1.簡介
本文介紹了一種名為Matrix-Game的交互式世界基礎模型,專門用于可控的游戲世界生成。
Matrix-Game通過一個兩階段的訓練流程來實現:首先進行大規模無標簽預訓練以理解環境,然后進行動作標記訓練以生成交互式視頻。為此,研究者們構建了一個名為Matrix-Game-MC的綜合Minecraft數據集,包含超過2700小時的無標簽游戲視頻片段和超過1000小時的高質量標記片段,這些片段具有精細的鍵盤和鼠標動作注釋。Matrix-Game采用基于參考圖像、運動上下文和用戶動作的可控圖像到世界生成范式,擁有超過170億個參數,能夠精確控制角色動作和攝像機運動,同時保持高視覺質量和時間連貫性。
為了評估性能,研究者們開發了GameWorld Score,這是一個統一的基準,用于衡量Minecraft世界生成的視覺質量、時間質量、動作可控性和物理規則理解。廣泛的實驗表明,Matrix-Game在所有指標上均優于現有的開源Minecraft世界模型,包括Oasis和MineWorld,特別是在可控性和3D一致性方面表現出色。雙盲人類評估進一步證實了Matrix-Game的優越性,強調了其在多樣化游戲場景中生成感知上逼真且精確可控的視頻的能力。

github地址:GitHub - SkyworkAI/Matrix-Game: Matrix-Game: Interactive World Foundation Model
論文地址:Matrix-Game/assets/report.pdf at main · SkyworkAI/Matrix-Game · GitHub
權重地址:https://huggingface.co/Skywork/Matrix-Game?
項目主頁:Matrix-Game: Interactive World Foundation Model?
基準測試:https://github.com/SkyworkAI/Matrix-Game/tree/main/GameWorldScore?
-
模型效果演示
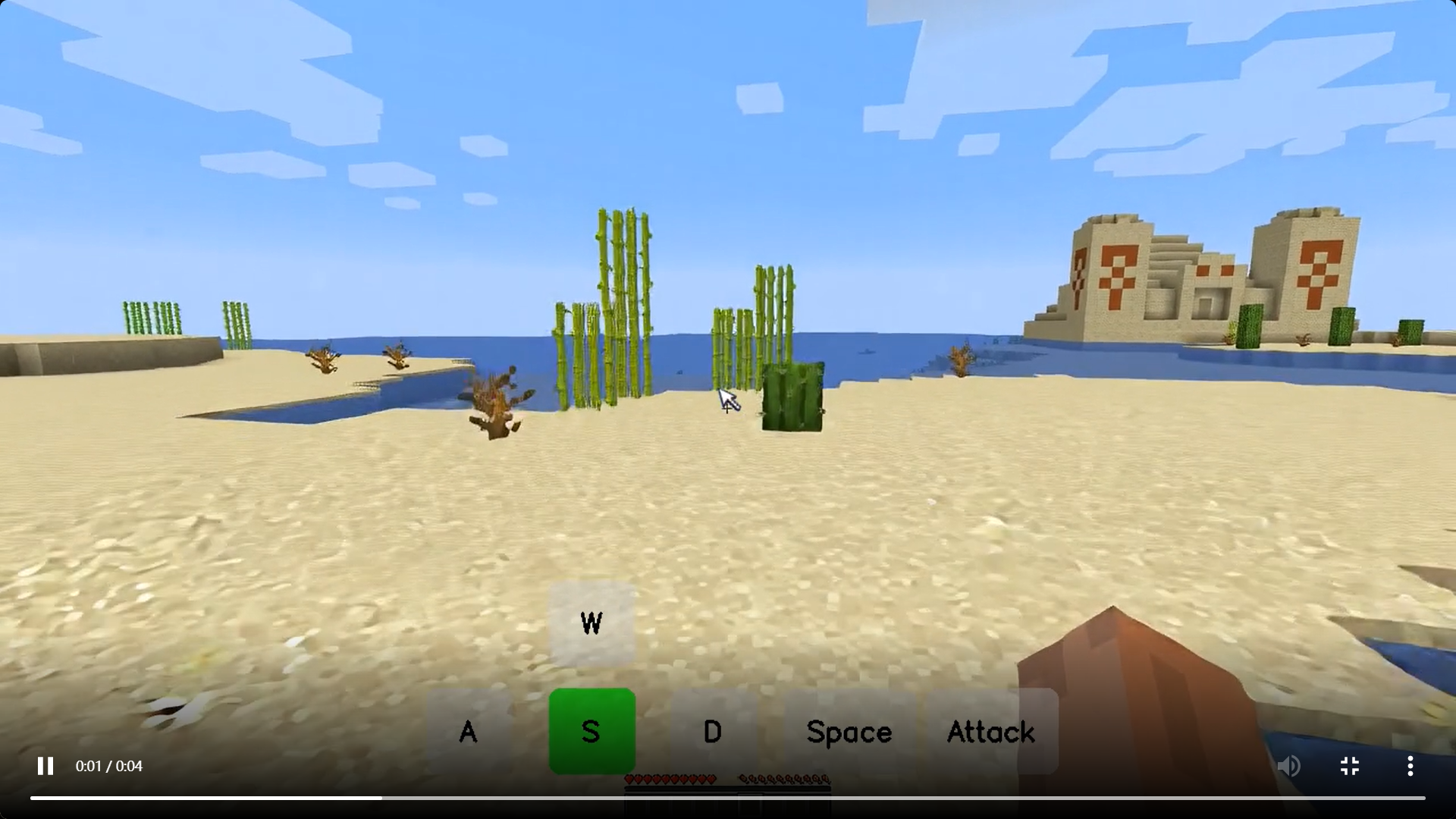
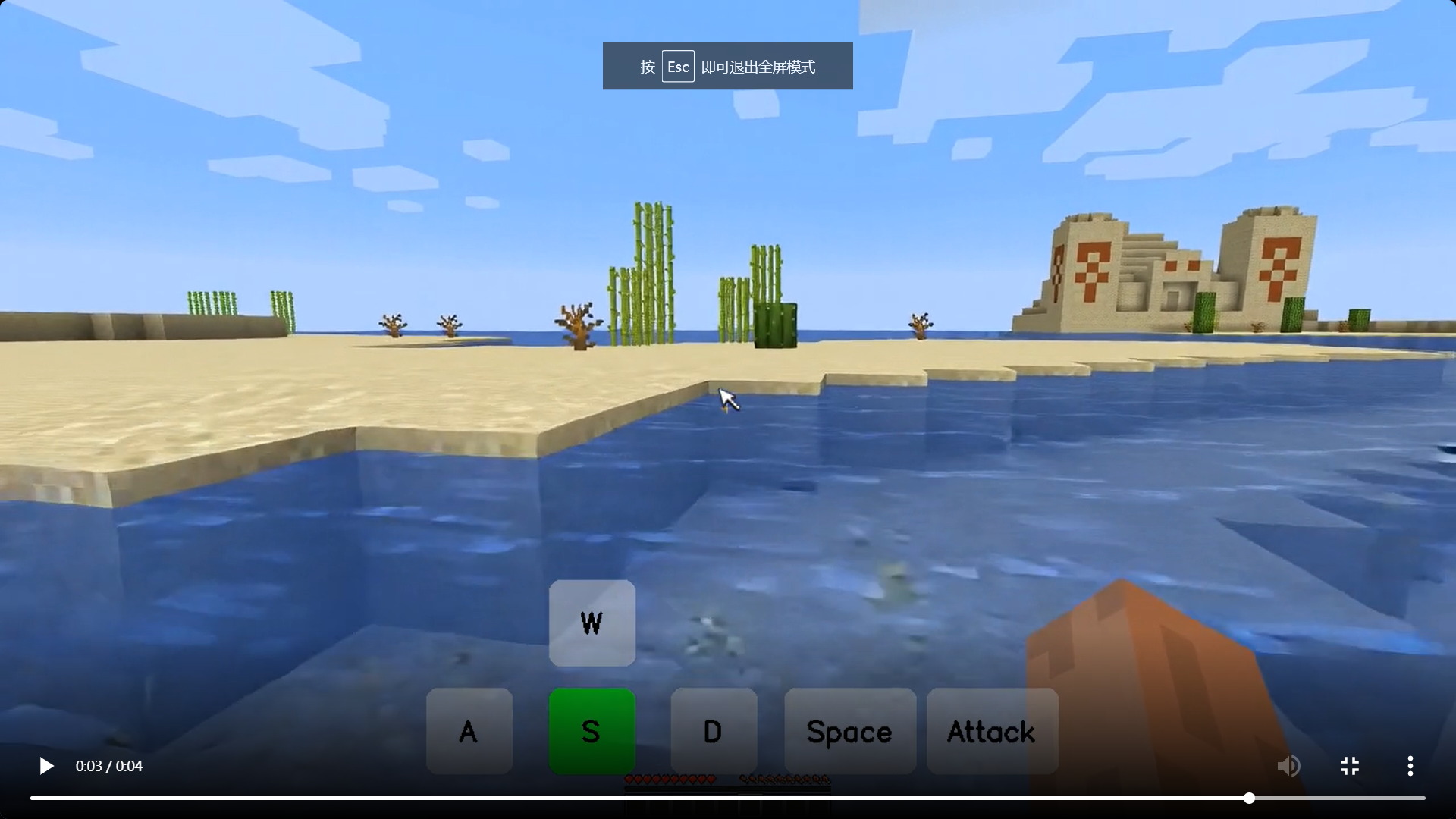
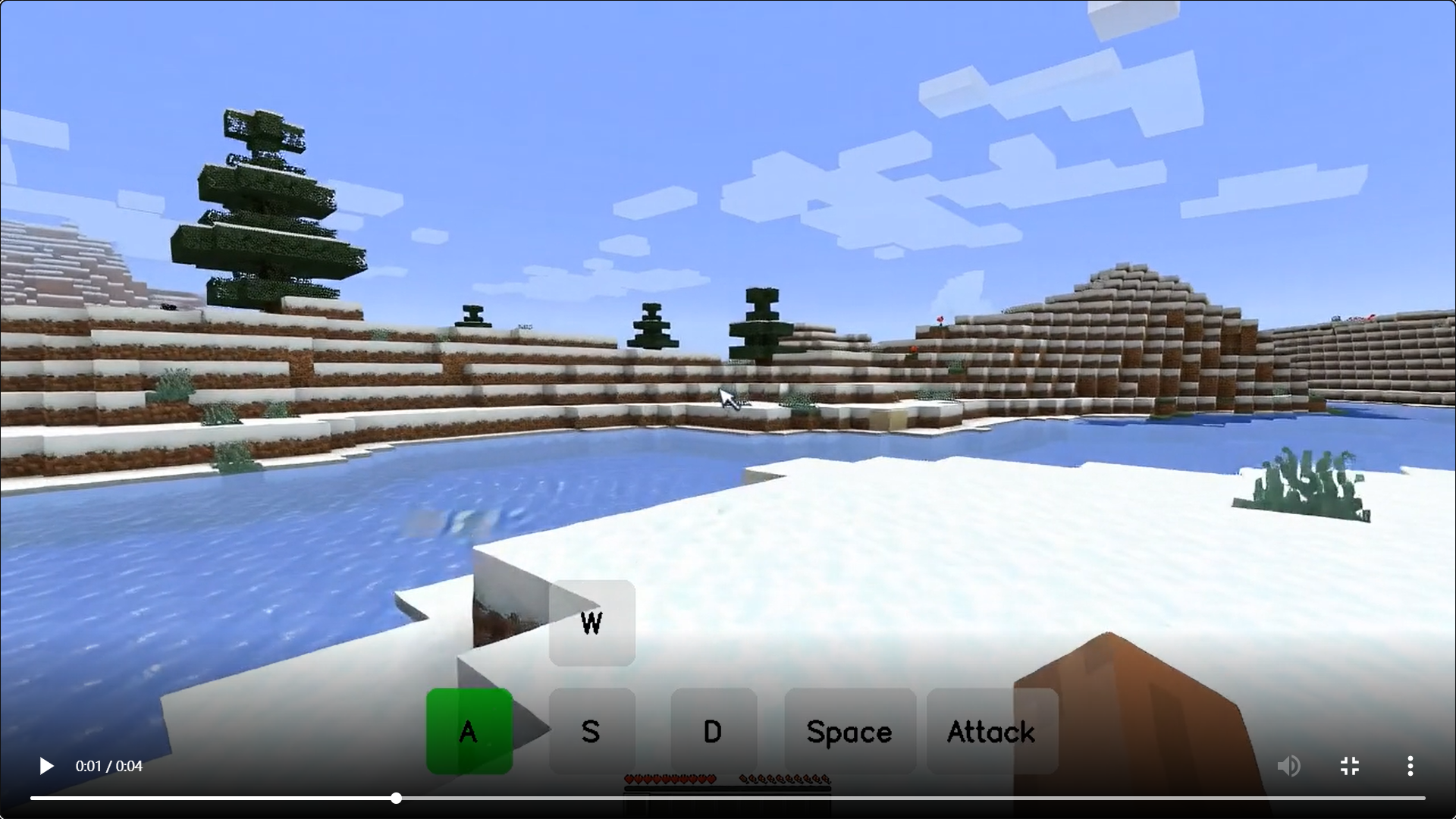
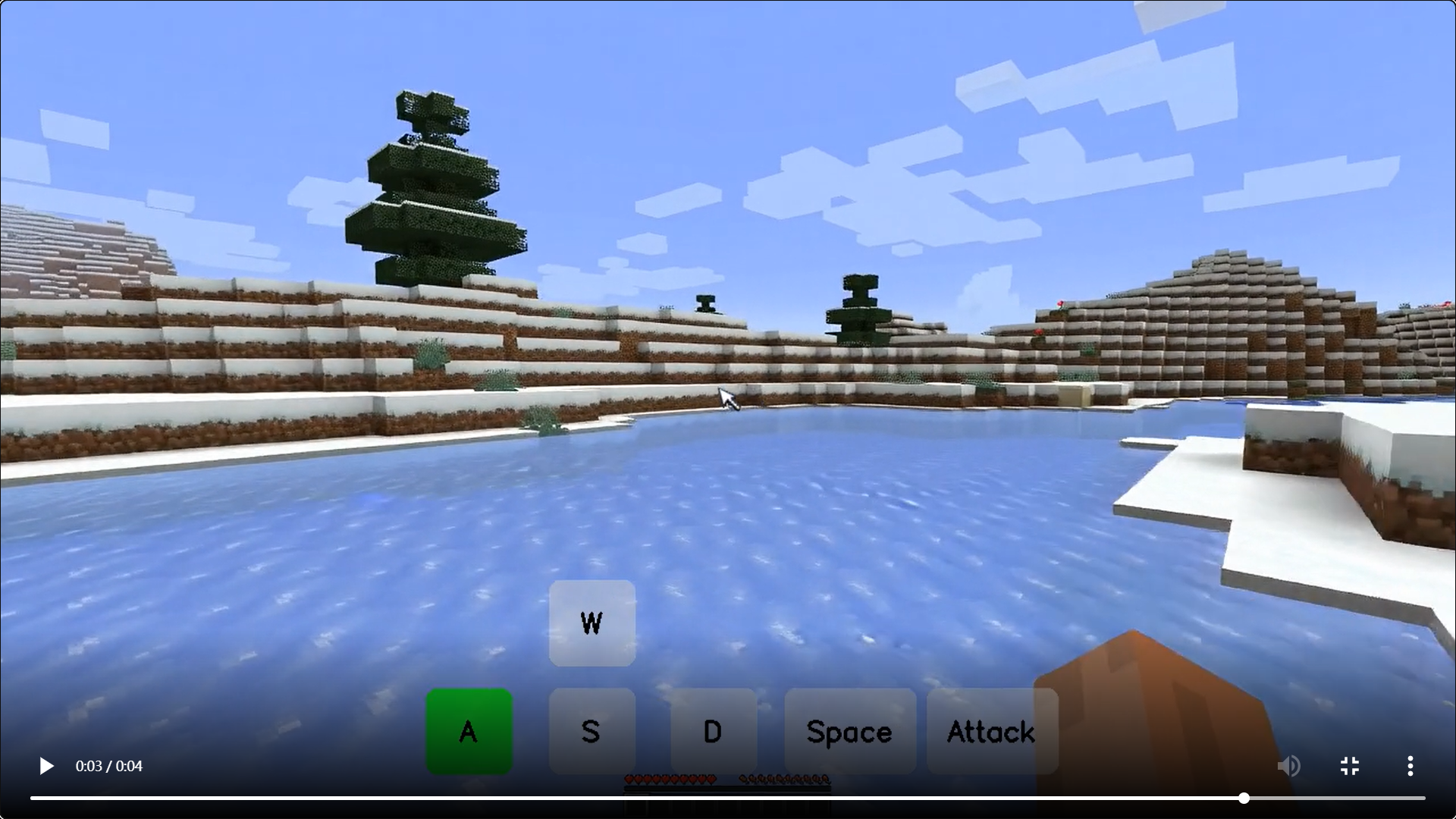
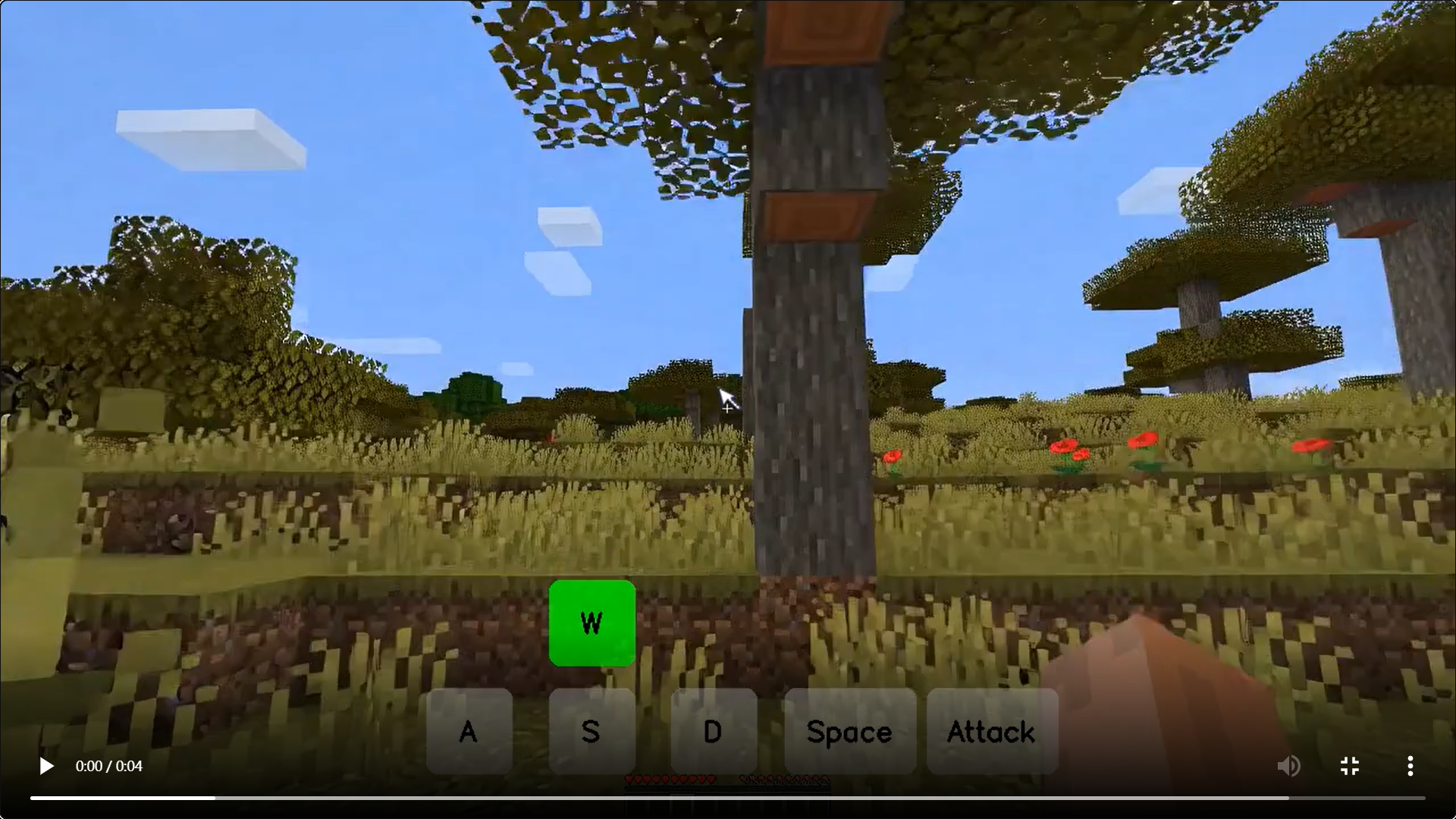
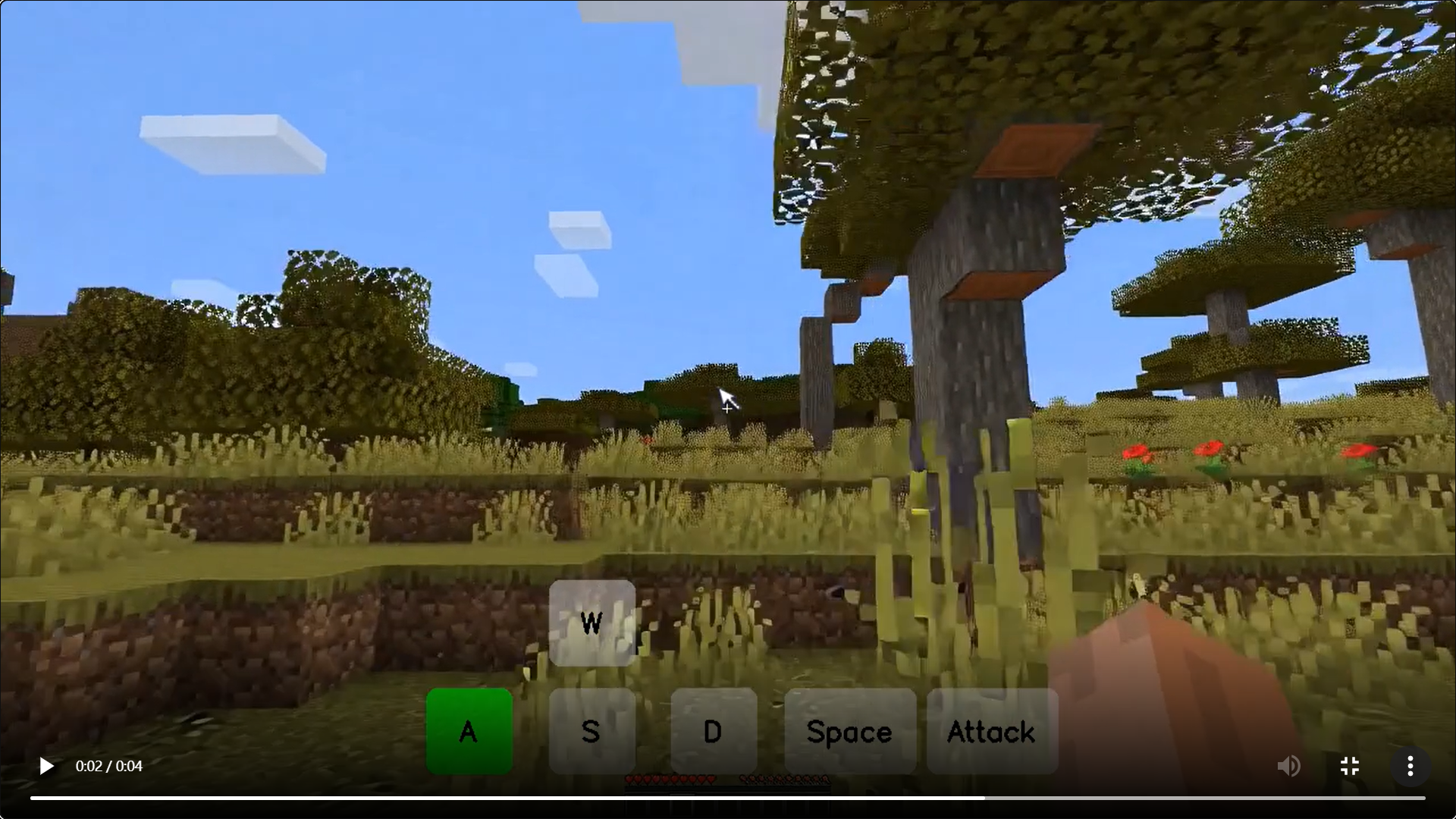
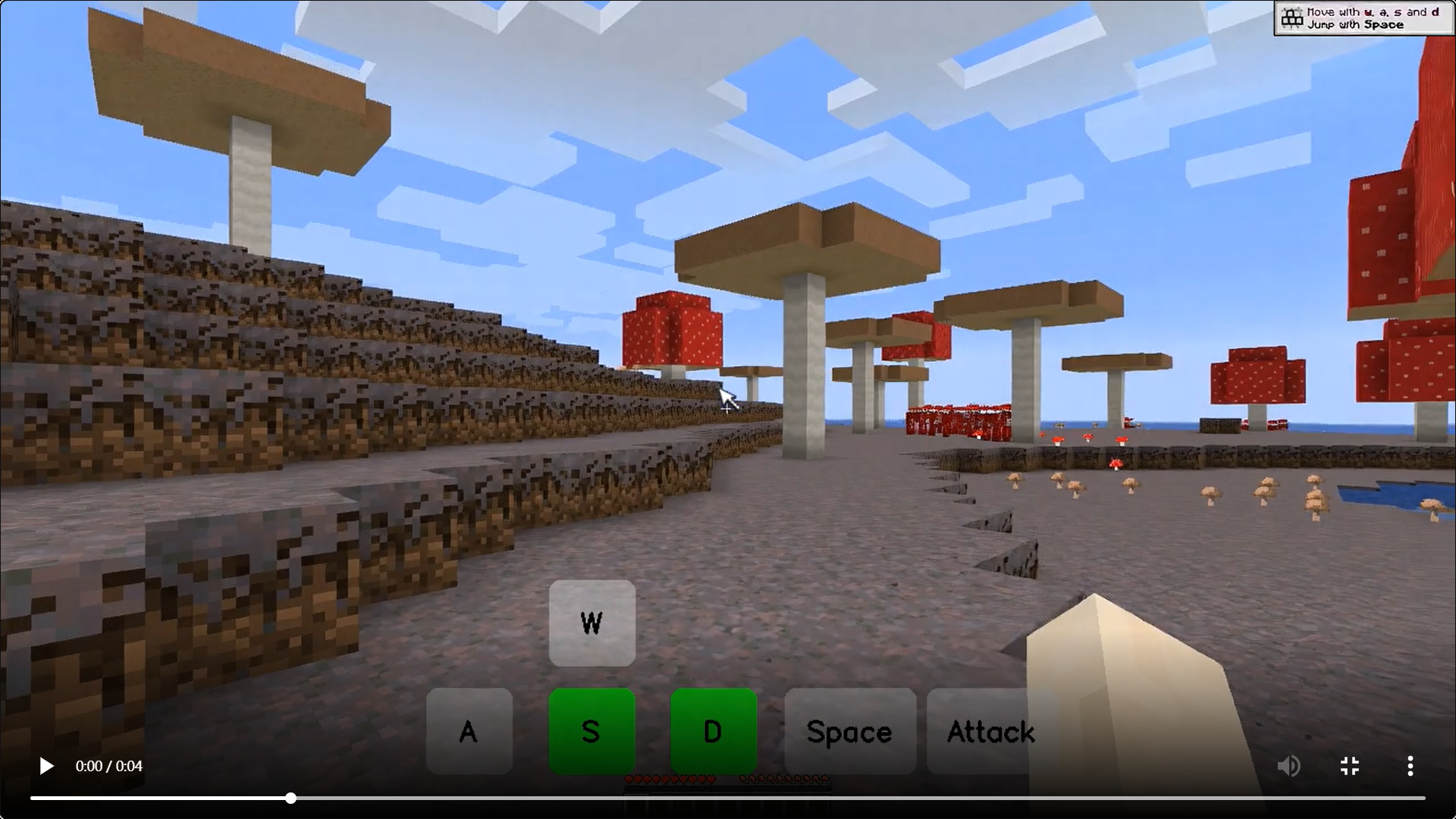
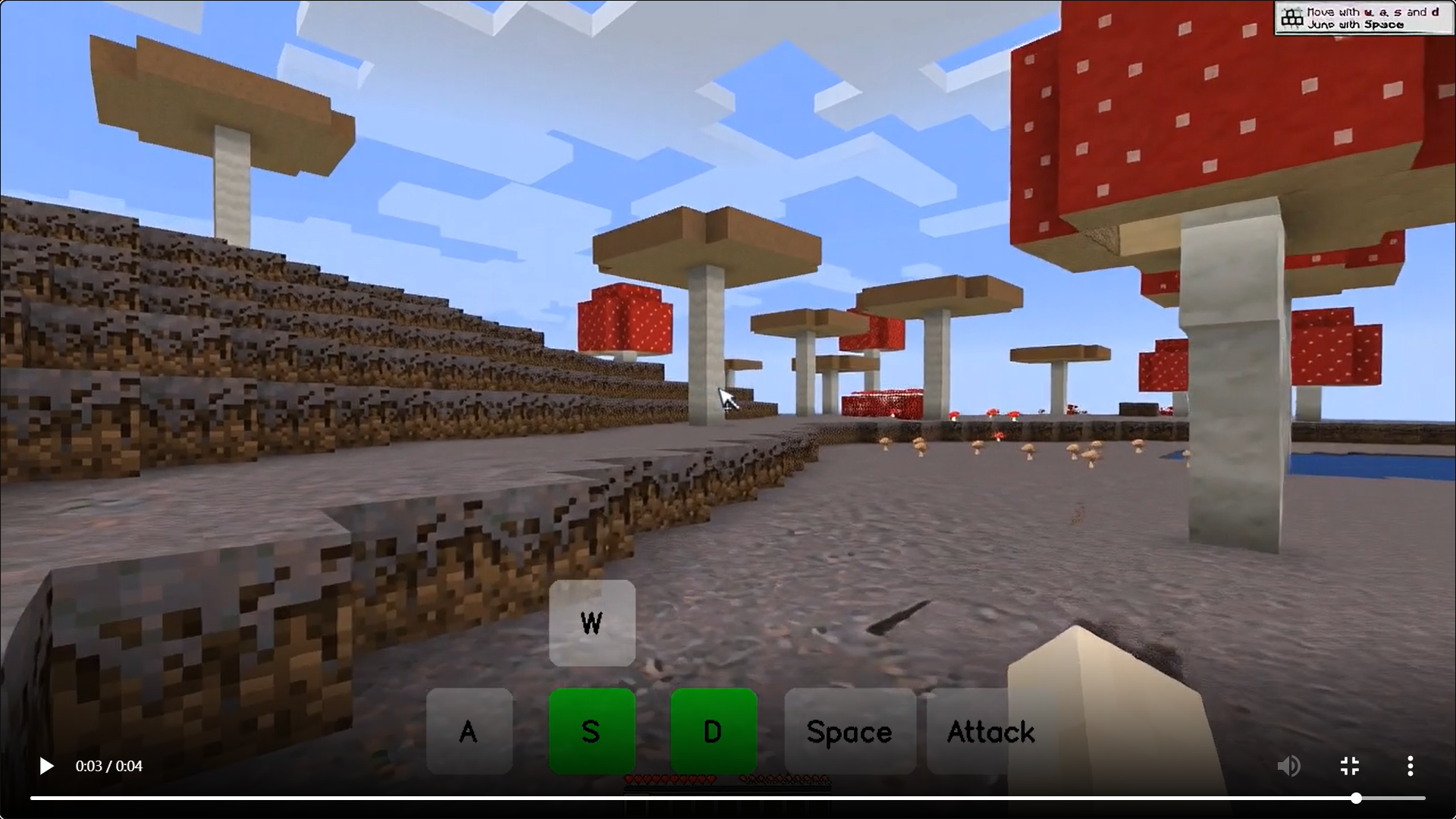
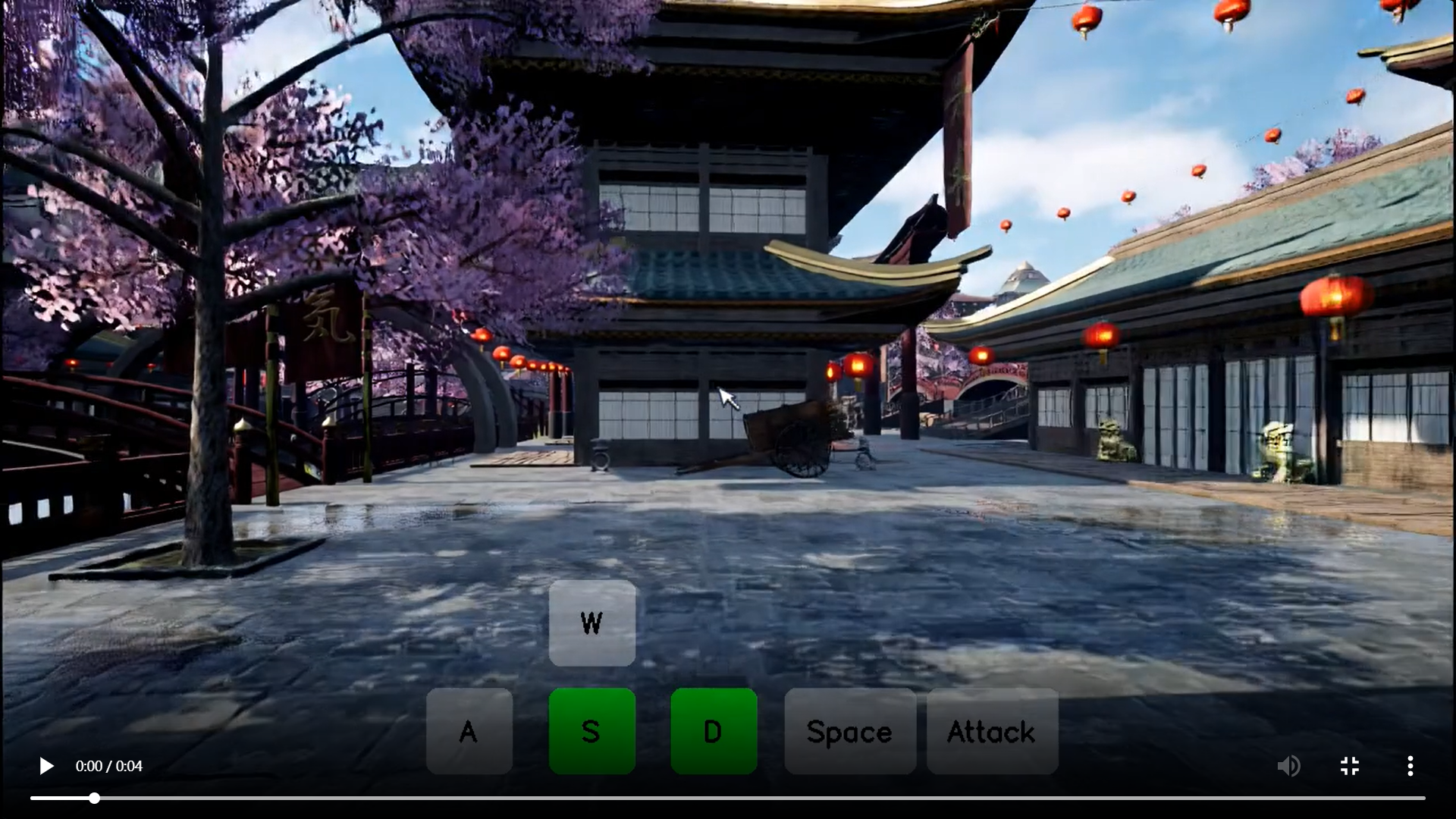
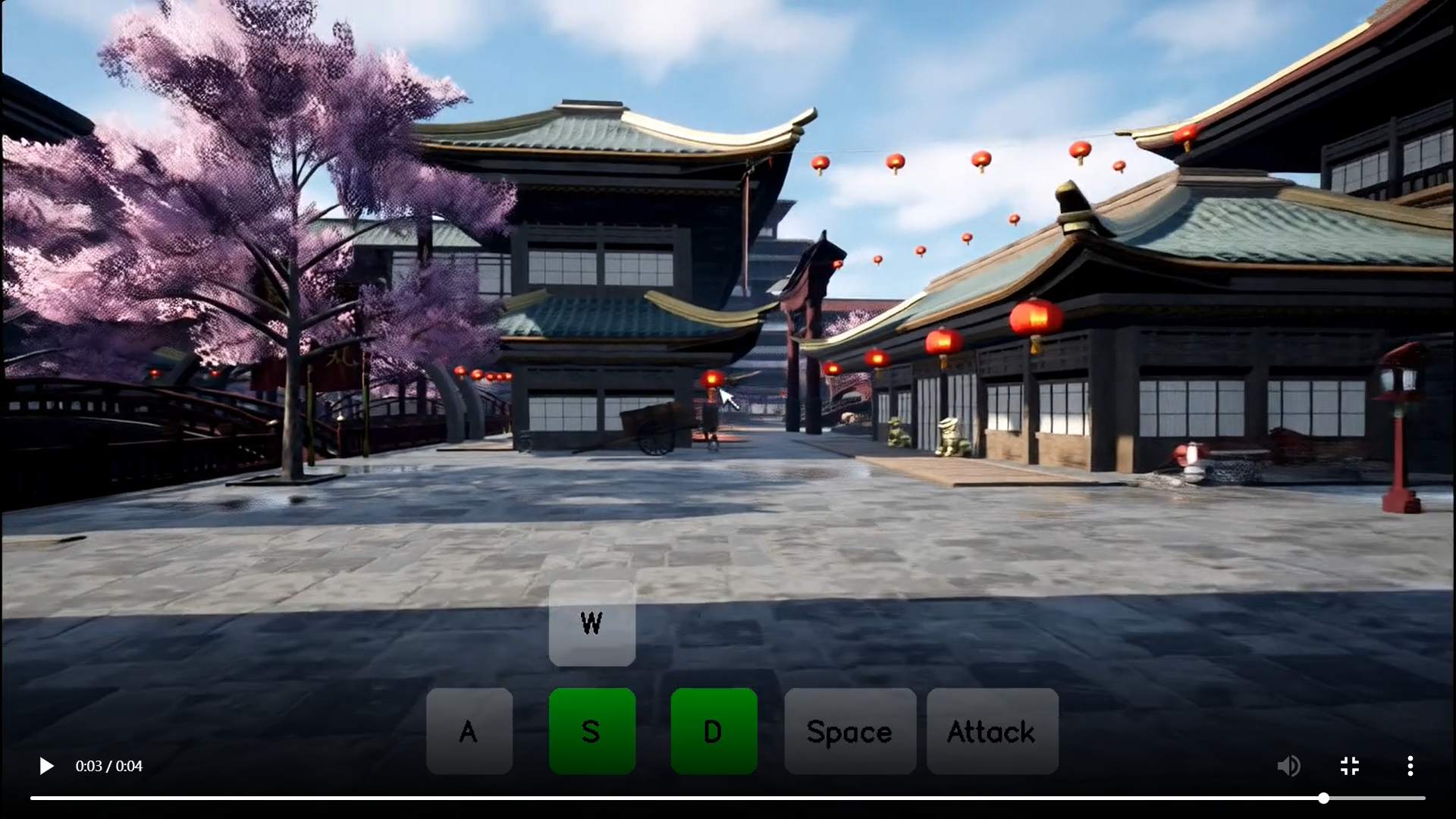
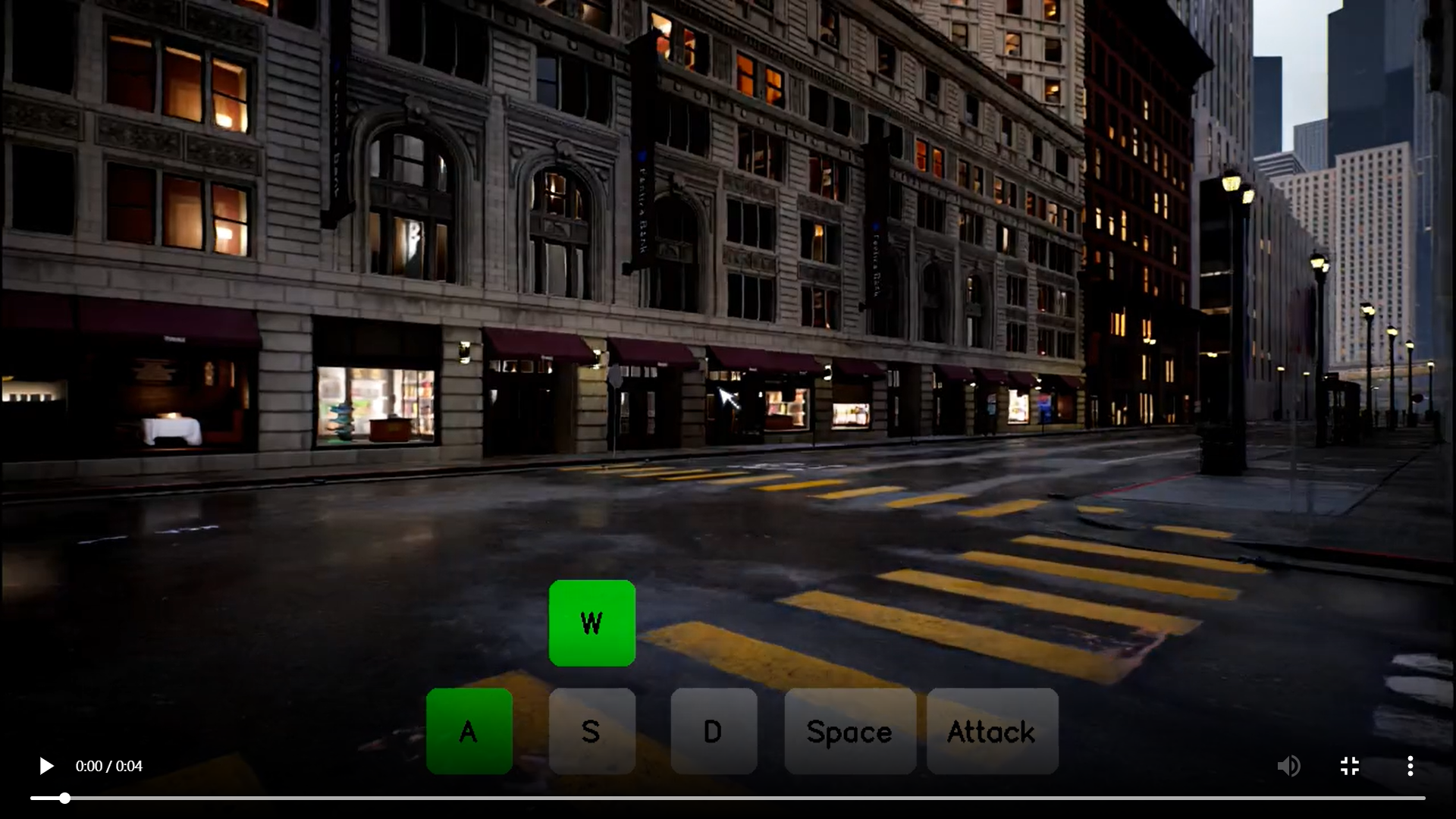
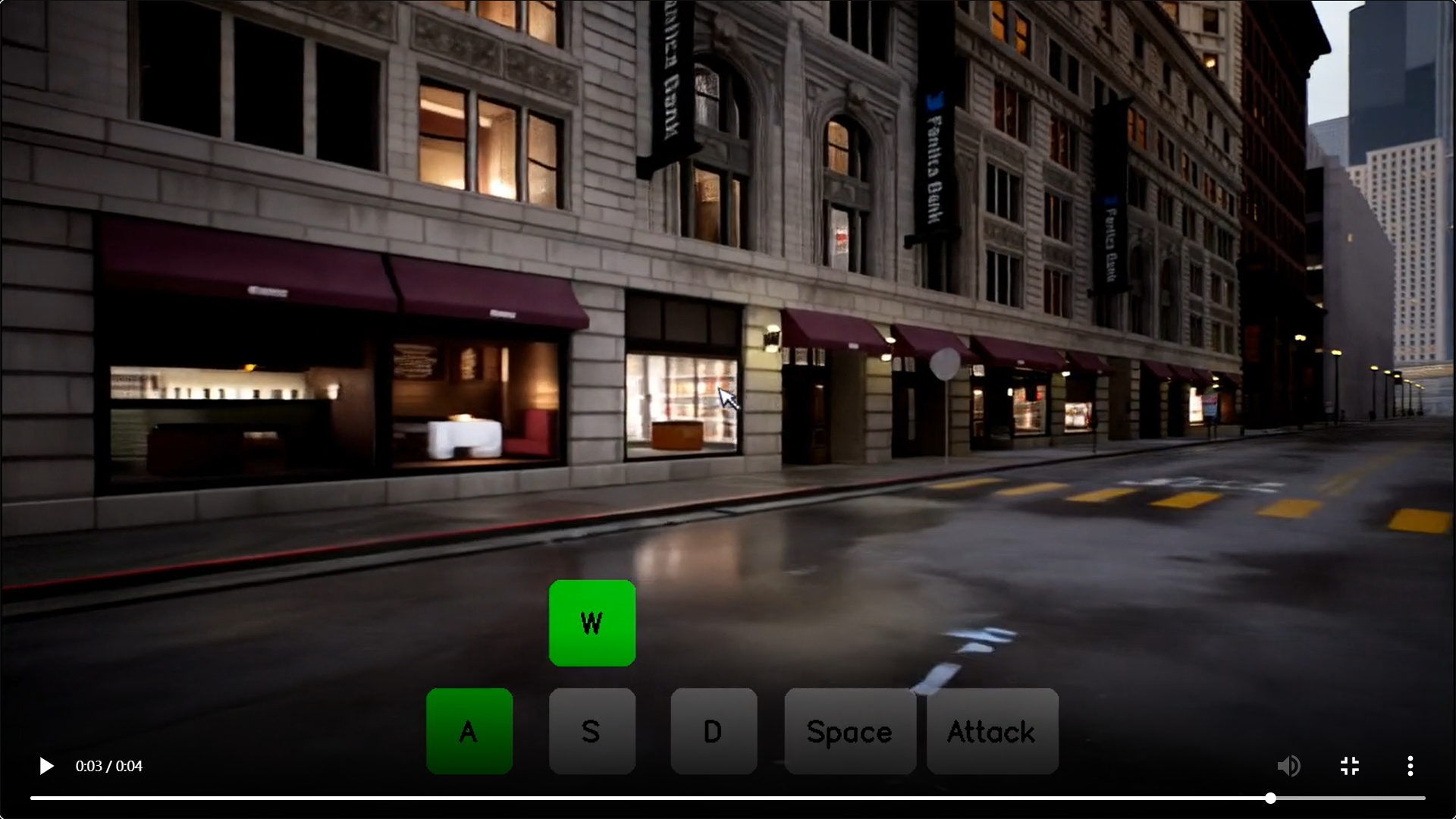
-
-
2.論文詳解
簡介
世界模型是智能代理的基礎,使它們能夠感知、模擬和推理環境的動態。這些模型通過內化外部世界的結構和行為,支持自動駕駛、具身智能和生成式游戲引擎等多種下游任務。近年來,視頻擴散模型因其能夠學習精細的空間-時間動態并生成視覺連貫的視頻而成為世界建模的領先范式。然而,獲取高質量的訓練數據并非易事,尤其是大規模的交互式視頻數據集。此外,建模世界的物理動態并實現時間上的精細可控性也是一大挑戰。最后,缺乏標準化的評估基準使得模型之間的客觀比較變得困難。
Matrix-Game的核心包括三個部分:
-
Matrix-Game-MC數據集:這是一個大規模的Minecraft數據集,包含無標簽的游戲視頻片段和豐富的動作標記視頻數據。該數據集通過自動化的管道以可擴展的方式生成精細的、動作標記的視頻片段,支持在多樣化場景中的可控模型訓練。
-
Matrix-Game模型:這是一個基于擴散的圖像到世界生成模型,支持基于用戶輸入(如鍵盤命令和鼠標驅動的攝像機運動)的交互式視頻生成。該架構強調可控性、時間連貫性和視覺保真度。
-
GameWorld Score基準:這是一個統一的基準,涵蓋多個評估維度(包括視覺質量、時間質量、可控性和物理規則理解),為Minecraft世界模型提供了一個全面的定量評估框架。
如圖1所示,Matrix-Game可以生成高質量、可控的視頻,這些視頻與各種Minecraft場景中的游戲物理相一致。通過將視覺感知與細粒度的用戶控制相結合,Matrix-Game將視頻生成重新定義為探索和創建的交互過程,使用戶能夠從單個參考圖像觀察,指導和構建連貫的虛擬世界。

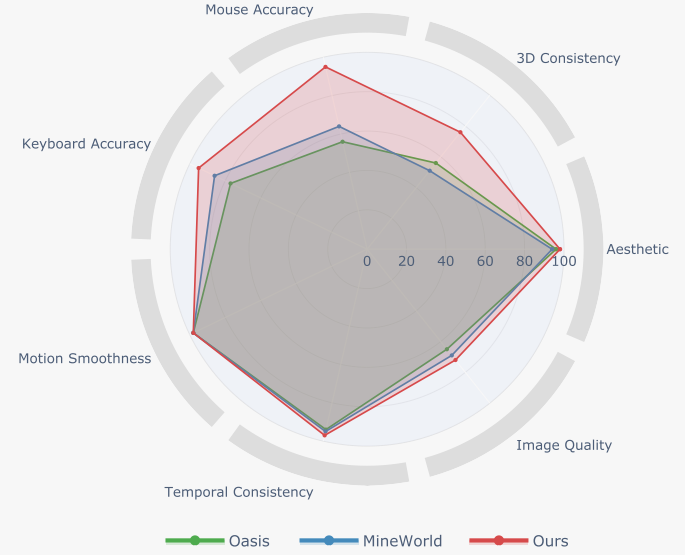
如圖2和表2所示,它始終優于領先的開源Minecraft世界模型,如Oasis [9]和MineWorld [17],在動作可控性和物理規則理解方面有著特別強的優勢。?
-?
Matrix-Game-MC
大規模、高質量的數據是必不作者的。我們采用Minecraft作為主要環境,因為它具有多樣的生物群落,豐富的代理環境交互和開放式游戲,這使得它非常適合學習世界建模。
然而,通過手動游戲獲取帶有動作標簽的Minecraft數據既耗時又耗費資源。為了解決這個問題,作者使用大量未標記的游戲視頻來補充訓練,以幫助模型學習運動動力學和環境規則。與此同時,作者構建了一個自動化的管道,以可擴展的方式生成細粒度的、帶有動作標簽的視頻剪輯,從而在不同的場景中實現可控的模型訓練。
無標簽樣本
未標記的數據采集方案。未標記的訓練數據集是從MineDojo數據集中提供的視頻資源中系統收集的。作者通過數據集的官方視頻存儲庫檢索了大約6,000小時的原始游戲畫面,其中包括演示核心游戲機制的教程內容,非結構化游戲錄制和環境交互演示。
這個多樣化的集合跨越多個生物群落,包括森林,沙漠和雪地生態系統,為Minecraft環境提供廣泛的視覺和物理覆蓋。為了準備訓練數據,作者首先使用TransNet V2來檢測場景轉換并將原始游戲視頻分割為單鏡頭剪輯。在檢測到的過渡邊界處使用FFmpeg執行分割。在處理之前,所有視頻數據都轉換為libx264編碼格式,以提高兼容性和效率。為了減輕逐漸過渡或不穩定的相機運動造成的偽影,作者丟棄每個分段剪輯的前四幀和后四幀。
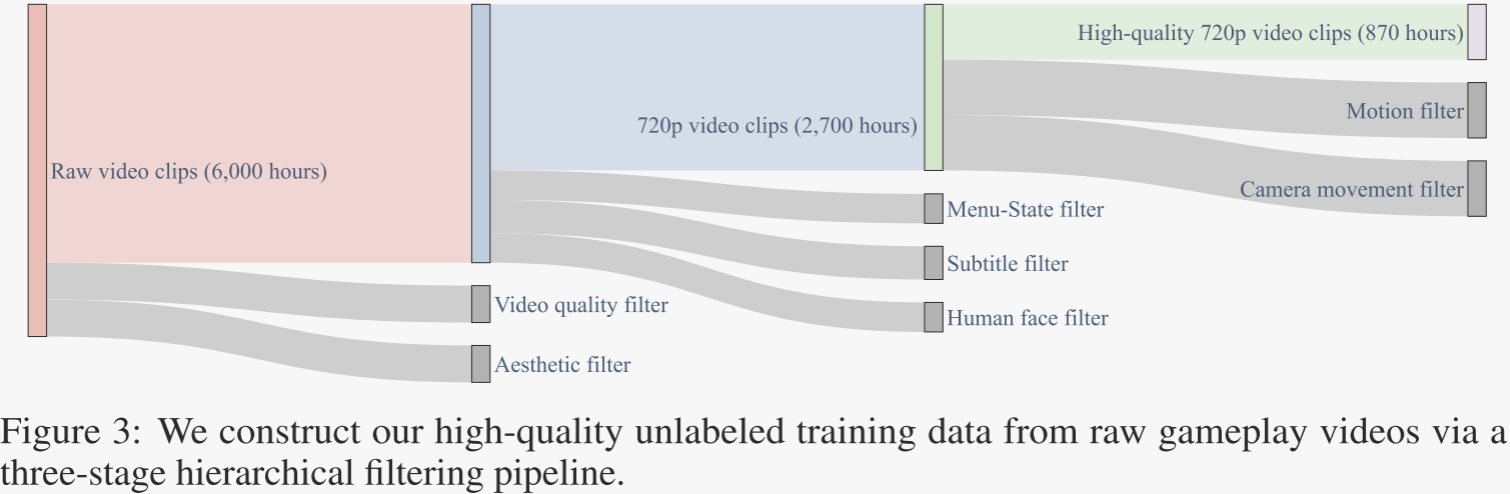
無標簽數據過濾管道。作者引入了一個分層過濾框架(如圖3所示),旨在從原始游戲畫面中挑選高質量、信息豐富的剪輯。作者的數據過濾管道由三個連續的階段組成。第一階段側重于視頻質量過濾和美學過濾。第二階段應用菜單狀態過濾、字幕過濾和面部過濾來移除非信息性或分散注意力的內容。最后一個階段涉及運動分析和相機運動過濾,以確保動態但視覺穩定的剪輯適合模型訓練。
- 視頻質量過濾。作者使用DOVER來評估視頻質量,應用特定類型的閾值來適應不同游戲類型的風格多樣性。這確保了視頻的保留具有足夠的分辨率,清晰度和一致性,以進行可靠的模型訓練。
- 審美過濾。作者使用LAION預測器計算美學評分,對每個剪輯的采樣幀進行平均評分。為了說明跨游戲類型的風格多樣性,作者應用了自適應的、類型感知的閾值。這可確保所選視頻保持視覺上的連貫性和吸引人的構圖,從而支持逼真的生成。
- 菜單-狀態過濾。作者使用逆動態模型(IDM)來檢測沒有玩家輸入(如菜單、空閑狀態或加載屏幕)的幀并排除它們。這確保了數據集專注于活躍的游戲玩法,增強了模型學習動作條件動態和可控時間轉換的能力。
- 字幕過濾:作者應用CRAFT文本檢測器來識別和刪除具有侵入性字幕,流橫幅或水印的視頻。通過將檢測集中在低屏幕和高風險區域,作者保留了游戲中的文本,同時排除了分散注意力的后期制作覆蓋,確保了訓練的清晰視覺輸入。
- 人臉過濾。為了確保數據集集中在游戲環境中,作者使用DeepFace來檢測和過濾包含流光面部攝像頭或人類覆蓋的視頻。通過在多個幀中檢查常見網絡攝像頭區域中的重復出現的人臉,作者消除了非游戲人類內容,保持了場景的純度,并防止模型學習虛假的視覺線索。
- 運動過濾:為了確保有意義的時間動態,作者使用GMFlow應用運動濾波來計算每個剪輯的平均光流幅度。運動太少的視頻(例如,靜態屏幕)或過度運動(例如,快速旋轉或場景假信號)被丟棄。這種雙向過濾保留了運動平衡的序列,支持穩定的訓練,并提高了模型學習時間一致和可控視頻生成的能力。
- 相機移動過濾:為了移除具有過度激進的視點變化的剪輯,作者基于逆動力學模型(IDM)估計的角度變化應用相機運動過濾。具有過度偏航或俯仰旋轉(通常由突然的鼠標移動引起)的視頻將被丟棄。這個過濾步驟促進穩定和連貫的視點軌跡,幫助模型隨著時間的推移學習一致的場景幾何和空間對齊。
有標簽樣本
為了實現可控的視頻生成,作者使用兩種互補策略構建標記數據集:
- 從MineRL環境中的游戲中導出的探索代理軌跡。作者通過VPT代理擴展了MineRL平臺,這些代理能夠在Minecraft世界中執行長期任務。這些智能體會自主探索不同的游戲場景,產生各種各樣的行為模式。作者從這些軌跡中提取每幀的鍵盤和鼠標動作,以構建一個以16Hz采樣的動作標記數據集。
- 以及虛幻程序模擬。為了用高度結構化的演示來補充勘探數據,作者在虛幻引擎中構建了跨越各種生物群落的自定義環境,包括城市、沙漠和森林環境。每個環境都是以編程方式設計和檢測的,以在每個幀提供詳細的監督。具體來說,作者收集:(1)離散動作標簽(例如,移動鍵和跳躍)和連續注視向量(相機俯仰/偏航)。(2)地面實況運動學信息,包括智能體的位置、速度和方向。(3)環境交互結果,例如塊操作操作的成功或失敗。這種程序生成的數據提供了一致的、無噪聲的注釋,使模型能夠在各種可控條件下學習精確的動作-響應映射。
作者在使用MineRL探索代理構建標記的Minecraft軌跡時采用了三種關鍵策略。
- 攝像機運動限制。為了確保視點的穩定性,并促進學習的時間一致的視覺表示,作者明確地限制相機的運動幅度。具體來說,偏航角和俯仰角被限制在每幀15度以內,有效地避免了突然的相機旋轉或迷失方向的視點移位。
-
為了確保視覺效果的一致性并消除渲染偽影,作者在數據生成過程中對MindRL引擎進行了針對性的修改。具體來說,作者禁用了視錐體基礎的區塊加載機制,這一機制會導致攝像機移動時新地形方塊突然出現。這一改動避免了場景突然出現的視覺突變,從而不會破壞視覺流的空間連貫性。
此外,作者還實現了對代理健康狀態和游戲界面狀態的實時監控。當代理接近死亡、卡住,或者暫停/菜單界面被激活時,記錄會自動終止。這些保障措施確保所有捕獲的片段都能反映連續的、有意義的游戲互動,而不是無關的或低質量的部分。
-
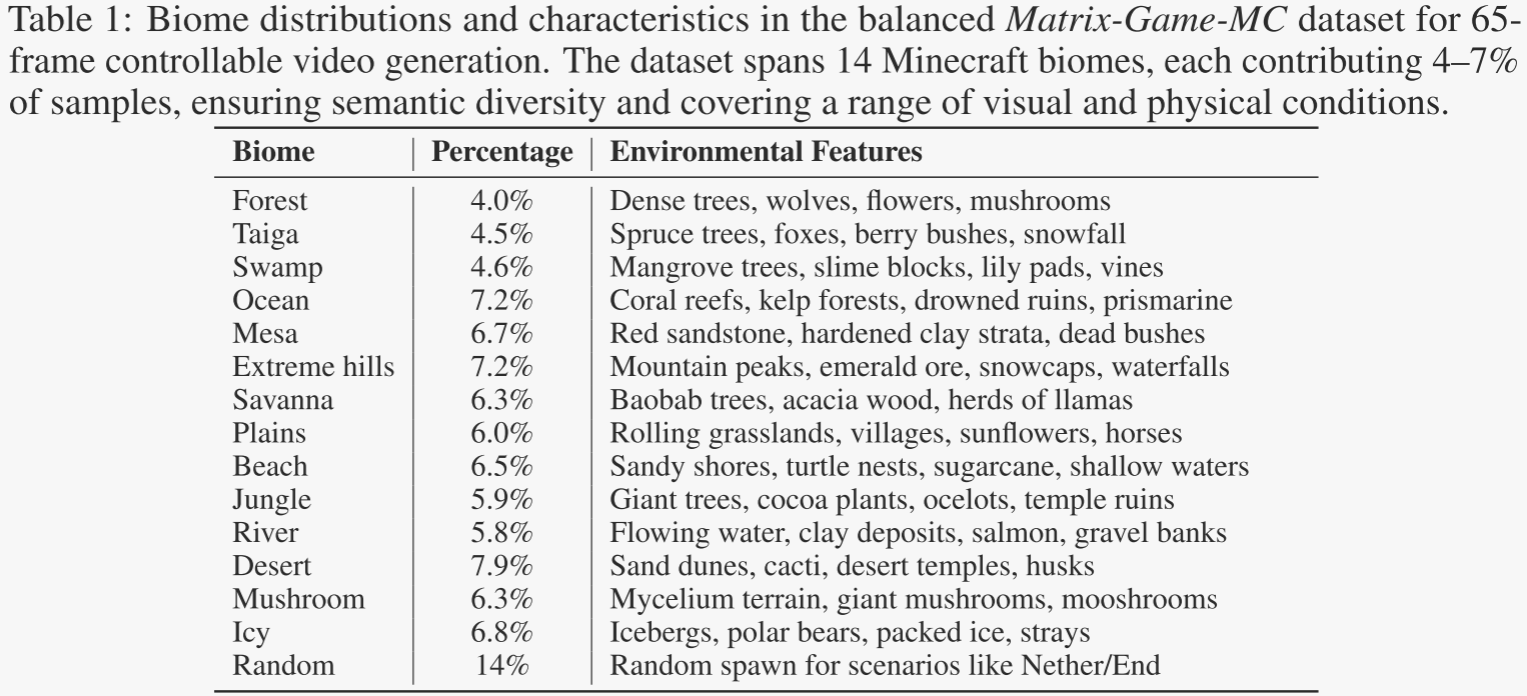
場景多樣化。作者精心挑選了14種《我的世界》(Minecraft)場景,每個場景都與特定的生物群落(例如森林、沙漠、海洋)相關聯,涵蓋了多樣化的地形、光照和建筑結構。玩家在每個場景中執行離散的動作(如移動、跳躍、攻擊),這些動作以平衡的方式進行采樣。
通過將上述數據構建策略應用于基于MineRL的探索代理,作者為《我的世界》合成了一套高質量的標注數據集,這構成了可控訓練語料庫的重要部分。為了進一步提升視覺多樣性與控制保真度,作者還引入了來自虛幻引擎(Unreal Engine)的程序生成視頻。這些來源共同產生了一個全面的標注數據集,包含超過1026小時的視頻片段,用于33幀的訓練。
為了確保在不同環境中的平衡覆蓋,我們還精心整理了一個擴展數據集,包含超過1200小時的視頻,用于65幀的訓練。值得注意的是,這個平衡數據集的大約一半來源于基于MineRL的場景,這些場景涵蓋了14種不同的《我的世界》生物群落,例如森林、沙漠、冰雪和蘑菇群落,其分布情況詳細記錄在表1中。這些生成的數據集具有穩定的運動、密集的動作以及豐富的結構多樣性,為訓練穩健且可控的視頻生成模型提供了強大且平衡的監督信號,使其能夠泛化到各種不同的虛擬環境中。
-?
模型
大多數現有的基于擴散的世界模型,例如SORA、HunyuanVideo I2V和Wan,依賴于文本提示和參考圖像作為先驗知識來指導生成過程。盡管這些方法可以生成高質量的結果,但文本的引入往往會引入語義偏見,限制空間解釋能力,并降低模型僅通過視覺和物理線索來構建理解的能力。因此,模型可能會產生不切實際的內容,或者過度擬合語言先驗,而不是忠實地建模視覺世界。受空間智能概念的啟發,Matrix-Game探索了一種不同的路徑:作者的模型不使用文本和圖像作為條件,而是純粹從原始圖像中學習。它通過構建一個能夠捕捉幾何形狀、物體運動以及事物之間物理交互的一致性場景來理解世界。
模型架構
如圖4所示,Matrix-Game采用了一種從圖像到世界的生成范式,以單張參考圖像作為理解世界和生成視頻的主要先驗知識。該模型在一個由3D因果變分自編碼器(3D Causal VAE)構建的時空壓縮的潛在空間中進行訓練,該空間將視頻序列的空間和時間分辨率分別降低了8倍和4倍。參考圖像經過視覺編碼器或多模態骨干網絡處理后,作為核心條件輸入。在高斯噪聲和可選用戶動作的條件下,擴散變換器(Diffusion Transformer,簡稱DiT)生成潛在表示,這些表示隨后通過3D VAE解碼器被解碼為連貫的視頻序列。
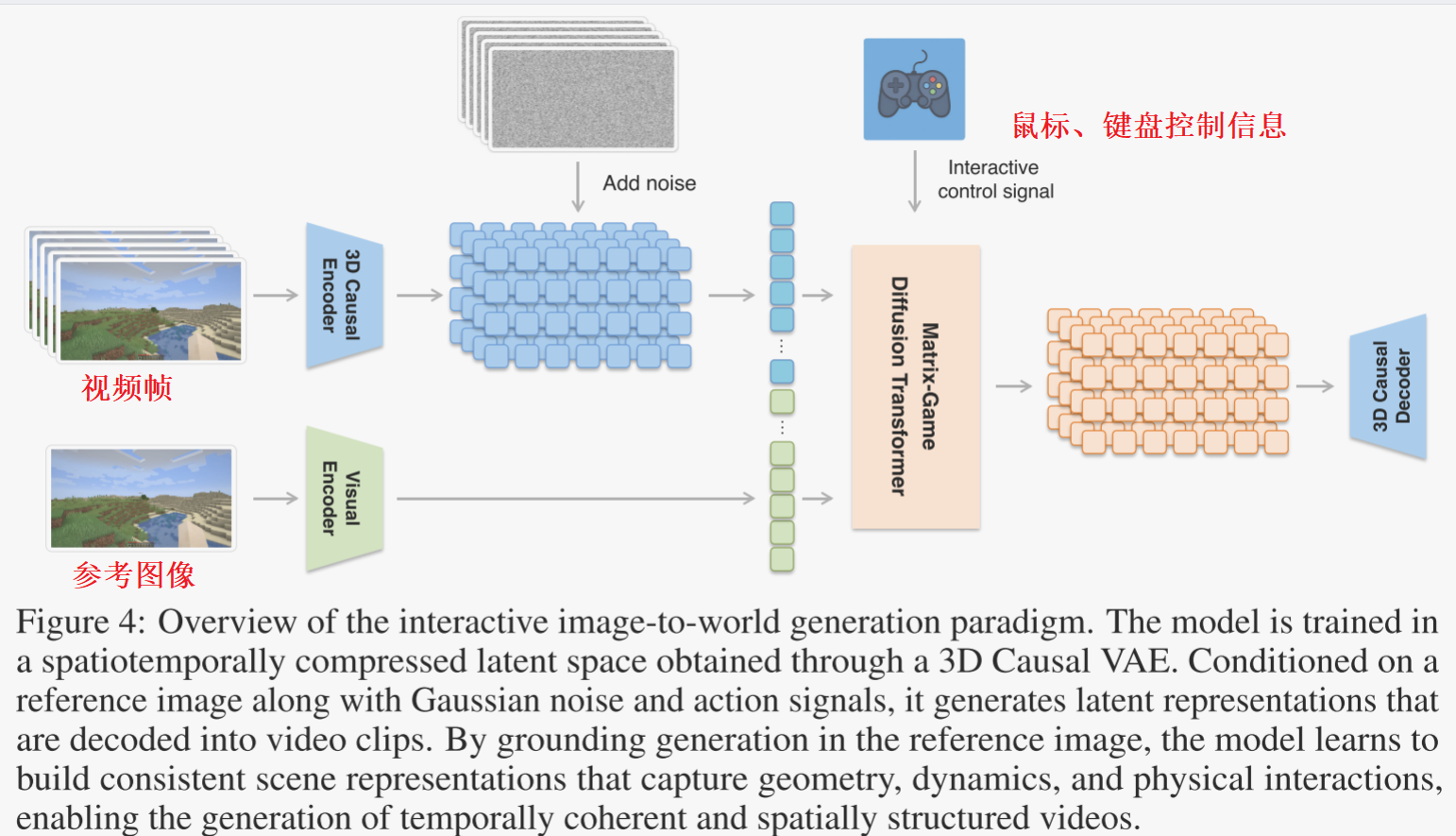 自回歸生成與擴散變換器。為了實現高質量的生成,作者采用多模態擴散變換器(MMDiT)進行圖像到世界的建模。像大多數當前的視頻生成方法一樣,如圖4所示的圖像到世界模型生成固定長度的視頻片段,這限制了其在需要長期或連續世界建模的實際場景中的適用性。為了克服這一限制,并借鑒近期在長時視頻生成方面的進展,作者采用了一種自回歸策略:在每一步中,模型將之前生成的視頻片段作為運動上下文,以生成下一個片段。如圖5(a)所示,作者使用每個生成片段的最后k = 5幀作為生成后續片段的運動條件。這種設計使得模型能夠在保持片段之間時間連貫性的同時,逐步擴展生成內容的時間跨度。
自回歸生成與擴散變換器。為了實現高質量的生成,作者采用多模態擴散變換器(MMDiT)進行圖像到世界的建模。像大多數當前的視頻生成方法一樣,如圖4所示的圖像到世界模型生成固定長度的視頻片段,這限制了其在需要長期或連續世界建模的實際場景中的適用性。為了克服這一限制,并借鑒近期在長時視頻生成方面的進展,作者采用了一種自回歸策略:在每一步中,模型將之前生成的視頻片段作為運動上下文,以生成下一個片段。如圖5(a)所示,作者使用每個生成片段的最后k = 5幀作為生成后續片段的運動條件。這種設計使得模型能夠在保持片段之間時間連貫性的同時,逐步擴展生成內容的時間跨度。
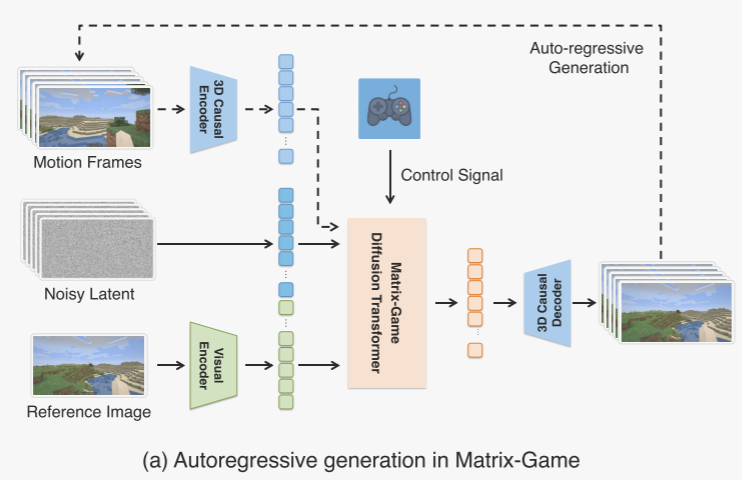
為此,如圖5(b)所示,作者將運動幀的潛在表示與噪聲潛在表示沿著通道維度拼接,以形成下一步生成的輸入。一個二進制掩碼被拼接以指示哪些幀包含有效的運動信息。然后,將合并后的潛在張量通過一個補丁嵌入層處理,并進一步沿著標記維度與圖像標記拼接。最后,在用戶控制信號作為額外指導輸入的條件下,多模態擴散變換器生成一個新的視頻片段。
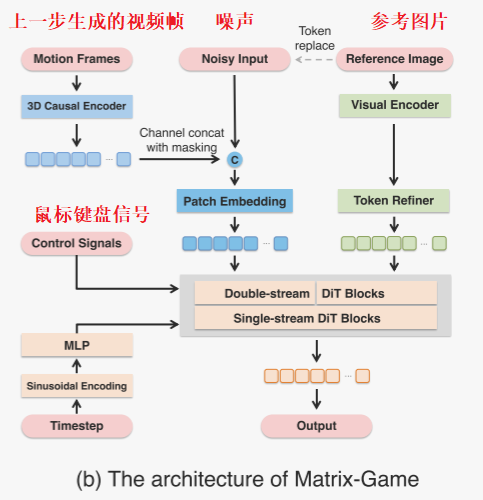
然而,自回歸生成的一個關鍵挑戰是時間誤差累積:最后幾幀生成的偽影可能會在后續片段中傳播并放大。為了提高自回歸過程的魯棒性,受Open-Sora計劃 的啟發,作者在訓練過程中以0.2的概率向運動幀和參考圖像引入高斯噪聲。此外,作者在訓練過程中對運動幀應用無分類器引導(Classifier-Free Guidance, CFG):運動幀的潛在表示以0.25的概率被替換為無條件信號(即零潛在表示)。這種CFG策略促使模型更有效地依賴運動上下文,從而實現更穩定、更可靠的自回歸視頻生成。
為可控視頻生成注入動作。受Genie 2的啟發,作者采用幀級控制信號來指導視頻生成。如圖6(a-b)所示,作者將控制模塊集成到多模態擴散Transformer中,以實現動作可控生成,而動作控制模塊的詳細架構如圖6(c)所示。
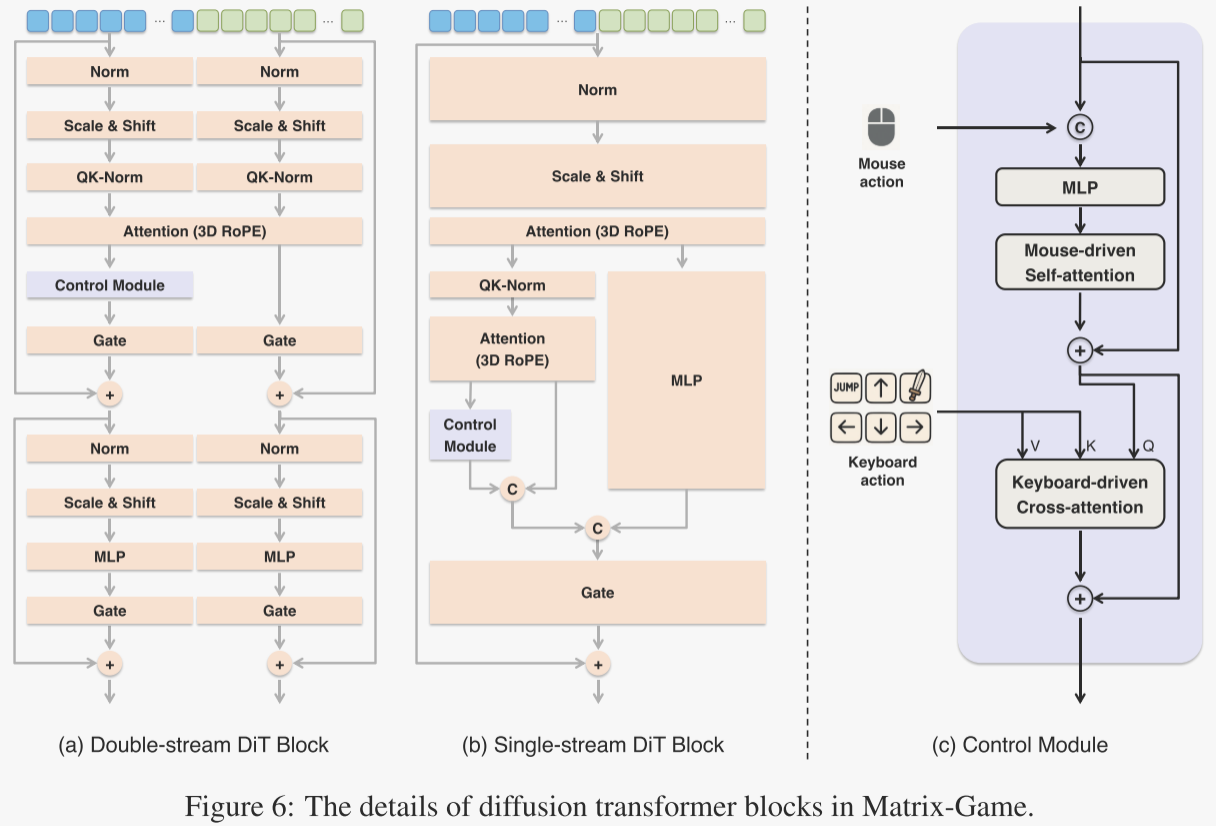
具體來說,作者使用離散編碼來表示鍵盤操作,包括“上”“下”“左”“右”“跳躍”和“攻擊”,并使用連續標量值來表示鼠標移動,定義為俯仰角的變化。為了將這些動作信號與3D因果變分自編碼器(3D Causal VAE)生成的壓縮潛在標記對齊,連續的鼠標動作與輸入潛在表示拼接后,通過一個多層感知機(MLP)處理,隨后經過時間自注意力模塊,而離散的鍵盤動作則通過交叉注意力模塊整合以引導擴散過程。此外,作者在訓練過程中對動作信號應用無分類器引導(classifier-free guidance),以0.1的概率將動作信號替換為無條件信號。這有助于模型在提供動作信號時更有效地利用它們,從而在生成的視頻中實現更好的控制和互動效果。
模型訓練
為了提高訓練的穩定性并實現更快的推理速度,Matrix-Game采用了流匹配范式,該范式在收斂性和采樣效率方面優于傳統的去噪擴散概率模型(DDPM)。為了支持復雜任務,例如建模世界知識、捕捉物理動態以及實現動作可控的生成,作者將訓練過程分為兩個逐步優化的階段,每個階段針對不同的學習目標進行優化。
第一階段:無標簽訓練用于游戲世界理解
為了加速收斂,模型初始化時使用了HunyuanVideo I2V 的預訓練權重。為了從文本驅動的生成轉變為基于圖像的條件世界建模,作者用圖像分支替換了多模態擴散變換器中原有的文本分支。在這一階段,排除了動作控制模塊,專注于視覺世界理解。主要目標是讓模型在大規模游戲環境中進行預訓練,使其能夠構建對虛擬世界的結構化理解,包括空間布局、物體動態以及直觀的物理規則。為此,作者使用了2700小時的無標簽《我的世界》視頻(720p分辨率)作為豐富的視覺和物理線索來源。作者使用不同幀數(17、33和65)和寬高比(16:9、4:3和21:9)的多樣化組合來訓練模型,以增強其在不同時間和空間設置下的魯棒性。
在初始的大規模預訓練之后,作者通過精心挑選同一數據集中的870小時高質量視頻片段,進一步優化模型的視覺和物理理解能力。這些片段的選擇基于穩定的攝像機運動、干凈的用戶界面以及整體視覺清晰度。這種針對性的優化提升了Matrix-Game建模連貫空間結構、捕捉精細物理交互以及生成具有更高感知質量和時間連貫性的視頻的能力。
第二階段:動作標注訓練用于交互式世界生成
在第二階段,作者將動作控制模塊集成到多模態擴散變換器中,以實現動作可控的視頻生成。最終的模型Matrix-Game包含170億個參數,并在來自《我的世界》和虛幻引擎環境的1200小時動作標注的720p 33幀視頻片段上進行訓練。為了確保在可控生成過程中的訓練穩定性和效率,作者在早期訓練階段采用固定的720p分辨率和33幀設置。
為了緩解世界場景中的類別不平衡問題,作者在第二階段的子階段進一步優化訓練數據。具體來說,作者通過整理來自8種不同《我的世界》生物群落的樣本,精心挑選出一個更加平衡的數據集:海灘、沙漠、森林、丘陵、冰雪、蘑菇、平原和河流。結合虛幻引擎生成的數據,這最終形成了一個高質量、平衡的訓練集,包含大約1200小時的720p 65幀視頻片段。我們在65幀的設置下繼續訓練,以增強模型捕捉長距離時間依賴關系的能力,這對于在擴展序列中保持連貫的交互至關重要。
通過整合平衡的、動作豐富的數據和強大的視覺先驗,Matrix-Game學會了精確地解釋用戶輸入,并在多樣化的交互環境中進行泛化。這種視覺理解與用戶控制的緊密結合,將視頻生成推進到一個用于世界探索和創造的交互式范式,使用戶能夠從單張參考圖像出發,感知、修改并構建連貫的虛擬環境。
-
GameWorld Score:Minecraft世界模型的統一基準
隨著世界模型的興起,越來越多的研究開始關注《我的世界》(Minecraft)世界生成,目標是利用視頻生成模型來生產不僅符合用戶動作輸入,同時也遵循游戲中固有物理規則的視頻。然而,現有研究缺乏一個統一的評估基準,以一致地衡量和比較在動作輸入設置下模型的性能。
為了更好地衡量和比較《我的世界》世界模型,作者開發了GameWorld Score,這是一個統一的基準測試,不僅評估生成視頻的感知質量,還評估其可控性和物理合理性。具體來說,我們將世界模型性能的評估分解為八個維度,每個維度針對視頻生成的一個特定方面。
在最高層級,GameWorld從四個關鍵支柱對模型進行評估:
- 視覺質量:評估每個單獨幀與人類視覺系統(Human Visual System, HVS)一致的視覺保真度,重點關注靜態圖像的清晰度、連貫性和逼真度。
- 時間質量:衡量模型在時間上保持一致性和流暢性的能力,捕捉諸如運動連續性和時間連貫性等動態特性。
- 動作可控性:評估生成視頻是否忠實地遵循用戶提供的控制輸入,例如移動指令和攝像機調整。
- 物理規則理解:評估視頻是否遵循基本的物理原理,例如重力、碰撞和物體恒存性,特別關注在空間和時間上保持物體的三維一致性,反映模型模擬物理連貫環境的能力。
這四個支柱進一步細分為更精細的維度,如圖7所示,使得在像《我的世界》這樣具有交互性和物理驅動的環境中,能夠對生成模型進行全面且結構化的評估。
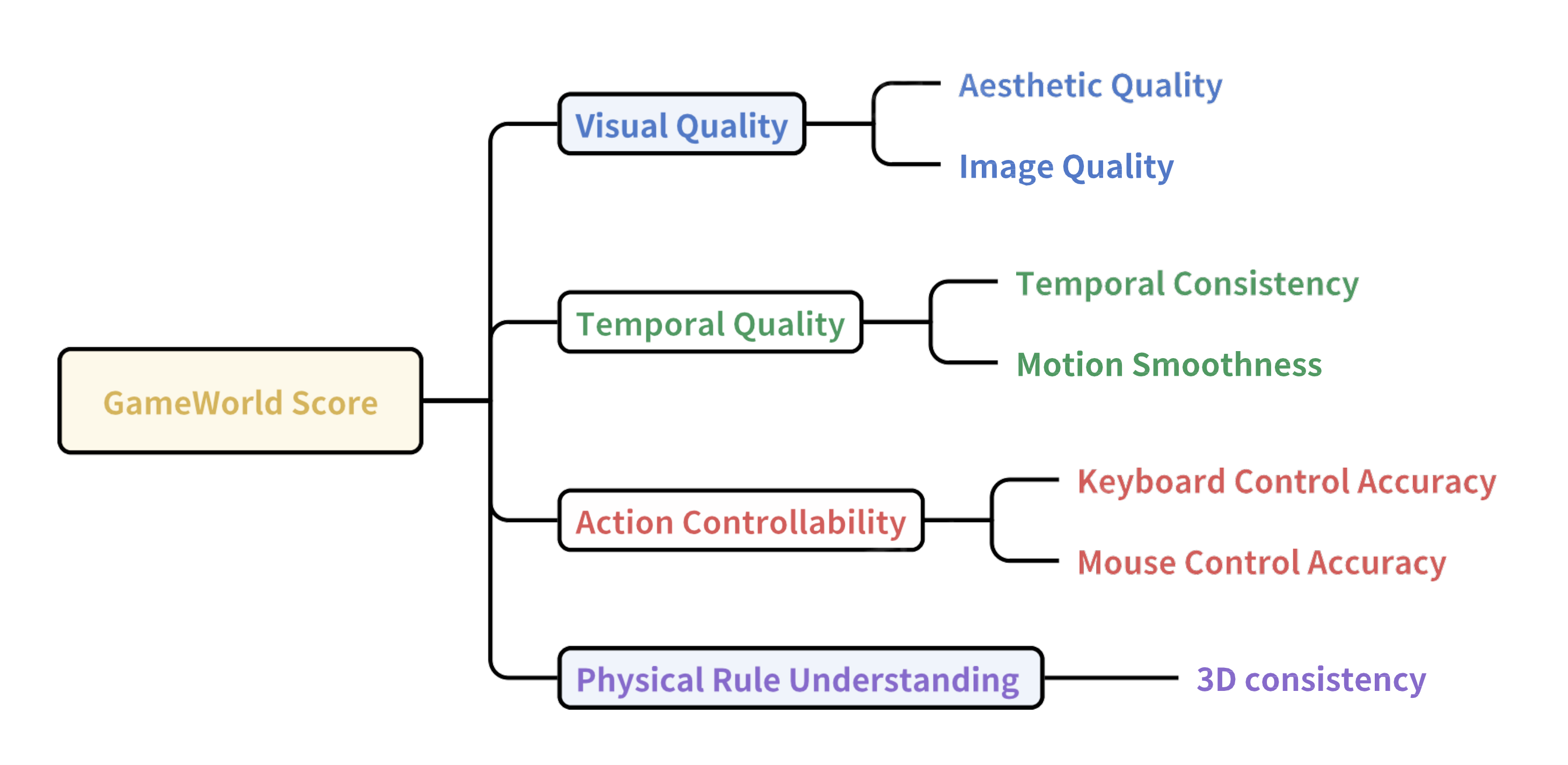
視覺質量:幀級質量衡量單個幀的優劣,忽略它們在時間上的相互作用。作者從兩個互補的視角分析每一幀:
- 美學質量。作者使用LAION美學預測器來評估單個幀的視覺吸引力,這是一個基于大規模人類美學偏好的訓練模型。該分數反映了多種因素的綜合,包括圖像構圖、色彩和諧、光影平衡、寫實性以及風格一致性。更高的美學分數表明與人類對視覺吸引力的判斷更一致,為像素級或結構化指標之外提供了補充視角。
- 圖像質量。為了評估每一幀的感知保真度,作者使用MUSIQ預測器來檢測低級視覺偽影,例如過曝、噪點、壓縮失真和模糊。MUSIQ是一個無參考圖像質量評估模型,基于SPAQ數據集 訓練而成,反映了多樣化的現實世界成像條件。這一指標為生成幀的清晰度、銳度和無偽影程度提供了定量衡量,是人類感知視覺質量的可靠代理。
時間質量:時間質量評估生成視頻在連續幀之間保持一致性和逼真度的能力。這一方面對于確保連貫的運動、避免閃爍偽影以及隨時間保持物體完整性至關重要。為了捕捉時間穩定性的不同方面,作者提出了兩個互補的維度:
- 時間一致性。為了評估背景和場景隨時間保持穩定的程度,作者計算從視頻序列的每一幀中提取的CLIP特征之間的成對相似性。CLIP嵌入能夠捕捉高層次的語義和視覺信息,使其適合于評估連續幀是否描繪了一個時間上連貫的場景。具體來說,作者計算相鄰幀之間的平均余弦相似度來量化一致性。更高的相似度表明模型在時間上保持了靜態元素(如背景布局),從而避免了常見的偽影,如閃爍、紋理漂移或突然的視覺變化。
- 運動流暢性。雖然時間一致性確保了幀之間外觀的穩定性,但它并沒有考慮到運動本身的質量。即使幀內容看起來連貫,仍然可能出現突然或抖動的過渡。為了解決這一問題,作者通過評估物體和攝像機的運動是否遵循物理上合理且時間上連續的軌跡來評估運動流暢性。作者利用視頻幀插值網絡所學習到的運動先驗來檢測不自然的動態。具體來說,作者將生成的視頻輸入到一個預訓練的插值模型中,并測量實際幀與從相鄰幀插值得到的幀之間的重建誤差。高插值精度意味著運動在幀之間流暢過渡,而較大的差異則表明存在不規律性,如抖動、卡頓或幀級不連續性。這種方法為判斷運動逼真度提供了一種代理,而無需密集的注釋。
動作可控性:該模塊旨在評估生成視頻對輸入動作條件的理解和遵循程度。理想情況下,生成視頻的視覺內容應逐幀響應給定的類似玩家的控制信號,反映交互式游戲環境中的行為。作者采用逆動力學模型(Inverse Dynamics Model, IDM)來評估可控性,通過從給定的視頻序列中推斷出潛在的動作條件。IDM在1962小時的《我的世界》游戲數據上訓練而成,在鍵盤預測方面達到了90.6%的準確率,鼠標運動回歸的R2分數為0.97,這使其成為從視頻中提取動作標簽的可靠代理。可控性通過將推斷出的動作與真實輸入進行比較來衡量,評估生成視頻對預期控制信號的反映是否準確。
- 鍵盤控制準確率:作者通過計算四個分組動作類別的精確度來評估鍵盤輸入的可控性:(向前、向后、無操作)、(向左、向右、無操作)、(攻擊、無操作)和(跳躍、無操作)。每個分組被視為一個多分類問題,其中的動作是互斥的。最終的鍵盤條件準確率是這四個分組的平均精確度。除了這個綜合得分外,作者還報告每個單獨動作(例如向前、向左、跳躍等)的每類精確度,這為分析模型對不同類型控制輸入的響應提供了更細致的分析。這使作者能夠分析模型對特定控制命令的遵循程度。
- 鼠標控制準確率:鼠標輸入影響攝像機的旋轉運動,這與鍵盤動作獨立建模。對于每個軸(x軸和y軸),當旋轉變化的絕對值超過預定義的閾值時,檢測到方向運動。這導致了九個類別:上、下、左、右、左上、右上、左下、右下和無操作。如果生成視頻中的運動方向與標記的條件匹配,則認為預測是正確的。最終準確率是所有正預測的精確度。
物理規則理解:為了評估模型對物理世界規則的理解,作者考察了其在幀間保持三維一致性的能力。
- 三維一致性。一個基于物理的模型應當能夠在時間上保持場景的幾何結構,即使存在紋理變化或光照改變。作者采用DROID-SLAM,一種密集的同步定位與建圖(SLAM)算法,來估計每一幀的像素級深度圖和攝像機姿態。隨后,利用估計的深度和姿態信息,計算連續幀中共同可見像素對之間的重投影誤差。由于DROID-SLAM本質上對外觀變化具有魯棒性,這一指標純粹關注場景的幾何穩定性。較低的重投影誤差表明更強的三維一致性,反映了模型在幀間維持穩定場景幾何結構和逼真攝像機運動的能力。因此,這一指標作為模型對物理規則(如物體恒存性、空間連續性和視角一致性結構)理解的一個間接但可靠的指標。
-
實驗
實驗目標。作者設計實驗旨在從多個維度全面評估所提出的模型。具體來說,作者希望回答以下四個問題:
- GameWorld Score基準測試:在視覺質量、時間質量、動作可控性和物理規則理解等關鍵維度上,作者的模型是否優于現有的最先進的開源《我的世界》模型?
- 動作可控性:作者的模型對各種用戶指令(尤其是鍵盤操作和鼠標移動)的響應程度如何?
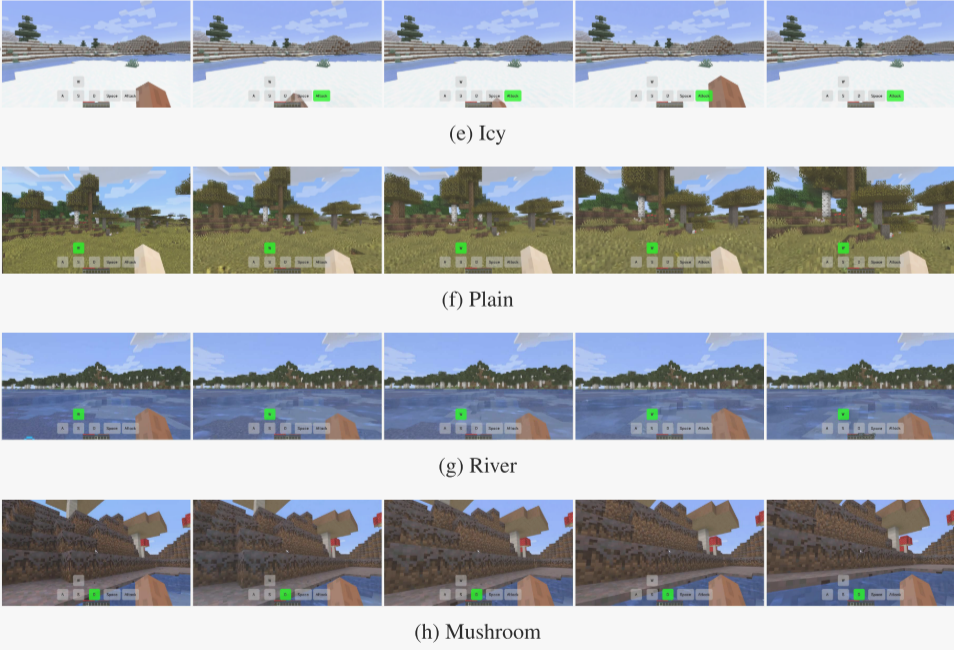
- 場景泛化能力:模型在多樣化的《我的世界》場景(例如森林、沙漠、冰雪、蘑菇)中的表現如何?
- 自回歸生成:在長時自回歸視頻生成過程中,作者的模型是否能夠保持連貫且可控的行為?
實驗細節。實驗在NVIDIA H800 GPU上進行,每個GPU的批量大小為1。作者采用bf16混合精度以及全分片數據并行(FSDP)策略以實現高效的大規模訓練。學習率設置為5×10??,訓練幀率為16 FPS,運動幀數為5幀。在推理階段,作者對參考圖像、運動幀和動作信號應用了無分類器引導(Classifier-Free Guidance, CFG)。CFG的尺度設置為6,采用流匹配采樣,采樣步數為50步,流匹配的偏移參數設置為15。
對比方法。為了建立堅實的對比基礎,作者選擇了兩個最具代表性的開源世界模型作為基線:OASIS和MineWorld。這兩項工作都是近期發布的,代碼和模型均公開可用,并且在《我的世界》世界生成方面展示了具有競爭力的結果。這些模型為評估視覺質量、時間動態和可控性提供了合理的基準,使作者能夠將所提出的方法與現有的公開系統進行對比。
評估指標。作者使用提出的GameWorld Score基準測試(參見第5節)來評估《我的世界》世界生成的性能。此外,為了補充標準定量指標(這些指標通常無法捕捉到感知質量的細微差異),作者還通過手動評分對所有基線輸出進行了人工評估。該評估涵蓋了四個關鍵方面:整體質量、可控性、視覺質量和時間一致性。評估以雙盲方式進行,由兩個獨立的標注團隊完成,兩個團隊均不知曉方法的身份,以確保公平性并盡量減少潛在偏見。
模型性能
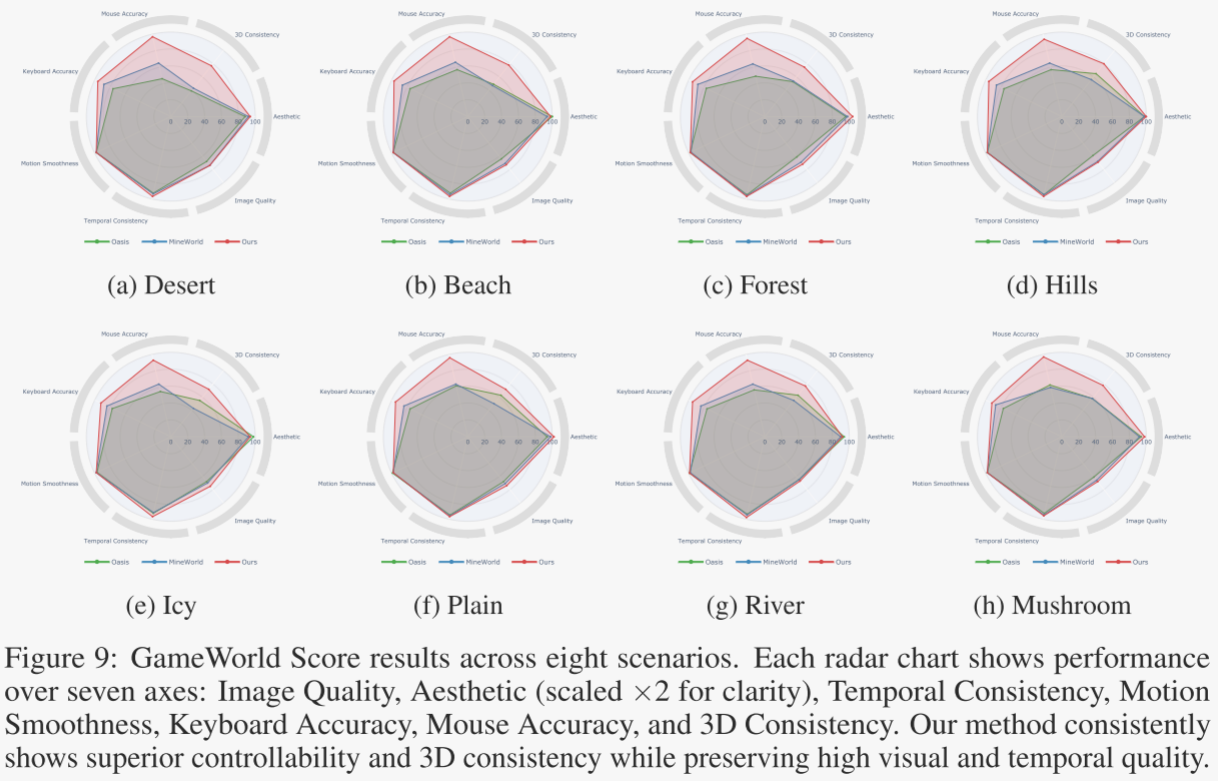
在第6.1節中,研究者們通過提出的 GameWorld Score 統一基準對Matrix-Game模型的性能進行了全面評估,并與現有的開源Minecraft世界生成模型(如Oasis和MineWorld)進行了對比。評估涵蓋了視覺質量、時間質量、動作可控性和物理規則理解等多個關鍵維度。
Matrix-Game在 GameWorld Score 基準的所有關鍵維度上均優于現有的開源Minecraft世界生成模型,特別是在動作可控性和3D一致性方面表現出色。該模型不僅在視覺質量和時間質量上保持了高水平,還在用戶交互和物理規則理解方面展現了顯著優勢。這些結果表明Matrix-Game能夠生成高質量、用戶可控且物理上合理的Minecraft世界,適合復雜的交互式世界生成任務。
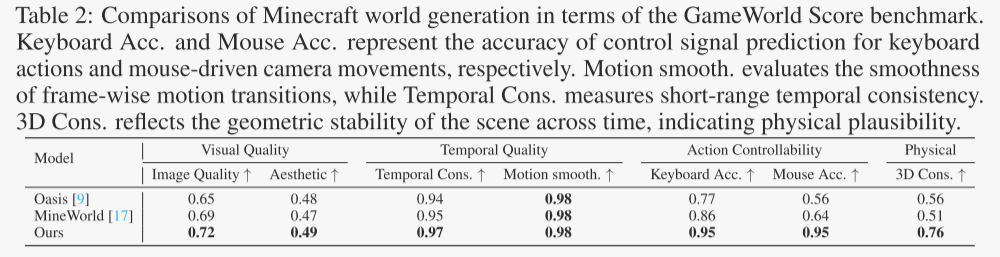
除了客觀的量化評估,研究者們還進行了雙盲人類評估,以驗證Matrix-Game在主觀質量上的優勢。人類評估結果顯示,Matrix-Game在 總體質量、可控性、視覺質量 和 時間連貫性 四個維度上均獲得了極高的勝率,分別為 96.3%、93.8%、98.2% 和 89.6%。這些結果進一步證實了Matrix-Game在生成逼真、可控且連貫的Minecraft世界方面的優越性。
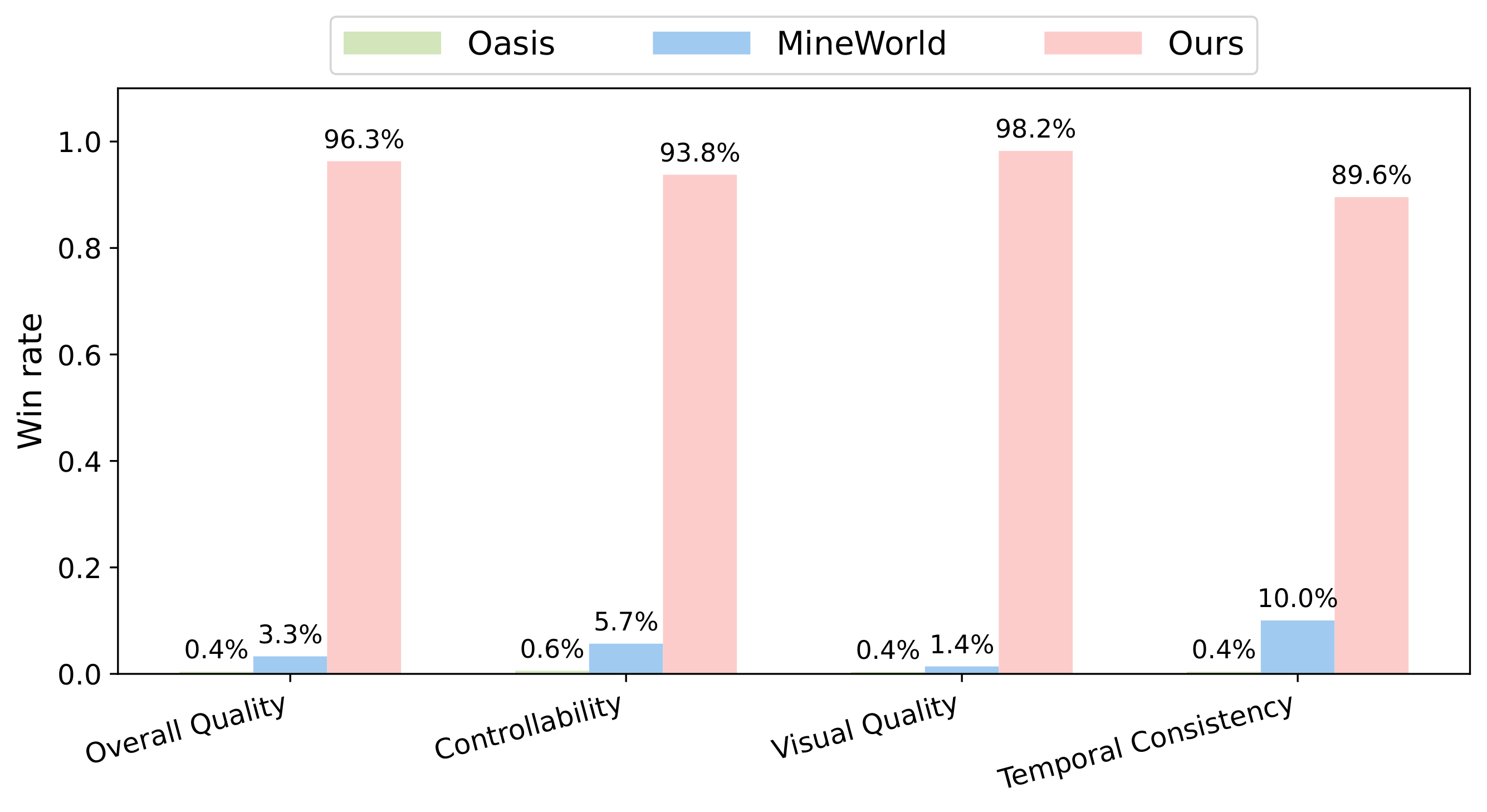
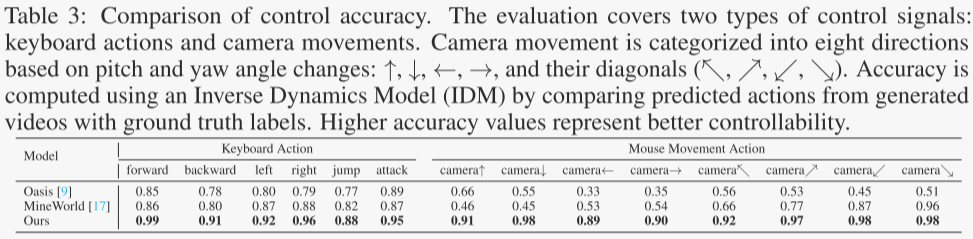
動作可控性評估
研究者們對Matrix-Game模型的動作可控性進行了詳細的評估,重點關注模型對用戶輸入(鍵盤動作和鼠標移動)的響應能力,并與現有的開源Minecraft世界生成模型(如Oasis和MineWorld)進行了對比。
Matrix-Game在動作可控性方面表現出色,能夠準確地將用戶輸入的動作信號轉化為生成視頻中的相應行為。與Oasis和MineWorld相比,Matrix-Game在鍵盤和鼠標動作的準確率上均取得了顯著提升,特別是在一些需要精細控制的動作(如“前進”和“右移”)上表現尤為突出。這些結果表明Matrix-Game在交互式世界生成任務中具有更強的用戶控制能力和更高的響應精度,能夠更好地滿足用戶對游戲世界生成的實時交互需求。
場景泛化能力評估
研究者們評估了Matrix-Game模型在多樣化Minecraft場景中的泛化能力,以驗證其在不同環境下的表現是否穩定且一致。這一部分的實驗旨在測試模型是否能夠適應多種不同的游戲場景,并在每個場景中保持高質量的生成效果。
Matrix-Game在多樣化Minecraft場景中展現出強大的泛化能力,無論是在視覺質量、時間連貫性、動作可控性還是物理規則理解方面,均優于現有的開源模型。該模型能夠適應不同環境的視覺和物理特性,生成高質量且符合用戶意圖的視頻內容。這些結果表明Matrix-Game不僅在單一場景中表現出色,還能在多種復雜場景中保持一致的高性能,適合用于多樣化的交互式世界生成任務。
長視頻生成能力評估
研究者們評估了Matrix-Game模型在長視頻生成任務中的表現,特別是其在多個視頻片段之間維持時間連貫性和響應用戶控制信號的能力。這一部分的實驗旨在驗證模型是否能夠在長序列中保持一致性和交互性。



失敗案例分析與討論
研究者們對Matrix-Game模型在某些特定場景下的失敗案例進行了分析,并討論了模型的局限性以及未來改進的方向。這一部分的分析旨在識別模型在當前實現中存在的問題,并提出可能的解決方案。
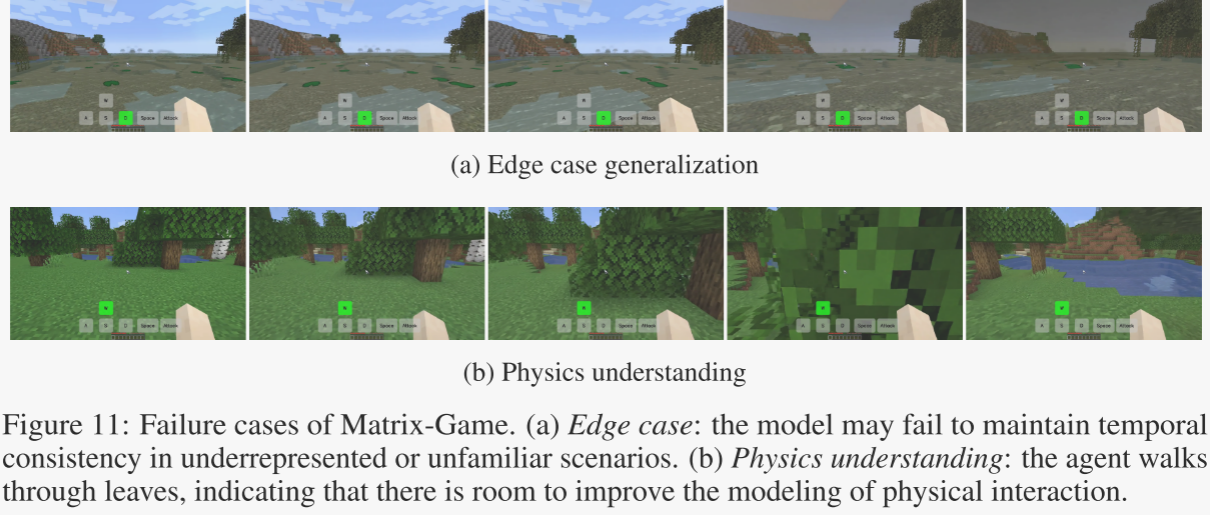
邊緣案例泛化問題:
-
問題描述:在一些視覺復雜或數據覆蓋不足的場景中(如罕見的生物群系或特殊地形),Matrix-Game可能會出現時間連貫性或空間一致性的問題。例如,模型可能無法準確地維持場景的幾何結構或響應用戶的控制信號。
-
原因分析:這些問題主要源于訓練數據的局限性。盡管Matrix-Game的數據集已經涵蓋了多種場景,但某些罕見或特殊的環境可能未被充分覆蓋,導致模型在這些場景下的表現不佳。
-
改進方向:研究者們計劃通過擴展訓練數據集,增加更多罕見場景的數據,并采用持續訓練策略,逐步適應新遇到的場景。
物理規則理解問題:
-
問題描述:盡管Matrix-Game在3D一致性方面表現出色,但在某些物理交互(如物體碰撞或地形穿越)的建模上仍有改進空間。例如,模型可能生成的角色會穿過樹葉等物體,顯示出對物理規則理解的不足。
-
原因分析:當前數據集中缺乏高保真度的物理監督數據,導致模型在這些復雜物理交互場景下的表現不夠準確。
-
改進方向:研究者們計劃通過增加更多物理規則相關的訓練數據,并設計更明確的環境約束建模,來提升模型對物理規則的理解能力。
-
-
3.代碼詳解
環境配置
配置conda環境后安裝必需包
pip install -r requirements.txt安裝apex:?GitHub - NVIDIA/apex: A PyTorch Extension: Tools for easy mixed precision and distributed training in Pytorch
安裝FlashAttention-3:https://github.com/Dao-AILab/flash-attention
然后運行即可推理:
bash run_inference.sh?-
inference_bench.py
這段代碼實現基于 MatrixGame 模型的圖像到視頻生成功能,
- main():主入口函數,設置 GPU 環境并啟動視頻生成流程。
- VideoGenerator 類負責初始化模型(VAE、DIT、文本編碼器)、處理輸入圖像與條件、調用模型生成視頻,并將結果保存為 MP4 文件。
首先來看模型初始化部分:
class VideoGenerator:def _init_models(self) -> None:"""初始化視頻生成所需的多個模型組件,并將它們移動到指定設備上。 Initialize all required models (VAE, text encoder, transformer)."""# 初始化 VAE Initialize VAEvae_path = self.args.vae_path self.vae = get_vae("matrixgame", vae_path, torch.float16)self.vae.requires_grad_(False)self.vae.eval()self.vae.enable_tiling()# 初始化 Transformer (DIT) Initialize DIT (Transformer)dit = MGVideoDiffusionTransformerI2V.from_pretrained(self.args.dit_path)dit.requires_grad_(False)dit.eval()# 初始化文本編碼器 Initialize text encodertextenc_path = self.args.textenc_pathweight_dtype = torch.bfloat16 if self.args.bfloat16 else torch.float32self.text_enc = get_text_enc('matrixgame', textenc_path, weight_dtype=weight_dtype, i2v_type='refiner')# 構建并移動 pipeline Move models to devicesself.pipeline = MatrixGameVideoPipeline(vae=self.vae.vae,text_encoder=self.text_enc,transformer=dit,scheduler=self.scheduler,).to(weight_dtype).to(self.device)在main()函數中會調用generate_videos()生成視頻,其代碼如下:
class VideoGenerator:def generate_videos(self) -> None:"""批量生成視頻,針對每種條件和圖像組合調用處理函數。 Main method to generate videos for all conditions."""# 創建輸出目錄 Create output directoryos.makedirs(self.args.output_path, exist_ok=True)# 加載預定義的條件列表 Load conditionsconditions = Bench_actions_76()print(f"Found {len(conditions)} conditions to process")# 加載輸入圖像路徑 Load sample imagesroot_dir = self.args.image_pathimage_paths = self._load_images(root_dir)if not image_paths:print("No images found in the specified directory")return# 對每個條件和每張圖像依次調用 _process_condition 方法進行處理 Process each conditionfor idx, condition in enumerate(conditions):for image_path in image_paths:print(f"Processing condition {idx+1}/{len(conditions)} with image {os.path.basename(image_path)}")self._process_condition(condition, image_path)其中,Bench_actions_76()如下,該函數生成用于測試的復合動作及其對應的鍵盤和鼠標輸入數據:
- 定義基礎動作(前進、后退等)和攝像頭方向;
- 構建組合動作列表 actions_to_test;
- 為每個動作創建65組輸入數據,其中包含鍵盤按鍵狀態和鼠標移動向量;
- 返回包含所有動作及其對應輸入數據的列表。
def Bench_actions_76():# 1.定義基礎動作(前進、后退等)和攝像頭方向actions_single_action = ["forward","back","left","right","jump","attack"]actions_double_action = ["forward_attack","back_attack","left_attack","right_attack","jump_attack","forward_left","forward_right","back_left","back_right","forward_jump","back_jump","left_jump","right_jump",]actions_single_camera = [ "camera_up","camera_down","camera_l","camera_r","camera_ur","camera_ul","camera_dl","camera_dr"]# 2.構建組合動作列表actions_to_test = actions_double_action # 構建組合動作列表for action in actions_single_action:for camera in actions_single_camera:double_action = f"{action}_{camera}"actions_to_test.append(double_action)print("length of actions: ", len(actions_to_test))base_action = actions_single_action + actions_single_cameraKEYBOARD_IDX = {"forward": 0, "back": 1, "left": 2, "right": 3, "jump": 4, "attack": 5}CAM_VALUE = 0.05CAMERA_VALUE_MAP = {"camera_up": [CAM_VALUE, 0],"camera_down": [-CAM_VALUE, 0],"camera_l": [0, -CAM_VALUE],"camera_r": [0, CAM_VALUE],"camera_ur": [CAM_VALUE, CAM_VALUE],"camera_ul": [CAM_VALUE, -CAM_VALUE],"camera_dr": [-CAM_VALUE, CAM_VALUE],"camera_dl": [-CAM_VALUE, -CAM_VALUE],}# 3.為每個動作創建65組輸入數據,其中包含鍵盤按鍵狀態和鼠標移動向量num_samples_per_action = 65data = []for action_name in actions_to_test:# 前,后,左,右,跳躍,攻擊keyboard_condition = [[0, 0, 0, 0, 0, 0] for _ in range(num_samples_per_action)] mouse_condition = [[0,0] for _ in range(num_samples_per_action)] for sub_act in base_action:if not sub_act in action_name: # 只處理action_name包含的動作continueprint(f"action name: {action_name} sub_act: {sub_act}")if sub_act in CAMERA_VALUE_MAP: # camera_dr 如果是攝像頭動作,則設置鼠標輸入mouse_condition = [CAMERA_VALUE_MAP[sub_act]for _ in range(num_samples_per_action)]elif sub_act == "attack": # 如果是攝像頭動作,則設置鼠標輸入# to do 只有幀數 (idx % 16 >= 8) & (idx % 16 < 16)才為1for idx in range(num_samples_per_action):if idx % 8 == 0:keyboard_condition[idx][KEYBOARD_IDX["attack"]] = 1elif sub_act in KEYBOARD_IDX: # 其他鍵盤動作則設置對應鍵位為1col = KEYBOARD_IDX[sub_act]for row in keyboard_condition:row[col] = 1data.append({"action_name": action_name,"keyboard_condition": keyboard_condition,"mouse_condition": mouse_condition})return data # 返回包含所有動作及其對應輸入數據的列表其中_process_condition()如下,該函數根據給定的鍵盤和鼠標條件,以指定圖像為起點,生成一段帶有動作模擬的視頻,并保存為MP4文件。具體流程如下:
- 準備輸入條件:將鍵盤和鼠標動作轉換為PyTorch張量,并移動到指定設備(如GPU)。
- 圖像預處理:加載圖像并調整大小;使用VideoProcessor進行進一步處理;若配置了前置幀,則復制初始幀作為歷史幀輸入。
- 視頻生成:調用pipeline模型,在無梯度模式下生成視頻序列。
- 結果后處理與保存:將生成的視頻張量轉為圖像數組,提取配置信息,構造輸出路徑,并調用process_video函數保存視頻文件。
class VideoGenerator:def _process_condition(self, condition: Dict, image_path: str) -> None:"""根據給定的鍵盤和鼠標條件,以指定圖像為起點,生成一段帶有動作模擬的視頻,并保存為MP4文件。Process a single condition and generate video.Args:condition: Condition dictionary containing action and conditionsimage_path: Path to input image"""# 1.將鍵盤和鼠標動作轉換為PyTorch張量,并移動到指定設備(如GPU) Prepare conditionskeyboard_condition = torch.tensor(condition['keyboard_condition'], dtype=torch.float32).unsqueeze(0)mouse_condition = torch.tensor(condition['mouse_condition'], dtype=torch.float32).unsqueeze(0)# Move to devicekeyboard_condition = keyboard_condition.to(torch.bfloat16 if self.args.bfloat16 else torch.float16).to(self.device)mouse_condition = mouse_condition.to(torch.bfloat16 if self.args.bfloat16 else torch.float16).to(self.device)# 2.使用VideoProcessor進行進一步處理 Load and preprocess imageimage = Image.open(image_path).convert("RGB")new_width, new_height = self.args.resolutioninitial_image = self._resize_and_crop_image(image, (new_width, new_height)) # 調整大小semantic_image = initial_imagevae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)video_processor = VideoProcessor(vae_scale_factor=vae_scale_factor)initial_image = video_processor.preprocess(initial_image, height=new_height, width=new_width)if self.args.num_pre_frames > 0:past_frames = initial_image.repeat(self.args.num_pre_frames, 1, 1, 1)initial_image = torch.cat([initial_image, past_frames], dim=0)# 3.調用pipeline模型,在無梯度模式下生成視頻序列。 Generate videowith torch.no_grad():video = self.pipeline(height=new_height,width=new_width,video_length=self.video_length,mouse_condition=mouse_condition,keyboard_condition=keyboard_condition,initial_image=initial_image,num_inference_steps=self.args.inference_steps if hasattr(self.args, 'inference_steps') else 50,guidance_scale=self.guidance_scale,embedded_guidance_scale=None,data_type="video",vae_ver='884-16c-hy',enable_tiling=True,generator=torch.Generator(device="cuda").manual_seed(42),i2v_type='refiner',args=self.args,semantic_images=semantic_image).videos[0]# 4.結果后處理與保存 Save videoimg_tensors = rearrange(video.permute(1, 0, 2, 3) * 255, 't c h w -> t h w c').contiguous()img_tensors = img_tensors.cpu().numpy().astype(np.uint8)config = ( # 從 keyboard_condition 和 mouse_condition 中提取 CPU 上的 NumPy 格式配置數據keyboard_condition[0].float().cpu().numpy(),mouse_condition[0].float().cpu().numpy())# 輸出路徑構建action_name = condition['action_name']output_filename = f"{os.path.splitext(os.path.basename(image_path))[0]}_{action_name}.mp4"output_path = os.path.join(self.args.output_path, output_filename)process_video( # 調用視頻生成函數img_tensors,output_path,config,mouse_icon_path=self.args.mouse_icon_path,mouse_scale=self.args.mouse_scale,mouse_rotation=self.args.mouse_rotation,fps=self.args.fps)-
Pipeline
MatrixGameVideoPipeline類的__call__()函數是代碼的核心部分,該函數是生成視頻的核心方法,主要完成以下功能:
- 參數檢查與初始化:校驗輸入參數并設置默認值;
- 文本編碼:將提示詞(prompt)和負向提示詞(negative prompt)編碼為嵌入向量;
- 時間步準備:根據調度器配置推理步數和時間步;
- 潛變量初始化:基于初始圖像或隨機噪聲構建潛空間表示;
- 去噪循環:迭代地使用Transformer模型預測噪聲,并通過調度器更新潛變量;
- 解碼輸出:將最終潛變量解碼為視頻幀;
- 結果返回:按指定格式返回生成的視頻。
class MatrixGameVideoPipeline(DiffusionPipeline):def __call__():...# 1. 參數檢查與初始化 Check inputs. Raise error if not correctself.check_inputs(prompt,height,width,video_length,callback_steps,negative_prompt,prompt_embeds,negative_prompt_embeds,callback_on_step_end_tensor_inputs,vae_ver=vae_ver,)self._guidance_scale = guidance_scaleself._guidance_rescale = guidance_rescaleself._clip_skip = clip_skipself._cross_attention_kwargs = cross_attention_kwargsself._interrupt = Falseself.args = args# 2. Define call parametersif prompt is not None and isinstance(prompt, str):batch_size = 1elif prompt is not None and isinstance(prompt, list):batch_size = len(prompt)else:batch_size = prompt_embeds.shape[0]device = self._execution_device# 3. 文本編碼 Encode input promptlora_scale = (self.cross_attention_kwargs.get("scale", None)if self.cross_attention_kwargs is not Noneelse None)n_tokens = (height//16 * width // 16 * ((video_length-1)//4+1))if semantic_images is None:if args.num_pre_frames > 0: semantic_images = initial_image[:1,...] #semantic_images torch.Size([1, 3, 352, 640]) ## print("semantic_images", semantic_images.shape) semantic_images = (semantic_images / 2 + 0.5).clamp(0, 1).cpu().permute(0, 2, 3, 1).float().numpy() # b c h w -> b h w csemantic_images = numpy_to_pil(semantic_images)else:semantic_images = initial_image(prompt_embeds,negative_prompt_embeds,prompt_mask,negative_prompt_mask,) = self.encode_prompt(prompt,device,num_videos_per_prompt,self.do_classifier_free_guidance,negative_prompt,prompt_embeds=prompt_embeds,attention_mask=attention_mask,negative_prompt_embeds=negative_prompt_embeds,negative_attention_mask=negative_attention_mask,lora_scale=lora_scale,clip_skip=self.clip_skip,data_type=data_type,semantic_images=semantic_images)prompt_embeds, prompt_embeds_2 = prompt_embedsnegative_prompt_embeds, negative_prompt_embeds_2 = negative_prompt_embedsprompt_mask, prompt_mask_2 = prompt_masknegative_prompt_mask, negative_prompt_mask_2 = negative_prompt_maskprompt_embeds = prompt_embeds[:,:144, ...] # 144 is the number of img tokens after MLLMprompt_mask = prompt_mask[:,:144, ...]negative_prompt_embeds = negative_prompt_embeds[:,:144, ...]negative_prompt_mask = negative_prompt_mask[:,:144, ...] # For classifier free guidance, we need to do two forward passes.# Here we concatenate the unconditional and text embeddings into a single batch# to avoid doing two forward passesif self.do_classifier_free_guidance:prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])if prompt_mask is not None:prompt_mask = torch.cat([negative_prompt_mask, prompt_mask])if prompt_embeds_2 is not None:prompt_embeds_2 = torch.cat([negative_prompt_embeds_2, prompt_embeds_2])if prompt_mask_2 is not None:prompt_mask_2 = torch.cat([negative_prompt_mask_2, prompt_mask_2])# 4. 時間步初始化 Prepare timestepsextra_set_timesteps_kwargs = self.prepare_extra_func_kwargs(self.scheduler.set_timesteps, {"n_tokens": n_tokens})timesteps, num_inference_steps = retrieve_timesteps(self.scheduler,num_inference_steps,device,timesteps,sigmas,**extra_set_timesteps_kwargs,)if "884" in vae_ver:video_length = (video_length - 1) // 4 + 1elif "888" in vae_ver:video_length = (video_length - 1) // 8 + 1else:video_length = video_lengthif initial_image is not None:initial_image = initial_image.to(device, dtype=prompt_embeds.dtype)if i2v_type == 'concat':num_channels_latents = self.transformer.config.in_channels // 2else:num_channels_latents = self.transformer.config.in_channels // 2else:num_channels_latents = self.transformer.config.in_channels# 5. 潛變量初始化 Prepare latent variablesif args.num_pre_frames > 0:latents, image_latents, concat_latents = self.prepare_latents(initial_image,batch_size * num_videos_per_prompt,num_channels_latents,height,width,video_length,prompt_embeds.dtype,device,generator,latents,i2v_type, )else: latents, image_latents = self.prepare_latents(initial_image,batch_size * num_videos_per_prompt,num_channels_latents,height,width,video_length,prompt_embeds.dtype,device,generator,latents,i2v_type, )# 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipelineextra_step_kwargs = self.prepare_extra_func_kwargs(self.scheduler.step,{"generator": generator, "eta": eta},)target_dtype = self.dtypeautocast_enabled = target_dtype != torch.float32vae_dtype = self.dtypevae_autocast_enabled = vae_dtype != torch.float32# 7. 去噪循環 Denoising loopnum_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.orderself._num_timesteps = len(timesteps)if args.num_pre_frames > 0: concat_latents = (torch.cat([torch.zeros_like(concat_latents), concat_latents]) if self.do_classifier_free_guidanceelse concat_latents) # if is_progress_bar:with self.progress_bar(total=num_inference_steps) as progress_bar:for i, t in enumerate(timesteps):if self.interrupt:continue# expand the latents if we are doing classifier free guidancelatent_model_input = (torch.cat([latents] * 2)if self.do_classifier_free_guidanceelse latents) latent_model_input = self.scheduler.scale_model_input( #do nothinglatent_model_input, t)if image_latents is not None:latent_image_input = torch.cat([image_latents] * 2) if self.do_classifier_free_guidance else image_latentsif i2v_type == 'concat':latent_model_input = torch.cat([latent_model_input, latent_image_input], dim=1)else:if args.num_pre_frames > 0: num_pre = latent_image_input.shape[2]#print("latent_image_input", latent_image_input.shape) #latent_image_input torch.Size([2, 16, 1, 44, 80])#print("latent_model_input", latent_model_input.shape) #latent_model_input torch.Size([2, 16, 5, 44, 80])#print("concat_latents", concat_latents.shape) #concat_latents torch.Size([1, 17, 5, 44, 80])latent_model_input = torch.cat([latent_image_input, latent_model_input[:,:,num_pre:,...]], dim=2)latent_model_input = torch.cat([latent_model_input, concat_latents], dim=1) else:num_pre = latent_image_input.shape[2] # 如果多幀past frame需要修改latent_model_input = torch.cat([latent_image_input, latent_model_input[:,:,num_pre:,...]], dim=2)t_expand = t.repeat(latent_model_input.shape[0])guidance_expand = (torch.tensor([embedded_guidance_scale] * latent_model_input.shape[0],dtype=torch.float32,device=device,).to(target_dtype)* 1000.0if embedded_guidance_scale is not Noneelse None)if mouse_condition is not None:mouse_condition_input = (torch.cat([torch.full_like(mouse_condition, 1.0), mouse_condition])if self.do_classifier_free_guidanceelse mouse_condition)# torch.zeros_like(mouse_condition)# torch.full_like(mouse_condition, 999.0)keyboard_condition_input = (torch.cat([torch.full_like(keyboard_condition, -1.0), keyboard_condition])if self.do_classifier_free_guidanceelse keyboard_condition)#torch.full_like(keyboard_condition, -1.0)#torch.zeros_like(keyboard_condition)# mouse_condition = torch.full_like(mouse_condition, 999.0)# keyboard 是 6維,改成 -1# keyboard_condition = torch.full_like(keyboard_condition, -1.0)else:mouse_condition_input = Nonekeyboard_condition_input = None# predict the noise residualwith torch.autocast(device_type="cuda", dtype=target_dtype, enabled=autocast_enabled):# import ipdb;ipdb.set_trace()noise_pred = self.transformer( # For an input image (129, 192, 336) (1, 256, 256)hidden_states = latent_model_input, # [2, 16, 33, 24, 42]timestep = t_expand, # [2]encoder_hidden_states=(prompt_embeds, prompt_embeds_2), # [2, 256, 4096]encoder_attention_mask=(prompt_mask, prompt_mask_2), # [2, 256]guidance=guidance_expand,return_dict=True,mouse_condition = mouse_condition_input,keyboard_condition = keyboard_condition_input,)["x"]# perform guidanceif self.do_classifier_free_guidance:noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:# Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdfnoise_pred = rescale_noise_cfg(noise_pred,noise_pred_text,guidance_rescale=self.guidance_rescale,)# compute the previous noisy sample x_t -> x_t-1if i2v_type == "concat":latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]else:latents = self.scheduler.step(noise_pred[:,:,1:,...], t, latents[:,:,1:,...], **extra_step_kwargs, return_dict=False)[0]latents = torch.concat([image_latents, latents], dim=2)if callback_on_step_end is not None:callback_kwargs = {}for k in callback_on_step_end_tensor_inputs:callback_kwargs[k] = locals()[k]callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)latents = callback_outputs.pop("latents", latents)prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)negative_prompt_embeds = callback_outputs.pop("negative_prompt_embeds", negative_prompt_embeds)# call the callback, if providedif i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):if progress_bar is not None:progress_bar.update()if callback is not None and i % callback_steps == 0:step_idx = i // getattr(self.scheduler, "order", 1)callback(step_idx, t, latents)# 解碼輸出:將最終潛變量解碼為視頻幀;if not output_type == "latent":expand_temporal_dim = Falseif len(latents.shape) == 4:if isinstance(self.vae, AutoencoderKLCausal3D):latents = latents.unsqueeze(2)expand_temporal_dim = Trueelif len(latents.shape) == 5:passelse:raise ValueError(f"Only support latents with shape (b, c, h, w) or (b, c, f, h, w), but got {latents.shape}.")if (hasattr(self.vae.config, "shift_factor")and self.vae.config.shift_factor):latents = (latents / self.vae.config.scaling_factor+ self.vae.config.shift_factor)else:latents = latents / self.vae.config.scaling_factorwith torch.autocast(device_type="cuda", dtype=vae_dtype, enabled=vae_autocast_enabled):if enable_tiling:self.vae.enable_tiling()image = self.vae.decode(latents, return_dict=False, generator=generator)[0]else:image = self.vae.decode(latents, return_dict=False, generator=generator)[0]if expand_temporal_dim or image.shape[2] == 1:image = image.squeeze(2)else:image = latentsimage = (image / 2 + 0.5).clamp(0, 1)# we always cast to float32 as this does not cause significant overhead and is compatible with bfloa16image = image.cpu().float()# if i2v_type == "concat":# image = image[:,:,4:,...]# Offload all modelsself.maybe_free_model_hooks()if not return_dict:return imagereturn MatrixGameVideoPipelineOutput(videos=image)其中文本編碼部分如下,這段代碼主要完成以下功能:
- LoRA縮放參數處理:從cross_attention_kwargs中獲取LoRA的縮放參數scale;
- 計算token數量:根據輸入視頻的高、寬和幀數計算圖像token總數;
- 語義圖像處理:若未提供semantic_images,則從初始圖像提取并預處理為語義圖像;
- 提示編碼:調用encode_prompt方法對文本提示進行編碼,支持無分類器引導(CFG);
- 嵌入裁剪:限制prompt embeddings的長度為144個tokens;
- 合并正負嵌入:在無分類器引導時,將負向和正向嵌入拼接以減少前向計算次數。
# 3. 文本編碼 Encode input prompt
lora_scale = ( # LoRA縮放參數處理self.cross_attention_kwargs.get("scale", None)if self.cross_attention_kwargs is not Noneelse None
)
n_tokens = (height//16 * width // 16 * ((video_length-1)//4+1)) # 計算token數量:根據輸入視頻的高、寬和幀數計算圖像token總數if semantic_images is None: # 若未提供semantic_images,則從初始圖像提取并預處理為語義圖像if args.num_pre_frames > 0: semantic_images = initial_image[:1,...] #semantic_images torch.Size([1, 3, 352, 640]) ## print("semantic_images", semantic_images.shape) semantic_images = (semantic_images / 2 + 0.5).clamp(0, 1).cpu().permute(0, 2, 3, 1).float().numpy() # b c h w -> b h w csemantic_images = numpy_to_pil(semantic_images)else:semantic_images = initial_image(prompt_embeds,negative_prompt_embeds,prompt_mask,negative_prompt_mask,
) = self.encode_prompt( # 調用encode_prompt方法對文本提示進行編碼prompt,device,num_videos_per_prompt,self.do_classifier_free_guidance,negative_prompt,prompt_embeds=prompt_embeds,attention_mask=attention_mask,negative_prompt_embeds=negative_prompt_embeds,negative_attention_mask=negative_attention_mask,lora_scale=lora_scale,clip_skip=self.clip_skip,data_type=data_type,semantic_images=semantic_images
)
prompt_embeds, prompt_embeds_2 = prompt_embeds
negative_prompt_embeds, negative_prompt_embeds_2 = negative_prompt_embeds
prompt_mask, prompt_mask_2 = prompt_mask
negative_prompt_mask, negative_prompt_mask_2 = negative_prompt_mask
prompt_embeds = prompt_embeds[:,:144, ...] # 嵌入裁剪:限制prompt embeddings的長度為144個tokens; 144 is the number of img tokens after MLLM
prompt_mask = prompt_mask[:,:144, ...]
negative_prompt_embeds = negative_prompt_embeds[:,:144, ...]
negative_prompt_mask = negative_prompt_mask[:,:144, ...] # For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
if self.do_classifier_free_guidance: # 在無分類器引導時,將負向和正向嵌入拼接以減少前向計算次數。prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])if prompt_mask is not None:prompt_mask = torch.cat([negative_prompt_mask, prompt_mask])if prompt_embeds_2 is not None:prompt_embeds_2 = torch.cat([negative_prompt_embeds_2, prompt_embeds_2])if prompt_mask_2 is not None:prompt_mask_2 = torch.cat([negative_prompt_mask_2, prompt_mask_2])其中時間步編碼部分如下,該段代碼主要完成以下功能:
- 設置推理步數與時間步:通過 prepare_extra_func_kwargs 和 retrieve_timesteps 配置調度器的時間步參數,支持自定義額外參數(如 n_tokens)。
- 視頻長度調整:根據使用的 VAE 版本("884" 或 "888"),對輸入視頻長度進行下采樣處理。
- 初始圖像處理:若提供初始圖像,則將其移動到指定設備和數據類型;根據圖像到視頻模式(i2v_type)決定潛在空間通道數。
- 默認通道數設置:若無初始圖像,則直接使用模型配置中的潛在空間通道數。
# 4. 時間步初始化 Prepare timesteps
extra_set_timesteps_kwargs = self.prepare_extra_func_kwargs( # 設置推理步數與時間步self.scheduler.set_timesteps, {"n_tokens": n_tokens}
)
timesteps, num_inference_steps = retrieve_timesteps( # 配置調度器的時間步參數self.scheduler, num_inference_steps,device,timesteps,sigmas,**extra_set_timesteps_kwargs,
)if "884" in vae_ver: # 視頻長度調整:根據使用的 VAE 版本("884" 或 "888"),對輸入視頻長度進行下采樣處理。video_length = (video_length - 1) // 4 + 1
elif "888" in vae_ver:video_length = (video_length - 1) // 8 + 1
else:video_length = video_lengthif initial_image is not None: # 若提供初始圖像,則將其移動到指定設備和數據類型initial_image = initial_image.to(device, dtype=prompt_embeds.dtype)if i2v_type == 'concat': # 根據圖像到視頻模式(i2v_type)決定潛在空間通道數num_channels_latents = self.transformer.config.in_channels // 2else:num_channels_latents = self.transformer.config.in_channels // 2
else:num_channels_latents = self.transformer.config.in_channels # 若無初始圖像,則直接使用模型配置中的潛在空間通道數。該段代碼實現了一個基于擴散模型的視頻生成過程,主要功能如下:
- 初始化與輸入處理:根據時間步timesteps和調度器設置進行推理步數計算,并處理初始隱狀態(包括無分類器引導時的輸入擴展)。
- 條件輸入構建:對圖像、鼠標、鍵盤等多模態條件信息進行拼接或填充處理,支持無分類器引導(CFG)。
- 噪聲預測:使用transformer模型預測當前時間步的噪聲殘差。
- 引導調整:應用分類器自由引導(CFG)和噪聲重縮放(rescale)策略優化預測結果。
- 去噪更新:調用scheduler.step更新隱變量latents,逐步去除噪聲。
- 回調機制:支持每一步結束后的回調函數處理(如進度條更新、用戶自定義操作)
# 7. 去噪循環 Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order # 計算預熱步數 num_warmup_steps,用于控制推理過程中跳過初始階段的步數;
self._num_timesteps = len(timesteps) # 設置當前時間步總數 _num_timesteps
if args.num_pre_frames > 0: # 如果有前置幀(args.num_pre_frames > 0),則在進行無分類器引導(classifier-free guidance)時,將 concat_latents 與零張量拼接,用于生成視頻起始幀。concat_latents = (torch.cat([torch.zeros_like(concat_latents), concat_latents]) if self.do_classifier_free_guidanceelse concat_latents)
# if is_progress_bar:
with self.progress_bar(total=num_inference_steps) as progress_bar:for i, t in enumerate(timesteps):if self.interrupt:continue# expand the latents if we are doing classifier free guidancelatent_model_input = ( # 條件輸入構建torch.cat([latents] * 2)if self.do_classifier_free_guidanceelse latents) latent_model_input = self.scheduler.scale_model_input( #do nothinglatent_model_input, t)if image_latents is not None: # 圖像潛在表示的拼接方式:根據i2v_type選擇是否將圖像潛變量與模型輸入在通道或時間維度拼接; latent_image_input = torch.cat([image_latents] * 2) if self.do_classifier_free_guidance else image_latents # 無分類器引導(CFG)if i2v_type == 'concat':latent_model_input = torch.cat([latent_model_input, latent_image_input], dim=1)else:if args.num_pre_frames > 0: num_pre = latent_image_input.shape[2]#print("latent_image_input", latent_image_input.shape) #latent_image_input torch.Size([2, 16, 1, 44, 80])#print("latent_model_input", latent_model_input.shape) #latent_model_input torch.Size([2, 16, 5, 44, 80])#print("concat_latents", concat_latents.shape) #concat_latents torch.Size([1, 17, 5, 44, 80])latent_model_input = torch.cat([latent_image_input, latent_model_input[:,:,num_pre:,...]], dim=2)latent_model_input = torch.cat([latent_model_input, concat_latents], dim=1) else:num_pre = latent_image_input.shape[2] # 如果多幀past frame需要修改latent_model_input = torch.cat([latent_image_input, latent_model_input[:,:,num_pre:,...]], dim=2)t_expand = t.repeat(latent_model_input.shape[0])guidance_expand = (torch.tensor([embedded_guidance_scale] * latent_model_input.shape[0],dtype=torch.float32,device=device,).to(target_dtype)* 1000.0if embedded_guidance_scale is not Noneelse None)if mouse_condition is not None: # 鼠標、鍵盤條件輸入處理mouse_condition_input = (torch.cat([torch.full_like(mouse_condition, 1.0), mouse_condition])if self.do_classifier_free_guidanceelse mouse_condition)# torch.zeros_like(mouse_condition)# torch.full_like(mouse_condition, 999.0)keyboard_condition_input = (torch.cat([torch.full_like(keyboard_condition, -1.0), keyboard_condition])if self.do_classifier_free_guidanceelse keyboard_condition)#torch.full_like(keyboard_condition, -1.0)#torch.zeros_like(keyboard_condition)# mouse_condition = torch.full_like(mouse_condition, 999.0)# keyboard 是 6維,改成 -1# keyboard_condition = torch.full_like(keyboard_condition, -1.0)else:mouse_condition_input = Nonekeyboard_condition_input = None# 噪聲預測:使用transformer模型預測當前時間步的噪聲殘差。 predict the noise residualwith torch.autocast(device_type="cuda", dtype=target_dtype, enabled=autocast_enabled):# import ipdb;ipdb.set_trace()noise_pred = self.transformer( # For an input image (129, 192, 336) (1, 256, 256)hidden_states = latent_model_input, # [2, 16, 33, 24, 42]timestep = t_expand, # [2]encoder_hidden_states=(prompt_embeds, prompt_embeds_2), # [2, 256, 4096]encoder_attention_mask=(prompt_mask, prompt_mask_2), # [2, 256]guidance=guidance_expand,return_dict=True,mouse_condition = mouse_condition_input,keyboard_condition = keyboard_condition_input,)["x"]# perform guidanceif self.do_classifier_free_guidance:noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)if self.do_classifier_free_guidance and self.guidance_rescale > 0.0: # 無分類器引導(CFG)# Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdfnoise_pred = rescale_noise_cfg(noise_pred,noise_pred_text,guidance_rescale=self.guidance_rescale,)# 去噪更新:調用scheduler.step更新隱變量latents,逐步去除噪聲。 compute the previous noisy sample x_t -> x_t-1if i2v_type == "concat":latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]else:latents = self.scheduler.step(noise_pred[:,:,1:,...], t, latents[:,:,1:,...], **extra_step_kwargs, return_dict=False)[0]latents = torch.concat([image_latents, latents], dim=2)if callback_on_step_end is not None:callback_kwargs = {}for k in callback_on_step_end_tensor_inputs:callback_kwargs[k] = locals()[k]callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)latents = callback_outputs.pop("latents", latents)prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)negative_prompt_embeds = callback_outputs.pop("negative_prompt_embeds", negative_prompt_embeds)# 回調機制:支持每一步結束后的回調函數處理 call the callback, if providedif i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):if progress_bar is not None:progress_bar.update()if callback is not None and i % callback_steps == 0:step_idx = i // getattr(self.scheduler, "order", 1)callback(step_idx, t, latents)這段代碼的作用是將潛在變量latent轉換為視頻幀
# 解碼輸出:將最終潛變量解碼為視頻幀;
if not output_type == "latent":expand_temporal_dim = Falseif len(latents.shape) == 4:if isinstance(self.vae, AutoencoderKLCausal3D):latents = latents.unsqueeze(2)expand_temporal_dim = Trueelif len(latents.shape) == 5:passelse:raise ValueError(f"Only support latents with shape (b, c, h, w) or (b, c, f, h, w), but got {latents.shape}.")if (hasattr(self.vae.config, "shift_factor")and self.vae.config.shift_factor):latents = ( # 對latents應用VAE配置的縮放和平移變換latents / self.vae.config.scaling_factor+ self.vae.config.shift_factor)else:latents = latents / self.vae.config.scaling_factorwith torch.autocast( # 使用VAE解碼,支持顯存優化的autocast和tilingdevice_type="cuda", dtype=vae_dtype, enabled=vae_autocast_enabled):if enable_tiling:self.vae.enable_tiling()image = self.vae.decode(latents, return_dict=False, generator=generator)[0]else:image = self.vae.decode(latents, return_dict=False, generator=generator)[0]if expand_temporal_dim or image.shape[2] == 1: # 若擴展了時間維度或解碼后時間維度為1,則將其壓縮回原始維度。image = image.squeeze(2)-
模型架構
3D causal Vae
3D causal VAE的定義如下:主要包括:
- 編碼器(EncoderCausal3D)和解碼器(DecoderCausal3D),用于學習輸入數據的潛在表示并重建輸出;
- 量化相關層(quant_conv 和 post_quant_conv)
class AutoencoderKLCausal3D(ModelMixin, ConfigMixin, FromOriginalVAEMixin):@register_to_configdef __init__( ):super().__init__()self.time_compression_ratio = time_compression_ratio# 1.設置編碼器(EncoderCausal3D)和解碼器(DecoderCausal3D)self.encoder = EncoderCausal3D(in_channels=in_channels,out_channels=latent_channels,down_block_types=down_block_types,block_out_channels=block_out_channels,layers_per_block=layers_per_block,act_fn=act_fn,norm_num_groups=norm_num_groups,double_z=True,time_compression_ratio=time_compression_ratio,spatial_compression_ratio=spatial_compression_ratio,mid_block_add_attention=mid_block_add_attention,)self.decoder = DecoderCausal3D(in_channels=latent_channels,out_channels=out_channels,up_block_types=up_block_types,block_out_channels=block_out_channels,layers_per_block=layers_per_block,norm_num_groups=norm_num_groups,act_fn=act_fn,time_compression_ratio=time_compression_ratio,spatial_compression_ratio=spatial_compression_ratio,mid_block_add_attention=mid_block_add_attention,)# 2.定義量化相關層self.quant_conv = nn.Conv3d(2 * latent_channels, 2 * latent_channels, kernel_size=1)self.post_quant_conv = nn.Conv3d(latent_channels, latent_channels, kernel_size=1)self.use_slicing = Falseself.use_spatial_tiling = Falseself.use_temporal_tiling = False# 3.配置與VAE分塊處理相關的參數 only relevant if vae tiling is enabledself.tile_sample_min_tsize = sample_tsizeself.tile_latent_min_tsize = sample_tsize // time_compression_ratioself.tile_sample_min_size = self.config.sample_sizesample_size = (self.config.sample_size[0]if isinstance(self.config.sample_size, (list, tuple))else self.config.sample_size)self.tile_latent_min_size = int(sample_size / (2 ** (len(self.config.block_out_channels) - 1)))self.tile_overlap_factor = 0.25?下面的函數實現了變分自編碼器(VAE)的前向傳播過程:
- 輸入處理:接收一個樣本 sample 和多個控制參數;
- 編碼階段:通過 encode 方法獲取潛在變量分布 posterior;
- 采樣策略:根據 sample_posterior 決定是采樣還是取模式值;
- 解碼階段:將采樣結果傳入 decode 得到重建輸出;
- 返回格式:根據標志決定是否返回字典結構或元組,并可包含后驗分布。
class AutoencoderKLCausal3D(ModelMixin, ConfigMixin, FromOriginalVAEMixin):def forward(self,sample: torch.FloatTensor,sample_posterior: bool = False,return_dict: bool = True,return_posterior: bool = False,generator: Optional[torch.Generator] = None,) -> Union[DecoderOutput2, torch.FloatTensor]:r"""Args:sample (`torch.FloatTensor`): Input sample.sample_posterior (`bool`, *optional*, defaults to `False`):Whether to sample from the posterior.return_dict (`bool`, *optional*, defaults to `True`):Whether or not to return a [`DecoderOutput`] instead of a plain tuple."""x = sampleposterior = self.encode(x).latent_dist # 通過 encode 方法獲取潛在變量分布 posteriorif sample_posterior: # 根據 sample_posterior 決定是采樣還是取模式值z = posterior.sample(generator=generator)else:z = posterior.mode()dec = self.decode(z).sample # 將采樣結果傳入 decode 得到重建輸出if not return_dict:if return_posterior:return (dec, posterior)else:return (dec,)if return_posterior:return DecoderOutput2(sample=dec, posterior=posterior)else:return DecoderOutput2(sample=dec)?我們以encoder為例,其初始化部分為:
class EncoderCausal3D(nn.Module):def __init__():super().__init__()self.layers_per_block = layers_per_block# 輸入層:使用 CausalConv3d 對輸入進行初步特征提取。self.conv_in = CausalConv3d(in_channels, block_out_channels[0], kernel_size=3, stride=1)self.mid_block = Noneself.down_blocks = nn.ModuleList([])# 下采樣塊downoutput_channel = block_out_channels[0]for i, down_block_type in enumerate(down_block_types):input_channel = output_channeloutput_channel = block_out_channels[i]is_final_block = i == len(block_out_channels) - 1num_spatial_downsample_layers = int(np.log2(spatial_compression_ratio))num_time_downsample_layers = int(np.log2(time_compression_ratio))if time_compression_ratio == 4: # 根據 time_compression_ratio 和 spatial_compression_ratio 決定時間與空間維度的下采樣策略。add_spatial_downsample = bool(i < num_spatial_downsample_layers)add_time_downsample = bool(i >= (len(block_out_channels) - 1 - num_time_downsample_layers)and not is_final_block)else:raise ValueError(f"Unsupported time_compression_ratio: {time_compression_ratio}.")downsample_stride_HW = (2, 2) if add_spatial_downsample else (1, 1)downsample_stride_T = (2,) if add_time_downsample else (1,)downsample_stride = tuple(downsample_stride_T + downsample_stride_HW)down_block = get_down_block3d( # 構建多個下采樣模塊,實現對輸入數據在時空維度上的逐步壓縮。down_block_type,num_layers=self.layers_per_block,in_channels=input_channel,out_channels=output_channel,add_downsample=bool(add_spatial_downsample or add_time_downsample),downsample_stride=downsample_stride,resnet_eps=1e-6,downsample_padding=0,resnet_act_fn=act_fn,resnet_groups=norm_num_groups,attention_head_dim=output_channel,temb_channels=None,)self.down_blocks.append(down_block)# 中間塊 midself.mid_block = UNetMidBlockCausal3D( # 包含注意力機制(可選),用于增強模型對長期依賴的建模能力。in_channels=block_out_channels[-1],resnet_eps=1e-6,resnet_act_fn=act_fn,output_scale_factor=1,resnet_time_scale_shift="default",attention_head_dim=block_out_channels[-1],resnet_groups=norm_num_groups,temb_channels=None,add_attention=mid_block_add_attention,)# 輸出層 out 使用 GroupNorm 和 SiLU 激活函數處理最終特征。self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[-1], num_groups=norm_num_groups, eps=1e-6)self.conv_act = nn.SiLU()conv_out_channels = 2 * out_channels if double_z else out_channelsself.conv_out = CausalConv3d(block_out_channels[-1], conv_out_channels, kernel_size=3) # 通過 CausalConv3d 輸出編碼結果,支持雙通道輸出(如VAE中的均值和方差)。
encoder的前向傳播過程為:
class EncoderCausal3D(nn.Module):def forward(self, sample: torch.FloatTensor) -> torch.FloatTensor:r"""The forward method of the `EncoderCausal3D` class."""assert len(sample.shape) == 5, "The input tensor should have 5 dimensions"sample = self.conv_in(sample)# downfor down_block in self.down_blocks:sample = down_block(sample)# middlesample = self.mid_block(sample)# post-processsample = self.conv_norm_out(sample)sample = self.conv_act(sample)sample = self.conv_out(sample)return sample其中CausalConv3d的定義如下:
- ?CausalConv3d 實現了一個帶有時間因果填充的3D卷積層,
- 其中?padding 為時間因果填充模式:空間維度(W, H)使用對稱填充,時間維度(T)僅向前填充,確保當前輸出不依賴未來幀。
class CausalConv3d(nn.Module):def __init__():super().__init__()self.pad_mode = pad_modepadding = (kernel_size // 2, kernel_size // 2, kernel_size // 2, kernel_size // 2, kernel_size - 1, 0) # W, H, T 設置 padding 為時間因果填充模式:空間維度(W, H)使用對稱填充,時間維度(T)僅向前填充,確保當前輸出不依賴未來幀。self.time_causal_padding = paddingself.conv = nn.Conv3d(chan_in, chan_out, kernel_size, stride=stride, dilation=dilation, **kwargs) # 調用 nn.Conv3d 構建實際的3D卷積層def forward(self, x):x = F.pad(x, self.time_causal_padding, mode=self.pad_mode)return self.conv(x)Visual Encoder
論文中用于對參考圖像進行編碼的Visual Encoder的定義如下:?
class MatrixGameEncoderWrapperI2V(ModelMixin):def __init__(self, model_path, weight_dtype, task='i2v', i2v_type = 'concat'):super().__init__()text_encoder_type_1 = "llm-i2v" # 設置文本編碼器和分詞器類型為 "llm-i2vtokenizer_type_1 = "llm-i2v"# 定義兩個提示模板 prompt_template 和 prompt_template_video,分別用于圖像和視頻任務,包含嵌入位置、長度等信息。prompt_template = {'template': PROMPT_TEMPLATE_ENCODE_I2V, 'crop_start': 36, "image_emb_start": 5,"image_emb_end": 581,"image_emb_len": 576,"double_return_token_id": 271}prompt_template_video = {"template": PROMPT_TEMPLATE_ENCODE_VIDEO_I2V, "crop_start": 103,"image_emb_start": 5,"image_emb_end": 581,"image_emb_len": 576,"double_return_token_id": 271}max_length_1 = 256 + ( # 計算最大文本長prompt_template_video.get("crop_start", 0)if prompt_template_video is not Noneelse prompt_template.get("crop_start", 0)if prompt_template is not Noneelse 0)# print("text len1:", max_length_1)# 設置編碼器其他參數,如跳過層、精度、是否應用歸一化等。hidden_state_skip_layer = 2text_encoder_precision = "fp16"apply_final_norm = Falsereproduce = Falselogger = Nonedevice = None# 實例化 TextEncoder 并根據 i2v_type 設置 image_embed_interleave 參數(concat 時為 2,否則為 4)text_encoder_1 = TextEncoder(text_encoder_type=text_encoder_type_1,max_length=max_length_1,text_encoder_precision=weight_dtype,tokenizer_type=tokenizer_type_1,i2v_mode = True,prompt_template=prompt_template,prompt_template_video=prompt_template_video,hidden_state_skip_layer=hidden_state_skip_layer,apply_final_norm=apply_final_norm,reproduce=reproduce,logger=logger,device=device,text_encoder_path = model_path,image_embed_interleave = 2 if i2v_type == 'concat' else 4)self.text_encoder_1 = text_encoder_1模型處理過程如下,主要流程是將輸入的提示(prompt)編碼為可用于生成視頻或圖像的嵌入表示(prompt embeddings),并處理注意力掩碼。:
- 確定批量大小:根據輸入 prompt 的類型(字符串、列表或已有的嵌入)確定 batch size。
- 文本編碼:
- 使用 text_encoder.text2tokens 將文本轉換為模型可接受的 token 輸入。
- 根據是否設置 clip_skip 決定使用哪一層的輸出作為嵌入,若設置則取指定層的隱藏狀態,并應用 LayerNorm。
- 處理 attention_mask:如果存在 attention mask,則將其復制擴展以匹配每個 prompt 生成多個視頻的需求。
- 調整 prompt_embeds 形狀根據維度對 prompt_embeds 進行重復擴展和重塑,使其適配每個 prompt 生成多個視頻的情況。
- 返回結果:返回處理后的 prompt_embeds 和 attention_mask,供后續生成過程使用。
class MatrixGameEncoderWrapperI2V(ModelMixin):def encode_prompt():# 確定批量大小if prompt is not None and isinstance(prompt, str):batch_size = 1elif prompt is not None and isinstance(prompt, list):batch_size = len(prompt)else:batch_size = prompt_embeds.shape[0]text_inputs = text_encoder.text2tokens(prompt, data_type=data_type) # 將文本轉換為模型可接受的 token 輸入。if clip_skip is None: # 根據是否設置 clip_skip 決定使用哪一層的輸出作為嵌入prompt_outputs = text_encoder.encode(text_inputs, data_type=data_type, device=device, semantic_images=semantic_images,)prompt_embeds = prompt_outputs.hidden_stateelse:prompt_outputs = text_encoder.encode(text_inputs,output_hidden_states=True,data_type=data_type,device=device,semantic_images=semantic_images)# Access the `hidden_states` first, that contains a tuple of# all the hidden states from the encoder layers. Then index into# the tuple to access the hidden states from the desired layer.prompt_embeds = prompt_outputs.hidden_states_list[-(clip_skip + 1)]# We also need to apply the final LayerNorm here to not mess with the# representations. The `last_hidden_states` that we typically use for# obtaining the final prompt representations passes through the LayerNorm# layer.prompt_embeds = text_encoder.model.text_model.final_layer_norm(prompt_embeds)attention_mask = prompt_outputs.attention_mask # 處理 attention_maskif attention_mask is not None: # 如果存在 attention mask,則將其復制擴展以匹配每個 prompt 生成多個視頻的需求。attention_mask = attention_mask.to(device)bs_embed, seq_len = attention_mask.shapeattention_mask = attention_mask.repeat(1, num_videos_per_prompt)attention_mask = attention_mask.view(bs_embed * num_videos_per_prompt, seq_len)prompt_embeds_dtype = text_encoder.dtypeprompt_embeds = prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)# 調整 prompt_embeds 形狀if prompt_embeds.ndim == 2:bs_embed, _ = prompt_embeds.shape# duplicate text embeddings for each generation per prompt, using mps friendly methodprompt_embeds = prompt_embeds.repeat(1, num_videos_per_prompt)prompt_embeds = prompt_embeds.view(bs_embed * num_videos_per_prompt, -1)else:bs_embed, seq_len, _ = prompt_embeds.shape# duplicate text embeddings for each generation per prompt, using mps friendly methodprompt_embeds = prompt_embeds.repeat(1, num_videos_per_prompt, 1)prompt_embeds = prompt_embeds.view(bs_embed * num_videos_per_prompt, seq_len, -1)return prompt_embeds, attention_mask # 返回處理后的 prompt_embeds 和 attention_maskDiT
class MGVideoDiffusionTransformerI2V(ModelMixin, ConfigMixin, PeftAdapterMixin):@register_to_configdef __init__():...# 1.初始化各類嵌入層:包括圖像、文本、時間步和引導信息的嵌入處理# image projectionself.img_in = PatchEmbed(self.patch_size, self.in_channels, self.hidden_size, **factory_kwargs)# text projectionif self.text_projection == "linear":self.txt_in = TextProjection(self.text_states_dim,self.hidden_size,get_activation_layer("silu"),**factory_kwargs,)elif self.text_projection == "single_refiner":self.txt_in = SingleTokenRefiner(self.text_states_dim, hidden_size, heads_num, depth=2, **factory_kwargs)else:raise NotImplementedError(f"Unsupported text_projection: {self.text_projection}")# time modulationself.time_in = TimestepEmbedder(self.hidden_size, get_activation_layer("silu"), **factory_kwargs)# guidance modulationself.guidance_in = (TimestepEmbedder(self.hidden_size, get_activation_layer("silu"), **factory_kwargs)if guidance_embedelse None)# 2.構建雙流與單流Transformer模塊# double blocksself.double_blocks = nn.ModuleList([MMDoubleStreamBlock(self.hidden_size,self.heads_num,mlp_width_ratio=mlp_width_ratio,mlp_act_type=mlp_act_type,qk_norm=qk_norm,qk_norm_type=qk_norm_type,qkv_bias=qkv_bias,action_config = action_config,**factory_kwargs,)for _ in range(mm_double_blocks_depth)])# single blocksself.single_blocks = nn.ModuleList([MMSingleStreamBlock(self.hidden_size,self.heads_num,mlp_width_ratio=mlp_width_ratio,mlp_act_type=mlp_act_type,qk_norm=qk_norm,qk_norm_type=qk_norm_type,action_config = action_config,**factory_kwargs,)for _ in range(mm_single_blocks_depth)])self.final_layer = FinalLayer(self.hidden_size,self.patch_size,self.out_channels,get_activation_layer("silu"),**factory_kwargs,)self.gradient_checkpointing = Falseself.gradient_checkpoint_layers = -1self.single_stream_block_no_attn_recompute_layers = 0self.double_stream_block_no_attn_recompute_layers = 0該函數是擴散模型中用于視頻生成的主干前向傳播邏輯,主要功能如下:
- 輸入處理:接收圖像、時間步、文本編碼等條件信息;
- 嵌入與位置編碼:對圖像和文本進行嵌入,并生成旋轉位置編碼;
- 時間與引導調制:構建時間步向量并融合引導信息(如CFG);
- 雙流Transformer塊處理:圖像與文本分別通過雙流模塊交互建模;
- 單流Transformer塊處理:合并圖像與文本token進行統一建模;
- 輸出重建:通過最終層和反patch操作還原為完整視頻幀;
- 返回結果:根據參數決定是否以字典形式返回輸出。
class MGVideoDiffusionTransformerI2V(ModelMixin, ConfigMixin, PeftAdapterMixin):def forward() -> Union[torch.Tensor, Dict[str, torch.Tensor]]:x = hidden_statest = timesteptext_states, text_states_2 = encoder_hidden_statestext_mask, test_mask_2 = encoder_attention_maskout = {}img = xtxt = text_states_, _, ot, oh, ow = x.shapefreqs_cos, freqs_sin = self.get_rotary_pos_embed(ot, oh, ow) # 對圖像和文本進行嵌入,并生成位置編碼tt, th, tw = (ot // self.patch_size[0],oh // self.patch_size[1],ow // self.patch_size[2],)# 處理時間步t Prepare modulation vectors.vec = self.time_in(t)if self.i2v_condition_type == "token_replace":token_replace_t = torch.zeros_like(t)token_replace_vec = self.time_in(token_replace_t) # 進行時間編碼frist_frame_token_num = th * tw # 計算首幀 token 數量else:token_replace_vec = Nonefrist_frame_token_num = None# guidance modulationif self.guidance_embed: # 啟用了引導嵌入功能if guidance is None:raise ValueError("Didn't get guidance strength for guidance distilled model.")# our timestep_embedding is merged into guidance_in(TimestepEmbedder)vec = vec + self.guidance_in(guidance) # 引導信息編碼,并加到 vec 上(如時間步嵌入中)。# 對輸入的圖像img和文本txt進行不同的特征映射處理 Embed image and text.img = self.img_in(img) # 對輸入圖像進行嵌入編碼if self.text_projection == "linear": # 對文本使用線性投影txt = self.txt_in(txt)elif self.text_projection == "single_refiner": # 使用包含時間步t和注意力掩碼(可選)的更復雜文本編碼txt = self.txt_in(txt, t, text_mask if self.use_attention_mask else None)else:raise NotImplementedError(f"Unsupported text_projection: {self.text_projection}")txt_seq_len = txt.shape[1]img_seq_len = img.shape[1]# Compute cu_squlens and max_seqlen for flash attentioncu_seqlens_q = get_cu_seqlens(text_mask, img_seq_len) # 獲取查詢(Q)和鍵/值(KV)的累積序列長度;cu_seqlens_kv = cu_seqlens_qmax_seqlen_q = img_seq_len + txt_seq_len # 設置最大序列長度max_seqlen_kv = max_seqlen_qfreqs_cis = (freqs_cos, freqs_sin) if freqs_cos is not None else None # 將 freqs_cos 和 freqs_sin 合并為 freqs_cisself.single_stream_block_no_attn_recompute_layers = 0if img_seq_len < 20 * 1024: # 根據圖像序列長度動態設置 single_stream_block_no_attn_recompute_layers 的值,以優化內存與計算效率。self.single_stream_block_no_attn_recompute_layers = 10elif img_seq_len < 30 * 1024:self.single_stream_block_no_attn_recompute_layers = 10elif img_seq_len < 40 * 1024:self.single_stream_block_no_attn_recompute_layers = 5# --------------------- 在模型的雙流塊中,依次對每個塊進行前向傳播 Pass through DiT blocks ------------------------for i, block in enumerate(self.double_blocks):if torch.is_grad_enabled() and self.gradient_checkpointing and i >= self.double_stream_block_no_attn_recompute_layers:def create_custom_forward(module): # 包裝模塊以支持檢查點;def custom_forward(*inputs):return module(*inputs)return custom_forwardckpt_kwargs: Dict[str, Any] = {"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}image_kwargs: Dict[str, Any] = {"tt":hidden_states.shape[2] // self.patch_size[0], # 提供圖像塊尺寸信息"th":hidden_states.shape[3] // self.patch_size[1],"tw":hidden_states.shape[4] // self.patch_size[2]}img, txt = torch.utils.checkpoint.checkpoint( # 對 block 進行前向計算create_custom_forward(block),img,txt,vec,cu_seqlens_q,cu_seqlens_kv,max_seqlen_q,max_seqlen_kv,freqs_cis,image_kwargs,mouse_condition,keyboard_condition,self.i2v_condition_type,token_replace_vec,frist_frame_token_num,False,**ckpt_kwargs,)else:image_kwargs: Dict[str, Any] = {"tt":hidden_states.shape[2] // self.patch_size[0],"th":hidden_states.shape[3] // self.patch_size[1],"tw":hidden_states.shape[4] // self.patch_size[2]}double_block_args = [img,txt,vec,cu_seqlens_q,cu_seqlens_kv,max_seqlen_q,max_seqlen_kv,freqs_cis,image_kwargs,mouse_condition,keyboard_condition,self.i2v_condition_type,token_replace_vec,frist_frame_token_num,True,]img, txt = block(*double_block_args)# 在模型的單流塊中,依次對每個塊進行前向傳播Merge txt and img to pass through single stream blocks.x = torch.cat((img, txt), 1)if len(self.single_blocks) > 0:for i, block in enumerate(self.single_blocks):if torch.is_grad_enabled() and self.gradient_checkpointing and i >= self.single_stream_block_no_attn_recompute_layers:def create_custom_forward(module):def custom_forward(*inputs):return module(*inputs)return custom_forwardckpt_kwargs: Dict[str, Any] = {"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}image_kwargs: Dict[str, Any] = {"tt":hidden_states.shape[2] // self.patch_size[0],"th":hidden_states.shape[3] // self.patch_size[1],"tw":hidden_states.shape[4] // self.patch_size[2]}x = torch.utils.checkpoint.checkpoint( # 前向傳播create_custom_forward(block),x,vec,txt_seq_len,cu_seqlens_q,cu_seqlens_kv,max_seqlen_q,max_seqlen_kv,(freqs_cos, freqs_sin),image_kwargs,mouse_condition,keyboard_condition,self.i2v_condition_type,token_replace_vec,frist_frame_token_num,False,**ckpt_kwargs,)else:image_kwargs: Dict[str, Any] = {"tt":hidden_states.shape[2] // self.patch_size[0],"th":hidden_states.shape[3] // self.patch_size[1],"tw":hidden_states.shape[4] // self.patch_size[2]}single_block_args = [x,vec,txt_seq_len,cu_seqlens_q,cu_seqlens_kv,max_seqlen_q,max_seqlen_kv,(freqs_cos, freqs_sin),image_kwargs,mouse_condition,keyboard_condition,self.i2v_condition_type,token_replace_vec,frist_frame_token_num,True,]x = block(*single_block_args)img = x[:, :img_seq_len, ...]# ---------------------------- Final layer ------------------------------img = self.final_layer(img, vec) # 對輸入張量 img 進行最終的圖像重建層處理,結合向量 vec(可能用于條件信息),輸出重構后的圖像塊; (N, T, patch_size ** 2 * out_channels)img = self.unpatchify(img, tt, th, tw) # 將圖像塊恢復為完整圖像;if return_dict: # 根據 return_dict 決定返回格式:若為真,則將結果放入字典 out 中并返回out["x"] = img return outreturn (img,)-
process_video()
該函數 process_video 的主要功能是處理視頻幀,在每一幀上繪制虛擬按鍵狀態并疊加鼠標圖標,最終輸出處理后的視頻。具體邏輯如下:
- 使用 parse_config 解析配置,獲取每幀的鍵盤和鼠標數據。
- 讀取鼠標圖標,并初始化輸出視頻列表。
- 遍歷輸入視頻的每一幀:
- 獲取當前幀的按鍵狀態和鼠標位置。
- 調用 draw_keys_on_frame 在幀上繪制按鍵狀態。
- 調用 overlay_icon 將鼠標圖標疊加到指定位置。
- 將處理后的幀歸一化后加入輸出列表。
- 使用 export_to_video 將處理后的幀導出為視頻文件。
def process_video(input_video, output_video, config, mouse_icon_path, mouse_scale=2.0, mouse_rotation=0,fps=16):# 該函數 process_video 的主要功能是處理視頻幀,在每一幀上繪制虛擬按鍵狀態并疊加鼠標圖標,最終輸出處理后的視頻。key_data, mouse_data = parse_config(config) # 使用 parse_config 解析配置,獲取每幀的鍵盤和鼠標數據。fps = fpsframe_width = input_video[0].shape[1]frame_height = input_video[0].shape[0]frame_count = len(input_video)mouse_icon = cv2.imread(mouse_icon_path, cv2.IMREAD_UNCHANGED) # 讀取鼠標圖標,并初始化輸出視頻列表。out_video = []frame_idx = 0for frame in input_video: # 遍歷輸入視頻的每一幀keys = key_data.get(frame_idx, {"W": False, "A": False, "S": False, "D": False, "Space": False, "Attack": False})raw_mouse_pos = mouse_data.get(frame_idx, (frame_width // 2 // 2, frame_height // 2 // 2)) # fallback 也用小分辨率中心mouse_position = (int(raw_mouse_pos[0] * 2), int(raw_mouse_pos[1] * 2)) # 獲取鼠標位置。draw_keys_on_frame(frame, keys, key_size=(75, 75), spacing=10, bottom_margin=20) # 調用 draw_keys_on_frame 在幀上繪制按鍵狀態。overlay_icon(frame, mouse_icon, mouse_position, scale=mouse_scale, rotation=mouse_rotation) # 調用 overlay_icon 將鼠標圖標疊加到指定位置。out_video.append(frame / 255) # 將處理后的幀歸一化后加入輸出列表。frame_idx += 1print(f"Processing frame {frame_idx}/{frame_count}", end="\r")export_to_video(out_video, output_video, fps=fps) # 使用 export_to_video 將處理后的幀導出為視頻文件。print("\nProcessing complete!")其中draw_keys_on_frame()如下,該函數在視頻幀上繪制虛擬鍵盤按鍵,用于可視化按鍵狀態(按下或未按下)。具體功能如下:
- 定義按鍵位置:根據幀大小計算 W、A、S、D、Space、Attack 按鍵的坐標位置;
- 繪制按鍵圖形:調用 draw_rounded_rectangle 繪制帶圓角矩形的按鍵;
- 顯示按鍵文字:使用 cv2.putText 在按鍵上繪制對應文字;?
def draw_keys_on_frame(frame, keys, key_size=(80, 50), spacing=20, bottom_margin=30): # 在視頻幀上繪制虛擬鍵盤按鍵,用于可視化按鍵狀態(按下或未按下)。h, w, _ = frame.shapehorison_shift = 90vertical_shift = -20horizon_shift_all = 50key_positions = { # 定義按鍵位置:根據幀大小計算 W、A、S、D、Space、Attack 按鍵的坐標位置"W": (w // 2 - key_size[0] // 2 - horison_shift - horizon_shift_all + spacing* 2, h - bottom_margin - key_size[1] * 2 + vertical_shift - 20),"A": (w // 2 - key_size[0] * 2 + 5 - horison_shift - horizon_shift_all+ spacing* 2, h - bottom_margin - key_size[1] + vertical_shift),"S": (w // 2 - key_size[0] // 2 - horison_shift - horizon_shift_all+ spacing* 2, h - bottom_margin - key_size[1] + vertical_shift),"D": (w // 2 + key_size[0] - 5 - horison_shift - horizon_shift_all+ spacing* 2, h - bottom_margin - key_size[1] + vertical_shift),"Space": (w // 2 + key_size[0] * 2 + spacing * 4 - horison_shift - horizon_shift_all , h - bottom_margin - key_size[1] + vertical_shift),"Attack": (w // 2 + key_size[0] * 3 + spacing * 9 - horison_shift - horizon_shift_all, h - bottom_margin - key_size[1] + vertical_shift),}for key, (x, y) in key_positions.items(): # 遍歷每個按鍵及其位置 (x, y)is_pressed = keys.get(key, False) # 判斷按鍵是否被按下top_left = (x, y)if key in ["Space", "Attack"]: bottom_right = (x + key_size[0]+40, y + key_size[1])else:bottom_right = (x + key_size[0], y + key_size[1])color = (0, 255, 0) if is_pressed else (200, 200, 200) # 設置顏色 color 和透明度 alphalpha = 0.8 if is_pressed else 0.5draw_rounded_rectangle(frame, top_left, bottom_right, color, radius=10, alpha=alpha) # 繪制帶圓角的矩形作為按鍵背景text_size = cv2.getTextSize(key, cv2.FONT_HERSHEY_SIMPLEX, 0.8, 2)[0] # 繪制帶圓角的矩形作為按鍵背景 if key in ["Space", "Attack"]:text_x = x + (key_size[0]+40 - text_size[0]) // 2else:text_x = x + (key_size[0] - text_size[0]) // 2text_y = y + (key_size[1] + text_size[1]) // 2cv2.putText(frame, key, (text_x, text_y), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 0), 2) # 顯示按鍵文字:使用 cv2.putText 在按鍵上繪制對應文字
其中draw_rounded_rectangle()函數使用 OpenCV 在圖像上繪制一個帶有圓角的矩形,并支持透明度疊加。?
def draw_rounded_rectangle(image, top_left, bottom_right, color, radius=10, alpha=0.5):overlay = image.copy()x1, y1 = top_leftx2, y2 = bottom_rightcv2.rectangle(overlay, (x1 + radius, y1), (x2 - radius, y2), color, -1) # 繪制圓角矩形cv2.rectangle(overlay, (x1, y1 + radius), (x2, y2 - radius), color, -1)cv2.ellipse(overlay, (x1 + radius, y1 + radius), (radius, radius), 180, 0, 90, color, -1) # 使用四個橢圓(cv2.ellipse)繪制四個圓角;cv2.ellipse(overlay, (x2 - radius, y1 + radius), (radius, radius), 270, 0, 90, color, -1)cv2.ellipse(overlay, (x1 + radius, y2 - radius), (radius, radius), 90, 0, 90, color, -1)cv2.ellipse(overlay, (x2 - radius, y2 - radius), (radius, radius), 0, 0, 90, color, -1)cv2.addWeighted(overlay, alpha, image, 1 - alpha, 0, image) # 將繪制好的圖形以指定透明度 alpha 疊加到原始圖像上。overlay_icon()的功能是在視頻幀的指定位置疊加一個經過縮放和旋轉的圖標(帶透明通道),并保持邊界處理和透明混合。
def overlay_icon(frame, icon, position, scale=1.0, rotation=0):x, y = positionh, w, _ = icon.shape# 縮放圖標,根據 scale 參數調整圖標大小。scaled_width = int(w * scale)scaled_height = int(h * scale)icon_resized = cv2.resize(icon, (scaled_width, scaled_height), interpolation=cv2.INTER_AREA)# 旋轉圖標,以圖標中心為軸心旋轉指定角度 rotation。center = (scaled_width // 2, scaled_height // 2)def overlay_icon(frame, icon, position, scale=1.0, rotation=0):x, y = positionh, w, _ = icon.shape# 縮放圖標scaled_width = int(w * scale)scaled_height = int(h * scale)icon_resized = cv2.resize(icon, (scaled_width, scaled_height), interpolation=cv2.INTER_AREA)# 旋轉圖標center = (scaled_width // 2, scaled_height // 2)rotation_matrix = cv2.getRotationMatrix2D(center, rotation, 1.0)icon_rotated = cv2.warpAffine(icon_resized, rotation_matrix, (scaled_width, scaled_height), flags=cv2.INTER_LINEAR, borderMode=cv2.BORDER_CONSTANT, borderValue=(0, 0, 0, 0))h, w, _ = icon_rotated.shapeframe_h, frame_w, _ = frame.shape# 計算繪制區域,確定圖標在幀上的放置位置,并限制在幀的邊界內。top_left_x = max(0, int(x - w // 2))top_left_y = max(0, int(y - h // 2))bottom_right_x = min(frame_w, int(x + w // 2))bottom_right_y = min(frame_h, int(y + h // 2))icon_x_start = max(0, int(-x + w // 2))icon_y_start = max(0, int(-y + h // 2))icon_x_end = icon_x_start + (bottom_right_x - top_left_x)icon_y_end = icon_y_start + (bottom_right_y - top_left_y)# 提取圖標區域icon_region = icon_rotated[icon_y_start:icon_y_end, icon_x_start:icon_x_end]alpha = icon_region[:, :, 3] / 255.0icon_rgb = icon_region[:, :, :3]# 提取幀對應區域frame_region = frame[top_left_y:bottom_right_y, top_left_x:bottom_right_x]# 疊加圖標print(frame_region.shape, icon_rgb.shape, alpha.shape)# import ipdb; ipdb.set_trace()for c in range(3):frame_region[:, :, c] = (1 - alpha) * frame_region[:, :, c] + alpha * icon_rgb[:, :, c]# 替換幀對應區域frame[top_left_y:bottom_right_y, top_left_x:bottom_right_x] = frame_regionrotation_matrix = cv2.getRotationMatrix2D(center, rotation, 1.0)icon_rotated = cv2.warpAffine(icon_resized, rotation_matrix, (scaled_width, scaled_height), flags=cv2.INTER_LINEAR, borderMode=cv2.BORDER_CONSTANT, borderValue=(0, 0, 0, 0))h, w, _ = icon_rotated.shapeframe_h, frame_w, _ = frame.shape# 計算繪制區域top_left_x = max(0, int(x - w // 2))top_left_y = max(0, int(y - h // 2))bottom_right_x = min(frame_w, int(x + w // 2))bottom_right_y = min(frame_h, int(y + h // 2))icon_x_start = max(0, int(-x + w // 2))icon_y_start = max(0, int(-y + h // 2))icon_x_end = icon_x_start + (bottom_right_x - top_left_x)icon_y_end = icon_y_start + (bottom_right_y - top_left_y)# 提取圖標區域icon_region = icon_rotated[icon_y_start:icon_y_end, icon_x_start:icon_x_end]alpha = icon_region[:, :, 3] / 255.0icon_rgb = icon_region[:, :, :3]# 提取幀對應區域frame_region = frame[top_left_y:bottom_right_y, top_left_x:bottom_right_x]# 疊加圖標,使用 alpha 通道將圖標疊加到幀上。print(frame_region.shape, icon_rgb.shape, alpha.shape)# import ipdb; ipdb.set_trace()for c in range(3):frame_region[:, :, c] = (1 - alpha) * frame_region[:, :, c] + alpha * icon_rgb[:, :, c]# 替換幀對應區域,將疊加后的圖像部分寫回原始幀中。frame[top_left_y:bottom_right_y, top_left_x:bottom_right_x] = frame_region-
-
總結
在本工作中,作者提出了Matrix-Game,這是一個專為開放式游戲環境中交互式視頻生成設計的新型世界基礎模型。與此同時,作者構建了MatrixGame-MC數據集,這是一個大規模且標注豐富的語料庫,旨在支持類似《我的世界》風格環境中的動作可控生成。為了促進這一新興領域的標準化評估,作者還開發了GameWorld Score,這是一個全面的基準測試,能夠衡量感知質量、時間連貫性、可控性和物理一致性等關鍵方面。作者將向社區發布模型權重和基準測試工具包,目標是推動交互式世界生成領域的未來研究。

)



)

)





python開發經驗)




)
