
當前點播視頻平臺搜索功能主要是基于視頻標題的關鍵字檢索。對于點播平臺而言,我們希望可以通過優化視頻搜索體驗滿足用戶通過模糊描述查找視頻的需求,從而提高用戶的搜索體驗。借助 Amazon Bedrock Data Automation(BDA)技術,運用 AI 自動剖析視頻內容,提取關鍵信息,通過向量搜索達成語義智能匹配,實現多角度(視頻關鍵字、臺詞、場景描述)視頻檢索,有利于提升用戶搜索效率,增加平臺活躍度,也為視頻創作者創造更多曝光機遇。 在下文中,我們會基于 Amazon Bedrock Data Automation(BDA)實現視頻處理與雙路召回的解決方案進行描述。
Amazon Bedrock Data Automation 功能概述
Bedrock Data Automation(BDA)是基于云的服務,借助生成式 AI,能將文檔、圖像、視頻和音頻等非結構化內容,高效轉化為結構化格式,自動提取、生成關鍵信息,助力開發人員快速構建應用程序,執行復雜工作流程。目前支持 us-east-1 和 us-west-2 兩個地區。
從輸出結果角度,BDA 支持標準結果和自定義結果的輸出,當用戶選擇自定義結果的輸出時,可以用 prompt 的方式去生成想要的結果。自定義的結構可以保存為藍圖為 BDA 項目所使用。目前自定義結果的輸出支持文檔和圖片。
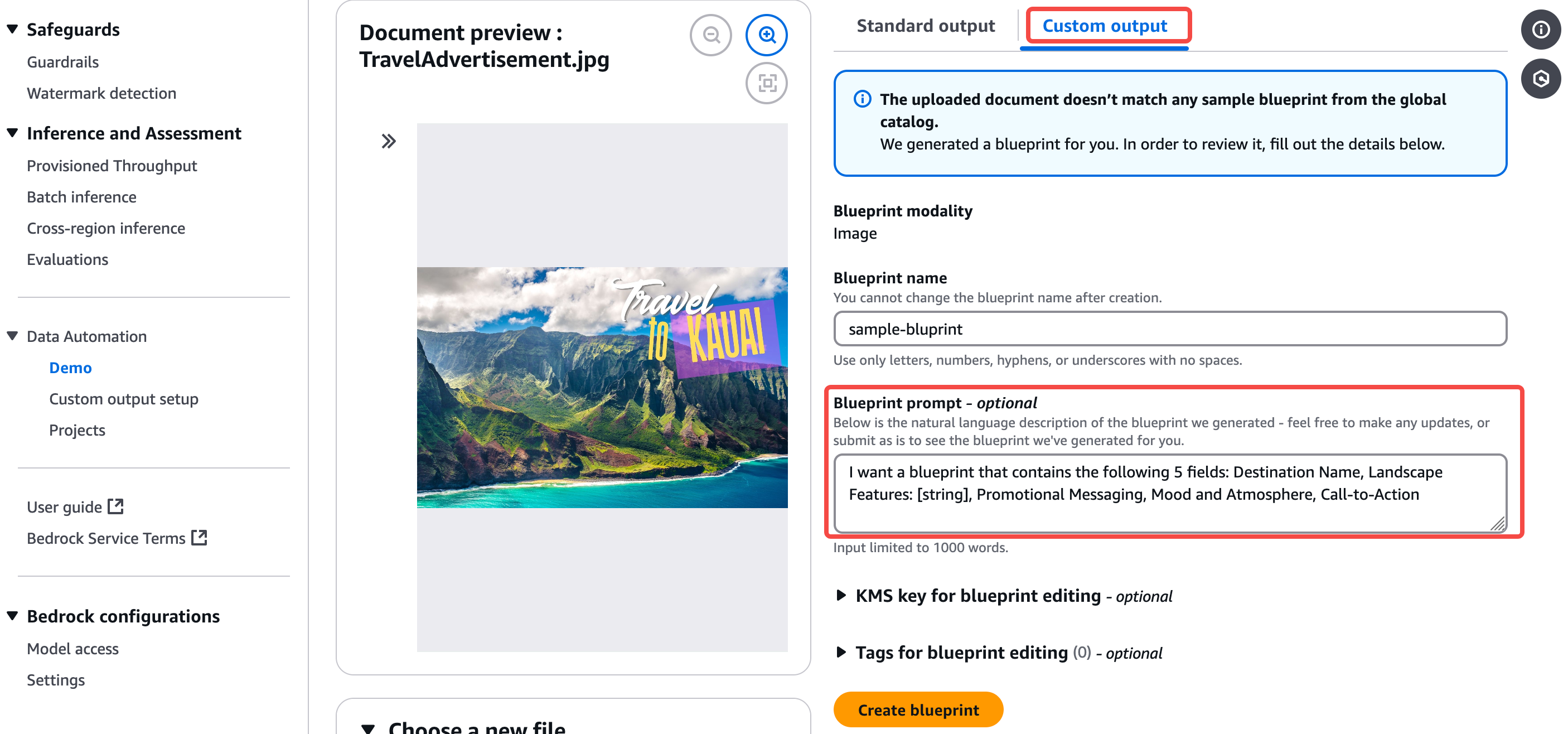
標準結果的輸出則對四種不同類型的數據源做了預定義的輸出結構,例如對于文檔數據,標準輸出結果如下圖所示,從而可以為不同下游應用所用:
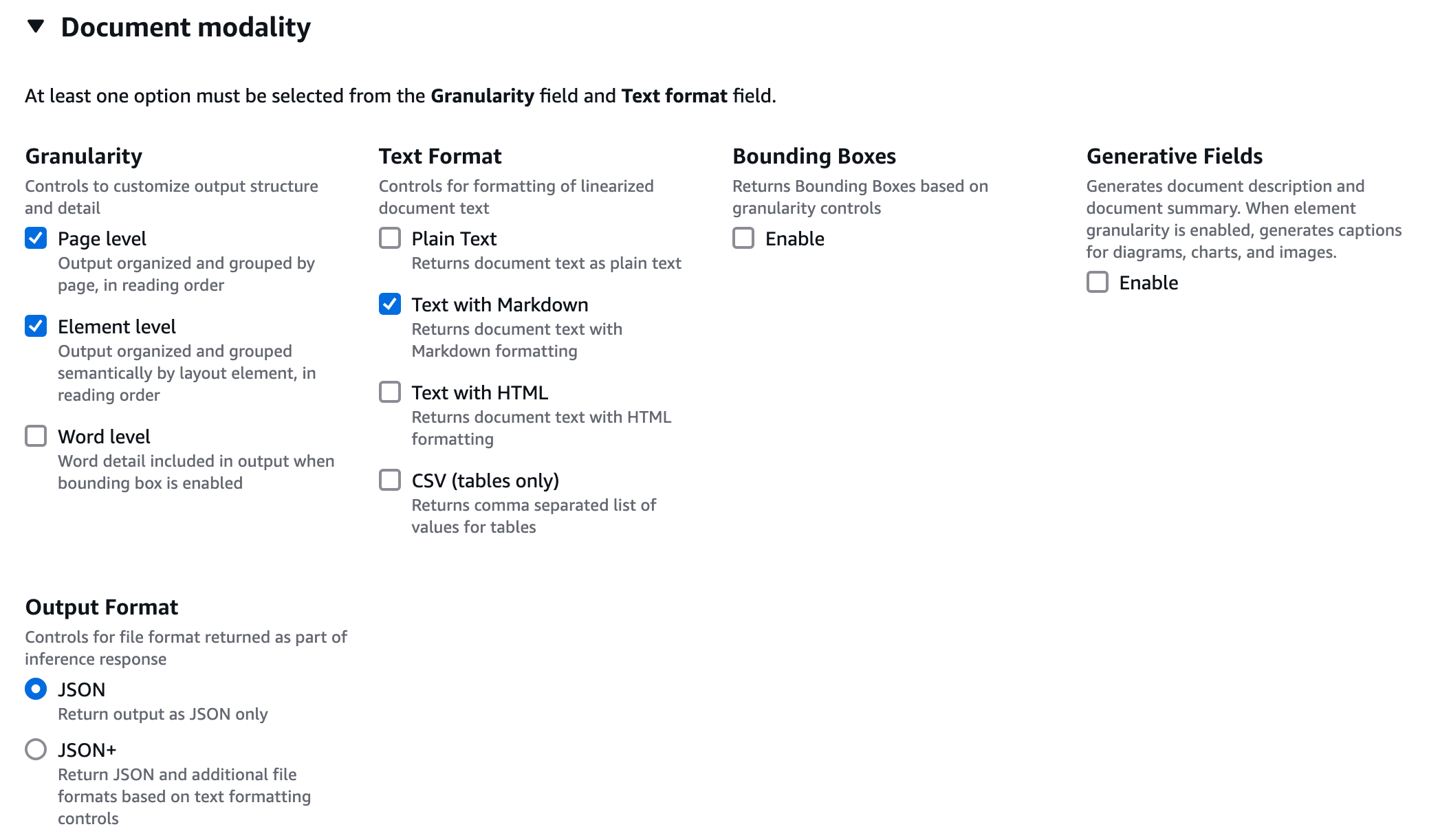
您可以手動在操作臺上測試 DBA 的各種功能包括文檔,圖片,視頻和音頻等,以下我們以視頻 Demo 為例。
首先找到 Amazon Bedrock 在控制臺的位置,然后點擊左側工具欄中 Data Automation 下的 Demo:
在工具欄中的 Demo中,您可以選擇用已存在 Demo 上的數據,或從本地/Amazon S3 中上傳的數據做為源數據進行測試:
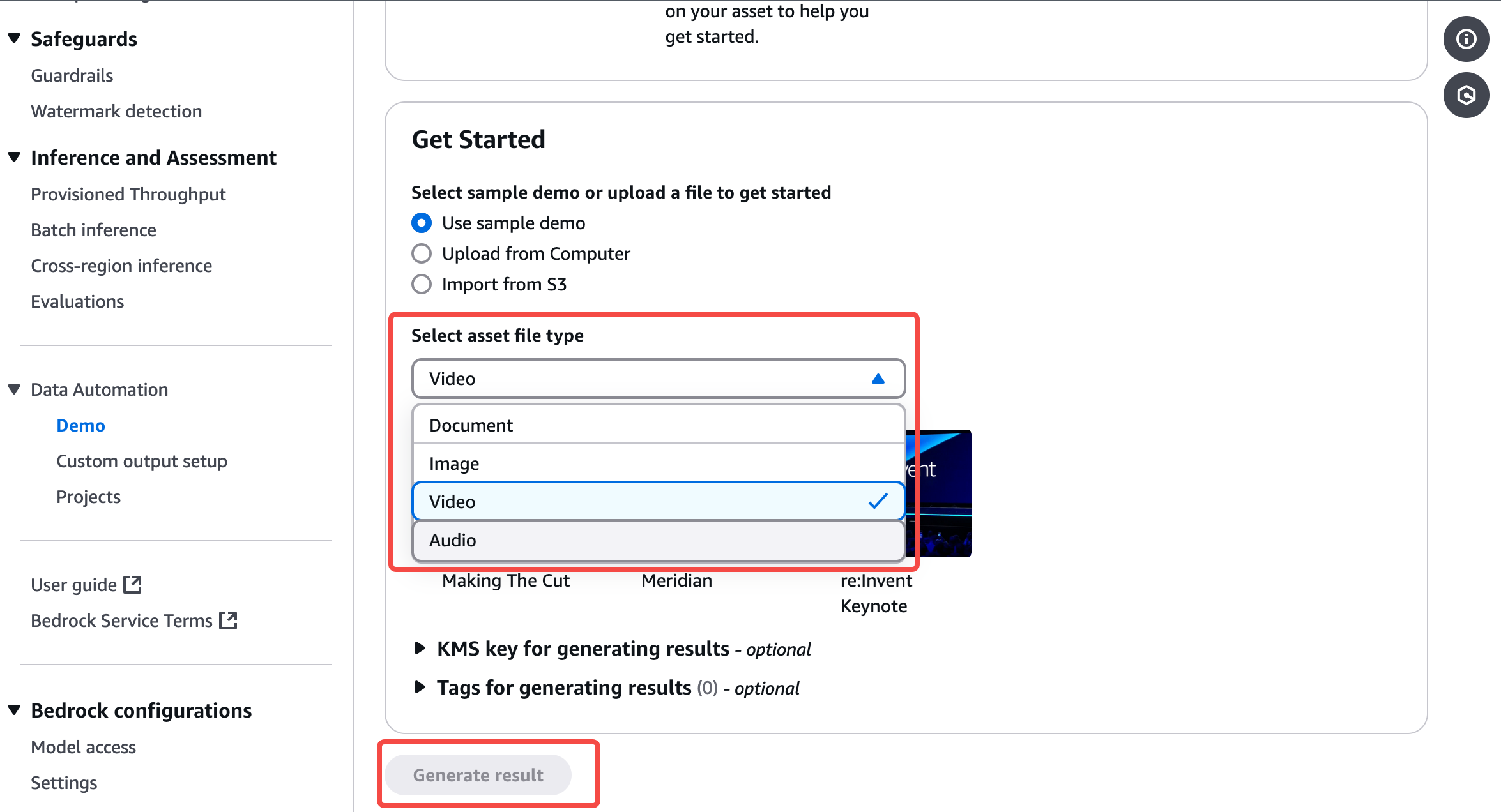
最后點擊 Generate result,便可以在左側輸出相關結果,并可以選擇標準數據結果或前面藍圖制定好的自定義輸出結果。
在視頻處理中,BDA 可以生成完整視頻摘要、章節摘要、提取 IAB 分類法、完整音頻腳本、視頻文字、進行徽標檢測和內容審核等。在推出 BDA 之前,傳統對視頻的 RAG 還是基于手工對切片處理,并手工通過 SaaS 或大模型對視頻聲音摘錄,文字提取。BDA 簡化了這一流程,輸出的內容以 Json 文檔的形式呈現。
Json 文檔結構目前版本主要包含以下幾個部分:Metadata、shots、chapters、video、statistics
-
Metadata 包含視頻的基本信息,如資產 ID、格式、幀率、編碼、時長、分辨率等。
-
Shots 是 DBA 自動將視頻分割成多個鏡頭,每個鏡頭包括開始和結束的時間碼,開始和結束的時間戳(毫秒),開始和結束的幀索引,持續時間,置信度,所屬章節索引。
-
Chapters 是 DBA 自動將視頻分割成多個章節,每個章節包含開始和結束的時間碼,開始和結束的時間戳(毫秒),開始和結束的幀索引,持續時間,包含的鏡頭索引,章節摘要,轉錄文本,IAB 分類,內容審核等。其中,IAB 分類可以幫助廣告找到視頻中可以切入的點,讓廣告的引入可以更加流暢。
-
Video 里面包含了視頻總結和視頻整體的轉錄文本。視頻整體的轉錄文本包含了每個章節的轉錄文本。
-
Statistics 主要是對視頻數據的統計,包含了鏡頭數量統計,章節統計和視頻中發言人的數量。
在本文中,我們主要用到了 DBA 視頻處理的處理手段,來將視頻數據轉化成 json 結構數據為用戶提供文字搜索功能。以下是相關架構的介紹。
相關架構說明
架構總覽
整個視頻處理與檢索系統主要由 Amazon S3、Amazon EventBridge、Amazon Lambda、Amazon Bedrock、Amazon DocumentDB、Amazon API Gateway 和 Amazon CloudFront 等組件構成,各組件協同工作,實現視頻數據的自動化處理與高效檢索。
相關技術組件
-
Amazon S3:作為對象存儲服務,負責存儲視頻文件和處理后的 json 文件。它具有高可靠性、高擴展性和低成本等優勢,為視頻數據的存儲提供了穩定的基礎。
-
Amazon EventBridge:作為系統中關鍵的事件觸發中樞,負責監測特定事件的發生。一旦檢測到視頻文件上傳至 S3 或 S3 路徑中文件生成,它便迅速響應,精準觸發相應的 Lambda 函數調用。
-
Amazon Lambda:基于無服務器計算架構,允許用戶直接通過代碼實現各種功能。在本系統中,Lambda 承擔了多項重要任務,如調用 Bedrock API 處理視頻,將非結構化的視頻數據轉化為結構化的 json 文件;調用 Bedrock 上的模型(如 titan-embed-text-v2:0)為 json 文件內容生成 embedding,以便后續進行向量檢索。
-
Amazon Bedrock:Amazon 的 AI 一站式平臺,集成了各種先進的 AI 模型,為系統提供強大的 AI 處理能力。在本案例中,其主要提供了 BDA 的視頻處理功能和 Titan 模型與 Cohere 模型的調用。其中,對 BDA 的調用需要依賴 BDA 項目對于輸出的預定義。在案例中,我們選擇以下輸出作為數據源進行處理,對于其他項目,具體輸出可以按照需要自行勾選:
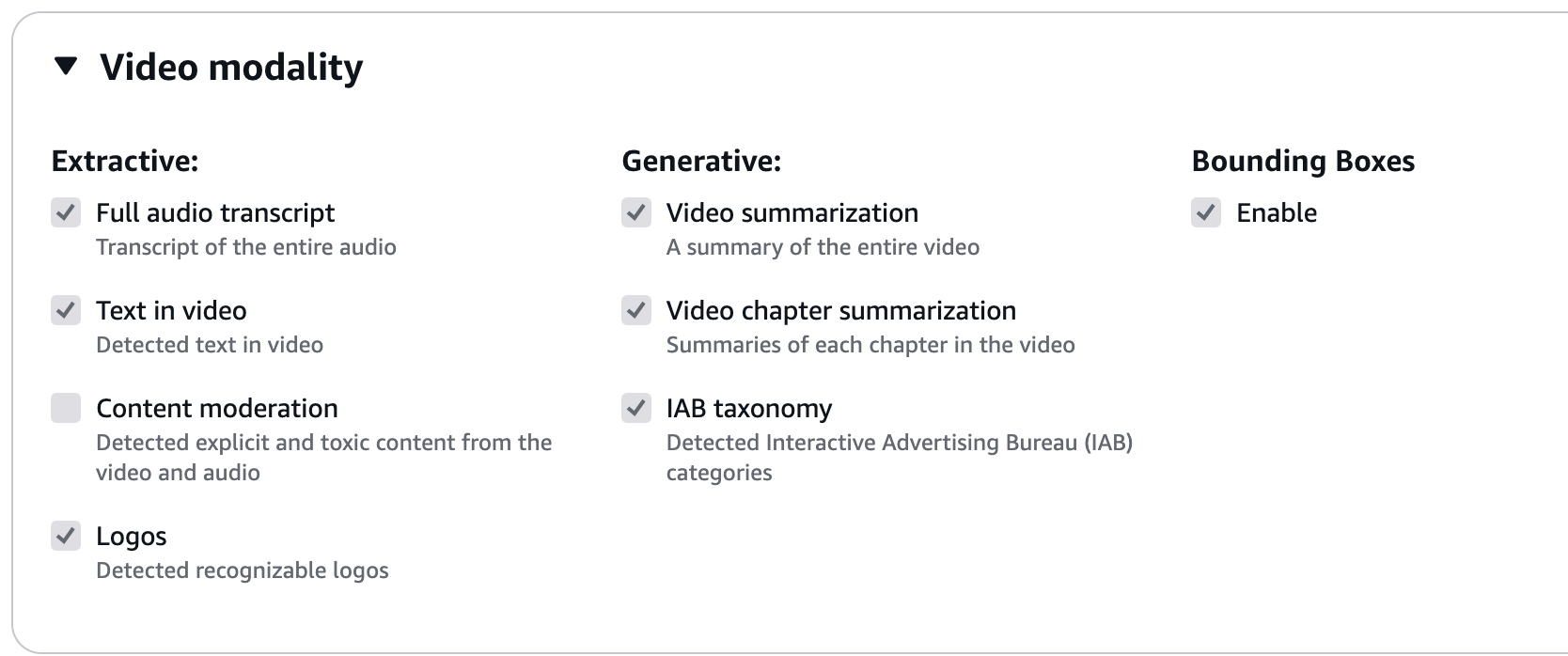
-
Amazon DocumentDB:存儲由 BDA 生成的 json 文檔。Amazon DocumentDB 兼容 Mongo DB,是原生的完全托管 json 文檔數據庫,支持向量、文本的存儲、索引和聚合。DocumentDB 具備強大的性能和擴展性,能夠同時滿足操作型和分析型工作負載的需求。
索引是一種數據結構,用于提高數據檢索的效率,在文字數據和向量數據的處理中都有著重要作用。我們在Amazon DocumentDB 中創建了文字倒排索引和向量索引為后續檢索做準備。由于是文本相似度計算,我們選用余弦相似度(cosine)來用于向量索引。
[{ v: 4, key: { _id: 1 }, name: '_id_', ns: 'VideoData.videodata' },{v: 1,key: { _fts: 'text', _ftsx: 1 },name: 'text_index',ns: 'VideoData.videodata',default_language: 'english',weights: { text: 1 },textIndexVersion: 1},{v: 4,key: { embedding: 'vector' },name: 'vector_index',vectorOptions: {type: 'ivfflat',dimensions: 1024,similarity: 'cosine',lists: 1000},ns: 'VideoData.videodata'}
]-
Amazon API Gateway:作為 API 管理接口,連接前端用戶與后端服務。它負責接收前端用戶的搜索請求,并將其轉發給后端的 Lambda 函數進行處理,同時將后端處理結果返回給前端用戶,保障了前后端數據交互的安全和高效。
-
Amazon CloudFront:主要用于加速視頻內容的分發和召回。通過在全球范圍內部署邊緣節點,它能夠快速將視頻內容傳遞給用戶,減少用戶等待時間,提升用戶觀看視頻的流暢度和體驗感。
架構圖
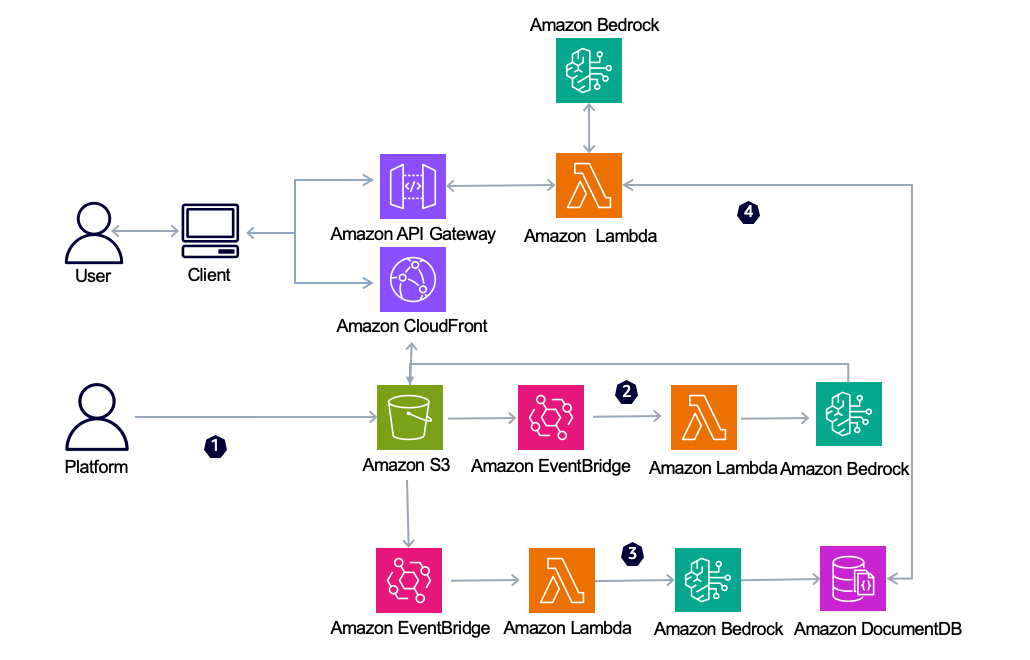
視頻檢索流程
前置過程
為了更加方便快速地部署和使用本方案,我們創建了基于AWS CDK 的全自動化部署方法: :sample-for-video-search。您可以按照 README 來將整套環境資源快速部署在自己的亞馬遜云科技環境中,隨后便可以開始以下檢索流程:
1. 數據上傳
在我們的案例中,平臺可以將視頻文件(mp4/mov 格式)上傳至 Amazon S3 路徑中,例如 s3://<bucket-name>/video-input/,作為后續處理的源數據。
2. 視頻處理與視頻 Json 文件生成
當 Amazon S3 路徑中有文件上傳完畢時,Amazon EventBridge 會監測到相關事件并觸發 Amazon Lambda 調用 Amazon Bedrock API 對視頻文件按照實現創建的 DBA 項目進行處理。DBA 項目是利用 Lambda 在視頻處理流程前創建。視頻處理完成后,生成相應的 json 文件,并將其傳回 Amazon S3 存儲 s3://<bucket-name>/video-output/。相關示例代碼如下:
# invokes bda by async approach with a given input file
def invoke_insight_generation_async(input_s3_uri,output_s3_uri,data_project_arn, blueprints = None):# Extract account ID from project ARNaccount_id = data_project_arn.split(':')[4]# Construct default Profile ARN using fixed us-west-2 region,which currently supports the 2 models required in the following processprofile_arn = f"arn:aws:bedrock:us-west-2:{account_id}:data-automation-profile/us.data-automation-v1"payload = {"inputConfiguration": {"s3Uri": input_s3_uri},"outputConfiguration": {"s3Uri": output_s3_uri},"dataAutomationConfiguration": {"dataAutomationProjectArn": data_project_arn,"stage": "LIVE"},"dataAutomationProfileArn": profile_arn,"notificationConfiguration": {"eventBridgeConfiguration": {"eventBridgeEnabled": True},}}try:response = bda_client_runtime.invoke_data_automation_async(**payload)print(f"Successfully invoked data automation: {response}")return responseexcept Exception as e:print(f"Error invoking data automation: {str(e)}")raise3. 基于視頻 Json 文件的 Embedding 處理
之后,Amazon S3 文件生成的規則會再次觸發的 Amazon EventBridge,使其啟動 Amazon Lambda 調用 Amazon Bedrock 集成的 amazon.titan-embed-text-v2:0 模型,為 Json 文件內容做 向量化用于后續查詢。
try:response = bedrock_client.invoke_model(modelId="amazon.titan-embed-text-v2:0",contentType="application/json",accept="application/json",body=json.dumps({"inputText": text}))由于每個 chapter 內的 transcripts 較長,為達到更好的檢索效果,會對其進行切片處理,最后將整理好的數據結構存入 DocumentDB。由于是簡易環境,我們基于字符長度做了簡單的切片處理:
def split_transcript_into_chunks(self, transcript_text, max_chunk_size=500, min_chunk_size=100):if not transcript_text:return []# 如果輸入是字典,嘗試提取文本if isinstance(transcript_text, dict):if 'text' in transcript_text:transcript_text = transcript_text['text']elif 'representation' in transcript_text and 'text' in transcript_text['representation']:transcript_text = transcript_text['representation']['text']else:transcript_text = json.dumps(transcript_text)# 確保輸入是字符串if not isinstance(transcript_text, str):transcript_text = str(transcript_text)# 按句子分割(句號、問號、感嘆號后跟空格)# 使用更寬松的模式,允許句子結束后有任何數量的空格sentences = re.split(r'([.!?])\s*', transcript_text)# 處理分割結果,將標點符號重新附加到句子processed_sentences = []i = 0while i < len(sentences):sentence = sentences[i]# 如果是標點符號,附加到前一個句子if i > 0 and sentence in ['.', '!', '?']:processed_sentences[-1] += sentenceelse:processed_sentences.append(sentence)i += 1# 將句子組合成塊chunks = []current_chunk = ""for sentence in processed_sentences:# 跳過空句子if not sentence.strip():continue# 如果當前塊加上新句子會超過最大大小,保存當前塊if current_chunk and len(current_chunk) + len(sentence) + 1 > max_chunk_size:if len(current_chunk) >= min_chunk_size:chunks.append(current_chunk.strip())current_chunk = sentenceelse:if current_chunk:current_chunk += " " + sentenceelse:current_chunk = sentence# 添加最后一個塊if current_chunk and len(current_chunk) >= min_chunk_size:chunks.append(current_chunk.strip())return chunks將 Json 文件向量化后,我們將 Json 文件的數據格式進行了處理,使其在 Amazon DocumentDB 中能更好地做檢索。

def flatten_video_data(self, video_data, video_name):flattened_data = []# 處理章節chapters = video_data.get('chapters', [])for chapter in chapters:chapter_summary = chapter.get('chapter_summary', {})flattened_chapter_summary = {"video_name": video_name,"source": f"chapter_{chapter.get('chapter_index', 0)}_summary","text": chapter_summary.get('text', ""),"embedding": chapter_summary.get('embedding', []),"start_timestamp_millis": chapter.get('start_timestamp_millis'),"end_timestamp_millis": chapter.get('end_timestamp_millis')}flattened_data.append(flattened_chapter_summary)# 處理章節轉錄塊transcript_chunks = chapter.get('transcript_chunks', [])for chunk in transcript_chunks:flattened_chunk = {"video_name": video_name,"source": f"chapter_{chapter.get('chapter_index', 0)}_transcript_chunk_{chunk.get('chunk_index', 0)}","text": chunk.get('text', ""),"embedding": chunk.get('embedding', []),"start_timestamp_millis": chapter.get('start_timestamp_millis'),"end_timestamp_millis": chapter.get('end_timestamp_millis')}flattened_data.append(flattened_chunk)return flattened_data對視頻生成的文字做完向量化和數據格式的整理后,便可以將其存入 Amazon DocumentDB 為用戶的檢索做準備了。
4. 用戶搜索文字的 Embedding 轉換
將向量和文字存入 Amazon DocumentDB 后,用戶便可以從前端輸入搜索文字并選擇搜索模式(文本搜索或場景搜索),系統會使用 amazon.titan – embed – text – v2:0 模型對搜索文字進行向量化,以便后續進行向量匹配。
flowchart LRA([接收搜索請求])-->B[解析查詢參數]B-->C{執行混合搜索}C-->D[向量搜索]C-->E[文本搜索]D-->F([合并搜索結果])E-->FF-->G([使用Cohere重排序])G-->H([返回最終結果])雙路召回與結果重排序:Amazon Lambda 利用轉換后的向量,同時進行文字和向量的雙路召回。在向量檢索中,使用 Amazon Document DB 的聚合 pipeline 對向量相似度進行搜索,根據搜索模式過濾結果,最后通過 project 返回相應字段;
$project:返回相應字段如下:
text: "<sample_text>"
video_name: "<sample_name>.mov"
source: "chapter_6_summary"
start_timestamp_millis: 181666
end_timestamp_millis: 227100similarity:與向量索引一樣,我們選擇余弦相似度(cosine)來衡量查詢向量和文檔向量之間的相似性。
top_k:返回的視頻數
filter_condition:由于我們的搜索分為場景搜索和臺詞文本搜索,便以此為篩選,從而用戶可以自行選擇搜索場景。
pipeline = [{"$search": {"vectorSearch": {"vector": query_embedding,"path": "embedding","similarity": "cosine","k": top_k * 3, # Fetch more results since we'll filter them"efSearch": 64}}},# Add a $match stage to filter results based on search mode (scene/transcripts){"$match": filter_condition},# Limit to top_k results after filtering{"$limit": top_k},{"$project": {"text": 1,"video_name": 1,"source": 1,"start_timestamp_millis": 1,"end_timestamp_millis": 1}}] 文字檢索則基于源文件為 json 文本的特點,通過 $text 操作符利用倒排索引進行文本搜索。倒排索引是一種用于快速查找包含特定單詞或短語的文檔的數據結構。與傳統的正向索引(從文檔到單詞的映射)不同,倒排索引是從單詞到文檔的映射。
檢索完成后,由于同一個 source 可能會同時被向量檢索和文字檢索出來,從而在合并結果時做了去重處理:
all_results = processed_vector_results + processed_text_results# Remove duplicates based on '_id' and prefer text search resultsunique_results = []seen_ids = set()for result in reversed(all_results): # Reverse the list to process text results firstresult_id = result['_id']if result_id not in seen_ids:seen_ids.add(result_id)unique_results.append(result)unique_results.reverse() # Reverse the list back to original order# Return unique results directlyreturn {"results": unique_results}最后通過 Amazon Bedrock 集成的 cohere.rerank – v3 – 5:0 模型對召回結果進行重排序,并對輸出結果進行了整理,而后按照相關度分數返回最符合用戶需求的視頻。
response = self.bedrock_client.invoke_model(modelId="cohere.rerank-v3-5:0",contentType="application/json",accept="application/json",body=json.dumps({"api_version": 2,"query": query,"documents": documents,"top_n": len(documents)}))總結
將 BDA 作為處理視頻的手段之一減少了手工分鏡,取幀等的工序。無服務器的架構為整體的設計提供了低成本的計算資源,后續的數據的存儲選用 DocumentDB 也是希望可以用靈活地手段做 Json 數據處理。在 AI 模型的加持下,希望本文能夠為 AI 與視頻搜索提供了一種新思路。
持續改進
作為新功能,目前 BDA 的視頻處理功能僅限于標準輸出,可以考慮后續加入 Amazon Nova 模型來豐富視頻場景描述數據,從而進一步提升視頻內容分析的精細度。Amazon Nova 模型能夠對視頻進行抽幀理解,從每一幀圖像中提取更豐富的信息,例如視頻場景中的物體細節、變化等。這些額外的信息將被整合到視頻檢索系統中,使得用戶在搜索視頻時,能夠獲得更精準、更豐富的搜索結果。
*前述特定亞馬遜云科技生成式人工智能相關的服務僅在亞馬遜云科技海外區域可用,亞馬遜云科技中國僅為幫助您了解行業前沿技術和發展海外業務選擇推介該服務。
本篇作者
本期最新實驗《多模一站通 —— Amazon Bedrock 上的基礎模型初體驗》
? 精心設計,旨在引導您深入探索Amazon Bedrock的模型選擇與調用、模型自動化評估以及安全圍欄(Guardrail)等重要功能。無需管理基礎設施,利用亞馬遜技術與生態,快速集成與部署生成式AI模型能力。
??[點擊進入實驗] 即刻開啟 AI 開發之旅
構建無限, 探索啟程!





紅黑樹)






模型:基于Transformer)

)


)

)