Diversifying the High-level Features for better Adversarial Transferability
- 摘要-Abstract
- 引言-Introduction
- 相關工作-Related Work
- 方法-Methodology
- 實驗-Experiments
- 結論-Conclusion

論文鏈接
GitHub鏈接
本文 “Diversifying the High-level Features for better Adversarial Transferability” 提出多樣化高級特征(DHF)方法,利用 DNNs 參數冗余,在梯度計算時對高層特征隨機變換并與良性樣本特征混合,提升對抗樣本遷移性。在 ImageNet 數據集實驗表明,DHF 能有效提升基于動量攻擊的遷移性,在基于輸入變換的攻擊中表現更優,攻擊防御模型時也顯著優于基線方法。
摘要-Abstract
Given the great threat of adversarial attacks against Deep Neural Networks (DNNs), numerous works have been proposed to boost transferability to attack real-world applications. However, existing attacks often utilize advanced gradient calculation or input transformation but ignore the white-box model. Inspired by the fact that DNNs are over-parameterized for superior performance, we propose diversifying the high-level features (DHF) for more transferable adversarial examples. In particular, DHF perturbs the high-level features by randomly transforming the high-level features and mixing them with the feature of benign samples when calculating the gradient at each iteration. Due to the redundancy of parameters, such transformation does not affect the classification performance but helps identify the invariant features across different models, leading to much better transferability. Empirical evaluations on ImageNet dataset show that DHF could effectively improve the transferability of existing momentumbased attacks. Incorporated into the input transformation-based attacks, DHF generates more transferable adversarial examples and outperforms the baselines with a clear margin when attacking several defense models, showing its generalization to various attacks and high effectiveness for boosting transferability.
鑒于深度神經網絡(DNN)面臨對抗攻擊的巨大威脅,人們提出了許多方法來提高攻擊在現實世界應用中的遷移性。然而,現有的攻擊方法通常采用先進的梯度計算或輸入變換,但忽略了白盒模型。受 DNN 為實現卓越性能而過度參數化這一事實的啟發,我們提出多樣化高級特征(DHF)的方法,以生成更具遷移性的對抗樣本。具體來說,DHF 在每次迭代計算梯度時,通過對高層特征進行隨機變換,并將其與良性樣本的特征混合,來擾動高級特征。由于參數的冗余性,這種變換不會影響分類性能,但有助于識別不同模型間的不變特征,從而顯著提高遷移性。在 ImageNet 數據集上的實證評估表明,DHF 能夠有效提高現有的基于動量攻擊的遷移性。將 DHF 融入基于輸入變換的攻擊中,它能生成更具遷移性的對抗樣本,并且在攻擊多個防御模型時,明顯優于基線方法,這表明 DHF 對各種攻擊具有通用性,并且在提高遷移性方面非常有效。
引言-Introduction
這部分主要闡述研究背景與動機,指出深度神經網絡(DNNs)易受對抗樣本攻擊,現有攻擊方法在跨模型時遷移性差,引出通過利用 DNN 參數冗余提升對抗樣本遷移性的研究思路,具體內容如下:
- 研究背景:DNNs 在諸多領域廣泛應用,但易受對抗樣本攻擊,這種攻擊對物理世界中部署的DNN安全構成重大威脅。現有對抗攻擊在攻擊者獲取目標模型全部知識時攻擊性能良好,但跨模型遷移性差,在現實世界中效率低下。
- 現有改進方法及不足:為提升對抗樣本遷移性,已提出輸入變換、集成模型攻擊和模型特定方法等。其中模型特定方法通過修改或利用 DNN 內部結構提升遷移性,效果較好且能與其他方法兼容,但現有這類方法對模型結構和圖像特征的利用仍不充分,存在改進空間。
- 研究動機與創新點:許多研究表明 DNNs 存在過參數化現象,深層網絡參數冗余明顯。受此啟發,文章聚焦于擾動高層特征,提出統一的擾動操作,建立了過參數化與對抗遷移性之間的關系,旨在利用高層特征的過參數化提升對抗樣本遷移性。
- 研究貢獻:首次建立過參數化與對抗遷移性的聯系;提出多樣化高層特征(DHF)方法,通過線性變換高層特征并與良性樣本特征混合,有助于識別不同模型間的不變特征;大量實驗表明 DHF 在對抗遷移性上優于現有方法,且對其他攻擊具有通用性。
相關工作-Related Work
該部分主要介紹了與本文研究相關的工作,涵蓋對抗攻擊、對抗防御和 DNNs 過參數化三個方面,具體內容如下:
- 對抗攻擊:自從 Szegedy 等人發現 DNNs 易受對抗樣本攻擊后,多種對抗攻擊方法被提出。基于梯度、遷移、分數、決策、生成的攻擊是主要的攻擊類型。其中,遷移攻擊因無需訪問目標模型,在現實場景攻擊深度模型中較受歡迎。為提升對抗遷移性,研究人員提出動量攻擊和輸入變換方法。但現有工作較少關注白盒模型本身,本文旨在通過多樣化高層特征生成更具遷移性的對抗樣本,且該方法適用于任何 DNN。
- 對抗防御:為減輕對抗攻擊威脅,出現多種防御方法。包括對抗訓練、輸入預處理、特征去噪、認證防御等。如 JPEG 通過壓縮輸入圖像消除對抗擾動,HGD 基于 U-Net 訓練去噪自動編碼器凈化圖像,R&P 通過隨機調整圖像大小和填充減輕對抗效果,Bit-Red 減少像素位數擠壓擾動,FD 采用基于 JPEG 的壓縮框架防御,Cohen 等人采用隨機平滑訓練魯棒的 ImageNet 分類器,NRP 采用自監督對抗訓練機制有效消除擾動。
- DNNs 的過參數化:自 Krizhevsky 等人使用卷積神經網絡在 ImageNet 上取得優異成績后,DNNs 變得更深更寬,參數眾多。過參數化能顯著提升模型性能,而模型量化技術用低精度權重替代浮點權重,減少過參數化模型的內存需求,這表明 DNNs 包含冗余信息。本文旨在利用這種冗余生成更具遷移性的對抗樣本。
方法-Methodology
該部分詳細闡述了多樣化高層特征(DHF)方法的動機、具體操作、高層特征優于低層特征的原因以及與 Ghost 方法的差異,具體內容如下:
- 動機:Lin 等人將對抗樣本生成類比于模型訓練過程,輸入變換方法類似于數據增強,能提升對抗遷移性,Li 等人提出的 Ghost 網絡通過對模型應用隨機失活和縮放操作使內部特征多樣化來提升遷移性。受此啟發,作者研究如何通過特征多樣化提升遷移性。由于 DNNs 參數冗余,對高層特征進行小擾動對模型性能影響小,且不同模型在特征上有相似性,因此可以通過擾動高層特征找到不變特征,進而提升對抗樣本的遷移性。
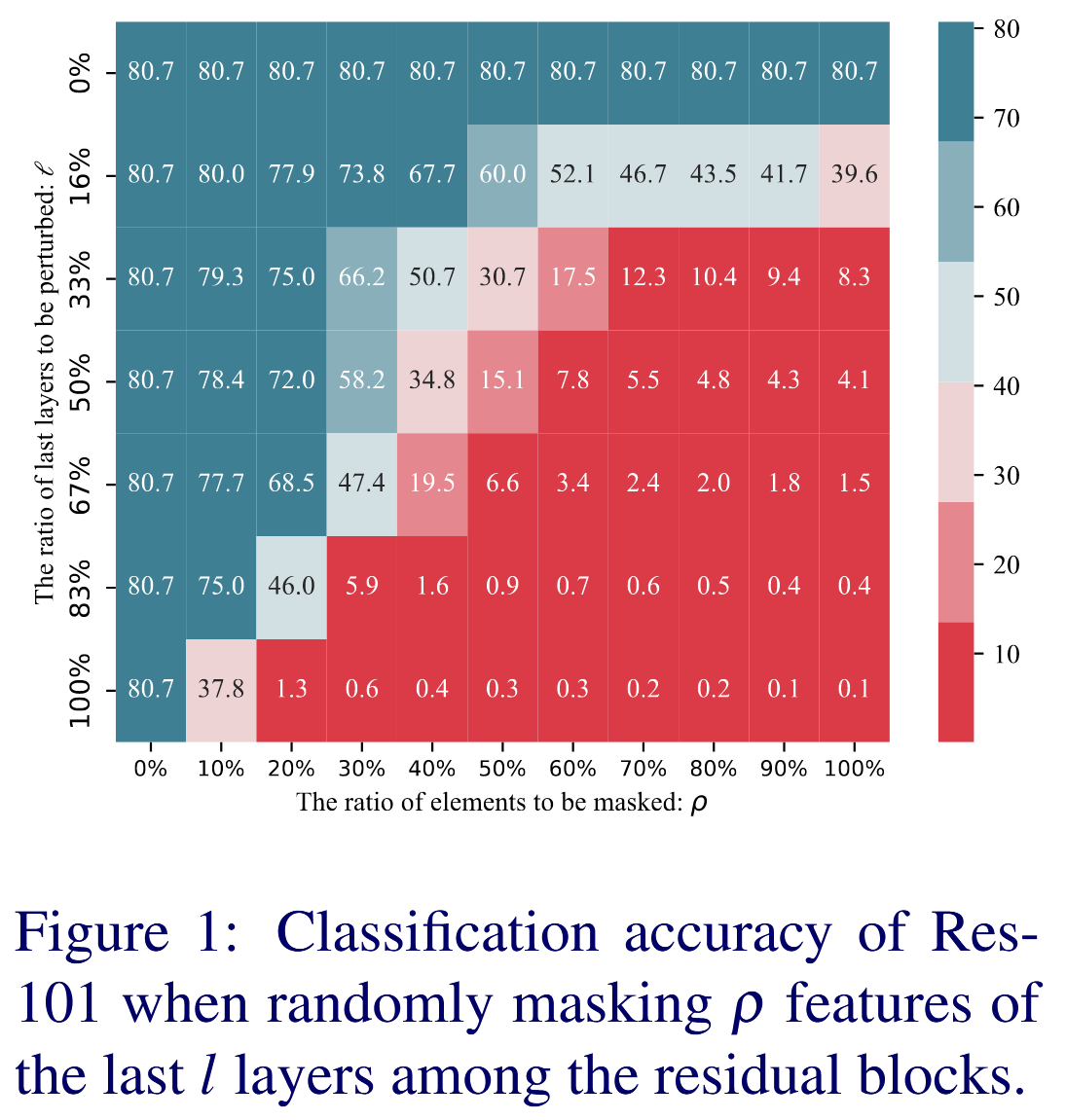
圖1:在殘差塊中隨機掩蔽最后 l l l 層的 ρ ρ ρ 個特征時,Res101 的分類準確率。

圖2:良性圖像及其由 DHF 生成的相應對抗樣本的可視化結果。 - 多樣化高層特征操作:
- 混合特征:為在不改變識別性能的情況下使對抗樣本特征多樣化,將當前樣本特征 y l a d v y_{l}^{a d v} yladv? 與良性樣本特征 y l y_{l} yl? 按公式 y l ? = ( 1 ? η ) ? y l a d v + η ? y l y_{l}^{*}=(1-\eta) \cdot y_{l}^{a d v}+\eta \cdot y_{l} yl??=(1?η)?yladv?+η?yl? 混合, η \eta η 服從 ( 0 , η m a x ) (0, \eta_{max }) (0,ηmax?) 的均勻分布。與 Admix 不同,DHF 僅與良性樣本特征混合,使中間層特征多樣化的同時不影響識別結果,穩定前向和反向傳播,使梯度更可靠。
- 隨機調整特征:隨機用特征均值替換 ρ \rho ρ 比例的特征元素,由于 DNNs 參數冗余,這樣做能穩定傳播并提升遷移性,且該操作可微,能得到更精確的梯度。與調整參數影響整個特征圖不同,這種局部特征替換只改變特定元素。
- 特征分析:采用平均 Hessian 跡衡量網絡層敏感性,隨著網絡層增加,平均 Hessian 跡下降,模型對高層特征的敏感性降低。在過參數化網絡中,適當改變高層特征不會改變模型輸出,因此在增強特征多樣性時,選擇敏感性低的高層特征進行擾動,既可以獲得多樣特征,又不會改變模型預測,更適合用于生成更具遷移性的對抗樣本。
- 與 Ghost 對比:
- 動機:DHF 基于參數冗余使特征多樣化以獲取不變特征,Ghost 旨在降低集成模型攻擊的訓練成本。
- 策略:DHF 擾動高層特征,因為低層參數冗余較少;Ghost 認為對后層的擾動無法提供遷移性,所以密集擾動各層特征。
- 變換:DHF 混合當前樣本和良性樣本特征,并隨機用均值替換特征;Ghost 在卷積層密集采用隨機失活層或對殘差連接進行隨機縮放。
- 泛化性:實驗表明 DHF 能持續提升各種攻擊的遷移性,而 Ghost 有時會降低性能。
實驗-Experiments
這部分通過多種實驗評估了 DHF 的有效性,涵蓋實驗設置、數值結果分析以及參數研究,具體內容如下:
- 實驗設置:
- 數據集:從 ILSVRC 2012 驗證集中隨機選取 1000 個類別中的 1000 張圖像,所選模型均能正確分類這些圖像。
- 模型:評估涉及 9 種模型,包含卷積神經網絡(如ResNet - 18、ResNet - 50等)和Transformer(如Vision Transformer、Swin)架構。同時考慮了多種具有防御機制的模型,像 NIPS 2017 防御競賽中的前3名提交模型,以及輸入預處理、認證防御和對抗擾動去噪相關的模型。
- 評估設置:選擇基于動量的攻擊方法 MI-FGSM 和 NI-FGSM,以及基于輸入變換的攻擊方法 DIM 和 TIM。設置 DHF 擾動最后 5 6 S \frac{5}{6}S 65?S 層,混合權重上界 η m a x = 0.2 \eta_{max}=0.2 ηmax?=0.2,擾動元素比例 ρ = 10 % \rho = 10\% ρ=10%,擾動預算 ε = 16 \varepsilon = 16 ε=16,迭代次數 T = 10 T = 10 T=10,步長 α = 1.6 \alpha = 1.6 α=1.6,衰減因子 μ = 1.0 \mu = 1.0 μ=1.0。
- 數值結果:
- 基于動量攻擊評估:對比 MI-FGSM 和 NI-FGSM 攻擊,所有方法都比原始模型生成的對抗樣本遷移性更好,DHF 在 CNNs 和 Transformer 模型上攻擊成功率最高,比表現最佳的基線方法 Ghost 平均分別高出 3.4% 和 4.1%.
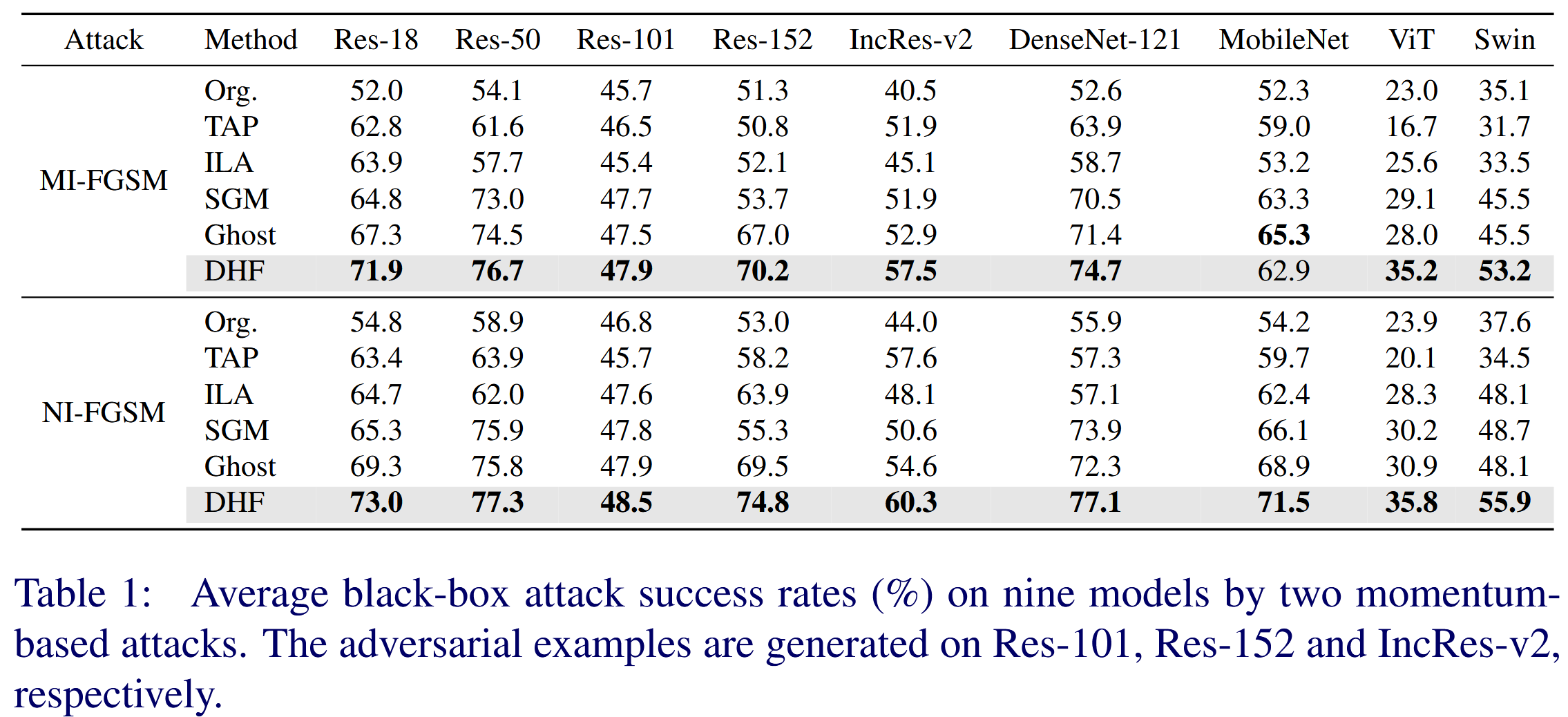
表1:兩種基于動量的攻擊方法在九個模型上的平均黑盒攻擊成功率(%)。對抗樣本分別在 Res-101、Res-152 和 Inception-ResNet v2 上生成。 - 基于輸入變換攻擊評估:將 DIM 和 TIM 集成到 MI-FGSM 中,結果顯示 DHF 在對抗遷移性上表現最優,比 Ghost 分別高出 4.0% 和 5.4%,驗證了利用參數冗余擾動高層特征可顯著提升遷移性的假設。
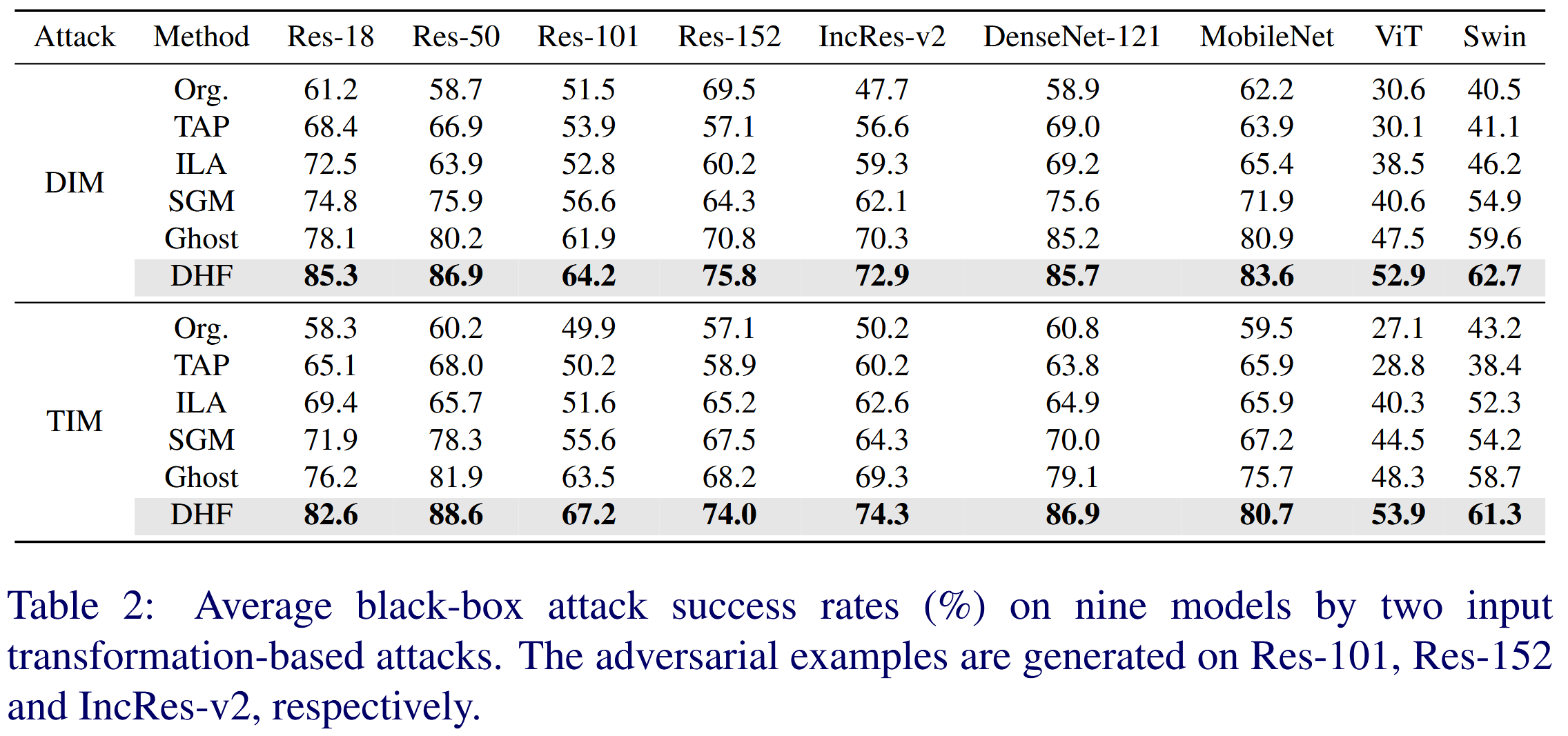
表2:兩種基于輸入變換的攻擊方法在九個模型上的平均黑盒攻擊成功率(%)。對抗樣本分別在 Res-101、Res-152 和 Inception-ResNet v2 上生成。 - 防御模型評估:針對多種防御模型,用 DIM 在不同模型上生成對抗樣本進行測試。DHF 攻擊成功率平均為56.2%,比基線方法 SGM 平均高出5.3% ,而 Ghost 表現最差,表明 DHF 在攻擊不同防御機制的黑盒模型時有效性和通用性高。
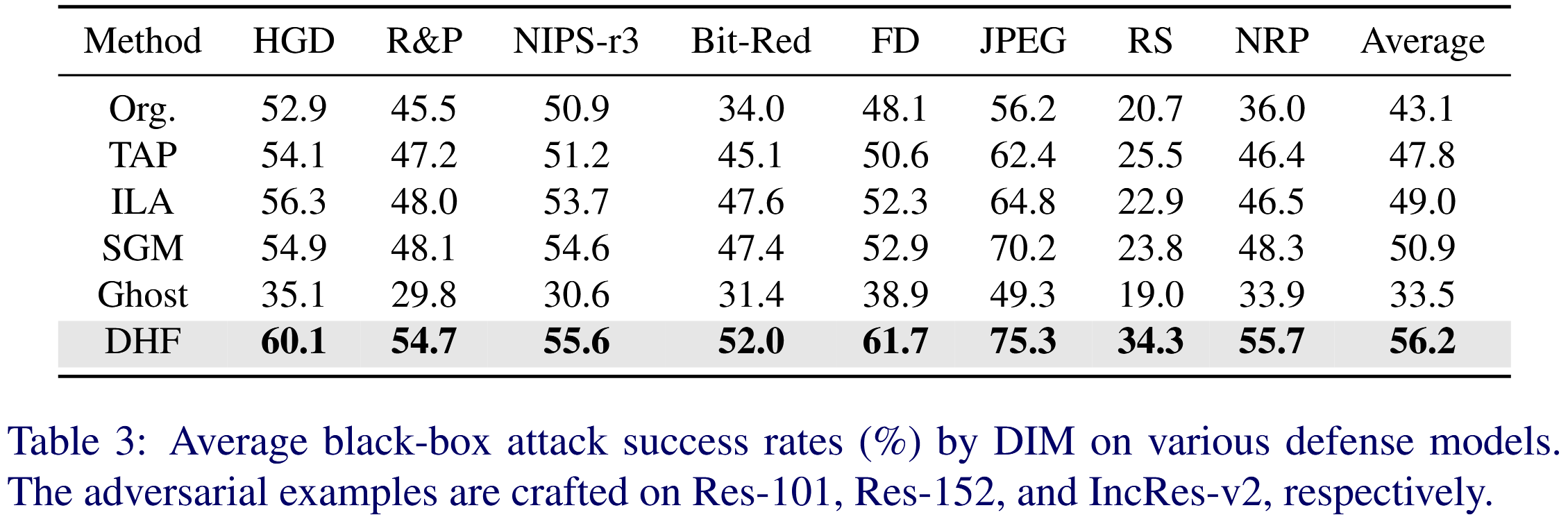
表3:通過 DIM 方法在各種防御模型上的平均黑盒攻擊成功率(%)。對抗樣本分別在 Res-101、Res-152 和 Inception-ResNet v2 模型上生成。
- 基于動量攻擊評估:對比 MI-FGSM 和 NI-FGSM 攻擊,所有方法都比原始模型生成的對抗樣本遷移性更好,DHF 在 CNNs 和 Transformer 模型上攻擊成功率最高,比表現最佳的基線方法 Ghost 平均分別高出 3.4% 和 4.1%.
- 參數研究:
- 混合權重上界 η m a x \eta_{max} ηmax?: η m a x \eta_{max} ηmax? 平衡干凈樣本和對抗樣本特征。實驗發現, η m a x = 0 \eta_{max}=0 ηmax?=0 時混合操作無效,遷移性低;在 η m a x = 0.2 \eta_{max}=0.2 ηmax?=0.2 左右攻擊性能達到峰值;繼續增大 η m a x \eta_{max} ηmax?,干凈特征占比過大,難以計算準確梯度,攻擊性能下降,因此實驗采用 η m a x = 0.2 \eta_{max}=0.2 ηmax?=0.2。
- 調整元素比例 ρ \rho ρ: ρ \rho ρ 用于減少特征方差以識別不變特征。實驗顯示, ρ \rho ρ 在不超過0.1時,整體性能略有提升并在 ρ = 0.1 \rho = 0.1 ρ=0.1 時達到峰值;更大的 ρ \rho ρ 會因過多用特征均值替換元素而降低分類精度,導致梯度不準確,攻擊性能顯著下降,所以實驗采用 ρ = 0.1 \rho = 0.1 ρ=0.1。
- 調整層數比例 r r r: 實驗發現不擾動特征( r = 0 % r = 0\% r=0%)時 DHF 無效,遷移性最低;擾動特征可顯著提升遷移性,在擾動最后 5 6 \frac{5}{6} 65? 層( r = 83 % r = 83\% r=83%)時達到峰值;擾動所有層性能反而不如擾動最后 5 6 \frac{5}{6} 65? 層,因此實驗選擇擾動最后 5 6 \frac{5}{6} 65? 層以獲得更好性能。
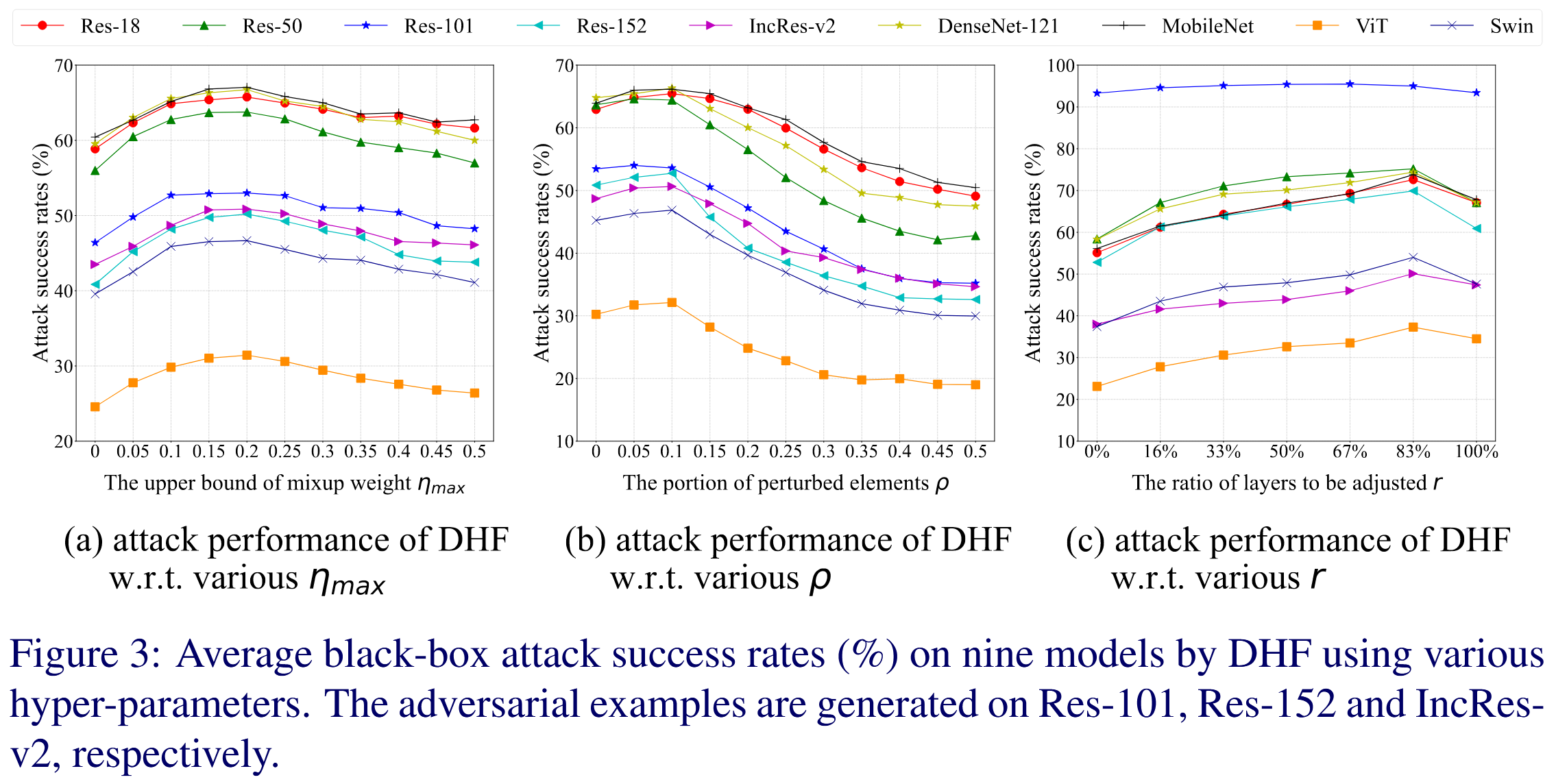
圖3:使用不同超參數的 DHF 對九個模型的平均黑盒攻擊成功率(%)。對抗樣本分別在 Res-101、Res-152 和 IncRes-v2 上生成。
結論-Conclusion
該部分指出深度神經網絡(DNNs)常因追求良好的泛化性而過度參數化。文章利用這一特性,提出多樣化高層特征(DHF)的方法來增強對抗樣本的遷移性。
- 方法核心:發現對 DNNs 的高層特征進行小的擾動,對模型整體性能的影響微乎其微。基于此,DHF 在梯度計算過程中,對高層特征進行隨機變換,并將其與良性樣本的特征相混合。
- 理論分析:文中還從理論層面分析了在進行特征多樣化時,高層特征相較于低層特征更具優勢的原因。
- 實驗驗證:大量的評估實驗表明,與現有的最先進攻擊方法相比,DHF 方法在對抗樣本遷移性上有顯著提升。這充分證明了 DHF 方法的有效性,為對抗攻擊領域提供了新的思路和方法。


)



)







)




