20世紀初,800人集體猜測一頭公牛的重量,結果與真實數值誤差不足1%——這就是著名的"群體智慧"效應。如今,這一古老智慧正以全新形態賦能AI訓練:通過動態優化標注流程,讓AI訓練結果像人群一樣達成精準共識。
本期澳鵬干貨將深入探討:澳鵬Appen平臺動態判斷功能(Dynamic Judgments)如何將這一原理轉化為生產力,在質量與效率間找到黃金平衡點。
群體決策的古老智慧
"群體智慧"(Wisdom of the Crowd)是人類協同完成復雜任務的核心方法論之一。這一概念最早可追溯至亞里士多德,并在20世紀初由弗朗西斯·高爾頓(Francis Galton)通過一個經典實驗驗證:當800人同時猜測一頭公牛的重量時,所有人猜測的中位數1,207磅與真實重量1,198磅的誤差不足1%。
這一發現證明:在特定條件下,匯集大量非專業人士的判斷,可以達到甚至超越單個專家的決策精度。如今,從維基百科的協同編輯到Quora的眾包問答,群體智慧已成為互聯網時代知識生產的基石。
數據標注領域的群體智慧挑戰
在AI訓練數據標注領域,群體智慧意味著:當任務不需要深度專業知識時,匯集多名經過培訓的標注員意見通常能獲得高質量結果。但關鍵問題在于:如何確定最低限度的標注數量?
對于內容審核等復雜主觀任務,行業慣例可能需收集多達10次判斷;
簡單任務通常需要較少判斷,但標注員間仍可能出現意見分歧;
如果為確保一致性盲目收集10次判斷,則會造成無意義的資源浪費......
矛盾點
增加標注次數雖能提高一致性,但會延緩項目進度并增加成本。
澳鵬的破局方案:動態判斷
針對這一挑戰,澳鵬Appen平臺"動態判斷"功能(Dynamic Judgments)提供智能化解決方案,允許設置每單元的最小/最大判斷次數(基礎設置)及基于置信度閾值的動態調整(高級設置)。
方案A:成本優先模式
可支持設置示例:最小3次判斷,最大5次判斷
優勢:達成一致時自動停止收集,成本可控
局限:不同單元的置信度存在波動
方案B:質量優先模式
可支持設置示例:置信度閾值0.8 (系統持續收集直至達標)
優勢:確保所有單元達到相同可靠性標準
置信度計算原理:
系統會綜合考量標注員間一致性(inter-annotator agreement)及個人信任評分(trust score),通過算法生成0-1之間的置信度評分。
對于包含多維度判斷的復合型任務,澳鵬Appen平臺"動態判斷"功能(Dynamic Judgments)支持精細化控制,例如在圖像標注任務中的:
① 分類判斷(識別圖片內容是吉娃娃犬還是松餅)
② 數量統計(計算圖中對象數量)
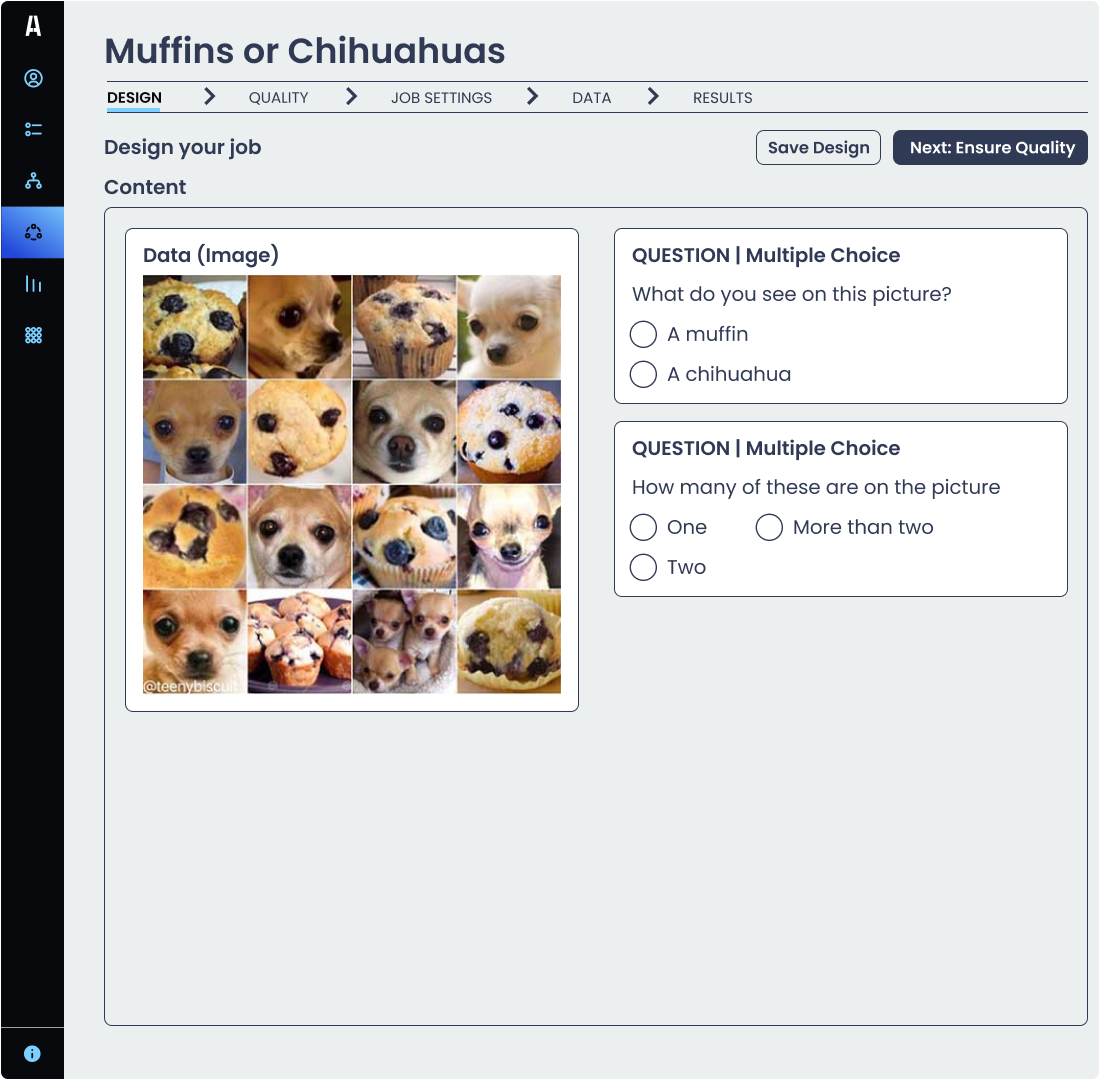
澳鵬Appen平臺"動態判斷"功能(Dynamic Judgments)支持對主觀性強的分類問題啟用動態判斷;對客觀的數量統計采用固定判斷次數;或為兩個問題分別設置不同的判斷策略。
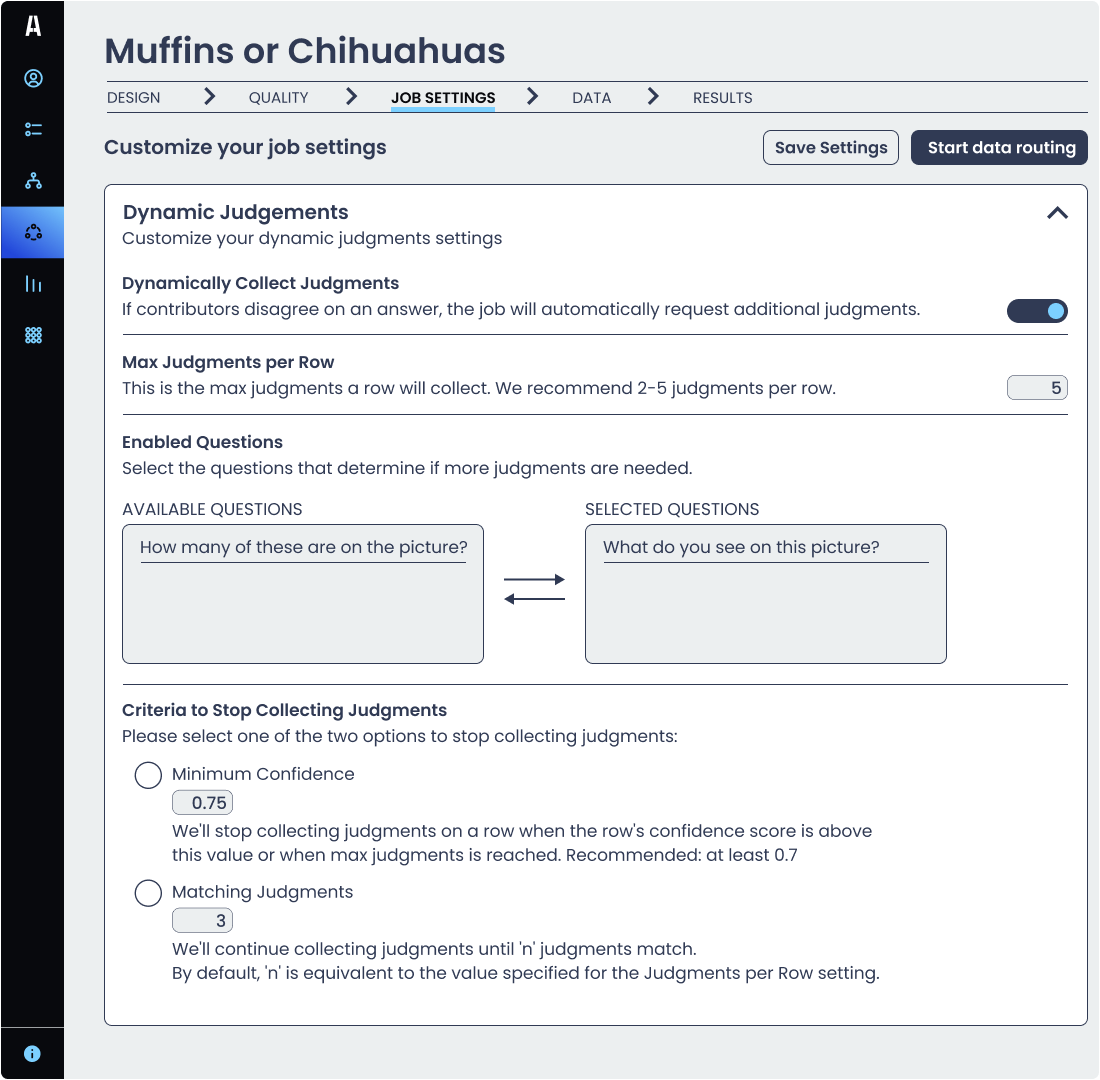
動態判斷(Dynamic Judgments)技術為AI項目帶來三重核心價值:通過智能化的群體共識機制保障標簽質量,精準控制標注次數以顯著提升效率,同時避免資源浪費實現降本增效。實踐證明:該功能能有效減少冗余標注次數,在確保高一致性的同時,讓AI訓練流程實現質量與效率的最佳平衡。

初階數據結構完)

![海外短劇H5系統開發:技術架構、SEO優化與全球市場突圍策略 [2025版]](http://pic.xiahunao.cn/海外短劇H5系統開發:技術架構、SEO優化與全球市場突圍策略 [2025版])

)





)





》)

