數據集
- 1. scikit-learn工具介紹
- 1.1 scikit-learn安裝
- 1.2 Scikit-learn包含的內容
- 2 數據集
- 2.1 sklearn玩具數據集介紹
- 2.2 sklearn現實世界數據集介紹
- 2.3 sklearn加載玩具數據集
- 示例1:鳶尾花數據
- 示例2:分析糖尿病數據集
- 2.4 sklearn獲取現實世界數據集
- 示例:獲取20分類新聞數據
- 2.5數據集的劃分
- (1) 函數
- (2)示例
- 列表數據集劃分
- 二維數組數據集劃分
- DataFrame數據集劃分
- 字典數據集劃分
- 鳶尾花數據集劃分
- 現實世界數據集劃分
1. scikit-learn工具介紹

- Python語言機器學習工具
- Scikit-learn包括許多智能的機器學習算法的實現
- Scikit-learn文檔完善,容易上手,豐富的API接口函數
- Scikit-learn官網:https://scikit-learn.org/stable/#
- Scikit-learn中文文檔:https://scikitlearn.com.cn/
- scikit-learn中文社區
1.1 scikit-learn安裝
參考以下安裝教程:https://www.sklearncn.cn/62/
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-learn
1.2 Scikit-learn包含的內容
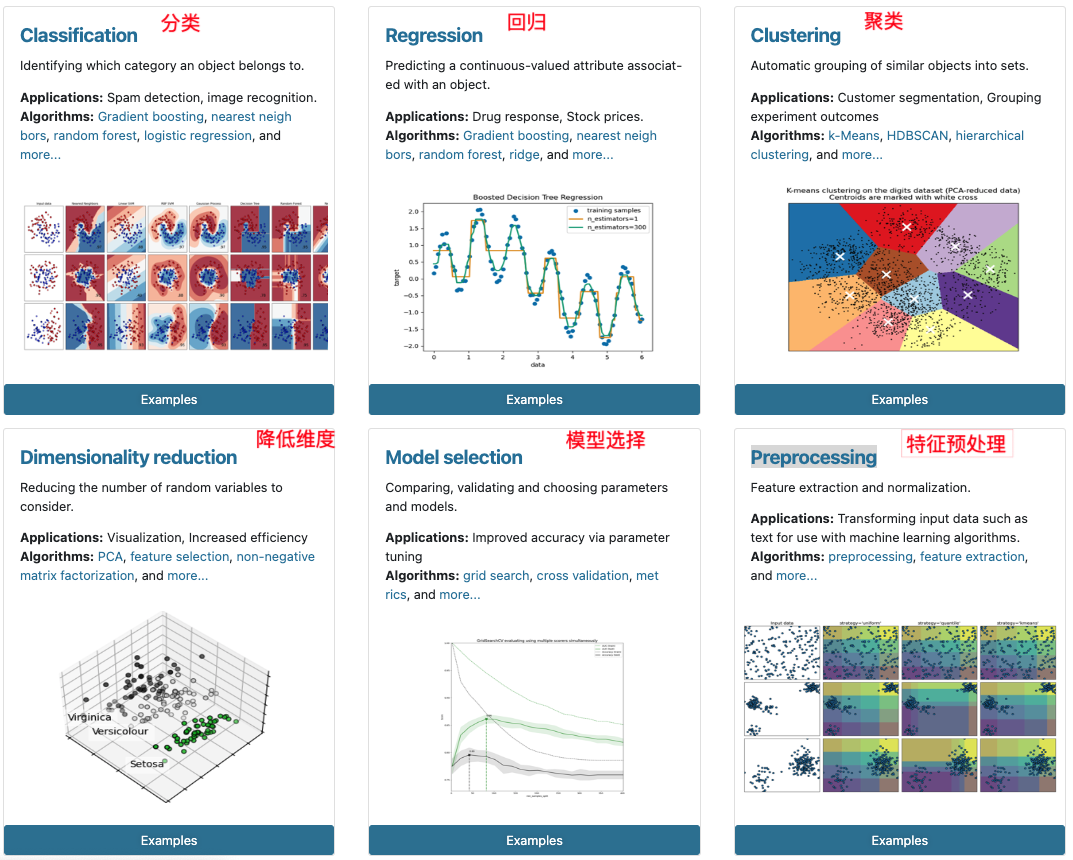
2 數據集
2.1 sklearn玩具數據集介紹
數據量小,數據在sklearn庫的本地,只要安裝了sklearn,不用上網就可以獲取
2.2 sklearn現實世界數據集介紹
數據量大,數據只能通過網絡獲取

2.3 sklearn加載玩具數據集
示例1:鳶尾花數據
from sklearn.datasets import load_iris
iris = load_iris()#鳶尾花數據
鳶尾花數據集介紹
特征有:
? 花萼長 sepal length
? 花萼寬sepal width
? 花瓣長 petal length
? 花瓣寬 petal width
三分類:
? 0-Setosa山鳶尾
? 1-versicolor變色鳶尾
? 2-Virginica維吉尼亞鳶尾
- sklearn.datasets.load_iris():加載并返回鳶尾花數據集

sklearn數據集的使用
sklearn數據集返回值介紹
load和fetch返回的數據類型datasets.base.Bunch(字典格式)
data:特征數據數組,是[n_samples * n_features]的二維numpy.ndarry數組
target:標簽數組,是n_samples的一維numpy.ndarry數組
DESCR:數據描述
feature_names:特征名,新聞數據,手寫數字、回歸數據集沒有
target_names:標簽名
代碼如下:
#獲取鳶尾花數據集的庫
from sklearn.datasets import load_iris
import numpy as np
import pandas as pd
# 獲取鳶尾花數據集
iris=load_iris()
# iris字典中有幾個重要屬性:
# data 特征
data=iris.data
# print('鳶尾花數據集的前5條數據',data[:5])
'''[[5.1 3.5 1.4 0.2][4.9 3. 1.4 0.2][4.7 3.2 1.3 0.2][4.6 3.1 1.5 0.2][5. 3.6 1.4 0.2]]'''# feature_names 特征描述
feature_names=iris.feature_names
print(feature_names)#['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
# target 目標
target=iris.target
# 獲取前五條數據的目標值
print(target[:5])# [0 0 0 0 0]
# target_names 目標描述
target_names=iris.target_names
print(target_names) #['setosa(山鳶尾)' 'versicolor(變色鳶尾花)' 'virginica(維基利亞鳶尾)']
# DESCR 數據集的描述
res=iris.DESCR
print(res)
# filename 下后到本地保存后的文件名
iris_filename=iris.filename
print(iris_filename)#iris.csv示例2:分析糖尿病數據集
這是回歸數據集,有442個樣本,有可能就有442個目標值。
代碼如下:
# 獲取糖尿病數據集的庫
from sklearn.datasets import load_diabetes
import numpy as np
import pandas as pd
dia=load_diabetes()
# print(dia)
data=dia.data
# print('糖尿病數據的特征的前五條',data[:5])
'''
糖尿病數據的特征的前五條 [[ 0.03807591 0.05068012 0.06169621 0.02187239 -0.0442235 -0.03482076-0.04340085 -0.00259226 0.01990749 -0.01764613][-0.00188202 -0.04464164 -0.05147406 -0.02632753 -0.00844872 -0.019163340.07441156 -0.03949338 -0.06833155 -0.09220405][ 0.08529891 0.05068012 0.04445121 -0.00567042 -0.04559945 -0.03419447-0.03235593 -0.00259226 0.00286131 -0.02593034][-0.08906294 -0.04464164 -0.01159501 -0.03665608 0.01219057 0.02499059-0.03603757 0.03430886 0.02268774 -0.00936191][ 0.00538306 -0.04464164 -0.03638469 0.02187239 0.00393485 0.015596140.00814208 -0.00259226 -0.03198764 -0.04664087]]
'''
#獲取特征名
feature_names=dia.feature_names
print(feature_names) #['age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6']
#獲取目標值
target=dia.target
print(target[:5]) #[151. 75. 141. 206. 135.]
#獲取目標名
# target_names=dia.target_names
# print(target_names[:5]) 因為糖尿病數據集是回歸的,所以它的目標值是線上的點沒有對應的名稱
#獲取糖尿病的描述
res=dia.DESCR
# print(res)注意:
- 因為糖尿病數據集是回歸的,所以它的目標值是線上的點沒有對應的名稱
2.4 sklearn獲取現實世界數據集
(1)所有現實世界數據,通過網絡才能下載后,默認保存的目錄可以使用下面api獲取。實際上就是保存到home目錄
from sklearn import datasets
datasets.get_data_home() #查看數據集默認存放的位置
(2)下載時,有可能回為網絡問題而出問題,要“小心”的解決網絡問題,不可言……
(3)第一次下載會保存的硬盤中,如果第二次下載,因為硬盤中已經保存有了,所以不會再次下載就直接加載成功了。
示例:獲取20分類新聞數據
(1)使用函數: sklearn.datasets.fetch_20newsgroups(data_home,subset)
(2)函數參數說明:
(2.1) data_home
None這是默認值,下載的文件路徑為 “C:/Users/ADMIN/scikit_learn_data/20news-bydate_py3.pkz”
自定義路徑例如 “./src”, 下載的文件路徑為“./20news-bydate_py3.pkz”
(2.2) subset
“train”,只下載訓練集
“test”,只下載測試集
“all”, 下載的數據包含了訓練集和測試集
(2.3) return_X_y,決定著返回值的情況
False,這是默認值
True,
(3) 函數返值說明:
當參數return_X_y值為False時, 函數返回Bunch對象,Bunch對象中有以下屬性*data:特征數據集, 長度為18846的列表list, 每一個元素就是一篇新聞內容, 共有18846篇*target:目標數據集,長度為18846的數組ndarray, 第一個元素是一個整數,整數值為[0,20)*target_names:目標描述,長度為20的list*filenames:長度為18846的ndarray, 元素為字符串,代表新聞的數據位置的路徑當參數return_X_y值為True時,函數返回值為元組,元組長度為2, 第一個元素值為特征數據集,第二個元素值為目標數據集
代碼
import sklearn.datasets as datasets
from sklearn.datasets import fetch_20newsgroups
import numpy as np
import pandas as pd
path=datasets.get_data_home()
news=fetch_20newsgroups(data_home='./src',subset='all')
# print(news.data[0])
# print(news.target_names[:5])data,target=fetch_20newsgroups(data_home='./src',subset='all',return_X_y=True)
2.5數據集的劃分
"""
1. 復習不定長參數
一個"*" 把多個參數轉為元組
兩個"*" 把多個關鍵字參數轉為字典
"""
def m(*a, **b):print(a) #('hello', 123)print(b) #{'name': '小王', 'age': 30, 'sex': '男'}
m("hello", 123, name="小王", age=30, sex="男")2. 復習列表值的解析
list = [11,22,33]
a, b, c = list # a=11 b=22 c=33
a, b = ["小王", 30] #a="小王" b=30
(1) 函數
sklearn.model_selection.train_test_split(*arrays,**options)
參數
(1) *array 這里用于接收1到多個"列表、numpy數組、稀疏矩陣或padas中的DataFrame"。
(2) **options, 重要的關鍵字參數有:test_size 值為0.0到1.0的小數,表示劃分后測試集占的比例random_state 值為任意整數,表示隨機種子,使用相同的隨機種子對相同的數據集多次劃分結果是相同的。否則多半不同strxxxx 分層劃分,填y
2 返回值說明返回值為列表list, 列表長度與形參array接收到的參數數量相關聯, 形參array接收到的是什么類型,list中對應被劃分出來的兩部分就是什么類型
(2)示例
列表數據集劃分
因為隨機種子都使用了相同的整數(22),所以劃分的劃分的情況是相同的。
代碼如下:
# 導入數據集劃分的庫
from sklearn.model_selection import train_test_split
# 1.列表數據集的劃分
x=[1,2,3,4,5,6,7,8,9]#作為特征值
y=['1a','2a','3a','4a','5a','6a','7a','8a','9a']#作為目標值
# x,y的長度要一致
# 直接對特征值進行劃分為訓練集0.8和測試集0.2
x_train,x_test=train_test_split(x,test_size=0.2,shuffle=True,random_state=5)
# shuffle:表示是否打亂,random_state:設置隨機種子
# print(x_train,x_test)#[9, 5, 8, 2, 1, 3, 6] [7, 4]順序是隨機的
# 對特征值和目標值進行劃分為訓練集0.8和測試集0.2
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,shuffle=True,random_state=5)
print(x_train,x_test)#[9, 8, 2, 1, 6, 7, 4] [3, 5]
print(y_train,y_test)#['9a', '8a', '2a', '1a', '6a', '7a', '4a'] ['3a', '5a']
# 劃分時特征值和目標值劃分的位置是一一對應的
注意:
- 1.x(特征值),y(目標值)的長度要一致
- 2.劃分時特征值和目標值劃分的位置是一一對應的
二維數組數據集劃分
# 2.二維數組數據集劃分
x=np.arange(16).reshape(4,4)
y=np.arange(0,160,10).reshape(4,4)
# print(x)
# print(y)
# x,y的長度要一致
# 直接對特征值進行劃分為訓練集0.8和測試集0.2
x_train,x_test=train_test_split(x,test_size=0.2,shuffle=True,random_state=5)
# shuffle:表示是否打亂,random_state:設置隨機種子
# print(x_train,x_test)#[9, 5, 8, 2, 1, 3, 6] [7, 4]順序是隨機的
# 對特征值和目標值進行劃分為訓練集0.8和測試集0.2
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,shuffle=True,random_state=5)
print(x_train)
print("="*20)
print(x_test)
print("="*20)
print(y_train)
print("="*20)
print(y_test)
'''
[[ 4 5 6 7][ 8 9 10 11][12 13 14 15]]
====================
[[0 1 2 3]]
====================
[[ 40 50 60 70][ 80 90 100 110][120 130 140 150]]
====================
[[ 0 10 20 30]]
'''
DataFrame數據集劃分
可以劃分DataFrame, 劃分后的兩部分還是DataFrame
x= np.arange(1, 16, 1)
x.shape=(5,3)
df = pd.DataFrame(x, index=[1,2,3,4,5], columns=["one","two","three"])
# print(df)x_train,x_test = train_test_split(df, test_size=0.4, random_state=22)
print("\n", x_train)
print("\n", x_test)
'''one two three
4 10 11 12
1 1 2 3
5 13 14 15one two three
2 4 5 6
3 7 8 9
'''
字典數據集劃分
可以劃分非稀疏矩陣
用于將字典列表轉換為特征向量。這個轉換器主要用于處理類別數據和數值數據的混合型數據集
1.對于類別特征DictVectorizer 會為每個不同的類別創建一個新的二進制特征,如果原始數據中的某個樣本具有該類別,則對應的二進制特征值為1,否則為0。
2.對于數值特征保持不變,直接作為特征的一部分
這樣,整個數據集就被轉換成了一個適合機器學習算法使用的特征向量形式
代碼如下:
# 字典數據集的劃分
# 引入字典向量化的模塊
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
# 創建一個字典
data = [{'city':'成都', 'age':30, 'temperature':20}, {'city':'重慶','age':33, 'temperature':60}, {'city':'北京', 'age':42, 'temperature':80},{'city':'上海', 'age':22, 'temperature':70},{'city':'成都', 'age':72, 'temperature':40},]
# 將字典進行向量化并轉換為稀疏矩陣
transfer=DictVectorizer(sparse=True)
# 將data進行向量化
data_new=transfer.fit_transform(data)
# print("data_new\n",data_new)
'''
<Compressed Sparse Row sparse matrix of dtype 'float64'with 15 stored elements and shape (5, 6)>Coords Values(0, 0) 30.0(0, 3) 1.0(0, 5) 20.0(1, 0) 33.0(1, 4) 1.0(1, 5) 60.0(2, 0) 42.0(2, 2) 1.0(2, 5) 80.0(3, 0) 22.0(3, 1) 1.0(3, 5) 70.0(4, 0) 72.0(4, 3) 1.0(4, 5) 40.0
'''
data=data_new.toarray()
# print(x,type(x))
'''
[[30. 0. 0. 1. 0. 20.][33. 0. 0. 0. 1. 60.][42. 0. 1. 0. 0. 80.][22. 1. 0. 0. 0. 70.][72. 0. 0. 1. 0. 40.]] <class 'numpy.ndarray'>'''
x=data[:,:5]
y=data[:,5]
# print(x)
# print(y)
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,shuffle=True,random_state=42)
print(x_train.shape,x_test.shape)
print(y_train.shape,y_test.shape)
print(y_train)
'''
(4, 5) (1, 5)
(4,) (1,)
[40. 80. 20. 70.]
'''
注意:
- 因為機器學習時只能對數字進行處理字典中不是數字的鍵不能直接處理,需要進行特征處理(向量化就是把他轉化為數字)
鳶尾花數據集劃分
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
x,y=load_iris(return_X_y=True)
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,shuffle=True,random_state=42)
print(x_train.shape,x_test.shape)
print(y_train.shape,y_test.shape)
print(y_train)
'''
(120, 4) (30, 4)
(120,) (30,)
[0 0 1 0 0 2 1 0 0 0 2 1 1 0 0 1 2 2 1 2 1 2 1 0 2 1 0 0 0 1 2 0 0 0 1 0 12 0 1 2 0 2 2 1 1 2 1 0 1 2 0 0 1 1 0 2 0 0 1 1 2 1 2 2 1 0 0 2 2 0 0 0 12 0 2 2 0 1 1 2 1 2 0 2 1 2 1 1 1 0 1 1 0 1 2 2 0 1 2 2 0 2 0 1 2 2 1 2 11 2 2 0 1 2 0 1 2]'''
現實世界數據集劃分
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
import numpy as np
news = fetch_20newsgroups(data_home=None, subset='all')
list = train_test_split(news.data, news.target,test_size=0.2, random_state=22)
# """
# 返回值是一個list:其中有4個值,分別為訓練集特征、測試集特征、訓練集目標、測試集目標
# 與iris相同點在于x_train和x_test是列表,而iris是
# """
x_train, x_test, y_train, y_test = list
#打印結果為: 15076 3770 (15076,) (3770,)
print(len(x_train), len(x_test), y_train.shape, y_test.shape)


功能,使用canvas實現功能)



)












)