本文目錄:
- 一、Series和Dataframe的概念
- 二、創建Series對象
- 三、創建Dataframe對象
- (一)Series
- 1.Series的常用屬性總結如下:
- 2.Series的常用方法總結如下:
- (二)Dataframe
- 1.Dataframe的常用屬性
- 2.Dataframe的常用方法
一、Series和Dataframe的概念
Pandas 只有兩種核心數據結構:
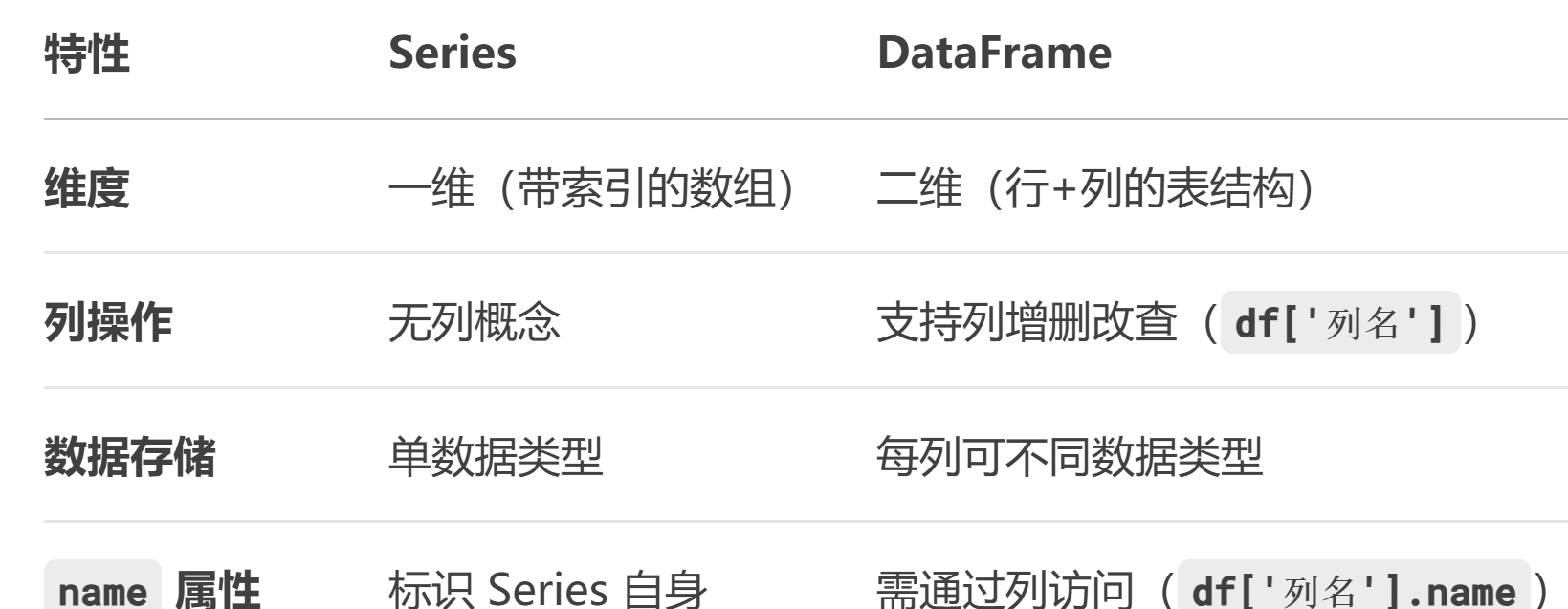
Series:一維數組(單列數據,帶索引)。
DataFrame:二維表格(多列 Series 的集合,每列可不同數據類型)。
【特別分享】
Pandas沒有獨立的“行”對象源于兩點原因****:
(1)設計哲學:Pandas 是圍繞 列式存儲(Column-oriented) 優化的,列操作(如聚合、過濾)比行操作更高效;
(2)內存布局:DataFrame 的每列(Series)在內存中連續存儲,而行是跨列的,訪問效率較低。
二、創建Series對象
Series是最基本的數據結構對象,DataFrame 的一列就是一個 Series;
它是一個類似于一維數組的對象;
它的創建主要包括三個部分:values(值:可為列表、字典、numpy數組、標量值等等)、index(行索引)、name(series名字),其中values是必須有的,index和name可有可無,當不指定index時,系統會默認從0開始。
Series的創建方式有多種:

代碼如下(列舉3種,其它類同):
import pandas as pd# 從列表創建,默認索引為 0, 1, 2...
data = [10, 20, 30, 40]
s = pd.Series(data)
print(s)# 字典的鍵自動成為索引
data = {'a': 10, 'b': 20, 'c': 30}
s = pd.Series(data)
print(s)# 所有值均為 5,索引需單獨指定
s = pd.Series(5, index=['a', 'b', 'c'])
print(s)注意:Series的缺失值用 NaN 表示。
三、創建Dataframe對象
DataFrame是Pandas中最基本的數據結構,Series的許多屬性和方法在DataFrame中也一樣適用,可以理解為一個二維表結構。
Dataframe的創建方式主要包括列表創建和字典創建,還有csv文件讀取,代碼如下:
import pandas as pd
#從字典創建
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35],'City': ['New York', 'London', 'Tokyo']
}df = pd.DataFrame(data)
print(df)#從列表創建
data = [['Alice', 25, 'New York'],['Bob', 30, 'London'],['Charlie', 35, 'Tokyo']
]df = pd.DataFrame(data, columns=['Name', 'Age', 'City'])
print(df)#從csv文件讀取
df = pd.read_csv('data.csv') # 讀取 CSV 文件
print(df.head()) # 查看前5行
四、屬性和方法
Series和Dataframe的很多屬性和方法是共通的。
(一)Series
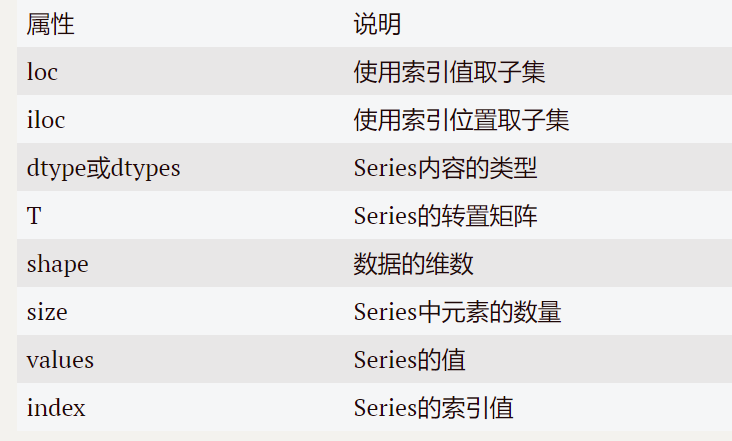
1.Series的常用屬性總結如下:
代碼如下:
例(列舉重點):
import pandas as pd
s = pd.Series([1, 2], name='my_series')
print(s) # 輸出:'my_series's1 = pd.Series([1, 2, 3], name="A")
s2 = pd.Series(["X", "Y", "Z"], name="B")print(s1.ndim)
print(s1.shape)
print(s1.loc[1]) #按索引1取值
print(s1.iloc[1])#按索引位置1取值
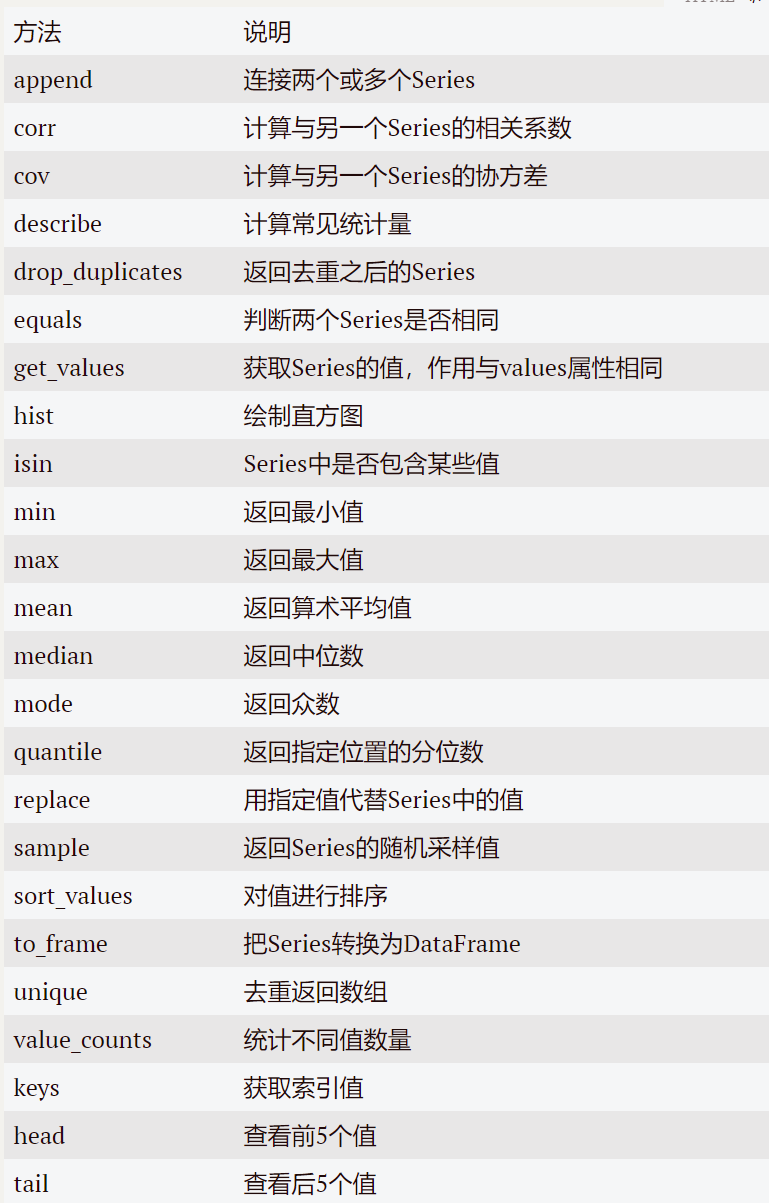
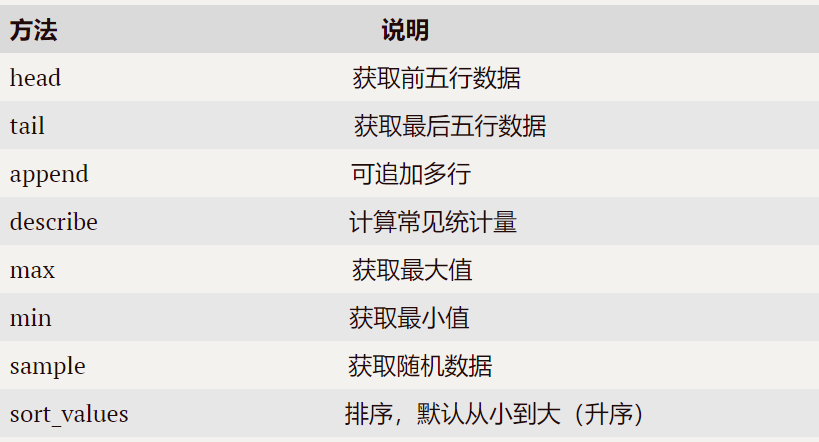
2.Series的常用方法總結如下:
代碼如下:
例(列舉重點):print(df.head()) #前五條數據
print(s.describe()) #查看詳情
s1=s.sample(2) #隨機抽取2條數據
print(s1)
print(s1.sort_values()) #默認升序,降序需指定ascending=False#擴展:
print(s1.sort_values(ascending=False)) #降序排列,返回新的
print(s1.sort_values(ascending=True)) #升序排列,返回新的
print(s1.describe(include="all")) #打印所有字段詳細信息
print(s1.describe(exclude="int,float")) #打印除了int和float的字段信息
(二)Dataframe
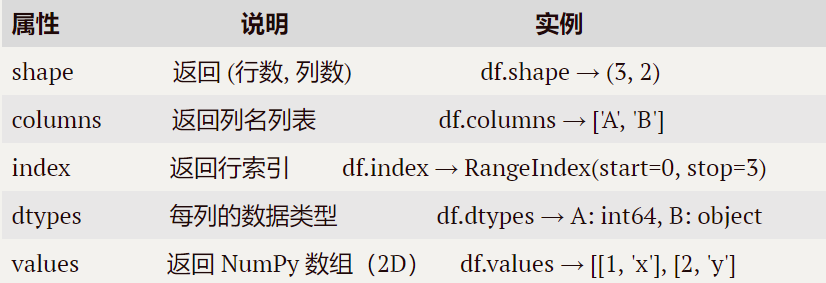
1.Dataframe的常用屬性
2.Dataframe的常用方法
有關屬性和方法整體代碼如下:
例(列舉部分重點):
import pandas as pd# 加載數據集, 得到df對象
df = pd.read_csv('data/scientists.csv')print('=============== 常用屬性 ===============')
# 查看維度, 返回元組類型 -> (行數, 列數), 元素個數代表維度數
print(df.shape)
# 查看數據值個數, 行數*列數, NaN值也算
print(df.size)
# 查看數據值, 返回numpy的ndarray類型
print(df.values)
# 查看維度數
print(df.ndim)
# 返回列名和列數據類型
print(df.dtypes)
# 查看索引值, 返回索引值對象
print(df.index)
# 查看列名, 返回列名對象
print(df.columns)
print('=============== 常用方法 ===============')
# 查看前5行數據
print(df.head())
# 查看后5行數據
print(df.tail())
# 查看df的基本信息
df.info()
# 查看df對象中所有數值列的描述統計信息
print(df.describe())
# 查看df對象中所有非數值列的描述統計信息
# exclude:不包含指定類型列
print(df.describe(exclude=['int', 'float']))
# 查看df對象中所有列的描述統計信息
# include:包含指定類型列, all代表所有類型
print(df.describe(include='all'))
# 查看df的行數
print(len(df))
# 查看df各列的最小值
print(df.min())
# 查看df各列的非空值個數
print(df.count())
# 查看df數值列的平均值
print(df.mean())
今天分享到此結束。

)







)









