Attentive Collaborative Filtering: Multimedia Recommendation with Item- and Component-Level Attention
Attentive Collaborative Filtering (ACF)、隱式反饋推薦、注意力機制、貝葉斯個性化排序
標題翻譯:注意力協同過濾:基于項目和組件級注意力的多媒體推薦
原文地址:點這里
摘要
多媒體內容正主導著當今網絡信息。用戶與多媒體項目之間的互動通常是二值的隱式反饋(例如照片點贊、視頻觀看、歌曲下載等),相比顯式反饋(如商品評分),這種隱式反饋能以更低的成本、大規模地收集。然而,大多數現有的協同過濾(CF)系統在多媒體推薦場景中并不理想,因為它們忽略了用戶與多媒體內容互動中的“隱式性”。我們認為,在多媒體推薦中,存在兩層“隱式”——項目層面(item-level)和組件層面(component-level),它們模糊了用戶真實的偏好。項目層面隱式性指用戶對整個項目(照片、視頻、歌曲等)的偏好強度未知;組件層面隱式性指用戶對項目內部不同組成部分(例如圖像的不同區域、視頻的不同幀)的偏好也未知。比如一次“觀看”操作既不告訴我們用戶到底多喜歡這段視頻,也不告訴我們他對視頻哪個部分感興趣。
為了解決這兩層隱式反饋帶來的挑戰,論文提出了一種將**注意力機制(Attention)**引入協同過濾的新框架——Attentive Collaborative Filtering (ACF)。該方法由兩個子模塊組成:
- 組件級注意力模塊:以任意內容特征提取網絡(如用于圖像/視頻的 CNN)為基礎,自動學習為項目中的各個組成部分分配權重,從而挑選出最有信息量的部分;
- 項目級注意力模塊:根據用戶和項目的特征,為不同項目分配權重,以建模用戶對各項目的真實興趣強度。
ACF 能無縫集成到經典的隱式反饋 CF 模型(如 BPR、SVD++)中,并可通過隨機梯度下降高效訓練。實驗證明,在 Vine 和 Pinterest 兩個真實的多媒體網絡服務數據集上,ACF 顯著優于現有最先進的 CF 方法。
一、引言
當我們登錄多媒體網絡服務(例如 YouTube)時,就像其他數十億用戶一樣,我們可以隨時瀏覽和分享線上數十億條內容。同時,隨著移動設備的發展,數以百萬計的新圖片和視頻正不斷涌入這些網站。以 Snapchat 為例——這是最受歡迎的視頻社交應用之一——在您閱讀此段文字的過程中,約有 5 萬段視頻片段被分享,2.4 百萬次視頻被觀看。毫無疑問,日益占據主導地位的網頁多媒體內容,需要尤其是基于協同過濾(CF)的現代推薦系統,在高度動態的環境中為用戶篩選出海量內容。
協同過濾(CF)通過分析用戶之間的關系和項目之間的相互依賴,以發現新的用戶–項目關聯【21,?23,?37】。在多媒體推薦中,“項目”指用戶消費的各種多媒體內容,如視頻、照片或歌曲。大多數 CF 系統依賴顯式的用戶興趣作為輸入,例如商品的星級評分,這提供了顯式反饋【19,?25,?38】。然而,在許多應用場景中并不總能獲得顯式評分。由于多媒體內容的規模龐大且類型多樣【15】,多媒體推薦系統中固有的用戶–項目交互通常基于隱式反饋,如**視頻的“觀看”、照片的“點贊”、歌曲的“播放”**等。由于隱式反饋缺少用戶不喜歡哪些項目(即負反饋)的直接證據,現有基于隱式反饋的 CF 方法【20,?21,?30】通常側重于如何將缺失的用戶–項目交互納入偏好建模。但很少有方法深入挖掘用戶偏好的“隱式”特征。我們認為,在多媒體推薦中存在兩層隱式反饋,這一點在大多數現有 CF 方法中尚未得到充分考慮。
項目層面的隱式反饋(Item-Level Implicit Feedback)。通過追蹤用戶的消費行為,每位用戶都會關聯上一組項目(即正向反饋)。然而,這組正反饋的項目并不意味著用戶對它們的喜好程度是相同的。這種現象在多媒體服務中尤為普遍,因為大多數此類服務具有社交屬性。例如,一些被用戶“點贊”的圖片可能僅僅是因為拍攝者是朋友,而并非出于用戶的真實興趣。即便是那些確實符合用戶興趣的圖片,用戶對它們的喜好程度也可能不同。這種無法獲取每個項目具體偏好程度的情形,被稱為項目層面的隱式性(item-level implicitness)。為了更好地刻畫用戶的偏好畫像,針對項目層面的隱式反饋,需要對不同項目給予不同的“注意力”權重。然而,據我們所知,現有的協同過濾模型通常使用統一權重【23】或預設的啟發式權重【21】,因此基于這些固定加權方式得到的鄰域上下文,難以有效建模項目層面的隱式反饋。
通俗地說,項目層面的隱式反饋就是:
用戶給了一批“喜歡”或“看過”的東西,但這些標記并不告訴我們他們到底有多喜歡每一件——有的只是隨手點點贊,有的是真心喜歡。
舉個例子:你在朋友圈里點了好幾張朋友的照片“贊”,可你并不一定真正喜歡每一張,也可能只是禮貌或因為對方是好友。
換到推薦系統里,就是說系統知道你看過或點過贊的項目,但不知道你對它們的真實偏愛度。所以,為了更準確地推薦,就需要給不同項目分配不同“重要度”——也就是給真正喜歡的項目更高的“注意力”權重,而不是把它們都當成一樣。
組件層面的隱式反饋(Component-Level Implicit Feedback)。對多媒體內容的反饋通常只在整體項目層面,而多媒體內容本身往往蘊含多種語義和多個組成部分。我們將組件層面的隱式性定義為無法獲得針對各個組件的單獨反饋的情形。以一場籃球比賽視頻為例,整段視頻包含多名球員和豐富的動作。一位用戶對該視頻的“播放”反饋,不一定意味著他喜歡視頻的全部內容,可能只是因為對視頻最后展示比賽最終比分的片段感興趣。因此,與僅把多媒體內容視為整體的傳統基于內容的協同過濾方法【4,?12】不同,我們應當建模用戶對低層次內容組件的偏好,比如圖像中不同位置的特征【39】或視頻中各幀的特征【6,?10,?41】。
通俗地說,組件層面的隱式反饋就是:
- 系統知道你看過、聽過或點過贊一個多媒體項目(比如一段視頻或一張圖片),
- 但它不知道你到底是因為哪個“部分”才感興趣——可能是視頻里的某個精彩片段,或者圖片里一個小細節,
- 換句話說,就是你對項目整體做了“喜歡”或“播放”,卻沒有對項目中的各個組成部分(幀、區域、音段等)打標簽,系統只能把整段內容一起看,無法針對最吸引你的那部分做出更精準的推薦。
然而,直接對項目層面和組件層面的隱式反饋進行建模以改進推薦并非易事,因為這兩層隱式反饋的真實標簽(ground truth)是不可得的。為了解決這一問題,我們提出了一種新穎的協同過濾框架——Attentive Collaborative Filtering(ACF),它能夠以遠程監督的方式,自動為兩層隱式反饋分配權重。
ACF 基于潛在因子模型,將用戶和項目映射到同一隱空間以便進行直接比較;同時,它結合了鄰域模型,通過對用戶歷史交互項目的加權求和來刻畫用戶的興趣畫像,其中項目的權重即反映了兩層隱式反饋的重要性。
- 項目層面建模(Section?4.2):我們設計了一個多層神經網絡作為加權函數,輸入包括用戶特征、項目特征及多媒體內容特征,輸出項目的注意力權重。
- 組件層面建模(Section?4.3):多媒體內容特征本身由對項目中多個組件(如圖像區域或視頻幀)進行加權求和而來;對應的組件注意力模塊也是一個多層神經網絡,輸入為用戶特征和組件特征。所有被賦予注意力的組件共同組成了項目的內容特征向量,作為項目層面注意力網絡的輸入之一。
ACF 可通過隨機梯度下降(SGD)在大規模圖像和視頻的用戶–項目交互數據上高效訓練(Section?4.4)。我們在代表兩類多媒體的真實數據集——Pinterest(圖像)和 Vine(視頻)上對 ACF 進行了全面評估。實驗結果表明,ACF 在各類方法(包括基于 CF 的、基于內容的【28,?35】及混合方法【9,?33】)中均取得了顯著領先(Section?5)。
本文貢獻總結
- 提出首個專門面向多媒體推薦中的隱式反饋問題、引入注意力機制的協同過濾框架 ACF。
- 針對項目層面與組件層面兩種隱式反饋,設計了兩套可無縫嵌入任意鄰域模型、并可端到端通過 SGD 高效訓練的注意力子模塊。
- 在兩個真實多媒體數據集上的廣泛實驗證明了 ACF 相較于多種先進隱式反饋 CF 方法的一致性能提升。
二、相關工作
基于隱式反饋的推薦問題也被稱為單類別問題(one-class problem)【27】,這是因為缺乏負反饋,系統中通常只存在正向反饋(例如點擊、觀看等)。除了這些正反饋之外,剩余的數據既包含了真實的負反饋,也可能只是缺失值。因此,僅憑隱式反饋,很難可靠地判斷用戶到底不喜歡哪些項目。
為了解決負樣本缺失的問題,已有若干方法被提出,大致可分為兩類:基于采樣的方法【20,?27,?30】和基于全數據的方法【21,?23】。前者從缺失數據中隨機抽取部分作為負樣本進行學習;后者則將所有缺失條目一律視為負反饋。因此,基于采樣的方法在效果上通常更佳,而基于全數據的方法則能覆蓋更多數據。
傳統的全數據方法假設所有未觀測到的交互都是負樣本,且賦予相同權重【23】。然而,這種做法并不真實,因為未觀測到的數據中可能包含“偽負”——其實只是缺失的正例。為此,最近一些工作【21,?27】著重于設計更精細的加權方案,根據對未觀測樣本是否真正為負例的“置信度”來分配權重。例如,提出了基于用戶偏好程度的非均勻加權【27】和基于項目流行度的非均勻加權【21】,它們已被證明比統一權重效果更好。但這種非均勻加權方法的一大局限在于:權重的設定依賴于作者的主觀假設,這些假設在真實數據中未必成立。
正如前文所述,大多數現有方法都集中在負反饋的采樣或加權方案上,以應對缺乏負反饋的問題,而對于兩層正反饋——即項目層面的注意力和組件層面的注意力——關注較少,這兩者其實相當于對正向樣本進行加權。為彌補正向樣本加權的空白,我們提出了一種新穎的注意力機制,能夠基于用戶–項目交互矩陣及項目內容,自動為正向隱式信號分配權重。
三、預備知識
我們先來定義一些符號:
- 令 R ∈ R M × N R \in \mathbb{R}^{M \times N} R∈RM×N 為用戶–項目交互矩陣,其中 M M M 是用戶數, N N N 是項目數。
- 矩陣中的第 ( i , j ) (i,j) (i,j) 個元素記作 R i j R_{ij} Rij?。
- 對于隱式反饋,若用戶 i i i 與項目 j j j 之間存在交互(例如點擊、觀看等),則 R i j = 1 R_{ij} = 1 Rij?=1;否則 R i j = 0 R_{ij} = 0 Rij?=0。
- 我們用集合 R = { ( i , j ) ∣ R i j = 1 } \mathcal{R} = \{(i,j)\mid R_{ij} = 1\} R={(i,j)∣Rij?=1} 表示所有有過交互的用戶–項目對。
在隱式反饋的協同過濾任務中,目標是利用已知的 R \mathcal{R} R 信息,對那些未觀測到的 ( i , j ) (i,j) (i,j) 對預測一個分數 R ^ i j \hat{R}_{ij} R^ij?,以便進行推薦排序。
3.1 潛在因子模型(Latent Factor Models)
潛在因子模型將用戶和項目同時映射到一個共同的低維隱空間中,并通過向量內積來估計用戶對項目的偏好得分。我們重點討論基于對用戶–項目評分矩陣進行奇異值分解(SVD)的模型。
-
令用戶的隱向量矩陣為
U = [ u 1 , … , u M ] ∈ R D × M , U = [u_1, \dots, u_M] \in \mathbb{R}^{D \times M}, U=[u1?,…,uM?]∈RD×M,
其中 u i u_i ui? 表示第 i i i 個用戶的 D D D 維隱向量。
-
令項目的隱向量矩陣為
V = [ v 1 , … , v N ] ∈ R D × N , V = [v_1, \dots, v_N] \in \mathbb{R}^{D \times N}, V=[v1?,…,vN?]∈RD×N,
其中 v j v_j vj? 表示第 j j j 個項目的 D D D 維隱向量, D ≤ min ? ( M , N ) D\le\min(M,N) D≤min(M,N) 是設定的隱特征維度。
用戶 i i i 對項目 j j j 的預測偏好得分為兩者向量的內積:
R ^ i j = ? u i , v j ? = u i T v j . \hat R_{ij} = \langle u_i, v_j \rangle = u_i^T v_j. R^ij?=?ui?,vj??=uiT?vj?.
模型的目標是通過最小化觀測到的評分的正則化平方損失來學習 U U U 和 V V V:
min ? U , V ∑ ( i , j ) ∈ R ( R i j ? R ^ i j ) 2 λ ( ∥ U ∥ 2 2 + ∥ V ∥ 2 2 ) , \min_{U,V} \sum_{(i,j)\in\mathcal{R}} (R_{ij} - \hat R_{ij})^2 \lambda \bigl(\|U\|_2^2 + \|V\|_2^2\bigr), U,Vmin?(i,j)∈R∑?(Rij??R^ij?)2λ(∥U∥22?+∥V∥22?),
1其中 λ \lambda λ 是正則化系數,一般采用 L2 范數以防止過擬合。模型訓練完成后,就可以根據預測得分 R ^ i j \hat R_{ij} R^ij? 對所有項目進行排序,進而為用戶生成推薦列表。
但是,當直接將 SVD 應用于隱式反饋場景時會遇到挑戰:未觀測到的條目數量非常大,如果不加區分地將它們都當作負樣本,會為訓練帶來大量的“偽負”——本來可能只是未點擊或遺漏的正樣本。
3.2 貝葉斯個性化排序(BPR)
BPR 是一個著名的框架,用于解決協同過濾中隱式反饋的“隱式”問題【30】。與 SVD 中的逐點(point-wise)學習不同,BPR 針對一個用戶和兩項物品構建三元組:其中一項是該用戶已交互(正例)的項目,另一項則是未交互(負例)的項目。具體地,若用戶 i i i 在交互矩陣 R R R 中對項目 j j j 進行了“查看”或其他正向操作,則假設用戶 i i i 更偏好項目 j j j 而非任意未交互的項目。
BPR 的優化目標基于最大后驗估計。結合上述潛在因子模型,常見的 BPR 損失函數為:
min ? U , V ∑ ( i , j , k ) ∈ R B ? ln ? σ ( R ^ i j ? R ^ i k ) + λ ( ∥ U ∥ 2 2 + ∥ V ∥ 2 2 ) , \min_{U,V} \sum_{(i,j,k)\in \mathcal{R}_B} -\ln\sigma\bigl(\hat R_{ij} - \hat R_{ik}\bigr) \;+\;\lambda\bigl(\|U\|_2^2 + \|V\|_2^2\bigr), U,Vmin?(i,j,k)∈RB?∑??lnσ(R^ij??R^ik?)+λ(∥U∥22?+∥V∥22?),
其中
- σ ( x ) = 1 / ( 1 + e ? x ) \sigma(x) = 1/(1+e^{-x}) σ(x)=1/(1+e?x) 是 logistic sigmoid 函數,
- λ \lambda λ 是正則化參數,
- R ^ i j = u i T v j \hat R_{ij} = u_i^T v_j R^ij?=uiT?vj? 如前所述,
- R B = { ( i , j , k ) ∣ j ∈ R ( i ) ∧ k ∈ I ? R ( i ) } \mathcal{R}_B = \{(i,j,k)\mid j\in \mathcal{R}(i)\;\wedge\;k\in \mathcal{I}\setminus\mathcal{R}(i)\} RB?={(i,j,k)∣j∈R(i)∧k∈I?R(i)}。
這里, I \mathcal{I} I 表示數據集中所有項目的集合, R ( i ) \mathcal{R}(i) R(i) 表示用戶 i i i 曾交互過的項目集合。每個三元組 ( i , j , k ) ∈ R B (i,j,k)\in\mathcal{R}_B (i,j,k)∈RB? 表明“用戶 i i i 偏好項目 j j j 勝過項目 k k k”。由于 BPR 能有效利用未觀測的用戶–項目反饋進行模型訓練,我們在本工作中以 BPR 作為基礎學習框架。
四、ACF(注意力協同過濾)
圖1
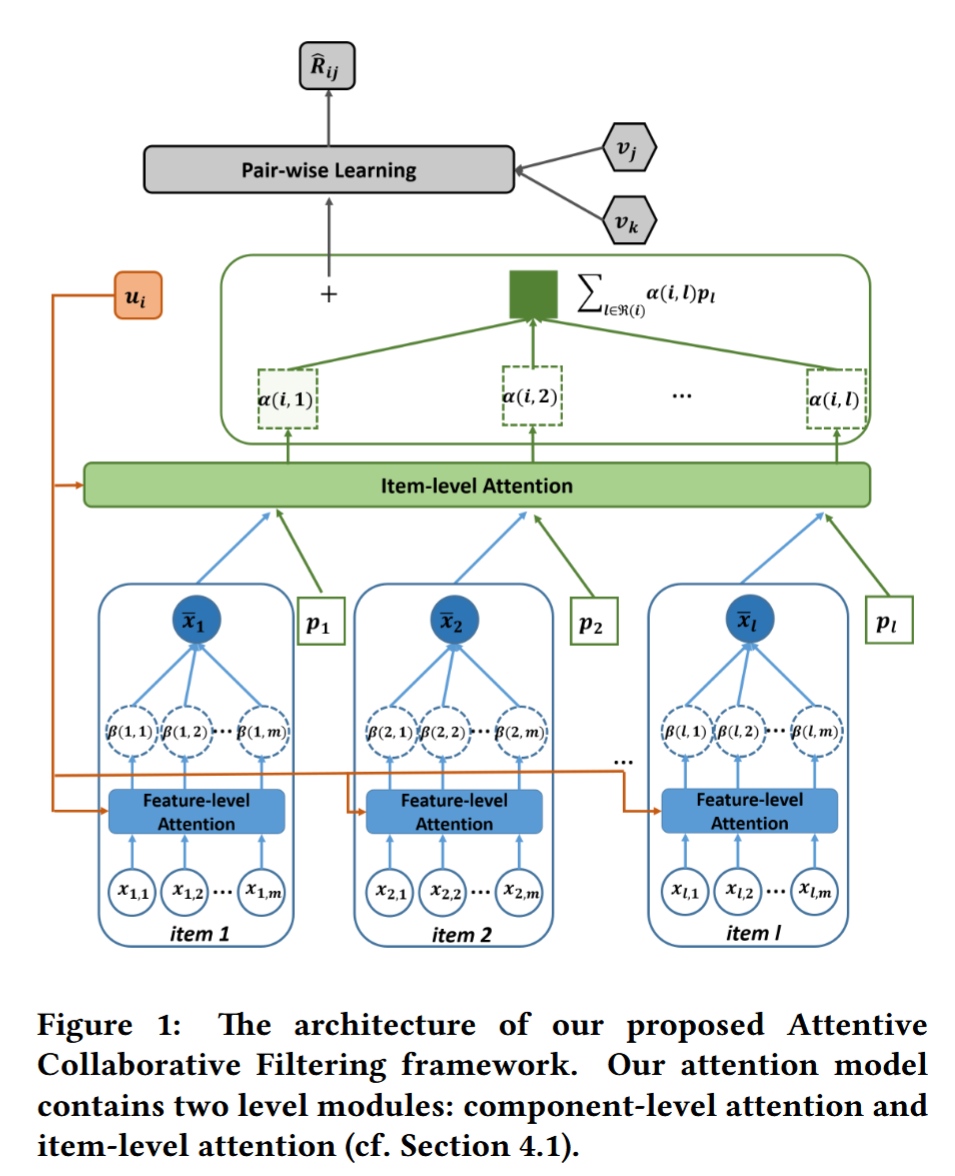
圖?1 展示了 ACF 的整體流程。首先,對第? i i i 位用戶,他交互過的一組項目構成了輸入集。對于每個項目? l l l:
-
組件特征提取
取出該項目的多個組件特征集合 { x l m } \{x_{lm}\} {xlm?}(圖中藍色實心圓),其中 x l m x_{lm} xlm? 可以是第? m m m 個空間位置的圖像區域特征【39】,也可以是視頻中第? m m m 幀的幀特征【41】。 -
組件級注意力
將用戶隱向量 u i u_i ui? 和每個組件特征 x l m x_{lm} xlm? 一同輸入組件級注意力子網絡,輸出該組件的注意力權重 β ( i , l , m ) \beta(i,l,m) β(i,l,m)(圖中藍色虛線圓)。通過對所有組件特征做加權求和x l = ∑ m β ( i , l , m ) x l m x_l = \sum_m \beta(i,l,m)\,x_{lm} xl?=m∑?β(i,l,m)xlm?
(圖中藍色實心圓),得到項目 l l l 的最終內容表示 x l x_l xl?。
-
項目級注意力
將用戶隱向量 u i u_i ui?、項目隱向量 v l v_l vl?、輔助項目向量 p l p_l pl? 以及剛得到的內容表示 x l x_l xl? 一同輸入項目級注意力子網絡,計算用戶 i i i 對項目 l l l 的注意力權重 α ( i , l ) \alpha(i,l) α(i,l)(圖中綠色虛線方框)。 -
鄰域聚合
類似地,對所有歷史項目做加權求和∑ l ∈ R ( i ) α ( i , l ) p l \sum_{l\in\mathcal{R}(i)} \alpha(i,l)\,p_l l∈R(i)∑?α(i,l)pl?
(圖中綠色實心方塊),得到用戶的鄰域表示。
- 優化訓練
將上述鄰域表示與基礎用戶隱向量 u i u_i ui? 相加,構成用戶的最終表征,并通過隨機梯度下降優化 BPR 的成對學習目標(參見式?(5))。
這兩級注意力機制使模型能夠自適應地從用戶–項目互動和多媒體內容中提取最具信息量的部分,進而提升推薦效果。
4.1 整體框架
ACF 是一個分層的神經網絡模型,用于同時在項目層面和組件層面刻畫用戶的偏好得分。設用戶為 i i i,項目為 l l l,項目 l l l 的第 m m m 個組件為該項目的一個子部分,我們分別用
- α ( i , l ) \alpha(i, l) α(i,l) 表示用戶 i i i 對項目 l l l 的整體偏好程度,
- β ( i , l , m ) \beta(i, l, m) β(i,l,m) 表示用戶 i i i 對項目 l l l 中第 m m m 個組件的偏好程度。
為此,ACF 設計了兩個注意力子網絡:
- 組件級注意力模塊:先對項目的各個組件(如視頻幀或圖像區域)分配權重,再生成該項目的內容表示;
- 項目級注意力模塊:以生成的內容表示(以及用戶和項目本身的特征)為輸入,進一步為不同項目分配注意力權重,從而構建對用戶的最終表征。
這兩個模塊協同工作,使模型能夠自適應地從“項目 → 組件”兩個層次抽取用戶的真實偏好信號。
目標函數 除了使用顯式參數向量 u i u_i ui? 來表示每個用戶 i i i 之外,ACF 還根據用戶 i i i 的歷史交互項目集合 R ( i ) \mathcal{R}(i) R(i) 來對用戶進行建模。因此,每個項目 l l l 有兩組隱向量:
- 基本項目向量 v l v_l vl?:作為潛在因子模型中項目本身的表示。
- 輔助項目向量 p l p_l pl?:用于根據用戶已經交互的項目集合來刻畫用戶的興趣畫像。
用戶 i i i 的最終表示由其個人向量 u i u_i ui? 與加權求和的輔助項目向量共同組成:
u i + ∑ l ∈ R ( i ) α ( i , l ) p l , u_i \;+\; \sum_{l \in \mathcal{R}(i)} \alpha(i, l)\,p_l, ui?+l∈R(i)∑?α(i,l)pl?,
其中 α ( i , l ) \alpha(i,l) α(i,l) 是用戶 i i i 對項目 l l l 的項目級注意力權重。
ACF 在 BPR(Bayesian Personalized Ranking)的成對學習目標下進行優化,旨在最大化用戶對正例項目與負例項目之間的排序差距。其數學形式為:
min ? U , V , P , Θ ∑ ( i , j , k ) ∈ R B ? ln ? σ ? ( ( u i + ??? ∑ l ∈ R ( i ) α ( i , l ) p l ) ? T v j ? ( u i + ??? ∑ l ∈ R ( i ) α ( i , l ) p l ) ? T v k ) + λ ( ∥ U ∥ 2 2 + ∥ V ∥ 2 2 + ∥ P ∥ 2 2 ) , \min_{U,V,P,\Theta}\ \sum_{(i,j,k)\in \mathcal{R}_B} -\,\ln \sigma\!\Bigl( \bigl(u_i + \!\!\sum_{l\in \mathcal{R}(i)}\alpha(i,l)\,p_l\bigr)^{\!T}v_j \;-\; \bigl(u_i + \!\!\sum_{l\in \mathcal{R}(i)}\alpha(i,l)\,p_l\bigr)^{\!T}v_k \Bigr) \;+\;\lambda\bigl(\|U\|_2^2 + \|V\|_2^2 + \|P\|_2^2\bigr), U,V,P,Θmin??(i,j,k)∈RB?∑??lnσ((ui?+l∈R(i)∑?α(i,l)pl?)Tvj??(ui?+l∈R(i)∑?α(i,l)pl?)Tvk?)+λ(∥U∥22?+∥V∥22?+∥P∥22?),
- R ( i ) \mathcal{R}(i) R(i) 是用戶 i i i 交互過的項目集合;
- α ( i , l ) \alpha(i,l) α(i,l) 由項目級注意力模塊計算,表示用戶 i i i 對項目 l l l 的偏好權重;
- p l p_l pl? 是項目 l l l 的輔助隱向量,用于聚合用戶歷史項目;
- u ^ i = u i + ∑ l ∈ R ( i ) α ( i , l ) p l \hat u_i = u_i + \sum_{l\in \mathcal{R}(i)}\alpha(i,l)\,p_l u^i?=ui?+∑l∈R(i)?α(i,l)pl? 為用戶 i i i 的最終隱表示;
- ( i , j , k ) ∈ R B (i,j,k)\in \mathcal{R}_B (i,j,k)∈RB? 表示正例 j j j 已被 i i i 交互,負例 k k k 未被交互;
- σ ( x ) = 1 / ( 1 + e ? x ) \sigma(x)=1/(1+e^{-x}) σ(x)=1/(1+e?x) 是 sigmoid 函數;
- Θ \Theta Θ 包含所有注意力網絡的參數;
- λ \lambda λ 是 L2 正則化系數,作用于 U , V , P U,V,P U,V,P 的范數。
組件級注意力也被整合到 α ( i , l ) \alpha(i,l) α(i,l) 的計算中,從而共同影響用戶最終表示和排序優化。
推斷(Inference) 在學習得到用戶、項目及輔助項目的隱向量 U U U、 V V V、 P P P 以及注意力網絡參數后,我們可以基于以下預測得分對所有項目進行排序,生成推薦:
R ^ i j = ( u i + ∑ l ∈ R ( i ) α ( i , l ) p l ) T v j . \hat R_{ij} = \Bigl(u_i + \sum_{l\in \mathcal{R}(i)} \alpha(i,l)\,p_l\Bigr)^T v_j. R^ij?=(ui?+l∈R(i)∑?α(i,l)pl?)Tvj?.
也就是說,用戶 i i i 對項目 j j j 的預測偏好得分 R ^ i j \hat R_{ij} R^ij? 就是用戶最終隱表示與項目隱向量 v j v_j vj? 的內積。
與鄰域模型的關系
我們可以將式 (6) 展開成兩部分之和:
R ^ i j = u i T v j ? 潛在因子模型 + ∑ l ∈ R ( i ) α ( i , l ) p l T v j ? 鄰域模型 , \hat R_{ij} = \underbrace{u_i^T v_j}_{\text{潛在因子模型}} \;+\; \underbrace{\sum_{l\in\mathcal{R}(i)}\alpha(i,l)\,p_l^T v_j}_{\text{鄰域模型}}, R^ij?=潛在因子模型 uiT?vj???+鄰域模型 l∈R(i)∑?α(i,l)plT?vj???,
其中 p l T v j p_l^T v_j plT?vj? 可以看作是項目 l l l 與項目 j j j 之間的相似度度量【24】。
-
第一項 u i T v j u_i^T v_j uiT?vj? 對應經典的潛在因子模型;
-
第二項 ∑ l α ( i , l ) p l T v j \sum_{l}\alpha(i,l)\,p_l^T v_j ∑l?α(i,l)plT?vj? 則是鄰域模型:用用戶歷史交互過的項目對目標項目加權求和。
-
當我們將注意力權重 α ( i , l ) \alpha(i,l) α(i,l) 簡化為統一的歸一化常數 1 ∣ R ( i ) ∣ \tfrac1{|\mathcal{R}(i)|} ∣R(i)∣1? 時,ACF 退化為 SVD++【25】;
-
若將其換成某種啟發式權重函數,則類似于 FISM【24】。
然而,這些方法忽略了多媒體推薦中兩層隱式反饋的重要性,固定或預設的權重假設所有歷史項目對預測貢獻相同。實際上,權重理應高度依賴于用戶特征和項目內容,我們將在 4.2 節和 4.3 節詳細介紹如何學習自適應的注意力權重。
4.2 項目級注意力(Item-Level Attention)
項目級注意力的目標是從用戶歷史交互的項目中挑選對其喜好最具代表性的項目,并聚合這些關鍵項目的表示來刻畫用戶。給定:
- 用戶的基礎隱向量 u i u_i ui?,
- 歷史項目 l l l 的隱向量 v l v_l vl?,
- 輔助項目向量 p l p_l pl?,以及
- 項目內容特征 x l x_l xl?(第?4.3 節詳述),
我們使用一個兩層前饋網絡來計算注意力分數 a ( i , l ) a(i,l) a(i,l):
a ( i , l ) = w 1 T ? ( W 1 u u i + W 1 v v l + W 1 p p l + W 1 x x l + b 1 ) + c 1 , a(i, l) = w_1^{T}\,\phi\bigl(W_{1u}\,u_i \;+\; W_{1v}\,v_l \;+\; W_{1p}\,p_l \;+\; W_{1x}\,x_l \;+\; b_1\bigr) \;+\; c_1, a(i,l)=w1T??(W1u?ui?+W1v?vl?+W1p?pl?+W1x?xl?+b1?)+c1?,
其中:
- W 1 u , W 1 v , W 1 p , W 1 x W_{1u}, W_{1v}, W_{1p}, W_{1x} W1u?,W1v?,W1p?,W1x? 以及偏置 b 1 b_1 b1? 是第一層的參數,
- 向量 w 1 w_1 w1? 和標量 c 1 c_1 c1? 是第二層的參數,
- ? ( x ) = max ? ( 0 , x ) \phi(x)=\max(0,x) ?(x)=max(0,x) 是 ReLU 激活函數,它比帶 tanh ? \tanh tanh 的單層感知機效果更好。
接著,用 Softmax 對所有歷史項目的注意力分數進行歸一化,得到項目級注意力權重 α ( i , l ) \alpha(i,l) α(i,l),它可以理解為項目 l l l 對用戶 i i i 偏好畫像的貢獻度:
α ( i , l ) = exp ? ( a ( i , l ) ) ∑ n ∈ R ( i ) exp ? ( a ( i , n ) ) . \alpha(i, l) = \frac{\exp\bigl(a(i,l)\bigr)} {\sum_{n \in \mathcal{R}(i)} \exp\bigl(a(i,n)\bigr)}. α(i,l)=∑n∈R(i)?exp(a(i,n))exp(a(i,l))?.
4.3 組件級注意力(Component-Level Attention)
多媒體項目包含豐富且復雜的信息,而不同用戶可能對同一項目中的不同部分感興趣。設項目 l l l 的組件特征集合為 { x l m } \{x_{lm}\} {xlm?},集合大小記為 ∣ { x l ? } ∣ \bigl|\{x_{l*}\}\bigr| ?{xl??} ?,其中 x l m x_{lm} xlm? 表示第 m m m 個組件的特征。與通常采用平均池化【6,?33】來提取統一內容表示的做法不同,組件級注意力的目標是根據用戶偏好為各組件分配不同權重,再通過加權求和構建內容表示。
-
注意力打分
對于用戶 i i i、項目 l l l 的第 m m m 個組件 x l m x_{lm} xlm?,其注意力分數由一個兩層網絡計算:b ( i , l , m ) = w 2 T ? ( W 2 u u i + W 2 x x l m + b 2 ) + c 2 , b(i,l,m) = w_2^{T}\,\phi\bigl(W_{2u}\,u_i \;+\; W_{2x}\,x_{lm} \;+\; b_2\bigr) \;+\; c_2, b(i,l,m)=w2T??(W2u?ui?+W2x?xlm?+b2?)+c2?,
其中 W 2 u , W 2 x W_{2u}, W_{2x} W2u?,W2x? 及偏置 b 2 b_2 b2? 是第一層參數,向量 w 2 w_2 w2? 和偏置 c 2 c_2 c2? 是第二層參數, ? ( x ) = max ? ( 0 , x ) \phi(x)=\max(0,x) ?(x)=max(0,x) 是 ReLU 激活。
-
歸一化權重
對所有組件分數做 Softmax 歸一化,得到注意力權重:β ( i , l , m ) = exp ? ( b ( i , l , m ) ) ∑ n = 1 ∣ { x l ? } ∣ exp ? ( b ( i , l , n ) ) . \beta(i,l,m) = \frac{\exp\bigl(b(i,l,m)\bigr)} {\sum_{n=1}^{|\{x_{l*}\}|} \exp\bigl(b(i,l,n)\bigr)}. β(i,l,m)=∑n=1∣{xl??}∣?exp(b(i,l,n))exp(b(i,l,m))?.
-
加權求和
最終,結合用戶偏好的組件注意力,計算項目 l l l 的內容表示:x l = ∑ m = 1 ∣ { x l ? } ∣ β ( i , l , m ) ? x l m . x_l = \sum_{m=1}^{|\{x_{l*}\}|}\beta(i,l,m)\,\cdot x_{lm}. xl?=m=1∑∣{xl??}∣?β(i,l,m)?xlm?.
這使得模型能夠聚焦于對用戶最具吸引力的組件,從而更精確地表達多媒體內容。
4.4 算法
我們提出了一種基于訓練三元組自助采樣(bootstrap sampling)的隨機梯度下降(SGD)算法來優化整個網絡。訓練流程如算法?1 所示。為簡化符號,我們將 ACF 劃分為三大子過程:
- ACFcomp(第?5–7 行):計算組件級注意力并匯總成內容表示(圖像為區域特征,視頻為幀特征)。
- ACFitem(第?4–9 行):基于內容表示、用戶向量和項目向量計算項目級注意力并匯總成鄰域表示。
- BPR-OPT:在第?12 行,根據式?(5) 對所有參數進行反向傳播和更新。
我們用 Θ \Theta Θ 表示項目級和組件級注意力網絡的所有參數,用 R ^ i j k \hat R_{ijk} R^ijk? 表示 R ^ i j ? R ^ i k \hat R_{ij}-\hat R_{ik} R^ij??R^ik?。在第?12 行中,按照鏈式法則計算每個參數的梯度,并沿著負梯度方向更新。每次迭代中,算法隨機選取一個訓練三元組 ( i , j , k ) (i,j,k) (i,j,k),再執行上述三個子過程并更新參數
劃分為三大子過程:
- ACFcomp(第?5–7 行):計算組件級注意力并匯總成內容表示(圖像為區域特征,視頻為幀特征)。
- ACFitem(第?4–9 行):基于內容表示、用戶向量和項目向量計算項目級注意力并匯總成鄰域表示。
- BPR-OPT:在第?12 行,根據式?(5) 對所有參數進行反向傳播和更新。
我們用 Θ \Theta Θ 表示項目級和組件級注意力網絡的所有參數,用 R ^ i j k \hat R_{ijk} R^ijk? 表示 R ^ i j ? R ^ i k \hat R_{ij}-\hat R_{ik} R^ij??R^ik?。在第?12 行中,按照鏈式法則計算每個參數的梯度,并沿著負梯度方向更新。每次迭代中,算法隨機選取一個訓練三元組 ( i , j , k ) (i,j,k) (i,j,k),再執行上述三個子過程并更新參數
)




的簡單介紹)




和value(受 React 狀態控制))

![wrod生成pdf。[特殊字符]改背景](http://pic.xiahunao.cn/wrod生成pdf。[特殊字符]改背景)




初階數據結構完)

![海外短劇H5系統開發:技術架構、SEO優化與全球市場突圍策略 [2025版]](http://pic.xiahunao.cn/海外短劇H5系統開發:技術架構、SEO優化與全球市場突圍策略 [2025版])