1.用String.format拼接字符串
不知道你有沒有拼接過字符串,特別是那種有多個參數,字符串比較長的情況。
比如現在有個需求:要用get請求調用第三方接口,url后需要拼接多個參數。
以前我們的請求地址是這樣拼接的:
String url =?"http://susan.sc.cn?userName="+userName+"&age="+age+"&address="+address+"&sex="+sex+"&roledId="+roleId;
字符串使用+號拼接,非常容易出錯。
后面優化了一下,改為使用StringBuilder拼接字符串:
StringBuilder urlBuilder =?new?StringBuilder("http://susan.sc.cn?");
urlBuilder.append("userName=")
.append(userName)
.append("&age=")
.append(age)
.append("&address=")
.append(address)
.append("&sex=")
.append(sex)
.append("&roledId=")
.append(roledId);
代碼優化之后,稍微直觀點。
但還是看起來比較別扭。
這時可以使用String.format方法優化:
String requestUrl =?"http://susan.sc.cn?userName=%s&age=%s&address=%s&sex=%s&roledId=%s";
String url = String.format(requestUrl,userName,age,address,sex,roledId);
代碼的可讀性,一下子提升了很多。
我們平常可以使用String.format方法拼接url請求參數,日志打印等字符串。
但不建議在for循環中用它拼接字符串,因為它的執行效率,比使用+號拼接字符串,或者使用StringBuilder拼接字符串都要慢一些。
2.創建可緩沖的IO流
IO流想必大家都使用得比較多,我們經常需要把數據寫入某個文件,或者從某個文件中讀取數據到內存中,甚至還有可能把文件a,從目錄b,復制到目錄c下等。
JDK給我們提供了非常豐富的API,可以去操作IO流。
例如:
public?class?IoTest1?{public?static?void?main(String[] args)?{FileInputStream fis =?null;FileOutputStream fos =?null;try?{File srcFile =?new?File("/Users/dv_susan/Documents/workspace/jump/src/main/java/com/sue/jump/service/test1/1.txt");File destFile =?new?File("/Users/dv_susan/Documents/workspace/jump/src/main/java/com/sue/jump/service/test1/2.txt");fis =?new?FileInputStream(srcFile);fos =?new?FileOutputStream(destFile);int?len;while?((len = fis.read()) != -1) {fos.write(len);}fos.flush();}?catch?(IOException e) {e.printStackTrace();}?finally?{try?{if?(fos !=?null) {fos.close();}}?catch?(IOException e) {e.printStackTrace();}try?{if?(fis !=?null) {fis.close();}}?catch?(IOException e) {e.printStackTrace();}}}
}
這個例子主要的功能,是將1.txt文件中的內容復制到2.txt文件中。這例子使用普通的IO流從功能的角度來說,也能滿足需求,但性能卻不太好。
因為這個例子中,從1.txt文件中讀一個字節的數據,就會馬上寫入2.txt文件中,需要非常頻繁的讀寫文件。
優化:
public?class?IoTest?{public?static?void?main(String[] args)?{BufferedInputStream bis =?null;BufferedOutputStream bos =?null;FileInputStream fis =?null;FileOutputStream fos =?null;try?{File srcFile =?new?File("/Users/dv_susan/Documents/workspace/jump/src/main/java/com/sue/jump/service/test1/1.txt");File destFile =?new?File("/Users/dv_susan/Documents/workspace/jump/src/main/java/com/sue/jump/service/test1/2.txt");fis =?new?FileInputStream(srcFile);fos =?new?FileOutputStream(destFile);bis =?new?BufferedInputStream(fis);bos =?new?BufferedOutputStream(fos);byte[] buffer =?newbyte[1024];int?len;while?((len = bis.read(buffer)) != -1) {bos.write(buffer,?0, len);}bos.flush();}?catch?(IOException e) {e.printStackTrace();}?finally?{try?{if?(bos !=?null) {bos.close();}if?(fos !=?null) {fos.close();}}?catch?(IOException e) {e.printStackTrace();}try?{if?(bis !=?null) {bis.close();}if?(fis !=?null) {fis.close();}}?catch?(IOException e) {e.printStackTrace();}}}
}
這個例子使用BufferedInputStream和BufferedOutputStream創建了可緩沖的輸入輸出流。
最關鍵的地方是定義了一個buffer字節數組,把從1.txt文件中讀取的數據臨時保存起來,后面再把該buffer字節數組的數據,一次性批量寫入到2.txt中。
這樣做的好處是,減少了讀寫文件的次數,而我們都知道讀寫文件是非常耗時的操作。也就是說使用可緩存的輸入輸出流,可以提升IO的性能,特別是遇到文件非常大時,效率會得到顯著提升。
3.減少循環次數
在我們日常開發中,循環遍歷集合是必不可少的操作。
但如果循環層級比較深,循環中套循環,可能會影響代碼的執行效率。
反例:
for(User user: userList) {for(Role role: roleList) {if(user.getRoleId().equals(role.getId())) {user.setRoleName(role.getName());}}
}
這個例子中有兩層循環,如果userList和roleList數據比較多的話,需要循環遍歷很多次,才能獲取我們所需要的數據,非常消耗cpu資源。
正例:
Map<Long, List<Role>> roleMap = roleList.stream().collect(Collectors.groupingBy(Role::getId));
for?(User user : userList) {List<Role> roles = roleMap.get(user.getRoleId());if(CollectionUtils.isNotEmpty(roles)) {user.setRoleName(roles.get(0).getName());}
}
減少循環次數,最簡單的辦法是,把第二層循環的集合變成map,這樣可以直接通過key,獲取想要的value數據。
雖說map的key存在hash沖突的情況,但遍歷存放數據的鏈表或者紅黑樹的時間復雜度,比遍歷整個list集合要小很多。
4.用完資源記得及時關閉
在我們日常開發中,可能經常訪問資源,比如:獲取數據庫連接,讀取文件等。
我們以獲取數據庫連接為例。
反例:
//1. 加載驅動類
Class.forName("com.mysql.jdbc.Driver");
//2. 創建連接
Connection connection = DriverManager.getConnection("jdbc:mysql//localhost:3306/db?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8","root","123456");
//3.編寫sql
String sql ="select * from user";
//4.創建PreparedStatement
PreparedStatement pstmt = conn.prepareStatement(sql);
//5.獲取查詢結果
ResultSet rs = pstmt.execteQuery();
while(rs.next()){int?id = rs.getInt("id");String name = rs.getString("name");
}
上面這段代碼可以正常運行,但卻犯了一個很大的錯誤,即:ResultSet、PreparedStatement和Connection對象的資源,使用完之后,沒有關閉。
我們都知道,數據庫連接是非常寶貴的資源。我們不可能一直創建連接,并且用完之后,也不回收,白白浪費數據庫資源。
正例:
//1. 加載驅動類
Class.forName("com.mysql.jdbc.Driver");Connection connection =?null;
PreparedStatement pstmt =?null;
ResultSet rs =?null;
try?{//2. 創建連接connection = DriverManager.getConnection("jdbc:mysql//localhost:3306/db?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8","root","123456");//3.編寫sqlString sql ="select * from user";//4.創建PreparedStatementpstmt = conn.prepareStatement(sql);//5.獲取查詢結果rs = pstmt.execteQuery();while(rs.next()){int?id = rs.getInt("id");String name = rs.getString("name");}
}?catch(Exception e) {log.error(e.getMessage(),e);
}?finally?{if(rs !=?null) {rs.close();}if(pstmt !=?null) {pstmt.close();}if(connection !=?null) {connection.close();}
}
這個例子中,無論是ResultSet,或者PreparedStatement,還是Connection對象,使用完之后,都會調用close方法關閉資源。
在這里溫馨提醒一句:ResultSet,或者PreparedStatement,還是Connection對象,這三者關閉資源的順序不能反了,不然可能會出現異常。
5.使用池技術
我們都知道,從數據庫查數據,首先要連接數據庫,獲取Connection資源。
想讓程序多線程執行,需要使用Thread類創建線程,線程也是一種資源。
通常一次數據庫操作的過程是這樣的:
-
創建連接
-
進行數據庫操作
-
關閉連接
而創建連接和關閉連接,是非常耗時的操作,創建連接需要同時會創建一些資源,關閉連接時,需要回收那些資源。
如果用戶的每一次數據庫請求,程序都都需要去創建連接和關閉連接的話,可能會浪費大量的時間。
此外,可能會導致數據庫連接過多。
我們都知道數據庫的最大連接數是有限的,以mysql為例,最大連接數是:100,不過可以通過參數調整這個數量。
如果用戶請求的連接數超過最大連接數,就會報:too many connections異常。如果有新的請求過來,會發現數據庫變得不可用。
這時可以通過命令:
show?variables?like?max_connections
查看最大連接數。
然后通過命令:
set GLOBAL max_connections=1000
手動修改最大連接數。
這種做法只能暫時緩解問題,不是一個好的方案,無法從根本上解決問題。
最大的問題是:數據庫連接數可以無限增長,不受控制。
這時我們可以使用數據庫連接池。
目前Java開源的數據庫連接池有:
-
DBCP:是一個依賴Jakarta commons-pool對象池機制的數據庫連接池。
-
C3P0:是一個開放源代碼的JDBC連接池,它在lib目錄中與Hibernate一起發布,包括了實現jdbc3和jdbc2擴展規范說明的Connection 和Statement 池的DataSources 對象。
-
Druid:阿里的Druid,不僅是一個數據庫連接池,還包含一個ProxyDriver、一系列內置的JDBC組件庫、一個SQL Parser。
-
Proxool:是一個Java SQL Driver驅動程序,它提供了對選擇的其它類型的驅動程序的連接池封裝,可以非常簡單的移植到已有代碼中。
目前用的最多的數據庫連接池是:Druid。
6.反射時加緩存
我們都知道通過反射創建對象實例,比使用new關鍵字要慢很多。
由此,不太建議在用戶請求過來時,每次都通過反射實時創建實例。
有時候,為了代碼的靈活性,又不得不用反射創建實例,這時該怎么辦呢?
答:加緩存。
其實spring中就使用了大量的反射,我們以支付方法為例。
根據前端傳入不同的支付code,動態找到對應的支付方法,發起支付。
我們先定義一個注解。
@Retention(RetentionPolicy.RUNTIME) ?
@Target(ElementType.TYPE) ?
public?@interface?PayCode { ?String?value(); ? ?String?name(); ?
}
在所有的支付類上都加上該注解
@PayCode(value =?"alia", name =?"支付寶支付") ?
@Service
publicclass?AliaPay?implements?IPay?{ ?@Overridepublic?void?pay()?{ ?System.out.println("===發起支付寶支付==="); ?} ?
} ?@PayCode(value =?"weixin", name =?"微信支付") ?
@Service
publicclass?WeixinPay?implements?IPay?{ ?@Overridepublic?void?pay()?{ ?System.out.println("===發起微信支付==="); ?} ?
}?@PayCode(value =?"jingdong", name =?"京東支付") ?
@Service
publicclass?JingDongPay?implements?IPay?{ ?@Overridepublic?void?pay()?{ ?System.out.println("===發起京東支付==="); ?} ?
}
然后增加最關鍵的類:
@Service
publicclass?PayService2?implements?ApplicationListener<ContextRefreshedEvent>?{ ?privatestatic?Map<String, IPay> payMap =?null; ?@Overridepublic?void?onApplicationEvent(ContextRefreshedEvent contextRefreshedEvent)?{ ?ApplicationContext applicationContext = contextRefreshedEvent.getApplicationContext(); ?Map<String, Object> beansWithAnnotation = applicationContext.getBeansWithAnnotation(PayCode.class); ?if?(beansWithAnnotation !=?null) { ?payMap =?new?HashMap<>(); ?beansWithAnnotation.forEach((key, value) ->{ ?String bizType = value.getClass().getAnnotation(PayCode.class).value(); ?payMap.put(bizType, (IPay) value); ?}); ?} ?} ?public?void?pay(String code)?{ ?payMap.get(code).pay(); ?} ?
}
PayService2類實現了ApplicationListener接口,這樣在onApplicationEvent方法中,就可以拿到ApplicationContext的實例。這一步,其實是在spring容器啟動的時候,spring通過反射我們處理好了。
我們再獲取打了PayCode注解的類,放到一個map中,map中的key就是PayCode注解中定義的value,跟code參數一致,value是支付類的實例。
這樣,每次就可以每次直接通過code獲取支付類實例,而不用if...else判斷了。如果要加新的支付方法,只需在支付類上面打上PayCode注解定義一個新的code即可。
注意:這種方式的code可以沒有業務含義,可以是純數字,只要不重復就行。
7.多線程處理
很多時候,我們需要在某個接口中,調用其他服務的接口。
比如有這樣的業務場景:
在用戶信息查詢接口中需要返回:用戶名稱、性別、等級、頭像、積分、成長值等信息。
而用戶名稱、性別、等級、頭像在用戶服務中,積分在積分服務中,成長值在成長值服務中。為了匯總這些數據統一返回,需要另外提供一個對外接口服務。
于是,用戶信息查詢接口需要調用用戶查詢接口、積分查詢接口 和 成長值查詢接口,然后匯總數據統一返回。
調用過程如下圖所示:
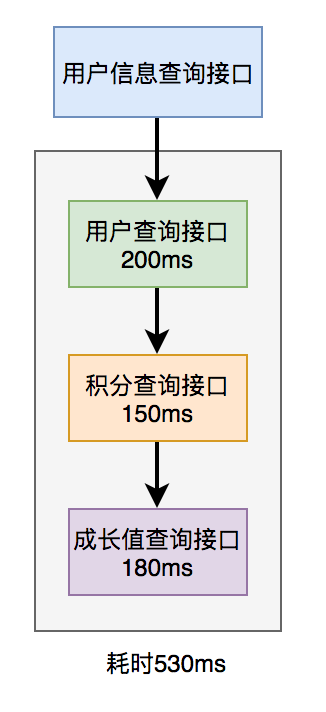
調用遠程接口總耗時 530ms = 200ms + 150ms + 180ms
顯然這種串行調用遠程接口性能是非常不好的,調用遠程接口總的耗時為所有的遠程接口耗時之和。
那么如何優化遠程接口性能呢?
上面說到,既然串行調用多個遠程接口性能很差,為什么不改成并行呢?
如下圖所示:
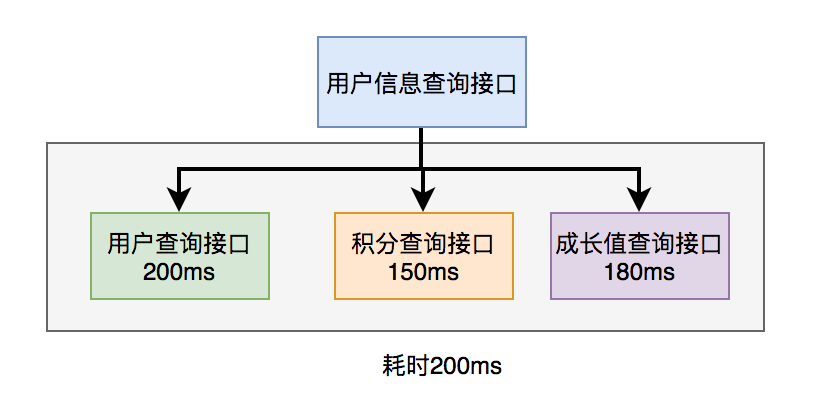
調用遠程接口總耗時 200ms = 200ms(即耗時最長的那次遠程接口調用)
在java8之前可以通過實現Callable接口,獲取線程返回結果。
java8以后通過CompleteFuture類實現該功能。我們這里以CompleteFuture為例:
public?UserInfo?getUserInfo(Long id)?throws?InterruptedException, ExecutionException?{final?UserInfo userInfo =?new?UserInfo();CompletableFuture userFuture = CompletableFuture.supplyAsync(() -> {getRemoteUserAndFill(id, userInfo);return?Boolean.TRUE;}, executor);CompletableFuture bonusFuture = CompletableFuture.supplyAsync(() -> {getRemoteBonusAndFill(id, userInfo);return?Boolean.TRUE;}, executor);CompletableFuture growthFuture = CompletableFuture.supplyAsync(() -> {getRemoteGrowthAndFill(id, userInfo);return?Boolean.TRUE;}, executor);CompletableFuture.allOf(userFuture, bonusFuture, growthFuture).join();userFuture.get();bonusFuture.get();growthFuture.get();return?userInfo;
}
溫馨提醒一下,這兩種方式別忘了使用線程池。示例中我用到了executor,表示自定義的線程池,為了防止高并發場景下,出現線程過多的問題。
8.懶加載
有時候,創建對象是一個非常耗時的操作,特別是在該對象的創建過程中,還需要創建很多其他的對象時。
我們以單例模式為例。
在介紹單例模式的時候,必須要先介紹它的兩種非常著名的實現方式:餓漢模式?和?懶漢模式。
8.1 餓漢模式
實例在初始化的時候就已經建好了,不管你有沒有用到,先建好了再說。具體代碼如下:
public?class?SimpleSingleton?{//持有自己類的引用private?static?final?SimpleSingleton INSTANCE =?new?SimpleSingleton();//私有的構造方法private?SimpleSingleton()?{}//對外提供獲取實例的靜態方法public?static?SimpleSingleton?getInstance()?{return?INSTANCE;}
}
使用餓漢模式的好處是:沒有線程安全的問題,但帶來的壞處也很明顯。
private?static?final?SimpleSingleton INSTANCE =?new?SimpleSingleton();
一開始就實例化對象了,如果實例化過程非常耗時,并且最后這個對象沒有被使用,不是白白造成資源浪費嗎?
還真是啊。
這個時候你也許會想到,不用提前實例化對象,在真正使用的時候再實例化不就可以了?
這就是我接下來要介紹的:懶漢模式。
8.2 懶漢模式
顧名思義就是實例在用到的時候才去創建,“比較懶”,用的時候才去檢查有沒有實例,如果有則返回,沒有則新建。具體代碼如下:
public?class?SimpleSingleton2?{privatestatic?SimpleSingleton2 INSTANCE;private?SimpleSingleton2()?{}public?static?SimpleSingleton2?getInstance()?{if?(INSTANCE ==?null) {INSTANCE =?new?SimpleSingleton2();}return?INSTANCE;}
}
示例中的INSTANCE對象一開始是空的,在調用getInstance方法才會真正實例化。
懶漢模式相對于餓漢模式,沒有提前實例化對象,在真正使用的時候再實例化,在實例化對象的階段效率更高一些。
除了單例模式之外,懶加載的思想,使用比較多的可能是:
-
spring的@Lazy注解。在spring容器啟動的時候,不會調用其getBean方法初始化實例。
-
mybatis的懶加載。在mybatis做級聯查詢的時候,比如查用戶的同時需要查角色信息。如果用了懶加載,先只查用戶信息,真正使用到角色了,才取查角色信息。
9.初始化集合時指定大小
我們在實際項目開發中,需要經常使用集合,比如:ArrayList、HashMap等。
但有個問題:你在初始化集合時指定了大小的嗎?
反例:
public?class?Test2?{public?static?void?main(String[] args)?{List<Integer> list =?new?ArrayList<>();long?time1 = System.currentTimeMillis();for?(int?i =?0; i <?100000; i++) {list.add(i);}System.out.println(System.currentTimeMillis() - time1);}
}
執行時間:
12
如果在初始化集合時指定了大小。
正例:
public?class?Test2?{public?static?void?main(String[] args)?{List<Integer> list2 =?new?ArrayList<>(100000);long?time2 = System.currentTimeMillis();for?(int?i =?0; i <?100000; i++) {list2.add(i);}System.out.println(System.currentTimeMillis() - time2);}
}
執行時間:
6
我們驚奇的發現,在創建集合時指定了大小,比沒有指定大小,添加10萬個元素的效率提升了一倍。
如果你看過ArrayList源碼,你就會發現它的默認大小是10,如果添加元素超過了一定的閥值,會按1.5倍的大小擴容。
你想想,如果裝10萬條數據,需要擴容多少次呀?而每次擴容都需要不停的復制元素,從老集合復制到新集合中,需要浪費多少時間呀。
10.不要滿屏try...catch異常
以前我們在開發接口時,如果出現異常,為了給用戶一個更友好的提示,例如:
@RequestMapping("/test")
@RestController
public?class?TestController?{@GetMapping("/add")public?String?add()?{int?a =?10?/?0;return?"成功";}
}
如果不做任何處理,當我們請求add接口時,執行結果直接報錯:
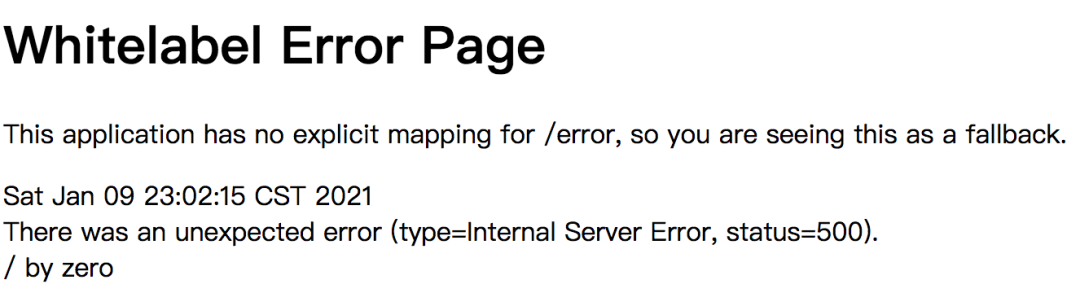
what?用戶能直接看到錯誤信息?
這種交互方式給用戶的體驗非常差,為了解決這個問題,我們通常會在接口中捕獲異常:
@GetMapping("/add")
public?String?add()?{String result =?"成功";try?{int?a =?10?/?0;}?catch?(Exception e) {result =?"數據異常";}return?result;
}
接口改造后,出現異常時會提示:“數據異常”,對用戶來說更友好。
看起來挺不錯的,但是有問題。。。
如果只是一個接口還好,但是如果項目中有成百上千個接口,都要加上異常捕獲代碼嗎?
答案是否定的,這時全局異常處理就派上用場了:RestControllerAdvice。
@RestControllerAdvice
publicclass?GlobalExceptionHandler?{@ExceptionHandler(Exception.class)public?String?handleException(Exception?e)?{if?(e?instanceof?ArithmeticException) {return"數據異常";}if?(e?instanceof?Exception) {return"服務器內部異常";}retur nnull;}
}
只需在handleException方法中處理異常情況,業務接口中可以放心使用,不再需要捕獲異常(有人統一處理了)。真是爽歪歪。
11.位運算效率更高
如果你讀過JDK的源碼,比如:ThreadLocal、HashMap等類,你就會發現,它們的底層都用了位運算。
為什么開發JDK的大神們,都喜歡用位運算?
答:因為位運算的效率更高。
在ThreadLocal的get、set、remove方法中都有這樣一行代碼:
int?i = key.threadLocalHashCode & (len-1);
通過key的hashCode值,與數組的長度減1。其中key就是ThreadLocal對象,與數組的長度減1,相當于除以數組的長度減1,然后取模。
這是一種hash算法。
接下來給大家舉個例子:假設len=16,key.threadLocalHashCode=31,
于是:int i = 31 & 15 = 15
相當于:int i = 31 % 16 = 15
計算的結果是一樣的,但是使用與運算效率跟高一些。
為什么與運算效率更高?
答:因為ThreadLocal的初始大小是16,每次都是按2倍擴容,數組的大小其實一直都是2的n次方。
這種數據有個規律就是高位是0,低位都是1。在做與運算時,可以不用考慮高位,因為與運算的結果必定是0。只需考慮低位的與運算,所以效率更高。
12.巧用第三方工具類
在Java的龐大體系中,其實有很多不錯的小工具,也就是我們平常說的:輪子。
如果在我們的日常工作當中,能夠將這些輪子用戶,再配合一下idea的快捷鍵,可以極大得提升我們的開發效率。
如果你引入com.google.guava的pom文件,會獲得很多好用的小工具。這里推薦一款com.google.common.collect包下的集合工具:Lists。
它是在太好用了,讓我愛不釋手。
如果你想將一個大集合分成若干個小集合。
之前我們是這樣做的:
List<Integer> list = Lists.newArrayList(1,?2,?3,?4,?5);List<List<Integer>> partitionList = Lists.newArrayList();
int?size =?0;
List<Integer> dataList = Lists.newArrayList();
for(Integer data : list) {if(size >=?2) {dataList = Lists.newArrayList();size =?0;}?size++;dataList.add(data);
}
將list按size=2分成多個小集合,上面的代碼看起來比較麻煩。
如果使用Lists的partition方法,可以這樣寫代碼:
List<Integer> list = Lists.newArrayList(1,?2,?3,?4,?5);
List<List<Integer>> partitionList = Lists.partition(list,?2);
System.out.println(partitionList);
執行結果:
[[1,?2], [3,?4], [5]]
這個例子中,list有5條數據,我將list集合按大小為2,分成了3頁,即變成3個小集合。
這個是我最喜歡的方法之一,經常在項目中使用。
比如有個需求:現在有5000個id,需要調用批量用戶查詢接口,查出用戶數據。但如果你直接查5000個用戶,單次接口響應時間可能會非常慢。如果改成分頁處理,每次只查500個用戶,異步調用10次接口,就不會有單次接口響應慢的問題。
13.用同步代碼塊代替同步方法
在某些業務場景中,為了防止多個線程并發修改某個共享數據,造成數據異常。
為了解決并發場景下,多個線程同時修改數據,造成數據不一致的情況。通常情況下,我們會:加鎖。
但如果鎖加得不好,導致鎖的粒度太粗,也會非常影響接口性能。
在java中提供了synchronized關鍵字給我們的代碼加鎖。
通常有兩種寫法:在方法上加鎖?和?在代碼塊上加鎖。
先看看如何在方法上加鎖:
public?synchronized?doSave(String fileUrl)?{mkdir();uploadFile(fileUrl);sendMessage(fileUrl);
}
這里加鎖的目的是為了防止并發的情況下,創建了相同的目錄,第二次會創建失敗,影響業務功能。
但這種直接在方法上加鎖,鎖的粒度有點粗。因為doSave方法中的上傳文件和發消息方法,是不需要加鎖的。只有創建目錄方法,才需要加鎖。
我們都知道文件上傳操作是非常耗時的,如果將整個方法加鎖,那么需要等到整個方法執行完之后才能釋放鎖。顯然,這會導致該方法的性能很差,變得得不償失。
這時,我們可以改成在代碼塊上加鎖了,具體代碼如下:
public?void?doSave(String path,String fileUrl)?{synchronized(this) {if(!exists(path)) {mkdir(path);}}uploadFile(fileUrl);sendMessage(fileUrl);
}
這樣改造之后,鎖的粒度一下子變小了,只有并發創建目錄功能才加了鎖。而創建目錄是一個非常快的操作,即使加鎖對接口的性能影響也不大。
最重要的是,其他的上傳文件和發送消息功能,任然可以并發執行。
14.不用的數據及時清理
在Java中保證線程安全的技術有很多,可以使用synchroized、Lock等關鍵字給代碼塊加鎖。
但是它們有個共同的特點,就是加鎖會對代碼的性能有一定的損耗。
其實,在jdk中還提供了另外一種思想即:用空間換時間。
沒錯,使用ThreadLocal類就是對這種思想的一種具體體現。
ThreadLocal為每個使用變量的線程提供了一個獨立的變量副本,這樣每一個線程都能獨立地改變自己的副本,而不會影響其它線程所對應的副本。
ThreadLocal的用法大致是這樣的:
-
先創建一個CurrentUser類,其中包含了ThreadLocal的邏輯。
public?class?CurrentUser?{privatestaticfinal?ThreadLocal<UserInfo> THREA_LOCAL =?new?ThreadLocal();public?static?void?set(UserInfo userInfo)?{THREA_LOCAL.set(userInfo);}public?static?UserInfo?get()?{THREA_LOCAL.get();}public?static?void?remove()?{THREA_LOCAL.remove();}
}
-
在業務代碼中調用CurrentUser類。
public?void?doSamething(UserDto userDto)?{UserInfo userInfo = convert(userDto);CurrentUser.set(userInfo);...//業務代碼UserInfo userInfo = CurrentUser.get();...
}
在業務代碼的第一行,將userInfo對象設置到CurrentUser,這樣在業務代碼中,就能通過CurrentUser.get()獲取到剛剛設置的userInfo對象。特別是對業務代碼調用層級比較深的情況,這種用法非常有用,可以減少很多不必要傳參。
但在高并發的場景下,這段代碼有問題,只往ThreadLocal存數據,數據用完之后并沒有及時清理。
ThreadLocal即使使用了WeakReference(弱引用)也可能會存在內存泄露問題,因為 entry對象中只把key(即threadLocal對象)設置成了弱引用,但是value值沒有。
那么,如何解決這個問題呢?
public?void?doSamething(UserDto userDto)?{UserInfo userInfo = convert(userDto);try{CurrentUser.set(userInfo);...//業務代碼UserInfo userInfo = CurrentUser.get();...}?finally?{CurrentUser.remove();}
}
需要在finally代碼塊中,調用remove方法清理沒用的數據。
15.用equals方法比較是否相等
不知道你在項目中有沒有見過,有些同事對Integer類型的兩個參數使用==號比較是否相等?
反正我見過的,那么這種用法對嗎?
我的回答是看具體場景,不能說一定對,或不對。
有些狀態字段,比如:orderStatus有:-1(未下單),0(已下單),1(已支付),2(已完成),3(取消),5種狀態。
這時如果用==判斷是否相等:
Integer orderStatus1 =?new?Integer(1);
Integer orderStatus2 =?new?Integer(1);
System.out.println(orderStatus1 == orderStatus2);
返回結果會是true嗎?
答案:是false。
有些同學可能會反駁,Integer中不是有范圍是:-128-127的緩存嗎?
為什么是false?
先看看Integer的構造方法:
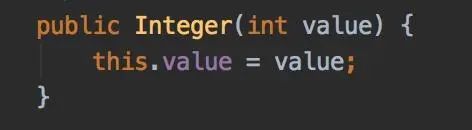
它其實并沒有用到緩存。
那么緩存是在哪里用的?
答案在valueOf方法中:
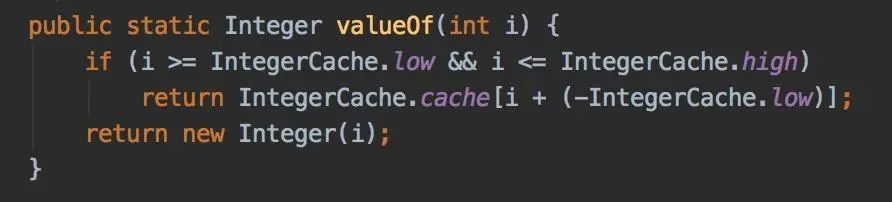
如果上面的判斷改成這樣:
String orderStatus1 =?new?String("1");
String orderStatus2 =?new?String("1");
System.out.println(Integer.valueOf(orderStatus1) == Integer.valueOf(orderStatus2));
返回結果會是true嗎?
答案:還真是true。
我們要養成良好編碼習慣,盡量少用==判斷兩個Integer類型數據是否相等,只有在上述非常特殊的場景下才相等。
而應該改成使用equals方法判斷:
Integer orderStatus1 =?new?Integer(1);
Integer orderStatus2 =?new?Integer(1);
System.out.println(orderStatus1.equals(orderStatus2));
運行結果為true。
16.避免創建大集合
很多時候,我們在日常開發中,需要創建集合。比如:為了性能考慮,從數據庫查詢某張表的所有數據,一次性加載到內存的某個集合中,然后做業務邏輯處理。
例如:
List<User> userList = userMapper.getAllUser();
for(User user:userList) {doSamething();
}
從數據庫一次性查詢出所有用戶,然后在循環中,對每個用戶進行業務邏輯處理。
如果用戶表的數據量非常多時,這樣userList集合會很大,可能直接導致內存不足,而使整個應用掛掉。
針對這種情況,必須做分頁處理。
例如:
private?staticfinalint?PAGE_SIZE =?500;int?currentPage =?1;
RequestPage page =?new?RequestPage();
page.setPageNo(currentPage);
page.setPageSize(PAGE_SIZE);Page<User> pageUser = userMapper.search(page);while(pageUser.getPageCount() >= currentPage) {for(User user:pageUser.getData()) {doSamething();}page.setPageNo(++currentPage);pageUser = userMapper.search(page);
}
通過上面的分頁改造之后,每次從數據庫中只查詢500條記錄,保存到userList集合中,這樣userList不會占用太多的內存。
這里特別說明一下,如果你查詢的表中的數據量本來就很少,一次性保存到內存中,也不會占用太多內存,這種情況也可以不做分頁處理。
此外,還有種特殊的情況,即表中的記錄數并不算多,但每一條記錄,都有很多字段,單條記錄就占用很多內存空間,這時也需要做分頁處理,不然也會有問題。
整體的原則是要盡量避免創建大集合,導致內存不足的問題,但是具體多大才算大集合。目前沒有一個唯一的衡量標準,需要結合實際的業務場景進行單獨分析。
17.狀態用枚舉
在我們建的表中,有很多狀態字段,比如:訂單狀態、禁用狀態、刪除狀態等。
每種狀態都有多個值,代表不同的含義。
比如訂單狀態有:
-
1:表示下單
-
2:表示支付
-
3:表示完成
-
4:表示撤銷
如果沒有使用枚舉,一般是這樣做的:
public?staticfinalint?ORDER_STATUS_CREATE =?1;
publicstaticfinalint?ORDER_STATUS_PAY =?2;
publicstaticfinalint?ORDER_STATUS_DONE =?3;
publicstaticfinalint?ORDER_STATUS_CANCEL =?4;
publicstaticfinal?String ORDER_STATUS_CREATE_MESSAGE =?"下單";
publicstaticfinal?String ORDER_STATUS_PAY =?"下單";
publicstaticfinal?String ORDER_STATUS_DONE =?"下單";
publicstaticfinal?String ORDER_STATUS_CANCEL =?"下單";
需要定義很多靜態常量,包含不同的狀態和狀態的描述。
使用枚舉定義之后,代碼如下:
public?enum?OrderStatusEnum { ?CREATE(1,?"下單"), ?PAY(2,?"支付"), ?DONE(3,?"完成"), ?CANCEL(4,?"撤銷"); ?privateint?code; ?private?String message; ?OrderStatusEnum(int?code, String message) { ?this.code = code; ?this.message = message; ?} ?public?int?getCode()?{ ?returnthis.code; ?} ?public?String?getMessage()?{ ?returnthis.message; ?} ?public?static?OrderStatusEnum?getOrderStatusEnum(int?code)?{ ?return?Arrays.stream(OrderStatusEnum.values()).filter(x -> x.code == code).findFirst().orElse(null); ?} ?
}
使用枚舉改造之后,職責更單一了。
而且使用枚舉的好處是:
-
代碼的可讀性變強了,不同的狀態,有不同的枚舉進行統一管理和維護。
-
枚舉是天然單例的,可以直接使用==號進行比較。
-
code和message可以成對出現,比較容易相關轉換。
-
枚舉可以消除if...else過多問題。
18.把固定值定義成靜態常量
不知道你在實際的項目開發中,有沒有使用過固定值?
例如:
if(user.getId() <?1000L) {doSamething();
}
或者:
if(Objects.isNull(user)) {throw?new?BusinessException("該用戶不存在");
}
其中1000L和該用戶不存在是固定值,每次都是一樣的。
既然是固定值,我們為什么不把它們定義成靜態常量呢?
這樣語義上更直觀,方便統一管理和維護,更方便代碼復用。
代碼優化為:
private?static?final?int?DEFAULT_USER_ID =?1000L;
...
if(user.getId() < DEFAULT_USER_ID) {doSamething();
}
或者:
private?static?final?String NOT_FOUND_MESSAGE =?"該用戶不存在";
...
if(Objects.isNull(user)) {throw?new?BusinessException(NOT_FOUND_MESSAGE);
}
使用static final關鍵字修飾靜態常量,static表示靜態的意思,即類變量,而final表示不允許修改。
兩個關鍵字加在一起,告訴Java虛擬機這種變量,在內存中只有一份,在全局上是唯一的,不能修改,也就是靜態常量。
19.避免大事務
很多小伙伴在使用spring框架開發項目時,為了方便,喜歡使用@Transactional注解提供事務功能。
沒錯,使用@Transactional注解這種聲明式事務的方式提供事務功能,確實能少寫很多代碼,提升開發效率。
但也容易造成大事務,引發其他的問題。
下面用一張圖看看大事務引發的問題。
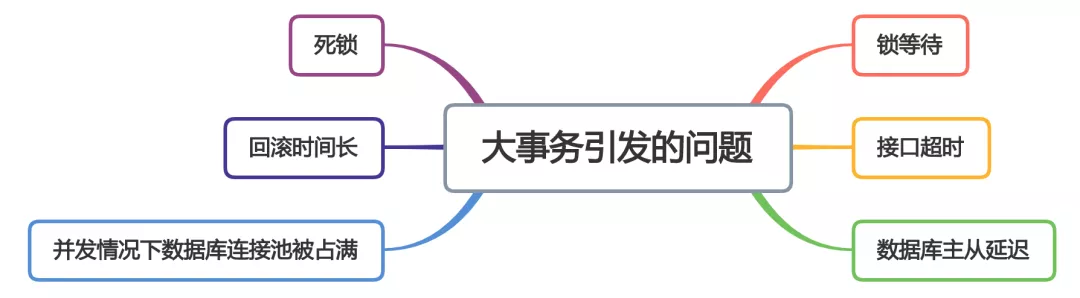
從圖中能夠看出,大事務問題可能會造成接口超時,對接口的性能有直接的影響。
我們該如何優化大事務呢?
-
少用@Transactional注解
-
將查詢(select)方法放到事務外
-
事務中避免遠程調用
-
事務中避免一次性處理太多數據
-
有些功能可以非事務執行
-
有些功能可以異步處理
20.消除過長的if...else
我們在寫代碼的時候,if...else的判斷條件是必不可少的。不同的判斷條件,走的代碼邏輯通常會不一樣。
廢話不多說,先看看下面的代碼。
public?interface?IPay?{ ?void?pay(); ?
} ?@Service
publicclass?AliaPay?implements?IPay?{ ?@Overridepublic?void?pay()?{ ?System.out.println("===發起支付寶支付==="); ?} ?
} ?@Service
publicclass?WeixinPay?implements?IPay?{ ?@Overridepublic?void?pay()?{ ?System.out.println("===發起微信支付==="); ?} ?
} ?@Service
publicclass?JingDongPay?implements?IPay?{ ?@Overridepublic?void?pay()?{ ?System.out.println("===發起京東支付===");?} ?
} ?@Service
publicclass?PayService?{ ?@Autowiredprivate?AliaPay aliaPay; ?@Autowiredprivate?WeixinPay weixinPay; ?@Autowiredprivate?JingDongPay jingDongPay; ?public?void?toPay(String code)?{ ?if?("alia".equals(code)) { ?aliaPay.pay(); ?} elseif ("weixin".equals(code)) { ?weixinPay.pay(); ?} elseif ("jingdong".equals(code)) { ?jingDongPay.pay(); ?}?else?{ ?System.out.println("找不到支付方式"); ?} ?} ?
}
PayService類的toPay方法主要是為了發起支付,根據不同的code,決定調用用不同的支付類(比如:aliaPay)的pay方法進行支付。
這段代碼有什么問題呢?也許有些人就是這么干的。
試想一下,如果支付方式越來越多,比如:又加了百度支付、美團支付、銀聯支付等等,就需要改toPay方法的代碼,增加新的else...if判斷,判斷多了就會導致邏輯越來越多?
很明顯,這里違法了設計模式六大原則的:開閉原則 和 單一職責原則。
開閉原則:對擴展開放,對修改關閉。就是說增加新功能要盡量少改動已有代碼。
單一職責原則:顧名思義,要求邏輯盡量單一,不要太復雜,便于復用。
那么,如何優化if...else判斷呢?
答:使用?策略模式+工廠模式。
策略模式定義了一組算法,把它們一個個封裝起來, 并且使它們可相互替換。工廠模式用于封裝和管理對象的創建,是一種創建型模式。
public?interface?IPay?{void?pay();
}@Service
publicclass?AliaPay?implements?IPay?{@PostConstructpublic?void?init()?{PayStrategyFactory.register("aliaPay",?this);}@Overridepublic?void?pay()?{System.out.println("===發起支付寶支付===");}
}@Service
publicclass?WeixinPay?implements?IPay?{@PostConstructpublic?void?init()?{PayStrategyFactory.register("weixinPay",?this);}@Overridepublic?void?pay()?{System.out.println("===發起微信支付===");}
}@Service
publicclass?JingDongPay?implements?IPay?{@PostConstructpublic?void?init()?{PayStrategyFactory.register("jingDongPay",?this);}@Overridepublic?void?pay()?{System.out.println("===發起京東支付===");}
}publicclass?PayStrategyFactory?{privatestatic?Map<String, IPay> PAY_REGISTERS =?new?HashMap<>();public?static?void?register(String code, IPay iPay)?{if?(null?!= code && !"".equals(code)) {PAY_REGISTERS.put(code, iPay);}}public?static?IPay?get(String code)?{return?PAY_REGISTERS.get(code);}
}@Service
publicclass?PayService3?{public?void?toPay(String code)?{PayStrategyFactory.get(code).pay();}
}
這段代碼的關鍵是PayStrategyFactory類,它是一個策略工廠,里面定義了一個全局的map,在所有IPay的實現類中注冊當前實例到map中,然后在調用的地方通過PayStrategyFactory類根據code從map獲取支付類實例即可。
如果加了一個新的支付方式,只需新加一個類實現IPay接口,定義init方法,并且重寫pay方法即可,其他代碼基本上可以不用動。
當然,消除又臭又長的if...else判斷,還有很多方法,比如:使用注解、動態拼接類名稱、模板方法、枚舉等等。
21.防止死循環
有些小伙伴看到這個標題,可能會感到有點意外,代碼中不是應該避免死循環嗎?為啥還是會產生死循環?
殊不知有些死循環是我們自己寫的,例如下面這段代碼:
while(true) {if(condition) {break;}System.out.println("do samething");
}
這里使用了while(true)的循環調用,這種寫法在CAS自旋鎖中使用比較多。
當滿足condition等于true的時候,則自動退出該循環。
如果condition條件非常復雜,一旦出現判斷不正確,或者少寫了一些邏輯判斷,就可能在某些場景下出現死循環的問題。
出現死循環,大概率是開發人員人為的bug導致的,不過這種情況很容易被測出來。
還有一種隱藏的比較深的死循環,是由于代碼寫的不太嚴謹導致的。如果用正常數據,可能測不出問題,但一旦出現異常數據,就會立即出現死循環。
其實,還有另一種死循環:無限遞歸。
如果想要打印某個分類的所有父分類,可以用類似這樣的遞歸方法實現:
public?void?printCategory(Category category)?{if(category ==?null?|| category.getParentId() ==?null) {return;}?System.out.println("父分類名稱:"+ category.getName());Category parent = categoryMapper.getCategoryById(category.getParentId());printCategory(parent);
}
正常情況下,這段代碼是沒有問題的。
但如果某次有人誤操作,把某個分類的parentId指向了它自己,這樣就會出現無限遞歸的情況。導致接口一直不能返回數據,最終會發生堆棧溢出。
建議寫遞歸方法時,設定一個遞歸的深度,比如:分類最大等級有4級,則深度可以設置為4。然后在遞歸方法中做判斷,如果深度大于4時,則自動返回,這樣就能避免無限循環的情況。
22.注意BigDecimal的坑
通常我們會把一些小數類型的字段(比如:金額),定義成BigDecimal,而不是Double,避免丟失精度問題。
使用Double時可能會有這種場景:
double?amount1 =?0.02;
double?amount2 =?0.03;
System.out.println(amount2 - amount1);
正常情況下預計amount2 - amount1應該等于0.01
但是執行結果,卻為:
0.009999999999999998
實際結果小于預計結果。
Double類型的兩個參數相減會轉換成二進制,因為Double有效位數為16位這就會出現存儲小數位數不夠的情況,這種情況下就會出現誤差。
常識告訴我們使用BigDecimal能避免丟失精度。
但是使用BigDecimal能避免丟失精度嗎?
答案是否定的。
為什么?
BigDecimal amount1 =?new?BigDecimal(0.02);
BigDecimal amount2 =?new?BigDecimal(0.03);
System.out.println(amount2.subtract(amount1));
這個例子中定義了兩個BigDecimal類型參數,使用構造函數初始化數據,然后打印兩個參數相減后的值。
結果:
0.0099999999999999984734433411404097569175064563751220703125
不科學呀,為啥還是丟失精度了?
Jdk中BigDecimal的構造方法上有這樣一段描述:
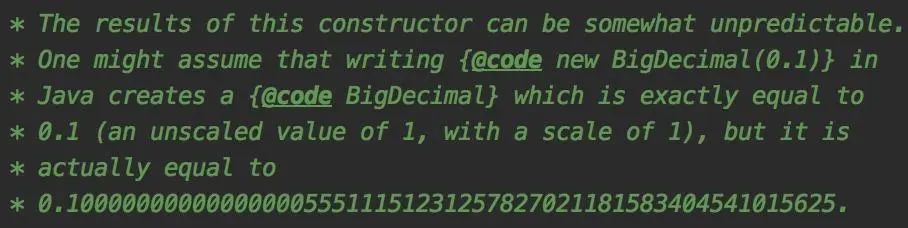
大致的意思是此構造函數的結果可能不可預測,可能會出現創建時為0.1,但實際是0.1000000000000000055511151231257827021181583404541015625的情況。
由此可見,使用BigDecimal構造函數初始化對象,也會丟失精度。
那么,如何才能不丟失精度呢?
BigDecimal amount1 =?new?BigDecimal(Double.toString(0.02));
BigDecimal amount2 =?new?BigDecimal(Double.toString(0.03));
System.out.println(amount2.subtract(amount1));
我們可以使用Double.toString方法,對double類型的小數進行轉換,這樣能保證精度不丟失。
其實,還有更好的辦法:
BigDecimal amount1 = BigDecimal.valueOf(0.02);
BigDecimal amount2 = BigDecimal.valueOf(0.03);
System.out.println(amount2.subtract(amount1));
使用BigDecimal.valueOf方法初始化BigDecimal類型參數,也能保證精度不丟失。在新版的阿里巴巴開發手冊中,也推薦使用這種方式創建BigDecimal參數。
23.盡可能復用代碼
ctrl + c?和?ctrl + v可能是程序員使用最多的快捷鍵了。
沒錯,我們是大自然的搬運工。哈哈哈。
在項目初期,我們使用這種工作模式,確實可以提高一些工作效率,可以少寫(實際上是少敲)很多代碼。
但它帶來的問題是:會出現大量的代碼重復。例如:
@Service
@Slf4j
public?class?TestService1?{public?void?test1()??{addLog("test1");}private?void?addLog(String info)?{if?(log.isInfoEnabled()) {log.info("info:{}", info);}}
}
@Service
@Slf4j
public?class?TestService2?{public?void?test2()??{addLog("test2");}private?void?addLog(String info)?{if?(log.isInfoEnabled()) {log.info("info:{}", info);}}
}
@Service
@Slf4j
public?class?TestService3?{public?void?test3()??{addLog("test3");}private?void?addLog(String info)?{if?(log.isInfoEnabled()) {log.info("info:{}", info);}}
}
在TestService1、TestService2、TestService3類中,都有一個addLog方法用于添加日志。
本來該功能用得好好的,直到有一天,線上出現了一個事故:服務器磁盤滿了。
原因是打印的日志太多,記了很多沒必要的日志,比如:查詢接口的所有返回值,大對象的具體打印等。
沒辦法,只能將addLog方法改成只記錄debug日志。
于是乎,你需要全文搜索,addLog方法去修改,改成如下代碼:
private?void?addLog(String info)?{if?(log.isDebugEnabled()) {log.debug("debug:{}", info);}
}
這里是有三個類中需要修改這段代碼,但如果實際工作中有三十個、三百個類需要修改,會讓你非常痛苦。改錯了,或者改漏了,都會埋下隱患,把自己坑了。
為何不把這種功能的代碼提取出來,放到某個工具類中呢?
@Slf4j
public?class?LogUtil?{private?LogUtil()?{throw?new?RuntimeException("初始化失敗");}public?static?void?addLog(String info)?{if?(log.isDebugEnabled()) {log.debug("debug:{}", info);}}
}
然后,在其他的地方,只需要調用。
@Service
@Slf4j
public?class?TestService1?{public?void?test1()??{LogUtil.addLog("test1");}
}
如果哪天addLog的邏輯又要改了,只需要修改LogUtil類的addLog方法即可。你可以自信滿滿的修改,不需要再小心翼翼了。
我們寫的代碼,絕大多數是可維護性的代碼,而非一次性的。所以,建議在寫代碼的過程中,如果出現重復的代碼,盡量提取成公共方法。千萬別因為項目初期一時的爽快,而給項目埋下隱患,后面的維護成本可能會非常高。
24.foreach循環中不remove元素
我們知道在Java中,循環有很多種寫法,比如:while、for、foreach等。
public?class?Test2?{public?static?void?main(String[] args)?{List<String> list = Lists.newArrayList("a","b","c");for?(String temp : list) {if?("c".equals(temp)) {list.remove(temp);}}System.out.println(list);}
}
執行結果:
Exception in thread?"main"?java.util.ConcurrentModificationExceptionat java.util.ArrayList$Itr.checkForComodification(ArrayList.java:901)at java.util.ArrayList$Itr.next(ArrayList.java:851)at com.sue.jump.service.test1.Test2.main(Test2.java:24)
這種在foreach循環中調用remove方法刪除元素,可能會報ConcurrentModificationException異常。
如果想在遍歷集合時,刪除其中的元素,可以用for循環,例如:
public?class?Test2?{public?static?void?main(String[] args)?{List<String> list = Lists.newArrayList("a","b","c");for?(int?i =?0; i < list.size(); i++) {String temp = list.get(i);if?("c".equals(temp)) {list.remove(temp);}}System.out.println(list);}
}
執行結果:
[a, b]
25.避免隨意打印日志
在我們寫代碼的時候,打印日志是必不可少的工作之一。
因為日志可以幫我們快速定位問題,判斷代碼當時真正的執行邏輯。
但打印日志的時候也需要注意,不是說任何時候都要打印日志,比如:
@PostMapping("/query")
public?List<User>?query(@RequestBody List<Long> ids)?{log.info("request params:{}", ids);List<User> userList = userService.query(ids);log.info("response:{}", userList);return?userList;
}
對于有些查詢接口,在日志中打印出了請求參數和接口返回值。
咋一看沒啥問題。
但如果ids中傳入值非常多,比如有1000個。而該接口被調用的頻次又很高,一下子就會打印大量的日志,用不了多久就可能把磁盤空間打滿。
如果真的想打印這些日志該怎么辦?
@PostMapping("/query")
public?List<User>?query(@RequestBody List<Long> ids)?{if?(log.isDebugEnabled()) {log.debug("request params:{}", ids);}List<User> userList = userService.query(ids);if?(log.isDebugEnabled()) {log.debug("response:{}", userList);}return?userList;
}
使用isDebugEnabled判斷一下,如果當前的日志級別是debug才打印日志。生產環境默認日志級別是info,在有些緊急情況下,把某個接口或者方法的日志級別改成debug,打印完我們需要的日志后,又調整回去。
方便我們定位問題,又不會產生大量的垃圾日志,一舉兩得。
26.比較時把常量寫前面
在比較兩個參數值是否相等時,通常我們會使用==號,或者equals方法。
我在第15章節中說過,使用==號比較兩個值是否相等時,可能會存在問題,建議使用equals方法做比較。
反例:
if(user.getName().equals("蘇三")) {System.out.println("找到:"+user.getName());
}
在上面這段代碼中,如果user對象,或者user.getName()方法返回值為null,則都報NullPointerException異常。
那么,如何避免空指針異常呢?
正例:
private?static?final?String FOUND_NAME =?"蘇三";
...if(null?== user) {return;
}
if(FOUND_NAME.equals(user.getName())) {System.out.println("找到:"+user.getName());
}
在使用equals做比較時,盡量將常量寫在前面,即equals方法的左邊。
這樣即使user.getName()返回的數據為null,equals方法會直接返回false,而不再是報空指針異常。
27.名稱要見名知意
java中沒有強制規定參數、方法、類或者包名該怎么起名。但如果我們沒有養成良好的起名習慣,隨意起名的話,可能會出現很多奇怪的代碼。
27.1 有意義的參數名
有時候,我們寫代碼時為了省事(可以少敲幾個字母),參數名起得越簡單越好。假如同事A寫的代碼如下:
int?a =?1;
int?b =?2;
String c =?"abc";
boolean?b =?false;
一段時間之后,同事A離職了,同事B接手了這段代碼。
他此時一臉懵逼,a是什么意思,b又是什么意思,還有c...然后心里一萬個草泥馬。
給參數起一個有意義的名字,是非常重要的事情,避免給自己或者別人埋坑。
正解:
int?supplierCount =?1;
int?purchaserCount =?2;
String userName =?"abc";
boolean?hasSuccess =?false;
27.2 見名知意
光起有意義的參數名還不夠,我們不能就這點追求。我們起的參數名稱最好能夠見名知意,不然就會出現這樣的情況:
String yongHuMing =?"張三";
String 用戶Name =?"張三";
String su3 =?"張三";
String suThree =?"張三";
這幾種參數名看起來是不是有點怪怪的?
為啥不定義成國際上通用的(地球人都能看懂)英文單詞呢?
String userName =?"張三";
String zhangsan =?"張三";
上面的這兩個參數名,基本上大家都能看懂,減少了好多溝通成本。
所以建議在定義不管是參數名、方法名、類名時,優先使用國際上通用的英文單詞,更簡單直觀,減少溝通成本。少用漢子、拼音,或者數字定義名稱。
27.3 參數名風格一致
參數名其實有多種風格,列如:
//字母全小寫
int?suppliercount =?1;//字母全大寫
int?SUPPLIERCOUNT =?1;//小寫字母 + 下劃線
int?supplier_count =?1;//大寫字母 + 下劃線
int?SUPPLIER_COUNT =?1;//駝峰標識
int?supplierCount =?1;
如果某個類中定義了多種風格的參數名稱,看起來是不是有點雜亂無章?
所以建議類的成員變量、局部變量和方法參數使用supplierCount,這種駝峰風格,即:第一個字母小寫,后面的每個單詞首字母大寫。例如:
int?supplierCount =?1;
此外,為了好做區分,靜態常量建議使用SUPPLIER_COUNT,即:大寫字母+下劃線分隔的參數名。例如:
private?static?final?int?SUPPLIER_COUNT =?1;
28.SimpleDateFormat線程不安全
在java8之前,我們對時間的格式化處理,一般都是用的SimpleDateFormat類實現的。例如:
@Service
public?class?SimpleDateFormatService?{public?Date?time(String time)?throws?ParseException?{SimpleDateFormat dateFormat =?new?SimpleDateFormat("yyyy-MM-dd HH:mm:ss");return?dateFormat.parse(time);}
}
如果你真的這樣寫,是沒問題的。
就怕哪天抽風,你覺得dateFormat是一段固定的代碼,應該要把它抽取成常量。
于是把代碼改成下面的這樣:
@Service
public?class?SimpleDateFormatService?{private?static?SimpleDateFormat dateFormat =?new?SimpleDateFormat("yyyy-MM-dd HH:mm:ss");public?Date?time(String time)?throws?ParseException?{return?dateFormat.parse(time);}
}
dateFormat對象被定義成了靜態常量,這樣就能被所有對象共用。
如果只有一個線程調用time方法,也不會出現問題。
但Serivce類的方法,往往是被Controller類調用的,而Controller類的接口方法,則會被tomcat的線程池調用。換句話說,可能會出現多個線程調用同一個Controller類的同一個方法,也就是會出現多個線程會同時調用time方法。
而time方法會調用SimpleDateFormat類的parse方法:
@Override
public?Date?parse(String text, ParsePosition pos)?{...Date parsedDate;try?{parsedDate = calb.establish(calendar).getTime();...}?catch?(IllegalArgumentException e) {pos.errorIndex = start;pos.index = oldStart;return?null;}return?parsedDate;
}?
該方法會調用establish方法:
Calendar?establish(Calendar cal)?{...//1.清空數據cal.clear();//2.設置時間cal.set(...);//3.返回return?cal;
}
其中的步驟1、2、3是非原子操作。
但如果cal對象是局部變量還好,壞就壞在parse方法調用establish方法時,傳入的calendar是SimpleDateFormat類的父類DateFormat的成員變量:
public?abstract?class?DateFormat?extends?Forma?{....protected?Calendar calendar;...
}
這樣就可能會出現多個線程,同時修改同一個對象即:dateFormat,它的同一個成員變量即:Calendar值的情況。
這樣可能會出現,某個線程設置好了時間,又被其他的線程修改了,從而出現時間錯誤的情況。
那么,如何解決這個問題呢?
-
SimpleDateFormat類的對象不要定義成靜態的,可以改成方法的局部變量。
-
使用ThreadLocal保存SimpleDateFormat類的數據。
-
使用java8的DateTimeFormatter類。
29.少用Executors創建線程池
我們都知道JDK5之后,提供了ThreadPoolExecutor類,用它可以自定義線程池。
線程池的好處有很多,下面主要說說這3個方面。
-
降低資源消耗:避免了頻繁的創建線程和銷毀線程,可以直接復用已有線程。而我們都知道,創建線程是非常耗時的操作。 -
提供速度:任務過來之后,因為線程已存在,可以拿來直接使用。 -
提高線程的可管理性:線程是非常寶貴的資源,如果創建過多的線程,不僅會消耗系統資源,甚至會影響系統的穩定。使用線程池,可以非常方便的創建、管理和監控線程。
當然JDK為了我們使用更便捷,專門提供了:Executors類,給我們快速創建線程池。
該類中包含了很多靜態方法:
-
newCachedThreadPool:創建一個可緩沖的線程,如果線程池大小超過處理需要,可靈活回收空閑線程,若無可回收,則新建線程。 -
newFixedThreadPool:創建一個固定大小的線程池,如果任務數量超過線程池大小,則將多余的任務放到隊列中。 -
newScheduledThreadPool:創建一個固定大小,并且能執行定時周期任務的線程池。 -
newSingleThreadExecutor:創建只有一個線程的線程池,保證所有的任務安裝順序執行。
在高并發的場景下,如果大家使用這些靜態方法創建線程池,會有一些問題。
那么,我們一起看看有哪些問題?
-
newFixedThreadPool:允許請求的隊列長度是Integer.MAX_VALUE,可能會堆積大量的請求,從而導致OOM。 -
newSingleThreadExecutor:允許請求的隊列長度是Integer.MAX_VALUE,可能會堆積大量的請求,從而導致OOM。 -
newCachedThreadPool:允許創建的線程數是Integer.MAX_VALUE,可能會創建大量的線程,從而導致OOM。
那我們該怎辦呢?
優先推薦使用ThreadPoolExecutor類,我們自定義線程池。
具體代碼如下:
ExecutorService threadPool =?new?ThreadPoolExecutor(8,?//corePoolSize線程池中核心線程數10,?//maximumPoolSize 線程池中最大線程數60,?//線程池中線程的最大空閑時間,超過這個時間空閑線程將被回收TimeUnit.SECONDS,//時間單位new?ArrayBlockingQueue(500),?//隊列new?ThreadPoolExecutor.CallerRunsPolicy());?//拒絕策略
順便說一下,如果是一些低并發場景,使用Executors類創建線程池也未嘗不可,也不能完全一棍子打死。在這些低并發場景下,很難出現OOM問題,所以我們需要根據實際業務場景選擇。
30.Arrays.asList轉換的集合別修改
在我們日常工作中,經常需要把數組轉換成List集合。
因為數組的長度是固定的,不太好擴容,而List的長度是可變的,它的長度會根據元素的數量動態擴容。
在JDK的Arrays類中提供了asList方法,可以把數組轉換成List。
正例:
String [] array =?new?String [] {"a","b","c"};
List<String> list = Arrays.asList(array);
for?(String str : list) {System.out.println(str);
}
在這個例子中,使用Arrays.asList方法將array數組,直接轉換成了list。然后在for循環中遍歷list,打印出它里面的元素。
如果轉換后的list,只是使用,沒新增或修改元素,不會有問題。
反例:
String[] array =?new?String[]{"a",?"b",?"c"};
List<String> list = Arrays.asList(array);
list.add("d");
for?(String str : list) {System.out.println(str);
}
執行結果:
Exception in thread?"main"?java.lang.UnsupportedOperationException
at java.util.AbstractList.add(AbstractList.java:148)
at java.util.AbstractList.add(AbstractList.java:108)
at com.sue.jump.service.test1.Test2.main(Test2.java:24)
會直接報UnsupportedOperationException異常。
為什么呢?
答:使用Arrays.asList方法轉換后的ArrayList,是Arrays類的內部類,并非java.util包下我們常用的ArrayList。
Arrays類的內部ArrayList類,它沒有實現父類的add和remove方法,用的是父類AbstractList的默認實現。
我們看看AbstractList是如何實現的:
public?void?add(int?index, E element)?{throw?new?UnsupportedOperationException();
}public?E?remove(int?index)?{throw?new?UnsupportedOperationException();
}
該類的add和remove方法直接拋異常了,因此調用Arrays類的內部ArrayList類的add和remove方法,同樣會拋異常。
)



)


)





![【GESP】C++三級真題 luogu-B4039 [GESP202409 三級] 回文拼接](http://pic.xiahunao.cn/【GESP】C++三級真題 luogu-B4039 [GESP202409 三級] 回文拼接)





