關于AI生成信息準確性的探討
在社群聊天記錄中,用戶提出在使用多種AI工具搜索培生出版企業上市信息時,遇到80%信息錯誤的問題,質疑AI為何無法勝任簡單的網絡信息爬取任務,并表達了對AI實用性的期望。
我抽空對此做出解答:
問題根源在于AI的信息來源不同、混雜低質量信息,以及大型語言模型(LLM)可能生成不準確內容,缺乏有效的事實校對機制。
解決方案:建議明確定義可信信息源,并整合信息;若具備AI編程能力,可自行優化信息源選擇。
Ask-Refine 提問策略
最近用得比較多的方法,分享給大家:
先提問以探明模型對問題的理解,然后基于反饋優化 Prompt,重新生成,而不是一問一答逐輪調整。
?( 提高一次回答得到好結果的能力)
原理:
通過初始提問(Ask),讓模型揭示其對任務的理解或局限性;然后分析輸出,優化 Prompt(Refine),用更貼近模型“溝通語言”的方式重新生成,減少回合數。 ?
優勢:
避免低效的逐輪對話,直接切換到精準表達,提升效率。 ?
步驟: ?
Ask:提出初始 Prompt,觀察模型輸出,分析其理解偏差。?
Refine:根據輸出調整 Prompt,融入 CO-STAR 框架,明確缺失的上下文、目標或細節。
Regenerate:用優化后的 Prompt 重新生成,獲取更精準輸出。
Agent最少的工具箱是什么樣的?
這個開源項目,總結了7種工具,這樣才是“五臟俱全”的Agent。
Minimal AI agent framework that just works with only seven tools.
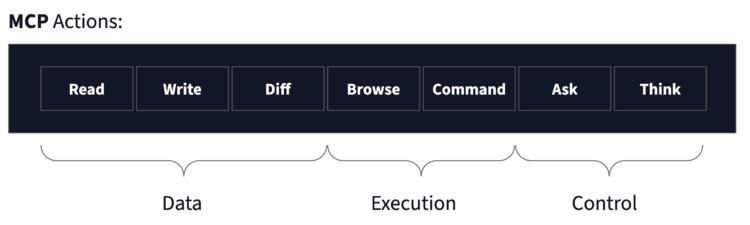
- 讀取——從文件系統訪問文件內容
- 寫入- 在文件系統上創建或修改文件
- Diff——比較文件的不同版本
- 瀏覽——導航并與網頁交互
- 命令——在終端中執行系統命令
- 詢問——向用戶請求信息或確認
- 思考——無需外部行動,進行內部推理
——
歡迎報名最新一期的 AI 編程 訓練營。
具體見 次條 消息。
)



)

)





python開發經驗)




)

