TTRL: Test-Time Reinforcement Learning
TTRL:測試時強化學習

https://github.com/PRIME-RL/TTRL
📖導讀:本篇博客有
🦥精讀版、🐇速讀版及🤔思考三部分;精讀版是全文的翻譯,篇幅較長;如果你想快速了解論文方法,可以直接閱讀速讀版部分,它是對文章的通俗解讀;思考部分是個人關于論文的一些拙見,歡迎留言指正、探討。最佳排版建議使用電腦端閱讀。
目錄
- `🦥精讀版`
- Abstrct
- 1 引言
- 2 測試時強化學習(Test-Time Reinforcement Learning,TTRL)
- 2.1 方法
- 2.2 多數投票獎勵函數
- 3 實驗
- 3.1 實驗設置
- 3.2 主要結果
- 3.3 訓練動態
- 4 討論
- 4.1 問題一:TTRL 的性能究竟有多強?
- 4.2 Q2: TTRL 為什么有效?
- 4.3 TTRL 可能在什么時候失效?
- 5 相關工作
- 5.1 測試時擴展(Test-Time Scaling, TTS)
- 5.2 用于推理的強化學習(RL for Reasoning)
- 6 結論
- 7 局限性與未來工作
- A 術語定義
- A.1 測試時訓練(Test-Time Training, TTT)
- A.2 測試時推理(Test-Time Inference, TTI)
- B 超參數(Hyper-parameters)
- `🐇速讀版`
- 1. 論文的動機
- 2. 提出的方法
- `🤔思考`
🦥精讀版
Abstrct
??本文研究了在沒有顯式標簽的數據上,針對大型語言模型(LLMs)推理任務進行強化學習(RL)的問題。該問題的核心挑戰在于推理階段無法獲得真實標簽(ground-truth),從而難以進行獎勵估計。盡管這一設定看起來難以實現,我們發現測試時縮放(Test-Time Scaling, TTS)中的一些常用方法(如多數投票)可以提供出人意料地有效的獎勵信號,足以驅動RL訓練。為此,我們提出了一種新方法——測試時強化學習(Test-Time Reinforcement Learning, TTRL),該方法可在無標簽數據上使用RL對大型語言模型進行訓練。TTRL通過利用預訓練模型中已有的先驗知識,實現了模型的自我進化。我們的實驗證明,TTRL能在多種任務和模型上持續提升性能。特別地,在AIME 2024測試集中,TTRL僅使用無標簽的測試數據就使Qwen-2.5-Math-7B模型的pass@1性能提升了約159%。更值得注意的是,雖然TTRL僅依賴于Maj@N這一指標進行監督,但其表現已經穩定超過初始模型的上限,并接近那些在帶標簽測試數據上直接訓練的模型性能。我們的實驗結果驗證了TTRL在多任務上的普適性和有效性,并展示了其在更廣泛任務和領域中的應用潛力。

1 引言
??測試時縮放(Test-Time Scaling, TTS)(Zhang 等,2025b;Balachandran 等,2025)代表了一種新興趨勢,用于增強**大型語言模型(LLMs)**的推理能力。近期研究(Snell 等,2024;Liu 等,2025a)表明,相比于預訓練階段的模型擴展(Kaplan 等,2020),TTS在計算效率上更具優勢,能夠以相同的計算資源實現更優的性能表現。大量研究已經探討了通過獎勵模型(reward models)來提升TTS性能(Lightman 等,2023;Yuan 等,2024;Zhang 等,2025a;Zhao 等,2025),其方法包括在解碼階段使用多數投票(Stiennon 等,2020;Nakano 等,2021)和**蒙特卡洛樹搜索(Monte Carlo Tree Search)**等策略。最近的一些領先的大型推理模型(Large Reasoning Models, LRMs),例如 DeepSeek-R1(Guo 等,2025)和 OpenAI 的 o1 模型(El-Kishky 等,2025),表明**強化學習(Reinforcement Learning, RL)**在提升長鏈式思維(chain-of-thought, Wei 等,2022)方面發揮著關鍵作用。然而,這些 LRM 模型在處理無標簽、持續涌現的新數據流方面仍面臨巨大挑戰。例如,盡管 OpenAI 的 o3 模型在 ARC-AGI-1 基準上取得了 75.7% 的成功率,但在更具挑戰性的 ARC-AGI-2(2025) 上卻只能解決 4% 的問題。
??這些關于測試時縮放(TTS)的研究清晰地展示了訓練時行為與測試時行為之間的差異,尤其是在關注訓練階段的基于強化學習(RL)的方法中尤為明顯。然而,僅在大規模訓練數據上應用RL方法,在應對新出現的、結構復雜的輸入特征或分布變化時顯得極其不足。最近,測試時訓練(Test-Time Training, TTT)方法逐漸受到關注,該方法允許模型在測試時根據新輸入的數據進行參數更新(Sun 等,2019;2024;Behrouz 等,2024;Akyürek 等,2024)。這些方法為使用RL在測試時微調模型、從而提升其對未見數據的泛化能力,提供了一個自然且前景廣闊的方向。然而,這又引入了一個關鍵問題:在測試時,如何獲得獎勵信號或驗證機制?隨著現實世界任務在復雜性與規模上不斷增長,為RL大規模標注此類數據已變得愈發不可行。這為當前領先模型的持續學習帶來了巨大障礙。
??為了解決上述問題,我們提出了測試時強化學習(Test-Time Reinforcement Learning, TTRL)方法,它通過強化學習實現測試階段的訓練。TTRL 在 rollout 階段使用重復采樣策略,以精確估計標簽并計算基于規則的獎勵,從而使RL可在無標簽數據上開展訓練。通過引入有效的多數投票獎勵機制,TTRL 能夠在缺乏真實標簽的情況下,促使RL訓練高效且穩定地進行。如前所述,現實任務的不斷演化必然會導致無標簽數據比例越來越高,而TTRL則直接應對了在缺少明確監督的條件下訓練模型的問題,研究模型在該關鍵場景下的自我探索與學習能力。從本質上講,TTRL使模型能夠生成自身的學習經驗、估算獎勵并在過程中不斷提升性能。
??在實驗中,將 TTRL 應用于 Qwen2.5-Math-7B 模型,在 AIME 2024 數據集上實現了 159% 的性能提升(從 13.3 提升至 43.3),并在 AMC、AIME 以及 MATH-500 三個數據集上平均提升 84%。這一提升完全是通過自我進化(self-evolution)實現的,無需任何標注訓練數據,且性能提升能夠進一步推廣至其他任務。TTRL 不僅提高了 pass@1 的表現,還通過多數投票機制改進了 測試時縮放(TTS)。此外,我們的初步實驗表明,TTRL 在不同規模和類型的模型上都表現出良好的通用性,并且可以與現有的 RL 算法集成使用。我們還發現,TTRL 具有較高的性能上限這一優勢。這些發現表明,TTRL 在大幅減少對人工標注依賴的同時,具備實現持續學習和大規模無監督強化學習的潛力。以下是幾個關鍵結論:
- 要點總結(Takeaways)
- 多數投票為 TTRL 提供了有效的獎勵估計方式(參見第 §3 節)。
- TTRL 能夠超越自身訓練信號和性能上限(Maj@N),并在效果上接近使用真實標簽直接訓練測試數據的模型(參見第 §4.1 節)。
- 在無監督條件下也可以實現高效且穩定的強化學習(參見第 §4.2 節)。

2 測試時強化學習(Test-Time Reinforcement Learning,TTRL)
??與傳統強化學習不同,傳統RL中智能體從已知的獎勵信號中學習,而TTRL是在無標簽的測試數據上進行訓練。換句話說,模型必須在沒有顯式監督信號的情況下學習和適應。我們將該任務定義如下:
??我們研究的問題是:在測試階段,使用強化學習對預訓練模型進行訓練,而不依賴真實標簽(ground-truth labels)。我們將這一設定稱為測試時強化學習(Test-Time Reinforcement Learning)。
2.1 方法
??圖 2 展示了我們的方法 TTRL 如何應對這一挑戰。在狀態由提示詞 x x x 表示的情況下,模型會根據策略 π θ ( y ∣ x ) \pi_\theta(y \mid x) πθ?(y∣x)(參數為 θ \theta θ)采樣生成一個輸出 y y y。為了在沒有真實標簽的情況下構造獎勵信號,我們通過重復采樣,從模型中生成多個候選輸出 { y 1 , y 2 , … , y N } \{y_1, y_2, \ldots, y_N\} {y1?,y2?,…,yN?}。然后,我們從這些候選輸出中得出一個共識輸出 y ? y^* y?,比如通過多數投票或其他聚合方法生成,該輸出作為最優動作的代理。環境隨后根據采樣動作 y y y 與共識動作 y ? y^* y? 之間的一致性來提供獎勵 r ( y , y ? ) r(y, y^*) r(y,y?)。因此,RL 的目標是最大化期望獎勵: max ? θ E y ~ π θ ( ? ∣ x ) [ r ( y , y ? ) ] (1) \max_\theta \mathbb{E}_{y \sim \pi_\theta(\cdot \mid x)} [r(y, y^*)]\tag{1} θmax?Ey~πθ?(?∣x)?[r(y,y?)](1)接著通過梯度上升法更新參數 θ \theta θ:
θ ← θ + η ? θ E y ~ π θ ( ? ∣ x ) [ r ( y , y ? ) ] (2) \theta \leftarrow \theta + \eta \nabla_\theta \mathbb{E}_{y \sim \pi_\theta(\cdot \mid x)} [r(y, y^*)]\tag{2} θ←θ+η?θ?Ey~πθ?(?∣x)?[r(y,y?)](2)其中 η \eta η 表示學習率。這種方法使得模型能夠在推理過程中進行自我調整,在無需標簽數據的情況下提升其對分布變化輸入的適應能力和性能。
2.2 多數投票獎勵函數
??多數投票獎勵的計算方式是,首先通過多數投票機制來估計一個標簽,然后用該標簽來計算基于規則的獎勵,這些獎勵最終作為強化學習的信號。具體而言,給定一個問題 x x x,我們首先將其輸入到LLM中以生成一組輸出。接著,使用答案提取器處理這些輸出,得到對應的預測答案,記為: P = { y i } i = 1 N P = \{ y_i \}_{i=1}^N P={yi?}i=1N?我們根據公式(Equation 4)對 P P P 應用多數投票機制,作為評分函數 s ( y , x ) s(y, x) s(y,x) 來估計標簽 y y y,即選擇在集合 P P P 中出現頻率最高的預測結果。這個通過多數投票選出的預測結果 y y y 被作為估計標簽,用于計算規則獎勵(rule-based reward)。參考 Guo 等人(2025)的做法,其獎勵函數定義如下: R ( y ^ i , y ) = { 1 , if? y ^ i = y 0 , otherwise (3) R(\hat{y}_i, y) =\begin{cases}1, & \text{if } \hat{y}_i = y \\0, & \text{otherwise}\end{cases}\tag{3} R(y^?i?,y)={1,0,?if?y^?i?=yotherwise?(3)

3 實驗
3.1 實驗設置
模型(Models)
??為了評估 TTRL 在不同基礎模型上的通用性,我們在基礎模型和指令微調模型(instruct models)上都進行了實驗。我們在基礎模型 Qwen2.5-Math-1.5B 和 Qwen2.5-Math-7B(Yang 等,2024)上進行實驗,以評估 TTRL 的擴展能力是否良好。對于指令微調模型,我們使用 LLaMA-3.1-8B-Instruct(Grattafiori 等,2024)以驗證 TTRL 在不同模型家族中的有效性。
基準任務(Benchmarks)
??我們在三個數學推理基準上評估 TTRL 的效果:AIME 2024(Li 等,2024)、AMC(Li 等,2024)和 MATH-500(Hendrycks 等,2021)。在每個基準任務上單獨應用 TTRL 后,我們使用貪婪解碼(greedy decoding)方式來報告pass@1 指標,以確保與先前工作的公平比較。我們還使用了 DeepSeek-R1(Guo 等,2025)中的解碼參數,并在圖6中報告 Avg@64 得分,以提供更可靠的評估。
對比方法(Baselines)
??由于此前尚未有工作探索通過測試時訓練(TTT)提升數學推理能力,我們主要與基礎模型進行對比,以驗證 TTRL 是否能通過自我進化帶來有效性能提升。對于兩個基礎模型,我們也納入了其經過大規模后訓練的指令微調版本進行對比。此外,我們還引用了一些當前主流的 “R1-Zero-Like”模型 作為參考基線,這些模型與我們使用的模型具有類似的結構,并進行了廣泛的強化學習訓練,包括: DeepSeek-R1-Distill-1.5B & 7B(Guo 等,2025),SimpleRL-Zero-7B(Zeng 等,2025), PRIME-Zero-7B(Cui 等,2025),OpenReasoner-Zero-7B(Hu 等,2025b),Oat-Zero-1.5B & 7B(Liu 等,2025b), LIMR(Li 等,2025)。注意:TTRL 的訓練設定不同于這些現有模型,因此嚴格的對比可能存在不公平性。
實現細節(Implementation Details)
??我們在每個基準任務上獨立應用 GRPO 方法(Shao 等,2024)來實現 TTRL。在超參數設置方面,我們使用固定學習率 5 × 1 0 ? 7 5 \times 10^{-7} 5×10?7,并在策略模型中采用 AdamW 優化器。在 rollout 階段,我們每個樣本采樣 64 個響應(MATH-500 為 32 個),使用溫度系數 1.0 進行多數投票標簽估計,并從中下采樣 16 個響應用于訓練。實驗表明,我們的“先投票、后采樣”策略在保持強性能的同時,有效降低了計算成本。生成的最大 token 數被設定為 3072。KL 散度系數(KL coefficient)設為 0,適用于所有實驗。根據數據集大小和任務復雜度,我們將訓練輪數(episode 數)分別設為:MATH:40,AMC:50,AIME:60。

3.2 主要結果
TTRL 在大多數任務和模型上表現優異。 盡管僅依賴于使用無標簽測試數據進行的自我進化,TTRL 依然達到了與現有基于 RL 的大規模有標簽模型相當的性能水平。如表 1 所示,在極具挑戰性的數學推理基準 AIME 2024 上,TTRL 實現了 159.3% 的顯著性能提升,超越了所有基于大規模數據集訓練的模型。進一步地,當將 TTRL 應用于 Qwen2.5-Math-7B 模型時,在三個基準任務中平均帶來 84.1% 的性能提升。
TTRL 具有自然的可擴展性。 另一個值得注意的觀察是:隨著模型規模從 1.5B 增加到 7B,TTRL 在 AIME 2024 和 AMC 上的性能收益也隨之增加,這表明 TTRL 具有良好的規模擴展特性。較大的模型能夠在自我改進過程中產生更準確的多數投票獎勵,從而在新數據上實現更有效的學習。然而,LLaMA-3.1-8B-Instruct 和 Qwen2.5-Math-1.5B 在 AIME 2024 上通過 TTRL 并未獲得顯著提升,這很可能是由于其模型容量受限。相比之下,Qwen2.5-Math-7B 擁有更大的模型容量和更充足的知識基礎,使其能夠更好地從自我進化中獲益,并獲得顯著性能提升。我們將在第 4.3 節 中對此進行更詳細的討論。

TTRL 的泛化能力遠超目標任務。 我們在每個基準任務上單獨應用 TTRL,并使用 Qwen2.5-Math-7B 作為主干模型在其他基準任務上進行進一步評估。圖3展示了相關結果。盡管這種設置具有分布外(out-of-distribution) 的特點,TTRL 在所有基準任務上都實現了顯著性能提升。這說明:TTRL 并非依賴于過擬合某一任務而犧牲其他任務表現,而是能夠在自我改進過程中獲得具有泛化能力的提升。
TTRL 兼容多種強化學習算法。 圖4展示了相關結果。我們在 MATH-500 上使用 PPO(Schulman 等,2017)來評估 TTRL 與不同 RL 算法的兼容性。實驗發現,PPO 與 GRPO 的表現軌跡高度一致。與 GRPO 相比,PPO 表現出更穩定的結果,同時總體性能也相當。

3.3 訓練動態
由于測試數據中缺乏真實標簽,因此在訓練過程中評估 TTRL 的性能是一項挑戰。為緩解這一限制,我們引入了一組專門設計用于訓練過程監控和評估 TTRL 有效性的訓練時指標。這些指標有助于選擇最佳 checkpoint,并為訓練過程中的動態變化提供重要洞見。圖 5 展示了在 AIME 2024 上,以 Qwen2.5-Math-7B 為例的兩個 TTRL 曲線。
- Entropy(熵):衡量模型生成輸出的不確定性。
- Majority Voting Reward(多數投票獎勵):基于多數投票標簽計算得到的規則獎勵。
- Majority Ratio(多數比率):在一次 rollout 中最常出現答案的頻率。
此外,我們還定義了若干依賴真實標簽的指標,以便在訓練過程中對模型行為進行更深入的分析:
- Label Accuracy(Maj@N):表示估計標簽是否與真實標簽一致。
- Reward Accuracy:表示基于估計標簽計算出的獎勵中,有多少比例與真實標簽計算出的獎勵一致。
- Ground-Truth Ratio(真實標簽比率):在 rollout 中真實標簽出現的頻率。
4 討論
4.1 問題一:TTRL 的性能究竟有多強?
- 要點總結(Takeaways)
-
TTRL 不僅超越了自身的訓練信號和直觀上限 Maj@N,還接近于使用有標簽測試數據訓練的直接 RL 模型的性能。這種提升可能得益于 TTRL 在測試時訓練中采用了 RL:通過將基于投票的偽標簽轉化為獎勵,TTRL 提升了監督信號的有效性(例如:準確率,見 §4.2),同時擺脫了 Maj@N 所帶來的限制性約束。
-
TTRL 的經驗上限是直接在測試數據上訓練模型(即“以測代訓”),這顯示出其相較于傳統訓練-評估流程的顯著優勢。
-
在復雜任務中,TTRL 甚至能僅憑 1.5B 模型達到經驗上限, 這說明大語言模型(LLMs)可以通過 TTRL 實現高效的自我進化,從而實現大規模數據集上的終身學習。
??我們通過兩個上限來分析 TTRL 的潛在性能: 第一個上限是 Maj@N,即 TTRL 訓練中用于計算獎勵的基于多數投票的偽標簽;第二個上限是:直接在基準測試集上使用真實標簽進行訓練,該方法假設訪問了 ground-truth 標簽,因而會將標簽信息直接傳遞給策略模型。
TTRL 受 Maj@N 監督,但超越了它。由于 TTRL 使用自身多數投票輸出作為強化學習的監督信號,因此這種基于投票的性能通常被視為模型性能的上限。然而,我們觀察到一個令人驚訝的現象:訓練后,模型不僅匹配了這個預期上限,甚至超越了它。這表明:模型超越了自己輸出所構成的監督信號質量。圖 6 顯示了 TTRL 在 Qwen2.5-Math-7B 上的結果。TTRL 的 Avg@64 成績在所有基準任務上均超越 Qwen2.5-Math-7B 的 Maj@64,遠超我們的預期。此外,一旦引入多數投票機制,TTRL 的性能有了顯著提升。這表明大語言模型可通過自身生成數據進行訓練并獲得性能提升。更重要的是,通過一個自我強化(self-reinforcing)的閉環,模型能夠“拽著自己的靴帶把自己拉起來”,突破原本的性能天花板。
TTRL 的性能提升接近直接在測試集上的訓練。TTRL 的動機是通過多數投票估計標簽,從而獲取更準確的獎勵,在沒有真實標簽的數據上通過 RL 實現有效的自我改進。因此,TTRL 的自然上限是:直接在測試集上執行 RL(即“leakage”訓練)。雖然由于信息泄露問題,這種設置鮮有被采用或研究,但它代表了在特定數據集上提升性能的最高效方式,其效率遠超傳統的訓練-評估范式。我們使用 Qwen2.5-Math-7B 在 MATH-500 上分別運行 TTRL 和 RL(leakage),圖 7 展示了兩者結果。我們驚訝地發現,TTRL 的性能曲線幾乎接近 RL(leakage),這說明:
-
TTRL 在無監督設置下的自我改進效果可與有監督學習相媲美,即便在信息泄露場景中也能達到極高性能,證明其效率與提升潛力。
-
TTRL 顯示出即使是小規模模型(如 1.5B)也能通過 RL 實現有效自我改進與持續學習。
例如,在 MATH-500 上,Qwen2.5-Math-1.5B 從初始的 33.0 提升到 80.0,性能提升了 142.4%,展示了 TTRL 所帶來的清晰自我增強能力。



4.2 Q2: TTRL 為什么有效?
??本節從兩個關鍵方面對 TTRL 在無監督條件下實現穩定且高效的強化學習機制進行了分析:標簽估計(Label Estimation) 和 獎勵計算(Reward Calculation)
標簽估計(Label Estimations)
??TTRL 與標準 RL 算法之間的一個直接區別是:TTRL 涉及標簽估計,而這會引入獎勵誤差。
盡管如此,我們認為 TTRL 依然有效的原因有以下兩點:(i) 現有研究表明,RL 能容忍一定程度的獎勵誤差。而且相比依賴記憶訓練數據的監督微調(SFT),RL 更具泛化能力(Chu 等,2025)。在 RL 中,獎勵信號通常是模糊的,主要作為探索方向的引導信號,這使得 RL 對獎勵噪聲具有魯棒性(Razin 等,2025)。(ii) 還有研究從優化角度探討了一個優秀的獎勵模型應具備哪些特性,發現:更精確的獎勵模型并不一定是更好的教師(Wang 等,2020)。因此,由策略模型本身生成的獎勵信號反而可能提供更適合的學習引導。
獎勵計算(Reward Calculations)
??當模型能通過多數投票正確估計標簽時,后續生成的獎勵信號通常是可靠的。但接下來我們面臨一個自然的問題:即便模型在 AIME 2024 等具有挑戰性的任務中未能估計出準確標簽,TTRL 為什么依然有效?根本原因在于 RL 中獎勵的定義方式:基于規則的獎勵是根據預測結果是否與“標簽”一致而賦值的。因此,即使估計的標簽不是真實標簽,只要它能識別預測答案與其不一致,系統依然可以給出正確的“負向”獎勵。
??為了更詳細地進行案例分析,我們在 AIME 2024 基準上、以 Qwen2.5-Math-7B 為基礎模型,評估了 TTRL 的性能。圖 8 展示了三項指標的變化曲線。我們識別出 TTRL 在 AIME 2024 上依然有效的兩個主要原因:
??第一,獎勵比標簽更密集(dense),從而帶來更高的魯棒性。這意味著即使估計的標簽不準確,模型仍有更多機會從其他學習信號中恢復有用信息。例如,即使估計標簽是錯誤的,在同一次 rollout(采樣)中生成的其他輸出仍有可能產生正確或高質量的獎勵(如圖 9 所示)。這使得整體獎勵信號對偽標簽誤差更具魯棒性。
??第二,一個有趣的現象是:當模型能力較弱時,TTRL 的獎勵反而可能更準確。以基礎模型為例:其最常出現的預測僅占所有預測的 16.6%(見圖 8)。這說明即使標簽估計不準確,大部分預測仍能收到正確的獎勵,因為模型的輸出高度多樣、錯誤分布均勻(如圖 9 所示)。這實際上形成了一種“悖論式提升”:模型越弱,錯誤越分散,獎勵估計反而更準確。一個實證觀察支持上述觀點:即 標簽準確率(Label Accuracy) 與 獎勵準確率(Reward Accuracy) 的對比(見圖 8):標簽準確率波動在 20%-50%;而獎勵準確率一開始就達到 92%,非常驚人!這樣的高獎勵準確率,為測試集上的有效自我改進提供了堅實基礎。



4.3 TTRL 可能在什么時候失效?
??從算法層面來看,TTRL 與現有的強化學習(RL)算法在本質上并無區別,因此也繼承了后者的一些特性,例如:對數據難度敏感、對先驗信息依賴較強、在某些條件下容易“崩潰”(collapse)等問題。在實現層面,這些問題會被進一步放大。TTRL 依賴多數投票估計標簽,且僅在測試數據上運行,而這些數據往往稀疏且前所未見,因此在某些場景下可能導致訓練失敗。在初步實驗中,我們識別出兩類潛在問題:
缺乏目標任務的先驗知識
??先驗知識在強化學習中起著關鍵作用,通常決定了 TTRL 學習過程的成敗。這是因為測試數據通常更難,且包含新的特征,而 TTRL 并未使用諸如數據篩選等機制來支持課程式學習(curriculum learning)。
??因此,對于同一個 backbone,如果模型的先驗知識不足以應對數據的復雜性,TTRL 就會失敗。我們推測,在 AIME 2024 上 Qwen2.5-Math-1.5B 和 LLaMA-3.1-8B-Instruct 性能無提升的原因即是如此。考慮到 TTRL 在其他復雜度較低的基準測試中表現良好,這種失敗可能源于模型先驗不足。
??為進一步驗證這一假設,我們在 MATH-500 上進行了消融研究。我們根據標注的難度等級將 MATH-500 分為五個子集(從1到5),并分別對每個子集獨立應用 TTRL,使用 Qwen2.5-Math-1.5B 模型。然后我們將結果與該 backbone 的性能進行比較,如表2所示。我們觀察到,隨著問題難度的增加,性能提升和長度縮減比率都呈下降趨勢。這表明 backbone 的現有先驗知識不足以支持對更難問題的學習。
不合適的強化學習超參數
??超參數設置在強化學習中起著關鍵作用,并常常導致訓練失敗。在 TTRL 中,超參數的影響被進一步放大,因為獎勵估計中可能存在的噪聲以及測試數據的特性。圖10 展示了在 AIME 2024 上幾次失敗嘗試的對比。兩個失敗的實驗在訓練過程中始終維持高熵輸出,與 He 等人(2025)的發現一致。在初步實驗中,我們確定了兩個關鍵的超參數,對訓練穩定性和成功與否具有顯著影響Temperature(溫度):將 temperature 設置為 1.0(而不是 0.6)會增加模型輸出的熵。這種設置鼓勵更廣泛的探索,使模型能夠更好地利用其先驗知識進行自我改進,這對于處理具有挑戰性的基準測試尤其重要。Episodes(訓練輪數):鑒于各數據集在大小和難度上的差異,規模更小且更難的數據集需要更多的訓練輪次,以實現足夠的探索。
5 相關工作
5.1 測試時擴展(Test-Time Scaling, TTS)
測試時擴展(TTS) 的設計目標是通過在測試階段增加計算資源,提升大語言模型(LLMs)在處理復雜任務時的能力。已有研究(Snell 等,2024;Liu 等,2025a)表明,相比于在預訓練階段擴展計算,TTS 更為高效(Kaplan 等,2020)。因此,將相同的計算資源從預訓練階段重新分配至測試階段,有望帶來更顯著的模型性能提升。當前關于 TTS 的研究主要分為兩類(Welleck 等,2024):并行生成(parallel generation) 和 序列生成(sequential generation)。并行生成:讓 LLMs 同時生成多個候選答案,包括:自一致性(self-consistency)(Wang 等,2022;Chen 等,2023),最優選擇(best-of-N)(Stiennon 等,2020;Nakano 等,2021),決策步驟(decision steps,例如蒙特卡洛樹搜索 Monte Carlo Tree Search)(Zhou 等,2023;Xie 等,2024),基于 token 的搜索(如獎勵引導搜索 Reward-guided Search)(Deng & Raffel, 2023;Khanov 等,2024)。推理過程中,隨后會使用聚合策略整合這些候選結果,常見方式是基于過程的獎勵模型(Lightman 等,2023;Wang 等,2023;Zhang 等,2025a)來進行評分。序列生成:關注于拓展 LLMs 輸出,使其生成更長的回答,通常伴隨反思(reflective)和思維鏈條(chain-of-thought)推理過程(Wei 等,2022;Madaan 等,2023)。盡管提示工程(prompting)技術被廣泛采用,但其效果常受限于基礎模型的能力。值得注意的是,DeepSeek-R1(Guo 等,2025)是該領域的一個代表性進展。該方法在預訓練語言模型中實現了基于結果的強化學習,具體為群體相對策略優化(Group Relative Policy Optimization, GRPO)(Shao 等,2024),顯著增強了其推理能力。與第一類方法(需要過程級監督)相比(Yuan 等,2024),第二類方法的可擴展性更強,因其依賴于基于規則的獎勵信號。
??除了前述專注于擴展測試時推理計算的方法之外,另一種提高測試時計算能力的途徑是測試時訓練(Test-Time Training, TTT)。我們在附錄 A 中介紹了這些術語之間的關系。以往的研究主要聚焦于視頻生成與理解等應用(Hardt & Sun, 2024;Dalal 等,2025),以及在一定程度上聚焦于大型語言模型(Wang 等,2025;Akyürek 等,2024),但將測試時擴展與強化學習結合起來的研究仍然基本未被深入探索。
5.2 用于推理的強化學習(RL for Reasoning)
??強化學習(Reinforcement Learning, RL)在增強大語言模型(LLMs)遵循指令的能力方面發揮著關鍵作用,尤其是通過諸如“來自人類反饋的強化學習”(RLHF)等方法。RLHF 使用如 Proximal Policy Optimization(PPO)等算法使基礎模型對人類偏好進行對齊。近年來,大型推理模型(Large Reasoning Models, LRMs),如 DeepSeek-R1,已經通過基于規則的獎勵展現出強化學習在提升推理能力方面的重要性,這一點在 GRPO 中表現得尤為明顯。與 RLHF 主要面向開放領域指令不同,GRPO 特別設計用于在數學問題求解中引導出長鏈式思維(Chain-of-Thought, CoT)推理。近期研究主要集中于提高基于規則的強化學習方法(如 GRPO 和 PPO)的訓練穩定性。
??然而,這些方法通常僅在有監督的訓練數據上訓練 LLM,而推理時則需要在未見過的測試問題上生成擴展的 CoT 推理。此外,目前的強化學習方法依賴于可驗證的輸出(如數學或代碼解答),這些輸出可以提供可靠的獎勵信號。但在實際應用中,這類可驗證條件往往難以滿足,甚至無法實現。新興研究提出了一種范式轉變:從依賴人類標注數據轉向依賴交互經驗進行學習。在這種背景下,策略模型(policy model)生成和標注自身訓練數據的能力變得愈加重要。
??TTRL 提出了一種利用自標注獎勵進行強化學習的初步嘗試,邁出了從經驗交互中學習的第一步。
6 結論
??在本文中,我們提出了測試時強化學習(TTRL)這一新穎框架,用于在無真實標簽的測試數據上,通過強化學習(RL)訓練大型語言模型。TTRL的一個關鍵組成部分是其多數投票獎勵函數,它基于模型預測的一致性生成規則驅動的獎勵。我們的實驗結果展示了****TTRL的強大潛力,在多種模型和任務上實現了持續的性能提升。我們將TTRL視為邁向“使用自標注獎勵進行強化學習”的初步嘗試,標志著從連續經驗流中學習的一個重要方向。
7 局限性與未來工作
局限性
??本研究是基于自標注獎勵的測試時強化學習的一次初步探索。盡管實驗結果令人鼓舞,但仍存在一些需要進一步研究的問題。特別是,我們計劃對“先驗知識”和“超參數配置”的影響進行更深入的分析,這兩者在強化學習的動態過程中起著關鍵作用。我們將在后續版本中提供更全面的討論和消融實驗。
未來工作
??基于現有發現,我們為未來研究提出以下幾個方向:
-
理論分析:開展TTRL的形式化收斂性分析,重點研究其向 §4.1 中兩個上界收斂的能力。
-
流式數據下的在線學習:將TTRL擴展到實時學習場景,使模型能夠與不斷到來的數據進行交互并動態適應,即“測試時自適應”(Liang 等人,2025)。
-
大規模自監督強化學習訓練:將TTRL擴展到大規模數據集和模型,探索其在無需人工標注數據的自監督框架中的潛力。
-
Agent任務與科學發現:將TTRL應用于更復雜的開放領域,如agent任務和多步推理的科學探索等。
A 術語定義
??測試時擴展(Test-Time Scaling, TTS) 指的是在模型推理階段增加計算資源的方法,可以細分為:測試時訓練(Test-Time Training, TTT),測試時推理(Test-Time Inference, TTI)。這兩種方式是互補的。我們將在下文介紹它們之間的關系。

A.1 測試時訓練(Test-Time Training, TTT)
??測試時訓練(TTT)是一種在推理過程中適配預訓練模型的技術,旨在應對分布漂移(distribution shifts)以提升泛化能力。設 f θ f_{\theta} fθ? 為在源域 D s = { ( x i , y i ) } i = 1 N \mathcal{D}_s = \{(x_i, y_i)\}_{i=1}^N Ds?={(xi?,yi?)}i=1N? 上訓練得到的模型,其中 x i ∈ X x_i \in \mathcal{X} xi?∈X, y i ∈ Y y_i \in \mathcal{Y} yi?∈Y,而 θ \theta θ 表示模型的參數。在標準推理過程中,模型會以固定參數 θ \theta θ 在測試樣本 x t ~ D t x_t \sim \mathcal{D}_t xt?~Dt? 上進行評估,且 D t ≠ D s \mathcal{D}_t \neq \mathcal{D}_s Dt?=Ds?。
??相反,TTT 允許模型在推理時對每個測試樣本 x t x_t xt? 進行自適應微調,通過最小化一個輔助的自監督損失 L aux \mathcal{L}_{\text{aux}} Laux?,而無需訪問標簽 y t y_t yt?。模型參數會在推理過程中在線更新,該輔助任務通常是無標簽的,且與主任務保持一致。
A.2 測試時推理(Test-Time Inference, TTI)
??測試時推理(TTI)指的是在推理過程中,通過分配額外的計算資源來提升大型語言模型性能的一種策略。形式化地,設 f θ f_\theta fθ? 表示一個參數為 θ \theta θ 的語言模型, x x x 是輸入提示(prompt)。模型通過從條件分布 p θ ( y ∣ x ) p_\theta(y \mid x) pθ?(y∣x) 中采樣生成輸出 y y y。TTI 技術旨在提升輸出 y y y 的質量,方法包括:生成多個候選輸出,然后基于打分函數選擇最佳輸出,或通過迭代過程不斷優化輸出(Welleck et al., 2024)。
??一種常見方法是生成 N N N 個候選輸出 { y 1 , y 2 , … , y N } \{y_1, y_2, \ldots, y_N\} {y1?,y2?,…,yN?},然后使用打分函數 s ( y , x ) s(y, x) s(y,x) 選擇最優輸出 y ? y^* y?:
y ? = arg ? max ? y i s ( y i , x ) (4) y^* = \arg\max_{y_i} s(y_i, x) \tag{4} y?=argyi?max?s(yi?,x)(4)
打分函數 s ( y , x ) s(y, x) s(y,x) 可以通過多種方式實現,例如:
- 多數投票(Majority Voting, MV):在候選輸出中選擇出現次數最多的結果。
- Best-of-N (BoN):使用獎勵模型(reward model)對每個候選項進行打分,并選擇得分最高者。
- 加權BoN(Weighted BoN):結合 MV 和 BoN 兩種策略,利用各自的優勢進行加權融合。
B 超參數(Hyper-parameters)
??為了實現我們工作的完全可復現性,我們提供了一個完整的訓練方案,該方案主要基于 OpenRLHF(Hu et al., 2024)。我們以在 AIME 2024 基準上的 TTRL 訓練過程為例,所用模型為 Qwen2.5-Math-7B。

🐇速讀版
1. 論文的動機
??這篇文章主要針對的是提升LLM的推理能力。對于推理模型來說,傳統的訓練策略是在大量預訓練數據上進行一些預訓練(比如掩碼訓練,next token預測等),然后在帶標簽的數據上進行后訓練(比如SFT或者RL),最后在實際場景的真實數據上應用訓練好的模型,如下圖。但隨著模型越來越大,這種策略出現了一系列弊端,比如,模型的訓練成本飆升;其次,互聯網上可以拿來訓練的數據也幾乎已經用盡,當訓練數據有限的情況下,根據scaling law,大模型性能會到達一個上限瓶頸。那在這種情況下,我們還能不能進一步提升大模型的推理能力?

??這時候就出現了一種新的策略,叫做測試時擴展(Test-Time Scaling,TTS)。它的意思就是說,當模型在真實的測試數據上進行推理的時候,提供給模型更多的計算量,進而可以優化推理過程,提升大語言模型的性能。一個典型的例子就是思維鏈(CoT),它的思想就是把一個復雜問題拆解為多步來回答,這個過程實際上就是花費了更多的計算量,換來了推理性能的提升,所以CoT就是一個典型的測試時擴展的方法。但是,TTS也有一些局限性,它依賴模型預訓練的知識,在面對未標注新數據或OOD數據時,泛化能力有限。

??這時候又出現了一個新的策略,測試時訓練(Test-Time Training,TTT)。它的意思就是在測試時進行訓練(也就是模型參數更新),使模型適應新數據或任務,從而彌補了 TTS 在泛化能力上的不足。

??同時,最近一些大的推理模型,比如DeepSeek-R1、OpenAI的o1模型都表明,RL在提升模型推理能力方面至關重要。那自然而然的,我們就會想,能不能在測試階段應用RL來訓練模型?但這時候就會面臨一個關鍵的問題:我們都知道,RL是需要reward信號來優化模型的policy分布的,由于測試數據沒有ground tuth的label,那我們應該如何獲得獎勵信號呢? 這篇文章就以此為動機,提出了TTRL,解決了在沒有顯式標簽的數據上,針對大型語言模型推理任務進行強化學習的問題。

2. 提出的方法
??論文要解決的問題是測試數據沒有標簽的情況下進行強化學習,所提出的方法實際上非常straightforward,思路核心就是多數投票機制。它的意思是說,當你給到LLM一個沒有標簽的測試數據,比如下圖中紅色字體舉例的一個數學問題:What is the median of 2 and 8?,正常來說LLM會輸出一個回答,而這篇文章是讓模型多次回答這個問題得到多個回復。比如圖中紅色數字給到的不同回復結果:5,6,10,5,然后選擇這些回復中最多次出現的那個答案,比如這里的5,將其作為這個測試數據的偽標簽,這樣就解決了測試數據沒有標簽的問題。接著再讓這個偽標簽當作計算reward時候的ground truth label,去計算reward。這里的reward函數也很簡單,對于回答中,是5的就打分為1,否則就是0,進而優化policy分布,這樣就能夠進行強化學習。

??上面就是這篇文章的解決方法,simple yet effective!在三個Benchmarks都取得了非常明顯的提升:
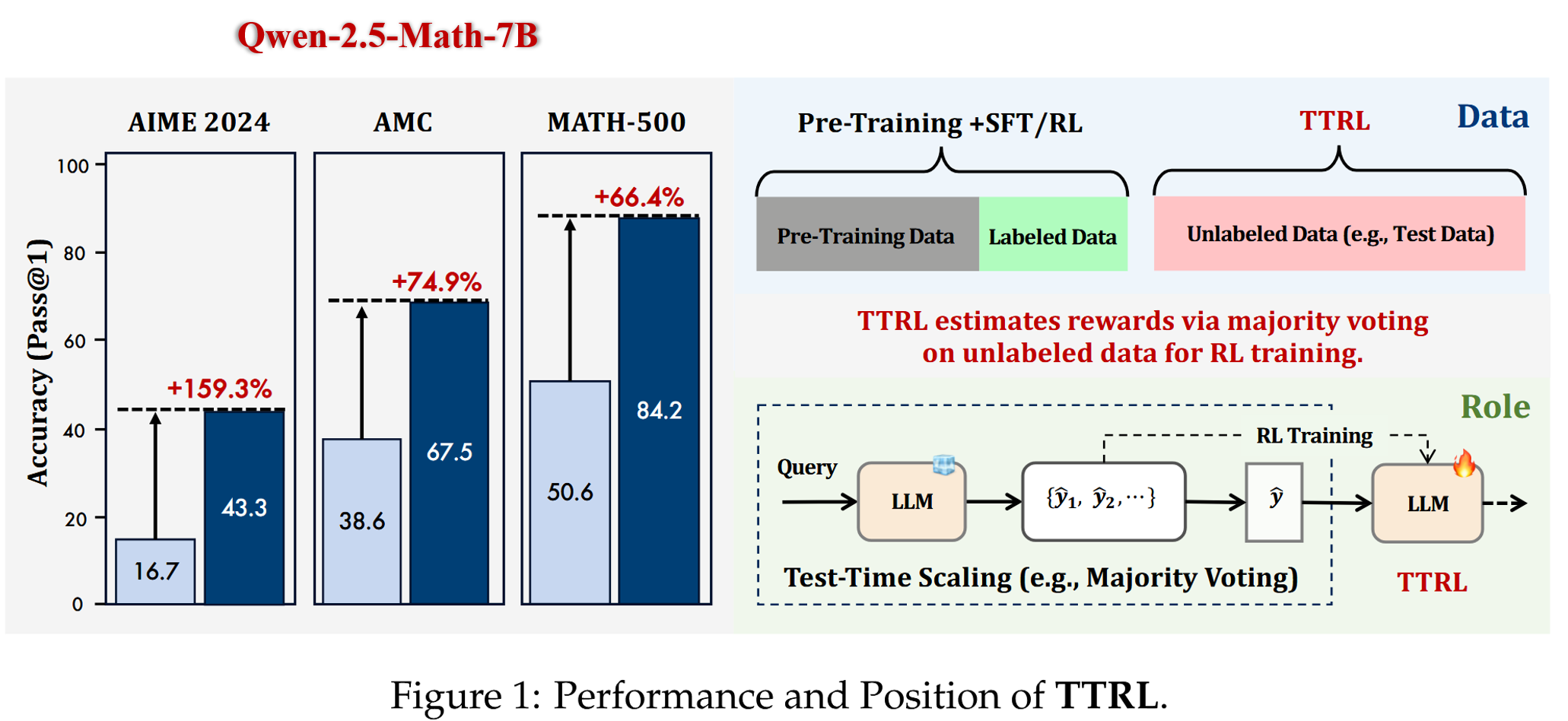
??這篇文章比較有啟發性的部分在于Discussions章節作者針對所提出的TTRL方法的上限以及它為什么有效展開了探討,并給出了合理的解釋,這部分建議感興趣的讀者閱讀上面🦥精讀版部分的原文對應章節,在讀完后或許你就能夠理解下面這張圖的含義:

🤔思考
??TTRL這篇文章是2025年4月22日上線在arXiv的一篇文章,它的思路其實和下圖這篇2022年的文章思路很類似,不同之處在于,下面這篇文章是通過SFT來進行微調模型的,而TTRL是通過RL微調模型。其實TTRL的方法在一些環節上可以進一步的探索,比如偽標簽的產生,或許可以在一些安全對齊或者模型去毒任務上替換為基于不同logits分布的方法來選擇偽標簽,而非多數投票。reward函數的設計或許也可以針對其他任務實驗BT loss的方法進行對比評分。

??這篇文章清晰的展示出了RL的潛力,尤其是相較于SFT而言。在論文的討論章節給到了很多很有啟發性的探討,值得深思。最后,個人認為這篇文章有一個小的局限性在于只在數學task上進行的實驗,而沒有在其他推理任務(如coding task)上驗證方法的普適性,這也為未來在更復雜任務場景中進一步拓展TTRL提供了可能的路徑。
參考文獻
@article{zuo2025ttrl,
title={TTRL: Test-Time Reinforcement Learning},
author={Zuo, Yuxin and Zhang, Kaiyan and Qu, Shang and Sheng, Li and Zhu, Xuekai and Qi, Biqing and Sun, Youbang and Cui, Ganqu and Ding, Ning and Zhou, Bowen},
journal={arXiv preprint arXiv:2504.16084},
year={2025}
}






)




5 - usbutils編譯(更新lsusb))


)




)