一、技術背景
隨著大型語言模型(LLM)廣泛應用于搜索、內容生成、AI助手等領域,對模型推理服務的并發能力、響應延遲和資源利用效率提出了前所未有的高要求。與模型訓練相比,推理是一個持續進行、資源消耗巨大的任務,尤其在實際業務中,推理服務需要同時支持大量用戶請求,保證實時性和穩定性。
在傳統架構中,LLM 的輸入處理(Prefill)和輸出生成(Decode)階段往往混合部署在同一批 GPU 上。這種“統一架構”雖然實現簡單,但很快暴露出嚴重的性能瓶頸和資源調度困境:Prefill 階段計算密集、耗時長,容易阻塞 Decode 階段對低延遲的需求,導致整體吞吐和響應速度下降;而 Decode 階段則受制于 KV Cache 帶寬和訪問延遲,難以并發擴展
二、PD 分離介紹討論
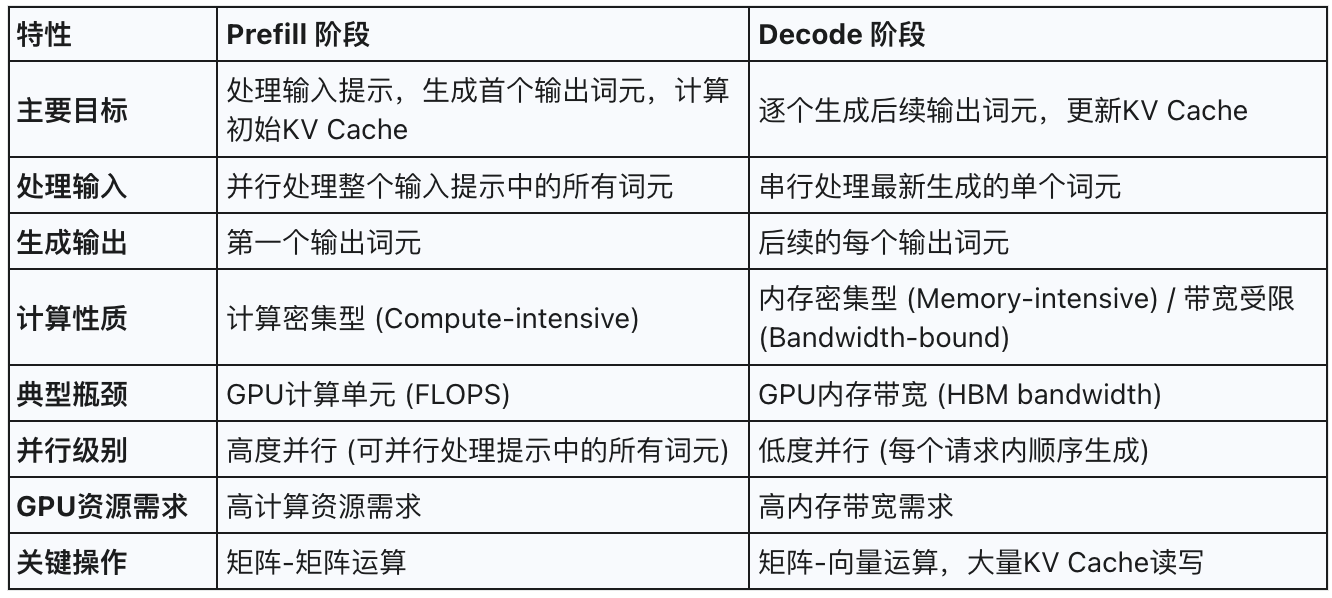
2.1 Prefill階段:特征與計算需求
Prefill階段負責并行處理輸入提示中的所有詞元,生成第一個輸出詞元,并計算初始的鍵值緩存 (Key-Value Cache, KV Cache) 。其主要特征是計算密集型 (computationally intensive),通常受限于計算資源 (compute-bound),尤其是在處理較長提示時。在此階段,模型對輸入序列中的每個詞元進行并行計算,通常涉及大規模的矩陣-矩陣運算,能夠充分利用GPU的并行計算能力,甚至使其達到飽和狀態。
2.3 Decode階段:特征與計算需求
Decode階段以自回歸的方式逐個生成后續的輸出詞元。在Decode的每一步中,模型僅處理最新生成的那個詞元,并結合先前存儲在KV Cache中的上下文信息來預測下一個詞元。與Prefill階段不同,Decode階段每個詞元的計算量相對較小,但其主要瓶頸在于內存帶寬 (memory-bandwidth-bound) 。這是因為每個解碼步驟都需要頻繁訪問和讀取不斷增長的KV Cache,涉及的操作主要是矩陣-向量運算。盡管只處理一個新詞元,但其對模型權重和KV Cache的I/O需求與Prefill階段相似。Decode階段可以看作是“逐字逐句地續寫回應”的過程
2.4. KV Cache 機制
KV Cache 是 LLM 高效推理的核心技術。它將每個詞元在 Transformer 計算中生成的 Key 和 Value 向量緩存到 GPU 顯存,避免重復計算,大幅提升生成效率。
-
Prefill 階段:為所有輸入詞元批量生成 KV Cache,計算密集型、強并行。
-
Decode 階段:每生成一個新詞元,都會增量更新 KV Cache,并頻繁讀取全部緩存內容,這使得 Decode 主要受內存帶寬限制。
KV Cache 的容量會隨著輸入和生成序列的長度線性增長,是 GPU 顯存消耗的主要來源。自回歸生成的順序性決定了 Decode 難以高并發,訪問 KV Cache 的效率成為系統瓶頸。高效的 KV Cache 管理和分階段調優是優化大模型推理的關鍵。
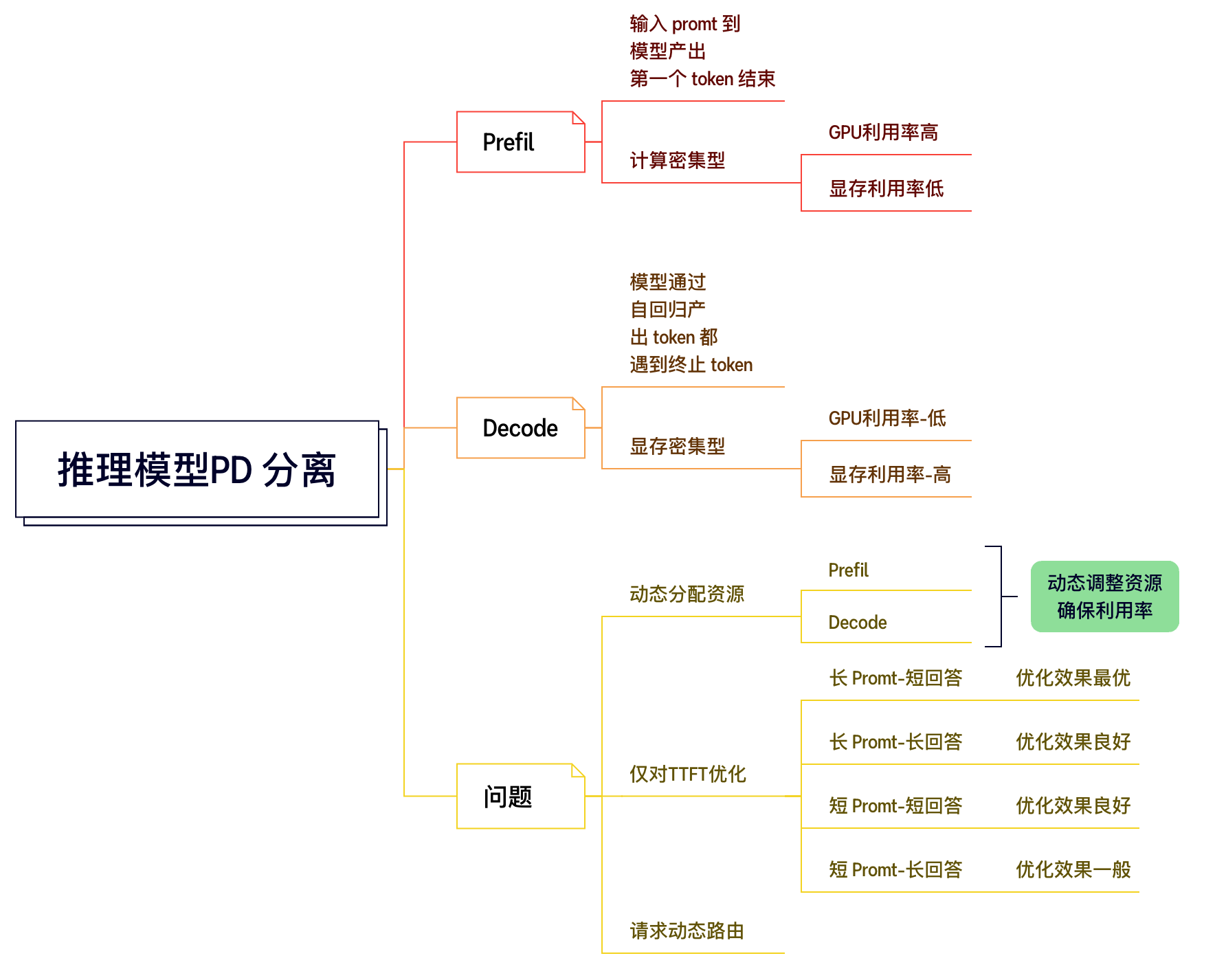
2.4 統一架構的局限性(PD Fusion)
實現相對簡單,無需復雜的跨節點通信,Prefill (計算密集) 和 Decode (內存密集) 兩個階段的資源需求和計算特性差異大,在同一組GPU上運行時容易相互干擾,導致GPU資源利用率不均衡。例如,Prefill 可能會搶占 Decode 的計算資源,導致 Decode 延遲增加;或者為了 Decode 的低延遲,Prefill 的批處理大小受限。
2.5 PD 分離式系統 (PD Disaggregation)
優點:
-
消除干擾:?Prefill 和 Decode 在獨立的硬件資源池中運行,避免了相互的性能干擾。
-
資源優化:?可以為 Prefill 階段配置計算密集型硬件,為 Decode 階段配置內存密集型硬件,從而更有效地利用資源。
-
獨立擴展:?可以根據 Prefill 和 Decode 各自的負載情況獨立擴展資源。
-
提升吞吐量和效率:?通過上述優化,通常能實現更高的系統總吞吐量。
缺點:
-
KV Cache 傳輸:?在 Prefill 階段計算完成的 KV Cache 需要傳輸到 Decode 節點,這個過程會引入額外的延遲和網絡開銷,是 PD 分離架構需要重點優化的環節。
-
調度復雜性:?需要一個全局調度器來協調 Prefill 和 Decode 任務的分發和管理。
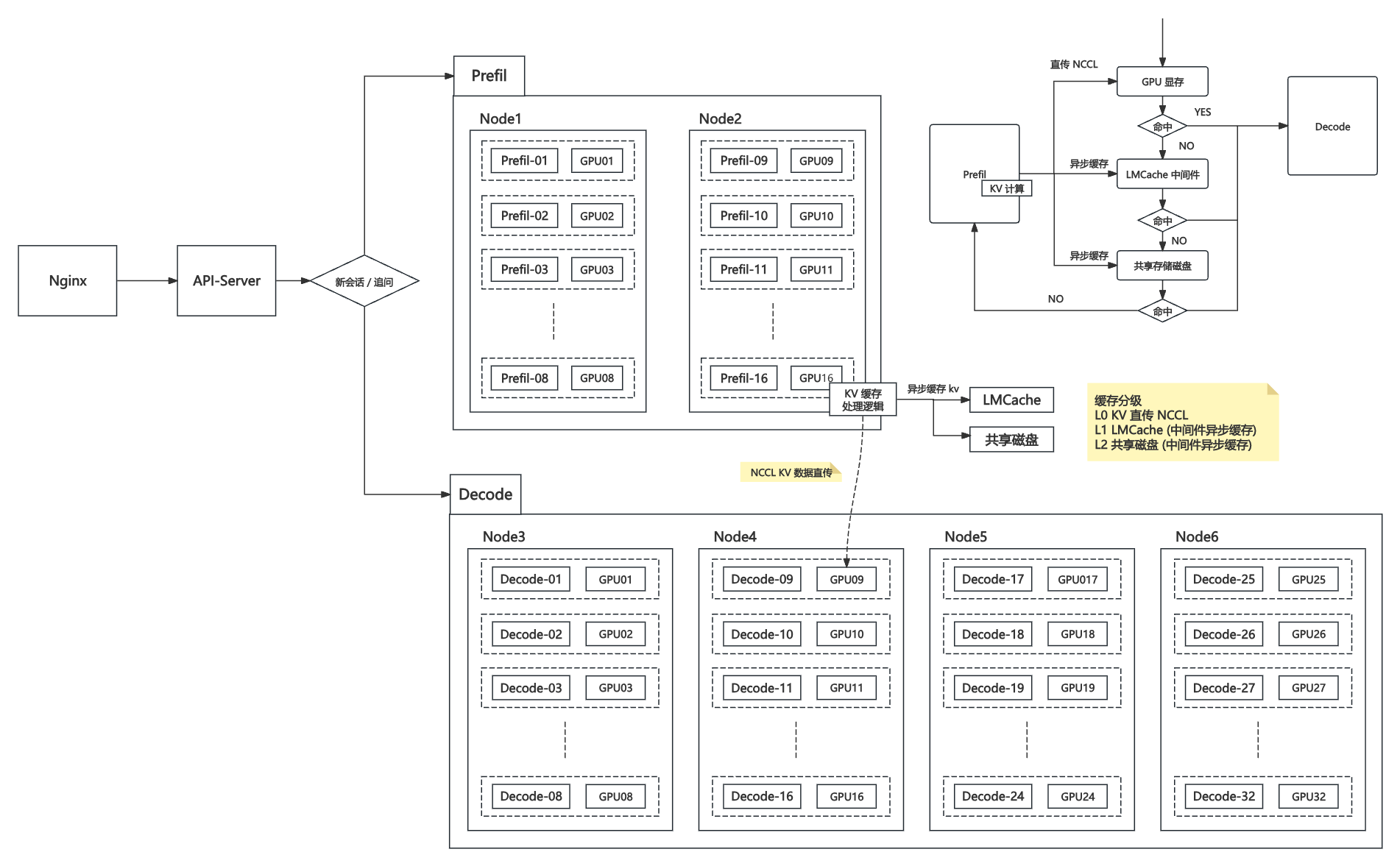
三、kv 緩存分析
3.1 直傳 KV 緩存
通過高速互聯(如 NVIDIA NCCL、NVLink、Infiniband 等)在多 GPU 之間直接傳遞 KV 緩存,無需落盤或經過主機內存。
-
優點:延遲極低、帶寬極高,非常適合同機或高速互聯環境下多 GPU 間的數據交互。
-
典型場景:Prefill 生成 KV 后,直接推送到 Decode GPU,適合高性能集群內部。
3.2 LMCache
利用獨立的 KV 緩存服務(如?LMCache),在集群節點間通過高性能網絡或主機內存中轉和管理 KV 數據。
-
優點:跨主機節點靈活,緩存可設定有效期,支持異步讀寫,適合中大型分布式環境。
-
典型場景:Prefill 結果寫入 LMCache,Decode 階段可在任意節點拉取所需 KV 緩存,實現解耦與彈性擴縮容。
3.3 共享緩存磁盤
將 KV 緩存寫入分布式文件系統或本地共享存儲(如 NFS、Ceph、HDFS),供多節點共享訪問。
-
優點:實現跨節點持久化、可恢復,可用于極大規模或需要歷史緩存復用的場景。
-
缺點:讀寫延遲和帶寬通常劣于顯存直傳和內存緩存,僅適合低頻訪問或大規模冷數據。
-
典型場景:大規模集群、節點動態加入/重啟恢復等需持久化的情況。
3.4 多級緩存
多級緩存是為最大化緩存命中率、降低延遲、平衡成本和容量而設計的一套分層緩存體系,廣泛應用于高性能分布式大模型推理服務中。其核心思想是:優先在最快速的存儲介質中查找和存取 KV 數據,逐層回退至更慢但容量更大的存儲層。
四、SGlang PD 分離實戰
4.1 基礎環境準備
1) GPU 服務器
這里直接選擇單卡雙卡/H800配置測試
2) NCCL 通信網卡
# 查看可用于nccl通信的網卡 在SGlang地方需要指定網卡
ibdev2netdev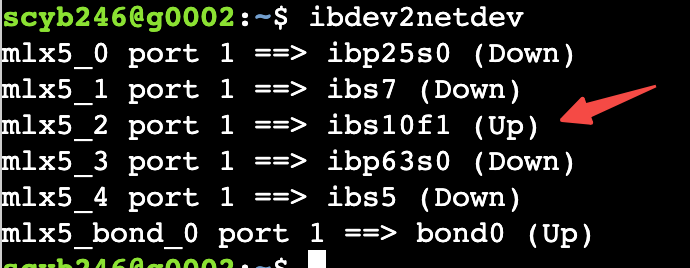
3) 推理模型環境
這里為了測試方便我直接采用sglang[all]全部下載。如果有需要可以按需下載各個組件
pip install sglang[all]
pip install mooncake-transfer-engine4) 基礎模型準備
4.2 推理模型部署
1) prefil 服務啟動
CUDA_VISIBLE_DEVICES=0 python -m sglang.launch_server \--model-path /data/public/model/qwen2.5/qwen2.5-7b-instruct \--port 7000 \--host 0.0.0.0 \--tensor-parallel-size 1 \--disaggregation-mode prefill \--disaggregation-bootstrap-port 8998 \--disaggregation-transfer-backend mooncake \--disaggregation-ib-device mlx5_2 \--max-total-tokens 4096 \--dtype float16 \--trust-remote-code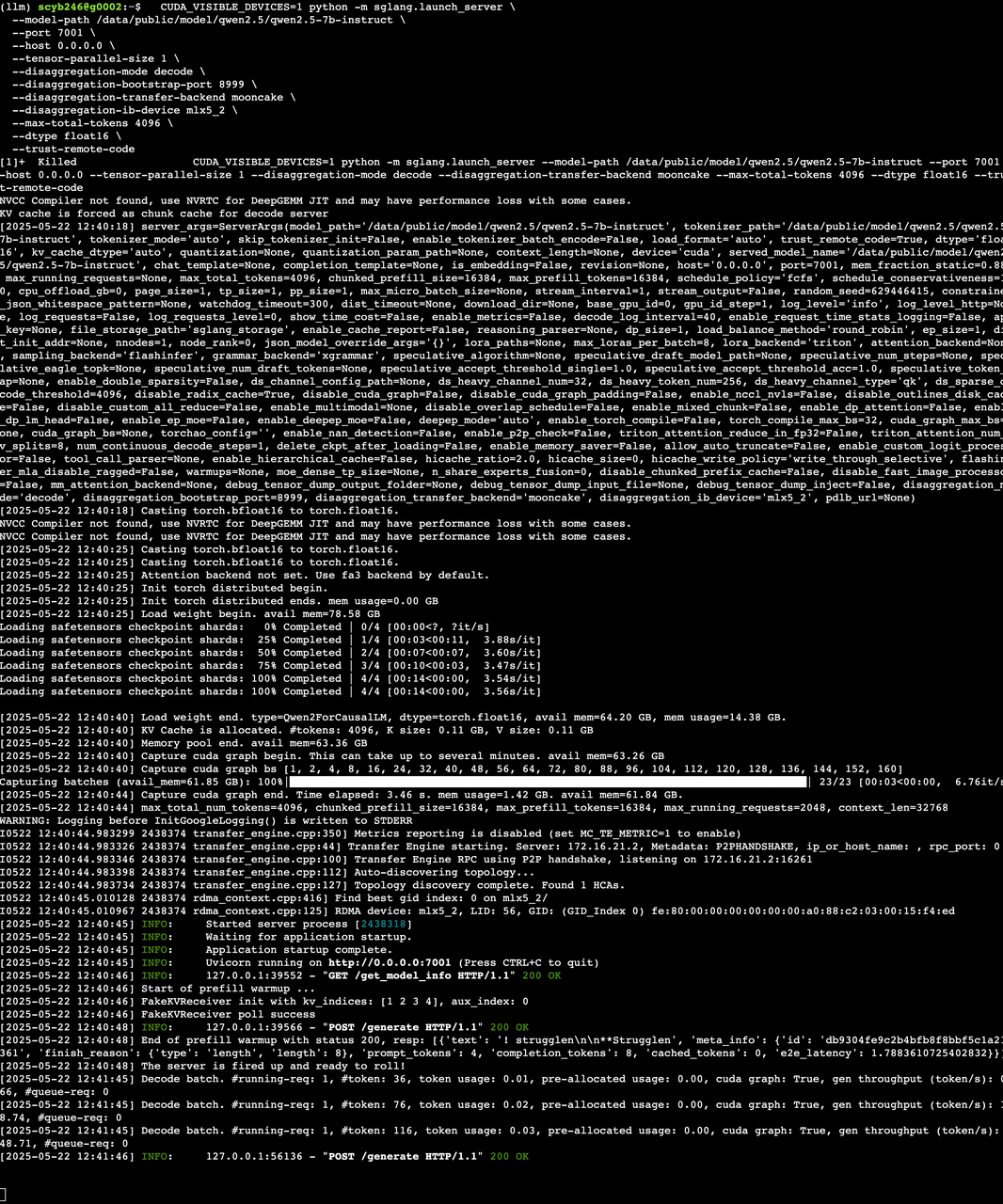
2) decode 服務啟動
CUDA_VISIBLE_DEVICES=1 python -m sglang.launch_server \--model-path /data/public/model/qwen2.5/qwen2.5-7b-instruct \--port 7001 \--host 0.0.0.0 \--tensor-parallel-size 1 \--disaggregation-mode decode \--disaggregation-bootstrap-port 8999 \--disaggregation-transfer-backend mooncake \--disaggregation-ib-device mlx5_2 \--max-total-tokens 4096 \--dtype float16 \--trust-remote-code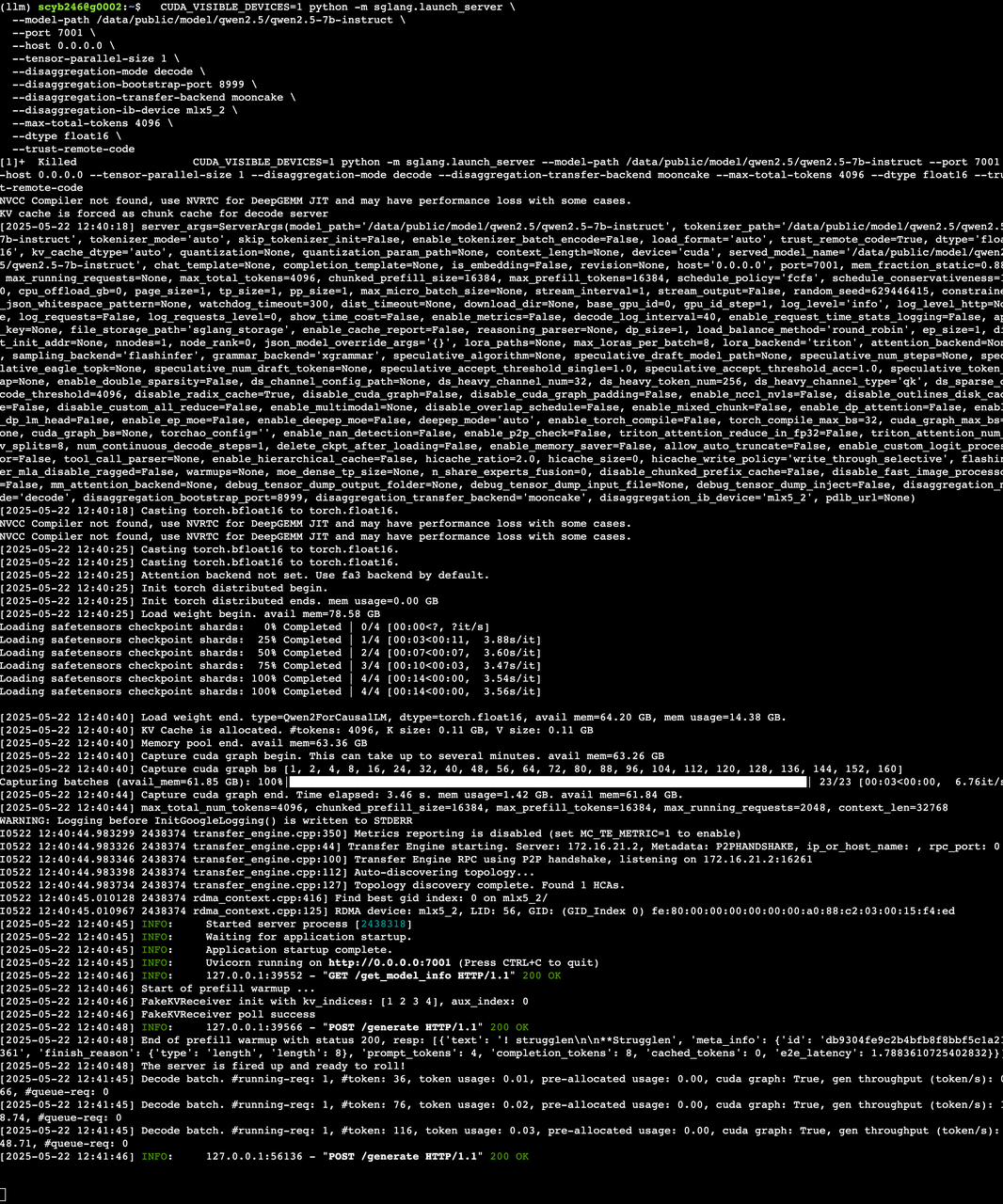
4.3 簡易版路由 mini_lb
python -m sglang.srt.disaggregation.mini_lb \--prefill http://127.0.0.1:7000 \--prefill-bootstrap-ports 8998 \--decode http://127.0.0.1:7001 \--host 0.0.0.0 \--port 8000 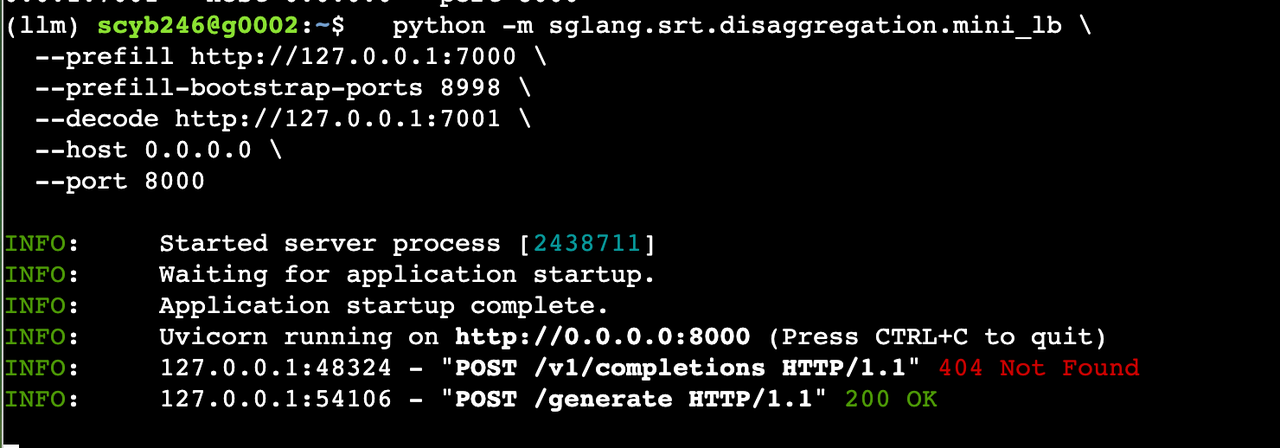
4.4 測試
curl -X POST http://localhost:8000/generate -H "Content-Type: application/json" -d '{"text": "請介紹一下你自己","max_new_tokens": 32,"temperature": 0.7}'
五、小結
kv 緩存概念理解起來就很痛苦。經過各種查資料問大模型才理解整個過程。相當不容易。現在的示例只是提供了 SGLang 的 Mooncake 框架的直傳也屬于 NCCL 的方式。還沒有體現出分布式多級緩存。如果是生產環境則需要將并行策略和多級緩存融合后再實施。
之 yolov5分類模型 訓練自己的數據集)





在Qt中的應用)








)

![函數[x]和{x}在數論中的應用](http://pic.xiahunao.cn/函數[x]和{x}在數論中的應用)
Python爬蟲高階:動態頁面處理與Scrapy+Selenium+BeautifulSoup分布式架構深度解析實戰)
