文章目錄
- 1. 磁盤空間不足-排查流程
- 2. 李導推薦書籍
- 2.1 大話存儲
- 2.2 性能之巔
- 3. 特殊符號
- 3.1 引號系列(面試題)
- 3.2 重定向符號
- 3.2.1 cat與重定向
- 3.2.2 tr命令:替換字符
- 3.2.3 xargs:參數轉換
- 3.2.4 標準全量追加重定向
- 4. 正則表達式
- 4.1 基礎正則
- 4.1.1 測試文件
- 4.1.2 查找以I開頭的行
- 4.1.3 查找以m結尾的行
- 4.1.4 查找非空行
- 4.1.5 排除sshd配置文件中空行和以#開頭的行
- 4.1.6 過濾出以I開頭以!結尾的行
- 4.1.7 過濾出含有大寫字符的行
- 4.1.8 過濾出含有大寫字符或數字的行
- 4.1.9 過濾出文件中以I或m或n開頭的并且以!或數字結尾的行
- 4.1.10 過濾出以.結尾的行
- 4.2 擴展正則
- 4.2.1 查詢sshd或rsyslog進程
- 4.2.2 統計文件中單詞次數,取出前5
- 4.2.3 統計文件中字母次數,取出前5
- 4.2.4 過濾最少有3個最多有5個連續數字的行
- 4.2.5 小括號():表示一個整體
- 5. awk和正則
- 5.1 取出passwd文件中第1、2列和最后一列
- 5.2 取出ip a命令中的ip地址
- 5.3 獲取文件中系統的運行時間
- 5.4 awk取行
- 6. 思維導圖
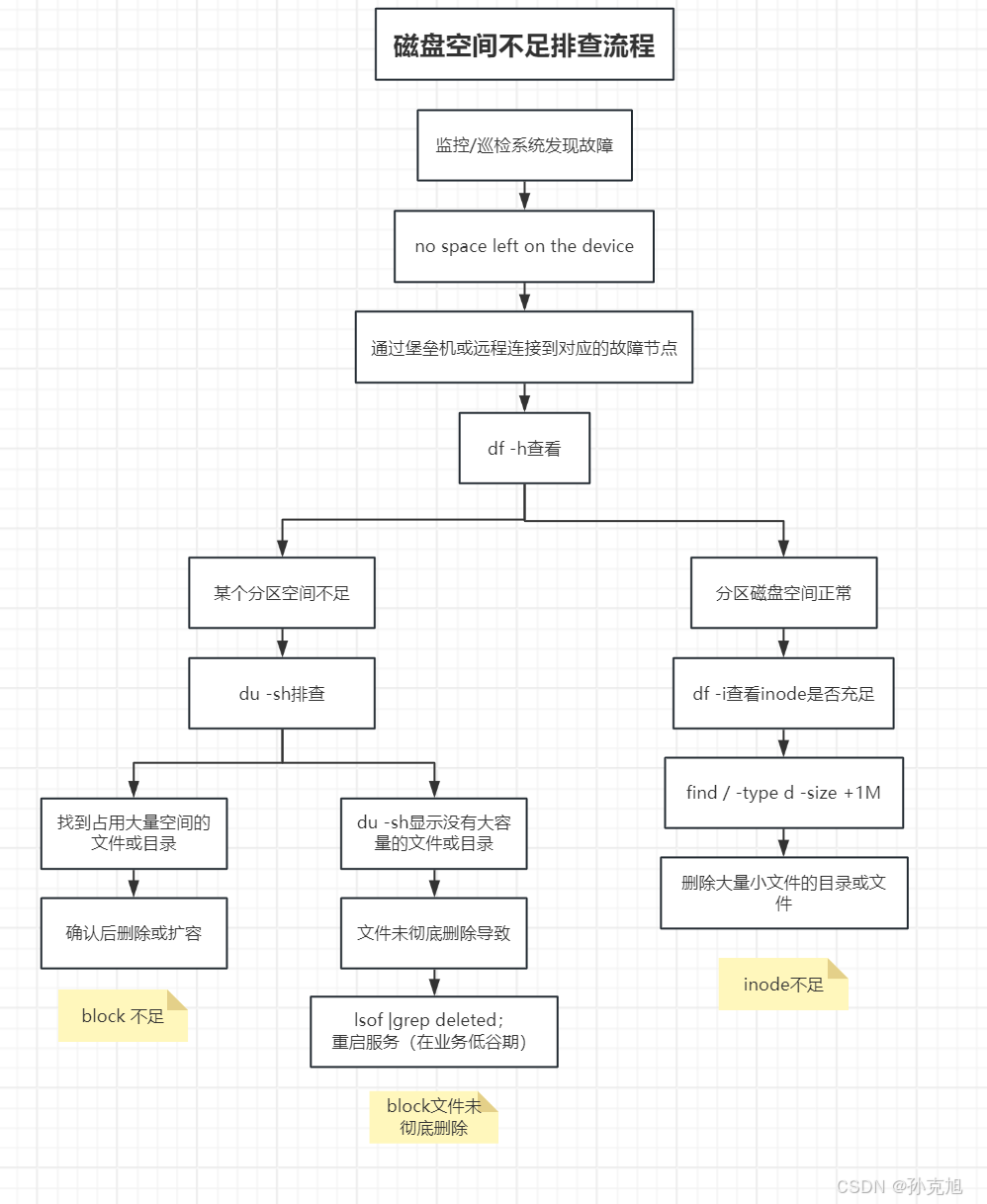
1. 磁盤空間不足-排查流程
2. 李導推薦書籍
2.1 大話存儲

2.2 性能之巔

3. 特殊符號
3.1 引號系列(面試題)
| 引號 | 說明 |
|---|---|
| 反引號 | 執行命令 |
| 單引號 | 所見即所得。單引號中的內容不會被解析,直接進行輸出。 |
| 雙引號 | 一些特殊符號會被解析:``,$(),$…… |
| 不加引號 | 特殊符號會被解析,額外支持{}、*通配符 |
3.2 重定向符號
| 重定向符號 | 說名 | 使用 |
|---|---|---|
| >或1> | 標準輸出重定向 | 創建文件并寫入內容 |
| >>或1>> | 標準輸出追加重定向 | 修改配置文件 |
| 2> | 標準錯誤輸出重定向 | 較少單獨使用 |
| 2>> | 標準錯誤輸出追加重定向 | 較少單獨使用 |
| >>oldboy.log 2>&1; &>>oldboy.log | 正確輸出和錯誤輸出都寫入到同一個文件 | 運行腳本或命令時經常使用 |
| <或0< | 標準輸入重定向,與特定命令使用,讀取文件內容:tr、xargs | 其他命令幾乎不會用 |
| <<或0<< | 標準輸入追加重定向,cat命令向文件中批量寫入多行內容 | cat常用 |
3.2.1 cat與重定向
- cat命令寫文件

- EOF為標識符標識內容的結束,用其他符號也行。
3.2.2 tr命令:替換字符
[root@oldboy99-Kylin /oldboy]# cat w.txt 16:26:42 up 83 days, 7:42, 1 user, load average: 0.00, 0.00, 0.0007:05:48 up 18:42, 2 users, load average: 0.01, 0.01, 0.00
[root@oldboy99-Kylin /oldboy]# tr 'a-z' 'A-Z' < w.txt 16:26:42 UP 83 DAYS, 7:42, 1 USER, LOAD AVERAGE: 0.00, 0.00, 0.0007:05:48 UP 18:42, 2 USERS, LOAD AVERAGE: 0.01, 0.01, 0.00
- tr接受標準輸入的數據,將數據中的小寫字符都替換成本大寫字符
3.2.3 xargs:參數轉換
- xargs的作用:從標準輸入接受多個參數并轉換成多行
- seq num:形成一列的序列數字
[root@oldboy99-Kylin /oldboy]# seq 10 > num.txt
[root@oldboy99-Kylin /oldboy]# cat num.txt
1
2
3
4
5
6
7
8
9
10
[root@oldboy99-Kylin /oldboy]# xargs -n 3 < num.txt
1 2 3
4 5 6
7 8 9
10
3.2.4 標準全量追加重定向
- >>oldboy.log 2>&1
- &>>oldboy.log
[root@oldboy99-Kylin /oldboy]# echo skx >> oldboy.log 2>&1
[root@oldboy99-Kylin /oldboy]# echo skx >> oldboy.log 2>&1
[root@oldboy99-Kylin /oldboy]# echo skx >> oldboy.log 2>&1
[root@oldboy99-Kylin /oldboy]# echo1 skx >> oldboy.log 2>&1
[root@oldboy99-Kylin /oldboy]# echo1 skx >> oldboy.log 2>&1
[root@oldboy99-Kylin /oldboy]# echo1 skx >> oldboy.log 2>&1
[root@oldboy99-Kylin /oldboy]# cat oldboy.log
skx
skx
skx
-bash: echo1: command not found
-bash: echo1: command not found
-bash: echo1: command not found
4. 正則表達式
正則表達式:regular expression,對字符進行查找或過濾。
| 正則表達式 | 符號 | 命令 |
|---|---|---|
| 基礎正則 | ^、&、.、*、[] | grep、sed、awk |
| 擴展正則 | |、+、{}、()、? | egrep/grep -E、sed -r、awk |
4.1 基礎正則
4.1.1 測試文件
cat >/oldboy/re.txt<<EOF
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and
chinese chess!
my blog is http://oldboy.blog.51cto.com
our size is http://blog.oldboyedu.com
my qq is 49000448
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
EOF
4.1.2 查找以I開頭的行
[root@oldboy99-Kylin /oldboy]# grep '^I' re.txt -n
1:I am oldboy teacher!
2:I teach linux.
4:I like badminton ball ,billiard ball and chinese chess!
4.1.3 查找以m結尾的行
- 文件中以m結尾的行最后還有空格
- cat -A:顯示文件中的隱藏字符
[root@oldboy99-Kylin /oldboy]# cat -A re.txt
I am oldboy teacher!$
I teach linux.$
$
I like badminton ball ,billiard ball and chinese chess!$
my blog is http://oldboy.blog.51cto.com $
our size is http://blog.oldboyedu.com $
$
my qq is 49000448$
not 4900000448.$
$
my god ,i am not oldbey,but OLDBOY!$
[root@oldboy99-Kylin /oldboy]# grep 'm $' re.txt
my blog is http://oldboy.blog.51cto.com
our size is http://blog.oldboyedu.com
4.1.4 查找非空行
- ^$:表示過濾空行
[root@oldboy99-Kylin /oldboy]# grep -vn '^$' re.txt
1:I am oldboy teacher!
2:I teach linux.
4:I like badminton ball ,billiard ball and chinese chess!
5:my blog is http://oldboy.blog.51cto.com
6:our size is http://blog.oldboyedu.com
8:my qq is 49000448
9:not 4900000448.
11:my god ,i am not oldbey,but OLDBOY!
4.1.5 排除sshd配置文件中空行和以#開頭的行
grep -Evn '^$|^#' /etc/ssh/sshd_config
4.1.6 過濾出以I開頭以!結尾的行
- .:表示任意字符
- *:表示前一個字符出現0次或多次
[root@oldboy99-Kylin /oldboy]# grep '^I.*!$' re.txt
I am oldboy teacher!
I like badminton ball ,billiard ball and chinese chess!
4.1.7 過濾出含有大寫字符的行
[root@oldboy99-Kylin /oldboy]# grep -n '[A-Z]' re.txt
1:I am oldboy teacher!
2:I teach linux.
4:I like badminton ball ,billiard ball and chinese chess!
11:my god ,i am not oldbey,but OLDBOY!
4.1.8 過濾出含有大寫字符或數字的行
[root@oldboy99-Kylin /oldboy]# grep -n '[A-Z0-9]' re.txt
1:I am oldboy teacher!
2:I teach linux.
4:I like badminton ball ,billiard ball and chinese chess!
5:my blog is http://oldboy.blog.51cto.com
8:my qq is 49000448
9:not 4900000448.
11:my god ,i am not oldbey,but OLDBOY!
4.1.9 過濾出文件中以I或m或n開頭的并且以!或數字結尾的行
[root@oldboy99-Kylin /oldboy]# grep '^[Imn].*[0-9!]$' re.txt
I am oldboy teacher!
I like badminton ball ,billiard ball and chinese chess!
my qq is 49000448
my god ,i am not oldbey,but OLDBOY!
4.1.10 過濾出以.結尾的行
[root@oldboy99-Kylin /oldboy]# grep -n '\.$' re.txt
2:I teach linux.
9:not 4900000448.
####################################################
[root@oldboy99-Kylin /oldboy]# grep -n '[.]$' re.txt
2:I teach linux.
9:not 4900000448.
4.2 擴展正則
4.2.1 查詢sshd或rsyslog進程
[root@oldboy99-Kylin /oldboy]# ps -ef |grep -E '[s]shd|[r]syslog'
root 866 1 0 08:27 ? 00:00:00 sshd: /usr/sbin/sshd -D [listener] 0 of 10-100 startups
root 908 1 0 08:27 ? 00:00:01 /usr/sbin/rsyslogd -n -i/var/run/rsyslogd.pid
root 1670 866 0 09:55 ? 00:00:00 sshd: root [priv]
root 1696 1670 0 09:55 ? 00:00:00 sshd: root@pts/0
4.2.2 統計文件中單詞次數,取出前5
- +:前一個字符出現一次或多次
- -o:輸出匹配的字符
[root@oldboy99-Kylin /oldboy]# grep -Eo '[a-zA-Z]+' re.txt |sort |uniq -c |sort -k1nr |head -53 blog3 I3 is3 my2 am
4.2.3 統計文件中字母次數,取出前5
[root@oldboy99-Kylin /oldboy]# grep -Eo '[a-zA-Z]' re.txt |sort |uniq -c |sort -k1nr |head -518 o15 l12 b11 i11 t
4.2.4 過濾最少有3個最多有5個連續數字的行
[root@oldboy99-Kylin /oldboy]# grep -E '[0-9]{3,5}' re.txt
my qq is 49000448
not 4900000448.
4.2.5 小括號():表示一個整體
[root@oldboy99-Kylin /oldboy]# lscpu |grep -E 'L(1d|1i|2|3)'
L1d cache: 32 KiB
L1i cache: 32 KiB
L2 cache: 256 KiB
L3 cache: 8 MiB
#############################################################
[root@oldboy99-Kylin /oldboy]# lscpu |grep -E 'L(1[di]|[23])'
L1d cache: 32 KiB
L1i cache: 32 KiB
L2 cache: 256 KiB
L3 cache: 8 MiB
5. awk和正則
- -F:Field Separator,字段分隔符
5.1 取出passwd文件中第1、2列和最后一列
[root@oldboy99-Kylin ~]# awk -F ':' '{print $1,$2,$NF}' /etc/passwd |head -5 |column -t
root x /bin/bash
bin x /sbin/nologin
daemon x /sbin/nologin
adm x /sbin/nologin
lp x /sbin/nologin
5.2 取出ip a命令中的ip地址
- awk按照空格或斜線作為分隔符
[root@oldboy99-Kylin ~]# ip a show ens33 |awk -F '[ /]+' 'NR==3{print $3}'
10.0.0.200
5.3 獲取文件中系統的運行時間
文件內容:
cat >> w.txt <<EOF
16:26:42 up 83 days, 7:42, 1 user, load average: 0.00, 0.00, 0.00
07:05:48 up 18:42, 2 users, load average: 0.01, 0.01, 0.00
EOF
[root@oldboy99-Kylin /oldboy]# awk -F 'up +|, +[0-9]+ +user' '{print $2}' w.txt
83 days, 7:42
18:42

5.4 awk取行
- awk ‘NR==3’
- awk ‘NR>=3’
- awk ‘NR>=3&&NR<=10’
- awk ‘/匹配行的正則表達式/’ 文件名
- 在passwd文件中過濾包含root或oldboy的用戶信息
[root@oldboy99-Kylin ~]# awk '/^root|^oldboy/' /etc/passwd
root:x:0:0:root:/root:/bin/bash
oldboy:x:1000:1000::/home/oldboy:/bin/bash
6. 思維導圖
【金山文檔】 思維導圖 https://www.kdocs.cn/l/co3I7PtpTYQX







)


從零實現用MobileFaceNet算法進行實時人臉識別(三)用yolov5-face算法實現人臉檢測)




 C++)



