1. 簡介
- 馬爾可夫決策過程正式地描述了強化學習的環境
- 其中環境是完全可觀測的
- 即當前狀態完全表征了這個過程
- 幾乎所有的強化學習問題都可以形式化為馬爾可夫決策過程,例如:
- 最優控制主要處理連續的馬爾可夫決策過程
- 部分可觀察的問題可以轉化為馬爾可夫決策過程
- 賭場問題是具有單一狀態的馬爾可夫決策過程
2. 馬爾科夫性(Markov property)
當一個隨機過程在給定現在狀態及所有過去狀態情況下,其未來狀態的條件概率分布僅依賴于當前狀態;換句話說,在給定現在狀態時,它與過去狀態(即該過程的歷史路徑)是條件獨立的,那么此隨機過程即具有馬爾可夫性質。具有馬爾可夫性質的過程通常稱之為馬爾可夫過程。
用式子來表示:
P [ S t + 1 ∣ S t ] = P [ S t + 1 ∣ S 1 , ? , S t ] P[S_{t+1}|S_t]=P[S_{t+1}|S_1,\cdots,S_t] P[St+1?∣St?]=P[St+1?∣S1?,?,St?]
或者:
P s s ′ = P [ S t + 1 = s ′ ∣ S t = s ] \mathcal{P}_{ss'}=\mathbb{P}[S_{t+1}=s'|S_t=s] Pss′?=P[St+1?=s′∣St?=s]
狀態轉移矩陣 P \mathcal{P} P 定義了從 s s s 的所有狀態到所有后繼狀態 s ′ s' s′ 的轉移概率,每一行的和都是1
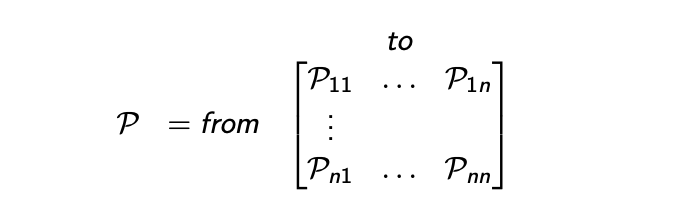
3. 馬爾可夫過程(Markov Process)
馬爾科夫過程是一個無記憶的隨機過程,比如一系列遵循馬爾科夫性的隨機狀態 S 1 , S 2 , ? S_1,S_2,\cdots S1?,S2?,?
定義:馬爾可夫過程(也稱為馬爾可夫鏈)是一個元組 ? S , P ? \left\langle S,\mathcal{P}\right \rangle ?S,P?,其中:
- S S S 是一個有限的狀態集合
- P \mathcal{P} P 是一個狀態轉移矩陣, P s s ′ = P [ S t + 1 = s ′ ∣ S t = s ] \mathcal{P}_{ss'}=\mathbb{P}[S_{t+1}=s'|S_t=s] Pss′?=P[St+1?=s′∣St?=s]
例子:學生馬爾可夫鏈
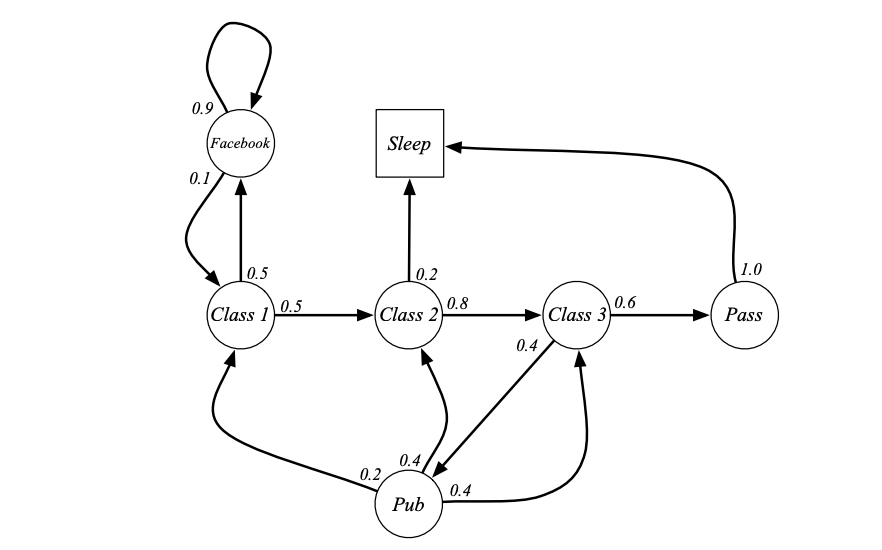
這個馬爾科夫鏈從 S 1 = C 1 S_1=C1 S1?=C1 開始, S 1 , S 2 , ? , S T S_1,S_2,\cdots,S_T S1?,S2?,?,ST? 舉例如下:
C 1 , C 2 , C 3 , P a s s , S l e e p C1,C2,C3,Pass,Sleep C1,C2,C3,Pass,Sleep
C 1 , F B , F B , C 1 , C 2 , S l e e p C1,FB,FB,C1,C2,Sleep C1,FB,FB,C1,C2,Sleep
C 1 , C 2 , C 3 , P u b , C 2 , C 3 , P a s s , S l e e p C1,C2,C3,Pub,C2,C3,Pass,Sleep C1,C2,C3,Pub,C2,C3,Pass,Sleep
C 1 , F B , F B , C 1 , C 2 , C 3 , P u b , C 1 , F B , F B , F B , C 1 , C 2 , C 3 , P u b , C 2 , S l e e p C1,FB,FB,C1,C2,C3,Pub,C1,FB,FB,FB,C1,C2,C3,Pub,C2,Sleep C1,FB,FB,C1,C2,C3,Pub,C1,FB,FB,FB,C1,C2,C3,Pub,C2,Sleep
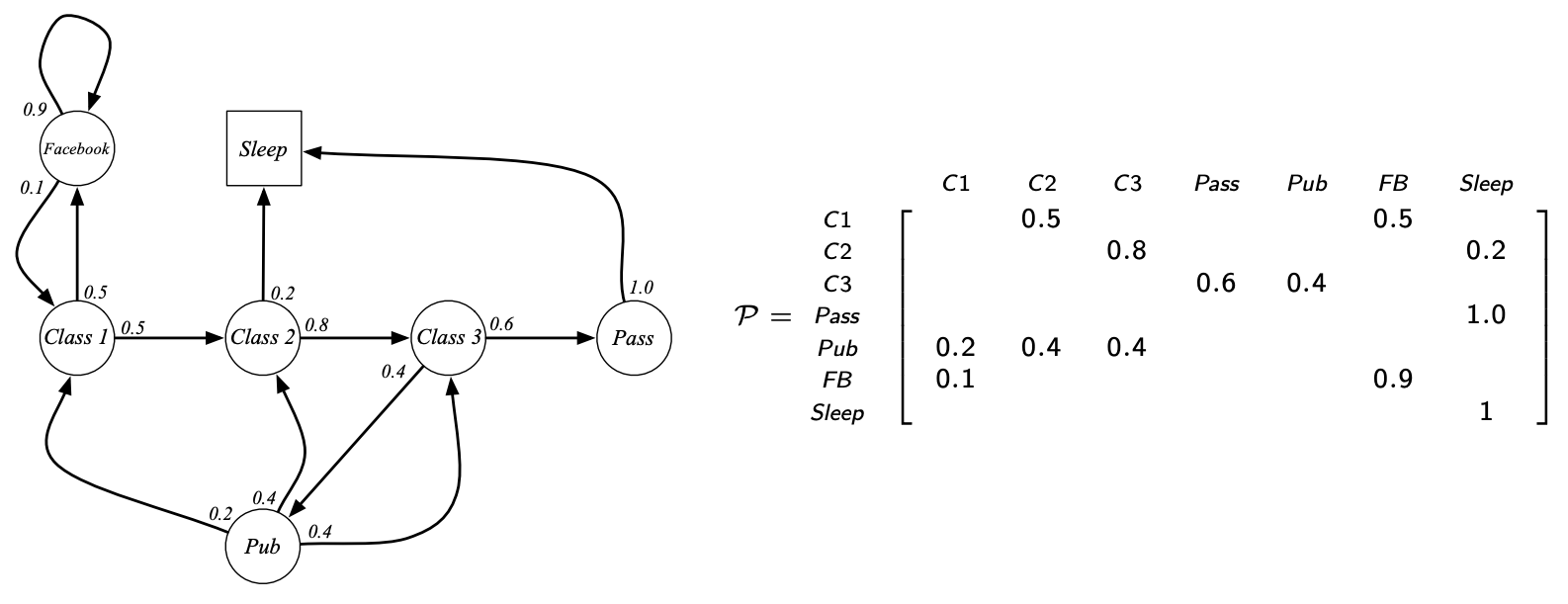
學生馬爾可夫鏈的轉移矩陣:
4. 馬爾可夫獎勵過程(Markov Reward Process)
馬爾可夫獎勵過程是一個元組 ? S , P , R , γ ? \left\langle S,\mathcal{P},\mathcal{R},\gamma\right \rangle ?S,P,R,γ?
- S S S 是一個有限的狀態集合
- P \mathcal{P} P 是一個狀態轉移矩陣, P s s ′ = P [ S t + 1 = s ′ ∣ S t = s ] \mathcal{P}_{ss'}=\mathbb{P}[S_{t+1}=s'|S_t=s] Pss′?=P[St+1?=s′∣St?=s]
- R \mathcal{R} R 是一個獎勵函數, R s = E [ R t + 1 ∣ S t = s ] \mathcal{R}_s=\mathbb{E}[R_{t+1}|S_t=s] Rs?=E[Rt+1?∣St?=s]
- γ \gamma γ 是一個折扣系數, γ ∈ [ 0 , 1 ] \gamma\in[0,1] γ∈[0,1]
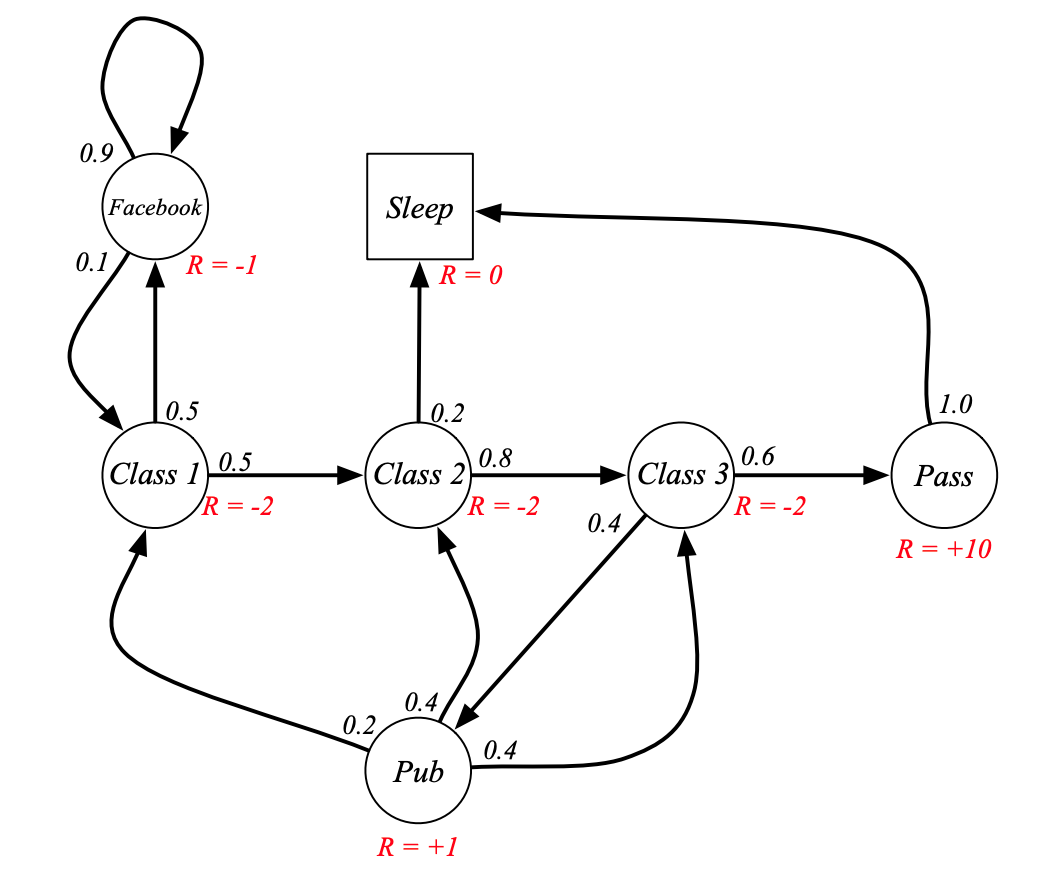
例子:學生馬爾可夫獎勵過程(Student MRP)
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + ? = ∑ k = 0 ∞ γ k R t + k + 1 G_t=R_{t+1} + \gamma R_{t+2} + \gamma^2R_{t+3} + \cdots = \sum_{k=0}^{\infty} \gamma^k R_{t+k+1} Gt?=Rt+1?+γRt+2?+γ2Rt+3?+?=∑k=0∞?γkRt+k+1? 代表收獲(return),是一個MDP中從某一個狀態 S t S_t St? 開始采樣直到終止狀態時所有獎勵的有衰減的和。
其中:
- 折扣系數(或者叫衰減系數) γ ∈ [ 0 , 1 ] \gamma\in[0,1] γ∈[0,1] 是未來獎勵的當下價值
- 在 k + 1 k+1 k+1 個時間步后獲得獎勵的價值為 γ k R \gamma^kR γkR
- 即時獎勵的價值高于延遲獎勵:
- γ \gamma γ 接近0會導致“近視”評估
- γ \gamma γ 接近1會導致“遠視”評估
大多數馬爾可夫獎勵和決策過程是帶有折扣的。為什么?
- 數學上折扣獎勵更方便
- 避免循環馬爾可夫過程中出現無限回報
- 對未來的不確定性可能無法完全表示
- 如果獎勵是金錢,即時獎勵可能比延遲獎勵賺取更多利息
- 動物/人類行為表現出對即時獎勵的偏好
- 有時可以使用不帶折扣的馬爾可夫獎勵過程(即 γ = 1 \gamma=1 γ=1),比如所有的序列都一定會終止
例子:Student MRP Returns
初始狀態為 S 1 = C 1 S_1=C1 S1?=C1, γ = 1 2 \gamma=\frac{1}{2} γ=21?
G 1 = R 2 + γ R 3 + ? + γ T ? 2 R T G_1=R_2+\gamma R_3+\cdots+\gamma^{T-2}R_T G1?=R2?+γR3?+?+γT?2RT?
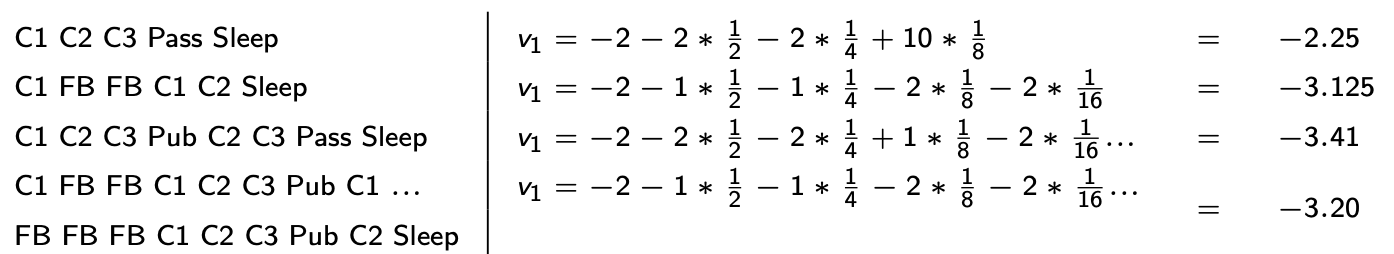
γ = 0 \gamma=0 γ=0 時學生MRP的狀態價值函數:
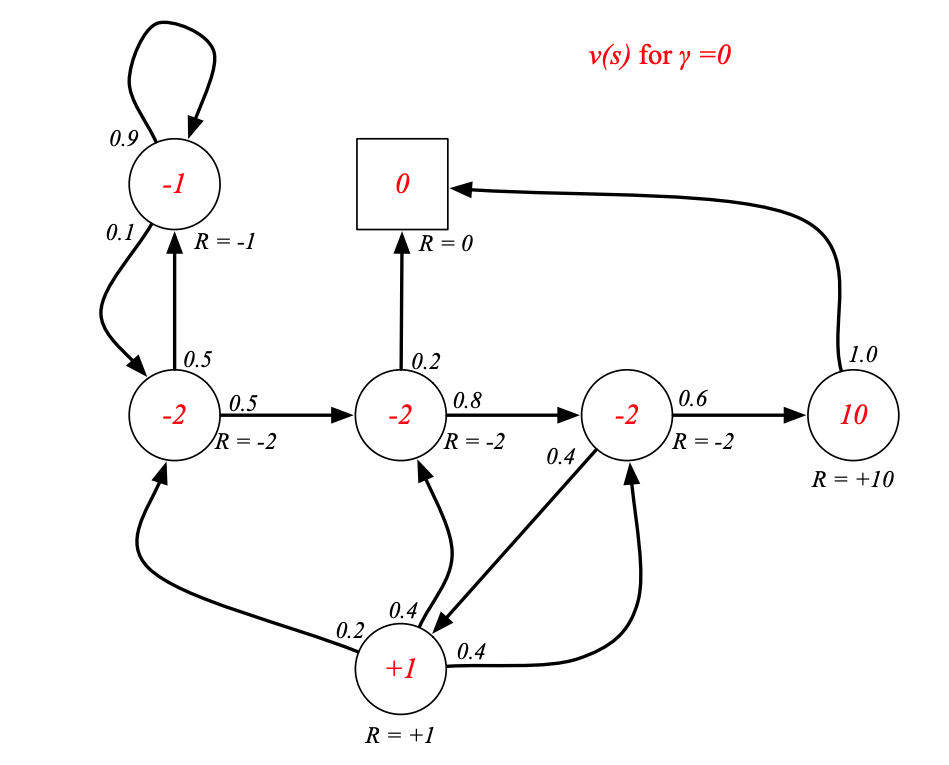
γ = 0.9 \gamma=0.9 γ=0.9 時學生MRP的狀態價值函數:
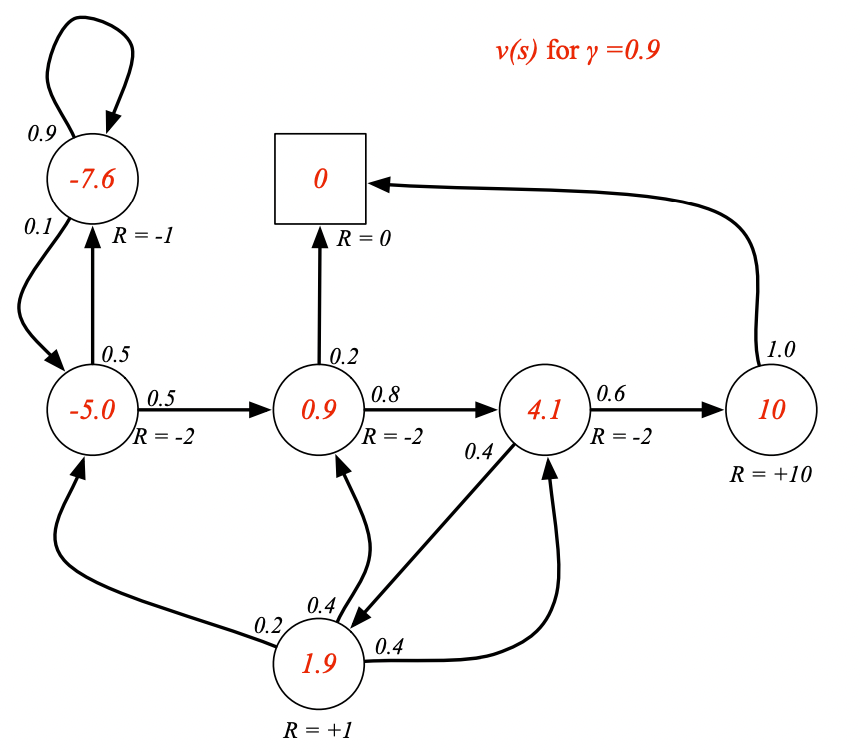
γ = 1 \gamma=1 γ=1 時學生MRP的狀態價值函數:
馬爾科夫獎勵過程的貝爾曼方程
狀態價值函數可以被分解為兩部分:
- 即時獎勵 R t + 1 R_{t+1} Rt+1?
- 后續狀態的折扣價值 γ v ( S t + 1 ) \gamma v(S_{t+1}) γv(St+1?)
v ( s ) = E [ G t ∣ S t = s ] = E [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + … ∣ S t = s ] = E [ R t + 1 + γ ( R t + 2 + γ R t + 3 + … ) ∣ S t = s ] = E [ R t + 1 + γ G t + 1 ∣ S t = s ] = E [ R t + 1 + γ v ( S t + 1 ) ∣ S t = s ] \begin{align*} v(s) &= \mathbb{E} [G_t \mid S_t = s] \\ &= \mathbb{E} [R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \ldots \mid S_t = s] \\ &= \mathbb{E} [R_{t+1} + \gamma (R_{t+2} + \gamma R_{t+3} + \ldots) \mid S_t = s] \\ &= \mathbb{E} [R_{t+1} + \gamma G_{t+1} \mid S_t = s] \\ &= \mathbb{E} [R_{t+1} + \gamma v(S_{t+1}) \mid S_t = s] \end{align*} v(s)?=E[Gt?∣St?=s]=E[Rt+1?+γRt+2?+γ2Rt+3?+…∣St?=s]=E[Rt+1?+γ(Rt+2?+γRt+3?+…)∣St?=s]=E[Rt+1?+γGt+1?∣St?=s]=E[Rt+1?+γv(St+1?)∣St?=s]?
馬爾科夫獎勵過程(MRPs)的貝爾曼方程:
v ( s ) = E [ R t + 1 + γ v ( S t + 1 ∣ S t = s ) ] v(s)=\mathbb{E}[R_{t+1}+\gamma v(S_{t+1}|S_t=s)] v(s)=E[Rt+1?+γv(St+1?∣St?=s)]
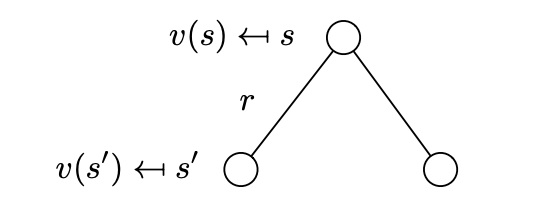
v ( s ) = R s + γ ∑ s ′ ∈ S P s s ′ v ( s ′ ) v(s)=\mathcal{R}_s+\gamma \sum_{s'\in\mathcal{S}}\mathcal{P}_{ss'}v(s') v(s)=Rs?+γs′∈S∑?Pss′?v(s′)
例子:Student MRP的貝爾曼方程
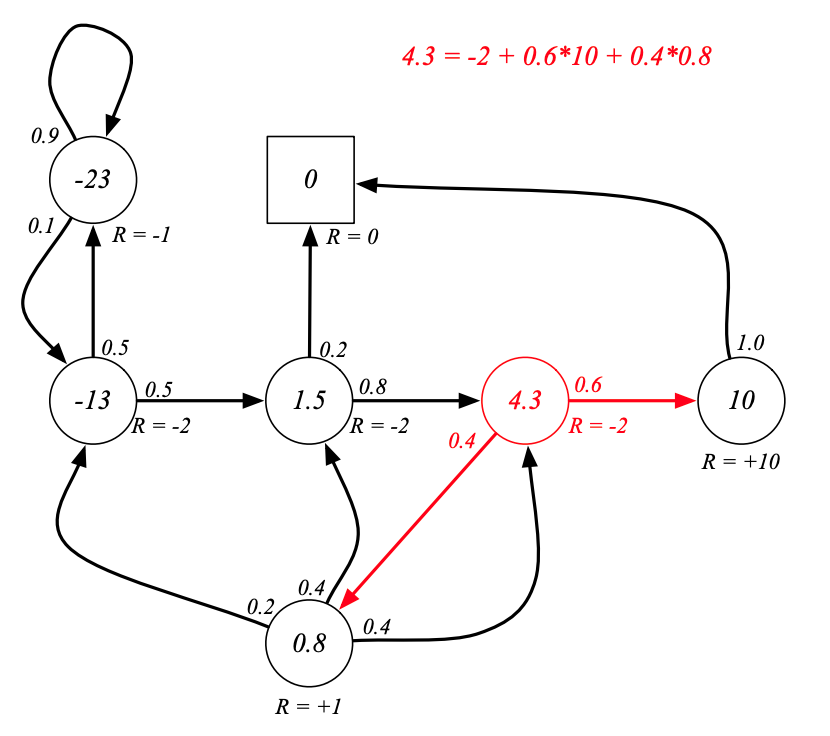
這里的 γ = 1 \gamma=1 γ=1,并且已經知道了Pub的狀態價值為0.8,Pass的狀態價值為10
貝爾曼方程的矩陣形式:
v = R + γ P v v=\mathcal{R}+\gamma \mathcal{P}v v=R+γPv
其中 v v v 是每個狀態都有一個對應元素的列向量:
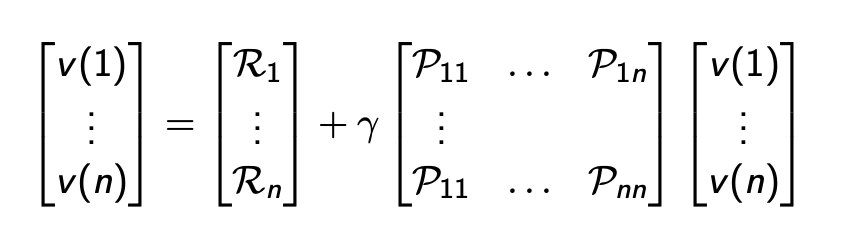
求解貝爾曼方程:
貝爾曼方程是一個線性方程,可以被直接求解:
v = R + γ P v ( I ? γ P ) v = R v = ( I ? γ P ) ? 1 R \begin{align*} v &= \mathcal{R} + \gamma \mathcal{P} v \\ (I - \gamma \mathcal{P}) v &= \mathcal{R} \\ v &= (I - \gamma \mathcal{P})^{-1} \mathcal{R} \end{align*} v(I?γP)vv?=R+γPv=R=(I?γP)?1R?
對于n個狀態的計算復雜度為 O ( n 3 ) O(n^3) O(n3)
因為計算復雜度比較大,直接求解只可能在小規模的馬爾科夫獎勵過程中實現,在大規模馬爾科夫獎勵過程中可以使用很多迭代的方法,比如:
- 動態規劃(Dynamic Programming)
- 蒙特卡洛法(Monte-Carlo evaluation)
- 時序差分法(Temporal-Difference)
5. 馬爾科夫決策過程 Markov Decision Process
馬爾科夫決策過程(MDP)就是帶有決策的馬爾科夫獎勵過程(MRP),它是一個所有狀態都符合馬爾科夫性質的環境。
馬爾科夫決策過程是一個元組 ? S , A , P , R , γ ? \left\langle \mathcal{S},\mathcal{A},\mathcal{P},\mathcal{R},\gamma\right \rangle ?S,A,P,R,γ?
- S \mathcal{S} S是一個有限的狀態集合
- A \mathcal{A} A 是一個有限的動作集合
- P \mathcal{P} P 是一個狀態轉移概率矩陣, P s s ′ a = P [ S t + 1 = s ′ ∣ S t = s , A t = a ] \mathcal{P}_{ss'}^{a}=\mathbb{P}[S_{t+1}=s'|S_t=s,A_t=a] Pss′a?=P[St+1?=s′∣St?=s,At?=a]
- R \mathcal{R} R 是一個獎勵函數, R = E [ R t + 1 ∣ S t = s , A t = a ] \mathcal{R}=\mathbb{E}[R_{t+1}|S_t=s,A_t=a] R=E[Rt+1?∣St?=s,At?=a]
- γ \gamma γ 是一個折扣率, γ ∈ [ 0 , 1 ] \gamma\in[0,1] γ∈[0,1]
例子:學生馬爾科夫決策過程
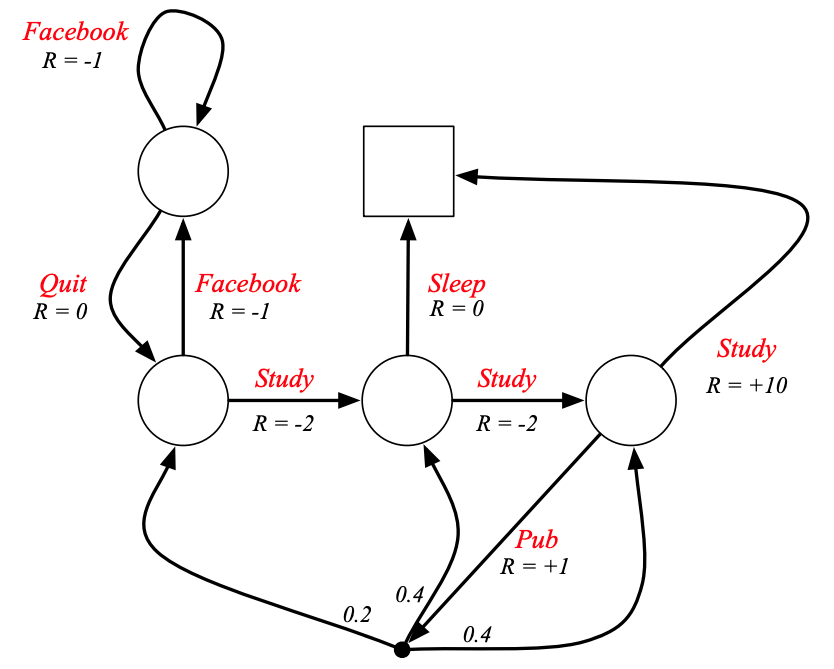
策略 π \pi π是給定狀態下動作的概率分布
π ( a ∣ s ) = P [ A t = a ∣ S t = s ] \pi(a|s)=\mathbb{P}[A_t=a|S_t=s] π(a∣s)=P[At?=a∣St?=s]
- 策略完全定義了一個agent的行為
- MDP的策略只依賴當前狀態(不依賴歷史狀態)
- 比如,策略是靜態的,與時間無關, A t ~ π ( ? ∣ S t ) , ? t > 0 A_t \sim \pi(\cdot \mid S_t), \forall t > 0 At?~π(?∣St?),?t>0
給定一個MDP ? S , A , P , R , γ ? \left\langle \mathcal{S},\mathcal{A},\mathcal{P},\mathcal{R},\gamma\right \rangle ?S,A,P,R,γ? 和一個策略 π \pi π,狀態序列 S 1 , S 2 , ? S_1,S_2,\cdots S1?,S2?,? 是一個馬爾科夫過程 ? S , P π ? \left\langle \mathcal{S}, \mathcal{P}^{\pi} \right \rangle ?S,Pπ?,狀態和獎勵序列 S 1 , R 2 , S 2 , ? S_1,R_2,S_2,\cdots S1?,R2?,S2?,? 是一個馬爾科夫獎勵過程 ? S , P π , R π , γ ? \left\langle \mathcal{S},\mathcal{P}^{\pi},\mathcal{R}^{\pi},\gamma\right \rangle ?S,Pπ,Rπ,γ?,則有:
P s , s ′ π = ∑ a ∈ A π ( a ∣ s ) P s s ′ a \mathcal{P}^\pi_{s,s'} = \sum_{a \in \mathcal{A}} \pi(a \mid s) \mathcal{P}^a_{ss'} Ps,s′π?=a∈A∑?π(a∣s)Pss′a?
R s π = ∑ a ∈ A π ( a ∣ s ) R s a \mathcal{R}^\pi_s = \sum_{a \in \mathcal{A}} \pi(a \mid s) \mathcal{R}^a_s Rsπ?=a∈A∑?π(a∣s)Rsa?
價值函數:
一個MDP的狀態價值函數 v π ( s ) v_{\pi}(s) vπ?(s) 是從狀態 s s s 開始依據策略 π \pi π 的收獲( G t G_t Gt?)的期望:
v π ( s ) = E π [ G t ∣ S t = s ] v_{\pi}(s)=\mathbb{E}_{\pi}[G_t|S_t=s] vπ?(s)=Eπ?[Gt?∣St?=s]
動作價值函數 q π ( s , a ) q_{\pi}(s,a) qπ?(s,a) 是是從狀態 s s s 開始依據策略 π \pi π 采取動作 a a a 的期望:
q π ( s , a ) = E π [ G t ∣ S t = s , A t = a ] q_{\pi}(s,a)=\mathbb{E}_{\pi}[G_t|S_t=s,A_t=a] qπ?(s,a)=Eπ?[Gt?∣St?=s,At?=a]
例子:Student MDP的狀態價值函數
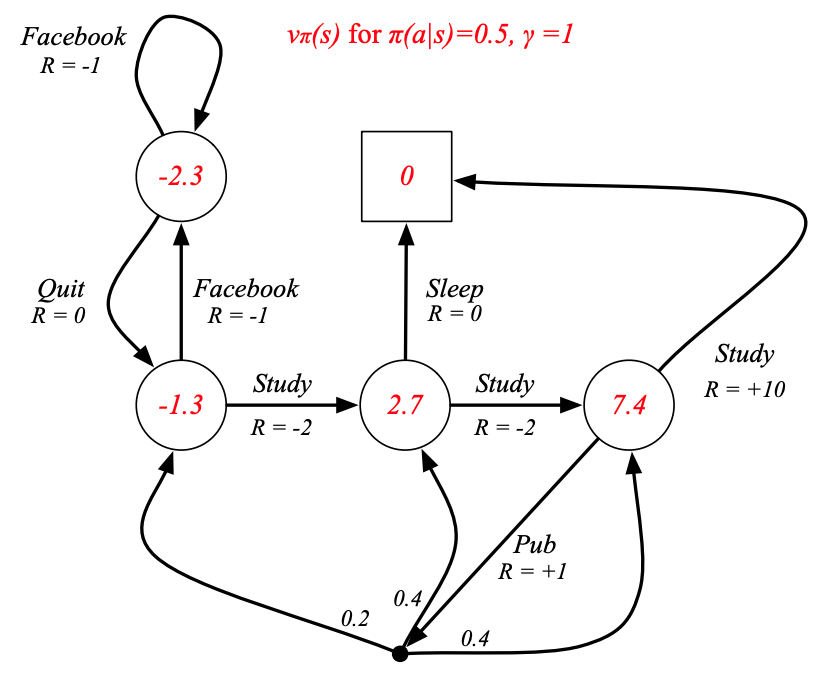
Bellman期望方程 Bellman Expectation Equation
MDP下的狀態價值函數和動作價值函數與MRP下的價值函數類似,可以改用下一時刻狀態價值函數或動作價值函數來表達,具體方程如下:
v π ( s ) = E π [ R t + 1 + γ v π ( S t + 1 ) ∣ S t = s ] v_\pi(s) = \mathbb{E}_\pi \left[ R_{t+1} + \gamma v_\pi(S_{t+1}) \mid S_t = s \right] vπ?(s)=Eπ?[Rt+1?+γvπ?(St+1?)∣St?=s]
q π ( s , a ) = E π [ R t + 1 + γ q π ( S t + 1 , A t + 1 ) ∣ S t = s , A t = a ] q_\pi(s, a) = \mathbb{E}_\pi \left[ R_{t+1} + \gamma q_\pi(S_{t+1}, A_{t+1}) \mid S_t = s, A_t = a \right] qπ?(s,a)=Eπ?[Rt+1?+γqπ?(St+1?,At+1?)∣St?=s,At?=a]
根據動作價值函數 q π ( s , a ) q_{\pi}(s,a) qπ?(s,a) 和狀態價值函數 v π ( s ) v_{\pi}(s) vπ?(s) 的定義,我們很容易得到他們之間的轉化關系公式:
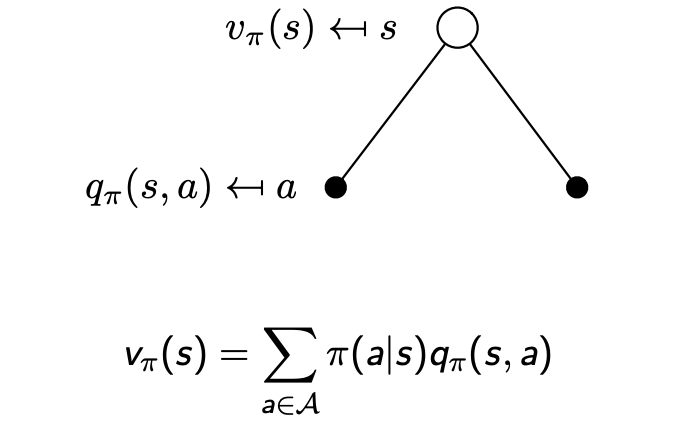
利用上貝爾曼方程,我們也很容易用狀態價值函數表示動作價值函數
,即:
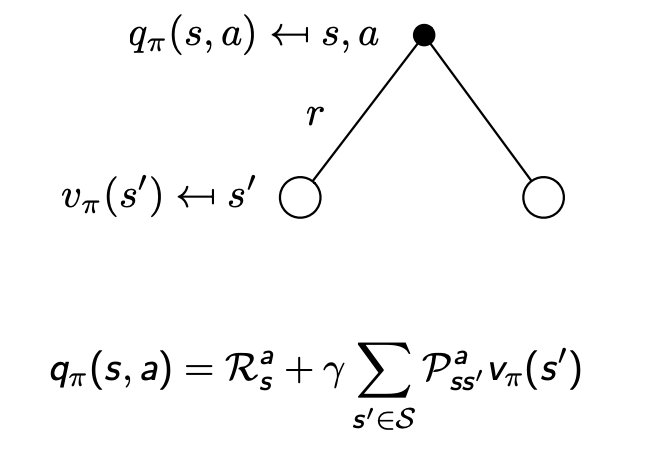
當然,也可以做一層推算:
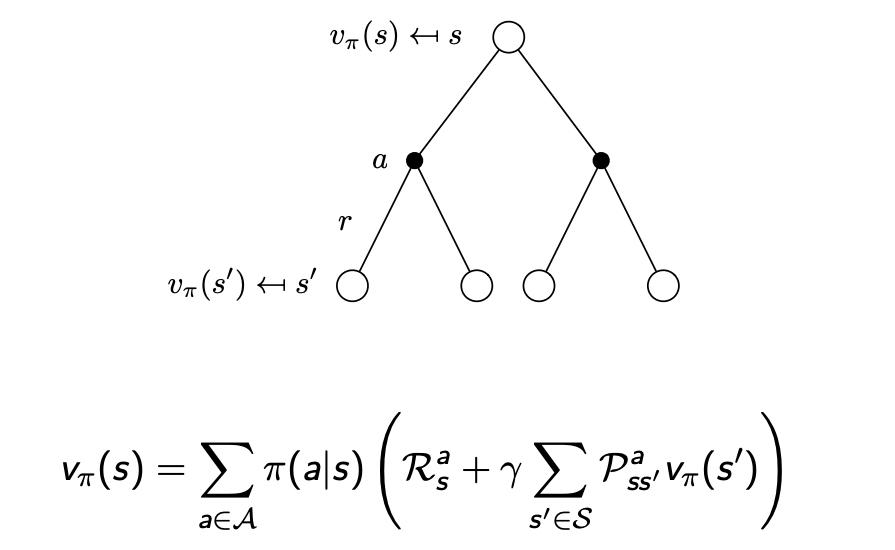
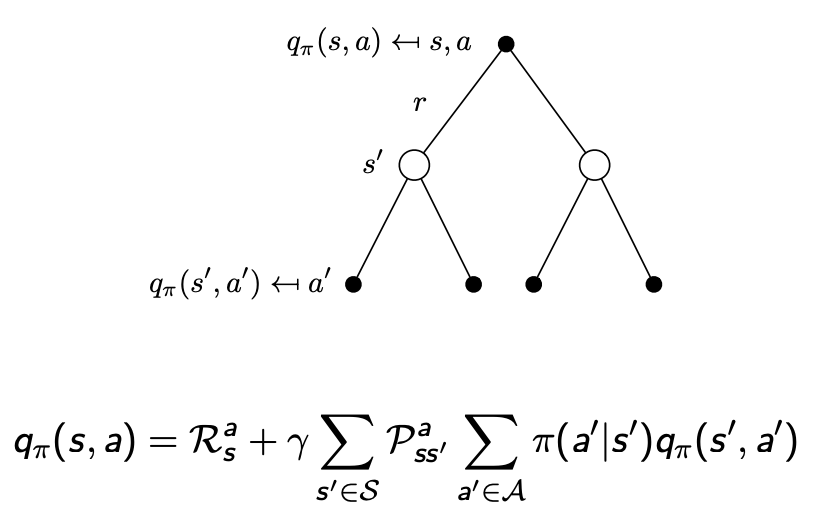
例子:Student MDP的貝爾曼期望方程
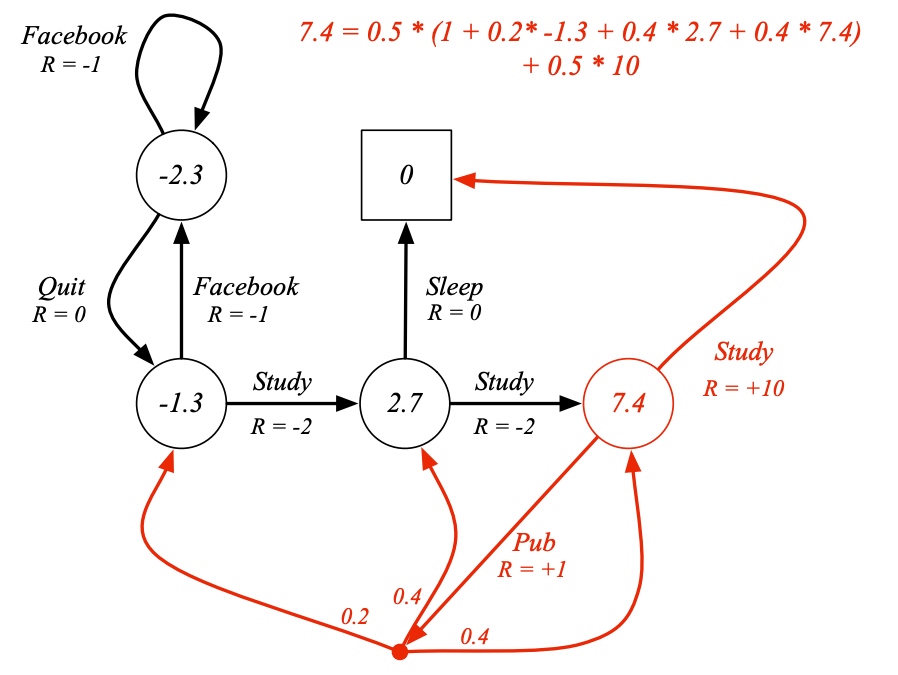
圖中計算Pass的狀態價值所用方程:
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) ( R s a + γ ∑ s ′ ∈ S P s s ′ a v π ( s ′ ) ) v_\pi(s) = \sum_{a \in \mathcal{A}} \pi(a \mid s) \left( \mathcal{R}^a_s + \gamma \sum_{s' \in \mathcal{S}} \mathcal{P}^a_{ss'} v_\pi(s') \right) vπ?(s)=a∈A∑?π(a∣s)(Rsa?+γs′∈S∑?Pss′a?vπ?(s′))
因為不是從Pub來推理Pass,而是從Pub的上一層 Class 1,Class 2和Class 3來推理,所以不用知道Pub的狀態價值就可以計算。同理因為Sleep沒有上一層,所以只需要用它的獎勵就可以計算Pass的價值。
貝爾曼期望方程的矩陣形式:
Bellman期望方程可以用誘導MRP簡潔地表示:
v π = R π + γ P π v π v_{\pi}=\mathcal{R}^{\pi}+\gamma \mathcal{P}^{\pi}v_{\pi} vπ?=Rπ+γPπvπ?
可以直接求解:
v π = ( I ? γ P π ) ? 1 R π v_\pi = (I - \gamma \mathcal{P}^\pi)^{-1} \mathcal{R}^\pi vπ?=(I?γPπ)?1Rπ
6. 最優價值函數
定義:
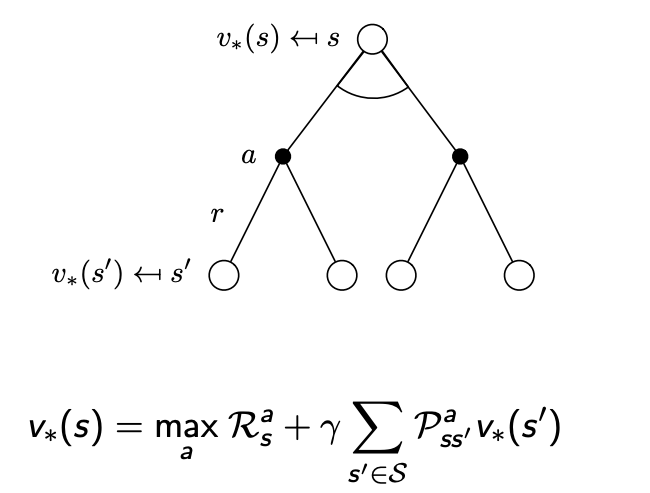
最優狀態價值函數 v ? ( s ) v_{*}(s) v??(s) 指的是在所有策略產生的狀態價值函數中,使狀態s價值最大的那個函數:
v ? ( s ) = max ? π v π ( s ) v_*(s) = \max_{\pi} v_{\pi}(s) v??(s)=πmax?vπ?(s)
最優動作價值函數 q ? ( s , a ) q_{*}(s,a) q??(s,a) 指的是在所有策略產生的動作價值函數中,使狀態動作對 ? s , a ? \left\langle s,a \right \rangle ?s,a?價值最大的那個函數:
q ? ( s , a ) = max ? π q π ( s , a ) q_*(s,a) = \max_{\pi} q_{\pi}(s,a) q??(s,a)=πmax?qπ?(s,a)
最優價值函數明確了MDP的最優可能表現,當我們知道了最優價值函數,也就知道了每個狀態的最優價值,這時便認為這個MDP得到了解決。
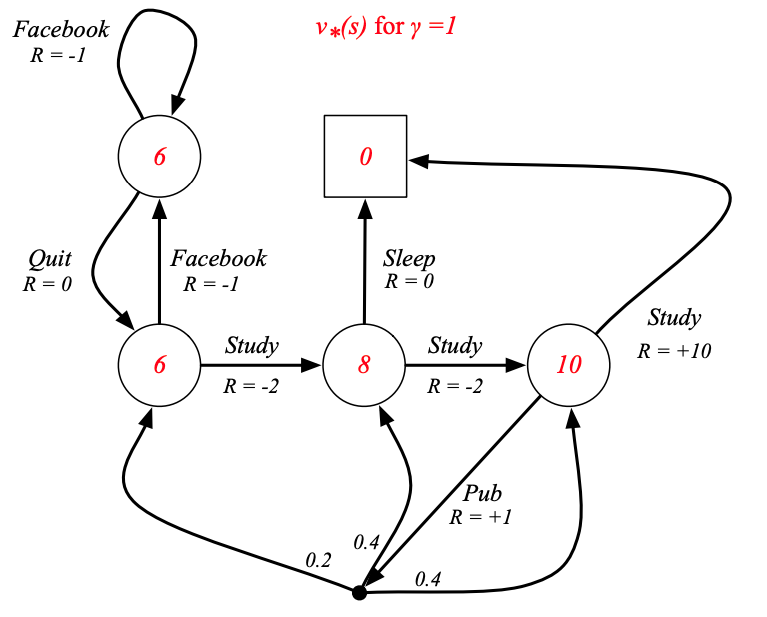
例子:Student MDP的最優價值函數
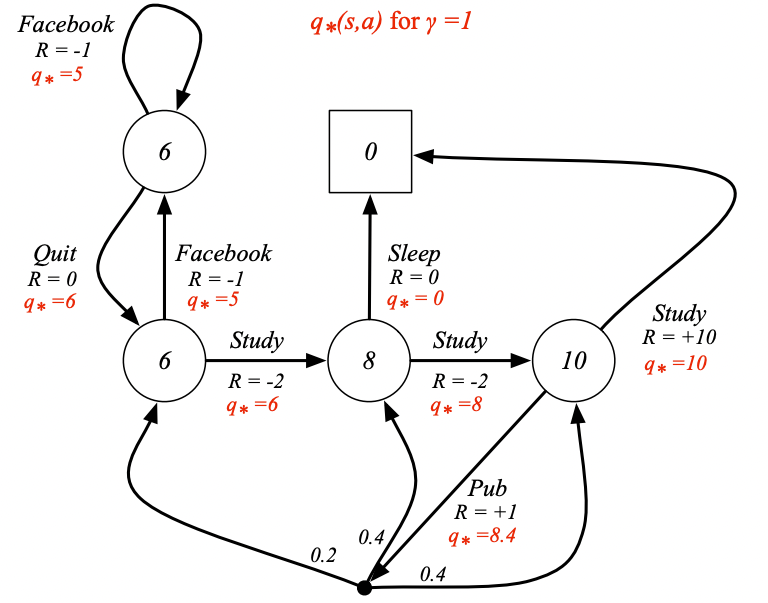
例子:Student MDP的最優動作價值函數
最優策略
定義策略的部分排序:
π ≥ π ′ if? v π ( s ) ≥ v π ′ ( s ) , ? s \pi \geq \pi' \ \text{if} \ v_{\pi}(s) \geq v_{\pi'}(s),\ \forall s π≥π′?if?vπ?(s)≥vπ′?(s),??s
定理:
對于任意馬爾可夫決策過程(Markov Decision Process, MDP):
- 存在一個最優策略 π ? \pi_{*} π??,它優于或等于所有其他策略,即 π ? ≥ π , ? π \pi_{*}\geq\pi,\ \forall \pi π??≥π,??π
- 所有最優策略都能達到最優狀態價值函數,即 v π ? ( s ) = v ? ( s ) v_{\pi_{*}}(s)=v_{*}(s) vπ???(s)=v??(s)
- 所有最優策略都能達到最優動作-價值函數,即 q π ? ( s , a ) = q ? ( s , a ) q_{\pi}{*}(s,a)=q_{*}(s,a) qπ??(s,a)=q??(s,a)
尋找最優策略
可以通過最大化最優行為價值函數來找到最優策略:
π ? ( a ∣ s ) = { 1 if? a = arg ? max ? a ∈ A q ? ( s , a ) 0 otherwise \pi_*(a|s) = \begin{cases} 1 & \text{if } a = \underset{a \in \mathcal{A}}{\arg\max}\ q_*(s, a) \\ 0 & \text{otherwise} \end{cases} π??(a∣s)=? ? ??10?if?a=a∈Aargmax??q??(s,a)otherwise?
- 對于任何MDP問題,總存在一個確定性的最優策略;
- 如果我們得到了最優動作價值函數 q ? ( s , a ) q_{*}(s,a) q??(s,a),則表明我們已經找到了最優策略。
例子:Student MDP的最優策略
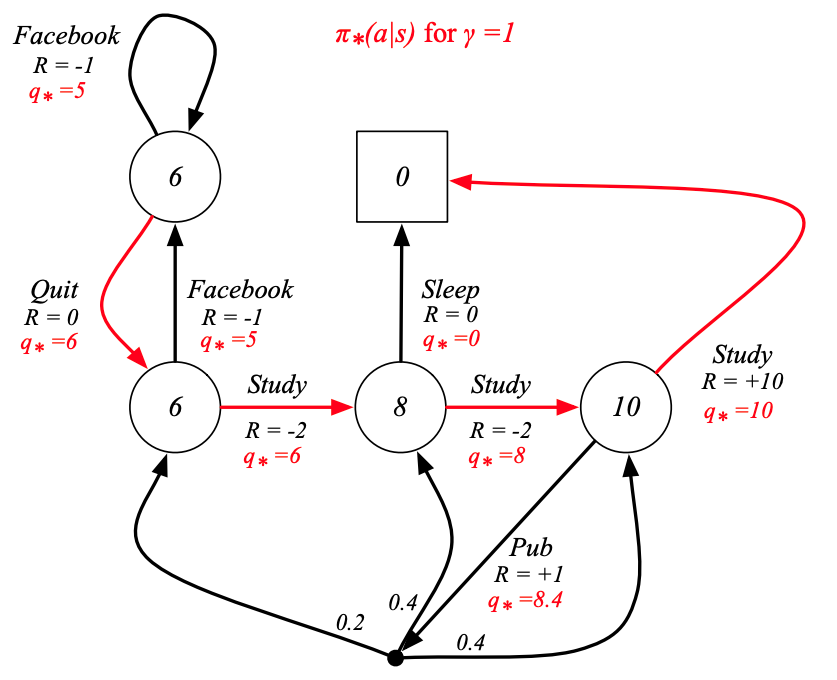
v ? v_{*} v??的貝爾曼最優方程
最優值函數通過貝爾曼最優方程遞歸關聯
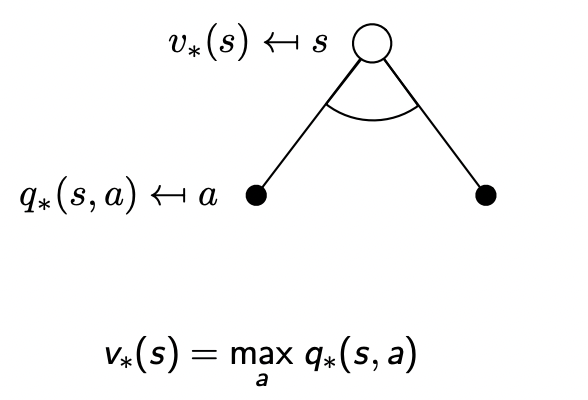
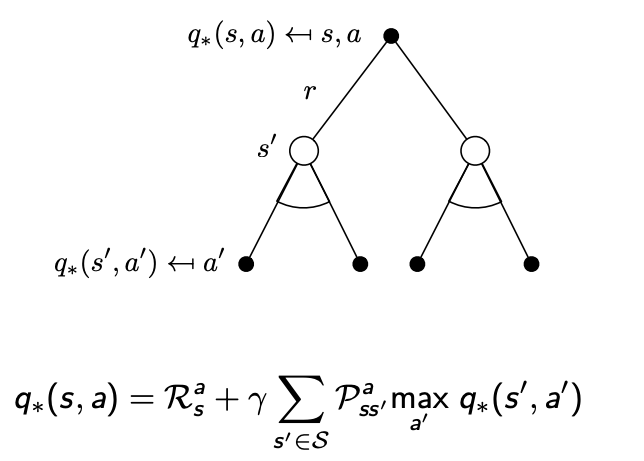
Q ? Q_{*} Q??的貝爾曼最優方程
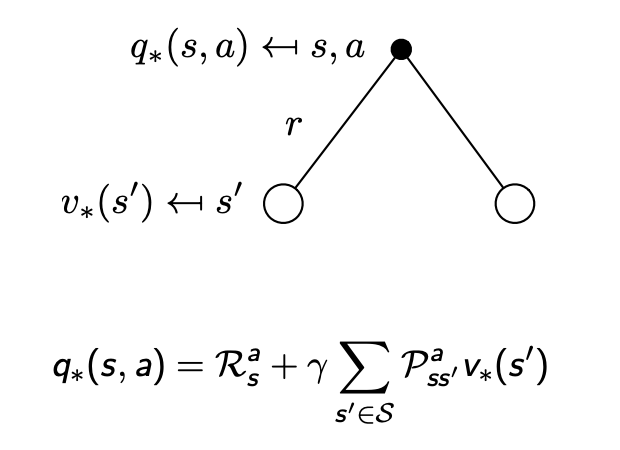
v ? v_{*} v??的貝爾曼最優方程(2)
Q ? Q_{*} Q??的貝爾曼最優方程(2)
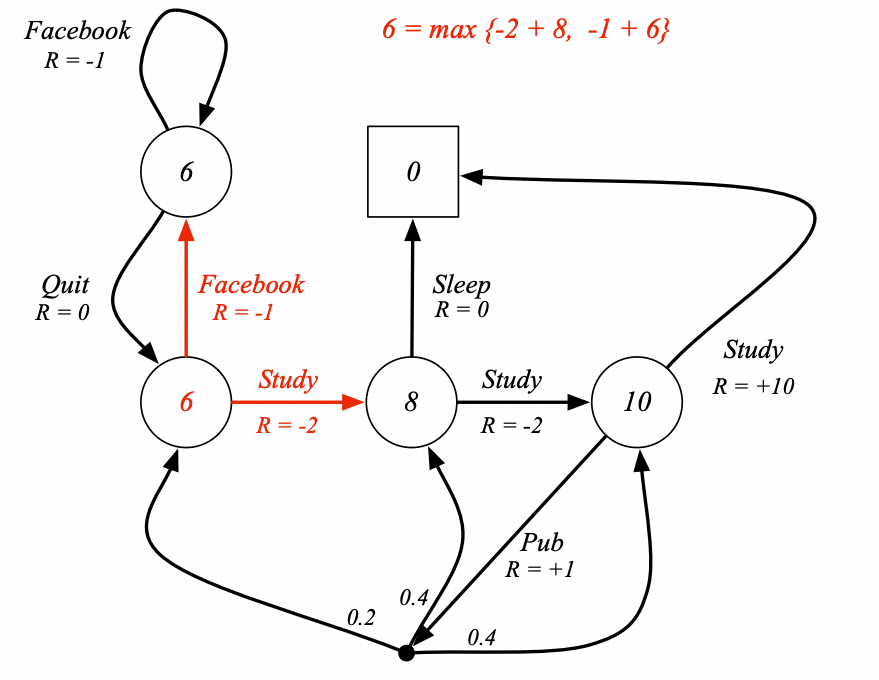
例子:Student MDP的貝爾曼最優方程
求解貝爾曼最優方程:
爾曼最優方程是非線性的,(一般情況下)沒有封閉解,但有許多迭代求解方法來解決:價值迭代(Value Iteration)、策略迭代(Policy Iteration)、Q學習(Q-learning)、Sarsa等
還有一些馬爾可夫決策過程(MDPs)的擴展,比如:
- 無限和連續的馬爾可夫決策過程(Infinite and continuous MDPs)
- 部分可觀測的馬爾可夫決策過程(Partially observable MDPs)
- 無折扣、平均獎勵的馬爾可夫決策過程(Undiscounted, average reward MDPs)
這里不做一一講解
——LeetCode45.跳躍游戲II763.劃分字母區間)





:常見位運算操作總結)












