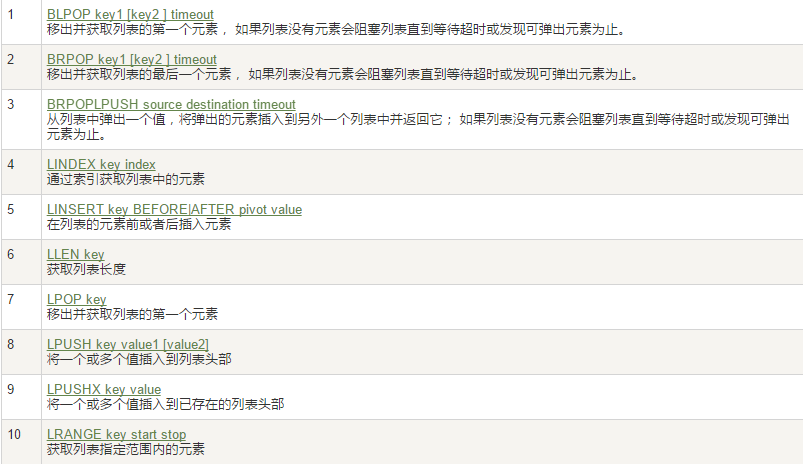
說明
| 指令 | 參數 | 作用 |
| LPUSH key LEN v1 v2 ... | LEN(長度) | 新增一個List |
| RPUSH key L R | L(左起點)R(右終點) | 遍歷List(在Redis中-1代表最后一個元素,0代表第一個元素) |
| LLEN | 無 | 獲取列表中元素的個數 |
| LREM key N ValueN | N(去重數量,+-代表方向正反,0代表所有)ValueN(重復元素) | 去重,自頭向尾 |
| LTRIM key L R | L(左起點)R(右終點) | 截取指定范圍的值后再賦值給原key |
| ROPLPUSH List1 list2 | List1(原列表)List2(轉入的列表) | 把原列表頭轉移到指定列表尾 |
| LSET key index value | inde(指定位置下標) | 把指定位置元素替換 |
| LINSERT key BEFORE/AFTER | BEFORE/AFTE(左/右) | 向指定位置元素的左/右添加元素 |
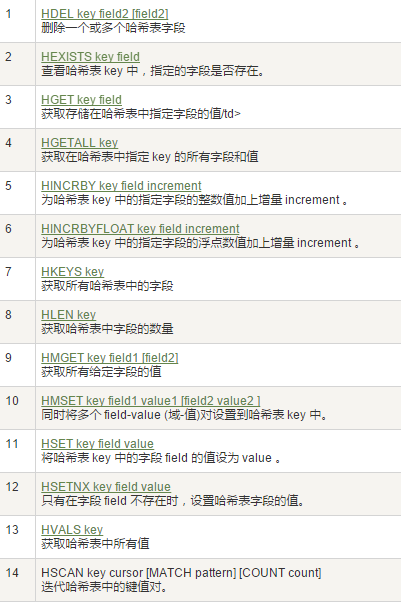
4. Hash 哈希
和javaSE的HashMap一樣
常用指令:
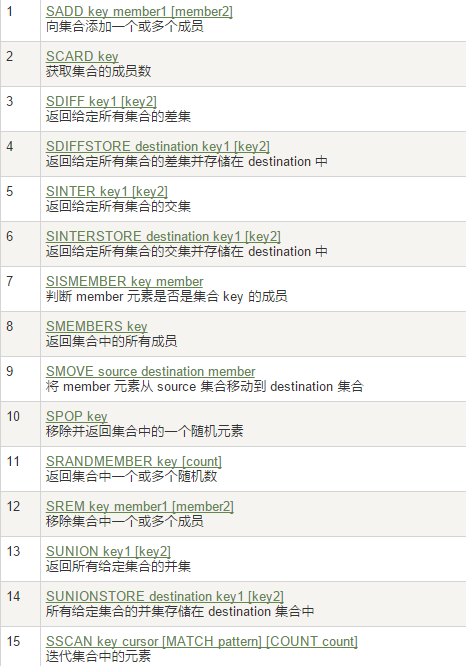
5. Set 集合
集合不可重復,沒有順序
常用指令:
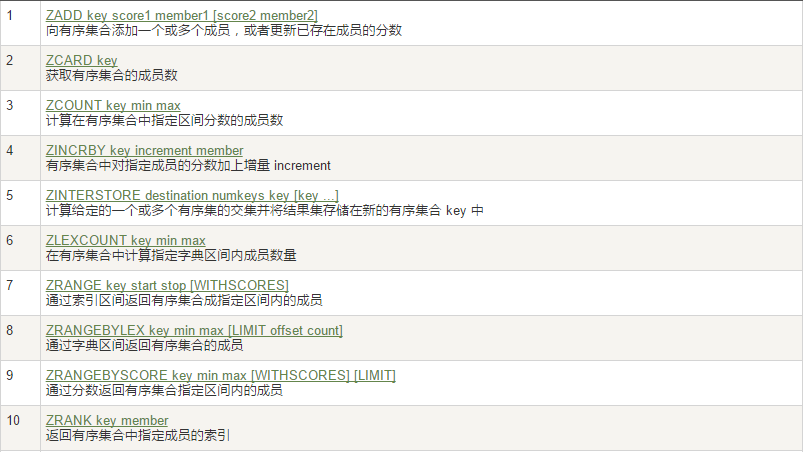
6. ZSet 有序集合
在set基礎上,每個val值前加一個score 權重值。之前set是k1 v1 v2 v3,現在zset是k1 score1 v1 score2 v2
常用指令:
7. BitMap 位圖
本質是String實現的由0/1二進制位組成的二進制數組:常作為true/false來按順序記錄判斷結果
使用場景:
日歷簽到,電影座位是否被占,狀態記錄
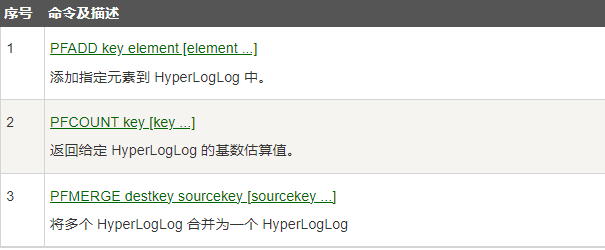
8. HyperLogLog 基數統計
用于大數據量下的數據統計:去重復統計功能的基數估計算法-就是HyperLogLog
- 基數統計:用于統計一個集合中不重復的元素個數,就是對集合去重復后剩余元素的計算,有0.81%的誤差
基本命令:
9. GEO 地理空間
根據經緯度保存空間坐標,底層是ZSet類型,但是權重變成經緯度了
10. Stream 流
和javaSE的不太一樣,Redis引入這種數據結構是為了減少項目中間件,是MQ消息中間件+阻塞隊列
- MQ消息隊列:先把訂單請求往隊列里一扔,讓數據庫按自己能承受的速度慢慢處理/彈出。
(1)隊列相關指令
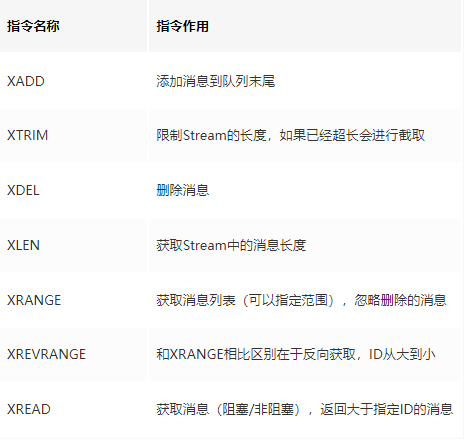
- XTRIM加上:
-
- maxlen關鍵字 + 數量,截取前2個的話,會保留后面的
- minid關鍵字 + 指定時間戳id,保留該id后的所有
(2)消費組相關指令
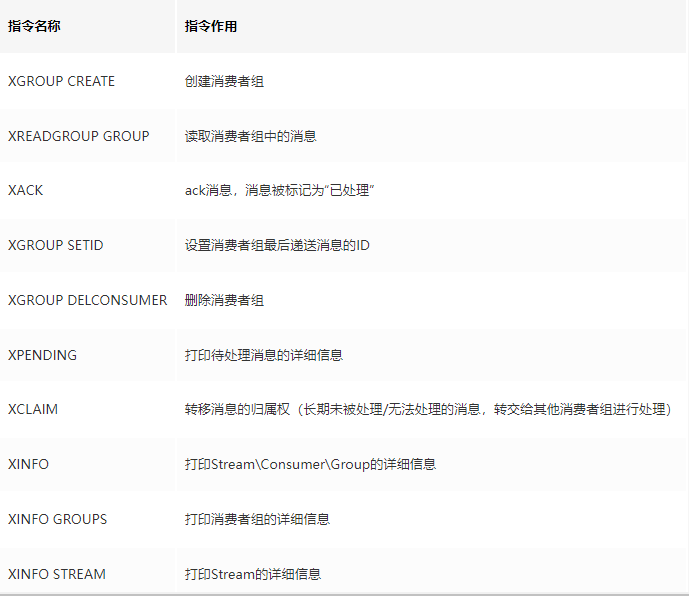
(3)4個特殊字符
| 符號 | 作用 |
| - + | 最小/最大可能出現的id |
| $ | 表示當前隊列最后一個的下一個--表示將來才會出現的添加入隊列的消息 |
| > | 用于XREADGROUP命令中,表示指針指向最新未消費的消息 |
| * | 用于XADD,不指定id,讓Redis根據時間戳生成id |
11. Redis 位域(了解即可)
BITFIELD 命令可以將一個 Redis 字符串看作是一個由二進制位組成的數組,并對這個數組中任意偏移進行訪問。可以使用該命令對一個有符號的5 位整型數的第 1234 位設置指定值,也可以對一個 31 位無符號整型數的第 4567 位進行取值。類似地,本命令可以對指定的整數進行自增和自減操作,可配置的上溢和下溢處理操作。
- 把字符串按字符轉換為二進制,然后把所有二進制碼拼成位圖數組
基本命令:
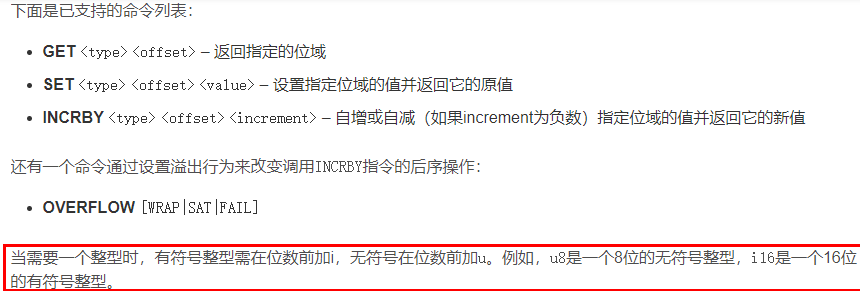
使用:

三、Redis 持久化
為了將數據同步保存下來,我們需要對Redis進行持久化處理,
1. RDB--RedisDataBase
在指定時間內如果修改到了一定次數,快照記錄Redis的數據到磁盤(dump.rdb文件)
(1)配置文件修改
- 修改自動保存的觸發間隔
該為5秒內如果修改了2次就自動保存
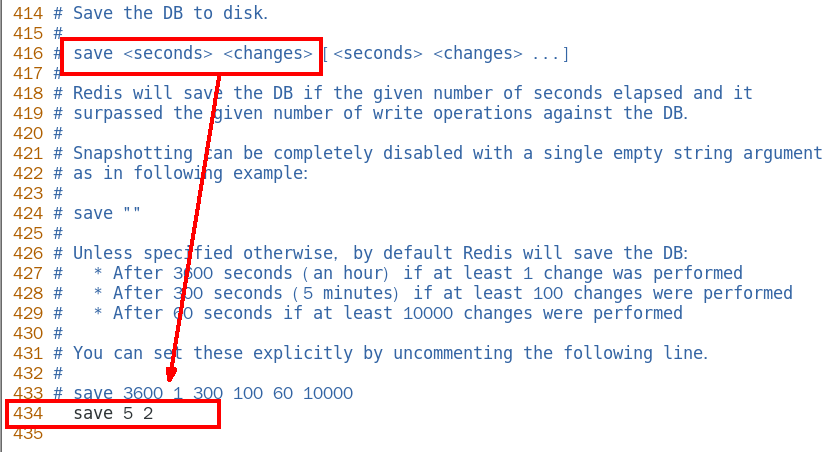
- 修改dump文件的儲存位置
改為黑字對應位置
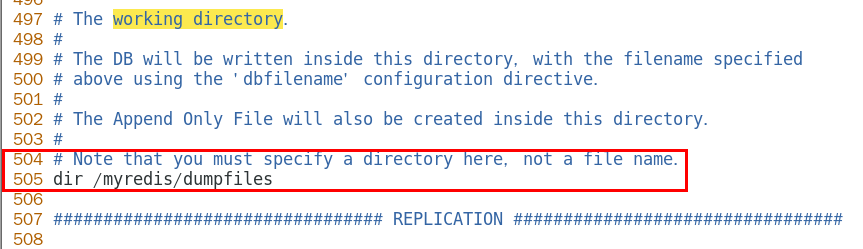
- 修改dump文件名稱

(2)觸發快照的方式
- 在系統設置的時間內進行了規定次數的操作
- 配置默認的快照配置時
- 手動sava/dgsave
- 清空dump文件時(此時生成的dump為空)
- 主從復制時,主節點觸發
(3)恢復備份
將dump備份文件移動到Redis安裝目錄后啟動Redis服務就能自動讀取
- 注意:在實際生產時推薦把備份的位置設置在其他服務器上進行隔離,以防生產機物理損壞后備份文件也掛了
(4)手動備份--save
- save指令 與 dgsave指令的區別
- save指令是阻塞式的,如果執行會導致redis服務停止,直到持久化完成
- dgsave指令是非阻塞式的,會通過linux的fork創建一個子進程,在子進程中完成持久化,主進程仍然正常運行
- fork是什么?
- 在Linux程序中,fork()會產生一個和父進程完全相同的子進程,但子進程在此后多會exec系統調用,出于效率考慮,盡量避免膨脹。
- lastsave指令
- 通過該指令可以獲取最后一次執行持久化的時間戳
(5)RDB的優缺點
優點:
- 適合大規模數據的恢復
- 能定時備份
- 對數據完整性、一致性要求不高
- RDB文件的加載速度在內存中比AOF快的多
缺點:
- 如果突然結束服務,最近的信息可能因為不滿足快照機制而丟失
- 如果數據量過大,強io會影響服務器性能
- fork會導致數據2倍膨脹,需要時刻小心
2. AOF--AppendOnlyFile
(1)概述
和RDB的全部記錄不同,他們最大的區別是AOF記錄所有的寫操作,使用他恢復時會遍歷所有寫操作來恢復數據
- 寫操作:不是指添加操作,而是指除了讀取數據以外的添加、修改、刪除等操作
(2)使用流程
- Client提供命令到Redis
- 命令不是直接寫入磁盤的AOF文件,而是先進入內存的AOF緩存區中保存,(減少磁盤io)
- 如果滿足三種寫回策略的指定的那一種后,將緩存的命令寫入AOF文件
- 為了防止文件內容過大,根據規則進行壓縮(又稱AOF重寫)
- Redis重啟時根據AOF重新加載到內存中
(3)回寫策略
就是把緩存寫入磁盤的策略
- Always:同步寫回,每個寫命令執行完立刻同步地將日志寫回磁盤
- everysec:每個寫命令執行完,每秒寫回,只是先把日志寫到AOF文件的內存緩沖區,每隔1秒把緩沖區中的內容寫入磁盤
- no:決定何時將緩沖區內容寫回磁盤操作系統控制的寫回,每個寫命令執行完,只是先把日志寫到AOF文件的內存緩沖區,由操作系統
| 配置項 | 寫回時機 | 優點 | 缺點 |
| Always | 同步寫回 | 可靠,數據不易丟失 | io多,效率低 |
| everysec(默認) | 每秒寫回 | 性能適中,留存率適中 | 會丟失1秒數據 |
| no | 操作系統控制寫回 | 性能高 | 丟失數據多 |
(4)配置文件
a. 開啟方式:
默認不開啟,配置開啟--修改配置文件:appendonly no yes
b. 儲存方式
路徑:默認儲存在/myredis/appendonlydir目錄下
在redis7以后,rdb文件儲存在/myredis目錄下,而dir文件儲存在/myredis/appendonlydir目錄下
c. 具體文件:
- BASE:AOF基礎文件,只有一個
- INCR:AOF開啟文件,在AOF開啟時就會被創建,可能存在多個
- HISTORY:AOF歷史文件,由更新前的INCR文件轉換,Redis會自動清理該類型文件
在Redis7前,只存在一個aof文件
(5)優劣之分
優勢:
- 相比RDB,儲存所有寫操作能更好保護數據不丟失、寫入磁盤的性能高、適合各種情況下的緊急恢復
劣勢:
- AOF文件占用遠大于RDB文件,恢復速度慢
- 雖然同步寫入io效率高,但是AOF運行時效率慢
(6)AOF重寫
AOF運行久了,文件過大,我們需要壓縮其空間,也就是重寫
AOF在沒有RDB配合的情況下重寫,寫入的INCR文件會壓縮后存入BASE文件中,同時創建一個新的INCR文件
a. 自動觸發重寫
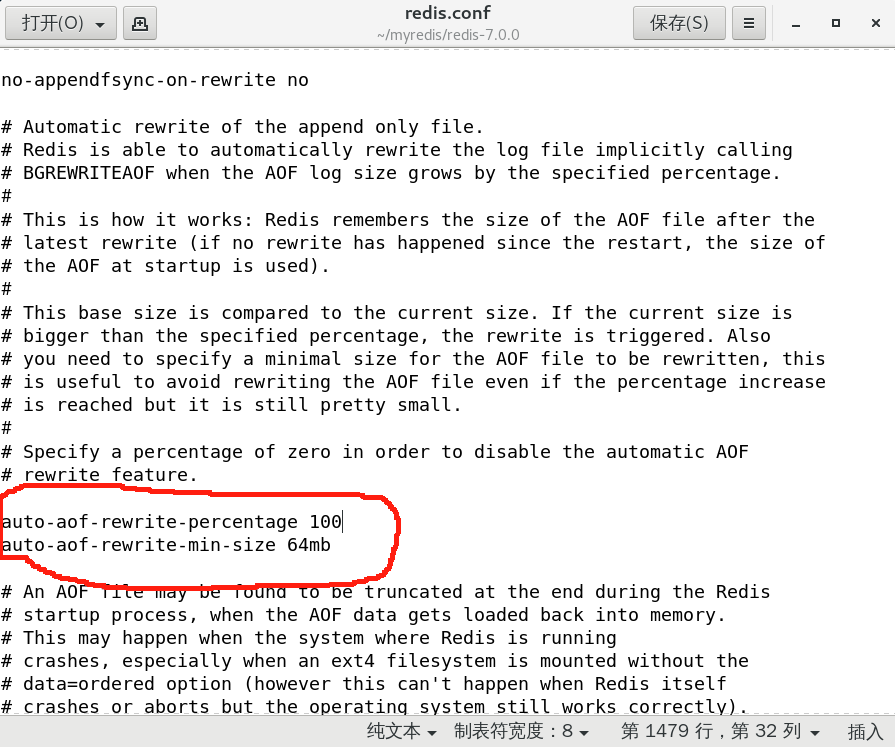
同時滿足以下條件:
- 占用100%
- 最大64mb
如果設置為50%,那么當文件達到32mb時就會重寫
b. 手動觸發重寫
輸入:bgrewriteaof
c. 重寫的具體流程
- 在重寫開始前,redis會創建一個“重寫子進程”,這個子進程會讀取現有的AOF文件,并將其包含的指令進行分析壓縮并寫入到一個臨時文件中。
- 與此同時,主進程會將新接收到的寫指令一邊累積到內存緩沖區中,一邊繼續寫入到原有的AOF文件中,這樣做是保證原有的AOF文件的可用性,避免在重寫過程中出現意外。
- 當“重寫子進程”完成重寫工作后,它會給父進程發一個信號,父進程收到信號后就會將內存中緩存的寫指令追加到新AOF文件中
- 當追加結束后,redis就會用新AOF文件來代替舊AOF文件,之后再有新的寫指令,就都會追加到新的AOF文件中
- 重寫aof文件的操作,并沒有讀取舊的aof文件,而是將整個內存中的數據庫內容用命令的方式重寫了一個新的aof文件,這點和快照有點類似
3. RDB+AOF 混合
(1)開啟方式
設置aof-use-rdb-preamble的值為 yes yes表示開啟,設置為no表示禁用
- 記得提前開啟AOF
(2)運行邏輯
RDB鏡像做全量持久化,AOF做增量持久化
先使用RDB進行快照存儲,然后使用AOF持久化記錄所有的寫操作,當重寫策略滿足或手動觸發重寫的時候,將最新的數據存儲為新的RDB記錄。這樣的話,重啟服務的時候會從RDB和AOF兩部分恢復數據,既保證了數據完整性,又提高了恢復數據的性能。簡單來說:混合持久化方式產生的文件一部分是RDB格式,一部分是AOF格式。----》AOF包括了RDB頭部+AOF混寫
4. 關閉持久化,Redis只作為緩存區
在實際場景下,我們未必會使用redis自帶的持久化功能,而是使用其他的東西完成持久化來分清各類功能
(1)禁用RDB:
save ""
- 在這種情況下,我們仍然可以使用RDB的手動指令sve、bgsave生成rdb文件
(2)禁用AOF:
appendonly no
- 同理,我們仍然可以使用命令bgrewriteaof生成aof文件
四、Redis的事務
1. Redis事務的特點
| 操作永遠是單獨的 | Redis由于本身就是單線程的,所以其事務也僅僅是保障了操作的連續性,在事務執行期間自然無法處理其他請求 |
| 沒有隔離級別(讀未提交、可重復讀..) | 因為同時只能執行事務內的操作,自然沒有同時讀入寫出的問題,本身就是最高隔離級別 |
| 不保證原子性 | Redis事務不保證所有指令同時成功或者失敗,而是決定是否開始執行全部指令,無法執行錯誤后回滾 |
| 排它性 | Redis保證事務內指令一次執行,不會被插入指令 |
2. 具體使用
和其他數據庫的事務不同,Redis的事務原子性對于語法錯誤時事務隊列不會執行(以此達到回滾的效果),但是當出現運行錯誤則其他指令正常運行(類似于類型不匹配等等,可以認為此時沒有原子性了,需要手動操作)
(1)一般使用
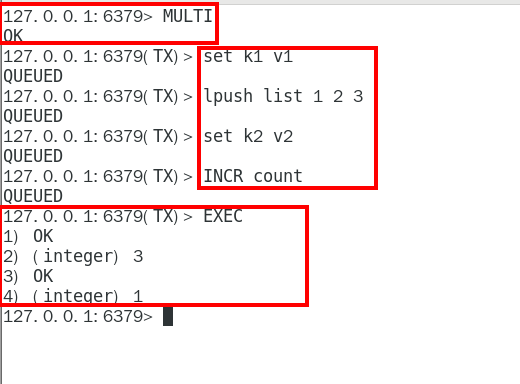
Redis的事務其實是一個隊列,有點像消息隊列,創建事務其實就是創建隊列
- MULTI:事務隊列開始
- EXEC:事務隊列結束
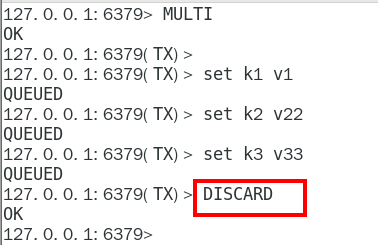
- DISCARD:事務隊列取消
正常執行:
手動取消:
(2)Redis事務薛定諤的原子性
存在原子性:
- 對于語法錯誤時,事務隊列不會執行
(以此達到回滾的效果)
沒有原子性:
- 當出現運行錯誤則其他指令正常運行
(類似于類型不匹配等等,可以認為此時沒有原子性了,需要手動操作)
(3)WATCH樂觀鎖
樂觀鎖:關注版本號,而不是先后順序,如果版本號被改,那么我就別亂搞
WATCH:相當于保存了當前數據的版本號,如果數據在別的訪問端被修改,此時真實版本號更新,而對于執行了WATCH指令的訪問端,再對該數據修改時就會報錯
WATCH key:設置觀察鎖
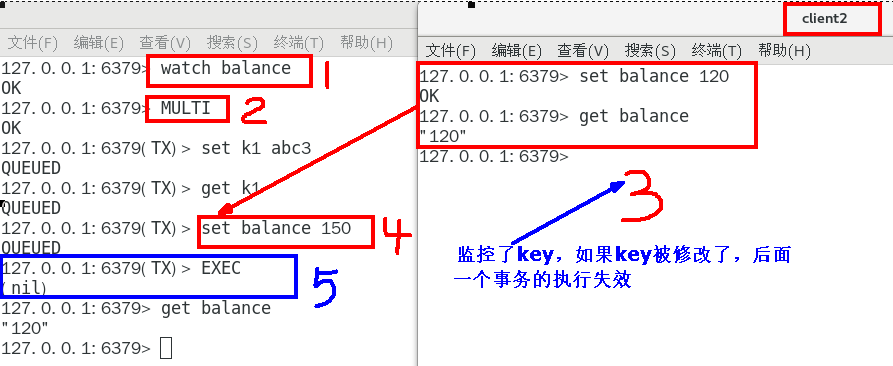
- 只有訪問端事先準備了WATCH鎖,才會對當前訪問端的EXEC指令生效
UNWATCH:取消當前所有WATCH鎖
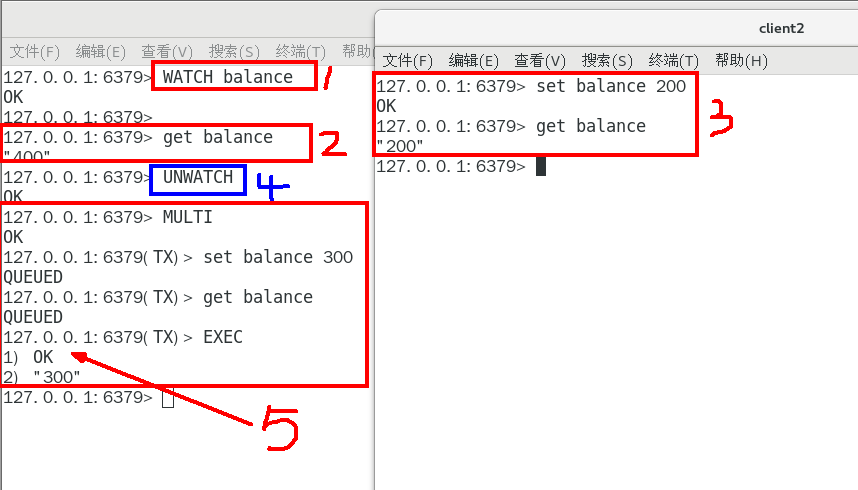
- 一旦執行了EXEC指令,在這之前所有的WATCH指令在之后都不再生效了
五、Redis 管道 Pipeline
Redis本質上仍然是 請求接受-數據處理-結果返回,對于大量的網絡指令,我們可以使用隊列來優化其批處理效率
- 類似與Redis原生的mget和mset指令
1. 基礎使用
對某一文件打開的同時使用linux的“|”管道符配合Redis的指令,將其傳入Redis管道中,系統會返回執行結果
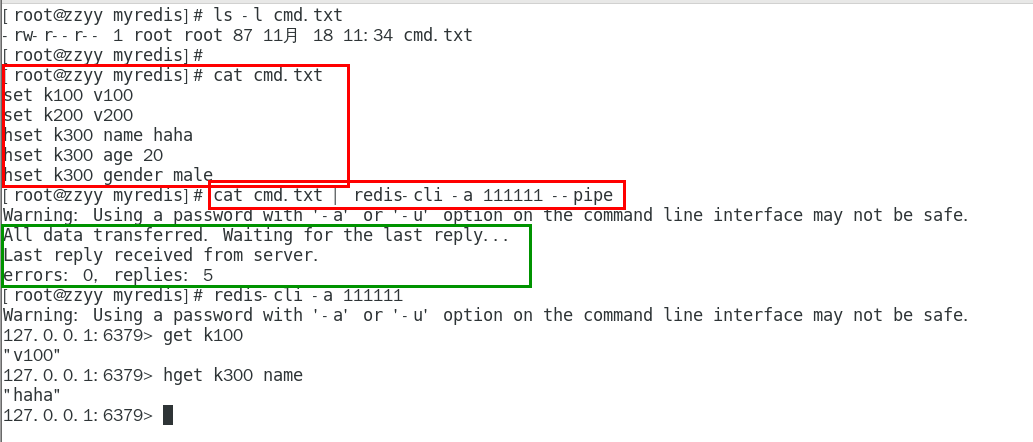
- 如果執行文件中有get指令,那么get結果不會顯示在終端上,需要指定輸出位置或使用工具解析
# 將結果保存到文件
cat cmd.txt | redis-cli -a 111111 --pipe > result.txt# 查看結果文件
cat result.txt2. Pipeline管道對比原生批處理(mget/mset)
Pipeline管道
原生批處理
- 非原子性
- 一次內可以執行多種指令
- 需要客戶端與服務端配合完成
(客戶端要把命令打包,而服務端解包并執行)
- 原子性
- 一次只能執行同一種指令
- 只在Redis服務端實施
3. Pipeline管道對比事務
這里指的是更常見的事務,不是專指Redis事務
Pipeline管道
事務
- 非原子性
- 一次發送多條指令
- 管道指令不中斷其他指令運行
- 有原子性
- 在事務隊列中一條一條發指令,還需要EXEC指令結束并執行
- 阻塞式,會導致其他指令被阻塞
4. 注意
- Pipeline非原子性,執行就算出問題了,其他指令仍然會繼續執行
- Pipeline中不要放過多指令,雖然Pipeline不完全阻塞,但是實際上會導致服務端使用隊列答復的方法,占用內存大
六、Redis復制
多Redis 服務器配合的基礎,實現了最基本的主從關系
1. 概述:
說是復制,其實更像數據庫的主從關系,當主數據庫更新后其數據會被異步同步入其下從數據庫。
- 默認情況下,當從庫(Slave)與主庫(Master)建立主從關系后,從庫中原有的數據會被清空,并完全替換為主庫的數據。
作用:
- 讀寫分離
(主數據庫用來寫入,從數據庫用來讀取) - 容災恢復
- 數據備份
- 水平擴容支撐高并發
2. 設置方式
(1)利用redis-cli 的指令設置
| 指令 | 說明 |
| REPLICAOF 主庫ip 主庫端口 | 設置當前數據庫,初次連接的數據庫(一定得是初次) |
| SLAVEOF 新主庫ip 新主庫端口 | 設置當前數據庫,新連接的數據庫 |
| SLAVEOF no one | 設置當前數據庫,沒有主庫 |
- REPLICA:復制 ;SLAVE:奴隸
注意事項:
- 當我們要連接有密碼的主庫時,當前數據庫的配置文件中需要寫好主庫的密碼,如果想要動態地連接,可以這樣寫,相當于臨時更改了密碼
# 第一步:設置密碼(必須最先執行!)
127.0.0.1:6380> CONFIG SET masterauth your_master_password
OK# 第二步:指定主庫地址和端口
127.0.0.1:6380> REPLICAOF <master_ip> <master_port>
OK(2)配置文件中規定
對于主從關系,我們可以把當前Redis 的主庫配置好,當該Redis 啟動后會自動綁定復制
流程:
- 指定連接的主庫ip和端口

- 指定主庫的密碼

- (可選)設置本機密碼

(3)三種場景
所有的情況都可以由這三種情況推出
一主多仆:
- 顧名思義,只有一個主機,但是有多個復制其的副機
代代相傳:
- 由一個主機往下一代代復制,從機之下還有從機復制它
自力更生:
- 把從機獨立出去,分開運行
3. 情景問題
- 從機能否執行寫命令?
不行,就算是該從機作為其他從機的主機,還是無法改變其本質。
- 從機啟動時會復制主機已經存在的數據嗎?
肯定是會的,不然為什么叫復制呢。
- 主機宕機后從機會成為新的主機嗎?
不一定,如果只有復制的話,從機會等待主機上線(但是有Redis哨兵的話,可以自動分配成為新主機)
- 主機宕機重啟后,其原來連接好的主從關系還在嗎?
看情況,如果配置文件沒配,那么我們還要手動重連
- 主機宕機重啟后,數據能同步嗎?
我們知道Redis的復制本質是讀取主機的持久化數據,而主機恢復時也是使用持久化數據的
4. 啟動流程
為了詳細,我使用了AI來寫
(1) 從節點啟動并初始化連接
- 觸發條件:從節點(Slave)啟動并配置
REPLICAOF指向主節點(Master)。 - 操作流程:
-
- 從節點向主節點發送
PSYNC命令(Redis 2.8+ 使用PSYNC替代舊版SYNC,支持部分同步)。 - 主節點根據從節點提供的復制歷史(
replication ID和offset)判斷是否需要全量或增量同步。
- 從節點向主節點發送
(2)首次全量復制(Full Sync)
- 觸發條件:從節點首次連接主節點,或復制歷史不匹配(如主節點切換、數據丟失)。
- 操作流程:
-
- 主節點生成 RDB 快照:
-
-
- 主節點調用
bgsave在后臺生成 RDB 文件。 - 生成 RDB 期間,主節點將新寫入的命令緩存到 復制緩沖區(Replication Buffer)。
- 主節點調用
-
-
- 傳輸 RDB 文件:
-
-
- RDB 生成完成后,主節點將 RDB 文件發送給從節點。
-
-
- 從節點加載數據:
-
-
- 從節點清空舊數據,加載 RDB 文件到內存,完成數據初始化。
-
-
- 同步緩沖命令:
-
-
- 主節點將 RDB 生成期間緩存的命令發送給從節點,確保數據一致性。
-
(3) 增量復制(Partial Sync)
- 觸發條件:主從已建立復制關系,且從節點斷線后重連時,其復制偏移量(
offset)仍存在于主節點的 復制積壓緩沖區(Repl Backlog) 中。 - 操作流程:
-
- 主節點檢查偏移量:
-
-
- 主節點根據從節點上報的
offset,從復制積壓緩沖區中提取斷線期間缺失的命令。
- 主節點根據從節點上報的
-
-
- 發送增量數據:
-
-
- 主節點將缺失的增量命令流(AOF-like)發送給從節點。
-
-
- 從節點應用增量命令:
-
-
- 從節點執行收到的增量命令,追上主節點數據狀態。
-
(4)心跳保持與長連接維護
- 主從心跳機制:
-
- 主從節點通過
PING-PONG心跳包保持長連接(默認間隔由repl-ping-replica-period控制,如 10 秒)。 - 從節點定期上報自身復制偏移量(
offset),主節點據此監控同步進度。
- 主從節點通過
- 復制積壓緩沖區(Repl Backlog):
-
- 主節點維護一個固定大小的環形緩沖區(由
repl-backlog-size配置,默認 1MB)。 - 緩沖區保存最近的寫入命令,用于支持從節點斷線后的增量復制。
- 主節點維護一個固定大小的環形緩沖區(由
(5) 從節點斷線重連恢復
- 斷線重連流程:
-
- 從節點重新連接主節點,發送
PSYNC <repl_id> <offset>。 - 主節點根據
repl_id和offset判斷是否允許增量同步:
- 從節點重新連接主節點,發送
- 若
offset仍在積壓緩沖區范圍內 → 增量同步。 - 若
offset已超出緩沖區 → 觸發全量同步。
5. Redis復制的缺點
(1)延遲復制,信號漸衰
由于所有的寫操作都是先在Master上操作,然后同步更新到Slave上,所以從Master同步到Slave機器有一定的延遲,當系統很繁忙的時候,延遲問題會更加嚴重,Slave機器數量的增加也會使這個問題更加嚴重。
(2)master宕機后不好處理
- 默認狀態下,不會有從機自動成為新的master'
- 每次宕機后從機的處理,和宕機后的恢復都需要手動處理
七、Redis哨兵 sentinel
本質上是無人值守運維,用來補充Redis復制的缺點,提高效率和穩定性
1. 概述
因為Redis復制的主從過于死板,一旦master宕機,slave都要停止。為了解決宕機和重啟的種種問題,Redis設計一種自動監控(哨兵),監控主從狀態,通過多哨兵聯合投票來更換主機
2. 如何使用哨兵
Redis哨兵也是由Redis數據庫更改設置而來,可以認為是一種特殊的從機,它綁定的主庫就是其監視對象,所以配置項和主從復制很像(但是哨兵不儲存數據,只有監視和通報的功能)
(1)配置Redis哨兵文件
創建sentinel.conf文件
參考以下配置:
| bind 0.0.0.0 daemonize yes protected-mode no port 26379 logfile "/myredis/sentinel26379.log" pidfile /var/run/redis-sentinel26379.pid dir /myredis sentinel monitor mymaster 192.168.111.169 6379 2 sentinel auth-pass mymaster 111111 |
配置項:
- bind:哨兵監聽地址,默認情況下為本機
- daemonize:是否以后臺daemon方式運行
- protected-mode:是否開啟安全保護模式
- port:哨兵運行的端口
- logfile:日志文件路徑
- pidfile:pid文件路徑
- dir:工作目錄
- sentinel monitor <master-name> <redis-port> <Ip> <quorum>:
-
- <master-name> <redis-port> <Ip>:設置監控的master服務器
- <quorum>:故障遷移的判定票數(最少有幾個哨兵認可才能下線)
- sentinel auth-pass <master-name> <password>:master的密碼
(2)啟動主從機
---------省略------------
(3)啟動哨兵
輸入:
redis-sentinel sentinelXXX.conf --sentinel3. 哨兵故障遷移的底層
(1)主觀下線和客觀下線
主觀下線:
這里的主體指的是當前的一個哨兵,如果哨兵發現監視的master在一定時間內沒有心跳包響應則認為該master下線了
客觀下線:
當多個哨兵發現并數量滿足哨兵中設置最大的quorum 值,那么哨兵們集體認為該master下線了
(2)選舉哨兵代表
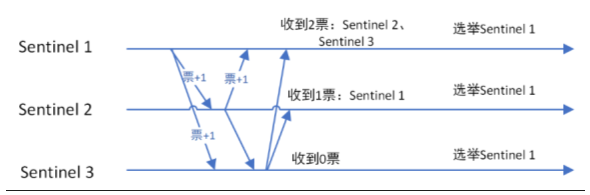
當master被集體認為客觀下線后,哨兵集群通過Raft算法,選舉一個哨兵代表,哨兵代表執行操作,使故障的master被failover(故障遷移)
▽ Raft算法
監視該主節點的所有哨兵都有可能被選為領導者,選舉使用的算法是Raft算法;Raft算法的基本思路是先到先得:
即在一輪選舉中,哨兵A向B發送成為領導者的申請,如果B沒有同意過其他哨兵,則會同意A成為領導者
八、Redis集群 Cluster
Redis復制+哨兵分布式的升級版,安全性、效率都遠高于原結構
1. 概述
(1)是什么?
Redis集群是多個Redis節點共享數據構成了一個整體程序集
- 與Redis復制最大才差異是可以有多臺master
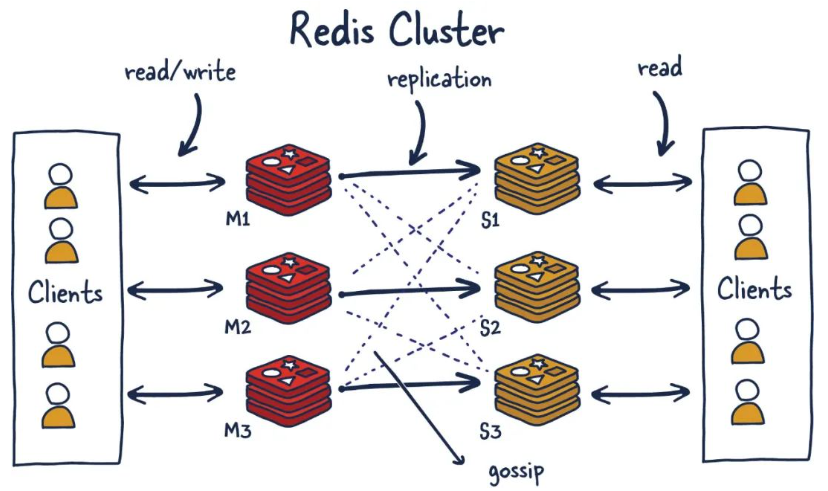
(2)有什么用?
- 多master+多slave:
在支持讀寫分離的同時,使數據高可用(安全、不易丟失),有利于海量數據的儲存和讀寫 - 自帶Sentinel的故障轉移機制:
無需使用哨兵來維護故障 - 客戶端與Redis的節點連接,不再需要連接集群中所有的節點,只需要任意連接集群中的一個可用節點即可
- 利用HASH槽分配到服務器儲存
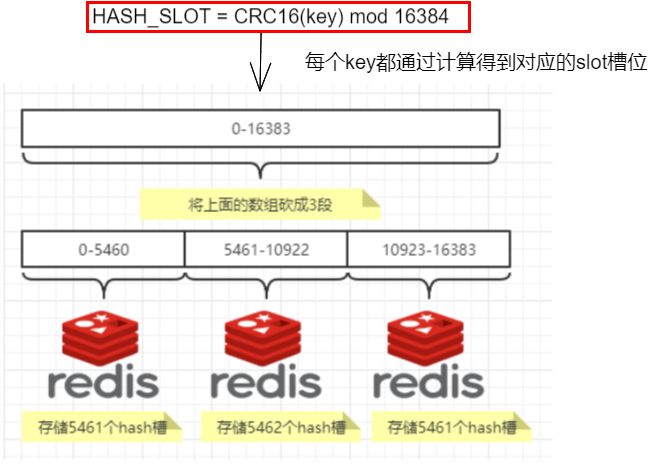
2. 集群的HASH槽位 slot
(1)是什么?
Redis設置有16384(2^14)個HASH槽,通過算法計算key的HASH值后將其內容儲存到對應槽位
a. HASH槽
和javaSE的HashMap類似,不過HASH槽是分配到各個Redis服務器中的,所以獲取數據時可以借此分流向各個服務器
b. 槽位分片
就是按一定規律將HASH槽分配到各個服務器,一個服務器對應就是一個片區
- 注意槽位的分配大多是打亂的,沒有什么連續性的說法
(2)有什么好的?
- 方便集群整體的擴縮容:
我們在擴容時相當于新增一個片區,由于使用槽位來儲存數據,新增的片區只要由老片區提供部分槽位及其數據就能完成擴容,并且不影響后續的服務 - 便于分派查找:
利用HASH槽,我們分開了各種key,在修改、查詢時壓力就很好地分散了
(3)三種HASH算法
對于HASH槽其實不止分片來處理,還有別的方法
a. 哈希取余分區
基礎的哈希算法
概述:
- 通過直接取余HASH來儲存,若有3臺機器,就用3取余
優點:
- 簡單直接,適合與小型工程
缺點:
- 因為節點數在初期就定死了,如果要擴/縮容或者有機器宕機的情況下,需要變動取模公式,而且原來的值也要感覺HASH重新刷新
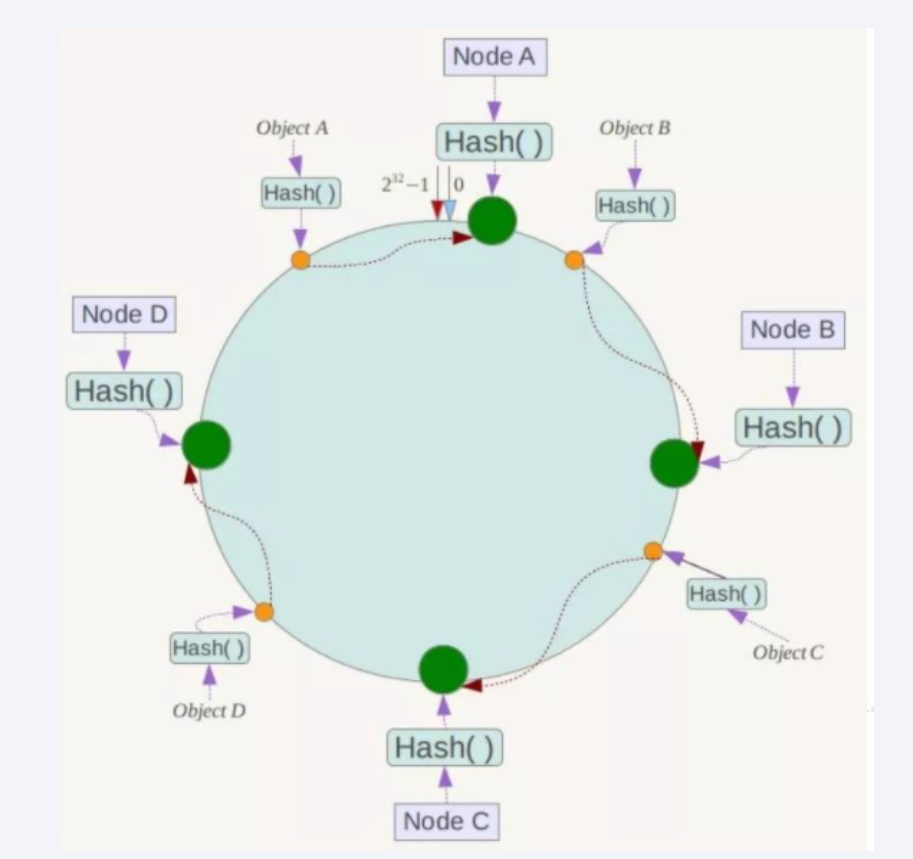
b. 一致性哈希算法
補充哈希算法分母的動態問題,保證無論多少服務器都不會出現一致性錯誤
概述:
- 保持總量的不變,動態地裝載數據
*流程:
- 構建一致性哈希環:
-
- 先定死HASH取模的大小,此時可以認為HASH槽為環形,
- Redis服務器節點映射:
-
- 每個Redis服務器通過算法對應哈希環上某點。
- key通過環添加到指定服務器:
-
- 保持Redis節點不動,key也以節點的形式加入哈希環,key節點朝順時針旋轉遇到的第一個Redis節點就是其所屬數據庫
作用:
- 容錯性--宕機不影響正常運行:
-
- 根據定義,我們可以使著取出一個Redis節點,可以發現,宕機的數據會遷移到順時針方向的下一個數據庫
- 擴展性--可以動態的擴展:
-
- 同樣根據定義,我們添加一個Redis節點,可以發現,新加入的節點截斷了部分數據,這樣也就完成了擴展
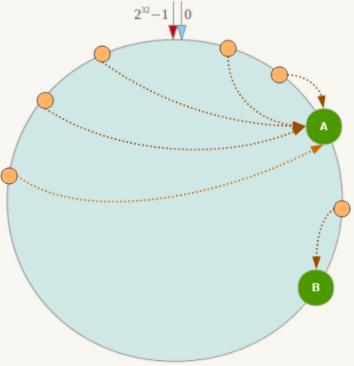
缺點:
- 會造成數據傾斜的問題:
-
- 當服務器節點過少或者分布不均衡時,可能導致大量數據集中到一個服務器上
c. 哈希槽分區
有點像一致性哈希算法,但是,哈希槽調優了分配和管理的能力,改善了數據傾斜問題
概述:
- 哈希槽通過將數據映射到固定數量的槽位并主動均衡分配至節點,解決了一致性哈希算法中因哈希值分布不均可能導致的負載失衡問題,以更可控的方式實現數據分布和集群擴展。
作用:
- 均衡數據:
-
- 其實核心還是那些,但是落入哈希槽和哈希環不同,哈希槽能夠均分入各個服務器
(4)注意
a. 面試--哈希槽為什么最多16384?
- 消息大小考慮:
-
- Redis 節點發送心跳數據包時需將所有槽放入。盡管 CRC16 算法能生成 65535 個值,但 16384 個哈希槽的消息占用約 2KB 內存,而 65535 個哈希槽則需 8KB。選擇 16384 個哈希槽可減少網絡帶寬占用和內存消耗,優化系統資源。
- 集群規模設計:
-
- Redis 支持的最大分片數為 1000。16384 個哈希槽能確保在所有分片均勻分布時,每個分片擁有的槽數不會過少,避免在極端情況下退化回傳統哈希算法,保證了數據分布均勻和系統擴展性。
b. Redis集群不保證數據一致性
當主機寫入完成但沒有傳入從機而主機宕機時,數據無法被讀取
3. 如何創建
(1)配置文件
redisCluster.conf:
| bind 0.0.0.0 daemonize yes protected-mode no port 6381 logfile "/myredis/cluster/cluster6381.log" pidfile /myredis/cluster6381.pid dir /myredis/cluster dbfilename dump6381.rdb appendonly yes appendfilename "appendonly6381.aof" requirepass 111111 masterauth 111111 cluster-enabled yes cluster-config-file nodes-6381.conf cluster-node-timeout 5000 |
| 參數 | 說明 |
|
| 啟用集群模式 |
|
| 自動生成的集群拓撲配置文件 |
|
| 節點失聯超時時間,超過此時間視為故障 |
|
| 是否要求所有槽都可用才提供服務 |
|
| 啟用 AOF 持久化(保證數據安全性) |
(2)服務器集群化啟動
redis-server /配置文件路徑/redisCluster1.conf
redis-server /配置文件路徑/redisCluster2.conf
redis-server /配置文件路徑/redisCluster3.conf
- 使用集群配置文件啟動多臺Redis服務
(3)啟動集群關系
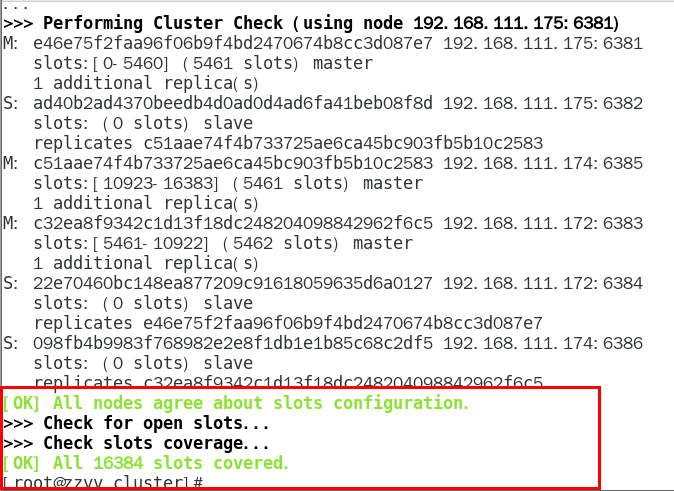
redis-cli -a 111111 --cluster create --cluster-replicas 1 192.168.111.175:6381 192.168.111.175:6382 192.168.111.172:6383 192.168.111.172:6384 192.168.111.174:6385 192.168.111.174:6386
- 這里連接了集群中全部的Redis數據庫,包括master還有slaver,用空格隔開服務器的ip與端口
連接成功的提示:
4. 集群的讀寫操作
(1)讀寫的問題
當我們設置并啟動了集群服務,我們如果仍然使用原來的方法啟動cli,有的時候讀寫一些鍵時會報錯。
因為,Redis集群中使用了HASH槽,如果簡單使用cli,只能訪問對應在本機上的key
(2)正確啟動cli
為了解決前面提出的問題,我們在啟動cli時,需要給啟動語句后加上 -c 參數
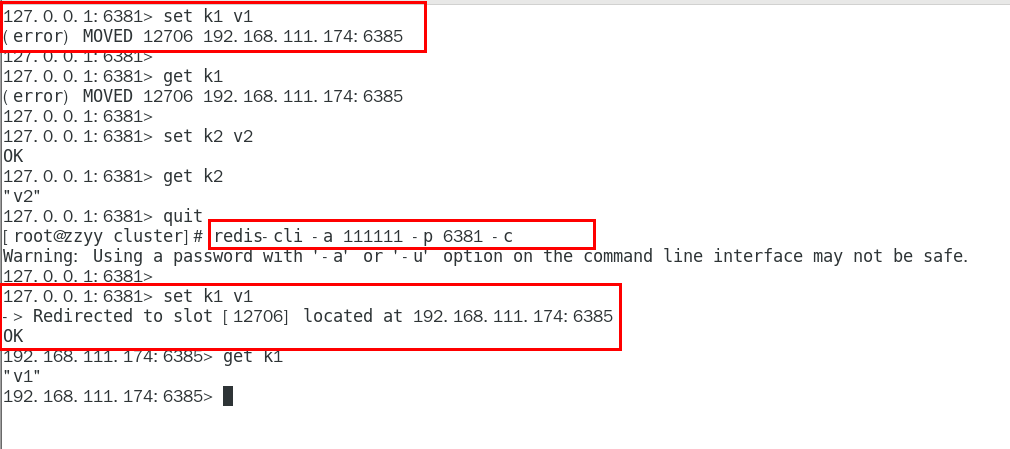
- 作用是優化路由,使其能匹配到其他服務器
(3)查看集群信息
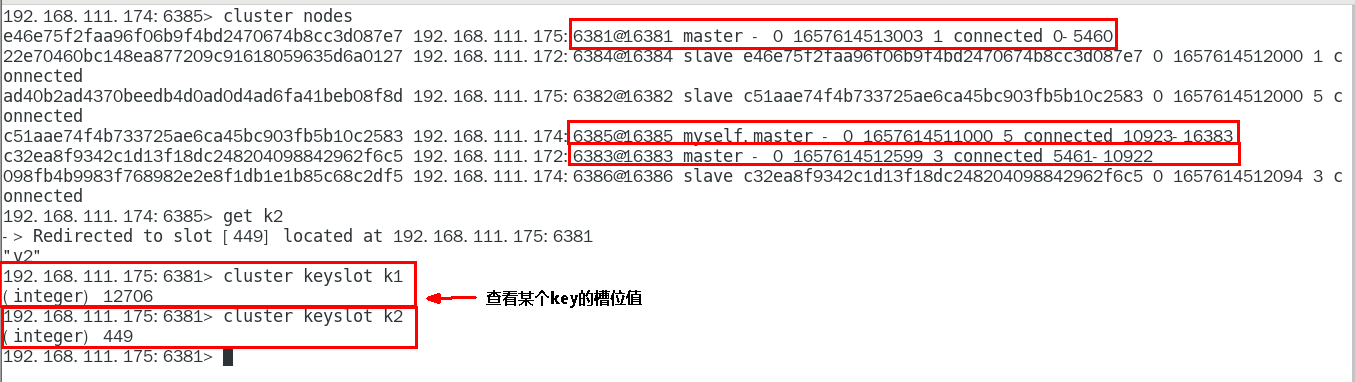
首先要啟動一個cli服務,然后輸入指令

(4)查看key對應的HASH槽
首先要啟動一個cli服務,然后輸入cluster keyslot 鍵
5. 主從容錯切換遷移
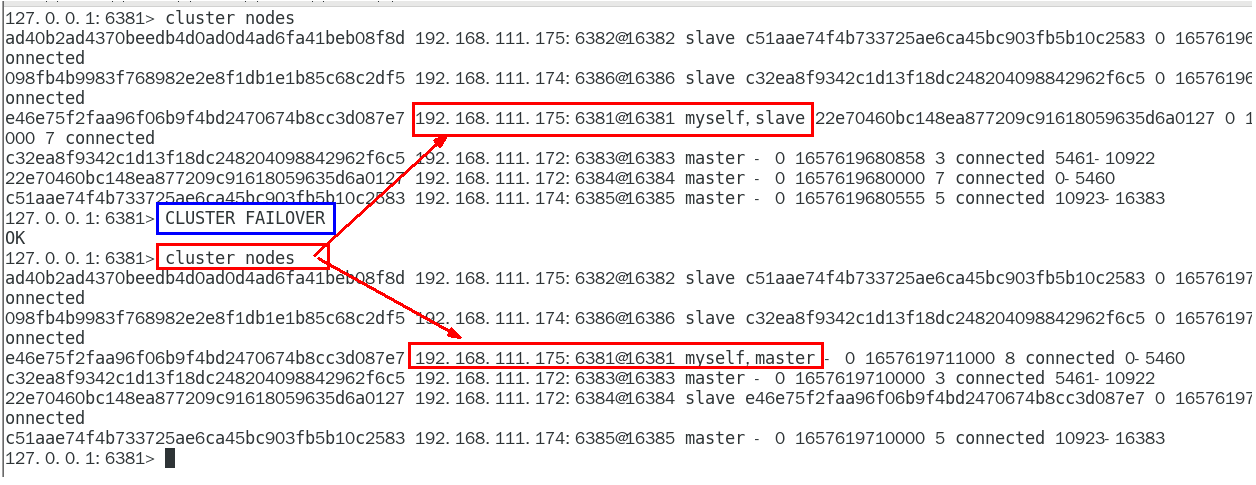
(1)容錯切換策略
如果主機突然宕機,那么集群會使用該策略維持服務
和Redis主從復制 + 哨兵 的效果一樣:
- 主機宕機-->從機上位
- 主機回歸-->主機轉為從機
(2)故障調整
由于出現故障會導致集群結構異常,我們需要進行調整,使其恢復原有結構
- 注意:集群結構也無法保障數據不完全一致不丟失
常用Redis自帶指令,在重連的主機cli上運行:CLUSTER FAILOVER
6. 主從擴縮容
(1)擴容
流程:
- 創建新的Redis服務和它的Cluster集群配置文件
- 通過Cluster配置文件啟動Redis服務
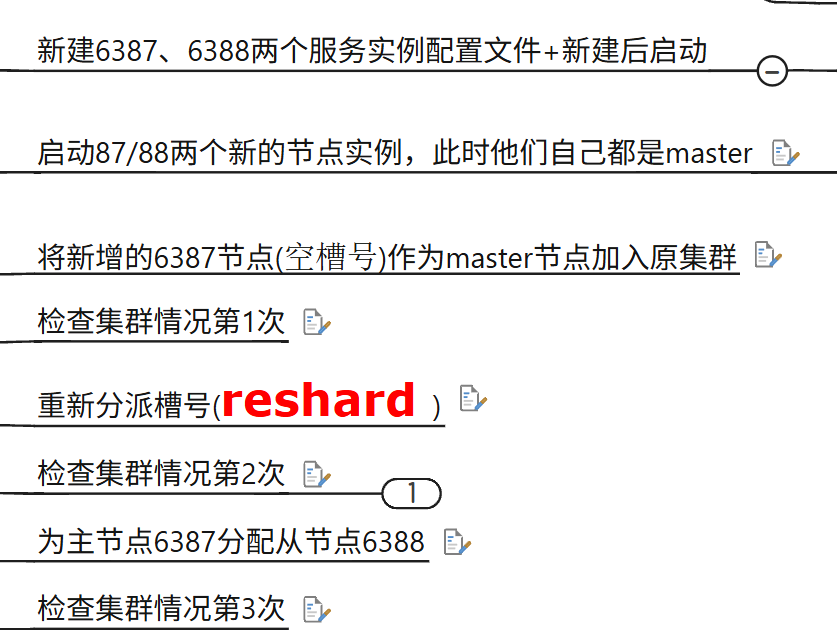
- 將新增的6387作為master節點加入原有集群:
redis-cli -a 密碼 --cluster add-node 新機P地址:6387 老機IP地址:6381
-
- 可以認為新機需要老機引入
- 此時新加入的master新機沒有被分配HASH槽
- 分配HASH槽:
redis-cli -a 密碼 --cluster reshard IP地址:端口號
-
- 指令分配后需要手動指定分配額度與分配給哪個數據庫,集群會自動均分每個老機的部分槽位
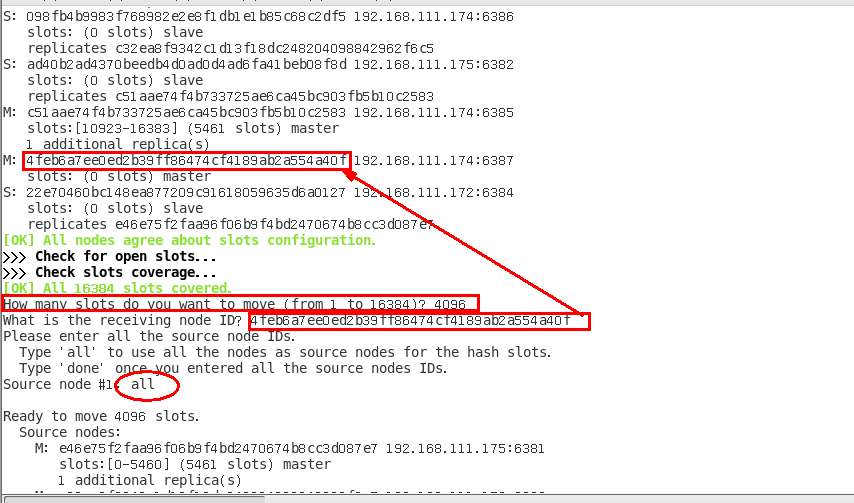
- 指令分配后需要手動指定分配額度與分配給哪個數據庫,集群會自動均分每個老機的部分槽位
- 校驗結果(非必須):
redis-cli --cluster check 真實ip地址:6381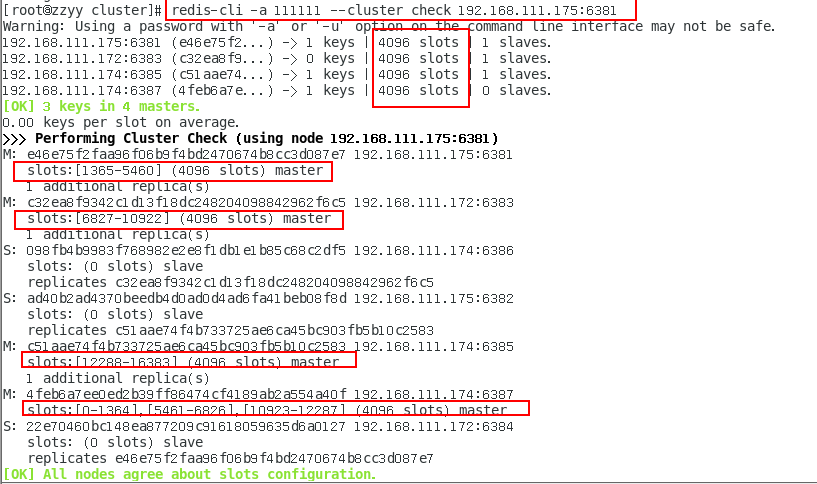
- 確實得到了一個新master,并完成了槽位分配
流程圖:
(2)縮容
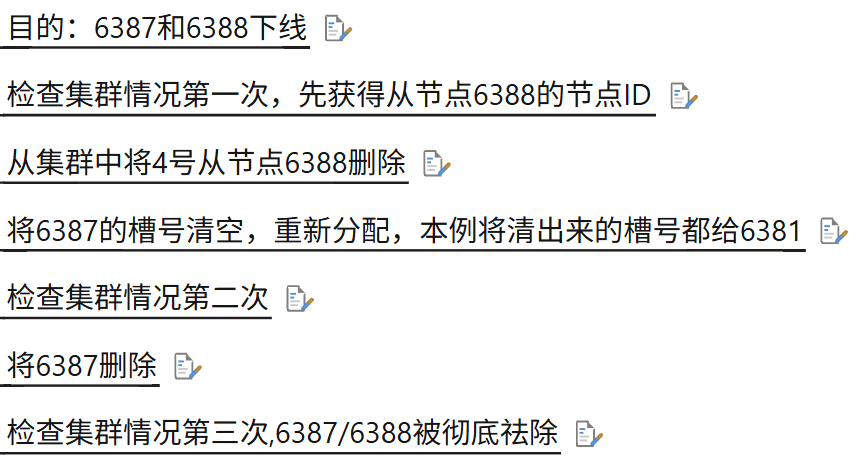
流程:
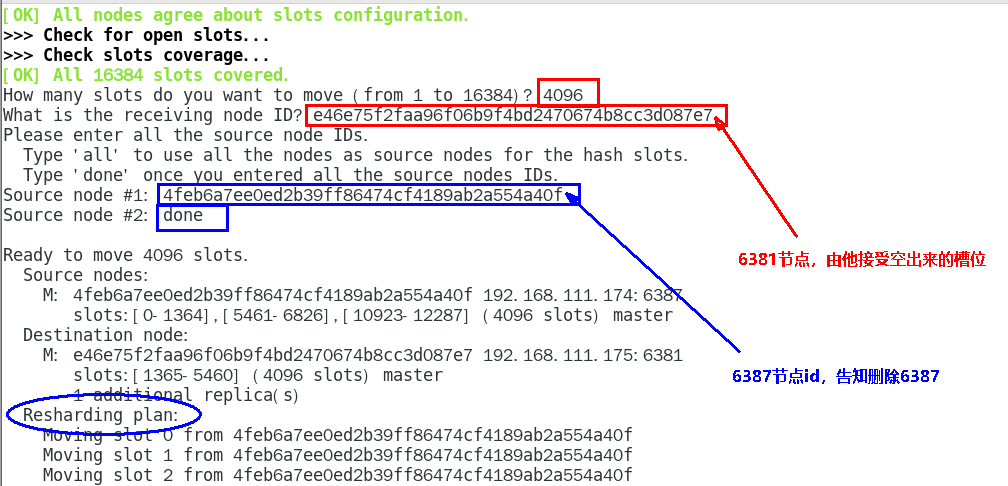
- 刪除主機下的從節點:
redis-cli -a 密碼 --cluster del-node ip:從機端口 從機6388節點ID - 清空主機的槽號:
redis-cli -a 密碼 -cluster reshard ip:主機端口 - 指定接收槽位的Redis服務器:(一般都是多次均分,這里圖方便)
-
- 分配徹底后原主機會變成最后一次操作對應主機的新從機
- 刪除原主機變成的新從機
redis-cli -a 密碼 --cluster del-node ip:主機端口 從機6387節點ID
流程圖:
7. 補充
(1)集群結構下批操作的限制
如果批操作的對象對應的HASH槽在不同的服務器,那么批處理會失敗
(2)CRC16的底層實現方法
是Redis中的一個 .c 文件中的函數
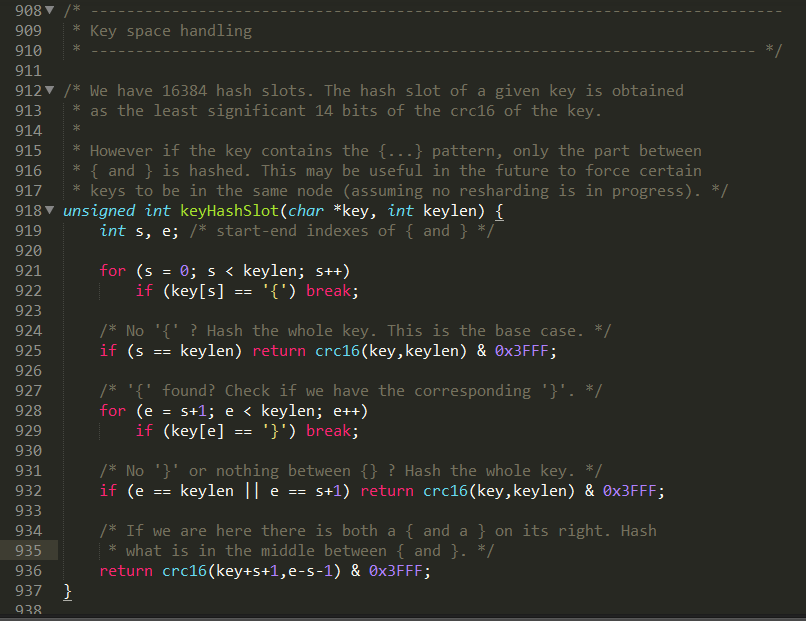
(3)常用指令
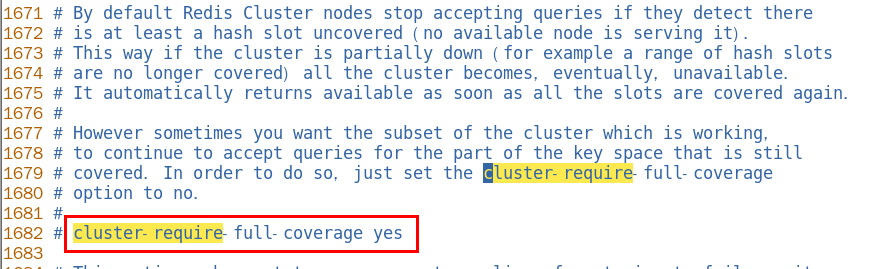
a. 集群是否必須完整才能對外服務
默認YES,現在集群架構是3主3從的redis cluster由3個master平分16384個slot,每個master的小集群負責1/3的slot,對應一部分數據。cluster-require-full-coverage: 默認值 yes , 即需要集群完整性,方可對外提供服務 通常情況,如果這3個小集群中,任何一個(1主1從)掛了,你這個集群對外可提供的數據只有2/3了, 整個集群是不完整的, redis 默認在這種情況下,是不會對外提供服務的。
b. 查看槽位是否被占用
CLUSTER COUNTKEYSINSLOT 槽位編號
- 1:被占用
- 0:空閑中
c. 查找key 計算后應該分配的槽位編號
CLUSTER KEYSLOT 鍵名
九、Redis與SpringBoot
主流有Jedis、Lettuce與RedisTemplate作為Redis與SpringBoot連接的中間件。
但是因為RedisTemplate效果最好,所以主要了解RedisTemplate就差不多了
1. Redis單機的連接
(1)導入依賴
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>(2)配置文件配置
# ========================redis=====================
spring.data.redis.database=0
spring.data.redis.host=127.0.0.1
spring.data.redis.port=6379
spring.data.redis.password=111111(3)配置類
@Configuration
public class RedisConfig
{/*** redis序列化的工具配置類,下面這個請一定開啟配置* 127.0.0.1:6379> keys ** 1) "ord:102" 序列化過* 2) "\xac\xed\x00\x05t\x00\aord:102" 野生,沒有序列化過* this.redisTemplate.opsForValue(); //提供了操作string類型的所有方法* this.redisTemplate.opsForList(); // 提供了操作list類型的所有方法* this.redisTemplate.opsForSet(); //提供了操作set的所有方法* this.redisTemplate.opsForHash(); //提供了操作hash表的所有方法* this.redisTemplate.opsForZSet(); //提供了操作zset的所有方法* @param lettuceConnectionFactory* @return*/@Beanpublic RedisTemplate<String, Object> redisTemplate(LettuceConnectionFactory lettuceConnectionFactory){RedisTemplate<String,Object> redisTemplate = new RedisTemplate<>();redisTemplate.setConnectionFactory(lettuceConnectionFactory);//設置key序列化方式stringredisTemplate.setKeySerializer(new StringRedisSerializer());//設置value的序列化方式json,使用GenericJackson2JsonRedisSerializer替換默認序列化redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());redisTemplate.setHashKeySerializer(new StringRedisSerializer());redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());redisTemplate.afterPropertiesSet();return redisTemplate;}
}- 這里主要是調整了Redis的keyV序列化,保證序列化和反序列化的一致性
2. Redis集群的連接
與單機基本上一樣,但是由于集群工作模式不同,會有一些和單機不同的地方
(1)改動配置文件
# ========================redis??=====================
spring.data.redis.password=111111
#密碼
spring.data.redis.cluster.nodes=192.168.111.175:6381,192.168.111.175:6382,192.168.111.172:6383,192.168.111.172:6384,192.168.111.174:6385,192.168.111.174:6386
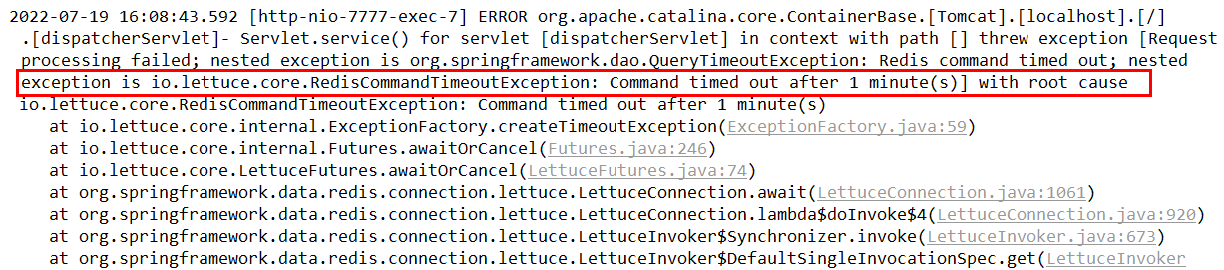
# 不連接單一Redis,而是把集群中的所有服務器的ip與端口都一一說明(2)問題:當原集群結構改變,Spring無法連接
原因:
- SpringBoot沒有動態感應到Redis集群的最新狀態
例:
- Redis Cluster集群部署采用了3主3從拓撲結構,數據讀寫訪問master節點, slave節點負責備份。當master宕機主從切換成功,redis手動OK,but 2個經典故障
?

?
由于是由語雀直接粘過來的,有些bug,詳見Redis7




深度講解)




:入門)







在線預覽)

)