一、YOLOv3的誕生:繼承與突破的起點
YOLOv3作為YOLO系列的第三代算法,于2018年由Joseph Redmon等人提出。它在YOLOv2的基礎上,針對小目標檢測精度低、多類別標簽預測受限等問題進行了系統性改進。通過引入多尺度特征圖檢測、殘差網絡架構和獨立分類器設計,YOLOv3在保持實時性的同時,顯著提升了檢測精度,成為目標檢測領域的經典算法之一。
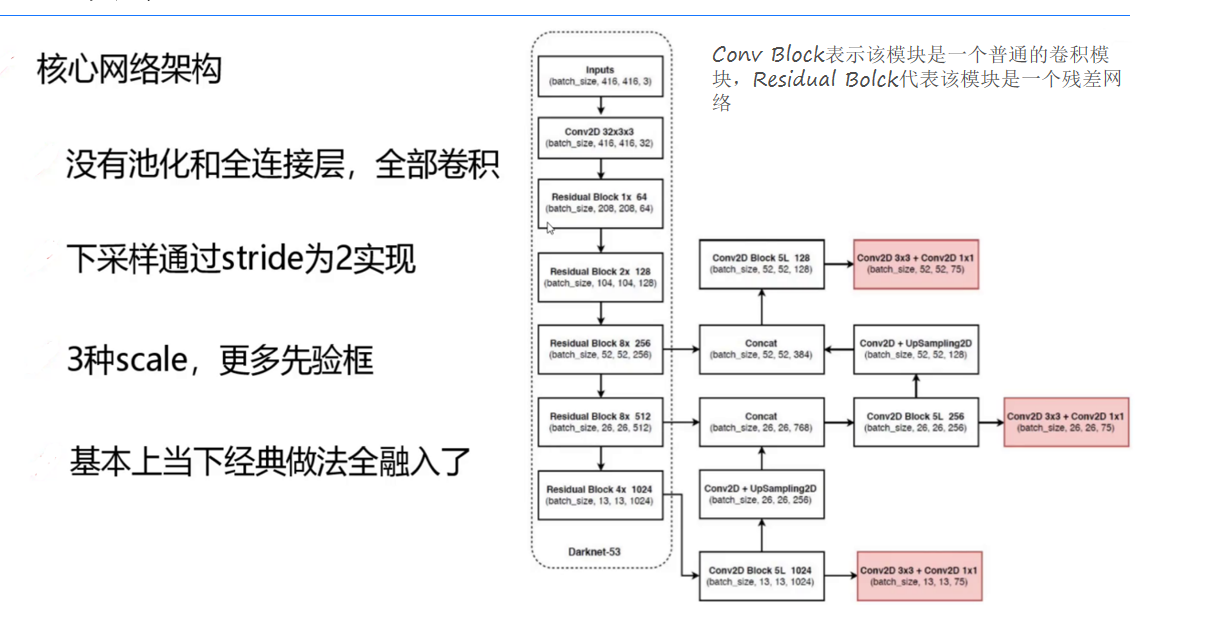
二、核心架構:Darknet-53與多尺度檢測的完美協同
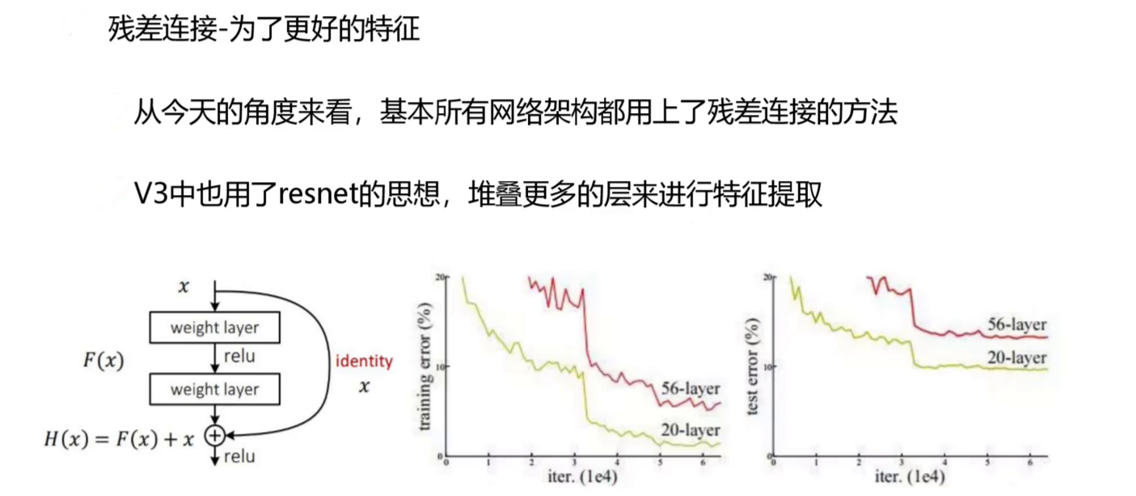
(一)Darknet-53:殘差網絡的高效實踐
YOLOv3的骨干網絡Darknet-53以**殘差連接(Residual Connection)**為核心,構建了53層的全卷積網絡,其架構設計體現了“深度與效率的平衡”:
-
殘差塊結構:每個殘差塊由兩個卷積層(1×1和3×3)和一個捷徑連接組成。
這種結構通過學習輸入與輸出的殘差(而非直接學習輸出),有效緩解了深層網絡的梯度消失問題,允許網絡堆疊更多層以提取更復雜的特征。 -
降采樣策略:摒棄傳統的池化層,通過步長為2的3×3卷積層實現降采樣。例如,輸入416×416的圖像,經過5次降采樣后,依次輸出52×52、26×26、13×13三種尺度的特征圖,分別對應小、中、大目標的檢測。
-
性能優勢:在ImageNet分類任務中,Darknet-53的TOP-1準確率達77.2%,優于ResNet-101(77.8%),且浮點運算量(FLOPs)僅為7.52B,約為ResNet-101的一半,體現了更高的計算效率。
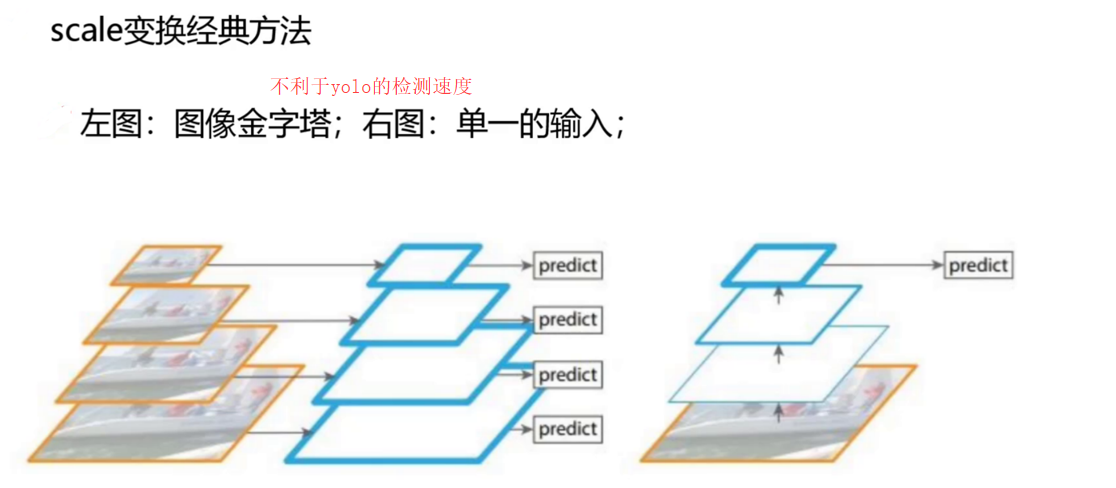
(二)三尺度特征圖檢測:小目標檢測的破局之道
YOLOv3首次將**特征金字塔網絡(FPN)**引入YOLO系列,通過多尺度特征融合解決小目標檢測難題:
-
特征圖尺度與目標匹配:
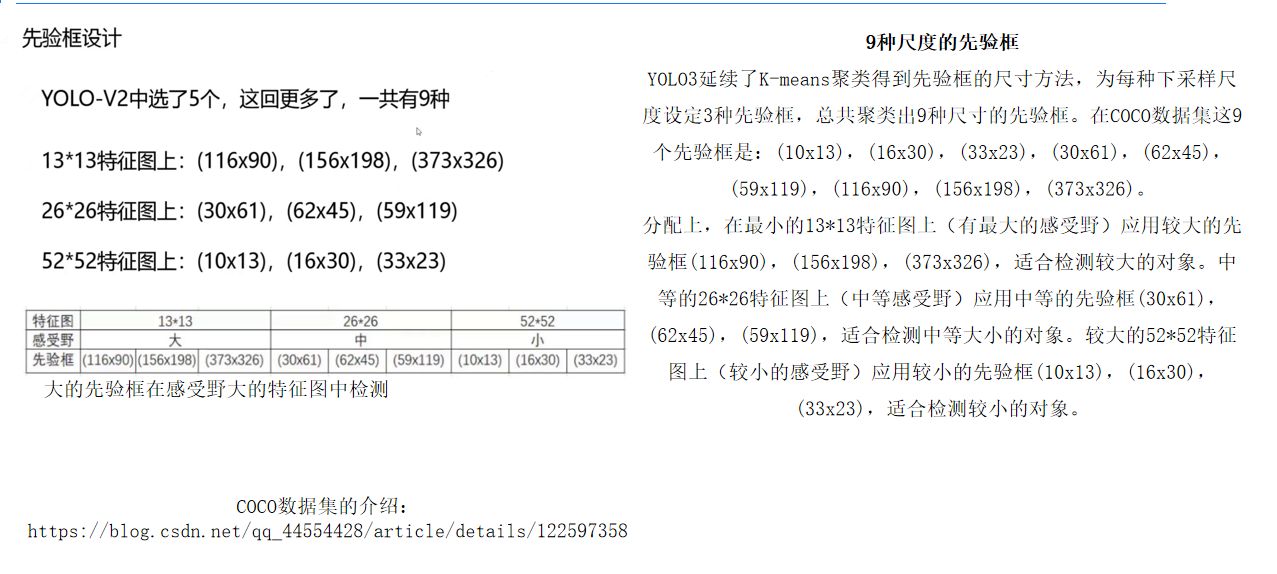
- 52×52特征圖(感受野小):負責檢測小型目標,如昆蟲、文字等,對應先驗框:(10×13)、(16×30)、(33×23)。
- 26×26特征圖(感受野中等):檢測中型目標,如行人、車輛,對應先驗框:(30×61)、(62×45)、(59×119)。
- 13×13特征圖(感受野大):檢測大型目標,如建筑物、飛機,對應先驗框:(116×90)、(156×198)、(373×326)。
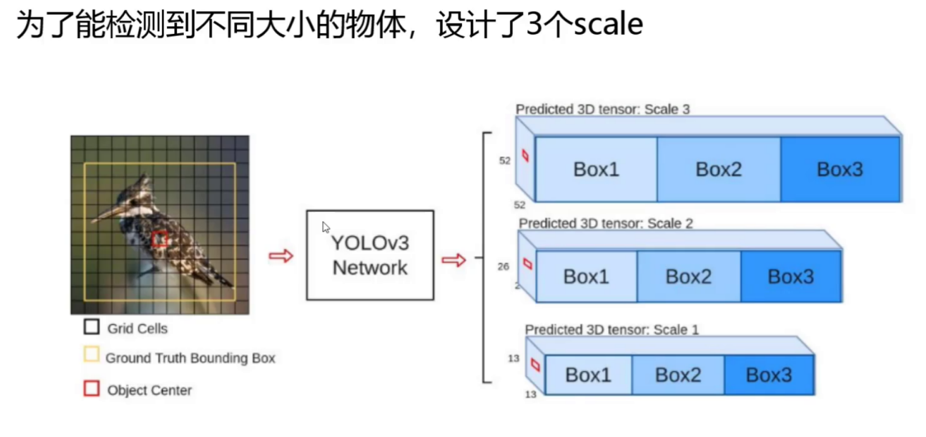
-
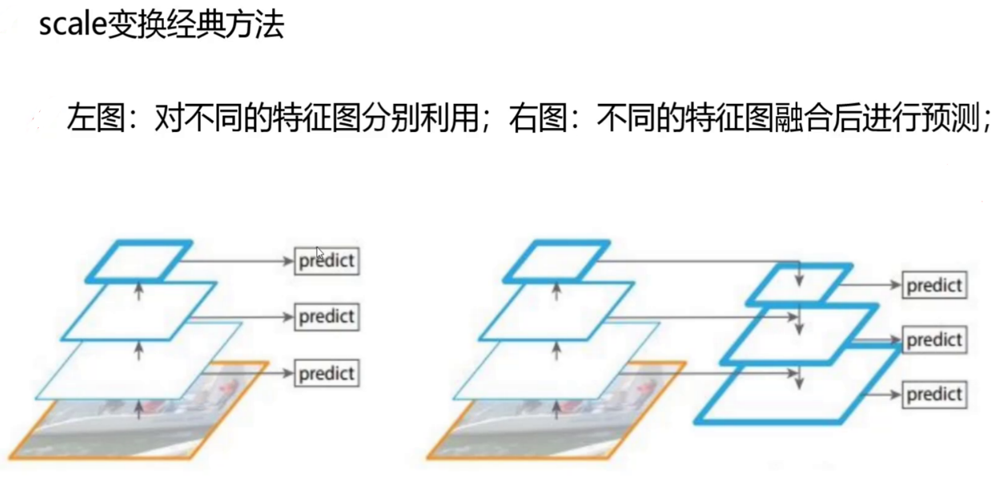
特征融合流程:
- 自頂向下路徑:高層特征圖(如13×13)通過上采樣(插值或轉置卷積)放大至低層特征圖尺寸(如26×26、52×52),與低層特征圖進行橫向連接(Concat操作)。
- 橫向連接優化:在融合前,對低層特征圖進行1×1卷積以減少通道數,對高層特征圖進行3×3卷積以增強特征表達,確保融合后的特征兼具高層語義信息(如“車輛”類別)和低層空間細節(如目標輪廓)。
- 輸出檢測頭:每個尺度的融合特征圖后接獨立的檢測頭,包含3個卷積層和1個1×1卷積層,輸出該尺度下的檢測結果(坐標、置信度、類別概率)。
-
效果驗證:在COCO數據集上,YOLOv3對小目標(面積<322像素)的mAP提升至19.0%,相比YOLOv2的13.0%顯著提升,證明了多尺度檢測的有效性。
三、關鍵改進:從分類到定位的細節革新
(一)獨立Logistic分類器:突破單標簽限制
YOLOv3舍棄了傳統的Softmax分類器,改用獨立Logistic回歸對每個類別進行二分類預測,核心改進如下:
- 多標簽支持:每個類別使用Sigmoid激活函數,輸出獨立的概率值(0-1),允許目標同時屬于多個類別。例如,一張圖像中的“消防栓”可同時被標記為“公共設施”和“金屬物體”。
- 閾值靈活設定:通過調整類別概率閾值(如0.5),可適應不同場景的檢測需求。在醫療影像中,可降低閾值以避免漏檢,在工業質檢中可提高閾值以減少誤報。
- 計算優化:Logistic分類器無需計算Softmax的全局歸一化,計算量減少約30%,推理速度略有提升。

(二)先驗框設計:K-means聚類與尺度分配策略
-
聚類生成先驗框:在COCO數據集上使用K-means算法對真實框進行聚類,生成9種尺寸的先驗框,并按尺度均勻分配到三個特征圖:
- 小特征圖(52×52):3種小先驗框,側重捕捉細節。
- 中特征圖(26×26):3種中等先驗框,平衡語義與定位。
- 大特征圖(13×13):3種大先驗框,適應遠距離目標。
-
先驗框的作用:為預測框提供初始尺寸和位置,減少網絡學習的復雜度。實驗表明,引入先驗框后,YOLOv3的召回率從YOLOv1的81%提升至88%,意味著模型能檢測到更多潛在目標。
(三)典型應用場景
- 智能安防:實時監控視頻中的異常行為(如人群聚集、物品遺留),通過多尺度檢測識別遠距離的小目標(如遠處的可疑包裹)。
- 自動駕駛:檢測道路標志、行人、車輛,利用13×13特征圖識別遠處車輛(大目標),52×52特征圖識別近處行人(小目標),支持多目標追蹤與路徑規劃。
- 工業自動化:電子元件缺陷檢測,通過高分辨率輸入(如608×608)和52×52特征圖捕捉元件表面的微小裂紋或污漬。
- 遙感圖像處理:衛星影像中的建筑物、車輛檢測,利用大感受野特征圖(13×13)識別大型建筑,小感受野特征圖(52×52)識別密集車輛群。
四、總結:YOLOv3的技術遺產與未來啟示
YOLOv3的成功源于其對多尺度特征融合、殘差網絡效率和多標簽分類的深刻理解,其技術創新對后續目標檢測算法產生了深遠影響:
- 多尺度檢測成為后續YOLOv4/v5、Faster R-CNN等算法的標配,甚至擴展至語義分割(如DeepLabv3+)。
- 殘差連接與特征金字塔的組合思想被廣泛應用于各類視覺任務,如姿態估計、實例分割。
- 端到端的單階段檢測架構依然是工業界的首選,其高效性在邊緣計算、實時系統中不可替代。
盡管YOLOv4/v5在精度和速度上進一步突破,但YOLOv3作為承上啟下的里程碑,依然是理解現代目標檢測算法的關鍵切入點。它證明了在深度學習中,通過合理的架構設計與細節優化,完全可以在效率與精度之間找到最優解,這一理念將持續啟發研究者在計算機視覺領域探索更高效、更通用的解決方案。
:安裝部署Docker Deskpot之后啟動出現Docker Engine Stopped!)

![[模型部署] 3. 性能優化](http://pic.xiahunao.cn/[模型部署] 3. 性能優化)








 解題報告 | 珂學家)







